Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
NA62 technical runs 2012 M. Sozzi CSN1 – Milano – 25.3.2013

2
NA62 in 1 minuto Misura di ~100 eventi del decadimento ultra-raro K + →π + νν BR exp = (1.73 +1.15 –1.05 ) · 10 –10 BR th = (0.78 ± 0.08) · 10 –10 Estrema precisione, estrema sensibilità a NP Nuova tecnica: decadimento in volo ad alta energia Approvazione 2009 Primo technical run 2012 Prima presa dati fine 2014
 · 10 –10 BR th = (0.78 ± 0.08) · 10 –10 Estrema precisione, estrema sensibilità a NP Nuova tecnica: decadimento in volo ad alta energia Approvazione 2009 Primo technical run 2012 Prima presa dati fine 2014")
3
NA62 in 1 altro minuto TDAQ

4
NA62 in 1 altro minuto TDAQ

5
Sala ECN3

6
FascioCompleto, intensita’ ~10% Tubo85/115m, vuoto OK CEDARInstallato, 4/8 settori, 30% PM, readout std. GTKNon installato, silicio passivo su fascio CHANTIPrototipo (1/5) non in vuoto, readout std. STRAW0.5/4 camera in vuoto, readout parziale prototipo standalone LAV8/12 installati, 3 alimentati, readout std. RICHNon installato CHODVecchio (NA48), funzionante, readout std. IRCNon installato LKRLetto 40% con vecchio readout (NA48) MUV2/3 installato, readout std. SACInstallato, readout std. Setup 2012
 non in vuoto, readout std. STRAW0.5/4 camera in vuoto, readout parziale prototipo standalone LAV8/12 installati, 3 alimentati, readout std. RICHNon installato CHODVecchio (NA48), funzionante, readout std. IRCNon installato LKRLetto 40% con vecchio readout (NA48) MUV2/3 installato, readout std. SACInstallato, readout std. Setup")
7
Setup 2012 - 2014

8
Dry run (TDAQ) 16 luglio – 12 agosto 2012 ~35 persone simultaneamente presenti Primo test dell’infrastruttura (fibre di distribuzione clock/trigger, rete, TEL62 servers, PC farm) Test elettronica Acquisizione dati standalone (front-end pulsers) Sincronizzazione e distribuzione dei trigger di L0 Acquisizione dati coordinata Trigger “vecchio stile” (manpower) Test prototipo di run control Fondamentale per la soluzione di molti problemi prima del fascio Non tutti i test sono stati possibili (firmware) Grande progresso
 16 luglio – 12 agosto 2012 ~35 persone simultaneamente presenti Primo test dell’infrastruttura (fibre di distribuzione clock/trigger, rete, TEL62 servers, PC farm) Test elettronica Acquisizione dati standalone (front-end pulsers) Sincronizzazione e distribuzione dei trigger di L0 Acquisizione dati coordinata Trigger vecchio stile (manpower) Test prototipo di run control Fondamentale per la soluzione di molti problemi prima del fascio Non tutti i test sono stati possibili (firmware) Grande progresso")
9
Technical run 29 ottobre – 3 Dicembre 2012 105 shifts (2 shifters + tutti gli esperti…) Numerosi stop causati da problemi “esterni”: magneti, PS, acqua
 Numerosi stop causati da problemi esterni : magneti, PS, acqua")
10
TDAQ comune CEDAR, CHANTI, LAV, RICH, CHOD, MUV, SAC, IRC Front-end (specifico per sub-detector) TDCB (128 canali @ 100 ps) 4x TDCB = 1 TEL62 (512 canali) 4 x 1Gb ethernet: - primitive di trigger L0 (a L0 Trigger Processor) - dati (a PC farm)
 TDCB ( ps) 4x TDCB = 1 TEL62 (512 canali) 4 x 1Gb ethernet: - primitive di trigger L0 (a L0 Trigger Processor) - dati (a PC farm)")
11
TEL62 Major upgrade delle TELL1(LHCb) Usate da: CEDAR, CHANTI, LAV, RICH, LKr/L0, CHOD, MUV, SAC, IRC 15 schede costruite (~90 totale necessario) Disegno OK, qualche problema di montaggio
 Usate da: CEDAR, CHANTI, LAV, RICH, LKr/L0, CHOD, MUV, SAC, IRC 15 schede costruite (~90 totale necessario) Disegno OK, qualche problema di montaggio")
12
TEL62 Firmware Sviluppo firmware e test relativi (Pisa) sono l’impegno piu’ gravoso che ha risentito pesantemente della riduzione di manpower (cfr. LHCb)
.")
13
TDCB Basate su CERN HPTDC Usate da: CEDAR, CHANTI, LAV, RICH, CHOD, MUV, SAC, IRC 29 schede costruite (~100 totale necessario) Disegno OK, pronte per la produzione
 Disegno OK, pronte per la produzione")
14
Test… Crates Network issues TTCex phase stability Firmware loading Not yet radiation tests Noise in TDCs tested Trigger synchronization and counting Clock/trigger phase synchronization Data transfer to farm Standalone trigger generation/distribution Trigger synchronization, data extraction from memories Long runs, rate tests… Technical run

15
Parte I: “test beams” Muoni, acquisizione standalone triggerless dei rivelatori Commissioning del fascio Parte II: “run collettivo” Muoni, “pencil beam” Intensita’ bassa (10%) e “alta” Trigger “vecchio stile” ma distribuito in “nuovo stile”
 e alta Trigger vecchio stile ma distribuito in nuovo stile")
16
Scan di pressione Correzioni di slewing Risoluzione temporale: 280 ps dopo correzione CEDAR

17
Fuori dall’accettanza del trigger, alone muoni Acquisizione standalone Caratterizzazione, occupancy, correzione di slewing, rumore, σ=1.1 ns single ch. CHANTI

18
3 stazioni lette, elevata statistica Run di muoni dedicati Studi di rumore a diversa intensita’ Allineamenti temporali, risoluzioni, occupancy, correlazioni Slewing corrected T ~ 800 ps LAV

19
Lettura parziale standalone con un prototipo non connesso al TDAQ Straws

20
Per il 2012: vecchio odoscopio di NA48 Trigger principale, buona risoluzione temporale σ = 300 ps Test parassitici di possibili soluzioni per un nuovo CHOD CHOD

21
Acquisizione semi-standalone 40% dei canali letti nel 2012 con il vecchio readout di NA48 integrato nel nuovo framework Selezione di 50/100 π+π0 per burst Calorimetro LKr Prototipo di un modulo del nuovo readout (CAEN) testato nelle ultime ore
 testato nelle ultime ore")
22
Muon Veto Elettronica temporanea Rumore/leaks su alcuni canali, refiring Segnale troppo lungo per finestra readout Luce di scintillazione MUV3: σ < 500 ps

23
CEDAR-LKR CHOD-LKRMUV3-LKR Risultati Allineamento temporale richiede il fascio, non triviale: clock, LTU, Trigger interface, TEL62, farm 150 GB di dati raccolti con il sistema di readout standard (no soluzione di backup)
")
24
K+→π+π0K+→π+π0 Breve run: risposte rivelatori a π e γ, timing, attivita’ nei veto Trigger CHOD*NHOD, Intensita’ 2% nominale, 8M eventi 2γ → π 0 (LKr); π 0 + K + (beam)→ π +. CEDAR K: Δt < 3ns da π 0 CHOD π: 15cm da π + estrapolato MUV μ: Δt minimo da π 0 LKr π: 15cm da π + estrapolato LKr π: 15cm da π + estrapolato

25
K+→π+π0K+→π+π0 40K eventi Fondo ~ 1% σ(m 2 miss ) = 3.8·10 –3 GeV 2 /c 4 ε(CEDAR) = 87% ε(CHOD) = 95% Accid(MUV) ≈ 6%
 = 3.8·10 –3 GeV 2 /c 4 ε(CEDAR) = 87% ε(CHOD) = 95% Accid(MUV) ≈ 6%")
26
Limitazioni, problemi ecc. Shift di fase del clock (previsti) Trigger rate (100 kHz) << del valore di disegno (1 MHz), → no validazione completa del sistema Trigger generato esternamente Quasi niente firmware specifico per sub-detector (ecc. LAV) Assenza di un processore di trigger L0 Inizializzazione detector/readout provvisoria Stabilita’ e affidabilita’ nella comunicazione slow control Banda della rete non testata Problemi di crates 2013: Test laboratorio, Dry runs, Produzioni 2014: Installazioni e run
 Trigger rate (100 kHz) << del valore di disegno (1 MHz), → no validazione completa del sistema Trigger generato esternamente Quasi niente firmware specifico per sub-detector (ecc. LAV) Assenza di un processore di trigger L0 Inizializzazione detector/readout provvisoria Stabilita’ e affidabilita’ nella comunicazione slow control Banda della rete non testata Problemi di crates 2013: Test laboratorio, Dry runs, Produzioni 2014: Installazioni e run.")
27
FIRB M. Sozzi CSN1 – Milano – 25.3.2013

28
‘’Realizzazione di un sistema innovativo per il calcolo complesso e il pattern recognition in tempo reale mediante l'utilizzo di processori grafici commerciali (GPU). Applicazione nella selezione di eventi rari in esperimenti di Fisica delle Alte Energie e nell'imaging medico in CT, NMR e PET’’ Meeting di collaborazione NA48/2 a Dubna (Settembre 2006): implementazione di GPGPU in real-time per trigger in HEP Sviluppo esplosivo del settore (NVIDIA) Studi di fattibilita’ (Pisa 2009-2011) Progetto FIRB interdisciplinare (Febbraio 2012): Approvazione (Novembre 2012) Inizio progetto: 1 Aprile 2013
: implementazione di GPGPU in real-time per trigger in HEP Sviluppo esplosivo del settore (NVIDIA) Studi di fattibilita’ (Pisa ) Progetto FIRB interdisciplinare (Febbraio 2012): Approvazione (Novembre 2012) Inizio progetto: 1 Aprile")
29
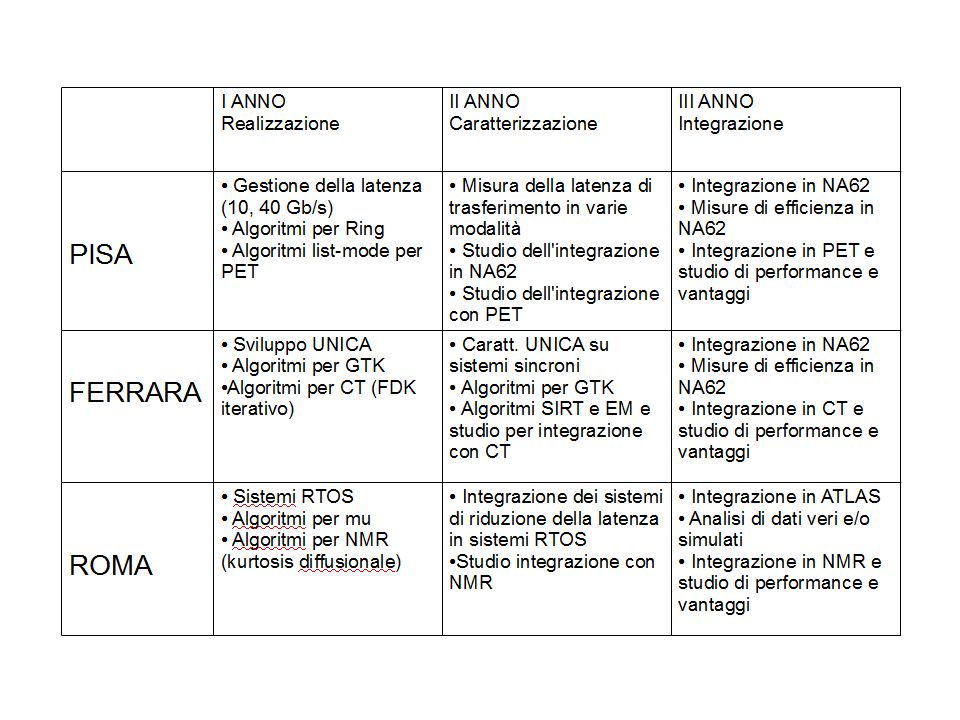
3 Unità di Ricerca in 3 anni Roma: Andrea Messina Stefano Giagu Marco Rescigno Silvia Capuani Marco Palombo Andrea Laghi Pisa (INFN): Gianluca Lamanna Marco Sozzi Riccardo Fantechi Mauro Piccini Gianmaria Collazuol Flavio Costantini Niccolò Camarlinghi Ferrara: Massimiliano Fiorini Luciano Milano Guido Zavattini Angelo Cotta Ramusino Stefano Chiozzi Alberto Gianoli Giovanni Di Domenico
: Gianluca Lamanna Marco Sozzi Riccardo Fantechi Mauro Piccini Gianmaria Collazuol Flavio Costantini Niccolò Camarlinghi Ferrara: Massimiliano Fiorini Luciano Milano Guido Zavattini Angelo Cotta Ramusino Stefano Chiozzi Alberto Gianoli Giovanni Di Domenico")
30
Livello HW di trigger HEP (Pisa, Ferrara, (Roma) ) Livello SW di trigger HEP (Roma, Ferrara, Pisa) NMR (Roma) PET (Pisa) CT (Ferrara) GPU
 ) Livello SW di trigger HEP (Roma, Ferrara, Pisa) NMR (Roma) PET (Pisa) CT (Ferrara) GPU")
31
Real Time Complexity L0 trigger SW trigger CT PET NMR hoursns easy hard

32
scientifici Il calcolo su processori video sta diventando comune in diversi settori scientifici Economico: Economico: quasi tutte le schede video possono essere utilizzate per il calcolo Scalabile: GPU Titan GPU Scalabile: cluster di GPU. Il computer più potente del mondo (Titan) è basato su GPU. Sviluppo tecnologico gratis video giochi e l’editing video Sviluppo tecnologico gratis: settore «trainato» dai video giochi e l’editing video. Facile (relativamente): (CUDA, OpenACC, OpenCL,…) Facile (relativamente): grosso sforzo per esporre le capacità di calcolo in modo user friedly (CUDA, OpenACC, OpenCL,…)
 è basato su GPU. Sviluppo tecnologico gratis video giochi e l’editing video Sviluppo tecnologico gratis: settore «trainato» dai video giochi e l’editing video. Facile (relativamente): (CUDA, OpenACC, OpenCL,…) Facile (relativamente): grosso sforzo per esporre le capacità di calcolo in modo user friedly (CUDA, OpenACC, OpenCL,…).")
33
Standard trigger system FE digitiz ation PCs “Triggerless” FE Digitization + buffer + (trigger primitives) PCs+GPU L0 L1 “quasi-triggerless” with GPUs Custom HW Commercial PCs Commercial GPU system FE digitiz ation Trigger primitives pipeline Trigger processor PCs L0 L1 FE HEP low-level trigger (PI)
 PCs+GPU L0 L1 quasi-triggerless with GPUs Custom HW Commercial PCs Commercial GPU system FE digitiz ation Trigger primitives pipeline Trigger processor PCs L0 L1 FE HEP low-level trigger (PI)")
34
HEP high-level trigger (RM) ATLAS Studi iniziati nel 2010 (Edimburgo) ZfinderTrackfitting Zfinder e Trackfitting algorithms SiTrack Versione GPGPU di SiTrack clustering. L’unità di Roma si occuperà di studiare una versione paralella GPU di un algoritmo migliorato per il trigger muonico in condizioni di alto pileup

35
Fisica medica (RM) LDRD MD K par K ort _K_K 0 1 2 0 1 2 ( m 2 /ms) Conventional DTI 128x128x32x15 = 7.864320 10 6 linear systems to solve 15 s on CPU* Kurtosis tensor imaging 128x128x32x15 = 7.864320 10 6 non-linear fit to perform 7200 s on CPU* * 8 threads on an Intel Xeon E5-2609 CPU at 2.4 GHz L’unità di Roma si occuperà di studiare la versione GPU di algoritmi di ricostruzione di parametri fisici (kurtosis diffusionale) in NMR. Collaborazione con policlinico Umberto I

36
GAP-CT (Ferrara) L’unità di Ferrara si occuperà di studiare la portabilità di algoritmi di ricostruzione in CT in geometria Conebeam, per acquisizione con bassa dose per CT a spirale e non. Collaborazione con il policlinico universitario di Ferrara GAP-PET (Pisa) L’unità di Pisa si occuperà di studiare algoritmi OSEM and MLME in versione GPU per acquisizione su scanner sperimentali Collaborazione per l’utilizzo degli scanner del gruppo di fisica medica di Pisa Fisica medica (FE, PI)
 L’unità di Pisa si occuperà di studiare algoritmi OSEM and MLME in versione GPU per acquisizione su scanner sperimentali Collaborazione per l’utilizzo degli scanner del gruppo di fisica medica di Pisa Fisica medica (FE, PI).")
Presentazioni simili
 timeline dell'esperimento –Presa dati conclusa nel 2000. Alcune analisi tuttora in corso.>")
: - check sistematico.>")








 TTCvi TTCex TRG BSY Builder Unit (XDAQ) Monitor (ORCA) BSY TRG CCB MiniCrate DT Chamber 1 ROB CCB MiniCrate DT Chamber.>")






 Napoli, 11/13 Aprile Gianluca Lamanna Università & INFN di Pisa.>")

