Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
MODELLI MATEMATICI E STATISTICI [6– Modelli statistici]
Università di Sassari LAUEREA SPECIALISTICA IN PRODUZIONI ZOOTECNICHE MEDITERRANEE MODELLI MATEMATICI E STATISTICI [6– Modelli statistici] Proff. Giuseppe Pulina & Corrado Dimauro
![MODELLI MATEMATICI E STATISTICI [6– Modelli statistici]](http://slideplayer.it/slide/2266105/8/images/1/MODELLI+MATEMATICI+E+STATISTICI+%5B6%E2%80%93+Modelli+statistici%5D.jpg "Università di Sassari. LAUEREA SPECIALISTICA IN. PRODUZIONI ZOOTECNICHE MEDITERRANEE. MODELLI MATEMATICI E STATISTICI. [6– Modelli statistici] Proff. Giuseppe Pulina & Corrado Dimauro.")
2
IL TEOREMA DEI MINIMI QUADRATI
E LA CURVA DI GAUSS

3
IL METODO DEI MINIMI QUADRATI
Il primo ad utilizzare tale metodo fu Carl Friederich Gauss ( ) TEOREMA Il valore medio delle osservazioni Om è il valore medio della grandezza misurata che minimizza La somma degli errori al quadrato
 TEOREMA. Il valore medio delle osservazioni Om è il valore. medio della grandezza misurata che minimizza. La somma degli errori al quadrato.")
4
DIMOSTRAZIONE Siano: Oi = i-esima osservazione Om = il valore medio x = il valore vero εi = l’errore di cui è affetta l’i-esima osservazione Poiché

5
Consideriamo la somma degli scarti dal valore vero al quadrato
Che può essere scritta, relativa alla media, come: Dobbiamo dimostrare che questa somma è minima quando x =Om Sviluppando i quadrati si ottiene:

6
Da cui ordinando si ha: Raggruppando si ottiene: = 0 Essendo

7
Si ha alla fine: Questa funzione ha un minimo in Da cui sostituendo si ha:

8
LA CURVA DI GAUSS Il prototipo della curva di Gauss è Con h = parametro di larghezza Studiamo questa funzione

11
La funzione ha quindi un massimo
E due flessi

12
h = parametro di larghezza?

13
Non è ancora nella sua forma finale
Condizione di normalizzazione

14
Sostituendo x con x-X Il massimo sarà f(x) x X X X
 x X X X")
15
Si può dimostrare che Ed infine si ha

16
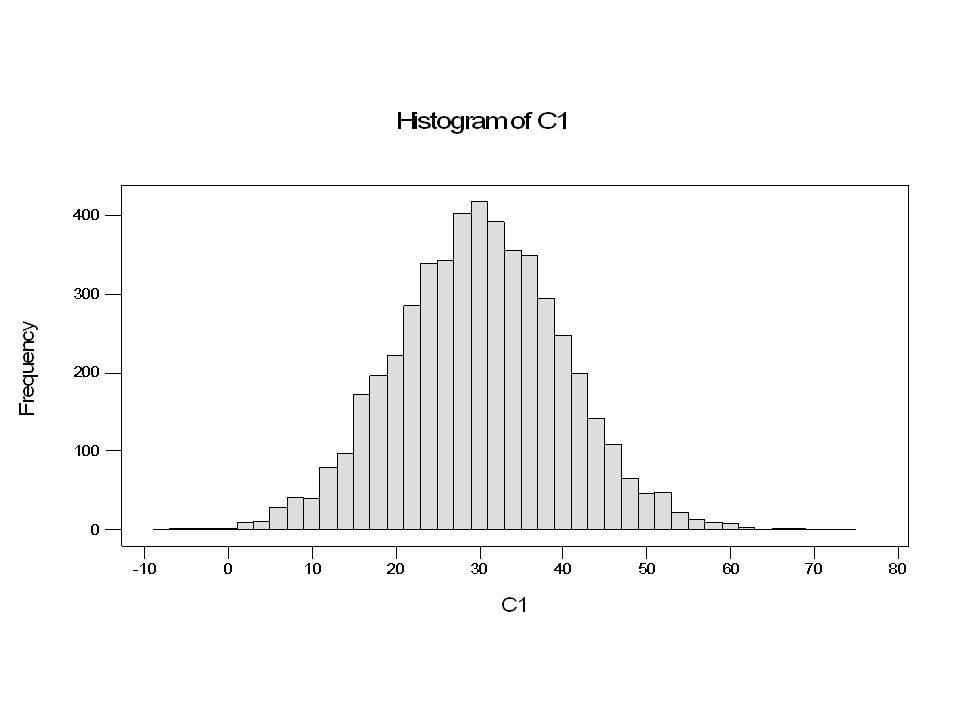
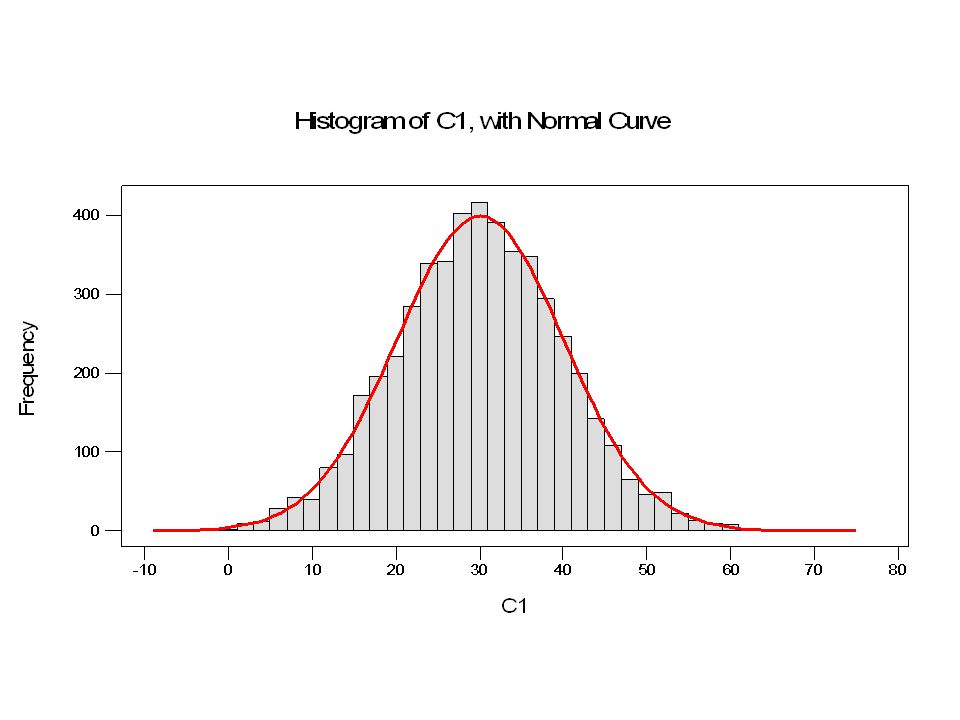
La deviazione standard come limite di confidenza del 68%
Probabilità che una data misura cada in [a,b] Probabilità che una data misura cada tra [μ-σ, μ+σ ]

17
68%

18
I MODELLI STATISTICI

19
I modelli statistici sono strumenti matematici e algebrici in grado di analizzare le componenti regolari e casuali di un insieme di dati In questo corso analizzeremo le relazioni fra variabili con il metodo della regressione multipla. Tale classe di modelli appartiene ai metodi dell’Analisi a più variabili. Saranno analizzate principalmente le tecniche della regressione lineare multipla [modelli lineari o linearizzabili] e una parte sarà dedicata alla regressione non lineare (esponenziale; allometrica) Le applicazioni saranno eseguite con le routine di MS-Excell®
 Le applicazioni saranno eseguite con le routine di MS-Excell®")
20
Il fine dell’analisi della regressione multipla è quello di stabilire, se esiste, una relazione fra una variabile risposta (variabile dipendente, generalmente indicata con y) e un insieme di variabili indipendenti, generalmente indicate con x1, x2…xn. Il modello statistico generale è il seguente yi = a + b1x1i+b2x2i,+…+bnxni+εi In cui yi= variabile dipendente; x.i = variabile indipendente; εi= scostamento casuale dal modello o residuo (media =0, varianza σ2); a = intercetta (stessa dimensione della y); b = coefficienti (o regressori parziali) del modello. Nelle scienze zootecniche l’analisi della regressione multipla è ampiamente utilizzata per la messa a punto di modelli di previsione del comportamento di una variabile di interesse zootecnico (es.: produzione di latte, accrescimento, qualità di prodotti, ingestione alimentare, ecc..) rispetto ad altre variabili [chiamate “predittori del modello”]
; a = intercetta (stessa dimensione della y); b = coefficienti (o regressori parziali) del modello. Nelle scienze zootecniche l’analisi della regressione multipla è ampiamente utilizzata per la messa a punto di modelli di previsione del comportamento di una variabile di interesse zootecnico (es.: produzione di latte, accrescimento, qualità di prodotti, ingestione alimentare, ecc..) rispetto ad altre variabili [chiamate predittori del modello ]")
21
REGRESSIONE LINEARE SEMPLICE
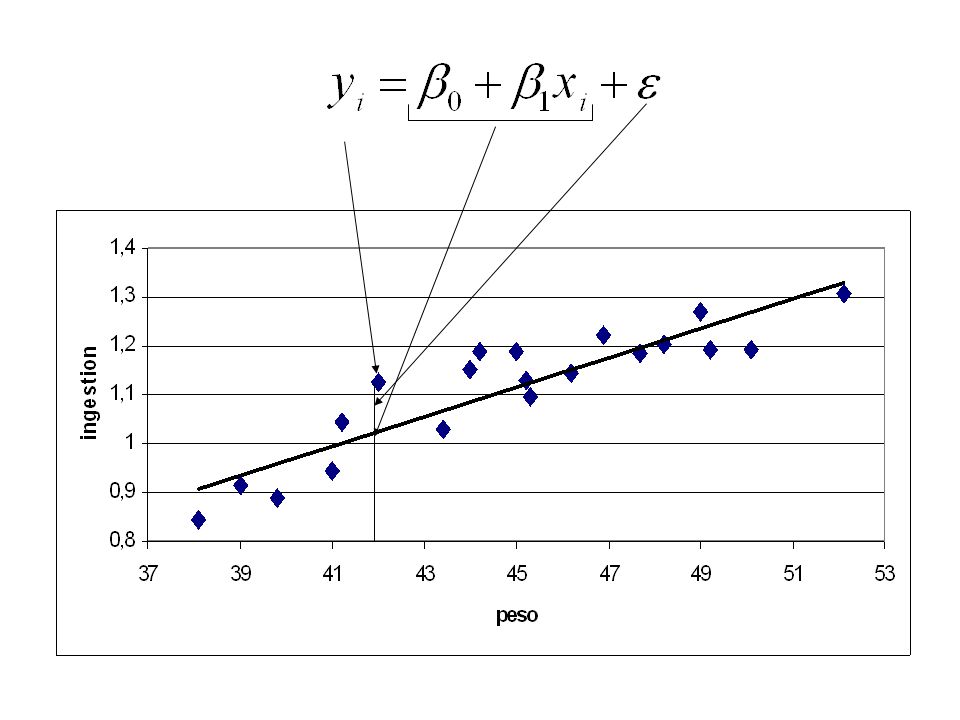
Consideriamo il caso in cui una certa variabile detta variabile dipendente è influenzata da una o più variabili dette variabili dipendenti. Il caso più semplice è: la y dipende solo da un’altra variabile x. ESEMPIO: relazione tra peso ed ingestione in pecore Sarde in asciutta

23
PLOT DEI DATI SU UN SISTEMA DI ASSI

24
Il metodo impiegato per la stima dei parametri dell’equazione che meglio si adatta ai dati è quello detto DEI MINIMI QUADRATI La procedura generale dei minimi quadrati è la seguente:

25
Equazione cartesiana della retta:
In statistica: Una equazione in questa forma rappresenta un modello deterministico

27
Vogliamo ottenere la stima dei parametri del modello:
Per ottenere la retta di regressione La stima di E(y) è data dall’equazione
 è data dall’equazione.")
28
e Metodo dei minimi quadrati per la stima dei parametri
Consideriamo il cosiddetto residuo Il metodo dei minimi quadrati permette di scegliere la retta migliore per minimizzare la somma:

29
Sviluppando i quadrati si ottiene:
Questa funzione è minima quando la derivata prima rispetto β0 e a β1 è zero:

30
Sviluppiamo la prima:

31
Sviluppiamo la seconda:

32
Le due derivate costituiscono un sistema di equazioni:
Poniamo: E sostituendo:

33
Risolvendo il sistema di equazioni si ottiene:
E sostituendo: β0 sarà calcolata sostituendo nell’equazione della retta:

34
REGRESSIONE LINEARE MULTIPLA

35
Ingestione Peso ProdLatte 2,833 45,0 1,7 2,459 44,0 1,4 2,087 35,0 1,2 2,130 41,0 1 2,941 42,0 2 3,003 43,4 2,1 2,524 46,9 2,663 45,2 1,5 2,295 39,8 3,160 50,1 2,2 2,926 49,2 1,9 2,722 45,3 3,031 46,2 2,353 44,2 2,310 41,2 1,24 3,154 52,1 2,05 3,094 47,7 2,11 2,785 48,2 1,75 2,108 38,1 1,1 2,440 49,0 0,9 Esempio: è noto che l’ingestione alimentare degli animali zootecnici dipende, tra le altre cose, dalla mole e dal livello produttivo. La matrice dei dati riportata a fianco riguarda dei rilievi sperimentali effettuati su pecore in lattazione di razza Sarda. Il quesito è: riusciamo a prevedere l’ingestione di sostanza secca di una pecora Sarda in base al suo peso corporeo e alla sua produzione di latte?

36
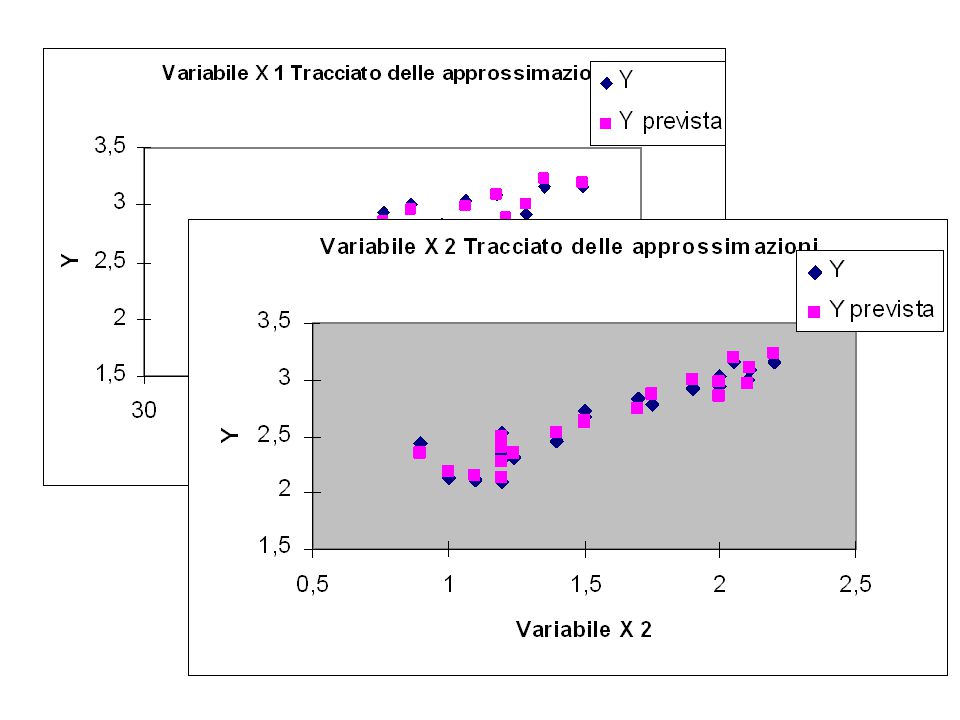
Il modello fornisce un’unica previsione e un insieme di correlazioni parziali. Ciascun coefficiente “b” rappresenta un contributo indipendente di ciascuna variabile alla previsione del valore della variabile dipendente (y). Il fatto di dover fornire un contributo indipendente significa che la variabili “x” sono indipendenti fra loro, cioè non sono correlate. In termini geometrici, gli assi delle variabili (tutte, dipendente e indipendenti) sono fra loro ortogonali. Il primo passo dell’analisi della regressione lineare multipla è l’EDA (exploratory data analysis) che consiste 1. nel “plottare” le singole variabili indipendenti rispetto alla variabile dipendente; 2. nel calcolare la matrice della correlazione fra le variabili indipendenti. Se fra due di esse la correlazione è “importante” [ad es, esiste (cioè è differente da zero per p<0,05) ed è superiore al 20-25%, una delle variabili deve essere eliminata per evitare fenomeni di collinearità.]
 sono fra loro ortogonali. Il primo passo dell’analisi della regressione lineare multipla è l’EDA (exploratory data analysis) che consiste. 1. nel plottare le singole variabili indipendenti rispetto alla variabile dipendente; 2. nel calcolare la matrice della correlazione fra le variabili indipendenti. Se fra due di esse la correlazione è importante [ad es, esiste (cioè è differente da zero per p<0,05) ed è superiore al 20-25%, una delle variabili deve essere eliminata per evitare fenomeni di collinearità.]")
37
L’EDA consente di verificare:
Se l’andamento della singola variabile indipendente rispetto alla dipendente è lineare Se vi è una correlazione “importante” fra le due Se le variabili indipendenti sono correlate fra di loro Se esiste una aggregazione di dati [cluster] e dei dati “lontani” detti outliers

38
Risposte ai singoli quesiti EDA.
Si: il “regressore” può essere trattato con un modello lineare. No: si deve utilizzare una trasformata (es, logaritmo, inversa, ecc.) oppure un ordine superiore (quarato, cubo). Si: la variabile va inserita nel modello lineare. No: va esclusa. Si: va scartata una delle due, di solito quella meno correlata con la y (cioè quella che spiega una minore quota di variabilità). Si: deve essere cambiata la scala (cluster); devono essere ricontrollati i dati e “scaricati” quelli anomali (grande attenzione a non “scaricare” dati “buoni”)
 oppure un ordine superiore (quarato, cubo). Si: la variabile va inserita nel modello lineare. No: va esclusa. Si: va scartata una delle due, di solito quella meno correlata con la y (cioè quella che spiega una minore quota di variabilità). Si: deve essere cambiata la scala (cluster); devono essere ricontrollati i dati e scaricati quelli anomali (grande attenzione a non scaricare dati buoni )")
39
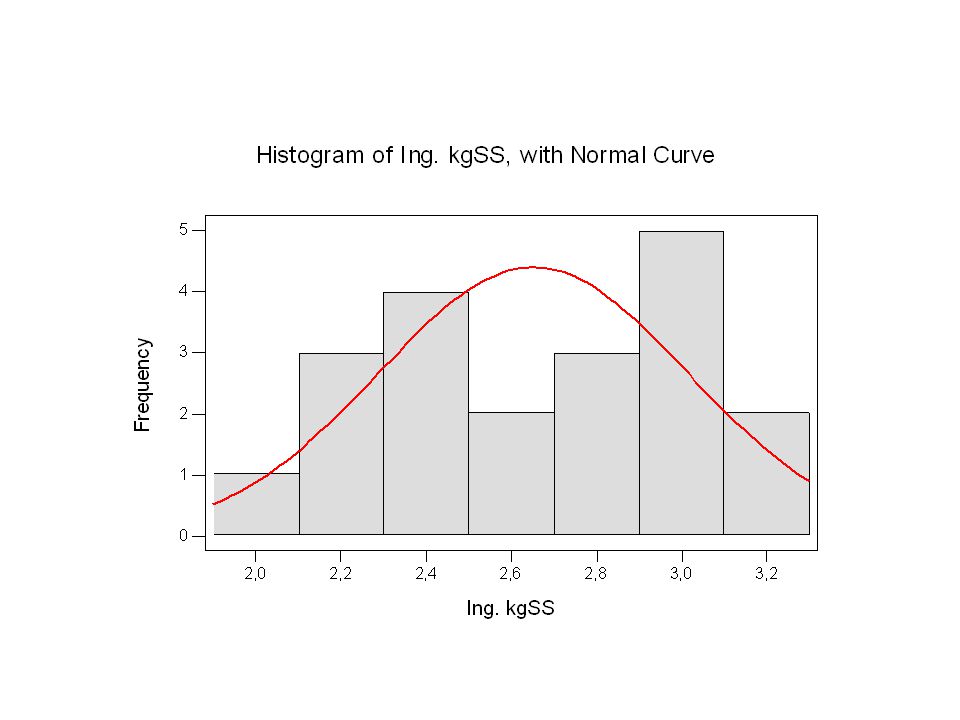
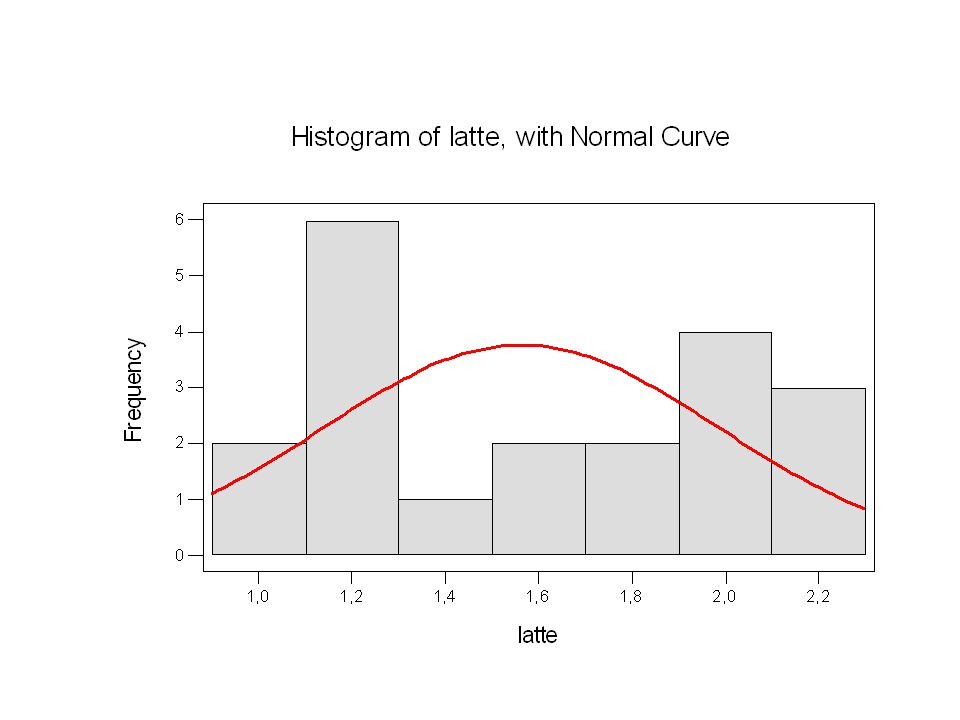
Un altro assunto importante per l’analisi della regressione multipla è la distribuzione normale delle variabili e degli errori (o residui). Ing. kgSS peso (kg) Latte (kg) Media 2,6509 44,68 1,5625 Errore standard 0, 0,958359 0,094821 Mediana 2,6925 45,1 1,5 Moda #N/D 1,2 Deviazione standard 0, 4,285913 0,424052 Varianza campionaria 0, 18,36905 0,17982 Curtosi -1, 0,000342 -1,52423 Asimmetria -0, -0,44209 0,086596 Intervallo 1,073 17,1 1,3 Minimo 2,087 35 0,9 Massimo 3,16 52,1 2,2 Somma 53,018 893,6 31,25 Conteggio 20
 Latte (kg) Media. 2, ,68. 1,5625. Errore standard. 0, , , Mediana. 2, ,1. 1,5. Moda. #N/D. 1,2. Deviazione standard. 0, , , Varianza campionaria. 0, , , Curtosi. -1, , , Asimmetria. -0, , , Intervallo. 1, ,1. 1,3. Minimo. 2, ,9. Massimo. 3,16. 52,1. 2,2. Somma. 53, ,6. 31,25. Conteggio. 20.")
43
EDA - Correlazioni (1)
")
44
EDA – Visione di insieme dei dati

45
EDA – Visione di insieme dei dati [superficie]
![EDA – Visione di insieme dei dati [superficie]](http://slideplayer.it/slide/2266105/8/images/45/EDA+%E2%80%93+Visione+di+insieme+dei+dati+%5Bsuperficie%5D.jpg "EDA – Visione di insieme dei dati [superficie]")
46
Ing. kgSS peso (kg) latte 1 0,742347 0,931149 0,486831
EDA - Correlazioni (2) Ing. kgSS peso (kg) latte 1 0,742347 0,931149 0,486831 Collinearità fra le variabili indipendenti Non vi è nessuna aggregazione [cluster] di dati né outliers.
 Ing. kgSS. peso (kg) latte. 1. 0, , , Collinearità fra le variabili indipendenti. Non vi è nessuna aggregazione [cluster] di dati né outliers.")
47
LA CORRELAZIONE PARZIALE
sxy > 0 se x ed y tendono a cadere al di sopra delle lore medie sxy < 0 se x ed y tendono a cadere al di sotto delle lore medie Es. Peso statura

48
Correlazione Negativa Positiva Piccola −0,3 a −0,1 0,1 a 0,3 Media −0,5 a −0,3 0,3 a 0,5 Grande −1,0 a −0,5 0,5 a 1,0 Es. Peso statura

50
Supponiamo di avere tre variabili: x, y, z
Ci interessa la correlazione tra x ed y, ma sospettiamo che z influenzi tale correlazione. Ad esempio x=HG ed y=cn: quale è l’influenza di z=HD? quale è la correlazione netta tra HG e cn?

51
rxy.z uguale a rxy Calcoliamo rxy.z rxy.z diverso da rxy Algoritmo di calcolo: 1) Regressione x-z e residui 2) Regressione y-z e residui 3) La correlazione parziale rxy.z è la correlazione tra i residui
 Regressione y-z e residui. 3) La correlazione parziale rxy.z è la correlazione tra i residui.")
52
VALUTAZIONE DELLA REGRESSIONE
La bontà della regressione è valutabile : 1. Dal valore del coefficiente di determinazione R2 2. Dalla distribuzione casuale dei residui 3. Dall’ininfluenza della eliminazione (trimming) di uno o più dati “estremi” sui valori dei regressori [a oppure b.] 4. Dall’esistenza deI regressore [a oppure b.] il cui valore deve essere significativamente diverso da zero.
 di uno o più dati estremi sui valori dei regressori [a oppure b.] 4. Dall’esistenza deI regressore [a oppure b.] il cui valore deve essere significativamente diverso da zero.")
53
Valore di significatività
Risultati dell’analisi della regressione effettuata con MS-Excell® Coefficienti Errore standard Stat t Valore di significatività Intercetta (SS) 0,3058 0,1602 1,9095 0,0732 Variabile X 1 (PC) 0,0298 0,0041 7,2852 0,0000 Variabile X 2 (L) 0,6479 0,0414 15,6556 L’equazione ottenuta è la seguente: Ingestione (kg/d SS) = 0,3058 (ns) + 0,0298 PC (kg) + 0,6479 L (kg/d) [+ ε]
 0, , , ,0732. Variabile X 1 (PC) 0, , , ,0000. Variabile X 2 (L) 0, , ,6556. L’equazione ottenuta è la seguente: Ingestione (kg/d SS) = 0,3058 (ns) + 0,0298 PC (kg) + 0,6479 L (kg/d) [+ ε]")
54
Sviluppo dell’equazione calcolata
Osservazione (Y) Prevista (Ŷ) Residui(ε) 2,833 2,750 0,083 2,459 2,525 -0,066 2,087 2,127 -0,040 2,130 2,177 -0,047 2,941 2,854 0,087 3,003 2,961 0,042 2,524 2,482 2,663 2,626 0,037 2,295 2,270 0,025 3,160 3,226 2,926 3,004 -0,078 2,722 2,629 0,093 3,031 2,980 0,051 2,353 2,402 -0,049 2,310 2,338 -0,028 3,154 3,188 -0,034 3,094 3,096 -0,002 2,785 2,877 -0,092 2,108 2,155 2,440 2,351 0,089
 Prevista (Ŷ) Residui(ε) 2,833. 2,750. 0,083. 2,459. 2, ,066. 2,087. 2, ,040. 2,130. 2, ,047. 2,941. 2,854. 0,087. 3,003. 2,961. 0,042. 2,524. 2,482. 2,663. 2,626. 0,037. 2,295. 2,270. 0,025. 3,160. 3,226. 2,926. 3, ,078. 2,722. 2,629. 0,093. 3,031. 2,980. 0,051. 2,353. 2, ,049. 2,310. 2, ,028. 3,154. 3, ,034. 3,094. 3, ,002. 2,785. 2, ,092. 2,108. 2,155. 2,440. 2,351. 0,089.")
55
Statistica della regressione
Risultati dell’analisi della regressione effettuata con MS-Excell® R2 = coefficiente di determinazione. Misura la quota di variabilità “spiegata” dalla regressione sulla variabilità totale Statistica della regressione R multiplo 0,985334 R al quadrato 0,970882 R al quadrato corretto 0,967457 Errore standard 0,06552 Osservazioni 20 ANALISI VARIANZA gdl SQ MQ F Significatività F Regressione (Ŷ) 2 2,433375 1,216687 283,4204 0,00000 Residuo (ε) 17 0,072979 0,004293 Totale (Y) 19 2,506354
 2. 2, , , , Residuo (ε) 17. 0, , Totale (Y) 19. 2,")
58
Forma geometrica della regressione [superficie]
![Forma geometrica della regressione [superficie]](http://slideplayer.it/slide/2266105/8/images/58/Forma+geometrica+della+regressione+%5Bsuperficie%5D.jpg "Forma geometrica della regressione [superficie]")
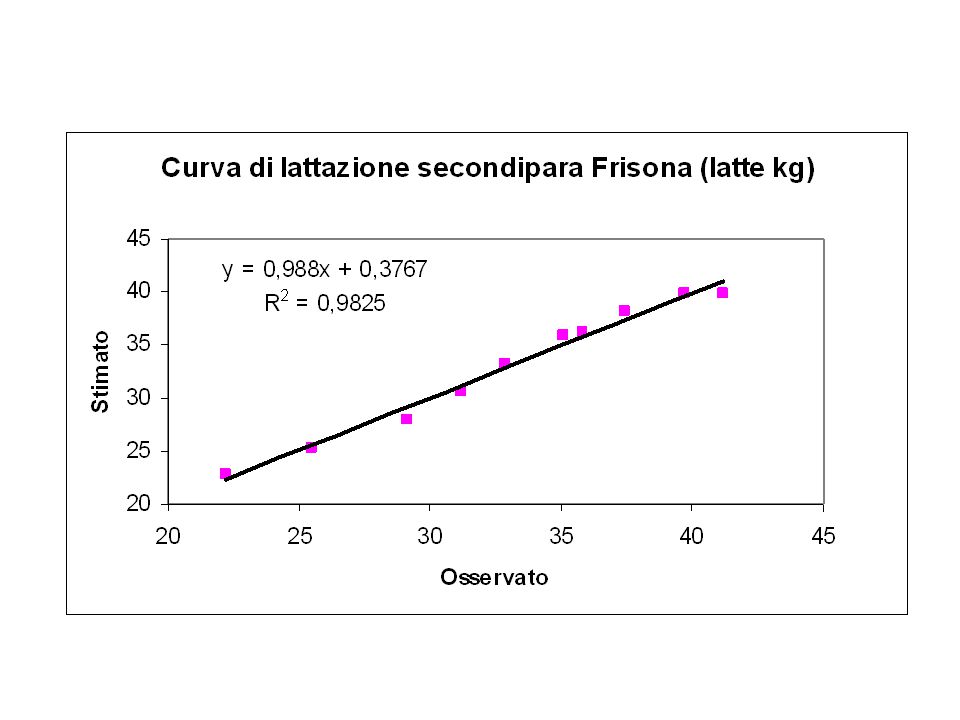
59
Un ulteriore modo per verificare la bontà del modello è quello di “plottare” i dati attesi su quelli osservati. Il modello è tanto migliore quanto l’R2 è maggiore, se il parametro “a” non differisce significativamente da zero e se il parametro “b” non differisce significativamente da 1. Coeff. ES Stat t P Inferiore 95% Superiore 95% Intercetta 0,0772 0,1060 0,7283 0,4758 -0,1455 0,2999 Variabile X 1 0,9709 0,0396 24,4987 0,0000 0,8876 1,0541

60
La validazione di un modello è la sua applicazione su un dataset indipendente. Nel caso del modello di ingestione da noi studiato, la sua applicazione ad una altro dataset ha fornito i seguenti risultati. Coefficienti ES Stat t P Inf95% Sup95% Intercetta -0,1018 0,3865 -0,2634 0,7937 -0,8850 0,6813 Variabile X 1 1,2976 0,1760 7,3748 0,0000 0,9411 1,6541

61
Stima dei parametri della curva di lattazione secondo il modello di Wood con il metodo della regressione lineare multipla. Prendiamo in considerazione i dati di produzione giornaliera di una vacca secondipara Frisona, rilevati con cadenza mensile. latte (kg/d) mese secondipare 1 35,8 2 41,2 3 39,7 4 37,4 5 35,1 6 32,9 7 31,2 8 29,1 9 25,5 10 22,2
 mese. secondipare , , , , , , , , , ,2.")
62
L’equazione gamma-modificata originariamente proposta da Wood (1966) è la seguente [vedi modulo 3 del corso] y(t) = a tb e-ct Il modello di wood può essere trasformato nella forma logaritmica ln (y) = ln (a) + b ln (t) + ct che rappresenta una equazione di regressione multipla utilizzabile per il fitting sui dati sperimentali Y = A + bx + ct In cui Y = ln(y); A = ln(a); x = ln(t)
![L’equazione gamma-modificata originariamente proposta da Wood (1966) è la seguente [vedi modulo 3 del corso]](http://slideplayer.it/slide/2266105/8/images/62/L%E2%80%99equazione+gamma-modificata+originariamente+proposta+da+Wood+%281966%29+%C3%A8+la+seguente+%5Bvedi+modulo+3+del+corso%5D.jpg "y(t) = a tb e-ct. Il modello di wood può essere trasformato nella forma logaritmica. ln (y) = ln (a) + b ln (t) + ct. che rappresenta una equazione di regressione multipla utilizzabile per il fitting sui dati sperimentali. Y = A + bx + ct. In cui Y = ln(y); A = ln(a); x = ln(t)")
63
Per poter applicare il modello logaritmico i dati devono essere riarrangiati nel seguente modo
Coefficienti Errore standard Intercetta 3,725633 0,021721 Variabile X 1 0,336426 0,041645 Variabile X 2 -0,13703 0,010083 log(latte) log(mese) mese 3,578 0,000 1 3,718 0,693 2 3,681 1,099 3 3,622 1,386 4 3,558 1,609 5 3,493 1,792 6 3,440 1,946 7 3,371 2,079 8 3,239 2,197 9 3,100 2,303 10 a = exp(3,725633) = 41,5 b = 0,336 c = -0,137 R2= 0,9841 y (t) = 41,5 t0,336 e-0,137 t
 log(mese) mese. 3,578. 0, ,718. 0, ,681. 1, ,622. 1, ,558. 1, ,493. 1, ,440. 1, ,371. 2, ,239. 2, ,100. 2, a = exp(3,725633) = 41,5. b = 0,336. c = -0,137. R2= 0,9841. y (t) = 41,5 t0,336 e-0,137 t.")
64
Curva di lattazione stimata con il modello di Wood
y (t) = 41,5 t0,336 e-0,137 t; R2=0,9841
 = 41,5 t0,336 e-0,137 t; R2=0,9841.")
66
Esercizio: evoluzione della produzione di latte in vacche Frisone: calcolare il valore dei parametri della curva di lattazione.

67
Evoluzione della produzione di latte in vacche Frisone
latte (kg/d) settimana primipare secondipare pluripare 1 27,4 35,8 38,1 2 30,5 41,2 43,9 3 29,9 39,7 41,6 4 30,2 37,4 39 5 29,1 35,1 35,5 6 28,6 32,9 32,6 7 31,2 29,8 8 25,4 27 9 22,8 25,5 24,2 10 21,3 22,2 20,2
 settimana. primipare. secondipare. pluripare ,4. 35,8. 38, ,5. 41,2. 43, ,9. 39,7. 41, ,2. 37, ,1. 35,1. 35, ,6. 32,9. 32, ,2. 29, , ,8. 25,5. 24, ,3. 22,2. 20,2.")
68
Cenni di tecniche di regressione non lineare
Tra le tecniche di regressione non lineare analizzeremo: La regressione allometrica La regressione esponenziale I modelli polinomiali di grado superiore al 2°

69
La regressione allometrica segue il modello
In cui i parametri da stimare sono “a” e “b” Prima di procedere all’applicazione del modello si effettua l’EDA sui dati sperimentali

70
Il grafico si riferisce alla produzione di latte e di grasso di pecore di razza Sarda. L’ipotesi è che l’andamento segua un modello allometrico

71
Si impiega la routine grafica di Excell ® [click sui dati con il pulsante destro del mouse; aggiungi linea di tendenza; potenza; opzioni; equazione; R2] per trovare l’equazione. L’equazione trovata conferma che il la secrezione complessiva di grasso è meno che proporzionale a quella di latte con una ragione d’esponente pari a 0,85.
![Si impiega la routine grafica di Excell ® [click sui dati con il pulsante destro del mouse; aggiungi linea di tendenza; potenza; opzioni; equazione; R2] per trovare l’equazione.](http://slideplayer.it/slide/2266105/8/images/71/Si+impiega+la+routine+grafica+di+Excell+%C2%AE+%5Bclick+sui+dati+con+il+pulsante+destro+del+mouse%3B+aggiungi+linea+di+tendenza%3B+potenza%3B+opzioni%3B+equazione%3B+R2%5D+per+trovare+l%E2%80%99equazione..jpg "L’equazione trovata conferma che il la secrezione complessiva di grasso è meno che proporzionale a quella di latte con una ragione d’esponente pari a 0,85.")
72
I dati a fianco si riferiscono alla velocità di secrezione oraria del grasso nel latte di pecore Frisone (Mickusick et al JDS 2002) Si impiega la routine grafica di Excell ® per trovare l’equazione.

73
L’equazione dice che la velocità di secrezione al tempo x=1 è di 14 g/h (circa) e che si riduce di una ragione esponenziale di circa 1/3 per ora.
 e che si riduce di una ragione esponenziale di circa 1/3 per ora.")
74
La regressione esponenziale segue il modello matematico
In cui i parametri da stimare sono “a” e “b” I dati a fianco si riferiscono alla frazione cisternale di latte in pecore Sarde in funzione dell’intermungitura (Pulina et al, 2005)
")
75
Si impiega la routine grafica di Excell ® [click sui dati con il pulsante destro del mouse; aggiungi linea di tendenza; opzioni; esponenziale; equazione; R2] per trovare l’equazione.
![Si impiega la routine grafica di Excell ® [click sui dati con il pulsante destro del mouse; aggiungi linea di tendenza; opzioni; esponenziale; equazione; R2] per trovare l’equazione.](http://slideplayer.it/slide/2266105/8/images/75/Si+impiega+la+routine+grafica+di+Excell+%C2%AE+%5Bclick+sui+dati+con+il+pulsante+destro+del+mouse%3B+aggiungi+linea+di+tendenza%3B+opzioni%3B+esponenziale%3B+equazione%3B+R2%5D+per+trovare+l%E2%80%99equazione..jpg "Si impiega la routine grafica di Excell ® [click sui dati con il pulsante destro del mouse; aggiungi linea di tendenza; opzioni; esponenziale; equazione; R2] per trovare l’equazione.")
76
Il modello polinomiale multiplo è il seguente
I parametri da stimare sono la “a” e i “b.” I dati a fianco si riferiscono alla velocità di secrezione oraria del latte in pecore Frisone (Mickusick et al JDS 2002)
")
77
Si impiega la routine grafica di Excell ® [click sui dati con il pulsante destro del mouse; aggiungi linea di tendenza; opzioni; polinomiale; equazione; R2] per trovare l’equazione. n.b. = excell calcola polinomi fino al 6° grado; dal 3° in poi i parametri perdono significato biologico!!
![Si impiega la routine grafica di Excell ® [click sui dati con il pulsante destro del mouse; aggiungi linea di tendenza; opzioni; polinomiale; equazione; R2] per trovare l’equazione.](http://slideplayer.it/slide/2266105/8/images/77/Si+impiega+la+routine+grafica+di+Excell+%C2%AE+%5Bclick+sui+dati+con+il+pulsante+destro+del+mouse%3B+aggiungi+linea+di+tendenza%3B+opzioni%3B+polinomiale%3B+equazione%3B+R2%5D+per+trovare+l%E2%80%99equazione..jpg "n.b. = excell calcola polinomi fino al 6° grado; dal 3° in poi i parametri perdono significato biologico!!")
78
…infatti, l’aumento del grado del polinomio comporta il passaggio della curva su tutti i dati. Nel nostro caso un polinomio di 6° grado si comporta così: …con l’ovvia conseguenza di descrivere tutto e non spiegare nulla.

79
Fine del corso e buon lavoro.

Presentazioni simili





















>")
 Per effettuare test di qualsiasi natura è necessaria.>")
>")