Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
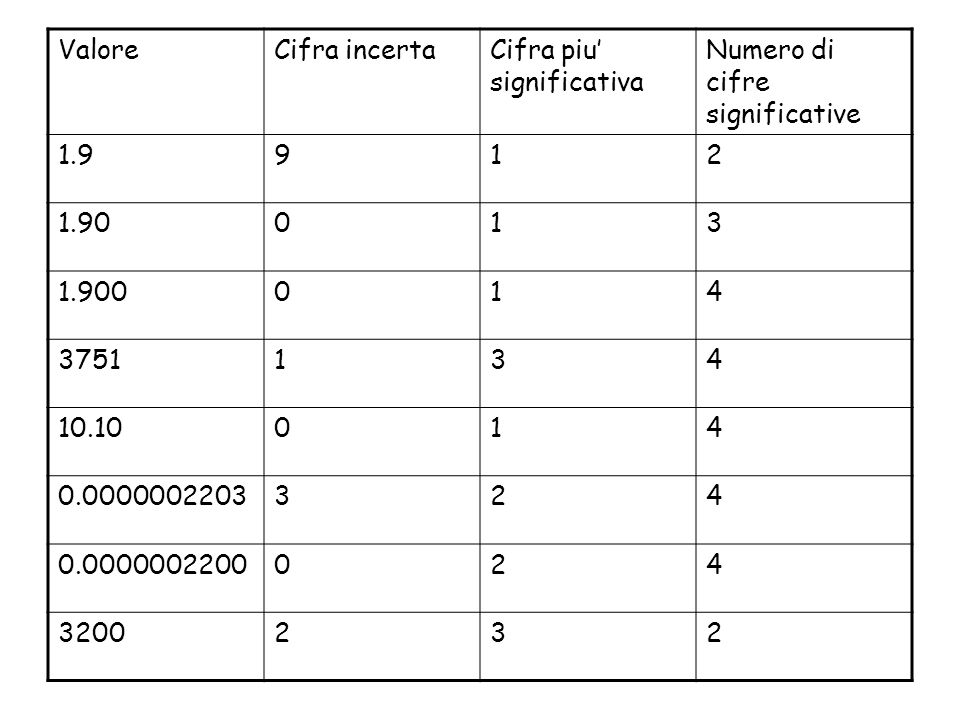
Cifre significative Misura Valore (s) 1 1.8 2 1.9 3 2.0 4 5 6 7
")
2
Valore Cifra incerta Cifra piu’ significativa Numero di cifre significative 1.9 9 1 2 1.90 3 1.900 4 3751 10.10 3200
3
1.900 più preciso di 1.900 che è più preciso di 1.90.
L’errore deve avere la stessa precisione della misura a cui si riferisce. 3200 ha 2 cifre significative ma se volessimo affermare che ne ha 4 allora scriveremmo x 103

4
Per convenzione gli errori si arrotondano ad 1 cifra significativa
ma in alcuni casi è opportuno usarne 2. Ad es. se dx = allora dx = 0.02 (1 cifra significativa) Ma se dx = allora dx = (2 cifre significative) poiché dx = 0.01 perde il 40% di informazione!!! Quando si fanno dei calcoli la regola è che la misura finale e l’errore siano dello stesso ordine di grandezza. Ad es. non è valido 92.81 ± 0.3 poichè l’incertezza è sui decimi diventa 92.8 ± 0.3 Se l’errore fosse 3 allora 93 ± 3 Se l’errore fosse 30 allora 90 ± 30
 Ma se dx = allora dx = (2 cifre significative) poiché. dx = 0.01 perde il 40% di informazione!!! Quando si fanno dei calcoli la regola è che la misura finale e l’errore siano dello stesso ordine di grandezza. Ad es. non è valido ± 0.3 poichè l’incertezza è sui decimi diventa 92.8 ± 0.3. Se l’errore fosse 3 allora 93 ± 3. Se l’errore fosse 30 allora 90 ± 30.")
10
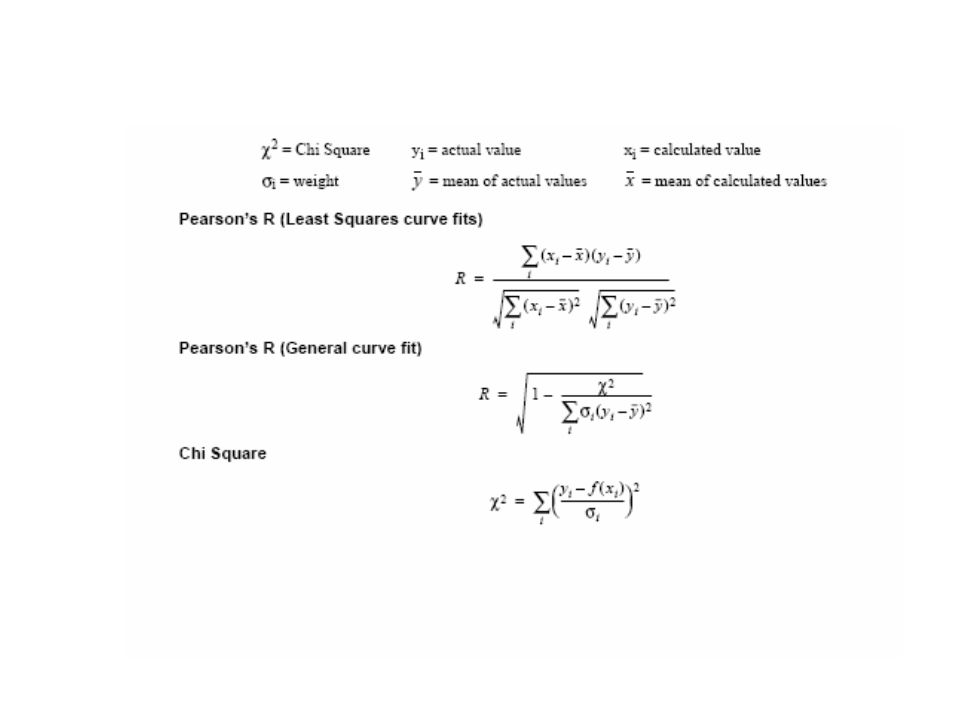
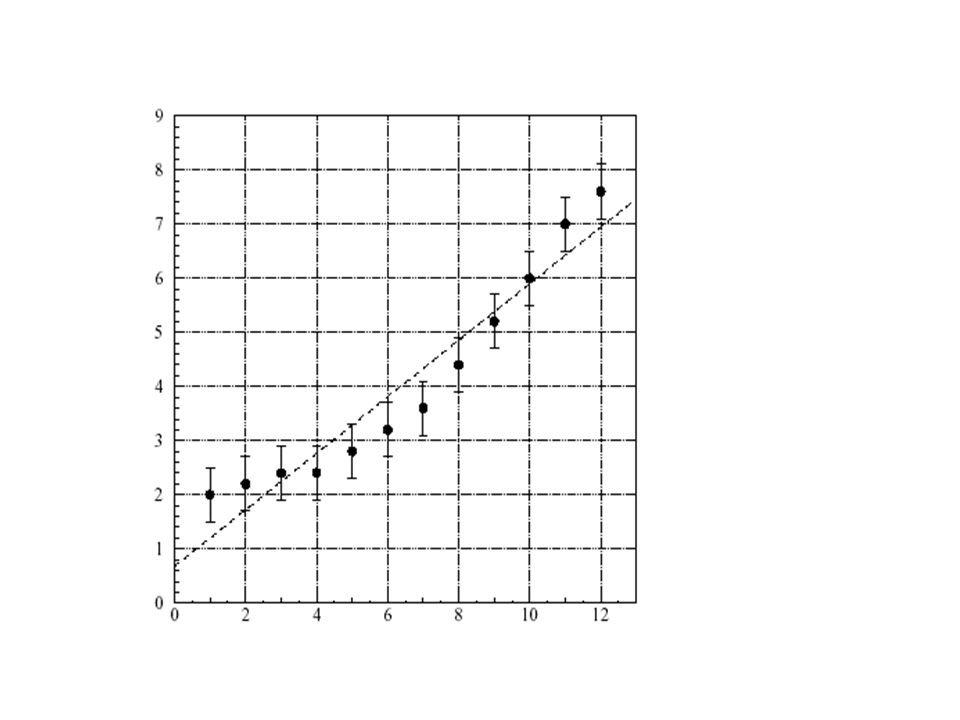
Calcolo coefficienti A e B di una retta del tipo
y=A+Bx con il metodo dei minimi quadrati

11
; Linear fit c10=c0^2; X^2 c11=c0*c1; X*Y c2=npts(c0)*csum(c10)-(csum(c0))^2; Denominatore per A e B c3=(csum(c10)*csum(c1)-csum(c0)*csum(c11))/c2; Calcolo di A c4=(npts(c0)*csum(c11)-csum(c0)*csum(c1))/c2; Calcolo di B c5=csum(c0)/npts(c0); media dei valori X c6=csum(c1)/npts(c1); media dei valori Y c12=c0-c5; X-X(medio) c13=c1-c6; Y-Y(medio) c14=c12*c13; [X-X(medio)]*[Y-Y(medio)] c15=(c12)^2; [X-X(medio)]^2 c16=(c13)^2; [Y-Y(medio)]^2 c7=csum(c14); Covarianza c8=sqrt(csum(c15)*csum(c16)); Prodotto deviazioni standard c9=c7/c8; r
*csum(c1)-csum(c0)*csum(c11))/c2; Calcolo di A. c4=(npts(c0)*csum(c11)-csum(c0)*csum(c1))/c2; Calcolo di B. c5=csum(c0)/npts(c0); media dei valori X. c6=csum(c1)/npts(c1); media dei valori Y. c12=c0-c5; X-X(medio) c13=c1-c6; Y-Y(medio) c14=c12*c13; [X-X(medio)]*[Y-Y(medio)] c15=(c12)^2; [X-X(medio)]^2. c16=(c13)^2; [Y-Y(medio)]^2. c7=csum(c14); Covarianza. c8=sqrt(csum(c15)*csum(c16)); Prodotto deviazioni standard. c9=c7/c8; r.")
13
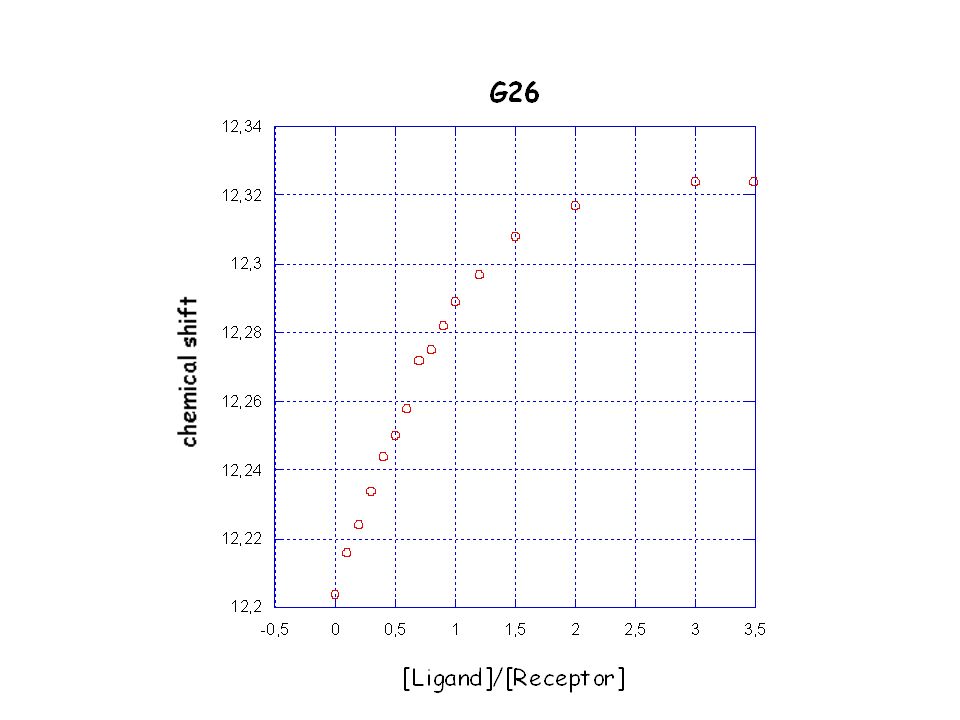
In molte titolazioni eseguite tramite metodi spettroscopici 2 composti interagiscono e si osserva la variazione di un parametro secondo un’equazione del tipo do=dbcb + dfcf dove do= variazione del segnale che si osserva durante la titolazione db= variazione del segnale che si osserva alla fine della titolazione do= variazione del segnale che si osserva all’inizio della titolazione Assumendo un’equilibrio del tipo R + L ↔ RL dove R potrebbe essere un recettore ed L un ligando. Quindi cb = frazione molare della specie legata (R o L) cf = frazione molare della specie libera (R o L) Provare ad ottenere una serie di dati con KD=0.01; cf =7; cb =10 R va da a 0.01 in step di L va da a 0.10 in step di 0.005 ed eventualmente risolvere il problema del fit
 cf = frazione molare della specie libera (R o L) Provare ad ottenere una serie di dati con. KD=0.01; cf =7; cb =10. R va da a 0.01 in step di L va da a 0.10 in step di ed eventualmente risolvere il problema del fit.")
18
3) Tramite minimi quadrati trova intercetta e pendenza della retta
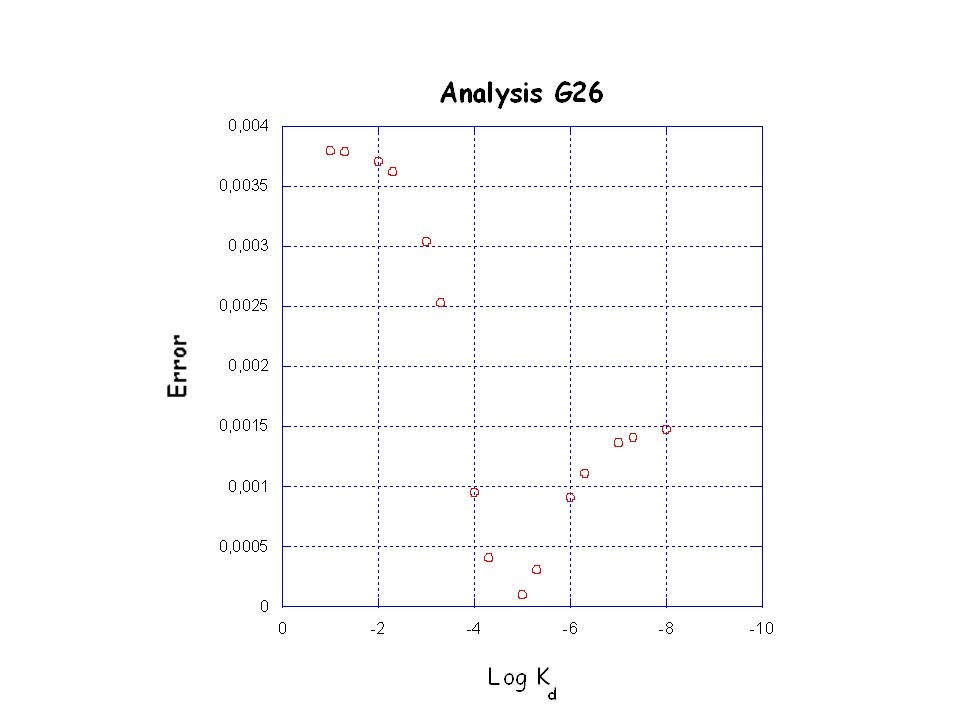
Inserisci KD 2) Calcola cb 3) Tramite minimi quadrati trova intercetta e pendenza della retta 4) Con i valori di intercetta e pendenza calcola dc 5) Calcola la somma quadratica degli errori tra dc e do e tieni in memoria il valore (Error) Torna al punto 1) Il valore minore di Error corrisponde alla miglior KD
 Calcola cb. 3) Tramite minimi quadrati trova intercetta e pendenza della retta. 4) Con i valori di intercetta e pendenza calcola dc. 5) Calcola la somma quadratica degli errori tra dc e do e tieni in memoria il valore (Error) Torna al punto 1) Il valore minore di Error corrisponde alla miglior KD.")
19
; c0= observed; c1=Receptor; c2= Ligand
;Kd=cell(0,5) c10=((cell(0,5)+c1+c2)-sqrt((cell(0,5)+c1+c2)^2-4*c1*c2))/(2*c1); bound fraction ; Linear fit c11=c10^2; X^2 c12=c10*c0; X*Y c13=npts(c10)*csum(c11)-(csum(c10))^2; Denominatore per A e B c14=(csum(c11)*csum(c0)-csum(c10)*csum(c12))/c13; Calcolo di A c15=(npts(c10)*csum(c12)-csum(c10)*csum(c0))/c13; Calcolo di B c16=c10*c15+c14; c17=(c16-c0)^2; c18=csum(c17); ;Kd=cell(1,5) ……..
 c10=((cell(0,5)+c1+c2)-sqrt((cell(0,5)+c1+c2)^2-4*c1*c2))/(2*c1); bound fraction. ; Linear fit. c11=c10^2; X^2. c12=c10*c0; X*Y. c13=npts(c10)*csum(c11)-(csum(c10))^2; Denominatore per A e B. c14=(csum(c11)*csum(c0)-csum(c10)*csum(c12))/c13; Calcolo di A. c15=(npts(c10)*csum(c12)-csum(c10)*csum(c0))/c13; Calcolo di B. c16=c10*c15+c14; c17=(c16-c0)^2; c18=csum(c17); ;Kd=cell(1,5) ……..")
20
;grafico errore cell(0,6)=csum(c17); cell(1,6)=csum(c27); cell(2,6)=csum(c37); cell(3,6)=csum(c47); cell(4,6)=csum(c57); cell(5,6)=csum(c67); cell(6,6)=csum(c77); cell(7,6)=csum(c87); cell(8,6)=csum(c97); cell(9,6)=csum(c107); cell(10,6)=csum(c117); cell(11,6)=csum(c127); cell(12,6)=csum(c137); cell(13,6)=csum(c147); cell(14,6)=csum(c157);
=csum(c57); cell(5,6)=csum(c67); cell(6,6)=csum(c77); cell(7,6)=csum(c87); cell(8,6)=csum(c97); cell(9,6)=csum(c107); cell(10,6)=csum(c117); cell(11,6)=csum(c127); cell(12,6)=csum(c137); cell(13,6)=csum(c147); cell(14,6)=csum(c157);")
21
cell(0,7)=log(cell(0,5)); cell(1,7)=log(cell(1,5)); cell(2,7)=log(cell(2,5)); cell(3,7)=log(cell(3,5)); cell(4,7)=log(cell(4,5)); cell(5,7)=log(cell(5,5)); cell(6,7)=log(cell(6,5)); cell(7,7)=log(cell(7,5)); cell(8,7)=log(cell(8,5)); cell(9,7)=log(cell(9,5)); cell(10,7)=log(cell(10,5)); cell(11,7)=log(cell(11,5)); cell(12,7)=log(cell(12,5)); cell(13,7)=log(cell(13,5)); cell(14,7)=log(cell(14,5));
=log(cell(4,5)); cell(5,7)=log(cell(5,5)); cell(6,7)=log(cell(6,5)); cell(7,7)=log(cell(7,5)); cell(8,7)=log(cell(8,5)); cell(9,7)=log(cell(9,5)); cell(10,7)=log(cell(10,5)); cell(11,7)=log(cell(11,5)); cell(12,7)=log(cell(12,5)); cell(13,7)=log(cell(13,5)); cell(14,7)=log(cell(14,5));")
22
10bp DNA titrated with C-HNS
2.0 1.4 1.2 1.0 C-HNS/DNA 0.8 Kd = 3·10-6 0.6 0.4 0.2 0.1 0.0

27
KD = 1.6 ∙ 10-4

37
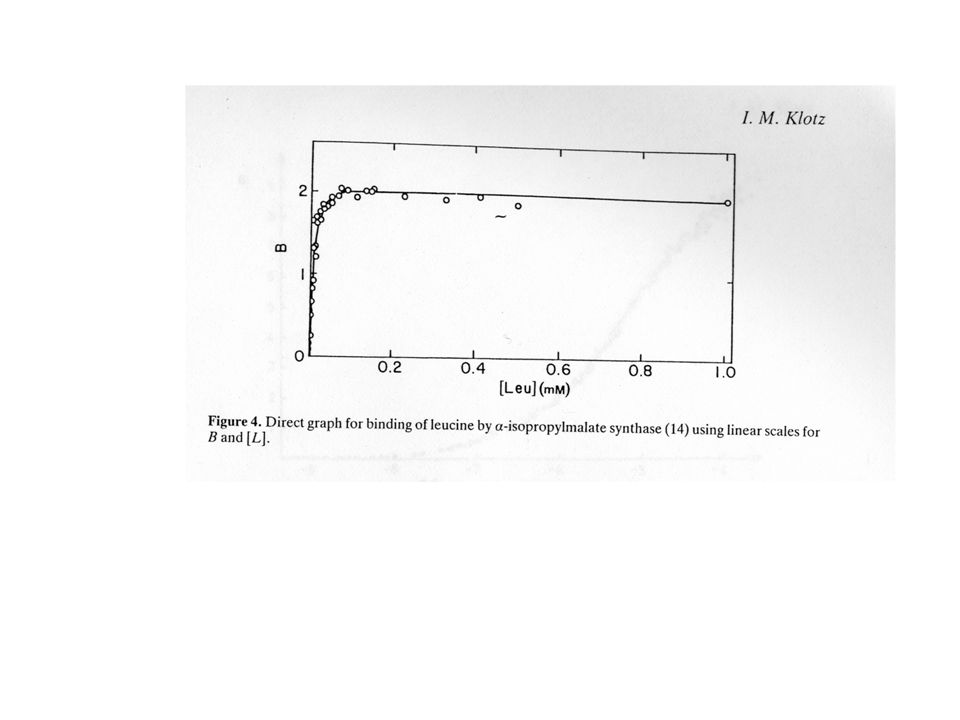
Come rappresentare i dati ?
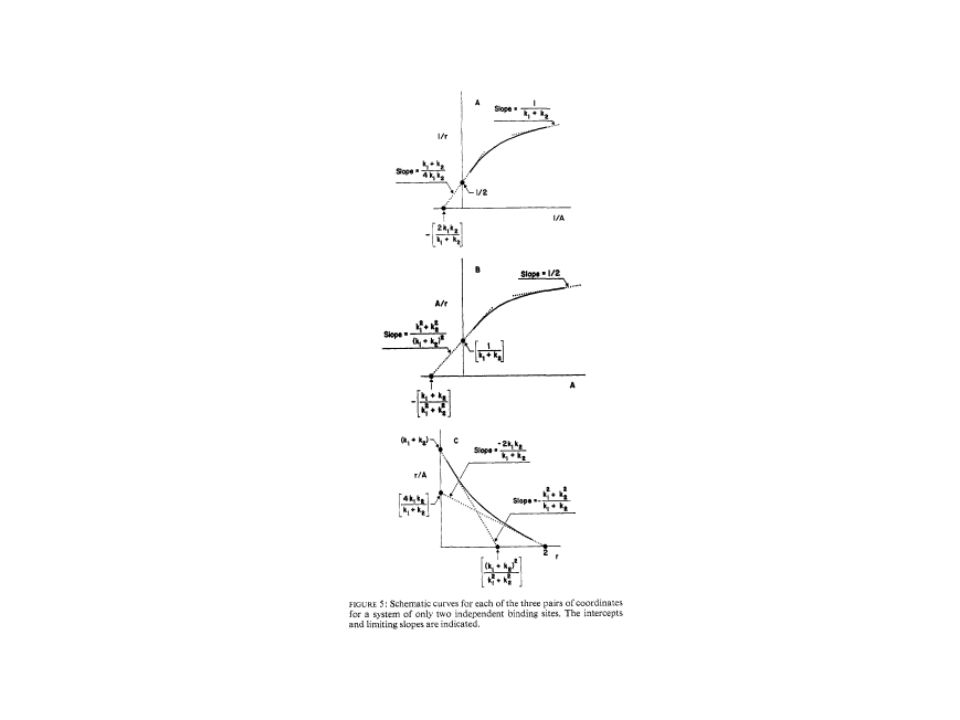
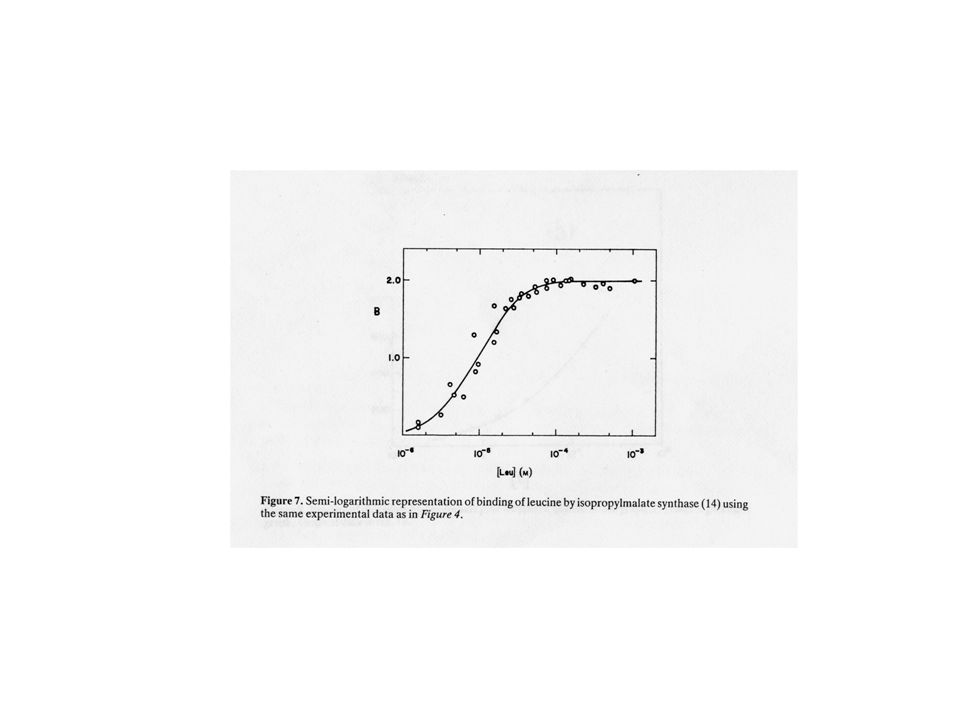
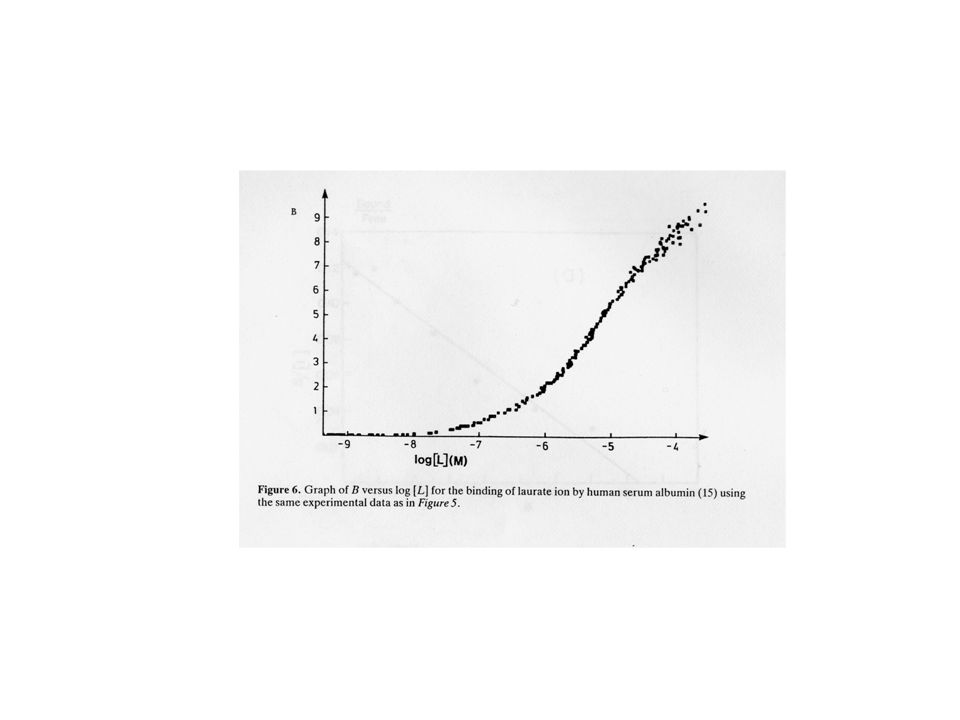
Scala diretta r vs. L Ma i punti possono essere poi troppo ravvicinati e non permette di capire quando si è giunti a saturazione 2) Scala semi-logaritmica Permette di capire quando si sia effettivamente giunti a saturazione. Anche se non permette un’analisi quantitativa dei dati è molto utile per capire se il nostro esperimento è giunto a conclusione 3) Altre forme di grafico, ad es. Scatchard plot. Possono essere causa di errori se non utilizzate opportunamente.
 Scala semi-logaritmica. Permette di capire quando si sia effettivamente giunti a saturazione. Anche se non permette un’analisi quantitativa dei dati è molto utile per capire se il nostro esperimento è giunto a conclusione. 3) Altre forme di grafico, ad es. Scatchard plot. Possono essere causa di errori se non utilizzate opportunamente.")
42
Scatchard plot L’intercetta sull’asse X rqppresenta il numero di siti di legame nel caso di n siti identici e indipendenti.

43
Scatchard plot L’intercetta sull’asse X rqppresenta il numero di siti di legame nel caso di n siti identici e indipendenti. Estrapolare l’intercetta sull’asse delle ascisse può dare risultati controversi. Inoltre la concavità può esser dovuta: Siti con diversa affinità e non interagenti tra di loro 2) Siti diversi la cui affinità cambia durante il binding (cooperatività)
 Siti diversi la cui affinità cambia. durante il binding (cooperatività)")
44
Scatchard plot L’intercetta sull’asse X rqppresenta il numero di siti di legame nel caso di n siti identici e indipendenti. Estrapolare l’intercetta sull’asse delle ascisse può dare risultati controversi. La concavità è stata erroneamente attribuita a 2 specie con diversa affinità e le costanti di equilibrio stimate in modo errato.

49
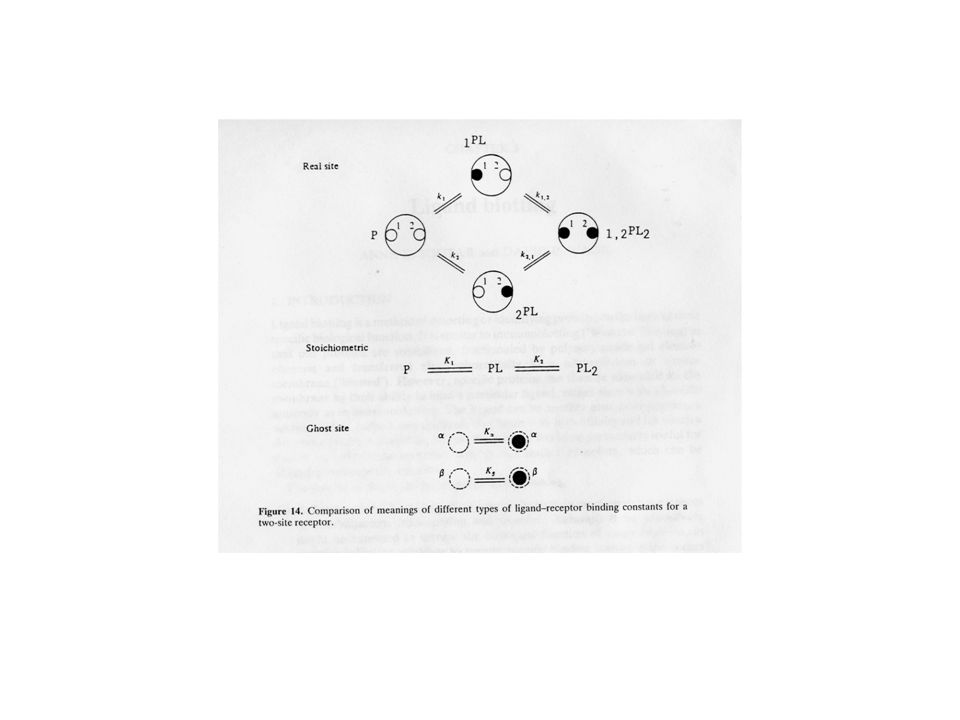
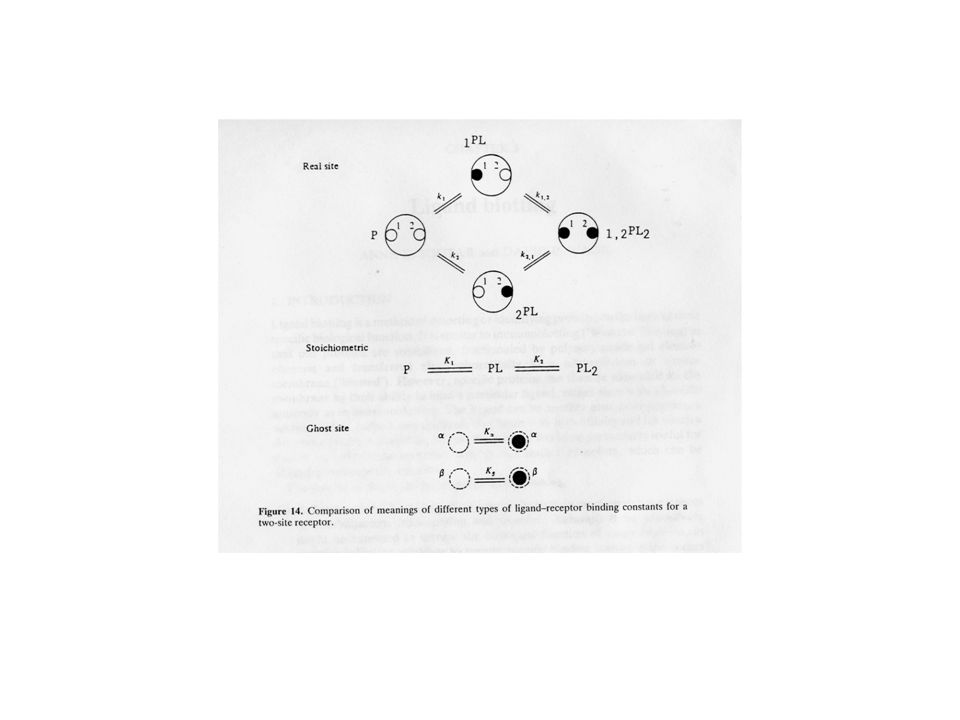
Numero di siti di legame
Numero totale di costanti sito specifiche, k1 Numero di costanti sito specifiche indipendenti Numero di costanti di legame stechiometriche, Ki Numero di costanti di legame fantasma, Kw 2 4 3 12 7 32 15 6 192 63 8 1024 255 24576 4095

51
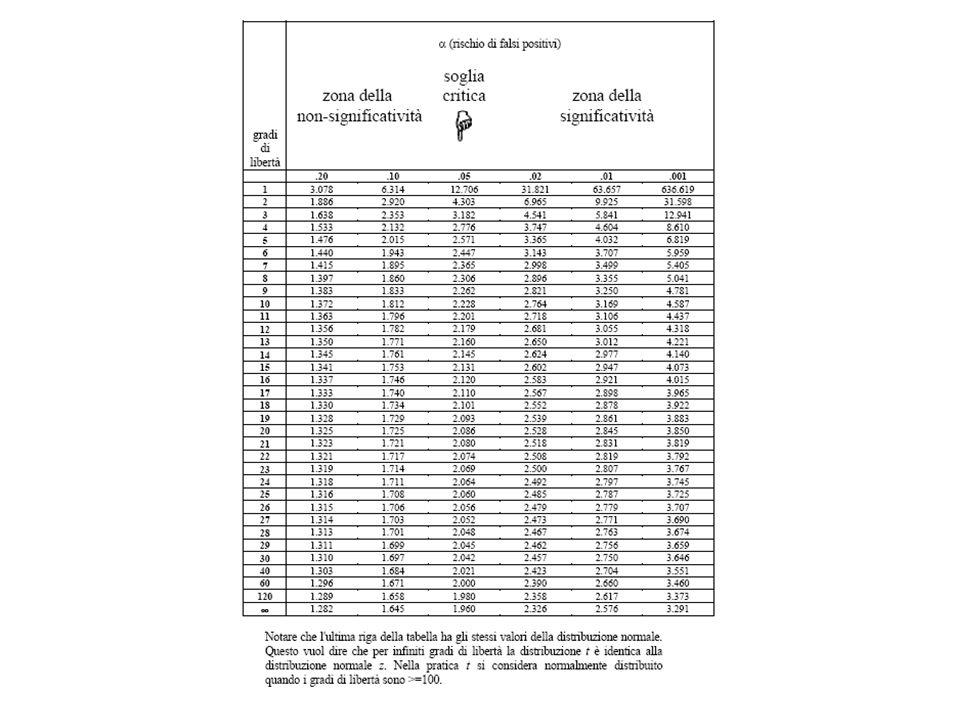
t-test di Student

52
2 campioni con lo stesso numero di elementi n1 = n2 Quindi va calcolata la differenza tra i due valori medi in rapporto alle larghezze di riga, ossia in rapporto alle deviazioni standard dalla media

56
Partecipante Controllo 35 22 31 25 29 23 28 39 30 41 37 33 38 n n x x

58
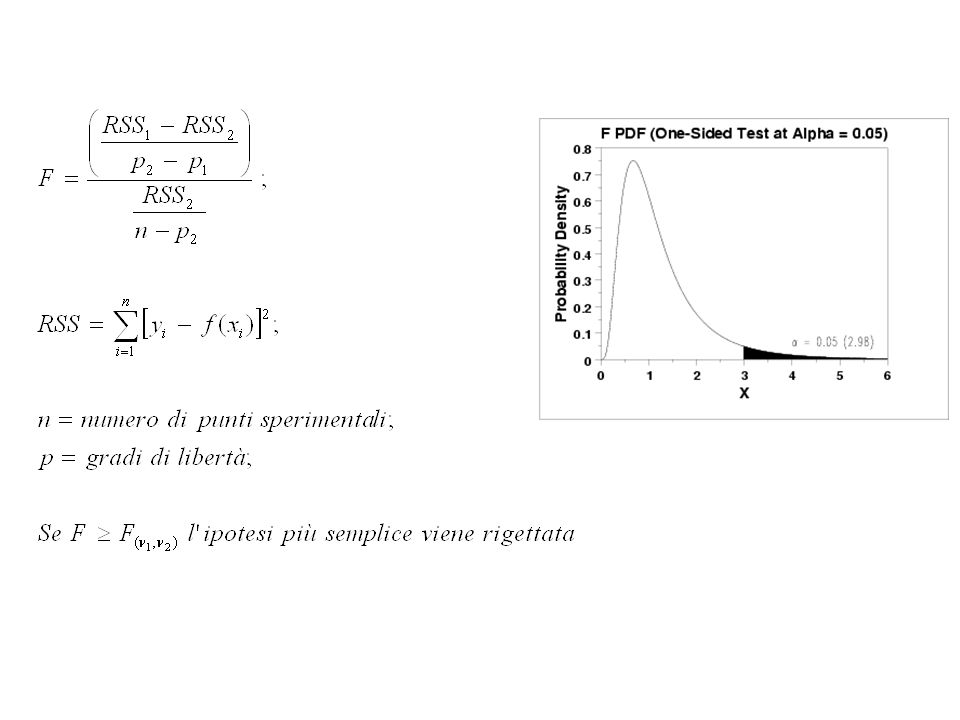
F test Abbiamo una serie di dati e vogliamo analizzarli con un’equazione. Y= b0 + b1x1 + b2x2 + b3x1x2 (forma ridotta) Scopriamo che un’equazione più complessa risulta in un fitting migliore Y= b0 + b1x1 + b2x2 + b3x1x2 + b4x12 + b5x22 (forma completa) Il fitting migliore è dovuto ad un’equazione che realmente fitta meglio i dati o semplicemente all’aggiunta di altri parametri?
 Il fitting migliore è dovuto ad un’equazione che realmente fitta meglio i dati o semplicemente all’aggiunta di altri parametri")
59
Se il modello più semplice è corretto l’aumento relativo della somma dei
quadrati è dello stesso ordine dell’aumento relativo dei gradi di libertà. (RSS1-RSS2)/RSS2 ~ (p1-p2)/p2 Se il modello più complicato è corretto l’aumento relativo della somma dei quadrati è maggiore dell’aumento relativo dei gradi di libertà. (RSS1-RSS2)/RSS2 > (p1-p2)/p2 1 si riferisce al modello più semplice, 2 a quello più complicato, p sono i gradi di libertà ed RSS la somma delle differenze dei quadrati. Possiamo dare una valutazione quantitativa? Qual’ è la probabilità che un modello più complesso spieghi meglio i dati perché si adatta meglio e non perché contiene semplicemente più variabili?
/RSS2 ~ (p1-p2)/p2. Se il modello più complicato è corretto l’aumento relativo della somma dei. quadrati è maggiore dell’aumento relativo dei gradi di libertà. (RSS1-RSS2)/RSS2 > (p1-p2)/p2. 1 si riferisce al modello più semplice, 2 a quello più complicato, p sono i gradi di libertà ed RSS la somma delle differenze dei quadrati. Possiamo dare una valutazione quantitativa Qual’ è la probabilità che un modello più complesso spieghi meglio i dati perché si adatta meglio e non perché contiene semplicemente più variabili")
61
Upper critical values of the F Distribution for n1 numerator
Upper critical values of the F Distribution for n1 numerator degrees of freedom and n2 denominator degrees of freedom 5% significance level F.05(n1,n2)
")
62
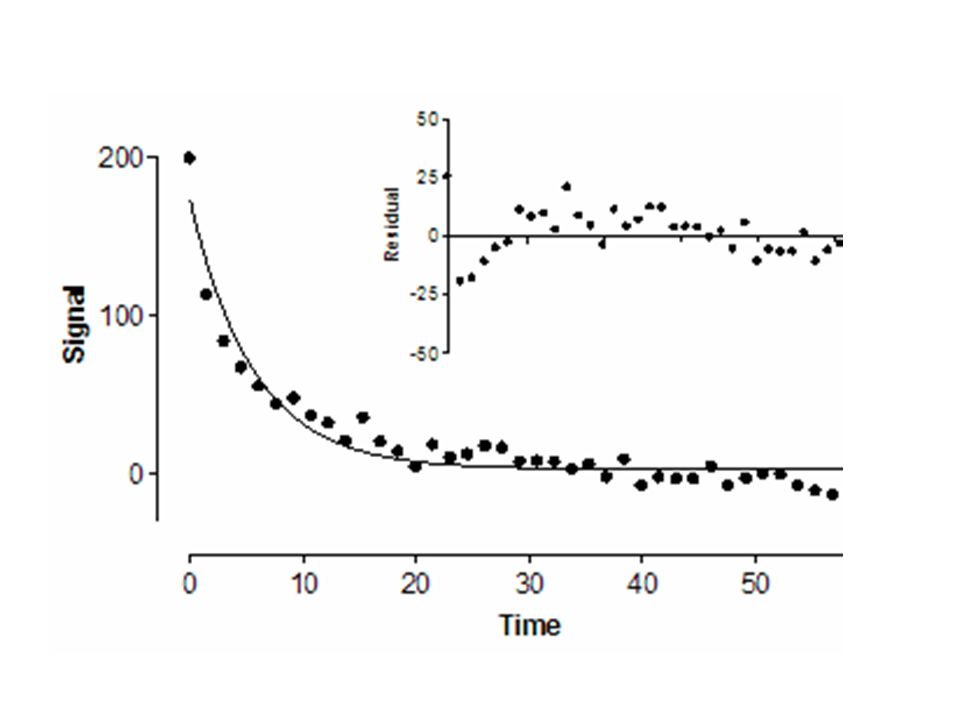
Esempio: distinguere tra una singola esponenziale ed una somma contenente
2 o 3 esponenziali per il fitting dei dati. Model No. parameters S F(2,49) exponential F(2,49) table 1 2 3 4 6 1843 69.01 61.95 2.79 @80% CL= 2.42 @90% CL= 3.19 n = 55
 exponential. F(2,49) table CL= CL= n = 55.")
66
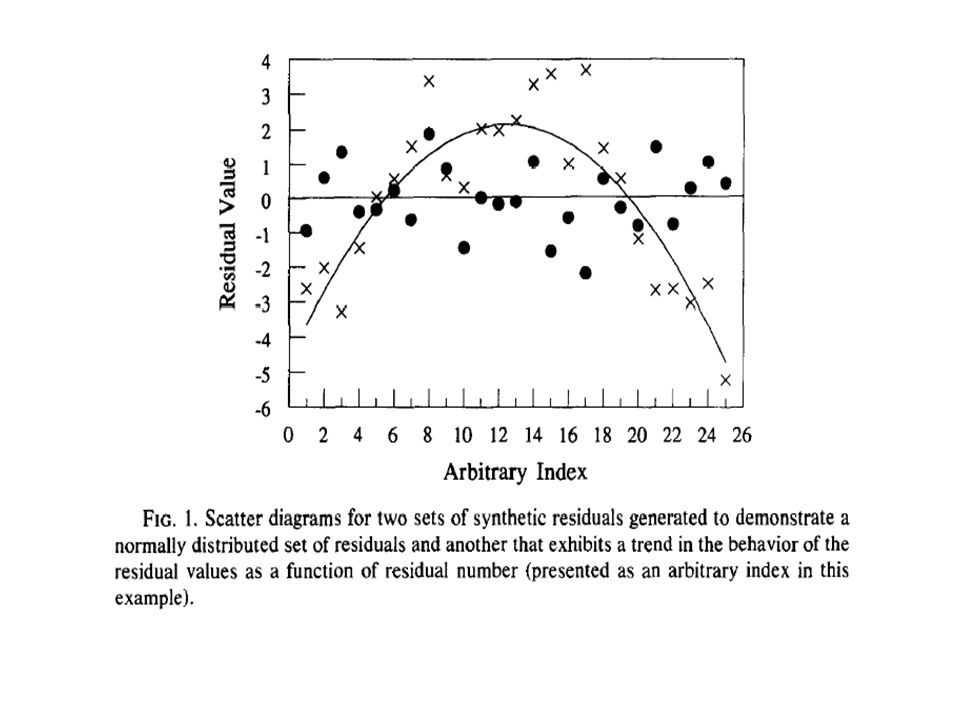
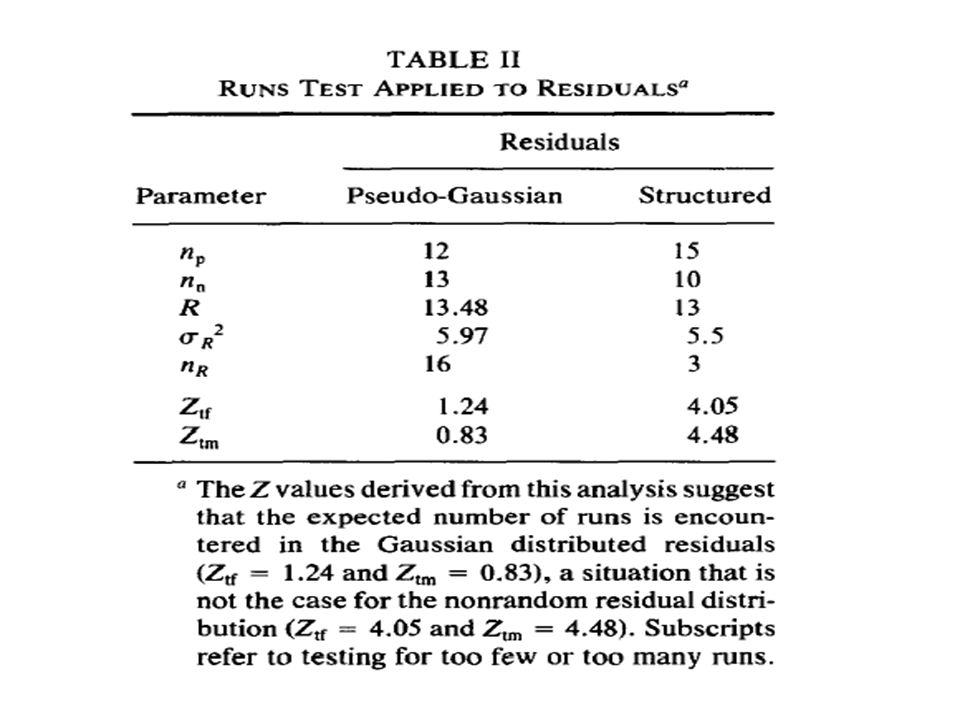
Run test np = numero di residuals positivi
nn = numero di residuals negativi R = numero di “runs” attesi sR2 = varianza di R nR = numero di “runs” osservati

Presentazioni simili