Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Programma 1. Equilibrio e fattori di scostamento: linkage disequilibrium e mutazione 2. Equilibrio e fattori di scostamento: deriva, flusso genico e selezione 3. Mantenimento dei polimorfismi 4. Introduzione al coalescente

2
Programma 3 Generalità sul coalescente Un’applicazione

3
La genetica studia la trasmissione ereditaria dal passato al presente
forward

4
Ma quando si lavora su popolazioni si raccolgono dati sul presente e si cerca di risalire al passato
? ? backward

5
Cos’è un modello? Definire il modello Esplorarne le proprietà
Stimare parametri dai dati Confrontare dati osservati e attese del modello La teoria coalescente è un modello di evoluzione, vista come processo genealogico Nella teoria coalescente la trasmissione ereditaria viene trattata indipendentemente dal processo di mutazione

6
Costruiamo (procedendo verso il passato) la genealogia materna di un gruppo di individui
Due possibilità: o ogni individuo ha una madre diversa: O due individui hanno la stessa madre Chiamo questo fenomeno coalescenza

7
Assunzioni del coalescente classico (Kingman 1982)
Neutralità Siti infiniti Se gli individui sono diploidi e le dimensioni della popolazione sono N, il modello vale per 2N copie aploidi e indipendenti del gene Unione casuale entro la popolazione Dimensioni della popolazione costanti (*) Generazioni non sovrapposte Parliamo di caratteri a trasmissione uniparentale
 Generazioni non sovrapposte. Parliamo di caratteri a trasmissione uniparentale.")
8
Ricostruire la storia di una popolazione
Passato Presente

9
Genealogie N = 10 N costante n = 6 9 generazioni

10
Genealogie MRCA

11
Genealogie MRCA

12
Mutazione

13
Mutazione CAATG CAATA CAGTG TAATA TAACA 1 1 2 3 3 4 5 TAACA TAATA
CGGTG CAGTG CAGTG

14
Non sempre l’albero ricostruito sulla base delle mutazioni è molto informativo
CGGTG CAGTG CAATG TAATA TAACA Possiamo capire qualcosa di più?

15
Nel risalire dal presente al passato incontriamo una successione di eventi di coalescenza. Conseguenze: 1. In un campione di r individui alla generazione 0, il numero di antenati 1, 2,…n generazioni fa (ξ1, ξ2, ..ξn) decresce fino ad arrivare a 1: r = ξ0 ξ1 ξ2 , ..ξn Ogni genealogia viene ricondotta necessariamente a un singolo antenato comune (MRCA). Non è possibile discriminare fra monofilia e polifilia
 decresce fino ad arrivare a 1: r = ξ0 ξ1 ξ2 , ..ξn. Ogni genealogia viene ricondotta necessariamente a un singolo antenato comune (MRCA). Non è possibile discriminare fra monofilia e polifilia.")
16
Nel risalire dal presente al passato incontriamo una successione di eventi di coalescenza. Conseguenze: N1=8 N0=8 ? 2. Se la popolazione è stazionaria (N costante), N donne hanno una madre fra le N donne della generazione precedente. La probabilità di coalescenza è vicina a 1/N
, N donne hanno una madre fra le N donne della generazione precedente. La probabilità di coalescenza è vicina a 1/N.")
17
P(ant.com) P(n) 2 1/N 1-(1/N) 3 2/N 1-(2/N) n n /N 1- n /N
Nel risalire dal presente al passato incontriamo una successione di eventi di coalescenza. Conseguenze: campione P(ant.com) P(n) 2 1/N 1-(1/N) 3 2/N 1-(2/N) n n /N 1- n /N 3. La probabilità P(n) che n alleli abbiano n antenati distinti alla generazione precedente diminuisce con le dimensioni del campione (più grande il campione, più grande la P di almeno un evento di coalescenza)
 P(n) 2. 1/N. 1-(1/N) 3. 2/N. 1-(2/N) n. n /N. 1- n /N. 3. La probabilità P(n) che n alleli abbiano n antenati distinti alla generazione precedente diminuisce con le dimensioni del campione (più grande il campione, più grande la P di almeno un evento di coalescenza)")
18
Dimensioni effettive A A A A Y X X X mt mt NC = 2 NeA = 4 NeX = 3
4. La dimensione effettiva della popolazione è proporzionale a: NC = 2 NeA = 4 NeX = 3 NeY = 1 Ne mt = 1 A A A A Y X X X mt mt

19
Nel risalire dal presente al passato incontriamo una successione di eventi di coalescenza. Conseguenze: 5. I tempi medi di coalescenza aumentano procedendo verso il passato

20
Nel risalire dal presente al passato incontriamo una successione di eventi di coalescenza. Conseguenze: Tempo atteso per passare da k a (k-1) antenati: Tk = 4N/[k(k-1)], o 2N per geni a trasm. uniparentale 6. Il tempo atteso fra due eventi di coalescenza è distribuito esponenzialmente. E(T)=4N: Wright-Fisher
 antenati: Tk = 4N/[k(k-1)], o 2N per geni a trasm. uniparentale. 6. Il tempo atteso fra due eventi di coalescenza è distribuito esponenzialmente. E(T)=4N: Wright-Fisher.")
21
1. Possiamo stimare alcuni parametri: E(TMRCA)=2N= 20 generazioni 2
1. Possiamo stimare alcuni parametri: E(TMRCA)=2N= 20 generazioni 2. Possiamo simulare genealogia e mutazioni 1 2 3 3 4 5 1 TAACA TAATA CAATG CGGTG CAGTG CAGTG
=2N= 20 generazioni 2. Possiamo simulare genealogia e mutazioni TAACA TAATA. CAATG. CGGTG. CAGTG CAGTG.")
22
Programma 3 Generalità sul coalescente Un’applicazione

23
SE-NW gradients in European allele frequencies (Piazza, 1993)
The starting point: genetic variation SE-NW gradients in European allele frequencies (Piazza, 1993)
")
24
Correlations with archaeology
A map describing the diffusion of Neolithic industries from Cavalli-Sforza et al. (1994)
")
25
Estimated ages of mitochondrial haplogroups (Kyrs)
Richards Sykes Richards et al et al. 2000 H(1) HV J(2A) T(2B) IWX(3) X: I: K(4) U(5) : Major extant lineages throughout Europe predate the Neolithic expansion
 HV J(2A) T(2B) IWX(3) X: 20.0 I: K(4) U(5) : Major extant lineages throughout Europe predate the Neolithic expansion.")
26
Is the European gene pool derived from the genes of the first Paleolithic colonisers?
Or did the ancestors of most Europeans live in the Levant before the Neolithic period? W E W E

27
There are significant practical implications
Frequency of the F-508 mutation on total CF mutations (from CFGAC 1994) approx. age 52,000 years
 approx. age. 52,000 years.")
28
Why are genes distributed the way they are?
Because they could not be distributed otherwise: selection Because their distribution reflects demographic history: random genetic drift and migration

29
How can we tell selection from drift/gene flow?
a. By neutrality tests (Tajima’s D, Fu’s Fs, etc.) However: D<0: Excess of rare alleles: Selection against deleterious alleles or population expansion D>0: Excess of intermediate-frequency alleles: Balancing selection or population bottleneck
 However: D<0: Excess of rare alleles: Selection against deleterious alleles or population expansion. D>0: Excess of intermediate-frequency alleles: Balancing selection or population bottleneck.")
30
How can we tell selection from drift/gene flow?
b. Gene flow, bottlenecks, founder effects, etc. affect all genes equally, whereas selection acts differently upon different genes Compare patterns of variation across some of the 30,000 human loci Difficult to infer migration from studies of single genes

31
Gene trees, population trees
Gene trees are unknown, but we can reconstruct some of their features assuming mutations occurred at a constant rate (=no selection)
")
32
Population-genetics theory describes
the expected features of gene trees in terms of population parameters T2=2N 4N T5=N/5 For nuclear genes, Exp time from k to (k-1) ancestors: Tk = 4N/[k(k-1)] generations (large std. errors)
 ancestors: Tk = 4N/[k(k-1)] generations (large std. errors)")
33
If two populations are isolated, the final
coalescence is 2N generations before the split past Exp (T) = 4N Exp(T2) = 2N Exp = T/2 T: gene divergence T2=2N Origin of the B population B A : population divergence present
 = 4N. Exp(T2) = 2N. Exp = T/2. T: gene. divergence. T2=2N. Origin of the B population. B. A. : population divergence. present.")
34
If there is initial polymorphism, the final coalescence
may be much more than 2N generations before the split past T>> T2=2N Origin of the B population B A present

35
Gene divergence predates population divergence: T is equal to only if 2 Ne =0
past E(T-) = 2 Ne generations T: gene divergence : population divergence present
 = 2 Ne. generations. T: gene divergence. : population. divergence. present.")
36
Only if there is a population bottleneck or a
founder effect does approximate T past Phylogeographic analyses require the assumption of strong founder effects 2Ne very small T present

37
Is it safe to assume that most human populations originated from a founder effect?
Evidence for rapid expansion ( Kyrs ago) in farming populations Evidence for shrinking in hunting-gathering populations, possible caused by competition with early farmers (Excoffier & Schneider 1999) Necessary to test for founder effects reduced genetic diversity at several loci in a population
 in farming populations. Evidence for shrinking in hunting-gathering populations, possible caused by competition with early farmers. (Excoffier & Schneider 1999) Necessary to test for founder effects reduced genetic diversity at several loci in a population.")
38
Simulation of two expanding populations:
No founder effect N0 = N0 = 400 Founder effect N0 = N0 = 4

39
Ages of molecules are not ages of populations
Initial polymorphism results in overestimation of the population’s age Population’s age Coalescence time From Krings et al. (1997)
")
40
Any conclusions? Robust inferences on past population processes are complicated No shortcuts: allele genealogies are not population genealogies Archaeologists need geneticists to tell demographic from cultural processes Geneticists need archeologists to identify good hypotheses to test

41
Sintesi 1 Il coalescente fornisce un modello di evoluzione basato sull’indipendenza fra processo genealogico e processo mutazionale Tramite il coalescente si possono stimare parametri sulla base di assunzioni esplicite e simulare geenalogie di geni

42
Sintesi 2 Vantaggi del coalescente: Rende esplicite le assunzioni;
fornisce misure di incertezza; non tratta (a differenza degli approcci filogeografici) i polimorfismi come mutazioni fissate.
 i polimorfismi come mutazioni fissate.")
43
Però: Se avessimo raccolto dati 10mila anni fa avremmo individuato un MRCA più antico Dati raccolti fra 10mila anni individueranno un MRCA più recente e quindi Il nostro MRCA può avere un valore speciale per noi, ma non ha alcun particolare significato evolutivo

44
Appendice: mismatch distribution in genealogie femminili e maschili

45
Maternal or paternal genealogies
past present Expanding population Stationary population

46
Nucleotide substitutions in the chromosomes of different individuals
Only a few are shared Many are shared

47
Distributions of pairwise sequence differences,
or mismatch distributions Unimodal Multimodal Peak ◄► age of expansion Many peaks Tajima’s D < Tajima D n.s. (= balancing selection) (= stabilizing selection)
 (= stabilizing selection)")
50
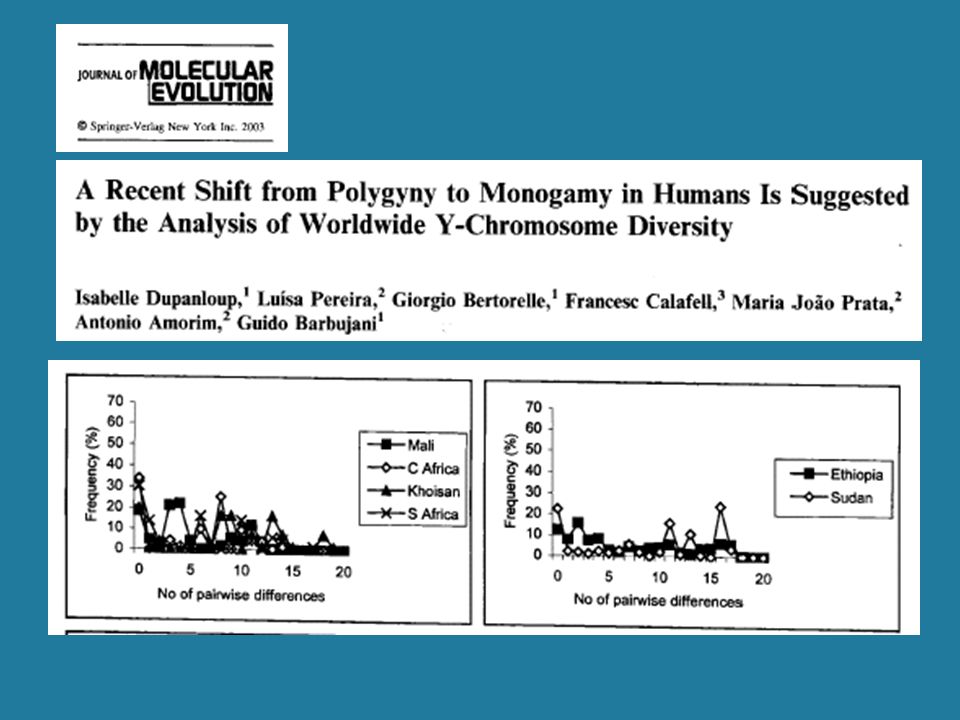
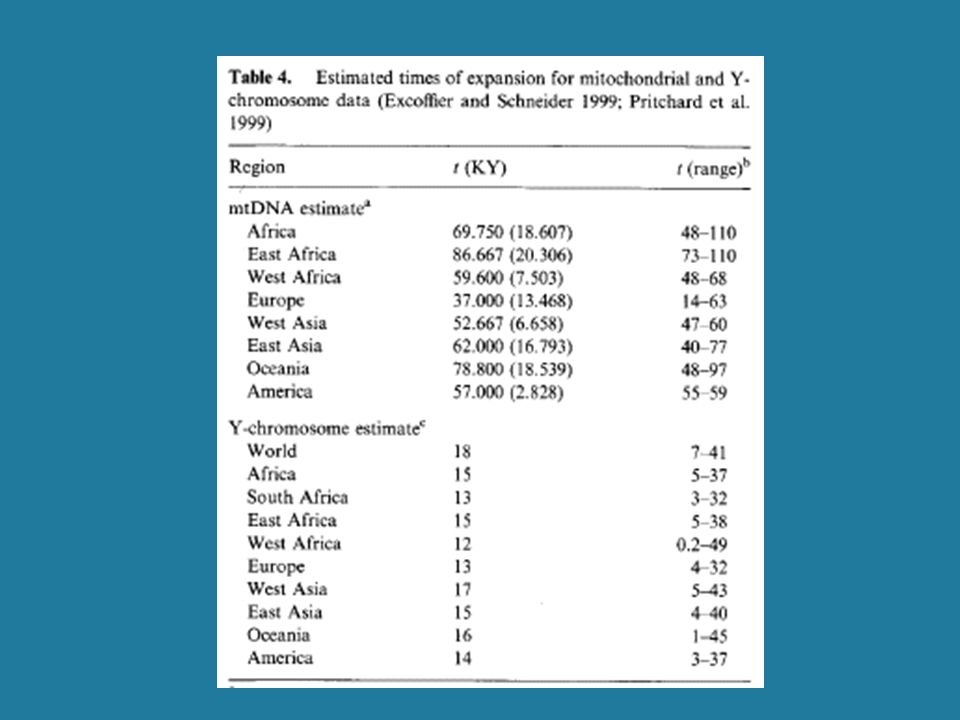
1. Rapid pop. growth inferred from mtDNA, 110-40 Kyrs BP
(Excoffier & Schneider 1999) 2. No evidence of growth in Y SNP mismatch distributions (Pereira et al. 2001; Dupanloup et al. 2003) Tajima’s D < 0 Tajima’s D = 0
 2. No evidence of growth in Y SNP mismatch distributions. (Pereira et al. 2001; Dupanloup et al. 2003) Tajima’s D < 0. Tajima’s D = 0.")
51
3. Evidence of growth for Y STRs, <20 Kyrs BP
(Pritchard et al. 1999) 4. Ascertainment bias may render SNPs insensitive to recent population growth (Dupanloup et al. 2003) 5. Patrilocality? (Seielstad et al. 1998) Long-term high Ne for females but not males: Extensive polygyny is a possibility
 4. Ascertainment bias may render SNPs insensitive to recent population growth. (Dupanloup et al. 2003) 5. Patrilocality (Seielstad et al. 1998) Long-term high Ne for females but not males: Extensive polygyny is a possibility.")
Presentazioni simili







>")







>")



