Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Una Breve Introduzione a EViews
Dipartimento di Economia Politica e Metodi Quantitativi Donatella Baiardi

2
EViews EViews è un pacchetto statistico per Windows usato principalmente nell’analisi econometrica. EViews può essere usato per effettuare analisi statistiche ed econometriche, come ad esempio analisi di dati panel, serie temporali o sezionali. Gretl è un software open source per l’econometria e per l’analisi delle serie storiche e costituisce un’alternativa ad EViews. Infatti, analogamente ad EViews, Gretl dispone di un'interfaccia (tradotta anche in italiano) dotata di menu con il quale aprire i file di dati o selezionare i moduli che si vogliono utilizzare.
 dotata di menu con il quale aprire i file di dati o selezionare i moduli che si vogliono utilizzare.")
3
EViews: la schermata iniziale
L’area blu in alto è la Barra del Titolo (Title Bar) mentre quella grigia chiaro in alto è la barra del Menu Principale (File, Edit, Object, View, Proc, Quick, Options, Window, Help). In seguito si noti la Finestra di Comando (area bianca) e l’Area di Lavoro (spazio in grigio scuro).
 mentre quella grigia chiaro in alto è la barra del Menu Principale (File, Edit, Object, View, Proc, Quick, Options, Window, Help). In seguito si noti la Finestra di Comando (area bianca) e l’Area di Lavoro (spazio in grigio scuro).")
4
Creare un workfile (file di lavoro)
Portare il cursore sulla barra del Menu Principale e seguire questo percorso: File → New → Workfile Comparirà la seguente schermata: Se si ha a che fare con serie storiche, in Date Specification si inserisce la frequenza dei dati (Frequency) e la data di inizio e fine delle serie storiche (Start date e End Date).
 e la data di inizio e fine delle serie storiche (Start date e End Date).")
5
Il risultato è il seguente Workfile (nell’esempio definito per dati annuali dal 1970 al 2010): EViews definisce di default la variabile c (che conterrà i parametri stimati per la costante di regressione) e resid (che conterrà i residui delle regressioni). Nella barra grigia si notino i comandi Save per salvare il Worfile creato e Genr per creare nuove variabili.

6
Caricare un workfile salvato in precedenza
Si deve seguire il seguente percorso: File → Open → EViews Workfile ... e selezionare la cartella in cui vi è il workfile di interesse.

7
Come importare i dati (da foglio Excel o file Lotus)
Si segue il seguente percorso: File → Import → Read Text-Lotus-Excel Si va quindi ad indicare il luogo in cui si trova il file Excel con i dati da importare (tramite un percorso costruito con clic successivi).
.")
8
Come importare i dati (da foglio Excel o file Lotus)
Compare quindi la seguente schermata: Dopo avere selezionato se i dati da importare sono tabulati per riga o colonna (Data order), nel box Upper-left data cell si deve digitare l’indicazione della colonna del foglio Excel in cui si trova il primo dato, nel box Excel 5+ sheet name il nome del foglio excel e nel box Name for series si digita il nome della variabile che comparirà poi nel workfile. Nell box import sample inserire l’intervallo temporale appropriato dei dati.
, nel box Upper-left data cell si deve digitare l’indicazione della colonna del foglio Excel in cui si trova il primo dato, nel box Excel 5+ sheet name il nome del foglio excel e nel box Name for series si digita il nome della variabile che comparirà poi nel workfile. Nell box import sample inserire l’intervallo temporale appropriato dei dati.")
9
Come inserire dati da tastiera per una nuova variabile
Digitare data + nome della nuova variabile nell’area bianca in alto: Ad esempio data pippo + INVIO Comparirà le schermata sotto riportata; dopo avere portato il cursore nel punto desiderato si possono digitare direttamente i dati, chiudendo poi il file La stessa procedura può essere utilizzare per aggiungere o modificare dati da serie preesistenti.

10
Come generare una nuova variabile
Cliccare Genr nel Menu dei comandi del Workfile appena creato. Scrivere nella apposita finestra (area bianca in alto): nome della variabile = contenuto Nell’esempio la variabile è chiamata “pippo” ed è una variabile di soli zero. Alternativamente, scrivere nell’area bianca dei comandi: genr pippo=0
: nome della variabile = contenuto. Nell’esempio la variabile è chiamata pippo ed è una variabile di soli zero. Alternativamente, scrivere nell’area bianca dei comandi: genr pippo=0.")
11
Il comando Genr risulta utile per costruire variabili dummy oppure creare nuove variabili attraverso opportuni comandi, come ad esempio: genr rappdebpil=deb/pil*100, a partire dalle variabili esistenti deb e pil. Si possono poi o generare o utilizzare direttamente variabili derivate da serie esistenti. Es: dlog(.) per la differenza logaritmica di ordine uno della serie – oppure genr vpil=dlog(pil)*100 dlog(.,n,s) per la differenza logaritmica di ordine n con differenza stagionale di ordine s; NB. La variazione tendenziale quadrimestrale del Pil sarà quindi dlog(pil, 0,4) sqrt(.) per la radice quadrata.
 per la differenza logaritmica di ordine uno della serie – oppure genr vpil=dlog(pil)*100. dlog(.,n,s) per la differenza logaritmica di ordine n con differenza stagionale di ordine s; NB. La variazione tendenziale quadrimestrale del Pil sarà quindi dlog(pil, 0,4) sqrt(.) per la radice quadrata.")
12
Come modificare o aggiungere dati ad una serie esistente o l’intervallo dei dati
Per modificare dati di una serie storica esistente nel workfile o aggiungere nuovi dati si può utilizzare il comando data già visto, oppure cliccare sulla serie in esame, portare il cursore sul primo dato da modificare (o aggiungere) e cliccare Edit dal Menu dei Comandi nel workfile. Digitare quindi i nuovi dati. Se si deve estendere l’intervallo del workfile di dati si deve digitare il comando expand nell’area bianca dei comandi, procedendo quindi a modificare inizio e/o fine del campione come desiderato.
 e cliccare Edit dal Menu dei Comandi nel workfile. Digitare quindi i nuovi dati. Se si deve estendere l’intervallo del workfile di dati si deve digitare il comando expand nell’area bianca dei comandi, procedendo quindi a modificare inizio e/o fine del campione come desiderato.")
13
Analisi delle serie storiche

14
Ad esempio, ecco il workfile PIL-AD-NEW.wf
Le serie contrassegnate con il riquadro giallo sono le serie storiche; i riquadri azzurri sono le equazioni salvate. I coefficienti e i gruppi di variabili salvati sono indicati con β e G rispettivamente su sfondo giallo.

15
Serie storiche Per rendere visibili le osservazioni della serie storica di interesse del workfile è necessario cliccare su di essa due volte. Il comando View permette principalmente di: Disegnare grafici; Calcolare statistiche descrittive e relativi test; Effettuare test di radice unitaria, cioè studiare la stazionarietà della serie storica (Augmented Dickey Fuller, Dickey Fuller GLS, Phillips-Perron, KPSS, etc.); Calcolare il correlogramma e la statistica di Ljung-Box (necessaria per definire il numero dei ritardi nei modelli ARMA).
; Calcolare il correlogramma e la statistica di Ljung-Box (necessaria per definire il numero dei ritardi nei modelli ARMA).")
16
Ad esempio, si possono disegnare grafici a linea o a barre, oppure di altro tipo per esaminare l’andamento stagionale (solo per dati ad alta frequenza) IMPORTANTE: Cliccando col tasto destro sull’area del grafico, è possibile definire ulteriori accorgimenti, come cambiare il colore del grafico, lo spessore della linea, rinominare o togliere le etichette e così via.

17
Correlogramma e statistica di Ljung Box
Il percorso è il seguente: View → Correlogram → selezione del “tipo” di correlogramma (di livello e nelle differenze prime o seconde) e del numero di ritardi Ad esempio, l’output per il PIL in livelli con 12 ritardi è:
 e del numero di ritardi. Ad esempio, l’output per il PIL in livelli con 12 ritardi è:")
18
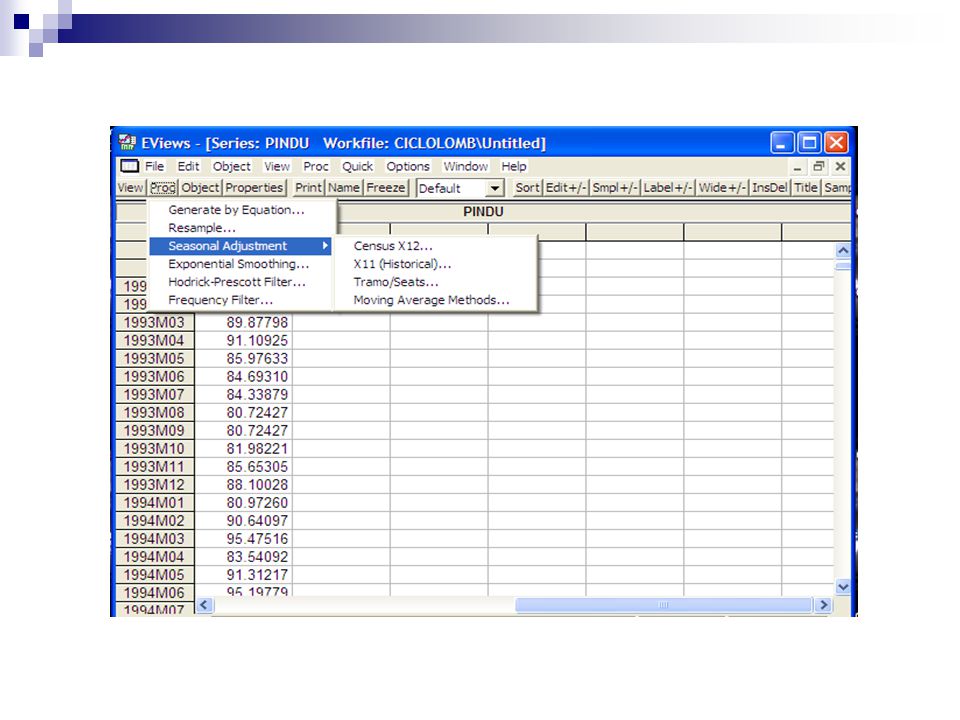
Proc → Seasonal Adjustment → scegliere la tecnica → ok
Stagionalità nei dati In generale conviene caricare serie storiche già destagionalizzate alla fonte (PIL, PIND, ecc.) Se la serie originaria non è destagionalizzata, esistono diverse tecniche per eliminare la stagionalità: ad esempio, EViews propone le metodologie più utilizzate nella pratica empirica, come: Census X12; X11 (Historical); Tramo/Seats (la più comune ora); Moving Average Methods. Il percorso è il seguente: Proc → Seasonal Adjustment → scegliere la tecnica → ok Eviews definisce in default il nome della nuova variabile destagionalizzata come: nome variabile originale_sa
 Se la serie originaria non è destagionalizzata, esistono diverse tecniche per eliminare la stagionalità: ad esempio, EViews propone le metodologie più utilizzate nella pratica empirica, come: Census X12; X11 (Historical); Tramo/Seats (la più comune ora); Moving Average Methods. Il percorso è il seguente: Proc → Seasonal Adjustment → scegliere la tecnica → ok. Eviews definisce in default il nome della nuova variabile destagionalizzata come: nome variabile originale_sa.")
20
L’uso dei filtri EViews permette di filtrare le variabili macroeconomiche definendo il loro andamento ciclico attraverso la rimozioni delle fluttuazioni ad alta frequenza. I filtri che possono essere utilizzati attraverso l’interfaccia grafica sono: il filtro di Hodrick-Prescott; il filtro simmetrico di Baxter-King e di Christiano Fitzgerald; Il filtro asimmetrico di Christiano Fitzgerald.

21
Un esempio: il filtro di Hodrick-Prescott
Dopo avere selezionato la variabile da filtrare, il percorso è il seguente: Proc → Hodrick-Prescott Filter → denominare la serie smoothed e quella della componente ciclica (cycle series) → definire il parametro λ (si consiglia di mantenere il valore di default proposto da EViews) → ok
 → definire il parametro λ (si consiglia di mantenere il valore di default proposto da EViews) → ok.")
22
Ordinary Least Squares (OLS)
È la procedura standard di regressione lineare. Una volta studiate le proprietà delle variabili di interesse, il modello OLS viene stimato da EViews attraverso il seguente iter: Quick (dal Menu Principale) → Estimate Equation → si ottiene la seguente schermata
 → Estimate Equation → si ottiene la seguente schermata.")
23
dove la prima variabile è la dipendente, seguita dalla costante (c), dalle variabili indipendenti e – nell’esempio - da una dummy relativa all’anno Si noti che la variabile qrld06 è ritardata di un periodo (-1). Se si desidera inserire componenti autoregressive o a media mobile si devono usare i seguenti codici ar(1), ar(2), ..., oppure ma(1), ma(2) e così via.
. Se si desidera inserire componenti autoregressive o a media mobile si devono usare i seguenti codici ar(1), ar(2), ..., oppure ma(1), ma(2) e così via..")
24
Il risultato della regressione lineare è:
Si consiglia di porre attenzione ai valori di t-statistic, alla Prob. (p-value), i quali definiscono la significatività dei regressori utilizzati, al valore di R-squared, Adjusted R-squared e della statistica di Durbin-Watson (autocorrelaione degli errori e/o cattiva specificazione della regressione).
, i quali definiscono la significatività dei regressori utilizzati, al valore di R-squared, Adjusted R-squared e della statistica di Durbin-Watson (autocorrelaione degli errori e/o cattiva specificazione della regressione).")
25
Previsione Infine, cliccando il tasto Forecast nella barra grigia dell’equazione è possibile fare previsioni fuori del campione. Compare la seguente schermata, in cui si sceglie il metodo di previsione (statico o dinamico), la natura della variabile dipendente da prevedere (in livelli o nelle differenze logaritmiche), il nome della nuova variabile che viene così generata (Forecast name) e l’intervallo di previsione. NB. E’ ovvio che per prevedere fuori del campione si devono inserire nel dataset i valori delle variabili esogene rilevanti.
, la natura della variabile dipendente da prevedere (in livelli o nelle differenze logaritmiche), il nome della nuova variabile che viene così generata (Forecast name) e l’intervallo di previsione. NB. E’ ovvio che per prevedere fuori del campione si devono inserire nel dataset i valori delle variabili esogene rilevanti.")
26
Ulteriori tecniche

27
L’analisi per componenti principali (cenni teorici)
L’analisi per componenti principali permette di sintetizzare in un numero limitato di variabili, definite componenti principali, l’informazione offerta da numerose serie storiche altamente correlate tra loro. Le componenti principali sono un set di combinazioni lineari delle serie originarie, ordinate in modo tale che la prima componente principale sintetizzi la quota massima possibile della variabilità totale delle serie originarie.

28
Determinazione delle componenti principali (1)
Definita S la matrice di varianza-covarianza delle serie storiche originarie, è necessario risolvere il seguente problema di massimo vincolato: Max {a’Sa} s. al v. a’a = 1 Si deve pertanto individuare il massimo del seguente lagrangiano: Φ(a, λ) = a’Sa – λ(a’a – 1)
 = a’Sa – λ(a’a – 1)")
29
Determinazione delle componenti principali (2)
Dalle condizioni del primo ordine si ottiene la seguente equazione: (S – λI)a = 0 a Є Cn Si tratta quindi di calcolare gli autovalori e gli autovettori associati della matrice di varianza covarianza S: λ1 è l’autovalore massimo della matrice S, mentre a1 è l’autovettore ad esso associato.
a = 0. a Є Cn. Si tratta quindi di calcolare gli autovalori e gli autovettori associati della matrice di varianza covarianza S: λ1 è l’autovalore massimo della matrice S, mentre a1 è l’autovettore ad esso associato.")
30
Determinazione delle componenti principali (3)
Più in generale ogni componente principale è definita come la combinazione lineare delle serie storiche originarie, coi pesi forniti dagli autovettori. Quindi, in termini matriciali, la prima componente principale (determinata in modo tale da estrarre la quota di massima varianza delle serie storiche originarie) viene definita come: y1 = Xa1 dove X rappresenta la matrice dei dati e a1 il primo autovettore associato al primo autovalore. Tutte le altre componenti principali vengono definite in maniera analoga.
 viene definita come: y1 = Xa1. dove X rappresenta la matrice dei dati e a1 il primo autovettore associato al primo autovalore. Tutte le altre componenti principali vengono definite in maniera analoga.")
31
Selezione del numero ottimale di componenti principali
Esistono diversi criteri per selezionare il numero minimo di componenti principali volte a descrivere sinteticamente i dati originari. In genere si procede identificando un limite inferiore q (pari ad esempio al 90%) della quota di varianza spiegata dalla prime r componenti principali - Qr, - scegliendo r in modo tale che Qr≥q. Oppure, si considera il grafico degli autovalori rispetto al numero d’ordine della componente principale (Scree plot) scegliendo l’r in corrispondenza del quale il grafico presenta un “gomito”.
 della quota di varianza spiegata dalla prime r componenti principali - Qr, - scegliendo r in modo tale che Qr≥q. Oppure, si considera il grafico degli autovalori rispetto al numero d’ordine della componente principale (Scree plot) scegliendo l’r in corrispondenza del quale il grafico presenta un gomito .")
32
Applicazioni Dato un set sufficientemente numeroso di serie storiche, è possibile definire quali tra esse presentino un peso significativo nella composizione di ciascuna componente principale, per poi utilizzarle a fini previsivi. Nella studio del ciclo economico, l’analisi per componenti principali permette di stimare il movimento comune e non osservato di numerose serie macroeconomiche, evidenziando le fluttuazioni cicliche.

33
L’analisi per componenti principali con EViews
È necessario creare un gruppo di variabili e calcolare la matrice di covarianza attraverso questo iter: Quick (dal Menu Principale) → Group Statistics → Covariances → digitare il nome delle variabili di interesse → ok Ottenuta la matrice di covarianza si procede con: View → Principal Components
 → Group Statistics → Covariances → digitare il nome delle variabili di interesse → ok. Ottenuta la matrice di covarianza si procede con: View → Principal Components.")
34
Si ottiene questa schermata:
A questo punto si deve solo inserire nel primo riquadro bianco il nome di ciascuna componente principale (si ottiene una matrice dove ogni colonna esibisce la denominazione data) e nelle due aree sottostanti il nome del vettore degli autovettori e degli autovalori.
 e nelle due aree sottostanti il nome del vettore degli autovettori e degli autovalori.")
35
Vector Autoregression (VAR)
La metodologia VAR (Vector Autoregression) è comunemente usata per prevedere sistemi di serie storiche correlate e per analizzare l’impatto dinamico dei disturbi casuali sul sistema di variabili costruito, nonché di prevedere l’evoluzione delle endogene al variare delle esogene. Ciascuna variabile endogena del sistema è trattata come una funzione dei valori ritardati di tutte le variabili endogene del sistema stesso, nonché di possibili variabili esogene (VARX).
 è comunemente usata per prevedere sistemi di serie storiche correlate e per analizzare l’impatto dinamico dei disturbi casuali sul sistema di variabili costruito, nonché di prevedere l’evoluzione delle endogene al variare delle esogene. Ciascuna variabile endogena del sistema è trattata come una funzione dei valori ritardati di tutte le variabili endogene del sistema stesso, nonché di possibili variabili esogene (VARX).")
36
Rappresentazione formale del VAR
La rappresentazione matematica del VAR è: yt = A1yt Apyt-p + Bxt + εt dove yt è il vettore delle variabili endogene (qui con p ritardi), mentre xt è un vettore di variabili esogene correnti e A1, ... , Ap e B sono le matrici dei coefficienti stimati. εt è il vettore degli errori (che dovrebbero essere casuali).
, mentre xt è un vettore di variabili esogene correnti e A1, ... , Ap e B sono le matrici dei coefficienti stimati. εt è il vettore degli errori (che dovrebbero essere casuali).")
37
Creare un VAR con EViews
Per stimare un VAR con EViews si deve seguire il seguente procedimento: Quick (dal Menu Principale) → Estimate VAR → si ottiene la seguente schermata: dove nell’area bianca in alto a destra si inseriscono le variabili endogene, nell’area bianca intermedia a destra si specifica il numero dei ritardi (ad esempio, se si vuole un solo ritardo è necessario digitare 1 1) e nell’area in basso a destra vengono inserite le eventuali variabili esogene (VARX). Nel box a sinistra si indica l’intervallo di stima prescelto.
 → Estimate VAR → si ottiene la seguente schermata: dove nell’area bianca in alto a destra si inseriscono le variabili endogene, nell’area bianca intermedia a destra si specifica il numero dei ritardi (ad esempio, se si vuole un solo ritardo è necessario digitare 1 1) e nell’area in basso a destra vengono inserite le eventuali variabili esogene (VARX). Nel box a sinistra si indica l’intervallo di stima prescelto.")
38
Previsione con i VAR Una volta creato il VAR, e verificata la robustezza dei coefficienti stimati, è possibile procedere con la previsione. Il procedimento è il seguente: Cliccare Proc nella finestra dell’output del VAR → Make Model → Solve → digitare il periodo di previsione di interesse nell’area bianca Solution Sample → ok: la serie storica con la previsione viene automaticamente generata nel workfile come nome serie originaria_0

39
Vector Autoregression (VAR)
Il VAR dipende da tutti i valori passati delle variabili endogene e dai valori correnti (o passati) delle eventuali variabili esogene (VARX). Inoltre, il VAR prevede che si definisca un sistema di equazioni (stimate tutte insieme), dove spetta al ricercatore specificare le variabili di interesse tra loro correlate. Il VAR presenta però il difetto di non considerare le relazioni simultanee tra variabili endogene (solo i valori passati entrano nel modello) e di dover stimare un notevole numero di parametri mantenendo anche i coefficienti non significativi. Un metodo per ovviare a questi inconvenienti è quello di ricorrere ad un modello SUR (Seemengly Unrelated Regression).
 delle eventuali variabili esogene (VARX). Inoltre, il VAR prevede che si definisca un sistema di equazioni (stimate tutte insieme), dove spetta al ricercatore specificare le variabili di interesse tra loro correlate. Il VAR presenta però il difetto di non considerare le relazioni simultanee tra variabili endogene (solo i valori passati entrano nel modello) e di dover stimare un notevole numero di parametri mantenendo anche i coefficienti non significativi. Un metodo per ovviare a questi inconvenienti è quello di ricorrere ad un modello SUR (Seemengly Unrelated Regression).")
40
Seemingly Unrelated Regression (SUR)
Per la costruzione del SUR è necessario seguire il seguente iter: Cliccare Object dal menu Principale → New Object → compare la seguente finestra:

41
... → Selezionare System e indicare il nome del SUR nell’area bianca in alto a destra → scrivere quindi le equazioni nell’area bianca nel formato “scolastico” : y = c(1) + c(2)*x + c(3)*z, ecc., utilizzando una riga per ogni equazione del sistema; terminata la scrittura delle equazioni → cliccare su Estimate → comparirà la seguente finestra: Nel menu a tendina in alto a sinistra scegliere Seemingly Unrelated Regression → ok

42
... Comparirà allora ad esempio la seguente finestra:
A questo punto procedere a migliorare la stima eliminando le variabili non significative (Estimate) (le costanti possono essere lasciate). Terminata la stima si può procedere alla previsione utilizzando la stessa tecnica mostrata in precedenza per la metodologia VAR.
 (le costanti possono essere lasciate). Terminata la stima si può procedere alla previsione utilizzando la stessa tecnica mostrata in precedenza per la metodologia VAR.")
43
Si ricorda che il VAR presuppone che le variabili considerate siano stazionarie e considera solamente le dinamiche di breve periodo, sulla base della struttura dei ritardi delle variabili endogene prescelta. Se si ritiene che tra le variabili endogene ci sia una relazione di lungo periodo (per esempio tra il consumo e il reddito) e che la risposta di breve periodo sia parte di un processo di aggiustamento verso l’equilibrio di lungo periodo, allora conviene usare un VECM (tanto più probabile tanto più “corta” è la serie storica). Nel caso in cui le variabili siano non stazionarie (presenza di radici unitarie) e cointegrate, è necessario ricorrere al Vector Error Correction Model (VECM).
 e cointegrate, è necessario ricorrere al Vector Error Correction Model (VECM).")
44
Vector Error Correction Model (VECM)
Per costruire un modello VECM si usa lo stesso procedimento in precedenza illustrato per stimare un VAR, seguendo quindi la sequenza: Quick (dal Menu Principale) → Estimate VAR → selezionare Vector Error Correction anziché Unresticted VAR. Il termine di cointegrazione è noto come Error Correction term, dato che la deviazione dall’equilibrio di lungo periodo è corretta gradualmente attraverso aggiustamenti parziali di breve periodo delle serie.
 → Estimate VAR → selezionare Vector Error Correction anziché Unresticted VAR. Il termine di cointegrazione è noto come Error Correction term, dato che la deviazione dall’equilibrio di lungo periodo è corretta gradualmente attraverso aggiustamenti parziali di breve periodo delle serie.")
Presentazioni simili

>")



>")








>")


>")

>")