Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
B-Alberi Algoritmi su grafi
Lezione 12 B-Alberi Algoritmi su grafi

2
Sommario B-Alberi Rappresentazione dei grafi Ordinamento topologico
definizione ricerca inserimento Rappresentazione dei grafi Visita in ampiezza Visita in profondità Ordinamento topologico

3
B-Alberi I B-Alberi sono una generalizzazione degli alberi binari di ricerca la principale differenza è che i B-Alberi ogni nodo dell’albero può contenere n>2 chiavi il grado di un nodo è alto ( ) i B-Alberi sono utilizzati per garantire l’efficienza delle operazioni su insiemi dinamici (ricerca, inserzione e cancellazione) di dati memorizzati su supporti secondari (dischi)
 i B-Alberi sono utilizzati per garantire l’efficienza delle operazioni su insiemi dinamici (ricerca, inserzione e cancellazione) di dati memorizzati su supporti secondari (dischi)")
4
Visualizzazione M D H Q T X B C F G J K L N P R S V W Y Z

5
Memorie Secondarie La memoria primaria (RAM) si basa su una tecnologia costosa ma che permette di eseguire le operazioni di scrittura e lettura in modo veloce la memoria secondaria (dischi) è più lenta (vi sono componenti meccaniche da muovere), ma più economica questo permette di rendere disponibile una quantità di memoria secondaria di uno o due ordini di grandezza maggiore della memoria primaria
 si basa su una tecnologia costosa ma che permette di eseguire le operazioni di scrittura e lettura in modo veloce. la memoria secondaria (dischi) è più lenta (vi sono componenti meccaniche da muovere), ma più economica. questo permette di rendere disponibile una quantità di memoria secondaria di uno o due ordini di grandezza maggiore della memoria primaria.")
6
Memorie Secondarie Le informazioni in un disco sono organizzate in blocchi il blocco minimo accessibile in lettura e scrittura è detto pagina una pagina corrisponde a circa 2 MB

7
Accesso alla memoria secondaria
Per trattare quantità estremamente grandi di dati si devono pertanto sviluppare algoritmi che lavorino con dati memorizzati in memoria secondaria si devono pertanto minimizzare gli accessi alla memoria oltre che garantire efficienza computazionale di CPU Le operazioni di accesso ai dati negli algoritmi vengono modificate in: x=puntatore a un dato Disk-Read(x) …operazioni di elaborazione di x Disk-Write(x) …operazioni che accedono a x in sola lettura
 …operazioni di elaborazione di x. Disk-Write(x) …operazioni che accedono a x in sola lettura.")
8
Accesso alla memoria secondaria
Le operazioni di lettura su disco si intendono fatte nel caso in cui il dato puntato da x non sia già disponibile nella memoria primaria le operazioni di scrittura vengono invece eseguite solo se il dato puntato da x è stato in qualche modo modificato

9
B-Alberi In ogni istante è possibile mantenere in memoria primaria solo un numero limitato di pagine le operazioni eseguite su i B-Alberi garantiscono di poter essere eseguite conservando solo un numero costante di pagine in memoria principale (tante più pagine tanto più efficienti saranno le varie operazioni) in genere un nodo di un B-Albero e tanto grande quanto una pagina di memoria secondaria Nota: nel presentare gli algoritmi si trascurerà la gestione di basso livello della memoria
 in genere un nodo di un B-Albero e tanto grande quanto una pagina di memoria secondaria. Nota: nel presentare gli algoritmi si trascurerà la gestione di basso livello della memoria.")
10
B-Alberi Per semplicità si suppone di memorizzare in un nodo solo la chiave dei dati un eventuale puntatore associato alla chiave servirà per indirizzare la pagina del disco su cui trovare i dati satellite

11
Definizione dei B-Alberi
un B-Albero è un albero radicato T che soddisfa le seguenti proprietà: ogni nodo x è caratterizzato dai seguenti attributi: n[x] numero delle chiavi memorizzate in x le n[x] chiavi sono memorizzate in ordine decrescente leaf[x] è true se il nodo è una foglia, false altrimenti un nodo interno x contiene n[x]+1 puntatori c1[x], c2[x],…, cn[x]+1[x] ai suoi figli (o NIL se x è una foglia) i campi keyi[x] definiscono gli intervalli delle chiavi memorizzate in ciascun sottoalbero: se ki è una qualunque chiave memorizzata nel sottoalbero di radice ci[x] allora k1 key1[x] k2 key2[x] … keyn[x][x] kn[x]+1 tutte le foglie sono alla stessa profondità, che coincide con l’altezza dell’albero
 i campi keyi[x] definiscono gli intervalli delle chiavi memorizzate in ciascun sottoalbero: se ki è una qualunque chiave memorizzata nel sottoalbero di radice ci[x] allora. k1 key1[x] k2 key2[x] … keyn[x][x] kn[x]+1. tutte le foglie sono alla stessa profondità, che coincide con l’altezza dell’albero.")
12
Definizione dei B-Alberi
il numero delle chiavi per ogni nodo è limitato sia inferiormente che superiormente in funzione di un intero t chiamato grado minimo del B-Albero t 2 ogni nodo (eccetto la radice) contiene almeno t-1 chiavi ogni nodo interno (eccetto la radice) ha almeno t figli ogni nodo può contenere al massimo 2t-1 chiavi ogni nodo interno può avere al massimo 2t figli un nodo è detto pieno se contiene esattamente 2t-1 chiavi
 contiene almeno t-1 chiavi. ogni nodo interno (eccetto la radice) ha almeno t figli. ogni nodo può contenere al massimo 2t-1 chiavi. ogni nodo interno può avere al massimo 2t figli. un nodo è detto pieno se contiene esattamente 2t-1 chiavi.")
13
Altezza di un B-Albero Un B-Albero con n chiavi e grado minimo t ha una altezza h logt (n+1)/2 Infatti: il caso peggiore è che un B-Albero abbia una radice con un’unica chiave e che tutti i nodi contengano il numero minimo di chiavi, cioè t-1 a profondità 1 ci saranno pertanto 2 nodi, a profondità 2, 2t nodi, a profondità 3, 2t2 nodi. Ogni nodo contiene t-1 chiavi pertanto il numero totale di chiavi n deve essere: n 1 + (t-1)i=1..h 2ti-1= 1+2(t-1)(th-1)/(t-1)=2th-1 ovvero h logt (n+1)/2
i=1..h 2ti-1= 1+2(t-1)(th-1)/(t-1)=2th-1. ovvero h logt (n+1)/2.")
14
Operazioni sui B-Alberi
La radice del B-Albero è sempre in memoria principale non devono pertanto essere effettuate operazioni di Disk-Read per leggere la radice tuttavia se si modifica la radice deve essere eseguita una operazione di Disk-Write si suppone che per tutti i nodi passati come parametro alle varie procedure si sia correttamente compiuta l’operazione di Disk-Read tutte le procedure che vedremo sono a “singola passata” cioè algoritmi che visitano l’albero a partire dalla radice e non risalgono mai indietro

15
Ricerca E’ un operazione simile alla ricerca sugli alberi binari di ricerca la differenza è che non ci sono solo due vie possibili ad ogni nodo, ma n[x]+1 la procedura B-Tree-Search prende in ingresso il puntatore alla radice dell’albero e la chiave da cercare restituisce la coppia ordinata (y,i) che consiste di un puntatore a nodo y e un indice i tale che keyi[y]=k
 che consiste di un puntatore a nodo y e un indice i tale che keyi[y]=k.")
16
Pseudocodice per la Ricerca
B-Tree-Search(x,k) 1 i 1 2 while i n[x] e k > keyi[x] 3 do i i+1 4 if i n[x] e k = keyi[x] 5 then return (x,i) 6 if leaf[x] 7 then return NIL 8 else DISK-READ(ci[x]) 9 return B-Tree-Search(ci[x],k)
 1 i 1. 2 while i n[x] e k > keyi[x] 3 do i i+1. 4 if i n[x] e k = keyi[x] 5 then return (x,i) 6 if leaf[x] 7 then return NIL. 8 else DISK-READ(ci[x]) 9 return B-Tree-Search(ci[x],k)")
17
Spiegazione pseudocodice
Nelle linee 1-3 si esegue una ricerca lineare per trovare il più piccolo indice i tale che k keyi[x] in 4-5 si controlla se la chiave è stata trovata altrimenti 6-9 o siamo in una foglia e la ricerca termina senza successo o procediamo ricorsivamente su un opportuno sottoalbero del nodo in esame che contiene chiavi comprese fra un valore sicuramente più piccolo di k e uno più grande

18
Visualizzazione M D H Q T X B C F G J K L N P R S V W Y Z
Ricerca della chiave R M D H Q T X B C F G J K L N P R S V W Y Z

19
Analisi La ricerca procede dalla radice lungo un cammino verso una foglia il numero di accessi è pertanto O(h)=O(logtn) poiché il numero di chiavi in un nodo è n[x]<2t la ricerca lineare 2-3 impiega per esaminare un qualsiasi nodo un tempo O(t) il tempo complessivo sarà pertanto O(t logtn)
 il tempo complessivo sarà pertanto O(t logtn)")
20
Costruzione di un B-Albero
Per costruire un B-Albero si utilizza una procedura B-Tree-Create per creare un nodo radice vuoto poi si utilizza la procedura B-Tree-Insert per inserire ogni nodo entrambe queste procedure fanno uso di una procedura ausiliaria Allocate-Node() che ha il compito di creare un nuovo nodo e di assegnargli una opportuna pagina del disco in tempo O(1)
 che ha il compito di creare un nuovo nodo e di assegnargli una opportuna pagina del disco in tempo O(1)")
21
Pseudocodice per la costruzione della radice di un B-Albero
B-Tree-Create 1 x Allocate-Node() 2 leaf[x] true 3 n[x] 0 4 Disk-Write(x) 5 root[T] x
 2 leaf[x] true. 3 n[x] 0. 4 Disk-Write(x) 5 root[T] x.")
22
Divisione di un nodo in un B-Albero
L’operazione di inserzione di un nodo è complicata dal fatto che se la nuova chiave deve essere memorizzata in un nodo pieno allora bisogna procedere a dividere questo nodo in due un nodo pieno y con 2t-1 chiavi viene diviso in due nodi di t-1 chiavi all’altezza della chiave mediana keyt[y] la chiave mediana viene spostata nel nodo padre se y è la radice si aumenta l’altezza dell’albero: è infatti questo il meccanismo di crescita dei B-Alberi

23
Visualizzazione keyi-1[x] keyi[x] keyi[x] keyi+1[x] x … N W ….
… N S W …. y=ci[x] P Q R S T U V P Q R T U V y=ci[x] z=ci+1[x]
![Visualizzazione keyi-1[x] keyi[x] keyi[x] keyi+1[x] x … N W ….](http://slideplayer.it/slide/5201314/16/images/23/Visualizzazione+keyi-1%5Bx%5D+keyi%5Bx%5D+keyi%5Bx%5D+keyi%2B1%5Bx%5D+x+%E2%80%A6+N+W+%E2%80%A6..jpg "… N S W …. y=ci[x] P Q R S T U V. P Q R. T U V. y=ci[x] z=ci+1[x]")
24
Idea intuitiva La procedura ha come parametri un nodo interno x non pieno, un indice i e un nodo y pieno. y è il figlio i-esimo di x. In origine y ha 2t-1 chiavi, dopo la divisione rimane con i t-1 chiavi minori un nuovo nodo z acquisisce i t-1 chiavi maggiori e diventa un figlio di x dopo y la chiave mediana di y viene rimossa da y e posta in x e diventa la chiave che separa y da z

25
Divisione di un nodo B-Tree-Split-Child(x,i,y) 1 z Allocate-Node()
2 leaf[z] leaf[y] 3 n[z] t-1 4 for j 1 to t-1 5 do keyj[z] keyj+t[y] 6 if not leaf[y] 7 then for j 1 to t 8 do cj[z] cj+t[y] 9 n[y] t-1 10 for j n[x]+1 downto i+1 11 do cj+1[x] cj[x] 12 cj+1[x] z 13 for j n[x] downto i 14 do keyj+1[x] keyj[x] 15 keyi[x] keyt[y] 16 n[x] n[x]+1 17 Disk-Write(y); Disk-Write(z); Disk-Write(x)
; Disk-Write(z); Disk-Write(x)")
26
Spiegazione dello pseudocodice
Le linee 1-8 creano un nuovo nodo z e gli assegnano le t-1 chiavi più grandi di y, assieme ai figli corrispondenti in si inserisce z come nuovo figlio di x in 15 si inserisce la chiave mediana di y come separatore in 16 si modifica il contatore delle chiavi n[x] in 17 si riporta su disco le modifiche effettuate

27
Analisi Il tempo di esecuzione è dominato dai cicli alle linee 4 o 7 o 10 o 13 che impiegano tutti un tempo limitato superiormente da O(t)
")
28
Inserimento di una nuova chiave
L’inserimento di una nuova chiave può avvenire in due casi: quando il nodo radice è pieno quando il nodo radice non è pieno La procedura B-Tree-Insert inserisce una nuova chiave k in un B-Albero e gestisce il caso in cui si debba inserire la chiave in una radice piena in questo caso si aumenta di 1 l’altezza dell’albero inserendo una nuova radice ci si riporta così al caso di inserimento in un albero con radice non piena che viene trattato dalla procedura B-Tree-Insert-Nonfull

29
Visualizzazione root[T] H s root[T] A D F H L N P A D F L N P r r
![Visualizzazione root[T] H s root[T] A D F H L N P A D F L N P r r](http://slideplayer.it/slide/5201314/16/images/29/Visualizzazione+root%5BT%5D+H+s+root%5BT%5D+A+D+F+H+L+N+P+A+D+F+L+N+P+r+r.jpg "Visualizzazione root[T] H s root[T] A D F H L N P A D F L N P r r")
30
Pseudocodice per l’inserimento di una nuova chiave
B-Tree-Insert(T,k) 1 r root[T] 2 if n[r] = 2t-1 3 then s Allocate-Node() 4 root[T] s 5 leaf[s] false 6 n[s] 0 7 c1[s] 0 8 B-Tree-Split-Child(s,1,r) 9 B-Tree-Insert-NonFull(s,k) 10 else B-Tree-Insert-NonFull(r,k)
 1 r root[T] 2 if n[r] = 2t-1. 3 then s Allocate-Node() 4 root[T] s. 5 leaf[s] false. 6 n[s] 0. 7 c1[s] 0. 8 B-Tree-Split-Child(s,1,r) 9 B-Tree-Insert-NonFull(s,k) 10 else B-Tree-Insert-NonFull(r,k)")
31
Inserimento in nodo non pieno
La procedura è organizzata in modo tale da essere chiamata sempre solo su nodi non pieni la procedura distingue il caso in cui si debba inserire la nuova chiave in un nodo foglia o si debba scendere ricorsivamente in un nodo interno per un nodo foglia si deve gestire la collocazione della chiave nella giusta posizione e aggiornare il numero di chiavi per un nodo interno si deve verificare che questo non sia pieno per poter applicare ricorsivamente la B-Tree-Insert-Nonfull nel caso in cui sia un nodo pieno si richiama la procedura B-Tree-Split-Child

32
Pseudocodice per l’inserimento
B-Tree-Insert-Nonfull(x,k) 1 i n[x] 2 if leaf[x] 3 then while i1 e k<keyi[x] 4 do keyi+1[x] keyi[x] 5 i i-1 6 keyi+1[x] k 7 n[x] n[x]+1 8 Disk-Write(x) 9 else while i1 e k<keyi[x] 10 do i i -1 11 i i+1 12 Disk-Read(ci[x]) 13 if n[ci[x]]=2t-1 14 then B-Tree-Split-Child(x,i,ci[x]) 15 if k > keyi[x] 16 then i i+1 17 B-Tree-Insert-Nonfull(ci[x],k)
 1 i n[x] 2 if leaf[x] 3 then while i1 e k<keyi[x] 4 do keyi+1[x] keyi[x] 5 i i-1. 6 keyi+1[x] k. 7 n[x] n[x]+1. 8 Disk-Write(x) 9 else while i1 e k<keyi[x] 10 do i i i i Disk-Read(ci[x]) 13 if n[ci[x]]=2t then B-Tree-Split-Child(x,i,ci[x]) 15 if k > keyi[x] 16 then i i B-Tree-Insert-Nonfull(ci[x],k)")
33
Spiegazione pseudocodice
In 3-8 ci si occupa del caso di inserimento della chiave nel nodo foglia: si determina la posizione della chiave facendole contemporaneamente posto in 9-17 si considera il caso in cui si debba scendere ricorsivamente attraverso nodi interni in 9-11 si determina quale figlio esaminare in 13 se il figlio è pieno si divide e in si determina per quale dei due nuovi sotto figli si debba proseguire in 17 si procede ricorsivamente su un nodo figlio sicuramente non pieno fino a raggiungere una foglia

34
Visualizzazione inserzione della chiave B in B-Albero con t=3
G M P X A C D E J K N O R S T U V Y Z G M P X A B C D E J K N O R S T U V Y Z

35
Visualizzazione inserzione della chiave Q
G M P X A B C D E J K N O R S T U V Y Z G M P T X A B C D E J K N O Q R S U V Y Z

36
Visualizzazione inserzione della chiave L
G M P T X A B C D E J K N O Q R S U V Y Z P G M T X A B C D E L J K N O Q R S U V Y Z

37
Visualizzazione inserzione della chiave F
P G M T X A B C D E L J K N O Q R S U V Y Z P C G M T X A B D E F L J K N O Q R S U V Y Z

38
Analisi Per un B-Albero di altezza h la procedura B-Tree-Insert effettua O(h) accessi al disco infatti: questa richiama la procedura B-Tree-Insert-Nonfull ricorsivamente su un numero di nodi al più numeroso come il massimo cammino fino ad una foglia (h) inoltre la procedura B-Tree-Insert-Nonfull esegue un numero O(1) di operazioni di lettura-scrittura
 inoltre la procedura B-Tree-Insert-Nonfull esegue un numero O(1) di operazioni di lettura-scrittura.")
39
Analisi per il tempo di computazione di CPU si ha che B-Tree-Insert-Nonfull ha un ciclo O(t) (linea 3 o 9) inoltre richiama una volta la procedura B-Tree-Split-Child che costa O(t) dato che B-Tree-Insert-Nonfull viene chiamata ricorsivamente al più O(h) volte si ha complessivamente un costo O(th)=O(t logtn)
 dato che B-Tree-Insert-Nonfull viene chiamata ricorsivamente al più O(h) volte si ha complessivamente un costo O(th)=O(t logtn)")
40
Grafi I grafi sono strutture dati molto diffuse in informatica
Vengono utilizzati per rappresentare reti e organizzazioni dati complesse e articolate Per elaborare i grafi in genere è necessario visitarne in modo ordinato i vertici Vedremo a questo proposito due modi fondamentali di visita: per ampiezza e per profondità

41
Nota sulla notazione asintotica
Il tempo di esecuzione di un algoritmo su un grafo G=(V,E) viene dato in funzione del numero di vertici |V| e del numero di archi |E| Utilizzando la notazione asintotica adotteremo la convenzione di rappresentare |V| con il simbolo V e |E| con E: quando diremo che il tempo di calcolo è O(E+V) vorremo significare O(|E|+|V|)
 viene dato in funzione del numero di vertici |V| e del numero di archi |E| Utilizzando la notazione asintotica adotteremo la convenzione di rappresentare |V| con il simbolo V e |E| con E: quando diremo che il tempo di calcolo è O(E+V) vorremo significare O(|E|+|V|)")
42
Rappresentazione di un grafo
Vi sono due modi per rappresentare un grafo: collezione di liste di adiacenza matrice di adiacenza si preferisce la rappresentazione tramite liste di adiacenza quando il grafo è sparso, cioè con |E| molto minore di |V|2 si preferisce la rappresentazione tramite matrice di adiacenza quando, al contrario, il grafo è denso o quando occorre alta efficienza nel rilevare se vi è un arco fra due vertici dati

43
Liste di adiacenza Si rappresenta un grafo G=(V,E) con un vettore Adj di liste, una lista per ogni vertice del grafo per ogni vertice u, Adj[u] contiene tutti i vertici v adiacenti a u, ovvero quei vertici v tali per cui esiste un arco (u,v)E in particolare questo insieme di vertici è memorizzato come una lista l’ordine dei vertici nella lista è arbitrario
E. in particolare questo insieme di vertici è memorizzato come una lista. l’ordine dei vertici nella lista è arbitrario.")
44
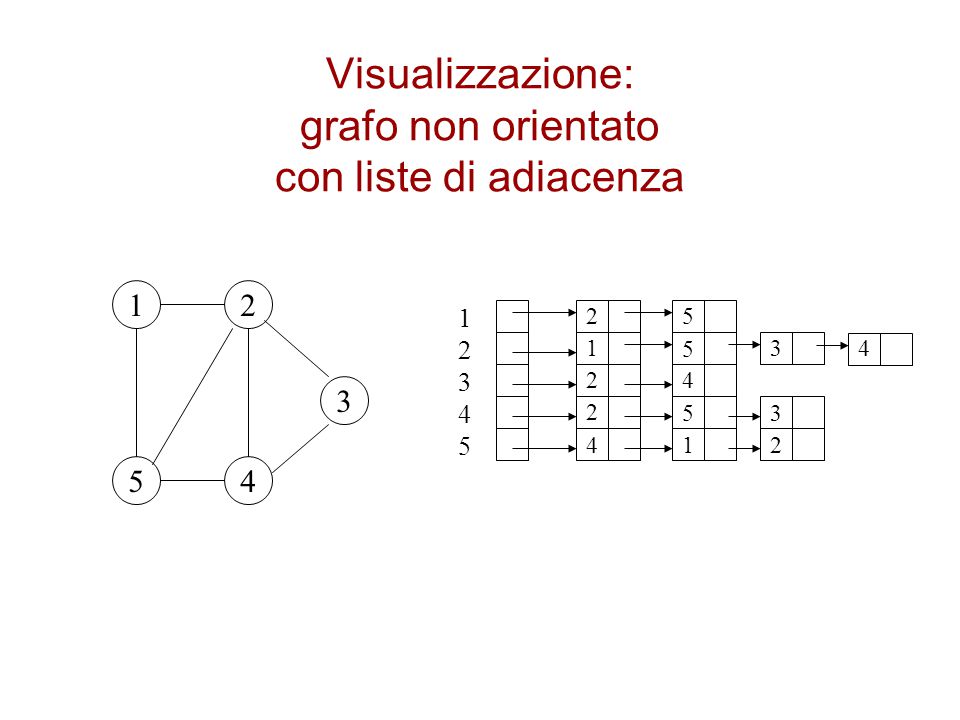
Visualizzazione: grafo non orientato con liste di adiacenza
1 2 1 2 3 4 5 2 5 1 5 3 4 2 4 3 2 5 3 4 1 2 5 4
45
Visualizzazione: grafo orientato con liste di adiacenza
1 2 1 2 3 4 5 6 2 4 5 6 5 3 2 4 4 5 6 6

46
Proprietà della rappresentazione con liste di adiacenza
Se un grafo è orientato allora la somma delle lunghezze di tutte le liste di adiacenza è |E| infatti per ogni arco (u,v) c’è un vertice v nella lista di posizione u Se un grafo non è orientato allora la somma delle lunghezze di tutte le liste di adiacenza è 2|E| infatti per ogni arco (u,v) c’è un vertice v nella lista di posizione u e un vertice u nella lista di posizione v La quantità di memoria necessaria per memorizzare un grafo (orientato o non) è O(max(V,E)) = O(V+E)
 c’è un vertice v nella lista di posizione u. Se un grafo non è orientato allora la somma delle lunghezze di tutte le liste di adiacenza è 2|E| infatti per ogni arco (u,v) c’è un vertice v nella lista di posizione u e un vertice u nella lista di posizione v. La quantità di memoria necessaria per memorizzare un grafo (orientato o non) è O(max(V,E)) = O(V+E)")
47
Grafi pesati In alcuni problemi si vuole poter associare una informazione (chiamata peso) ad ogni arco un grafo con archi con peso si dice grafo pesato si dice che esiste una funzione peso che associa ad un arco un valore w : E R ovvero un arco (u,v) ha peso w(u,v)
 ha peso w(u,v)")
48
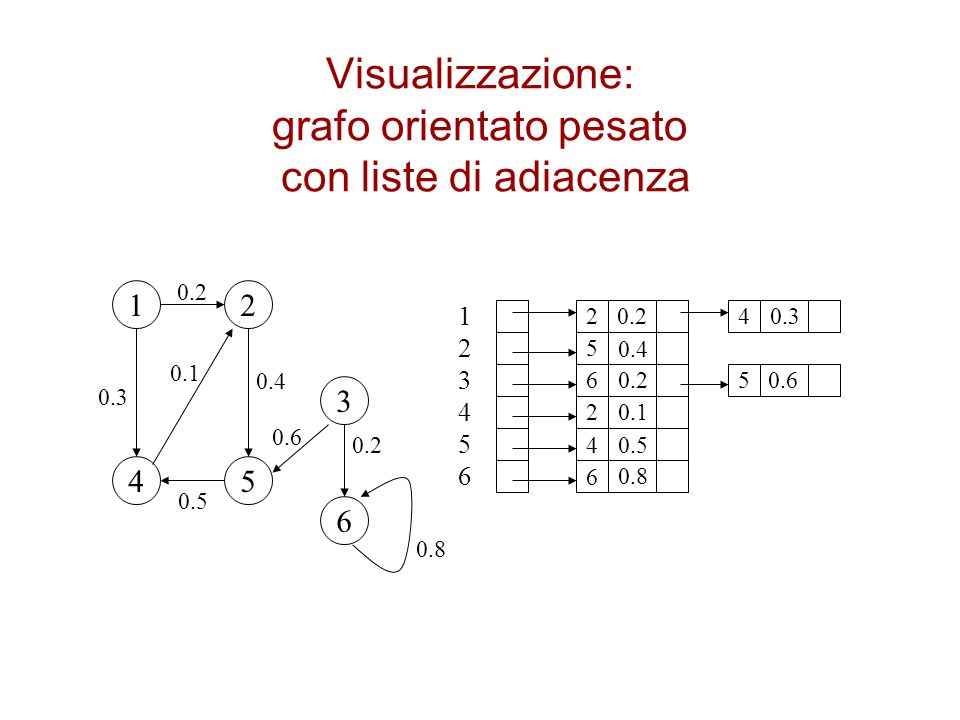
Grafi pesati con liste di adiacenza
Si memorizza il peso w(u,v) insieme al vertice v nella lista per il vertice u
 insieme al vertice v nella lista per il vertice u.")
49
Visualizzazione: grafo orientato pesato con liste di adiacenza
0.2 1 2 1 2 3 4 5 6 2 0.2 4 0.3 5 0.4 0.1 0.4 6 0.2 5 0.6 0.3 3 2 0.1 0.6 0.2 4 0.5 4 5 6 0.8 0.5 6 0.8
50
Svantaggi della rappresentazione con liste di adiacenza
Per sapere se un arco (u,v) è presente nel grafo si deve scandire la lista degli archi di u
 è presente nel grafo si deve scandire la lista degli archi di u.")
51
Matrici di adiacenza Per la rappresentazione con matrici di adiacenza si assume che i vertici siano numerati in sequenza da 1 a |V| Si rappresenta un grafo G=(V,E) con una matrice A=(aij) di dimensione |V|x|V| tale che: aij=1 se (i,j) E aij=0 altrimenti
 con una matrice A=(aij) di dimensione |V|x|V| tale che: aij=1 se (i,j) E. aij=0 altrimenti.")
52
Visualizzazione: grafo non orientato con matrice di adiacenza
1 2 3 5 4

53
Visualizzazione: grafo orientato
1 2 3 4 5 6

54
Proprietà della rappresentazione con matrice di adiacenza
La rappresentazione di un grafo G=(V,E) con matrice di adiacenza richiede memoria (V2) indipendentemente dal numero di archi La matrice di adiacenza di un grafo non orientato è simmetrica ovvero aij= aji Per un grafo non orientato si può allora memorizzare solo i dati sopra la diagonale (diagonale inclusa), riducendo della metà lo spazio per memorizzare la matrice
 con matrice di adiacenza richiede memoria (V2) indipendentemente dal numero di archi. La matrice di adiacenza di un grafo non orientato è simmetrica ovvero aij= aji. Per un grafo non orientato si può allora memorizzare solo i dati sopra la diagonale (diagonale inclusa), riducendo della metà lo spazio per memorizzare la matrice.")
55
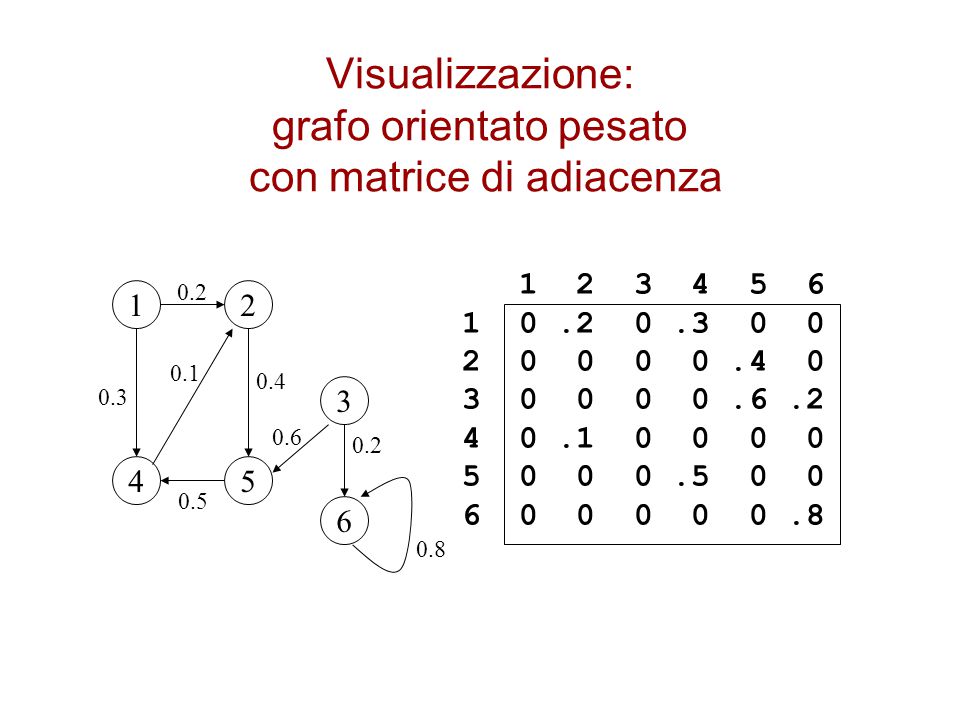
Grafi pesati con matrici di adiacenza
Si memorizza il peso nell’elemento aij invece di 1 se l’arco non esiste si indica con 0 o o NIL a secondo del problema

56
Visualizzazione: grafo orientato pesato con matrice di adiacenza
0.2 1 2 0.1 0.4 0.3 3 0.6 0.2 4 5 0.5 6 0.8
57
Vantaggi della rappresentazione con matrice di adiacenza
la rappresentazione con matrice di adiacenza è semplice se il grafo è piccolo non vi è sostanziale differenza di efficienza con la rappresentazione con liste di adiacenza per grafi non pesati si può rappresentare ogni singolo elemento della matrice non con una parola ma con un singolo bit

58
Visita in ampiezza La visita in ampiezza (breadth-first-search BFS) di un grafo dato un vertice sorgente s consiste nella esplorazione sistematica di tutti i vertici raggiungibili da s in modo tale da esplorare tutti i vertici che hanno distanza k prima di iniziare a scoprire quelli che hanno distanza k+1 inoltre la procedura di visita in ampiezza che vedremo: calcola la distanza da s ad ognuno dei vertici raggiungibili produce un albero BFS che ha s come radice e che comprende tutti i vertici raggiungibili da s
 di un grafo dato un vertice sorgente s consiste nella esplorazione sistematica di tutti i vertici raggiungibili da s in modo tale da esplorare tutti i vertici che hanno distanza k prima di iniziare a scoprire quelli che hanno distanza k+1. inoltre la procedura di visita in ampiezza che vedremo: calcola la distanza da s ad ognuno dei vertici raggiungibili. produce un albero BFS che ha s come radice e che comprende tutti i vertici raggiungibili da s.")
59
Idea intuitiva L’idea è quella di tenere traccia dello stato (già scoperto, appena scoperto, ancora da scoprire) di ogni vertice, “colorandolo” di un colore diverso i colori possibili sono: bianco: vertice ancora non scoperto grigio: vertice appena scoperto ed appartenente alla frontiera nero: vertice per cui si è terminata la visita un vertice da bianco diventa grigio e poi nero se (u,v) E ed u è un vertice nero, allora il vertice v è grigio, ovvero tutti i vertici adiacenti ad un vertice nero sono già stati scoperti
 di ogni vertice, colorandolo di un colore diverso. i colori possibili sono: bianco: vertice ancora non scoperto. grigio: vertice appena scoperto ed appartenente alla frontiera. nero: vertice per cui si è terminata la visita. un vertice da bianco diventa grigio e poi nero. se (u,v) E ed u è un vertice nero, allora il vertice v è grigio, ovvero tutti i vertici adiacenti ad un vertice nero sono già stati scoperti.")
60
Visualizzazione

61
Idea intuitiva La visita in ampiezza costruisce un albero BFT
la radice è il nodo sorgente s quando un vertice bianco v viene scoperto durante la scansione della lista di adiacenza di un vertice già scoperto u allora si aggiunge all’albero il vertice v e l’arco (u,v) si dice che u è padre di v poiché un vertice viene scoperto al massimo una volta ha al massimo un padre
 si dice che u è padre di v. poiché un vertice viene scoperto al massimo una volta ha al massimo un padre.")
62
Strutture ausiliarie La procedura di visita in ampiezza assume che il grafo G=(V,E) sia rappresentato usando liste di adiacenza ad ogni vertice u sono associati inoltre l’attributo colore: color[u] padre: [u] la distanza dalla sorgente s: d[u] L’algoritmo fa anche uso di una coda Q per gestire l’insieme dei vertici grigi

63
Pseudocodice BFS(G,s) 1 for ogni vertice u V[G]-{s}
2 do color[u] WHITE 3 d[u] 4 [u] NIL 5 color[s] GRAY 6 d[s] 0 7 [s] NIL 8 Q {s} 9 while Q 10 do u head[Q] 11 for ogni v Adj[u] 12 do if color[v]=WHITE 13 then color[v] GRAY 14 d[v] d[u]+1 15 [v] u 16 Enqueue(Q,v) 17 Dequeue(Q) 18 color[u] BLACK
![Pseudocodice BFS(G,s) 1 for ogni vertice u V[G]-{s}](http://slideplayer.it/slide/5201314/16/images/63/Pseudocodice+BFS%28G%2Cs%29+1+for+ogni+vertice+u+%EF%83%8E+V%5BG%5D-%7Bs%7D.jpg "2 do color[u] WHITE. 3 d[u] 4 [u] NIL. 5 color[s] GRAY. 6 d[s] 0. 7 [s] NIL. 8 Q {s} 9 while Q 10 do u head[Q] 11 for ogni v Adj[u] 12 do if color[v]=WHITE. 13 then color[v] GRAY. 14 d[v] d[u] [v] u. 16 Enqueue(Q,v) 17 Dequeue(Q) 18 color[u] BLACK.")
64
Spiegazione del codice
Le linee 1-4 eseguono l’inizializzazione: tutti i vertici sono colorati di bianco la distanza di tutti i vertici è non nota e posta a il padre di ogni vertice inizializzato a nil la linea 5 inizializza la sorgente a cui: viene assegnato il colore grigio viene assegnata distanza 0 viene assegnato padre nullo nil la linea 8 inizializza la coda Q con il vertice sorgente s

65
Spiegazione del codice
Il ciclo principale è contenuto nelle linee 9-18 il ciclo continua fino a quando vi sono vertici grigi in Q, ovvero vertici già scoperti le cui liste di adiacenza non siano state ancora completamente esaminate la linea 10 preleva l’elemento in testa alla coda nelle linee si esaminano tutti i vertici v adiacenti a u se v non è ancora stato scoperto lo si scopre si colora di grigio si aggiorna la sua distanza alla distanza di u +1 si memorizza u come suo predecesore si pone in fondo alla coda quando tutti i vertici adiacenti a u sono stati scoperti allora si colora u di nero e lo si rimuove da Q

66
Visualizzazione 1 Q:s Q:wr 1 1 2 1 2 Q:rtx Q:txv 1 2 2 1 2 r s t u r s
Q:s Q:wr 1 v w x y v w x y r s t u r s t u 1 2 1 2 Q:rtx Q:txv 1 2 2 1 2 v w x y v w x y

67
Visualizzazione 1 2 3 1 2 3 Q:xvu Q:vuy 2 1 2 2 1 2 3 1 2 3 1 2 3 Q:uy
r s t u r s t u 1 2 3 1 2 3 Q:xvu Q:vuy 2 1 2 2 1 2 3 v w x y v w x y r s t u r s t u 1 2 3 1 2 3 Q:uy Q:y 2 1 2 3 2 1 2 3 v w x y v w x y

68
Analisi Il tempo per l’inizializzazione è O(V)
Dopo l’inizializzazione nessun vertice sarà mai colorato più di bianco quindi il test in 12 assicura che ogni vertice sarà inserito nella coda Q al più una volta le operazioni di inserimento ed eliminazione dalla coda richiedono un tempo O(1) il tempo dedicato alla coda nel ciclo 9-18 sarà pertanto un O(V)
 il tempo dedicato alla coda nel ciclo 9-18 sarà pertanto un O(V)")
69
Analisi poiché la lista di adiacenza è scandita solo quando si estrae il vertice dalla coda allora la si scandisce solo 1 volta per vertice poiché il numero di archi è pari a |E| allora la somma delle lunghezze di tutte le liste è (E) allora il tempo speso per la scansione delle liste complessivamente è O(E) in totale si ha un tempo di O(V+E) quindi la procedura di visita in ampiezza richiede un tempo lineare nella rappresentazione con liste di adiacenza
 allora il tempo speso per la scansione delle liste complessivamente è O(E) in totale si ha un tempo di O(V+E) quindi la procedura di visita in ampiezza richiede un tempo lineare nella rappresentazione con liste di adiacenza.")
70
Alberi BFS La procedura BFS costruisce un albero BFS durante la visita del grafo l’informazione sull’albero è contenuta nei puntatori al padre formalmente, dato G=(V,E) con sorgente s si definisce il sottografo dei predecessori di G come G=(V,E) dove: V ={v V : [v] NIL} {s} E={([v],v) E : v V -{s}}
 con sorgente s si definisce il sottografo dei predecessori di G come G=(V,E) dove: V ={v V : [v] NIL} {s} E={([v],v) E : v V -{s}}")
71
Alberi BFS G è un albero BFS se
V contiene tutti e soli i vertici raggiungibili da s e se per ogni v V vi è un unico cammino semplice da s a v in G che è anche un cammino minimo da s a v in G. Un albero BFS è effettivamente un albero perché è connesso e |E|=|V|-1 si dimostra che dopo aver eseguito la procedura BFS a partire da una sorgente s, il sottografo dei predecessori è effettivamente un albero BFS

72
Visualizzazione dell’albero BFS
t u 1 2 3 r 2 1 2 3 1 1 v w x y w 2 2 2 x t v 3 3 u y

73
Visita in profondità La visita in profondità (depth-first-search DFS) di un grafo consiste nella esplorazione sistematica di tutti i vertici andando in ogni istante il più possibile in profondità gli archi vengono esplorati a partire dall’ultimo vertice scoperto v che abbia ancora archi non esplorati uscenti quando questi sono finiti si torna indietro per esplorare gli altri archi uscenti dal vertice dal quale v era stato scoperto
 di un grafo consiste nella esplorazione sistematica di tutti i vertici andando in ogni istante il più possibile in profondità. gli archi vengono esplorati a partire dall’ultimo vertice scoperto v che abbia ancora archi non esplorati uscenti. quando questi sono finiti si torna indietro per esplorare gli altri archi uscenti dal vertice dal quale v era stato scoperto.")
74
Visita in profondità Il procedimento continua fino a quando non vengono scoperti tutti i vertici raggiungibili dal vertice sorgente originario se al termine rimane qualche vertice non scoperto uno di questi diventa una nuova sorgente e si ripete la ricerca a partire da esso questo fino a scoprire tutti i vertici

75
Visita in profondità A differenza che nella visita per ampiezza il cui sottografo dei predecessori formava un albero, nel caso della visita in profondità si forma una foresta di diversi alberi DFS infatti si hanno più sorgenti (radici)
")
76
Visualizzazione

77
Idea intuitiva Come per la visita in ampiezza i vertici vengono colorati per tenere conto dello stato di visita: ogni vertice è inizialmente bianco è grigio quando viene scoperto viene reso nero quando la visita è finita, cioè quando la sua lista di adiacenza è stata completamente esaminata

78
Marcatura temporale Oltre al colore si associa ad ogni vertice v due informazioni temporali: tempo di inizio visita d[v], cioè quando è reso grigio per la prima volta tempo di fine visita f[v], cioè quando è reso nero il valore temporale è dato dall’ordine assoluto con cui si colorano i vari vertici del grafo si usa per questo una variabile globale tempo che viene incrementata di uno ogni volta che si esegue un inizio di visita o una fine visita

79
Marcatura temporale il tempo è un intero compreso fra 1 e 2|V| poiché ogni vertice può essere scoperto una sola volta e la sua visita può finire una sola volta per ogni vertice u si ha sempre che d[u]<f[u] ogni vertice u è WHITE prima di d[u] GRAY fra d[u] e f[u] BLACK dopo f[u]

80
Utilità della marcatura temporale
La marcatura temporale è usata in molti algoritmi sui grafi E’ utile in generale per ragionare sul comportamento della visita in profondità

81
Pseudocodice DFS(G) 1 for ogni vertice u V[G] 2 do color[u] WHITE
3 [u] NIL 4 time 0 5 for ogni vertice u V[G] 6 do if color[u]=WHITE 7 then DFS-Visit(u) DFS-Visit(u) 1 color[u] GRAY 2 d[u] time time +1 3 for ogni v Adj[u] 4 do if color[v]=WHITE 5 then [v] u 6 DFS-Visit(v) 7 color[u] BLACK 8 f[u] time time +1
![Pseudocodice DFS(G) 1 for ogni vertice u V[G] 2 do color[u] WHITE](http://slideplayer.it/slide/5201314/16/images/81/Pseudocodice+DFS%28G%29+1+for+ogni+vertice+u+%EF%83%8E+V%5BG%5D+2+do+color%5Bu%5D+%EF%82%AC+WHITE.jpg "3 [u] NIL. 4 time 0. 5 for ogni vertice u V[G] 6 do if color[u]=WHITE. 7 then DFS-Visit(u) DFS-Visit(u) 1 color[u] GRAY. 2 d[u] time time for ogni v Adj[u] 4 do if color[v]=WHITE. 5 then [v] u. 6 DFS-Visit(v) 7 color[u] BLACK. 8 f[u] time time +1.")
82
Spiegazione dello pseudocodice
Le righe 1-4 della procedura DFS eseguono la fase di inizializzazione colorando ogni vertice del grafo di bianco, settando il padre a NIL e impostandola variabile globale time a 0 il ciclo 5-7 esegue la procedura DFS-Visit su ogni nodo non ancora scoperto del grafo, creando un albero DFS ogni volta che viene invocata la procedura

83
Spiegazione dello pseudocodice
In ogni chiamata DFS-Visit(u) il vertice u è inizialmente bianco viene reso grigio e viene marcato il suo tempo di inizio visita in d[u], dopo aver incrementato il contatore temporale globale time vengono poi esaminati tutti gli archi uscenti da u e viene invocata ricorsivamente la procedura nel caso in cui i vertici collegati non siano ancora stati esplorati in questo caso il loro padre viene inizializzato ad u dopo aver visitato tutti gli archi uscenti u viene colorato BLACK e viene registrato il tempo di fine visita in f[u]
 il vertice u è inizialmente bianco. viene reso grigio e viene marcato il suo tempo di inizio visita in d[u], dopo aver incrementato il contatore temporale globale time. vengono poi esaminati tutti gli archi uscenti da u e viene invocata ricorsivamente la procedura nel caso in cui i vertici collegati non siano ancora stati esplorati. in questo caso il loro padre viene inizializzato ad u. dopo aver visitato tutti gli archi uscenti u viene colorato BLACK e viene registrato il tempo di fine visita in f[u]")
84
Visualizzazione u u u v w v w v w x x y z x y z y z u v w u v w u v w
1/ 1/ 2/ 1/ 2/ 3/ x x y z x y z y z u v w u v w u v w 1/ 2/ 1/ 2/ 1/ 2/ 4/ 3/ 4/5 3/ 4/5 3/6 x y z x y z x y z

85
Visualizzazione u v w u v w u v w x y z x y z x y z u v w u v w u v w
1/ 2/7 1/8 2/7 1/8 2/7 9/ 4/5 3/6 4/5 3/6 4/5 3/6 x y z x y z x y z u v w u v w u v w 1/8 2/7 9/ 1/8 2/7 9/ 1/8 2/7 9/12 4/5 3/6 10/ 4/5 3/6 10/11 4/5 3/6 10/11 x y z x y z x y z

86
Analisi del tempo di calcolo
Il ciclo di inizializzazione di DFS e il ciclo for 5-7 richiedono entrambi tempo (V) la procedura DFS-Visit viene chiamata solo una volta per ogni vertice (poiché viene chiamata quando il vertice è bianco e lo colora immediatamente di grigio) in DFS-Visit il ciclo for 3-6 viene eseguito |Adj[v]| volte, e dato che la somma della lunghezza di tutte le liste di adiacenza è (E), il costo è (E) il tempo totale è quindi un (V+E)
 la procedura DFS-Visit viene chiamata solo una volta per ogni vertice (poiché viene chiamata quando il vertice è bianco e lo colora immediatamente di grigio) in DFS-Visit il ciclo for 3-6 viene eseguito |Adj[v]| volte, e dato che la somma della lunghezza di tutte le liste di adiacenza è (E), il costo è (E) il tempo totale è quindi un (V+E)")
87
Ordinamento topologico
L’ordinamento topologico è un ordinamento definito su i vertici di un grafo orientato aciclico (directed acyclic graph DAG) si può pensare all’ordinamento topologico come ad un modo per ordinare i vertici di un DAG lungo una linea orizzontale in modo che tutti gli archi orientati vadano da sinistra verso destra
 si può pensare all’ordinamento topologico come ad un modo per ordinare i vertici di un DAG lungo una linea orizzontale in modo che tutti gli archi orientati vadano da sinistra verso destra.")
88
Ordinamento topologico
I grafi aciclici diretti sono utilizzati per modellare precedenze fra eventi consideriamo ad esempio le precedenze nelle operazioni del vestirsi utilizzando un DAG i cui nodi siano indumenti certi indumenti vanno messi prima di altri (i calzini prima delle scarpe) mentre altri indumenti possono essere indossati in qualsiasi ordine (calzini e pantaloni) un arco orientato (u,v) indica che l’indumento u deve essere indossato prima dell’indumento v l’ordinamento topologico del DAG fornirà dunque un ordine per vestirsi
 mentre altri indumenti possono essere indossati in qualsiasi ordine (calzini e pantaloni) un arco orientato (u,v) indica che l’indumento u deve essere indossato prima dell’indumento v. l’ordinamento topologico del DAG fornirà dunque un ordine per vestirsi.")
89
Visualizzazione calzini pantaloni orologio scarpe camicia cintura
cravatta giacca orologio 15/16 11/14 9/10 12/13 1/8 6/7 2/5 3/4

90
Visualizzazione 15/16 11/14 12/13 9/10 1/8 6/7 2/5 3/4 calzini
pantaloni scarpe orologio camicia cintura cravatta giacca 15/16 11/14 12/13 9/10 1/8 6/7 2/5 3/4

91
Pseudocodice Topological-Sort(G)
1 chiama DFS(G) per calcolare f[v] per ogni v 2 appena la visita di un vertice è finita inseriscilo in testa ad una lista 3 return la lista concatenata dei vertici
 per calcolare f[v] per ogni v. 2 appena la visita di un vertice è finita inseriscilo in testa ad una lista. 3 return la lista concatenata dei vertici.")
92
Analisi Si esegue un ordinamento topologico in tempo O(V+E) dato che:
la visita DFS richiede un tempo O(V+E) l’inserimento di ognuno dei |V| vertici richiede ciascuno un tempo O(1)
 l’inserimento di ognuno dei |V| vertici richiede ciascuno un tempo O(1)")
Presentazioni simili





>")



>")









