Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Focused Crawler Arlind Kopliku Dicembre 2006

2
Riferimenti Focused Crawling: A new approach to Topic-Specific Resource Discovery - Soumen Chakrabarti, Martin van den Berg, Byron Dom, IBM Almaden Reasearch Center Mining the web - Morgan Kauffman Focused Crawling using context graphs – M.Diligenti, F.M Coetzze, S.Lawrence http://www.Netcraft.org - Web surveyswww.Netcraft.org

3
Il focused crawler Il focused crawler è un gestionale dellinformazione ipertestuale. Esso cerca solo le pagine rilevanti a un certo insieme di argomenti. Invece di raccogliere tutte le pagine ipertestuali accessibili, per essere capace a rispondere a tutte le queries possibili, il focused cralwer analizza il suo confine cercando i link più rilevanti per lui. Evita cosi regioni inutili del web.

4
General-purpose crawler vs focused crawler Non è molto costoso Basta un PC Deve ricoprire una picola percentuale del web laggionamento è più veloce Non è dispersivo Da risposte solo dentro il dominio di ricerca Propone soluzioni a base di persona, campo di ricerca, argomenti, etc È costoso hw, risorse rete richiede enorme copertura del web aggiornamento lento E dispersivo Le risposte ottenute alle query sono spesso fuori dal dominio del qualle noi siammo interessati E una soluzione one-size fits all Focused crawlerGeneral-purpose crawler

5
La crescita del www NetcraftNetcraft's latest Web survey found 101,435,253 websites in November 2006

6
1991-1997: Explosive growth, at a rate of 850% per year. 1998-2001: Rapid growth, at a rate of 150% per year. 2002-2006: Maturing growth, at a rate of 25% per year. Solo nel mese di novembre sono state aggiunti 3.5 milioni di nuovi siti. Il numero di pagine attuali del web si aggirà sulla decina di miliardi. Ci possiamo aspetare 200 milioni di siti per il 2010.

7
Statistiche sulle ricerche sui motori di ricerca piu famosi 6,40213Total 1666Others 37813Ask 48616AOL 84528MSN 1,79260Yahoo 2,73391Google Per Month (Millions)Per Day (Millions)Searches
Per Day (Millions)Searches")
8
Copertuara attuale web dai motori di ricerca : 30%-40% Laggiornamento dura da una settimana a mesi. Le risposte alle query sono spesso dispersive

9
Introduzione al focused crawler E un crawler a priorità Focalizzato su un insieme di argomenti (topic) Espande il suo dominio di ricerca solo a partire da pagine rilevanti Ha un sistema di valutazione di rilevanza e autorità E più difficile del general-purpose crawling
 Espande il suo dominio di ricerca solo a partire da pagine rilevanti Ha un sistema di valutazione di rilevanza e autorità E più difficile del general-purpose crawling")
10
Focused Crawler URL seed Frontiera: i nodi rilevanti con link ancora inesplorati Composto da Crawler Rating system (Sistema di valutazione) Classificatore ipertestuale Il crawler fa i seguenti passi: Trova la pagina con priorità massima t.c sia rilevante Recupera le pagine linkate ad essa Classifica le pagine recuperate Valuta la loro rilevanza ed autorevolezza Ripete dal primo passo Fetch Il focused crawler ha le seguenti modalità operazionali: Imparare da esempi: nella fase iniziale. Scoprire risorse: grandi quantità in tempi rapidi, mantenendo alta rilevanza al topic. Ricognizionamento: identificare le pagine che portano al più possibile di pagine rilevanti. Mantenimento: verificare il materiale già recuperato.

11
Focused Crawler Administration Il focused crawler necessita dellintervento umano in 2 forme: –Costruzione di tassonomie basilari dei più importanti topic –Indicazione da parte dellutente delle categorie (e relative sottocategorie) in cui è interessato Le tassonomie sono strutturate in un master category tree e forniscono una base sulla quale lutente mappa i propri interessi. Perché mappare i topic su una gerarchia di categorie fissate? –Per poter riutilizzare il classifier-training: produrre lalbero una volta sola; utilizzare la nuova, ampia conoscenza come espansione del set di traning. –Per migliorare il modello di classe negativa gli esempi negativi sono fonte di informazione. –Per scoprire classi correlate che inizialmente non erano naturalmente correlate.

13
Focused Crawler Administration Il primo passo consiste nel mappare i topic in una serie di nodi allinterno del master category tree. Il classificatore dirotta i documenti al miglior nodo associato nellalbero delle categorie. Lamministratore può comunque fornire feedback in tre modi: –Correggendo classificazioni –Eliminando classi –Raffinando classi A questo punto può essere lanciato il crawler.

14
System Architecture La rilevanza è calcolata usando un hypertext classificator, assumendo che la tassonomia imponga una partizione gerarchica dei documenti R(d) = Σ good(c) Pr[c|d] La tabella del documento ha 2 campi inerenti alla tassonomia: –Relevance settata a R(d) –cid rappresenta il nodo che meglio associa al documento Yamaha d riguardante Vale Rossi radice tortemoto Ducati 1 0,80,1 0,860,3
![System Architecture La rilevanza è calcolata usando un hypertext classificator, assumendo che la tassonomia imponga una partizione gerarchica dei documenti R(d) = Σ good(c) Pr[c|d] La tabella del documento ha 2 campi inerenti alla tassonomia: –Relevance settata a R(d) –cid rappresenta il nodo che meglio associa al documento Yamaha d riguardante Vale Rossi radice tortemoto Ducati 1 0,80,1 0,860,3](http://images.slideplayer.it/1/571774/slides/slide_14.jpg "System Architecture La rilevanza è calcolata usando un hypertext classificator, assumendo che la tassonomia imponga una partizione gerarchica dei documenti R(d) = Σ good(c) Pr[c|d] La tabella del documento ha 2 campi inerenti alla tassonomia: –Relevance settata a R(d) –cid rappresenta il nodo che meglio associa al documento Yamaha d riguardante Vale Rossi radice tortemoto Ducati 1 0,80,1 0,860,3")
15
La relevanza di un documento Il documento è visto come bag of words

16
System Architecture Oltre alla rilevanza, si calcola il popularity rating sulla base dellalgoritmo di HITS, generando un mutuo rinforzo sulla base: a[v] = Σ (u,v) E h[u] h[u] = Σ (u,v) E a[v] Un diverso algoritmo prevede di considerare anche la rilevanza: 1. Si seleziona una soglia di rilevanza; 2. Attraverso delle iterazioni si calcola a[v] come R[u]/h[u,v] e h[u] come R[u]/a[u,v]; 4. Cambieremo il valore di autorevolezza solo a quelle pagine che superano il valore R[x] > ;
![System Architecture Oltre alla rilevanza, si calcola il popularity rating sulla base dellalgoritmo di HITS, generando un mutuo rinforzo sulla base: a[v] = Σ (u,v) E h[u] h[u] = Σ (u,v) E a[v] Un diverso algoritmo prevede di considerare anche la rilevanza: 1.](http://images.slideplayer.it/1/571774/slides/slide_16.jpg "Si seleziona una soglia di rilevanza; 2. Attraverso delle iterazioni si calcola a[v] come R[u]/h[u,v] e h[u] come R[u]/a[u,v]; 4. Cambieremo il valore di autorevolezza solo a quelle pagine che superano il valore R[x] > ;.")
17
HITS: authority score e hub score Per il calcolo di a[v] u1 u2 u3 v Per il calcolo di h[u] v1 v2 v3 u Il valore di hub di u è dato dalla somma dei valori di autorevolezza dei v puntati da u. Una pagina u è tanto più un buon hub quanto più punta a pagine autorevoli. Il valore di autorevolezza di v è dato dalla somma dei valori di hub degli u che puntanto a v. Una pagina v è tanto più autorevole quanto più è puntata da buoni hub.
![HITS: authority score e hub score Per il calcolo di a[v] u1 u2 u3 v Per il calcolo di h[u] v1 v2 v3 u Il valore di hub di u è dato dalla somma dei valori di autorevolezza dei v puntati da u.](http://images.slideplayer.it/1/571774/slides/slide_17.jpg "Una pagina u è tanto più un buon hub quanto più punta a pagine autorevoli. Il valore di autorevolezza di v è dato dalla somma dei valori di hub degli u che puntanto a v. Una pagina v è tanto più autorevole quanto più è puntata da buoni hub..")
18
Crawling Strategies Due tipologie di focused crawling: –Hard crawling Il problema di questo metodo è la possibilità di perdere informazioni sensibili riguardo il topic in questione (crawl stagnation: fallendo nellacquisizione di pagine rilevanti addizionali) –Soft crawling Questo metodo pecca del problema inverso, ovvero il rischio di una quantità di informazioni non eccessivamente in co-relazione con il topic in esame (crawl diffusion: accumulando troppo poche pagine rilevanti)
 –Soft crawling Questo metodo pecca del problema inverso, ovvero il rischio di una quantità di informazioni non eccessivamente in co-relazione con il topic in esame (crawl diffusion: accumulando troppo poche pagine rilevanti)")
19
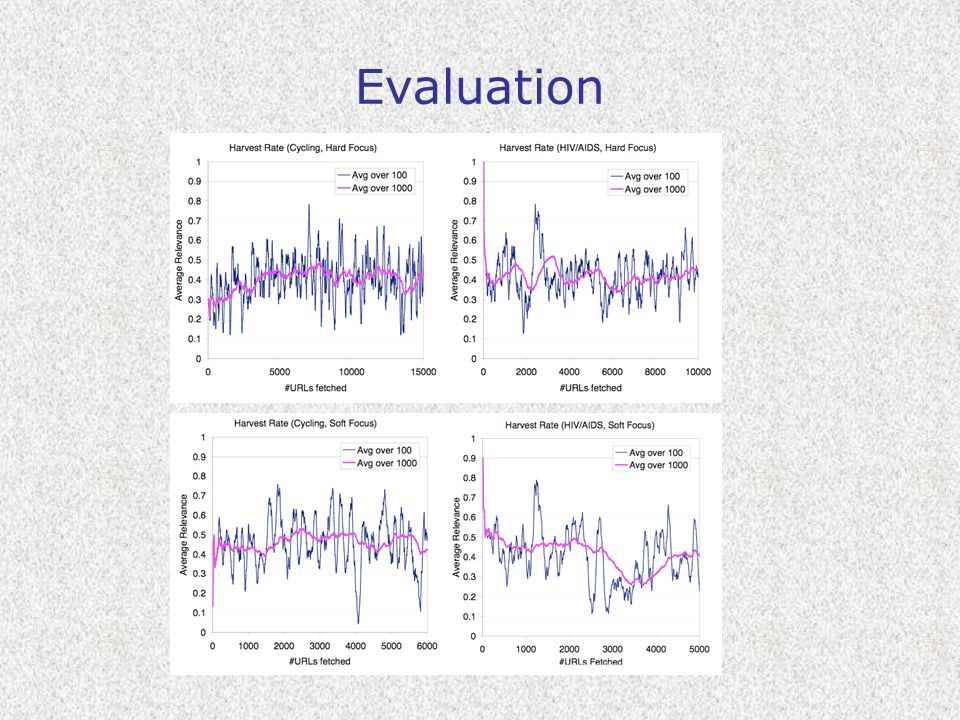
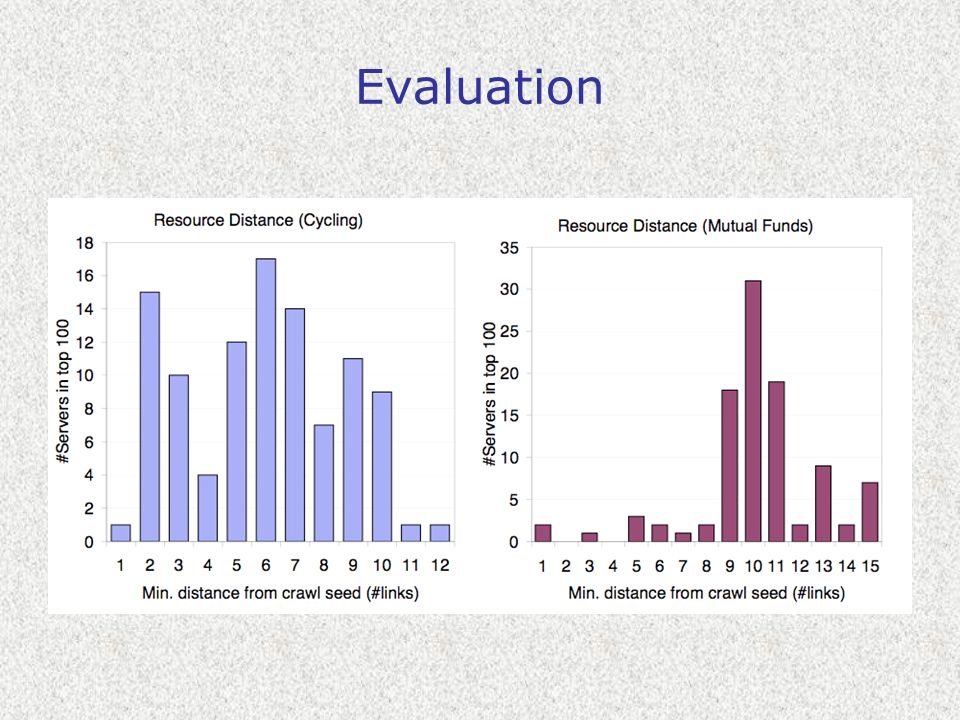
Evaluation Ci sono fondamentalmente 4 misure per valutare le performance di un crawler: –Relevance (precision) –Coverage (recall) spesso difficilmente calcolabile –Refresh rate spesso difficilmente calcolabile –Quality
 –Coverage (recall) spesso difficilmente calcolabile –Refresh rate spesso difficilmente calcolabile –Quality")
20
Evaluation

Presentazioni simili








, Ministero degli Affari Esteri. Documenti e decisioni della.>")
>")








>")


