Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Computer assisted translation (2) Cristina Bosco Informatica applicata alla comunicazione multimediale 2013
 Cristina Bosco Informatica applicata alla comunicazione multimediale 2013")
2
Cosa è una Memoria di Traduzione Una TM (Translation Memory) è un archivio di materiali linguistici, in formato elettronico, in lingua originale (LS) e tradotta (LT). È costruita da traduttori umani grazie a sistemi di CAT ed organizzata in frammenti di testo detti Unità di Traduzione (UdiT) solitamente di lunghezza pari ad una frase.
 solitamente di lunghezza pari ad una frase..")
3
Cosa è una Memoria di Traduzione I sistemi di gestione delle TM servono per costruire ed ampliare le TM e per utilizzarle. Il risultato è di incrementare la produttività dl traduttore che non si trova a tradurre più di una volta il frammento di testo che ha precedentemente tradotto, ma anche l’uniformità terminologica e stilistica della traduzione.

4
Cosa è una Memoria di Traduzione Un sistema di CAT memorizza coppie bilingui allineate nella TM. Quando, nel corso della traduzione, un segmento di testo identico o simile ad uno precedentemente tradotto viene trovato nella TM (match), il sistema ne propone la traduzione. Il traduttore può accettarla, modificarla o rifiutarla.
, il sistema ne propone la traduzione. Il traduttore può accettarla, modificarla o rifiutarla..")
5
Come funziona una Memoria di Traduzione Supponiamo che nella TM ci siano le seguenti UdiT: UdiT-1: Io mangiavo ieri una pera. allineata con Yesterday I ate a pear. UdiT-2: Io mangio sovente una mela. allineata con I often eat an apple. (se sono nella TM vuol dire che il traduttore le ha tradotte e il sistema le ha allineate)
.")
6
Come funziona una Memoria di Traduzione Quando il traduttore traduce la nuova frase: Io mangio una mela Il sistema propone: I often eat an apple. perché il sistema riconosce una somiglianza tra la frase nuova e una delle frasi presenti nella TM (UdiT-2) e propone di conseguenza la traduzione di UdiT-2.
 e propone di conseguenza la traduzione di UdiT-2..")
7
Come funziona una Memoria di Traduzione Il sistema non è in grado di riconoscere in cosa consiste la differenza tra la frase nuova e quella che trova nella TM; fa solo un calcolo sulla differenza tra le due frasi e se questo calcolo porta ad un risultato che supera la soglia stabilita dal traduttore non propone la traduzione.

8
Come funziona una Memoria di Traduzione I match che vengono trovati tra il testo da tradurre e quello contenuto nella TM non sono infatti solo quelli perfetti, ma anche quelli parziali, in accordo con le impostazioni scelte dal traduttore. Per questo motivo i sistemi di CAT si rivelano utili per testi con: omogeneità terminologica omogeneità fraseologica frasi semplici e brevi, poco ambigue e ripetitive

9
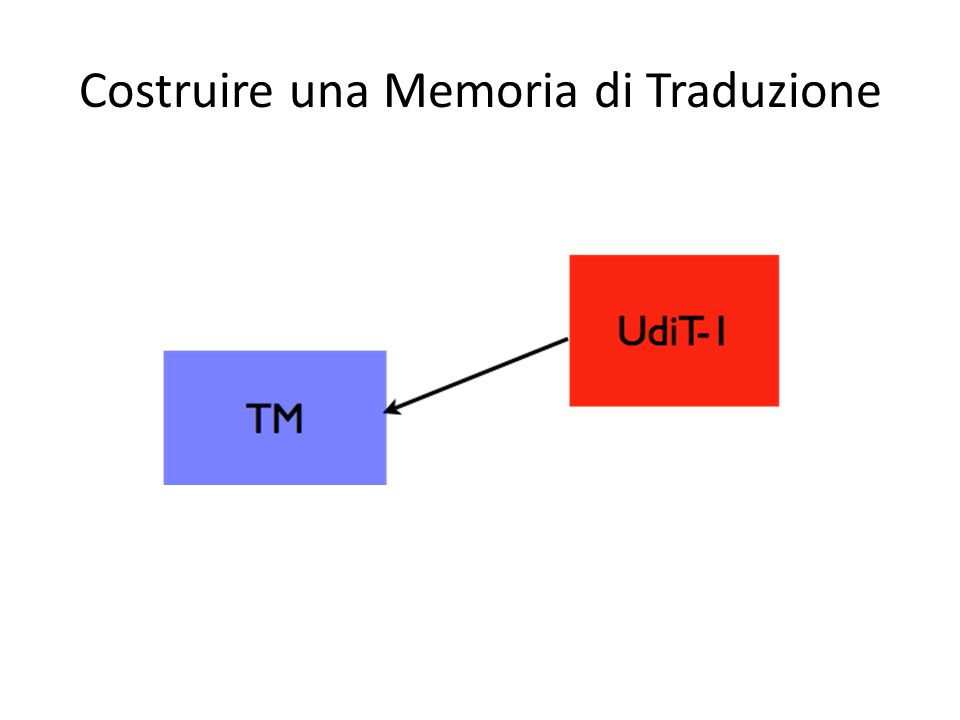
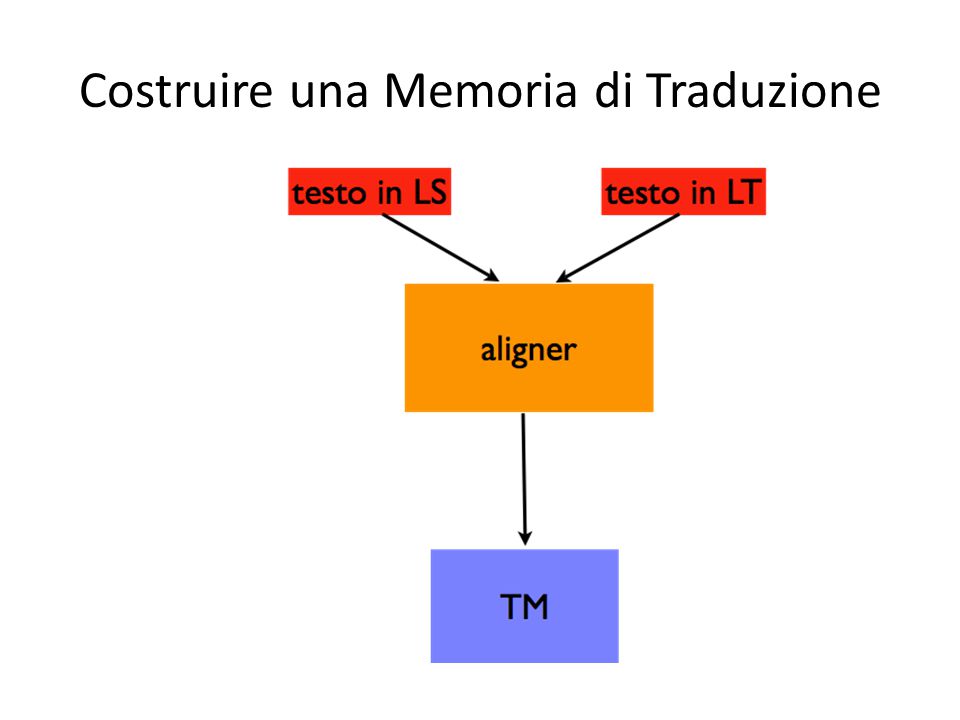
Costruire una Memoria di Traduzione Nel corso della traduzione, in un sistema di CAT, tutto il testo in LS e la sua traduzione in LT viene automaticamente memorizzato in forma allineata nella TM scelta dal traduttore. È anche possibile importare altre TM o allineare testi disponibili in LS e in LT utilizzando programmi appositi.

10
Costruire una Memoria di Traduzione

13
Gestire una Memoria di Traduzione Ogni UdiT in una TM consiste in una coppia di segmenti di testo, il segmento in LS e quello in LT, insieme a informazioni relative alla date di creazione e modifica dei segmenti, alla persona che ha creato o modificato il segmento, al progetto e al cliente per cui quella particolare UdiT viene adoperata. Questo consente di filtrare le TM per future traduzioni.

14
Utilizzare una Memoria di Traduzione Una volta che si ha a disposizione una TM la si utilizza durante il successivo lavoro di traduzione e si continua anche ad arricchirla. Il sistema di CAT infatti utilizza la TM per proporre all’utente possibili traduzioni per la nuove UdiT da tradurre, ma continua anche ad aggiungere tutte le traduzioni nuove che il traduttore introduce nel sistema.

15
Utilizzare una Memoria di Traduzione I sistemi di gestione delle TM usano algoritmi per la ricerca di corrispondenze che si basano su criteri come la somiglianza tra stringhe di caratteri. La percentuale di somiglianza viene impostata dal traduttore. La percezione della somiglianza può però essere differente per il sistema e il traduttore.

16
Utilizzare una Memoria di Traduzione I sistemi di gestione delle TM possono funzionare in due modi alternativi: Interattivo, il testo da tradurre è mostrato suddiviso in UdiT e il traduttore sceglie quale UdiT tradurre, il sistema cerca il match nella TM e produce di conseguenza una proposta di traduzione

17
Utilizzare una Memoria di Traduzione I sistemi di gestione delle TM possono funzionare in due modi alternativi: Automatico, il sistema analizza tutto il testo e per tutte le UdiT cerca il match nella TM e produce di conseguenza una proposta di traduzione

18
Utilizzare una Memoria di Traduzione Un sistema di CAT basato su TM risulta utile perché evita di ripetere la traduzione di frasi già tradotte, ma funziona bene soprattutto se si ha a disposizione una TM di grandi dimensioni.

19
Effetti negativi di una Memoria di Traduzione L’utilizzo di una TM può anche avere conseguenze negative sulla qualità della traduzione: una TM opera generalmente a livello della frase e il pericolo è che il traduttore si concentri troppo su frasi isolate trascurando il contesto in cui esse sono inserite. Limita la ridistribuzione del testo in più frasi.

20
Una nota TM Una reale TM è quella dell’Acquis Communautaire, nota con il nome di DGT-TM (European Commission's Directorate-General for Translation) e accessibile alla pagina http://ipsc.jrc.ec.europa.eu/index.php?id=197 resa disponibile a partire dal 2007 allo scopo di supportare il multilinguismo, la diversità linguistica e il riutilizzo della informazioni della Commissione.
 e accessibile alla pagina id=197 resa disponibile a partire dal 2007 allo scopo di supportare il multilinguismo, la diversità linguistica e il riutilizzo della informazioni della Commissione.")
21
DGT-TM L’Acquis Communautaire è l’intero corpus legislativo della Comunità Europea, comprensivo di trattati regolamenti e direttive. È un corpus parallelo tradotto nelle 23 lingue ufficiali della Comunità rappresentate nelle seguenti sezioni: Bulgarian, Czech, Danish, Dutch, English, Estonian, German, Greek, Finnish, French, Irish, Hungarian, Italian, Latvian, Lithuanian, Maltese, Polish, Portuguese, Romanian, Slovak, Slovene, Spanish e Swedish.

22
DGT-TM I testi paralleli, o bi-testi, sono prodotti manualmente tramite traduzione e raccolti nella DGT-TM in forma di unità di traduzione. DGT-TM è attualmente il più grande corpus parallelo esistente, per la dimensione e per il numero di lingue che comprende. Il suo valore dipende però anche dal fatto che include coppie di lingue rare.

23
DGT-TM La prima release di DGT-TM risale al 2007 e includeva i documenti pubblicati fino al 2006. La seconda release è stata resa pubblica nel 2012 ed include i documenti dal 2007 al 2010. Ogni anno viene rilasciata una nuova release. L’allineamento dei dati è manuale fino al 2007, automatico dopo il 2007. Il formato dei dati è sempre Translation Memory eXchange (TMX).
..")
24
DGT-TM Il numero di unità di traduzione varia da una release all’altra e da una lingua all’altra: 2007: 19.071.485 2011: 379.963.629 2012: 6.226.855 totale: 63.261.969

25
DGT-TM Il numero di unità di traduzione varia tra le diverse lingue. Ad esempio la sezione Irish del corpus, in gaelico, esiste solo nell’ultima release e contiene 2.848 unità di traduzione, mentre la sezione English in inglese contiene 322.377 unità.

Presentazioni simili


>")

>")


>")
>")



>")
>")
: header, navigazione, footer una parte variabile: contenuti.>")




