Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
AA 2011/2012 Lezione 3 Adriana Maggi
DOCENTE DI BIOTECNOLOGIE FARMACOLOGICHE CORSO DI LAUREA SPECIALISTICA IN BIOTECNOLOGIE DEL FARMACO AA 2011/2012 Lezione 3

2
e la ricerca di nuovi bersagli farmacologci
La GENOMATICA e la ricerca di nuovi bersagli farmacologci

3
GENOMATICA: studio del genoma* degli esseri viventi attraverso la mappatura o sequenziamento dei geni e lo studio della loro funzione * Per genoma si intende l’intero contenuto in DNA di una cellula, geni e sequenze intrageniche incluse

4
genoma umano Il genoma nucleare umano è costituito da di paia di basi diviso in 24 sequenze lineari : i cromosomi di cui 22 sono autosomi e 2 sono i cromosomi sessuali Il DNA mitocondriale è circolare e ha le dimensioni di pb

5
Come si costruiscono le mappe geniche?
Che significato ha localizzare fisicamente i geni nei diversi cromosomi? Come si costruiscono le mappe geniche? Storicamente attraverso la costruzione di mappe fisiche (identificare e ordinare marcatori lungo il cromosoma) Attualmente con il sequenziamento
 Attualmente con il sequenziamento.")
6
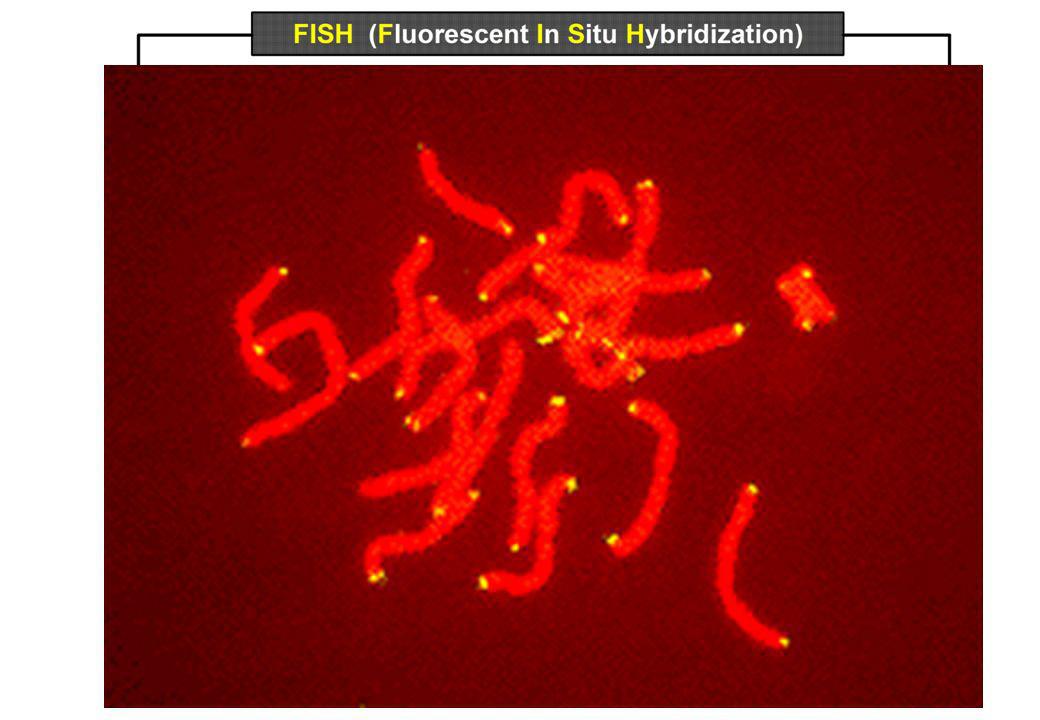
Costruzione di mappe fisiche
FISH (Fluorescent in situ hybridization) mapping studi genetici di ‘linkage’ restriction mapping di banche di DNA use of sequence tagget site (STS)
 mapping. studi genetici di ‘linkage’ restriction mapping di banche di DNA. use of sequence tagget site (STS)")
7
FISH (Fluorescent in situ hybridization) mapping
 mapping")
9
FISH per studiare FISH per localizzare Omologie di sequenza
Moltiplicazione di geni Evoluzione del DNA FISH per localizzare Delezioni Traslocazioni Inserzioni

10
restriction mapping

11
RESTRICTION MAPPING Frammentazione del DNA genomico con enzimi di restrizione Separazione dei frammenti per elettroforesi su agarosio Immobilizzazione DNA per trasferimento su membrana Ibridazione con sonda opportunamente marcata Identificazione di RLFP

12
RESTRICTION MAPPING 6E 4E 5E 3B 5B 7B B E 3 1 5 3B1E5E1B5 = 5B1E5E1B3
Gel Data Uncut: 15 kb EcoR1: 4, 5, 6 kb BamH1: 3, 5, 7 kb EcoR1 & BamH1: 1, 3, 5 kb

13
RESTRICTION MAPPING

14
restriction mapping sequence tagget site

15
A sequence-tagged site (or STS) is a short (200 to 500 base pair) DNA sequence that has a single occurrence in the genome and whose location and base sequence are known. STSs can be easily detected by the polymerase chain reaction (PCR) using specific primers. For this reason they are useful for constructing genetic and physical maps from sequence data reported from many different laboratories. They serve as landmarks on the developing physical map of a genome. When STS loci contain genetic polymorphisms (e.g. simple sequence length polymorphisms, SSLPs, single nucleotide polymorphisms), they become valuable genetic markers, i.e. loci which can be used to distinguish individuals. They are used in shotgun sequencing, specifically to aid sequence assembly.
 using specific primers. For this reason they are useful for constructing genetic and physical maps from sequence data reported from many different laboratories. They serve as landmarks on the developing physical map of a genome. When STS loci contain genetic polymorphisms (e.g. simple sequence length polymorphisms, SSLPs, single nucleotide polymorphisms), they become valuable genetic markers, i.e. loci which can be used to distinguish individuals. They are used in shotgun sequencing, specifically to aid sequence assembly.")
16
studi genetici di ‘linkage’

17
IL MAPPAGGIO GENETICO Analisi di linkage

18
SU COSA SI BASA IL LINKAGE?
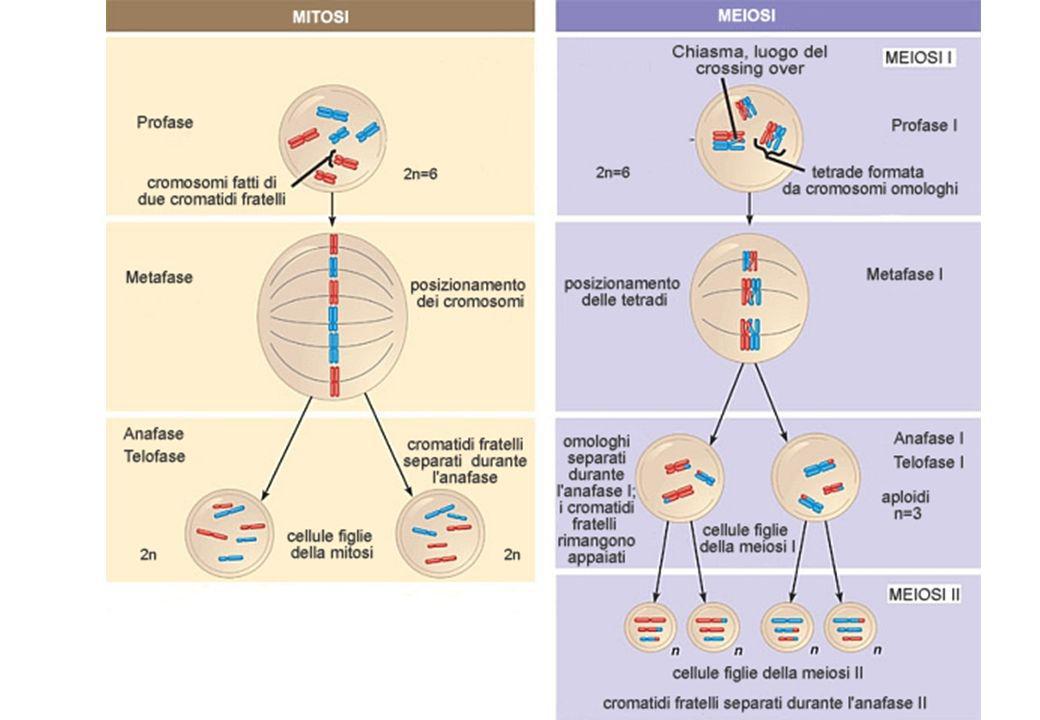
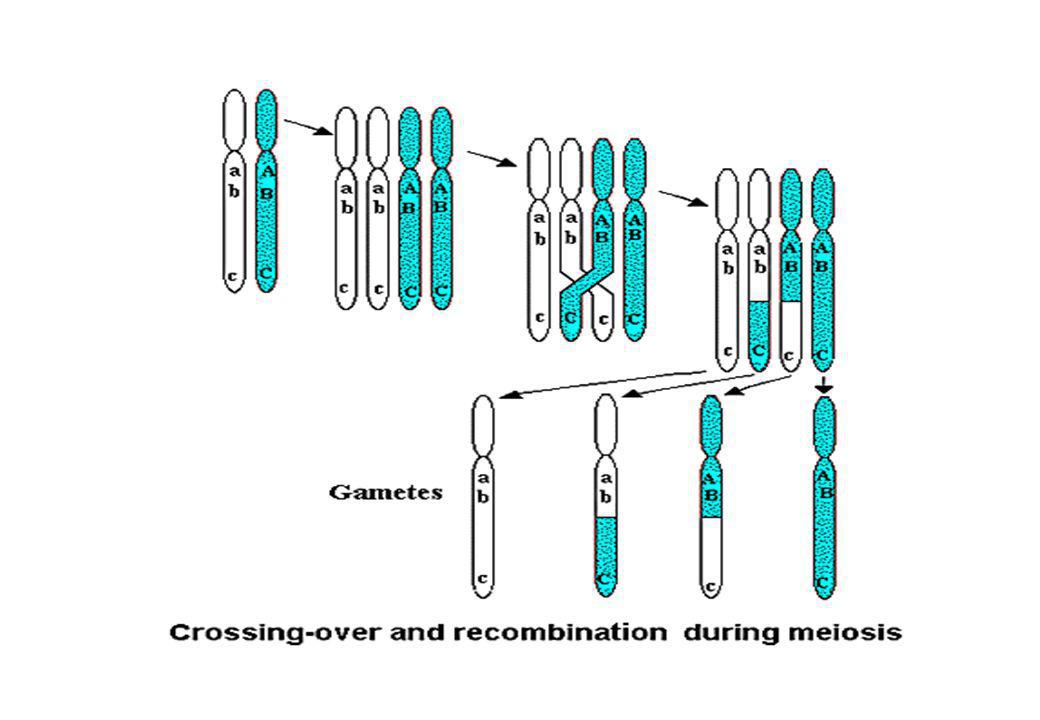
Due geni che mappano sullo stesso cromosoma si dicono SINTENICI Due geni sintenici segregherebbero sempre assieme se non esistesse il crossing-over nella prima divisione meiotica l’evento di crossing-over da luogo alla formazione di gameti RICOMBINANTI SINTENICI

19
LA CONCATENAZIONE o LINKAGE
Consente di mappare un gene sulla base dello studio della sua vicinanza ad un altro locus sullo stesso cromosoma.

22
LA MEIOSI ED I GAMETI RICOMBINANTI
Il crossing-over avviene durante la meiosi L’evento di crossing-over porta alla formazione di gameti ricombinanti Se due loci non sono associati avremo il 50% di gameti non ricombinanti ed il 50% di gameti ricombinanti per questi due loci

23
IN GENERALE Il crossing-over separerà raramente loci che si trovano molto vicini sullo stesso cromosoma, in quanto un solo evento di crossing-over localizzato esattamente nel piccolo spazio tra i due loci creera’ dei ricombinanti Più due loci sono distanti, più è probabile che un evento di crossing-over li separi Si definisce un valore detto frazione di ricombinazione, misura della distanza di due loci

24
LA DISTANZA GENETICA Il centimorgan(cM) e’ l’unita’ di misura della distanza genetica di due loci DUE LOCI CHE PRESENTANO 1% DI RICOMBINAZIONE SONO DEFINITI DISTANTI 1 cM

25
Conoscendo la frazione di ricombinazione
Sapendo che due loci distanti 1 cM avranno una frazione di ricombinazione uguale a 0,01 Possiamo ricavare la distanza genetica fra due loci Ricordando che LA DISTANZA GENETICA NON E’ UGUALE ALLA DISTANZA FISICA

26
Doppio crossing over

27
Dopo una certa distanza fisica la frazione di ricombinazione non rispecchia più la distanza genetica per l’esistenza di doppi crossing-over Loci che distano su una mappa 40 cM hanno una ricombinazione molto inferiore al 40%, in quanto la frazione di ricombinazione non supera mai lo 0,5 La frazione di ricombinazione sara’ uguale a 0,5 non solo per loci non sintenici, ma anche per loci sintenici molto distanti fra loro

28
LE FUNZIONI DI MAPPA La funzione di mappa definisce la relazione tra funzione di ricombinazione e distanza genetica Esistono diverse funzioni di mappa, che tengono conto di diverse variabili La più semplice funzione di mappa è la funzione di Haldane ω= -1/2 ln (1-2θ) θ= 1/2[1-exp(-2ω)] dove ω e’la distanza di mappa e θ è la frazione di ricombinazione
 θ= 1/2[1-exp(-2ω)] dove ω e’la distanza di mappa e. θ è la frazione di ricombinazione.")
29
IL MAPPAGGIO GENETICO NELL’UOMO
Associare il gene ad un cromosoma e conoscere la sua posizione Solitamente vengono studiati geni che, se mutati, sono responsabili di un fenotipo patologico L’analisi di concatenazione nell’uomo si basa sullo studio degli alberi genealogici e sulla ricerca delle meiosi informative Una meiosi è informativa quando si può identificare se il gamete è o meno ricombinante

30
IL MAPPAGGIO GENETICO NELL’UOMO
Per mappare i geni nell’uomo vengono usati dei marcatori il MARCATORE è un carattere mendeliano sufficientemente polimorfico da offrire una ragionevole probabilità che una persona scelta a caso sia eterozigote. Per mappare il gene è necessario conoscere la posizione del marcatore. Vengono costruite per questo delle mappe genetiche dei marcatori usando un mappaggio marcatore-marcatore

31
QUALI CARATTERI SONO USATI COME MARCATORE?
Qualsiasi carattere mendeliano e polimorfico può essere usato come marcatore E’ meglio che il carattere possa essere individuato facilmente e a basso costo Per rendere più facile il mappaggio è necessario che i marcatori siano tanti e quanto piu’ possibile vicini fra loro (progetto genoma)
")
32
BREVE STORIA DEI MARCATORI
Gruppi Sanguigni e Varianti della mobilita’ elettroforetica delle proteine del siero 1970-Tipi Tissutali HLA 1975-RFLP del DNA 1985-Minisatelliti Oggi Microsatelliti

33
ACTCACTCACTCACTC o (ACTC)4
Si definiscono microsatelliti (o short tandem repeats o STR) sequenze ripetute di DNA non codificante costituiti da unità di ripetizione molto corte (1-5 bp) disposte secondo una ripetizione in tandem, utilizzabili come marcatori molecolari di loci. La loro presenza nel genoma umano non influisce per più del 3%, ma si pensa che comunque essi svolgano una funzione essenziale per la struttura dei cromosomi. II microsatelliti sono ereditati in modo mendeliano Esempi di microsatelliti: AAAAAAAAAAA o (A)11 GTGTGTGTGTGT o (GT)6 CTGCTGCTGCTG o (CTG)4 ACTCACTCACTCACTC o (ACTC)4
 sequenze ripetute di DNA non codificante costituiti da unità di ripetizione molto corte (1-5 bp) disposte secondo una ripetizione in tandem, utilizzabili come marcatori molecolari di loci. La loro presenza nel genoma umano non influisce per più del 3%, ma si pensa che comunque essi svolgano una funzione essenziale per la struttura dei cromosomi. II microsatelliti sono ereditati in modo mendeliano. Esempi di microsatelliti: AAAAAAAAAAA o (A)11. GTGTGTGTGTGT o (GT)6. CTGCTGCTGCTG o (CTG)4. ACTCACTCACTCACTC o (ACTC)4.")
34
MAPPATURA DI UN GENE-MALATTIA
Ricostruzione dell’albero genealogico delle famiglie da analizzare Tipizzazione delle famiglie con marcatori informativi Analisi statistica dell’associazione tra i marcatori e la comparsa della malattia

35
I PROBLEMI… E LA SOLUZIONE
Le famiglie da analizzare solitamente contano pochi membri, o sono disponibili i campioni biologici di un basso numero di individui In famiglie poco numerose vi e’ un basso numero di ricombinanti I risultati cosi’ ottenuti hanno una bassa significatività statistica La soluzione è analizzare più famiglie assieme. Per questo è stato introdotto il LOD SCORE Il LOD SCORE e’ definito come il logaritmo delle probabilità che i loci siano associati (con frazione di ricombinazione θ) piuttosto che non associati (frazione di ricombinazione 0,5)
 piuttosto che non associati (frazione di ricombinazione 0,5)")
36
IL LOD SCORE E’ LA MISURA STATISTICA DEL LINKAGE
Il LOD SCORE (Z) e’ una funzione della frazione di ricombinazione Vengono calcolati i valori di LOD SCORE per una gamma di valori di θe ne viene stimato il valore massimo (Ž) La probabilità complessiva di linkage in un gruppo di famiglie è il prodotto delle probabilità in ciascuna famiglia, per cui i lod score di famiglie diverse, che sono logaritmi, possono essere sommati
 e’ una funzione della frazione di ricombinazione. Vengono calcolati i valori di LOD SCORE per una gamma di valori di θe ne viene stimato il valore massimo (Ž) La probabilità complessiva di linkage in un gruppo di famiglie è il prodotto delle probabilità in ciascuna famiglia, per cui i lod score di famiglie diverse, che sono logaritmi, possono essere sommati.")
37
PRINCIPALI VALORI DI LOD SCORE
Tutti i lod score sono uguali a 0 per θ=0,5 poiché si sta misurando il rapporto di due probabilità identiche I due loci sono in linkage con una probabilità di errore del 5%quando Z e’maggiore o uguale a 3, cioe’quando la probabilità di linkage è mille volte laprobabilità che i due loci non siano concatenati I due loci non sono in linkages Z e’minore di -2 Valori tra i due estremi non permettono conclusioni

38
SOFTWARE PER IL MAPPAGGIO GENETICO
Per il calcolo dei lod score vengono usati i programmi LIPED e MLINK Il programma EXCLUDE trasforma i dati negativi di linkage in un diagramma delle possibili localizzazioni residue

40
IL MAPPAGGIO A PIU’ PUNTI
Serve a mappare un locus patologico rispetto ad una batteria di marcatori Aiuta a superare i problemi causati dalla limitata informatività dei marcatori Particolarmente utile, soprattutto per quanto riguarda la costruzione di mappe dei marcatori, per stabilire l’ordine lungo un cromosoma di un gruppo di loci associati

41
IL MAPPAGGIO A PIU’ PUNTI DI UN GENE-MALATTIA
Lo scopo è localizzare il gene in uno degli intervalli della mappa dei marcatori Viene usato il programma LINKMAP che ricava le posizioni del locus-malattia rispetto la griglia di marcatori, calcolando la probabilità complessiva dei dati di linkage per ciascuna delle posizioni possibili

42
IL RISULTATO Il risultato che si ottiene e’ una curva diprobabilita’rispetto alle localizzazioni di mappa Il picco piu’ alto indica la posizione piu’ probabile del locus malattia Le regioni in cui la curva si trova al di sotto del valore di -2 vanno escluse dall’analisi Oggi, il mappaggio marcatore-malattia a piu’punti non viene usato, a eccezione che per il mappaggio di esclusione

43
COSTRUZIONE DELLE MAPPE MARCATORE-MARCATORE
Uso di famiglie raccolte specificamente a questo scopo dal CEPH (Centrepourl’Etude des Polymorphismes Humaines) Linee cellulari immortalizzate di tutti i membri delle famiglie disponibili a richiesta per la mappatura di un nuovo marcatore Risultati delle mappe disponibili in banca dati ad uso di tutti
 Linee cellulari immortalizzate di tutti i membri delle famiglie disponibili a richiesta per la mappatura di un nuovo marcatore. Risultati delle mappe disponibili in banca dati ad uso di tutti.")
44
E LORO DISTANZA NELLE MAPPE
ORDINE DEI MARCATORI E LORO DISTANZA NELLE MAPPE Per la costruzione delle mappe dei marcatori e’ indispensabile il mappaggio a piu’ punti Per determinare l’ordine dei marcatori vengono usati metodi di mappaggio fisico, oltre che i calcoli di lod score Le distanze genetiche marcatore-marcatore nelle mappe sono approssimative Un obbiettivo del Progetto Genoma e’ la costruzione di mappe genetiche di marcatori che distano fra loro mediamente 1 cM

45
CENNI PER L’ANALISI DI LINKAGE SENZA MODELLI
Usata per lo studio di patologie non perfettamente mendeliane e caratteri multifattoriali come la schizofrenia, il diabete mellito, l’ipertensione… I metodi usati trascurano l’analisi delle persone non affette Ci si basa sulla ricerca dei segmenti cromosomici comuni agli individui affetti

46
CON CHI VIENE USATO IL METODO DEI SEGMENTI COMUNI
❚Studio di famiglie nucleari (tipo analisi di coppie di fratelli) ❚Studio di ampie famiglie note ❚Studio di popolazioni
 ❚Studio di ampie famiglie note. ❚Studio di popolazioni.")
47
POPOLAZIONI STUDIATE ❚POPOLAZIONI GENETICAMENTE ISOLATE ❚POPOLAZIONI GIOVANI: poche generazioni dal momento della fondazione, pochicrossing-overs, pochericombinazioni ❚POPOLAZIONI OMOGENEE: poche famiglie fondatrici

48
ESEMPI DI POPOLAZIONI STUDIATE
❚FINLANDESI: geneticamente e linguisticamente sono molto diversi dai loro vicini nordici e slavi; la popolazione e’ giovane in quanto fondata circa anni fa da poche famiglie fondatrici ❚ITALIA: studi condotti sulla popolazione SARDA, molto isolata geneticamente

49
STUDI DI ASSOCIAZIONE NELLE POPOLAZIONI
❚Le persone affette dalla malattia ignorano di essere imparentate ❚Molte generazioni e molte meiosi separano gli affetti dal loro antenato comune con una conseguente riduzione della regione identica per discendenza ❚All’interno della regione ci sara’, a livello di popolazione, un’associazione tra la malattia ed un particolare allele o aplotipo

50
ASSOCIAZIONE ALLELICA
ASSOCIAZIONE ALLELICA ❚Possibililta’di portare l’analisi di linkage a risoluzioni irraggiungibili con gli studi sulle famiglie anche per condizioni mendeliane ❚Relazioneallelemarcatore/allelemalattia ❚Marcatori con elevato potere di risoluzione (1 cM), con frequenze simili a quelledell’allelepatologico
, con frequenze simili a quelledell’allelepatologico.")
51
LA COSTRUZIONE DI UNA MAPPA PRECISA DEL GENOMA UMANO MEDIANTE SEQUENZIAMENTO

52
Progetto GENOMA UMANO Scopi:
Sequenziamento dei genomi di interesse biologico o farmacologico Studi di funzione genica

53
Progetto GENOMA UMANO Strategie:
Generazione sistematica di mappe fisiche Sequenziamento di Expressed Sequence Tag (EST) Miglioramento delle tecnologie di sequenziamento
 Miglioramento delle tecnologie di sequenziamento.")
54
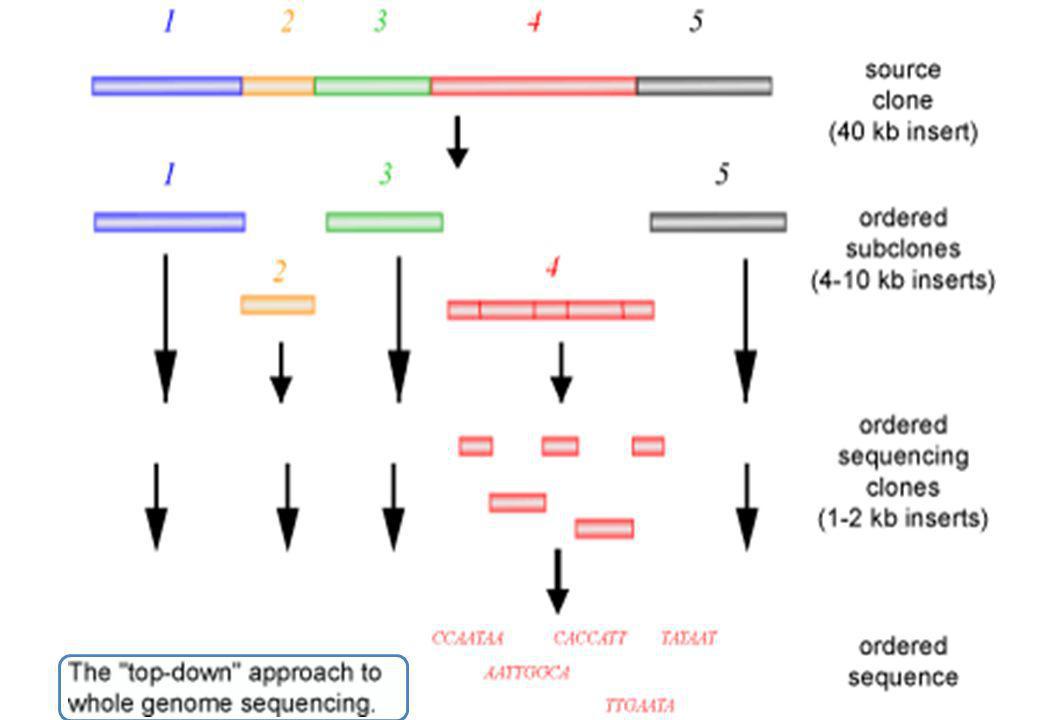
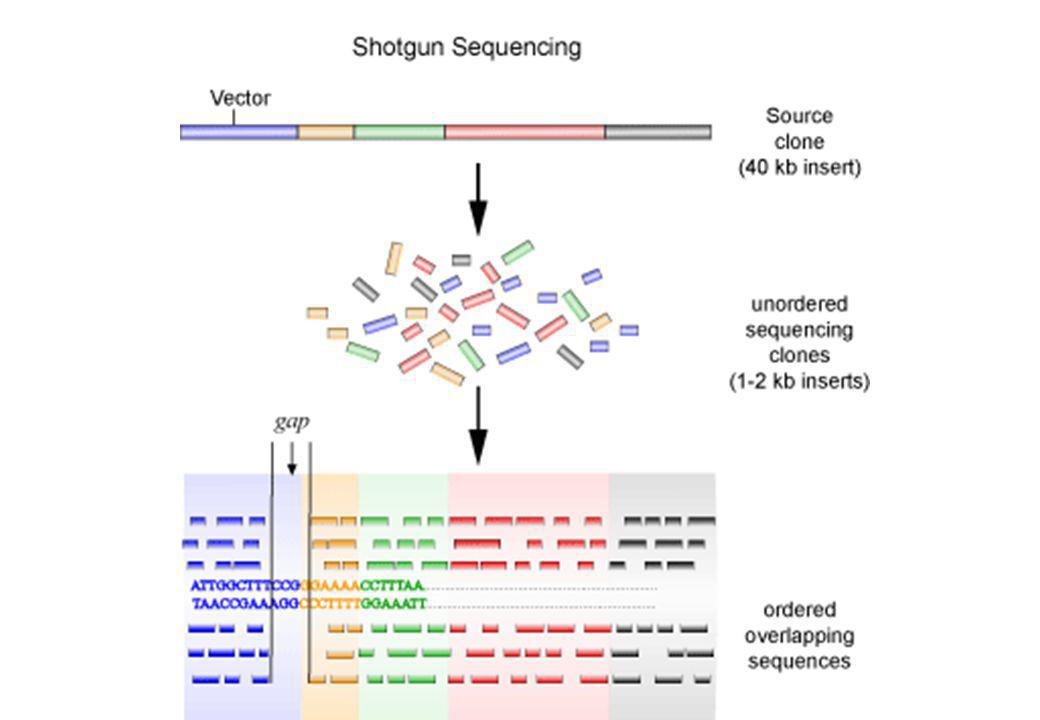
Strategie di sequenziamento del genoma

57
Durata del sequenziamento del genoma umano con il metodo
‘Whole genome shot-gun’ 8 settembre 1999 17 giugno 2000 Craig Venter Termine del progetto Genoma Umano 2003 Investimento NIH nel progetto 3 miliardi di dollari /13 anni Francis Collin

58
1990: Launch of the Human Genome Project 1990: ELSI Founded (Ethical, Legal and Social Implications ) 1990: Research on BACs 1991: ESTs, Fragments of Genes (expressed-sequence tag ) 1992: Second-generation Genetic Map of Human Genome 1992: Data Release Guidelines Established 1993: NEW HGP Five-year Plan 1994: FLAVR SAVR Tomato (Calgene, Inc. of Davis, California ) 1994: Detailed Human Genetic Map 1994: Microbial Genome Project (The microbes DOE chose do not cause disease but are important for their environmental, energy, and commercial roles 1995: Ban on Genetic Discrimination in Workplace 1995: Two Microbial Genomes Sequenced 1995: Physical Map of Human Genome Comp leted 1996: International Strategy Meeting on Human Genome Sequencing 1996: Mouse Genetic Map Completed 1996: Yeast Genome Sequenced 1996: Archaea Genome Sequenced 1996: Health Insurance Discrimination Banned 1996: 280,000 Expressed Sequence Tags (ESTs) 1996: Human Gene Map Created 1996: Human DNA Sequence Begins (large-scale sequencing) 1997: Bermuda Meeting Affirms Principle of Data Release 1997: E. coli Genome Sequenced 1997: Recommendations on Genetic Testing 1998: Private Company Announces Sequencing Plan 1998: M. Tuberculosis Bacterium Sequenced 1998: Committee on Genetic Testing (Service’s Advisory Committee on Genetic Testing 1998: HGP Map Includes 30,000 Human Genes 1998: New HGP Goals for : SNP Initiative Begins (single nucleotide polymorphism, multigene disorders) 1998: Genome of Roundworm C. elegans Sequenced 1999: Full-scale Human Genome Sequencing 1999: Chromosome 22
 1996: Human Gene Map Created 1996: Human DNA Sequence Begins (large-scale sequencing) : Bermuda Meeting Affirms Principle of Data Release 1997: E. coli Genome Sequenced 1997: Recommendations on Genetic Testing 1998: Private Company Announces Sequencing Plan 1998: M. Tuberculosis Bacterium Sequenced 1998: Committee on Genetic Testing (Service’s Advisory Committee on Genetic Testing 1998: HGP Map Includes 30,000 Human Genes 1998: New HGP Goals for : SNP Initiative Begins (single nucleotide polymorphism, multigene disorders) 1998: Genome of Roundworm C. elegans Sequenced 1999: Full-scale Human Genome Sequencing 1999: Chromosome")
59
2000: Free Access to Genomic Information 2000: Chromosome : Working Draft 2000: Drosophila and Arabidopsis genomes sequenced 2000: Executive Order Bans Genetic Descrimination in the Federal Workplace 2000: Yeast Interactome Published 2000: Fly Model of Parkinson's Disease Reported 2001: First Draft of the Human Genome Sequence Released 2001: RNAi Shuts Off Mammalian Genes 2001: FDA Approves Genetics-based Drug to Treat Leukemia Gleevec to treat patients with chronic myeloid leukemia (CML). 2002: Mouse Genome Sequenced 2002: Researchers Find Genetic Variation Associated with Prostate Cancer 2002: Rice Genome Sequenced 2002: The International HapMap Project is Announced 2002: The Genomes to Life Program is Launched 2002: Researchers Identify Gene Linked to Bipolar Disorder 2003: Human Genome Project Completed 2003: Fiftieth Anniversary of Watson and Crick's Description of the Double Helix 2003: The First National DNA Day Celebrated 2003: ENCODE Program Begins 2003: Premature Aging Gene Identified

60
2004-The Future 2004: Rat and Chicken Genomes Sequenced 2004: FDA Approves First Microarray 2004: Refined Analysis of Complete Human Genome Sequence 2004: Surgeon General Stresses Importance of Family History 2005: Chimpanzee Genomes Sequenced 2005: HapMap Project Completed 2005: Trypanosomatid Genomes Sequenced 2005: Dog Genomes Sequenced 2006: The Cancer Genome Atlas (TCGA) Project Started 2006: Second Non-human Primate Genome is Sequenced 2006: Initiatives to Establish the Genetic & Environmental Causes of Common Diseases Launched
 Project Started 2006: Second Non-human Primate Genome is Sequenced 2006: Initiatives to Establish the Genetic & Environmental Causes of Common Diseases Launched.")
61
Alcuni risultati dell’analisi della sequenza del genoma umano
n. geni 26*103 arrangiamento dei geni non casuale (in cluster) esoni 1.1% del genoma introni 24% sequenze intergeniche 75% > 1.4 milioni di siti polimorfici (SNPs)
 esoni 1.1% del genoma. introni 24% sequenze intergeniche 75% > 1.4 milioni di siti polimorfici (SNPs)")
63
NATURE Human Genome Collection
It is now more than 15 years since work began sequencing the 2.85 billion nucleotides of the human genome. While the draft sequence was published in Nature in 2001, researchers at the Human Genome Project continued to fill the gaps and subject individual chromosomes to ever more detailed analyses. Nature is proud to present here the complete and comprehensive DNA sequence of the human genome as a freely available resource.

65
Risultati del Progetto GENOMA UMANO

68
The Cancer Genome Atlas (TCGA) is a comprehensive and coordinated effort to accelerate our understanding of the genetics of cancer using innovative genome analysis technologies. The overarching goal of The Cancer Genome Atlas (TCGA) is to improve our ability to diagnose, treat and prevent cancer
 is to improve our ability to diagnose, treat and prevent cancer.")
70
The National Institutes of Health announced in 2009 the expansion of TCGA project.
After a rigorous review process, the scope of the TCGA Research Network has expanded to include more than 20 tumor types and thousands of samples over the next five years. Each cancer will undergo comprehensive genomic characterization that incorporates powerful bioinformatic and data analysis components. The expansion of TCGA is expected to lead to the most comprehensive understanding of cancer genomes and will enable researchers to further mine the data generated by TCGA to improve prevention, diagnosis and treatment of cancer.

71
ENCyclopdia Of DNA Elements (ENCODE).
2003 NIH ENCODE Project ENCyclopdia Of DNA Elements (ENCODE). To identify and locate all of the genome’s protein-coding genes, non-protein coding genes, and other sequence-based functional elements. When completed, the collection of elements identified by the ENCODE program will help scientists better understand how the genome influences our health.
. To identify and locate all of the genome’s protein-coding genes, non-protein coding genes, and other sequence-based functional elements. When completed, the collection of elements identified by the ENCODE program will help scientists better understand how the genome influences our health.")
80
use gene targeting to make the resource of null alleles, marked with a high utility reporter, preferably in C57BL/6; support a repository to house the products of this resource; develop improved C57BL/6 ES cells that show robust germline transmission, so that they may be used in a high throughput pipeline in generating this resource; implement a data coordination center which will make the status and relevant data of the production effort available to the research community.

81
NIH 2006 Genes and Environment Initiative (GEI).
GEI has two components: the analysis of genetic variation among people with specific diseases an effort to develop technology that will find new ways to monitor environmental exposures that interact with genetic variations leading to disease. The specific diseases that GEI will focus on will be decided by peer review.

82
HapMap Project The International HapMap Project is a multi-country effort to identify and catalog genetic similarities and differences in human beings. Using the information in the HapMap, researchers will be able to find genes that affect health, disease, and individual responses to medications and environmental factors. The goal of the International HapMap Project is to compare the genetic sequences of different individuals to identify chromosomal regions where genetic variants are shared

Presentazioni simili


























 Diversità genetica (b) Equilibrio di Hardy-Weinberg>")







>")





