Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Semi-Supervised Text Classification Using EM

2
Visione della Probabilità 2 VISIONI VISIONE CLASSICA O FREQUENTISTA VISIONE SOGGETTIVA O BAYESIANA

3
Visione Classica o Frequentista della Probabilità La concezione classica afferma che la probabilità è una proprietà fisica del mondo e per essere valutata è necessario ripetere varie volte un esperimento.

4
Visione Classica o Frequentista della Probabilità Siano n eventi esaustivi e mutuamente esclusivi. Si effettuino esperimenti osservandone il risultato. : numero di volte in cui si è verificato l’evento : numero totale degli esperimenti

5
Visione Classica o Frequentista della Probabilità Se è sufficientemente grande si può definire la probabilità dell’evento :

6
Visione Bayesiana della Probabilità La visione bayesiana afferma che la probabilità di un evento è il grado di credenza (degree of belief) di una persona in quell’evento. QUINDI la probabilità è il GRADO SOGGETTIVO DI ASPETTATIVA CHE UNA PERSONA ASSEGNA AL VERIFICARSI DI UN EVENTO INCERTO.

7
Visione Bayesiana della Probabilità La probabilità di un evento è la frazione di una quantità che una persona ritiene EQUO sia pagata per la promessa di ricevere in cambio la quantità nel caso si verifichi

8
DEFINIZIONE ASSIOMATICA DI PROBABILITA’ La probabilità di un evento è un numero che soddisfa i seguenti assiomi:

9
APPRENDIMENTO BAYESIANO GOAL FARE DELLE PREVISIONI, RITIENE IL PROBLEMA DELLA FORMULAZIONE DI IPOTESI A PARTIRE DAI DATI, COME UN SUO SOTTOPROBLEMA.

10
APPRENDIMENTO BAYESIANO COSA SI INTENDE PER MIGLIORE IPOTESI LA MIGLIORE IPOTESI E’ QUELLA PIU’ PROBABILE, AVENDO A DISPOSIZIONE DEI DATI ED UNA CERTA CONOSCENZA INIZIALE DELLE PROBABILITA’ A PRIORI DELLE VARIE IPOTESI.

11
APPRENDIMENTO BAYESIANO Sia un insieme di dati, sia una quantità ignota su cui vogliamo fare delle previsioni e siano delle ipotesi; l’apprendimento bayesiano assume la forma: Si può dimostrare che nessun altro metodo di predizione ha in media delle prestazioni migliori.

12
APPRENDIMENTO BAYESIANO Il calcolo di per tutte le è INTRATTABILE. IPOTESI si considera SOLO l’ipotesi più probabile, ovvero solo l’ipotesi che massimizza

13
APPRENDIMENTO BAYESIANO IPOTESI si considera SOLO l’ipotesi più probabile, ovvero solo l’ipotesi che massimizza Questa ipotesi si chiama “massima a posteriori” o MAP (maximum a posteriori) e si indica con
 e si indica con")
14
APPRENDIMENTO BAYESIANO Per calcolare si ricorre al teorema di Bayes:

15
APPRENDIMENTO BAYESIANO Il termine rappresenta la verosimiglianza (likelihood) dei dati, assunta l’ipotesi come quella corretta. La è la probabilità a priori (prior) dell’ipotesi. Il denominatore rappresenta la probabilità dei dati senza nessuna conoscenza su quale ipotesi possa valere, è una costante di normalizzazione.
 dell’ipotesi. Il denominatore rappresenta la probabilità dei dati senza nessuna conoscenza su quale ipotesi possa valere, è una costante di normalizzazione..")
16
APPRENDIMENTO BAYESIANO Il termine è la probabilità a posteriori (posterior) dell’ipotesi che combina insieme la verosimiglianza dei dati e la conoscenza a priori sull’ipotesi e riflette la nostra confidenza che valga l’ipotesi dopo aver osservato i dati.
 dell’ipotesi che combina insieme la verosimiglianza dei dati e la conoscenza a priori sull’ipotesi e riflette la nostra confidenza che valga l’ipotesi dopo aver osservato i dati.")
17
APPRENDIMENTO BAYESIANO COME SCEGLIERE LA PROBABILITA’ A PRIORI? Privilegiare le ipotesi più semplici rispetto a quelle più complesse (rasoio di Ockham).
..")
18
APPRENDIMENTO BAYESIANO IPOTESI si assume un prior uniforme sulle ipotesi e si sceglie quindi l’ipotesi che massimizza la : tale ipotesi si chiama a massima verosimiglianza o ML (maximum likelihood):
:")
19
Categorizzazione del Testo E’ la classificazione dei documenti in un numero fissato e predefinito di categorie. In generale ogni documento può appartenere ad una categoria, a più categorie o a nessuna categoria. Per poter definire in modo formale il problema dell’apprendimento, si assume che ogni documento appartenga esattamente ad una categoria.

20
Categorizzazione del Testo GOAL Apprendere dagli esempi dei classificatori che siano in grado di assegnare automaticamente una categoria ad un nuovo documento

21
Categorizzazione del Testo In generale: Dato un insieme di documenti e l’insieme delle loro categorie identificate con le etichette si vuole approssimare la funzione per mezzo di una funzione in modo che “coincidano il più possibile”.

22
Categorizzazione del Testo APPROCCIO PRATICO Formulare un algoritmo per ottenere la funzione approssimata. L’approssimazione deriverà dall’impossibilità di osservare tutti i documenti di ogni categoria stabilita. Questo approccio ci consente di osservare un numero finito di esempi e successivamente di utilizzare il modello appreso per classificare istanze non osservate.

23
Categorizzazione del Testo training/validation set per l’apprendimento e la ricerca dei migliori parametri DATASET test set per verificare le prestazioni dell’algoritmo

24
Categorizzazione del Testo Durante la fase di addestramento si cerca di minimizzare la differenza tra ; l’algoritmo di apprendimento sfrutterà la conoscenza a priori data dalle etichette presenti sui documenti nell’insieme di training. Al termine del processo di apprendimento sarà possibile richiedere al classificatore di predire la categoria di un documento sconosciuto. Viene utilizzata una procedura di cross-validazione al fine di evitare un iperadattamento del modello dei dati.

25
Categorizzazione del Testo procedura di cross-validazione viene suddiviso l’insieme dei dati disponibili in sottoinsiemi; viene poi addestrato il modello su insiemi e misurate le prestazioni sull’insieme rimanente. Per ogni n-pla di parametri analizzati viene ripetuto questo procedimento volte.

26
Categorizzazione del Testo rappresentazione dei documenti CORPUS insieme di documenti uno degli approcci più diffusi rappresenta ciascun documento con un vettore le cui componenti sono indicizzate dalle parole presenti nel corpus. Ogni entrata nel vettore è data da un peso dipendente dal numero di occorrenze della parola all’interno del documento.

27
Categorizzazione del Testo rappresentazione dei documenti Sia il modo di calcolare il peso che il concetto di parola sono soggetti a vari tipi di modellazione. Il concetto di parola può essere ridefinito applicando un algoritmo di stemming per sostituire a ciascuna parola la sua radice, facendo confluire nomi, verbi ed aggettivi nello stesso termine (es. combattere, combattente, combattivo COMBATT)
.")
28
Categorizzazione del Testo rimozione delle stop-words rimozione delle parole più frequenti presenti in una lingua come ‘il’, ‘la’, ‘per’, ‘di’, ‘da’, … se stiamo classificando per argomento delle pagine web rimuovere parole come ‘io’, ‘mi’, ‘mia’ o ‘miei’ potrebbe eliminare un’importante informazione nell’individuare le pagine personali.

29
Categorizzazione del Testo bag-of-words stabilito un dizionario di parole, ogni documento viene rappresentato con un vettore di elementi, ciascuno dei quali indica il peso del termine in quel documento. Questo tipo di rappresentazione non tiene conto dell’ordine delle parole né della punteggiatura, né di eventuali riferimenti tra un documento ed altri; ci si riferisce a questo modello come bag-of-words ovvero un insieme non ordinato di termini.

30
Il Classificatore Naive Bayes Avvalendosi di un insieme di dati etichettati per l’addestramento, si stimano i parametri del modello generativo e si classificano le nuove istanze utilizzando il teorema di Bayes e selezionando la categoria che ha la probabilità più alta di aver generato l’esempio. ASSUNZIONE DEL NAIVE BAYES tutti gli attributi che descrivono una certa istanza sono tra loro condizionalmente indipendenti data la categoria a cui appartiene l’istanza. Quando questa ipotesi è verificata, il Naive Bayes esegue una classificazione di tipo MAP.

31
Interpretazione Bayesiana del Naive Bayes DOMINIO APPLICATIVO DEL CLASSIFICATORE NAIVE BAYES riguarda la classificazione di istanze che possono essere descritte mediante un insieme di attributi di cardinalità anche molto elevata. Sia un insieme di variabili che modellano gli attributi delle istanze da classificare e sia una variabile i cui stati rappresentano le categorie a cui appartengono le istanze. Si tratta di stimare una funzione che, applicata ad ogni istanza, fornisca la classe di appartenenza dell’istanza stessa, partendo da un insieme di dati di addestramento in cui ogni elemento è descritto tramite i valori dei suoi attributi e tramite la sua classe

32
Interpretazione Bayesiana del Naive Bayes Una nuova istanza può essere classificata partendo dalla sua descrizione in termini di attributi. Secondo l’approccio bayesiano, si calcolano le probabilità a posteriori e si determina la categoria che massimizza tale probabilità: MAP è “maximum a posteriori” = classe più verosimile

33
Interpretazione Bayesiana del Naive Bayes Il teorema di Bayes permette di esprimere la probabilità a posteriori in funzione della verosimiglianza e della probabilità a priori: Regola di Bayes Abbiamo tralasciato il denominatore perchè rappresenta una costante di normalizzazione

34
Interpretazione Bayesiana del Naive Bayes Il termine può essere stimato facilmente contando il numero di volte che la classe compare tra i dati. La stima del termine è più difficoltosa, perché il numero di configurazioni che può assumere è, dove è il numero degli attributi. Per avere una stima attendibile, servirebbe un numero di dati che è esponenziale nel numero di attributi.

35
Interpretazione Bayesiana del Naive Bayes Per ridurre il numero dei parametri da stimare e corrispondentemente il numero dei dati necessari, si fa l’ipotesi semplificativa che gli attributi siano MUTUAMENTE INDIPENDENTI data la classe dell’istanza:

36
Interpretazione Bayesiana del Naive Bayes Se è soddisfatta l’ipotesi di indipendenza degli attributi, il classificatore Naive Bayes esegue una stima MAP, quindi. Il numero dei termini da stimare si riduce a, che è lineare nel numero di attributi. Il numero totale dei parametri da stimare è

37
Modello Generativo Probabilistico del Classificatore Naive Bayes IPOTESI (1) i dati sono generati da un modello di misture (2) esiste una corrispondenza biunivoca tra le componenti delle misture e le classi cioè si fa corrispondere più componenti della mistura alla stessa classe (3) le componenti della mistura sono distribuzioni multinomiali di singole parole
 i dati sono generati da un modello di misture (2) esiste una corrispondenza biunivoca tra le componenti delle misture e le classi cioè si fa corrispondere più componenti della mistura alla stessa classe (3) le componenti della mistura sono distribuzioni multinomiali di singole parole")
38
Modello Generativo Probabilistico del Classificatore Naive Bayes Sia M l’insieme delle classi e |X| la cardinalità di un vocabolario di parole di dimensione finita. Ogni documento è così generato in accordo ad una distribuzione di probabilità definita da un insieme di parametri e consistente in una mistura di componenti

39
Modello Generativo Probabilistico del Classificatore Naive Bayes Indichiamo con sia la j-esima componente della mistura, sia la j-esima classe. La creazione di un documento avviene in due passi: 1. si seleziona una componente della mistura in accordo alla distribuzione di probabilità a priori sulle classi ; 2. la componente della mistura scelta genera il documento in accordo ai propri parametri con distribuzione.

40
Modello Generativo Probabilistico del Classificatore Naive Bayes La verosimiglianza di un documento può essere vista come la somma pesata delle probabilità che il documento sia generato da ciascuna classe:

41
Modello Generativo Probabilistico del Classificatore Naive Bayes Per poter applicare il classificatore Naive Bayes al problema della categorizzazione del testo, si deve decidere quali debbano essere gli attributi utili a rappresentare un documento e stabilire come stimare le tabelle di probabilità. Modello di Bernoulli 2 approcci Modello Multinomiale

42
Modello di Bernoulli Il modello di Bernoulli rappresenta un documento come un insieme di attributi binari che indicano la presenza o l'assenza di un certo insieme di parole che costituiscono il vocabolario. Questo approccio trascura parte dell'informazione disponibile, perché non considera il numero di occorrenze delle parole nel documento ed è più adatto in quei domini che hanno un numero fissato di attributi.

43
Modello Multinomiale Il modello multinomiale rappresenta un documento come un insieme di parole con associato il loro numero di occorrenze. Anche in questo caso, si perde l'ordinamento delle parole, ma viene catturata la loro frequenza. Gli attributi di un documento coincidono con le parole che lo costituiscono e sono indipendenti tra di loro data la classe ed indipendenti anche dalla posizione che occupano.

44
Modello Multinomiale e Bag of Words La rappresentazione del documento in cui la probabilità di trovare una certa parola è indipendente dalla posizione, viene detta bag of words: si crea così una rappresentazione del testo di tipo attributo-valore. Ogni parola diversa dalle altre corrisponde ad un attributo che ha come valore il numero di volte che la parola compare nel documento.

45
Modello Multinomiale e Feature Selection Per evitare di avere degli insiemi di parole di cardinalità troppo elevata (overfitting), si può eseguire una procedura di feature selection che mira a ridurre il numero di parole che compaiono nel vocabolario: eliminare le parole che compaiono al di sotto e al di sopra di un certo numero di volte nel training set; Procedere ad una selezione delle parole che hanno la più alta informazione mutua con la classe (information gain criterion); applicare alle parole un algoritmo di stemming che estrae la radice, facendo collidere più parole nella stessa feature.
, si può eseguire una procedura di feature selection che mira a ridurre il numero di parole che compaiono nel vocabolario: eliminare le parole che compaiono al di sotto e al di sopra di un certo numero di volte nel training set; Procedere ad una selezione delle parole che hanno la più alta informazione mutua con la classe (information gain criterion); applicare alle parole un algoritmo di stemming che estrae la radice, facendo collidere più parole nella stessa feature.")
46
Modello Multinomiale e Classificatore Naive Bayes L’eliminazione delle parole più comuni come gli articoli o le congiunzioni, garantisce che i termini con basso contenuto informativo non contribuiscano alla classificazione di nuovi documenti. CLASSIFICATORE NAIVE BAYES modello generativo probabilistico per documenti testuali L’assunzione di indipendenza delle parole permette di descrivere il modello con un numero ridotto di parametri.

47
Modello Multinomiale e Classificatore Naive Bayes Supponiamo inizialmente che un documento sia una lista ordinata di parole, dove indica la parola del documento in posizione appartenente al vocabolario : questa ipotesi sarà semplificata con l’assunzione di indipendenza del Naive Bayes e con l’ipotesi di indipendenza dalla posizione. Supponiamo che la lunghezza di un documento sia indipendente dalla mistura: questo equivale ad assumere che la lunghezza è indipendente dalla classe.

48
Modello Multinomiale e Classificatore Naive Bayes Per generare un documento: si seleziona una componente della mistura in accordo alla sua probabilità a priori; la componente scelta genera una sequenza di parole in modo indipendente dalla lunghezza.

49
Modello Multinomiale e Classificatore Naive Bayes Ciascun documento ha una etichetta di classe. Indichiamo con sia la j-esima componente della mistura, sia la j-esima classe. Indichiamo con l’etichetta di classe di un particolare documento. Se un documento è stato generato da una componente della mistura scriveremo. Indichiamo con il numero di volte che la parola compare nel documento

50
Modello Multinomiale e Classificatore Naive Bayes IPOTESI: La probabilità di una parola sia indipendente dalle altre parole presenti data la classe e che sia anche indipendente dalla posizione nel documento. La probabilità di generare un particolare documento, data la classe, assume la seguente forma:

51
Modello Multinomiale e Classificatore Naive Bayes L’insieme completo di parametri del modello è un insieme di distribuzioni multinomiali e di probabilità a priori su queste distribuzioni: dove con In aggiunta devono valere i vincoli di normalizzazione:

52
Modello Multinomiale e Classificatore Naive Bayes I parametri delle componenti delle misture non sono altro che distribuzioni multinomiali sulle parole. Poiché la lunghezza di un documento è identicamente distribuita per tutte le classi, non c’è bisogno di parametrizzarla per la classificazione. Il modello multinomiale è superiore a quello di Bernoulli per grosse dimensioni del vocabolario ed anche nella maggior parte dei casi in cui la dimensione è piccola: in media l’accuratezza supera del 27% quella del modello bernoulliano.

53
Modello Multinomiale e Classificatore Naive Bayes Nei documenti reali le seguenti ipotesi circa la generazione dei documenti di testo sono violate: Modello di misture; Corrispondenza biunivoca tra classi e componenti delle misture; L’indipendenza delle parole; Distribuzione uniforme della lunghezza dei documenti.

54
Modello Generativo: Supervised Text Classification Per stimare i parametri del modello generativo, occorre un insieme di dati etichettati. L’approccio bayesiano massimizza la probabilità a posteriori della stima, dati gli esempi di addestramento e la probabilità a priori: dove rappresenta il valore stimato di.

55
Modello Generativo: Supervised Text Classification Il termine è il prodotto delle likelihood di tutti i documenti, mentre il termine, che rappresenta la probabilità a priori del modello, viene modellato con una distribuzione di Dirichlet: Il parametro pesa l’effetto del prior rispetto ai dati: in questo caso fissiamo, che coincide con il Laplace Smoothing e serve a prevenire che alcuni parametri diventino nulli.

56
Modello Generativo: Supervised Text Classification Per massimizzare l’equazione si ricorre ai moltiplicatori di Lagrange con il vincolo di normalizzazione delle probabilità. In particolare, si massimizza il sistema di derivate parziali di. Le formule di stima dei parametri a cui si giunge come risultato della precedente massimizzazione, non sono altro che rapporti tra il numero di volte che le parole e le classi compaiono nei dati ed un coefficiente di normalizzazione.

57
Modello Generativo: Supervised Text Classification Per quanto riguarda le probabilità a priori delle classi, si ottiene la seguente relazione che vale per entrambi i modelli di documento: 1 se 0 altrimenti IPOTESI: tutti i documenti sono etichettati 1 se 0 altrimenti IPOTESI: tutti i documenti sono etichettati

58
Modello Generativo: Supervised Text Classification La stima dei parametri, dipende invece dal particolare modello di documento che viene scelto. Nel caso venga impiegato un modello di Bernoulli, si ottiene: è un indicatore binario della presenza della parola nel documento 1 se 0 altrimenti IPOTESI: tutti i documenti sono etichettati 1 se 0 altrimenti IPOTESI: tutti i documenti sono etichettati

59
Modello Generativo: Supervised Text Classification Se il documento viene rappresentato con una distribuzione multinomiale sulle parole, si ha: indica il numero di volte che la parola compare nel documento 1 se 0 altrimenti IPOTESI: tutti i documenti sono etichettati 1 se 0 altrimenti IPOTESI: tutti i documenti sono etichettati

60
Classificazione di Nuovi Documenti La classificazione di nuovi documenti utilizza i parametri stimati durante la fase di addestramento per calcolare le probabilità di tutte le classi dato il documento e poi seleziona quella con il valore più alto, in accordo al modello bayesiano. Regola di Bayes

61
Classificazione di Nuovi Documenti Per valutare occorre stabilire la rappresentazione del documento. Essendo per il modello multinomiale si ottiene:

62
L’Algoritmo EM (Expectation-Maximization) L’algoritmo EM fa parte di una classe di algoritmi iterativi per stime ML o MAP nei problemi con dati incompleti. Supponiamo di avere una funzione densità di probabilità della variabile aleatoria che dipende da un insieme di parametri e di aver collezionato un insieme di dati indipendenti ed identicamente distribuiti presi da questa distribuzione. Nel caso di un problema di stima massima a posteriori, si cerca di trovare un valore per in modo che mentre nel caso di stima a massima verosimiglianza dove viene chiamata verosimiglianza dei parametri avendo osservato i dati o più semplicemente funzione di verosimiglianza

63
L’Algoritmo EM (Expectation-Maximization) Invece di massimizzare direttamente, si utilizza il suo logaritmo, perché analiticamente più semplice: Stima ML Stima MAP Funzione di verosimiglianza
 Invece di massimizzare direttamente, si utilizza il suo logaritmo, perché analiticamente più semplice: Stima ML Stima MAP Funzione di verosimiglianza")
64
L’Algoritmo EM (Expectation-Maximization) L’algoritmo EM è utile quando I dati sono mancanti a causa di problemi o limitazioni con il processo di osservazione è utile quando I dati sono mancanti a causa di problemi o limitazioni con il processo di osservazione un caso interessa l’ottimizzazione di una funzione che è analiticamente intrattabile ma che può essere semplificata introducendo delle variabili nascoste addizionali tali che se fossero noti i loro valori, l’ottimizzazione risulterebbe semplificata
 L’algoritmo EM è utile quando I dati sono mancanti a causa di problemi o limitazioni con il processo di osservazione è utile quando I dati sono mancanti a causa di problemi o limitazioni con il processo di osservazione un caso interessa l’ottimizzazione di una funzione che è analiticamente intrattabile ma che può essere semplificata introducendo delle variabili nascoste addizionali tali che se fossero noti i loro valori, l’ottimizzazione risulterebbe semplificata")
65
Utilizzo dei Dati non Etichettati con EM I dati non etichettati possono essere usati per incrementare le prestazioni del classificatore Naive Bayes. L’aggiunta di una grande quantità di dati non etichettati ad un piccolo numero di dati etichettati utilizzando l’algoritmo EM, può portare a dei miglioramenti della stima dei parametri. I documenti non etichettati sono considerati dei dati incompleti, perché sono privi dell’etichetta di classe. Si potrebbe pensare che i dati non etichettati non forniscano nessuna indicazione aggiuntiva, invece contengono delle informazioni sulla distribuzione congiunta sulle parole.

66
Il Classificatore Naive Bayes e l’Algoritmo EM Inizialmente viene addestrato un classificatore utilizzando solo i dati etichettati, poi con questo classificatore si assegnano in modo probabilistico delle etichette ai dati non etichettati calcolando il valore medio delle etichette di classe mancanti. Infine si apprendono i parametri di un nuovo classificatore utilizzando le etichette di tutti i documenti e si itera fino alla convergenza.

67
EM: Equazioni di Stima dei Parametri Supponiamo di avere a disposizione un insieme di documenti di addestramento. A differenza del classificatore Naive Bayes, solo un sottoinsieme di documenti sono etichettati, mentre i restanti appartenenti a non hanno etichetta di classe. Si è così creata una partizione di in due sottoinsiemi disgiunti. L’apprendimento di questo modello segue una stima MAP secondo l’approccio bayesiano:

68
EM: Equazioni di Stima dei Parametri La probabilità di tutti i documenti di addestramento è semplicemente il prodotto delle probabilità di tutti i documenti, in quanto ogni documento è indipendente dagli altri: Per i documenti non etichettati, la probabilità di un documento può essere vista come la somma pesata delle probabilità che il documento sia generato da ciascuna classe, come descritto dall’equazione:

69
EM: Equazioni di Stima dei Parametri Per i documenti etichettati, l’etichetta di classe seleziona solo una componente generativa e quindi non c’è bisogno di ricorrere a tutte le componenti della mistura ma solo a quella corrispondente alla classe. La probabilità di tutti i documenti è data da: dove con si è indicata la classe del documento che è nota perché il documento è etichettato.

70
EM: Equazioni di Stima dei Parametri Invece di massimizzare direttamente, si preferisce lavorare con il logaritmo di : il punto di massimo non cambia in quanto il logaritmo è una funzione monotona crescente. Definiamo la funzione di verosimiglianza dei dati incompleti: che può essere riscritta nel seguente modo: Purtroppo questa equazione contiene una somma di logaritmi per i dati non etichettati che rende computazionalmente intrattabile la massimizzazione attraverso le derivate parziali. dove con si è indicata la classe del documento che è nota perché il documento è etichettato.

71
EM: Equazioni di Stima dei Parametri Se però conoscessimo l’etichetta di classe di tutti i documenti, la somma all’interno del logaritmo si ridurrebbe ad un solo termine, semplificando il problema della massimizzazione. Sia un insieme di variabili nascoste in corrispondenza biunivoca con, tali che, se fossero noti i loro valori, allora sarebbe nota l’etichetta di classe di tutti i documenti dell’insieme di addestramento. Ogni elemento può essere visto come un vettore di indicatori binari in cui se e solo se il documento appartiene alla classe, altrimenti. dove con si è indicata la classe del documento che è nota perché il documento è etichettato.

72
EM: Equazioni di Stima dei Parametri Il primo passo dell’algoritmo EM calcola il valore medio del logaritmo della verosimiglianza dei dati completi rispetto ai dati non osservati avendo a disposizione i dati osservati ed una stima corrente dei parametri: Nel nostro caso: dove con si è indicata la classe del documento che è nota perché il documento è etichettato. Q è una nuova funzione, mentre E è l’operatore valore medio

73
EM: Equazioni di Stima dei Parametri Applicando la disuguaglianza di Jensen con si ottiene: dove con si è indicata la classe del documento che è nota perché il documento è etichettato. La disuguaglianza di Jensen permette di sostituire il log di una somma con una somma di logaritmi

74
EM: Equazioni di Stima dei Parametri La funzione di verosimiglianza dei dati completi assume la forma dove è stato aggiunto il termine che tiene conto del prior sui parametri. Per terminare il calcolo dell’E-step basta applicare l’operatore valore medio ad entrambi i membri della disequazione su riportata: dove con si è indicata la classe del documento che è nota perché il documento è etichettato.

75
EM: Equazioni di Stima dei Parametri Il passo di massimizzazione ottimizza al variare dei parametri : Questa procedura iterativa di hill-climbing determina un massimo locale della funzione di verosimiglianza ricalcolando alternativamente il valore atteso di e la stima massima a posteriori dei parametri. Il valore di è noto per i documenti etichettati e quindi deve essere stimato solo per quelli non etichettati. dove con si è indicata la classe del documento che è nota perché il documento è etichettato.

76
EM: Equazioni di Stima dei Parametri Se denotano rispettivamente la stima per e per al passo, allora l’algoritmo trova un massimo locale di iterando i due seguenti passi: L’E-step assegna in modo probabilistico le etichette di classe ai documenti non etichettati usando la stima corrente dei parametri per mezzo dell’equazione

77
EM: Equazioni di Stima dei Parametri dove il termine dipende dal modello di documento usato (multinomiale o di Bernoulli) mentre ne è indipendente. L’M-step calcola una nuova stima MAP dei parametri del modello, usando le stime correnti per.

78
EM: Equazioni di Stima dei Parametri La stima dei parametri non dipende dal particolare modello di documento usato mentre i parametri si differenziano a seconda del modello adottato, nel caso venga impiegata una distribuzione multinomiale sulle parole abbiamo: 1 se 0 altrimenti IPOTESI: tutti i documenti sono etichettati 1 se 0 altrimenti IPOTESI: tutti i documenti sono etichettati

79
Algoritmo EM applicato al Classificatore Naive Bayes 1. Inputs: Un insieme di documenti etichettati ed un insieme di documenti non etichettati Sia 2. Costruire un classificatore Naive Bayes iniziale utilizzando solo i dati etichettati. Usare una stima massima a posteriori per determinare. 3. Ripetere i due passi seguenti finchè l’incremento della verosimiglianza dei dati completi è al di sopra di una certa soglia. a) E-step: Usare il classificatore corrente per stimare la probabilità che ogni componente della mistura abbia generato ogni documento non etichettato. M-step: Aggiornare la stima del classificatore avendo a disposizione le stime di appartenenza di ogni documento alle varie classi. Usare una stima massima a posteriori per trovare 4.Output: Un classificatore che predice l’etichetta di classe di ogni documento non etichettato che gli viene presentato.
 E-step: Usare il classificatore corrente per stimare la probabilità che ogni componente della mistura abbia generato ogni documento non etichettato. M-step: Aggiornare la stima del classificatore avendo a disposizione le stime di appartenenza di ogni documento alle varie classi. Usare una stima massima a posteriori per trovare 4.Output: Un classificatore che predice l’etichetta di classe di ogni documento non etichettato che gli viene presentato..")
80
Algoritmo EM applicato al Classificatore Naive Bayes L’inizializzazione dell’algoritmo esegue un M-step iniziale che costruisce un classificatore Naive Bayes utilizzando solo i dati etichettati Segue poi il ciclo delle iterazioni che comincia con un E-step che usa il classificatore appena creato per etichettare in modo probabilistico i documenti non etichettati per la prima volta. I due passi dell’algoritmo si alternano finchè non si converge ad un valore di che non cambia da un’iterazione ad un’altra.

81
Limitazioni ed Estensioni Nei documenti reali le 2 ipotesi circa la generazione dei documenti di testo sono violate: Modello di misture; Corrispondenza biunivoca tra classi e componenti delle misture; quindi in certe situazioni il contributo fornito dai dati non etichettati può essere quasi inesistente o portare persino ad un peggioramento delle prestazioni, come nel caso in cui siano disponibili molti dati etichettati.

82
Limitazioni ed Estensioni In molte situazioni è comune avere a disposizione una piccola quantità di dati etichettati ma un numero di dati non etichettati. In questi casi, la grande maggioranza delle informazioni per la stima dei parametri con EM proviene dai dati non etichettati e si può pensare che EM esegua per lo più un clustering non supervisionato, cercando di adattare le componenti della mistura per massimizzare la verosimiglianza dei documenti non etichettati. NB EM 300 documenti etichettati (15 x classe) 52% acc. 66% acc. 20 “ “ (1 x classe) 20% acc. 35% acc.
 52% acc. 66% acc. 20 (1 x classe) 20% acc. 35% acc..")
83
Più Componenti della Mistura per Classe IPOTESI si assume che ci possa essere una corrispondenza MOLTI A UNO tra le componenti della mistura e le classi, cioè che una classe possa contenere più sottoargomenti, ognuno dei quali è rappresentato in modo migliore da una differente distribuzione delle parole. L’utilizzo di più componenti per classe permette anche di catturare alcune dipendenze tra le parole. IMPORTANTE la possibilità di poter avere più componenti per classe introduce dei valori mancanti anche per i documenti etichettati. La stima dei parametri sarà sempre eseguita con EM, con l’aggiunta che per ogni documento etichettato si deve individuare quale componente lo ha generato.

84
Implementazione Maximum Likelihood Estimation Smoothing with Dirichlet (Additive) Priors Inference
 Priors Inference")
85
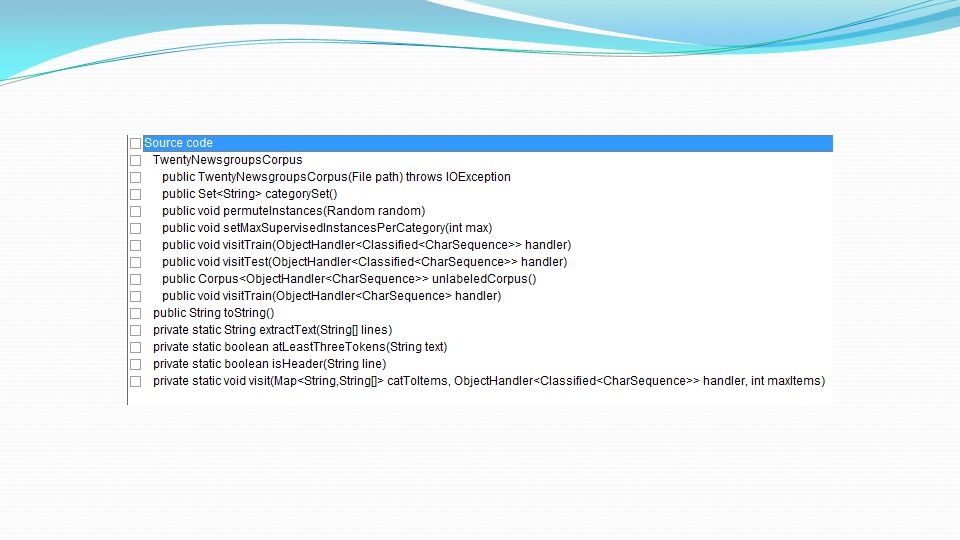
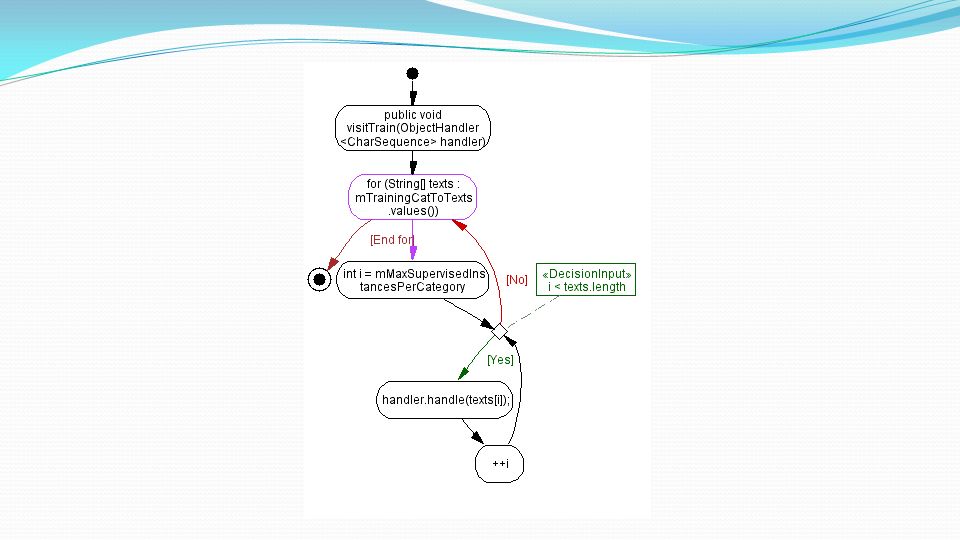
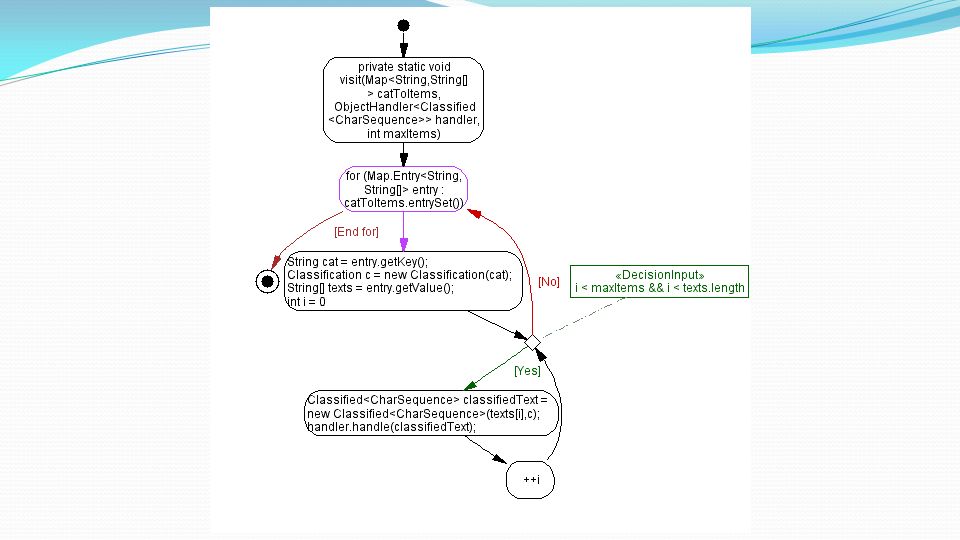
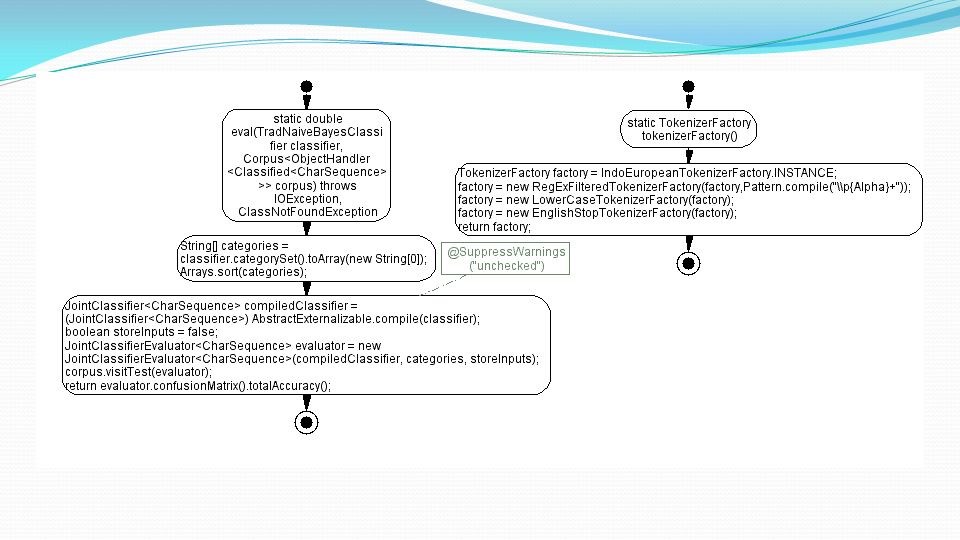
Implementazione Class TradNaiveBayesClassifier (converte sequenze di caratteri in token)
")
86
Implementazione Naive Bayes integrato con EM Factory crea un nuovo classificatore in ogni epoca

87
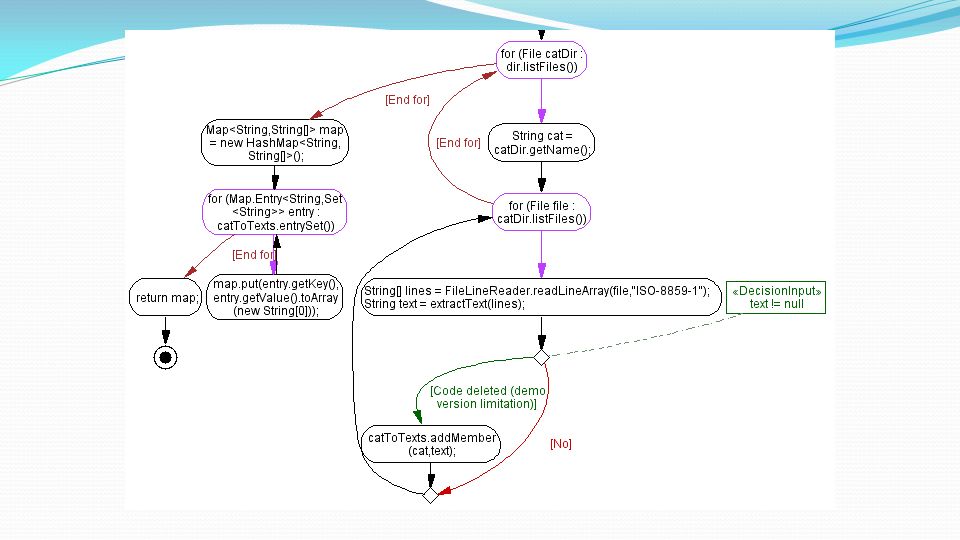
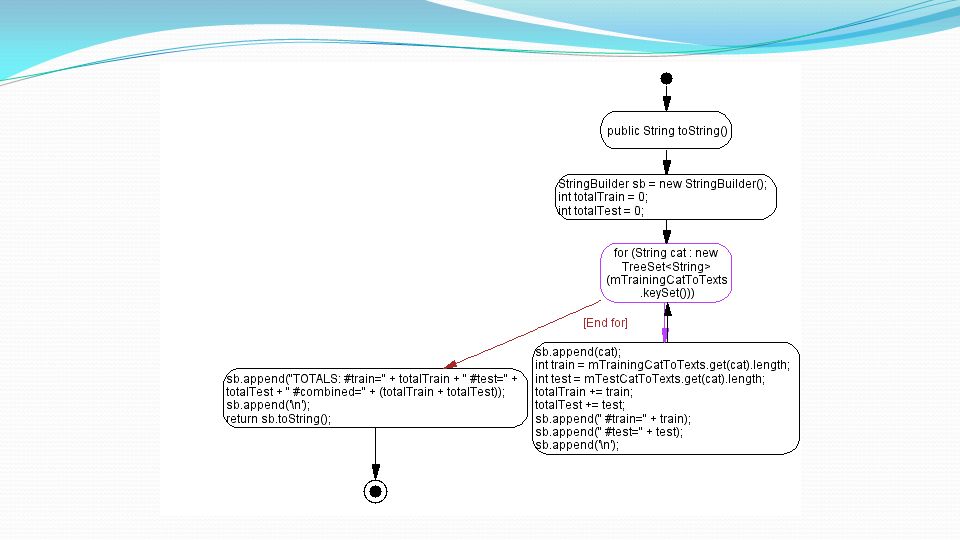
Implementazione Creazione di Corpora etichettati e senza etichetta Il programma è costituito da due classi, una per fare la stima di EM e impostare tutti i parametri necessari di factory e un’altra per creare il corpus. I corpora sono definiti nella classe TwentyNewsgroupsCorpus. Input dei dati Per esempio, mTestCatToTexts.get("sci.med") restituisce una array dove ogni voce è un testo di prova per il newsgroup sci.med.
 restituisce una array dove ogni voce è un testo di prova per il newsgroup sci.med..")
88
Implementazione Permutazione dei dati Al fine di ottenere risultati diversi in diverse esecuzioni, applichiamo permutazioni per i dati di training:

89
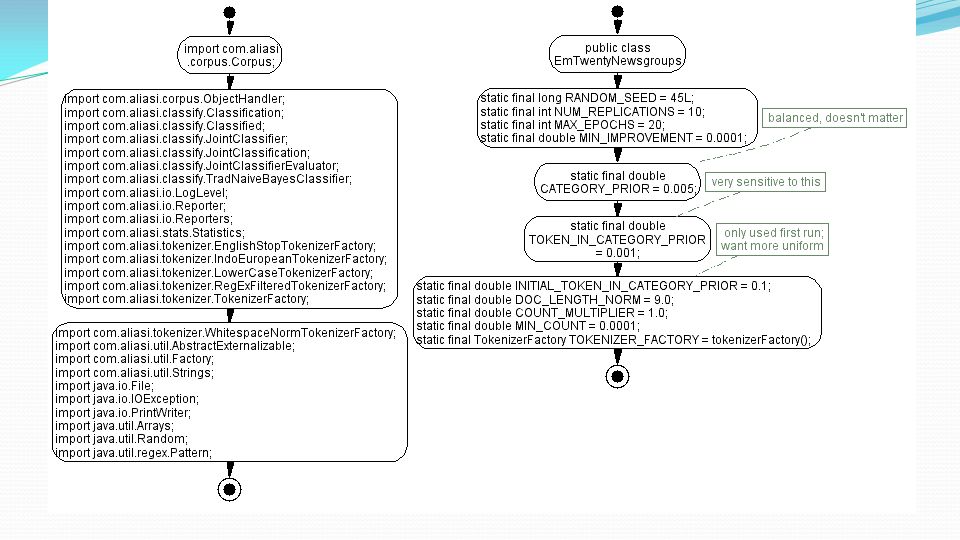
Implementazione La classe EM (stima dei parametri) 10 trial per numero di campioni di addestramento I parametri:
 10 trial per numero di campioni di addestramento I parametri:")
90
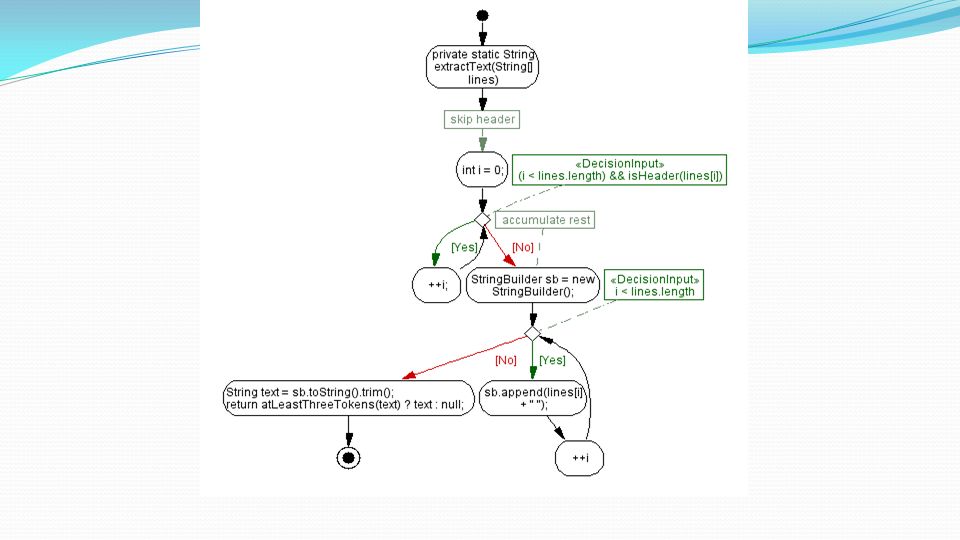
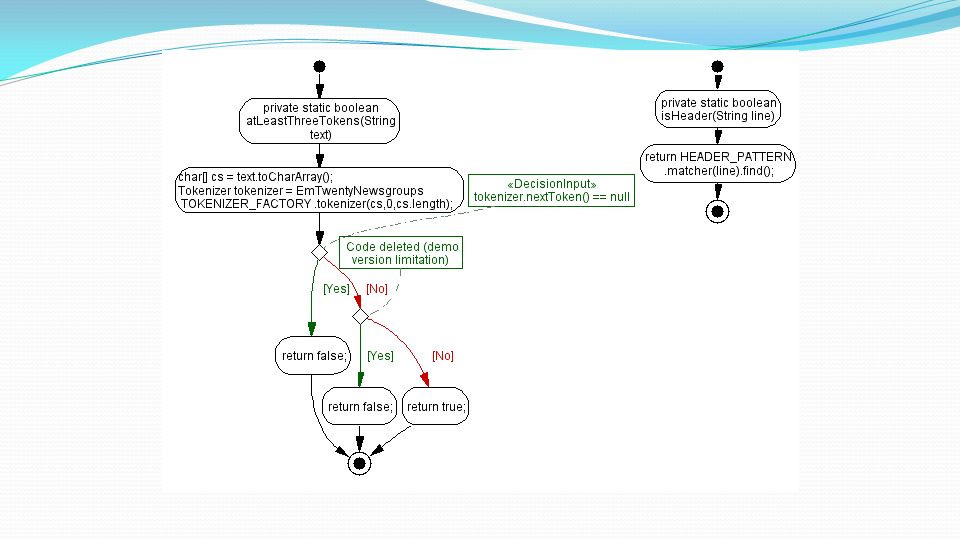
Implementazione Tokenization Questo metodo imposta un insieme di filtri sul token. Prima di tutto, usiamo la nostra base tokenizer indoeuropea, che fornisce un’istanza singleton. Rimuoviamo tutti i token non alfa-numerici. Reporting

91
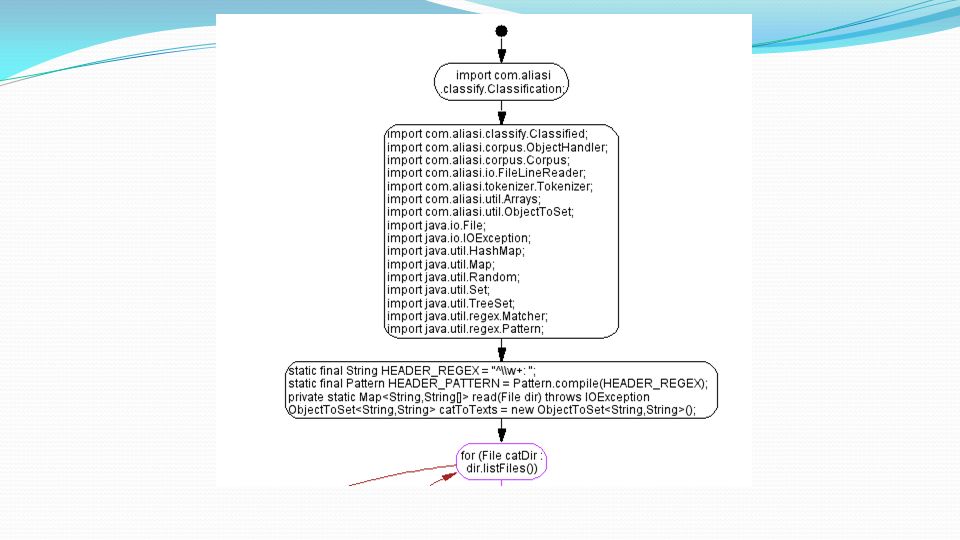
Implementazione Costruzione di Corpora Costruiamo i corpora utilizzando il costruttore e il path dei dati scompattati:

92
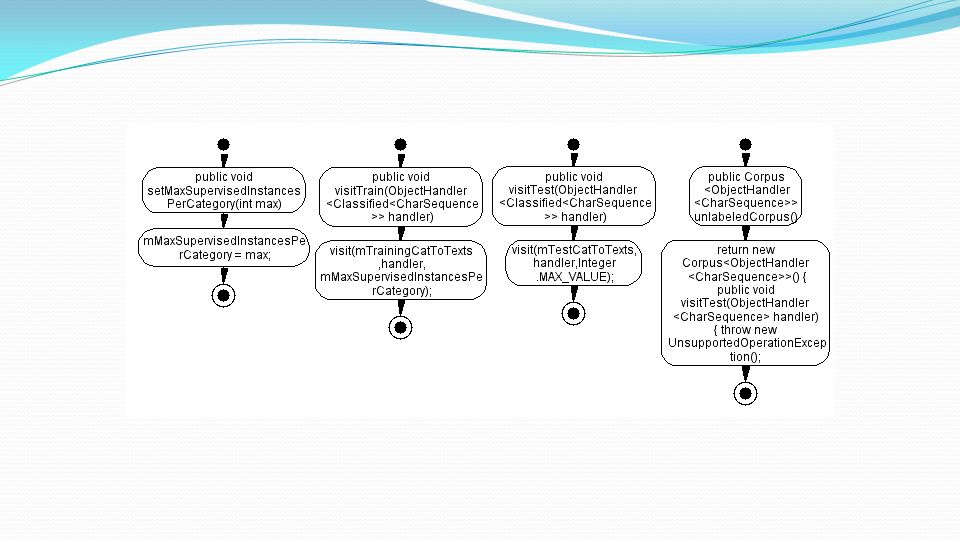
Implementazione Classificatore Iniziale

93
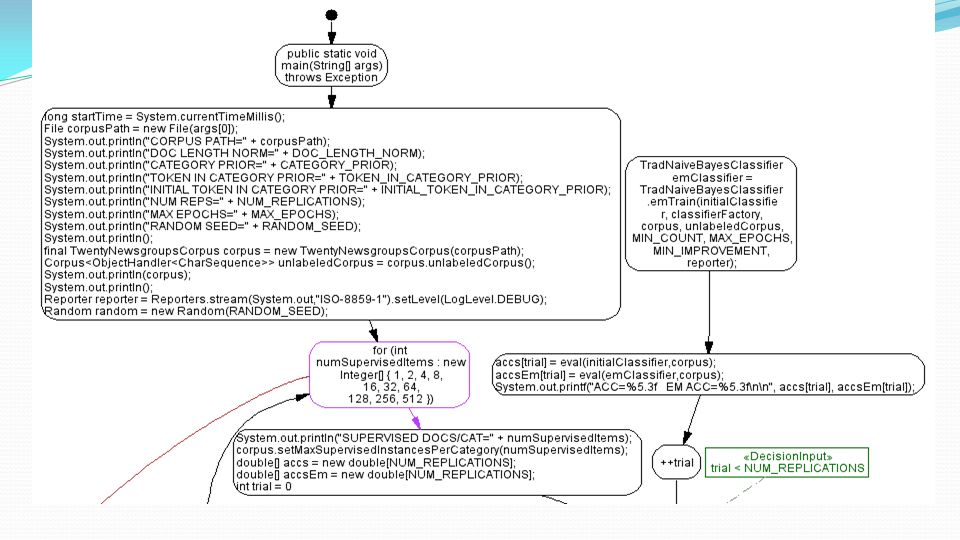
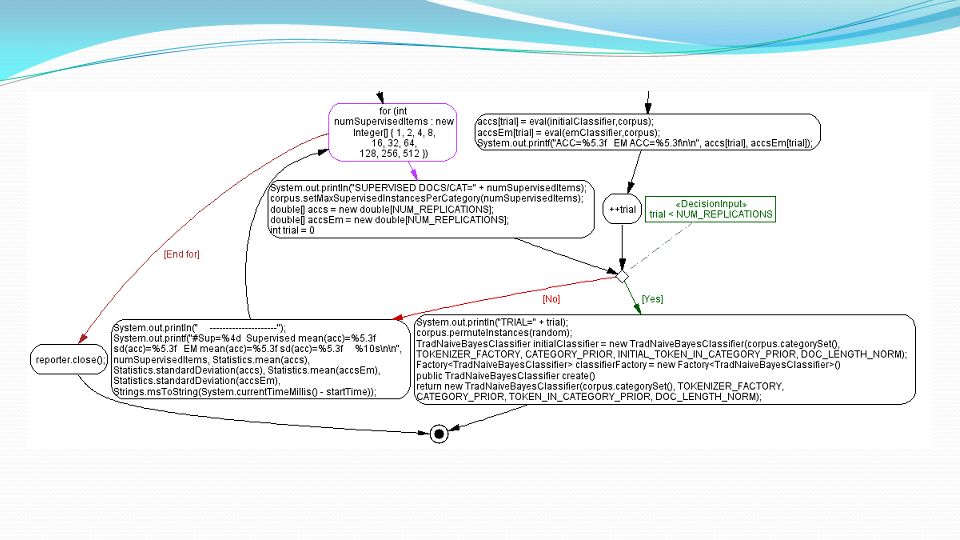
Implementazione Esecuzione:

94
Implementazione Esecuzione:

95
Implementazione Esecuzione:

96
Implementazione Esecuzione:

97
Implementazione ant -Dnewsgroups.path=TWENTY_NEWSGROUPS em > risultati.txt

98
Implementazione

114
Risultati Sperimentali: Data Set Il data set 20 Newsgroups collezionato da Ken Lang, raccoglie 20000 articoli in formato testuale suddivisi equamente tra 20 differenti gruppi di discussione di UseNet, ognuno contenente 1000 articoli. Questo insieme di dati è stato collezionato in un periodo di diversi mesi nel 1993. Tra i dati raccolti ci saranno naturalmente delle correlazioni temporali: infatti gli articoli inviati nello stesso periodo avranno una probabilità più alta di appartenere allo stesso sottoargomento del gruppo di discussione. Inoltre, quando si risponde ad un articolo, è buona regola riportare anche il testo dell'articolo a cui si sta replicando: questa abitudine, spesso, porta ad avere molte parole in comune negli articoli che si susseguono.

115
Risultati Sperimentali: Data Set Lo scopo è quello di classificare ogni articolo nel corrispondente gruppo di discussione a cui è stato inviato, tramite il classificatore Naive Bayes. utilizzando dati etichettati e non etichettati. Tutti i dati a disposizione sono etichettati: se vogliamo ottenere dei dati non etichettati, è sufficiente nascondere all'algoritmo di apprendimento l'etichetta del documento. In fase di classificazione, si considerano i documenti appartenenti al test set come se fossero non etichettati, ignorando la loro categoria di appartenenza. Si esegue poi una classificazione di questi dati con il modello addestrato e si valuta l'accuratezza del classificatore facendo riferimento alla reale categoria del documento che era stata precedentemente ignorata.

117
Un Articolo del Gruppo di Discussione rec.sports.baseball.

118
Risultati Sperimentali: Data Set La parte iniziale presenta una serie di linee consecutive che rappresentano l'header del messaggio e che descrivono le caratteristiche dell'articolo: possiamo riconoscere il newsgroup di appartenenza, la data di invio, il numero di linee, l'identificatore del messaggio, etc. Ai fini della classificazione, è importante eliminare l'header dell'articolo, perché contiene il newsgroup di appartenenza che identifica direttamente la categoria a cui deve essere assegnato. L'header è seguito dal corpo del messaggio. In questo caso, si può notare che l'utente che ha spedito l'articolo, ha risposto ad un messaggio precedentemente inviato che viene riportato nelle prime linee contrassegnate con il carattere >. Segue poi il testo vero e proprio del messaggio in cui il mittente esprime la propria opinione.

119
Risultati Sperimentali: Data Set L'elaborazione di un articolo che porta ad una rappresentazione come bag of bag of words, inizia costruendo il vocabolario delle parole. Per ogni articolo viene eliminato l'header che contiene la categoria di appartenenza del documento: non vengono invece scartate le linee che riportano il testo di un messaggio precedentemente inviato per non ridurre troppo il numero di parole che costituiscono il documento. I token corrispondenti alle parole, sono formati dai caratteri alfabetici continui: i caratteri non alfabetici vengono sostituiti con dei caratteri di spaziatura. I documenti con meno di 3 token sono rimossi.

120
Risultati Sperimentali: Training Set e Test Set Il corpus contiene 18.846 documenti: http://qwone.com/~jason/20Newsgroups/20news-bydate.tar.gz Dopo aver rimosso i documenti con meno di tre token restano 18.803 documenti, divisi fra i 20 gruppi di discussione: training(60%), test(40%)
, test(40%)")
121
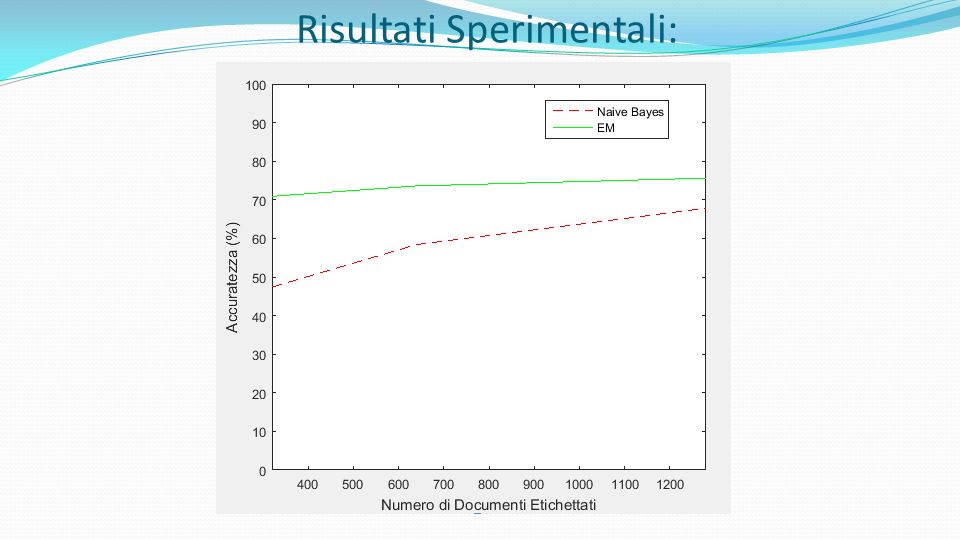
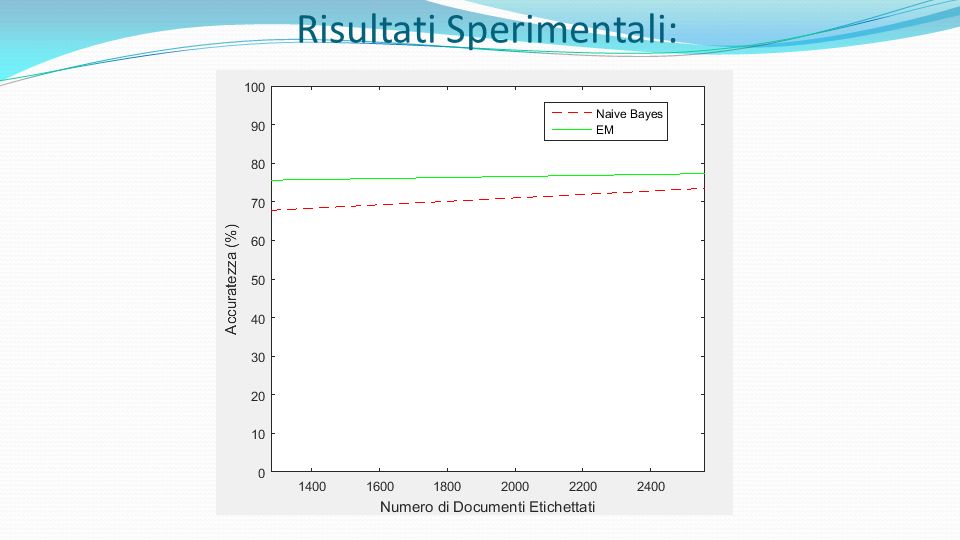
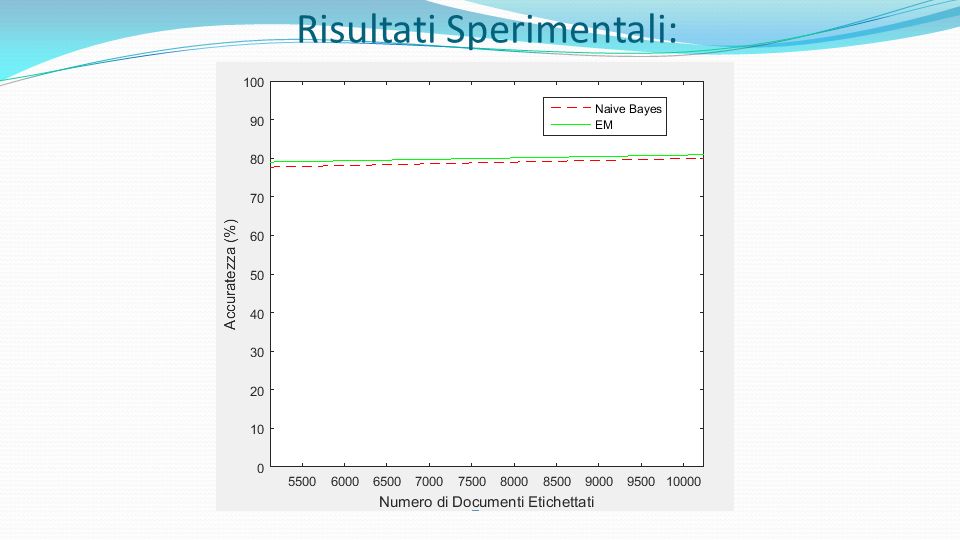
Risultati Sperimentali: Risultati Supervised e Semi-Supervised su 20 Newsgroups #Sup Supervised Accuracy EM Accuracy #Sup= 1 Supervised mean(acc)=0,122 sd(acc)=0,010 EM mean(acc)=0,339 sd(acc)=0,046 1:13:17 #Sup= 2 Supervised mean(acc)=0,175 sd(acc)=0,020 EM mean(acc)=0,522 sd(acc)=0,061 2:17:26 #Sup= 4 Supervised mean(acc)=0,262 sd(acc)=0,015 EM mean(acc)=0,613 sd(acc)=0,035 3:18:29 #Sup= 8 Supervised mean(acc)=0,358 sd(acc)=0,016 EM mean(acc)=0,665 sd(acc)=0,011 4:15:18 #Sup= 16 Supervised mean(acc)=0,474 sd(acc)=0,011 EM mean(acc)=0,709 sd(acc)=0,014 5:08:41 #Sup= 32 Supervised mean(acc)=0,584 sd(acc)=0,007 EM mean(acc)=0,736 sd(acc)=0,008 5:58:10 #Sup= 64 Supervised mean(acc)=0,678 sd(acc)=0,009 EM mean(acc)=0,756 sd(acc)=0,007 6:46:03 #Sup= 128 Supervised mean(acc)=0,735 sd(acc)=0,004 EM mean(acc)=0,773 sd(acc)=0,003 7:25:47 #Sup=256 Supervised mean(acc)=0,777 sd(acc)=0,003 EM mean(acc)=0,790 sd(acc)=0,003 8:00:51 #Sup=512 Supervised mean(acc)=0,800 sd(acc)=0,002 EM mean(acc)=0,809 sd(acc)=0,001 8:25:05 documenti supervisionati e non supervisionati solo su documenti supervisionati
=0,122 sd(acc)=0,010 EM mean(acc)=0,339 sd(acc)=0,046 1:13:17 #Sup= 2 Supervised mean(acc)=0,175 sd(acc)=0,020 EM mean(acc)=0,522 sd(acc)=0,061 2:17:26 #Sup= 4 Supervised mean(acc)=0,262 sd(acc)=0,015 EM mean(acc)=0,613 sd(acc)=0,035 3:18:29 #Sup= 8 Supervised mean(acc)=0,358 sd(acc)=0,016 EM mean(acc)=0,665 sd(acc)=0,011 4:15:18 #Sup= 16 Supervised mean(acc)=0,474 sd(acc)=0,011 EM mean(acc)=0,709 sd(acc)=0,014 5:08:41 #Sup= 32 Supervised mean(acc)=0,584 sd(acc)=0,007 EM mean(acc)=0,736 sd(acc)=0,008 5:58:10 #Sup= 64 Supervised mean(acc)=0,678 sd(acc)=0,009 EM mean(acc)=0,756 sd(acc)=0,007 6:46:03 #Sup= 128 Supervised mean(acc)=0,735 sd(acc)=0,004 EM mean(acc)=0,773 sd(acc)=0,003 7:25:47 #Sup=256 Supervised mean(acc)=0,777 sd(acc)=0,003 EM mean(acc)=0,790 sd(acc)=0,003 8:00:51 #Sup=512 Supervised mean(acc)=0,800 sd(acc)=0,002 EM mean(acc)=0,809 sd(acc)=0,001 8:25:05 documenti supervisionati e non supervisionati solo su documenti supervisionati")
122
Risultati Sperimentali: Nei test effettuati, si varia il numero di documenti etichettati da un minimo di 20 (uno per categoria) fino ad un massimo di 10.240 (512 per categoria), con il duplice obiettivo di valutare le prestazioni del classificatore e di analizzare il contributo fornito dai dati non etichettati al variare della percentuale di documenti etichettati.
 fino ad un massimo di (512 per categoria), con il duplice obiettivo di valutare le prestazioni del classificatore e di analizzare il contributo fornito dai dati non etichettati al variare della percentuale di documenti etichettati.")
123
Risultati Sperimentali:

128
Innanzitutto si può osservare che l'incremento dell'accuratezza è pressoché trascurabile se si utilizzano più di 3.000 documenti etichettati in entrambi i classificatori. Il Naive Bayes integrato con EM raggiunge delle prestazioni migliori: per esempio, con soli 20 documenti etichettati (uno per categoria), il primo raggiunge un'accuratezza del 12.2%, mentre il secondo del 33.9%, con un incremento del 21.7%.
, il primo raggiunge un accuratezza del 12.2%, mentre il secondo del 33.9%, con un incremento del 21.7%..")
129
Risultati Sperimentali: L’esperimento mostra che quando ci sono molti dati etichettati e la curva del Naive Bayes è per lo più piatta, l'aggiunta dei dati non etichettati non aiuta ad incrementare l'accuratezza, perché c’è già una quantità sufficiente di dati etichettati per stimare in modo accurato i parametri del modello: ad esempio, con 5.120 documenti etichettati (256 per classe), l'accuratezza di classificazione rimane praticamente invariata.
, l accuratezza di classificazione rimane praticamente invariata.")
130
Risultati Sperimentali: Questi esperimenti dimostrano che EM trova una stima dei parametri che aumenta l'accuratezza di classificazione e riduce il bisogno dei dati etichettati. Per esempio, per raggiungere un'accuratezza del 58%, il Naive Bayes richiede 640 documenti etichettati (32 per classe), mentre EM ne richiede solo 80 (4 per classe), con una riduzione di 8 volte.
, mentre EM ne richiede solo 80 (4 per classe), con una riduzione di 8 volte..")
Presentazioni simili




 GLI INTERVALLI DI CONFIDENZA>")














>")



