Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
CUDA & OpenMP parallel programming

2
GPU vs CPU

3
Multiprocessor CPU

4
CPU POSIX Threads OpenMP

5
CPU POSIX Threads OpenMP

6
CPU POSIX Threads MPI OpenMP

7
CPU MapReduce POSIX Threads MPI OpenMP

8
GPU CUDA

9
GPU CUDA

10
GPU Vs CPU

11
GPU Vs CPU

12
Che cosè un processo?

13
fock()
")
14
Multi-threading

15
POSIX Threads, or Pthreads, is a POSIX standard for threads.
The standard, POSIX.1c, Threads extensions, defines an API for creating and manipulating threads. #include <pthread.h> #include <stdio.h> #include <stdlib.h> #define NUM_THREADS 5 void *PrintHello(void *threadid) { long tid; tid = (long)threadid; printf("Hello World! It's me, thread #%ld!\n", tid); pthread_exit(NULL); } int main (int argc, char *argv[]) pthread_t threads[NUM_THREADS]; int rc; long t; for(t=0; t<NUM_THREADS; t++){ printf("In main: creating thread %ld\n", t); rc = pthread_create(&threads[t], NULL, PrintHello, (void *)t); if (rc){ printf("ERROR; return code from pthread_create() is %d\n", rc); exit(-1);
 { long tid; tid = (long)threadid; printf( Hello World! It s me, thread #%ld!\n , tid); pthread_exit(NULL); } int main (int argc, char *argv[]) pthread_t threads[NUM_THREADS]; int rc; long t; for(t=0; t<NUM_THREADS; t++){ printf( In main: creating thread %ld\n , t); rc = pthread_create(&threads[t], NULL, PrintHello, (void *)t); if (rc){ printf( ERROR; return code from pthread_create() is %d\n , rc); exit(-1);")
16
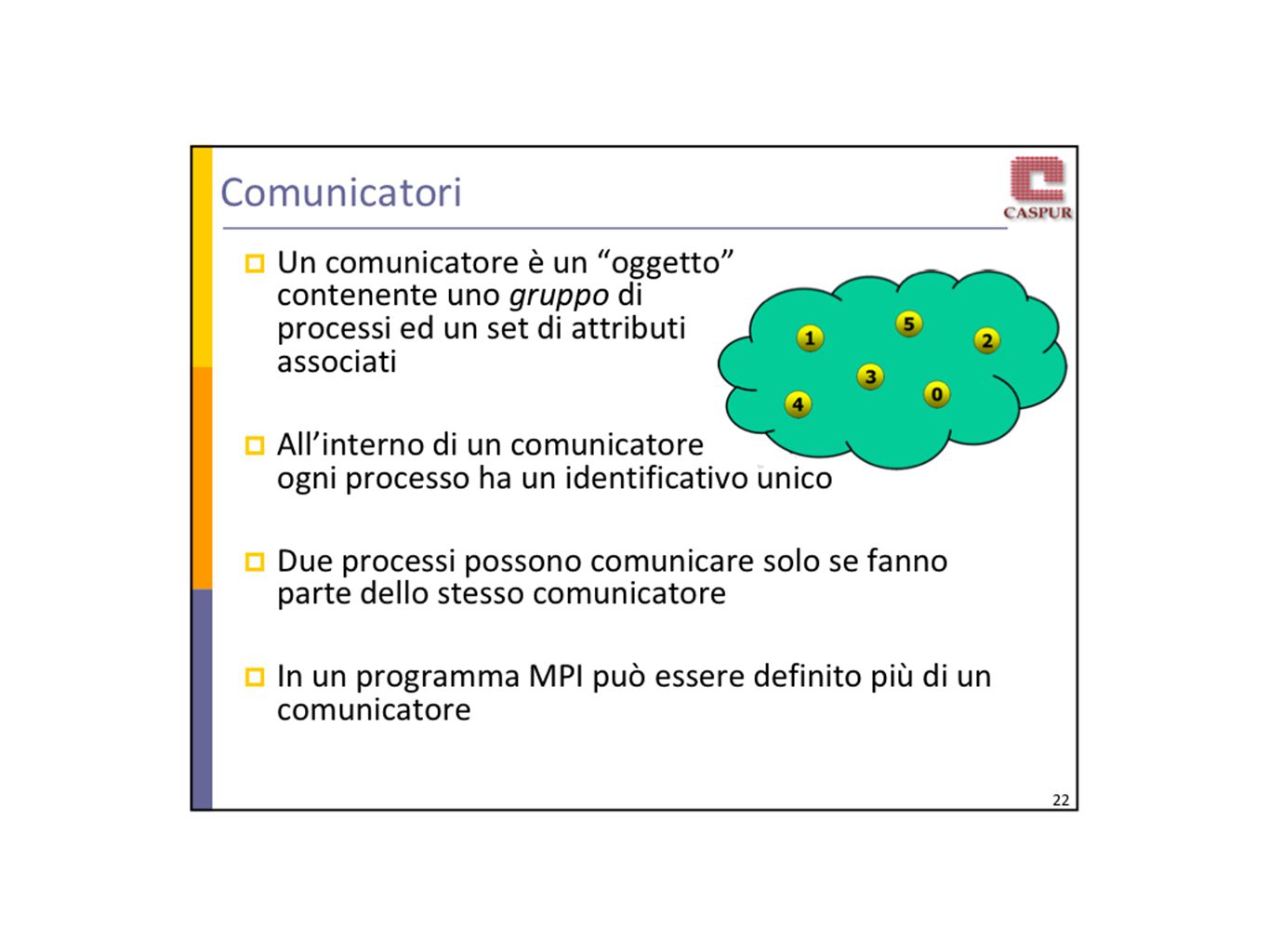
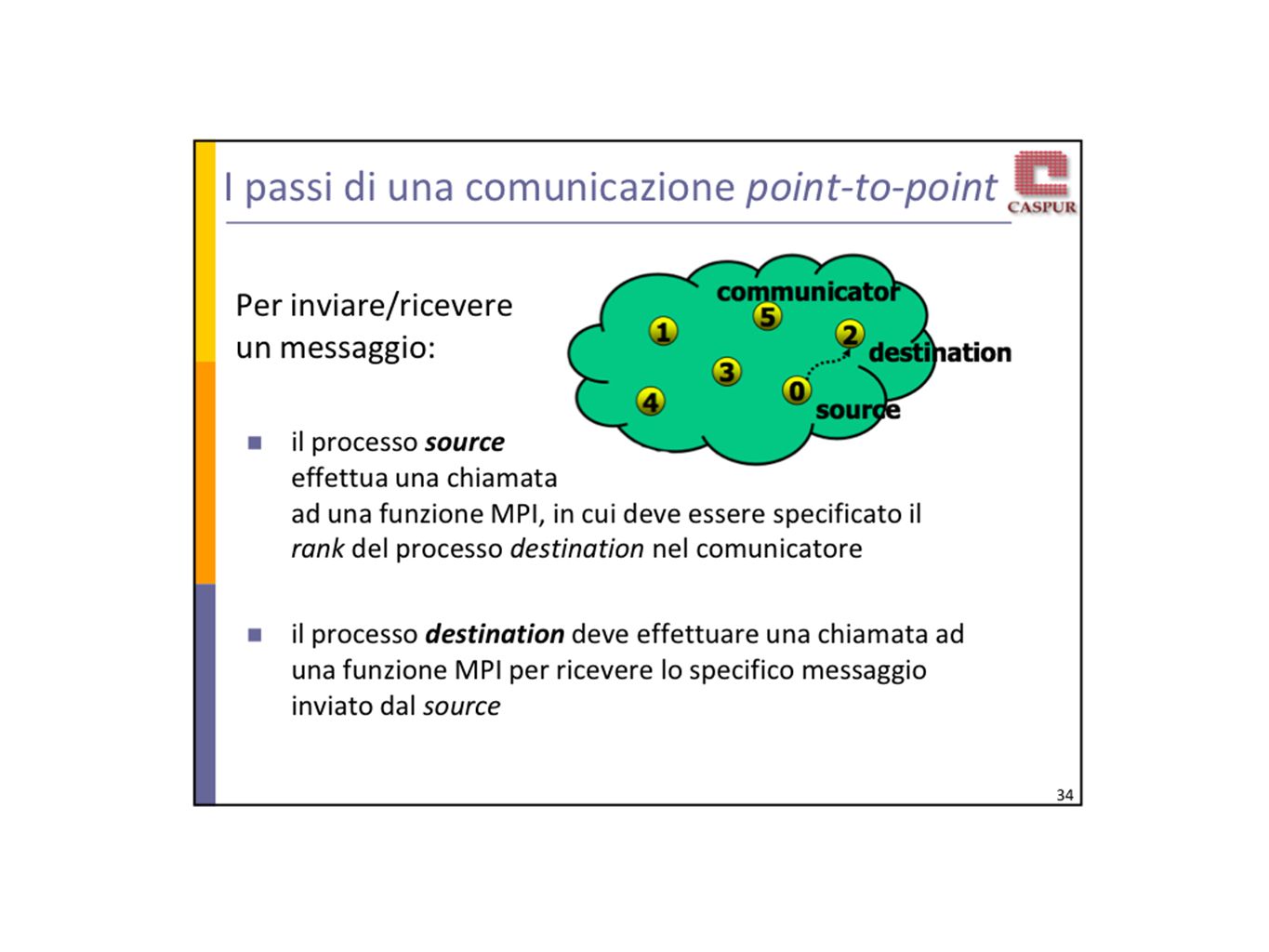
MPI Message Passing Interface

17
MPI Message Passing Interface

22
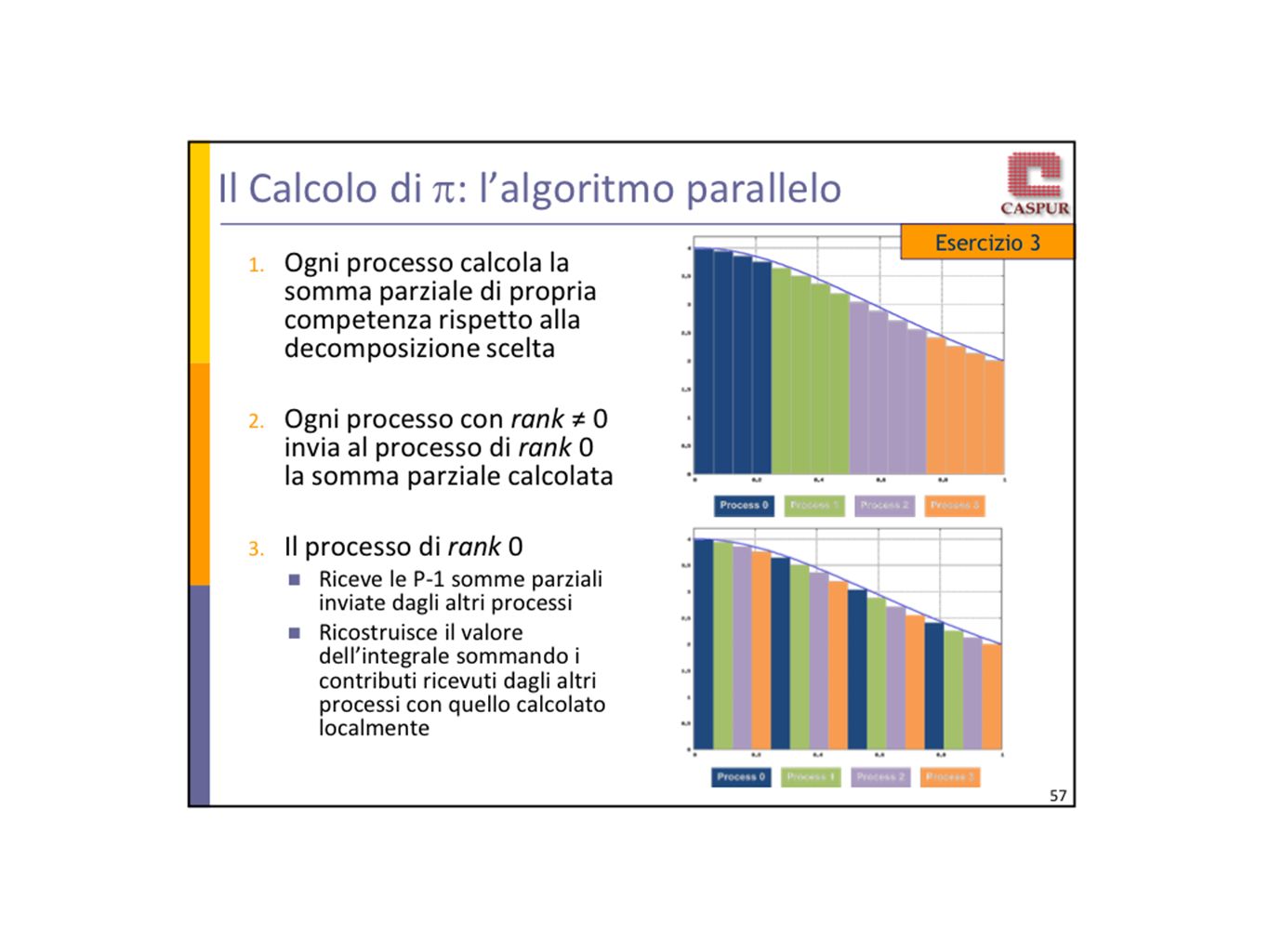
ESEMPIO

23
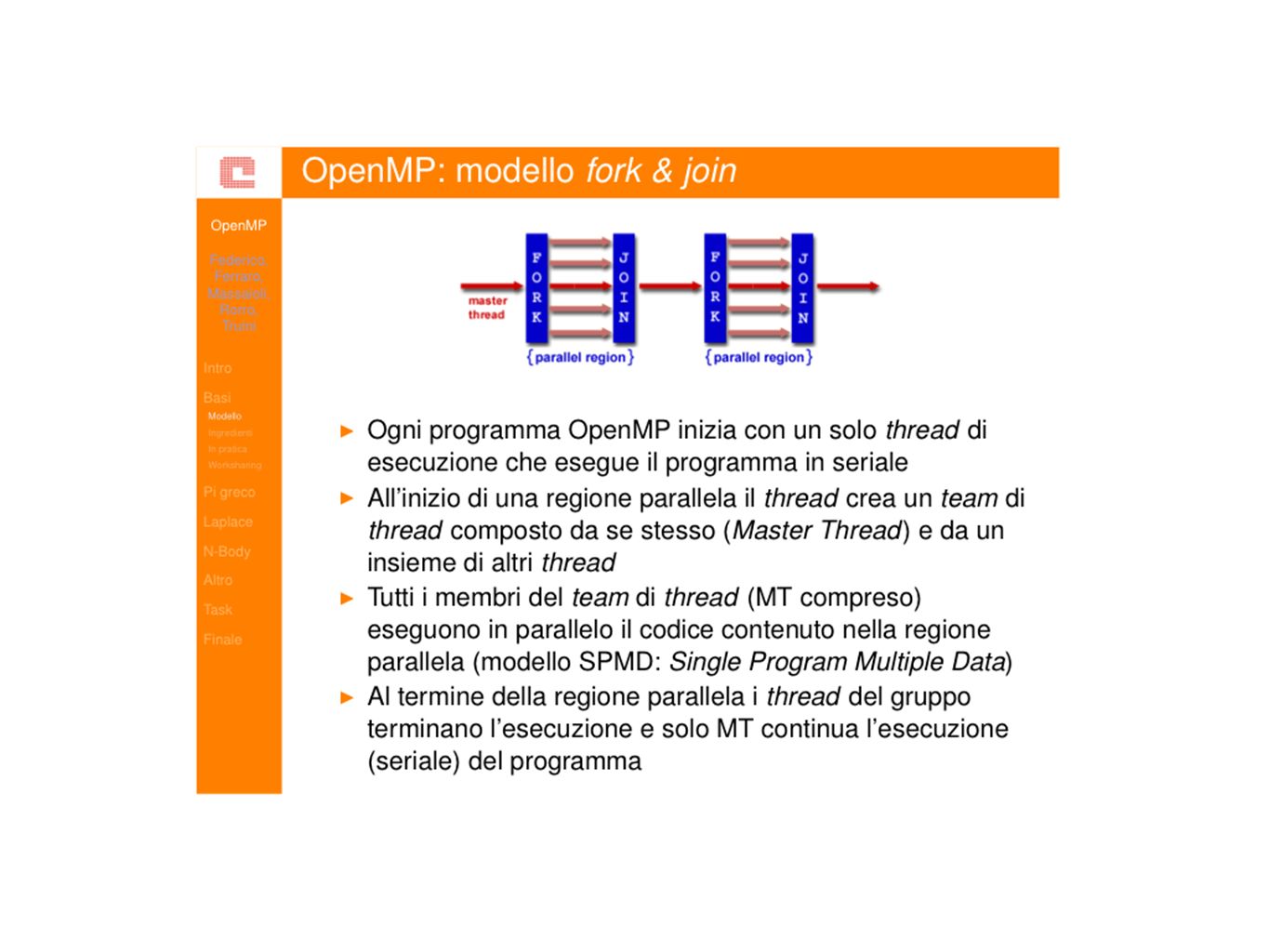
OpenMP Open Multi-Processing

27
Costrutti OpenMP

28
Costrutti OpenMP

29
ESEMPI

30
CUDA Compute Unified Device Architecture

31
Processing flow on CUDA

32
CUDA programming language

33
CUDA programming language
Third party wrappers are also available for Python, Fortran, Java and Matlab

34
Architettura nelle GPU
Nelle GPU sono integrati 512 CUDA Cores, nome scelto da NVIDIA per indicare i propri stream processors. Le GPU vedono i 512 CUDA Cores divisi in blocchi, ciascuno dei quali è indicato come streaming multiprocessor o SM;

35
Come è fatto un SM? La parte centrale vede la presenza dei 32 CUDA cores: a gruppi di 4 sono associati a due unità di load e store (LD/ST). Mentre 2 di questi gruppi, per un totale di 8 CUDA cores, sono abbinati ad una unità di tipo special function (SFU). A monte troviamo una cache per le istruzioni, seguita da due Warp Scheduler e da due unità per le operazioni di dispatch, collegate al registro dei files capace di gestire un massimo di entry a 32bit. Ogni singolo CUDA Core integra al proprio interno un Dispatch Port, una unità per la raccolta degli operanti, una unità in floating point e una per i calcoli interni oltre ad una result queue.
. A monte troviamo una cache per le istruzioni, seguita da due Warp Scheduler e da due unità per le operazioni di dispatch, collegate al registro dei files capace di gestire un massimo di entry a 32bit. Ogni singolo CUDA Core integra al proprio interno un Dispatch Port, una unità per la raccolta degli operanti, una unità in floating point e una per i calcoli interni oltre ad una result queue.")
36
Come è fatto un SM? Per ogni streaming microprocessor troviamo una cache dedicata da 64 Kbytes di capacità, partizionabile come memoria condivisa e come cache L1: i rapporti sono 1:3 oppure 3:1 Ogni SM integra al proprio interno 4 texture units, per un totale quindi di 60 unità di questo tipo presenti all'interno delle schede GeForce GTX 480 Le textures units sono dotate di una propria cache dedicata integrata all'interno dello specifico SM.

37
A completare la gerarchia della cache segnaliamo anche la presenza di una cache L2 integra alla GPU, di tipo unificato tra i vari SM, in quantitativo di 768 Kbytes. La gerarchia della cache vede quindi ogni thread a gestire in primo livello la cache da 64 Kbytes integrata in ogni SM, divisa in un blocco condiviso e in un secondo blocco di tipo L1 con dimensioni che possono essere pari a 16K/48K oppure 48K/16K.

38
GeForce GTX 480

39
Threads Hierarchy

40
Memory Hierarchy

41
Heterogeneous Programming

42
Coalesced Global Memory Access

43
Coalesced Global Memory Access

Presentazioni simili


















>")
 int valore, dato; printf(Introduci n:>")

, direttamente dalla linea.>")
