Riunione gruppo storage – Roma 05/05/2005 Test di affidabilita’ e performance a Genova Alessandro Brunengo
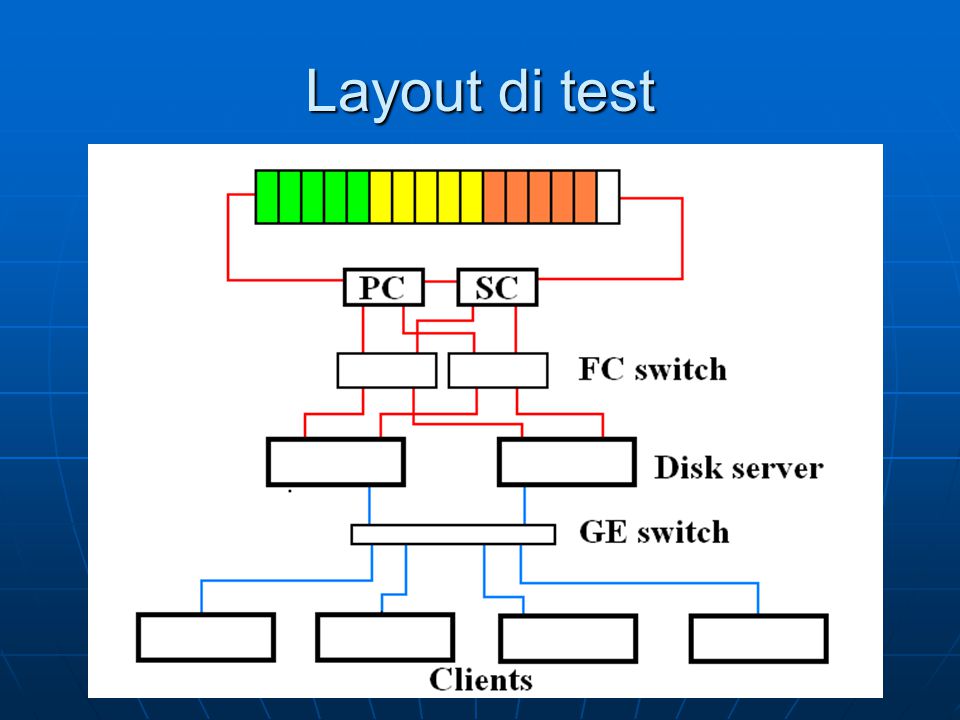
Layout di test
Controller Infortrend Eonstore A16F-R1112 doppio controller FC to SATA alimentazione e ventilazione ridondata 256 MB di cache 16 HD SATA da 250 GB tre volumi in RAID 5 da 1 TB
Layout di test Due switch Emulex 355 (ex Vixel InSpeed 355)
Layout di test Disk server dual Xeon 2.8 e 3.0 GHz, 2 GB di RAM HBA Qlogic QLA3212 dual head SLC3
Layout di test Switch Extreme Networks (48 porte GE)
Layout di test 4 client dual Xeon 3.2 GHz, SLC3
Layout di test
Ridondanza sul controller Ciascun volume viene esportato come LUN da un solo controller, eventualmente su entrambi i canali Ciascun volume viene esportato come LUN da un solo controller, eventualmente su entrambi i canali In caso di guasto ad un controller, il controller operativo si presenta sul loop con entrambi gli indirizzi, simulando la presenza dell’altro controller, ed esporta i volumi originariamente associati al controller off-line In caso di guasto ad un controller, il controller operativo si presenta sul loop con entrambi gli indirizzi, simulando la presenza dell’altro controller, ed esporta i volumi originariamente associati al controller off-line
Ridondanza sulle HBA dual head Se un volume e’ visibile da entrambe le porte, l’HBA lo riconosce: Se un volume e’ visibile da entrambe le porte, l’HBA lo riconosce: se non e’ operativo il failover, uno dei due cammini verso il volume viene automaticamente disattivato e puo’ essere attivato manualmente in caso di failure dell’altro camminose non e’ operativo il failover, uno dei due cammini verso il volume viene automaticamente disattivato e puo’ essere attivato manualmente in caso di failure dell’altro cammino se il failover e’ operativo, uno dei due cammini viene disattivato ed attivato automaticamente in caso di failure del primo camminose il failover e’ operativo, uno dei due cammini viene disattivato ed attivato automaticamente in caso di failure del primo cammino con il failover operativo e’ possibile configurare il cammino preferenziale a livello di singola LUN (load balancing)con il failover operativo e’ possibile configurare il cammino preferenziale a livello di singola LUN (load balancing) Il driver inserito nel kernel della SLC3 contiene il codice per la gestione del failover, ma deve essere esplicitamente attivato Il driver inserito nel kernel della SLC3 contiene il codice per la gestione del failover, ma deve essere esplicitamente attivato La configurazione dell’HBA puo’ essere fatta editando un file di testo, ma non e’ documentato; esiste un pacchetto software (SANsurfer) scaricabile gratuitamente che fornisce una GUI per la configurazione La configurazione dell’HBA puo’ essere fatta editando un file di testo, ma non e’ documentato; esiste un pacchetto software (SANsurfer) scaricabile gratuitamente che fornisce una GUI per la configurazione
GPFS GPFS e’ stato configurato in modalita’ “tiebreaker disk”, con i due disk server definiti come “quorum node” GPFS e’ stato configurato in modalita’ “tiebreaker disk”, con i due disk server definiti come “quorum node” I test sono stati fatti in diverse configurazioni, utilizzando un file system costituito da I test sono stati fatti in diverse configurazioni, utilizzando un file system costituito da un solo NSDun solo NSD due NSD esportati da un solo disk serverdue NSD esportati da un solo disk server due NSD esportati ciascuno da un diverso disk server; in questo caso ciascun server ha funzioni di backup per l’esportazione dell’NSD dell’altro serverdue NSD esportati ciascuno da un diverso disk server; in questo caso ciascun server ha funzioni di backup per l’esportazione dell’NSD dell’altro server
Test di failover E’ stata testata l’operativita’ del sistema in presenza dei diversi eventi: E’ stata testata l’operativita’ del sistema in presenza dei diversi eventi: failure di un HDfailure di un HD failure del controller FC (primario e secondario)failure del controller FC (primario e secondario) failure di uno switchfailure di uno switch failure di un disk server (in configurazione con 2 NSD esportate e server di backup configurato)failure di un disk server (in configurazione con 2 NSD esportate e server di backup configurato) In tutti i casi il test e’ stato fatto in condizioni di I/O sul disco, che non si e’ interrotto In tutti i casi il test e’ stato fatto in condizioni di I/O sul disco, che non si e’ interrotto le operazioni di I/O si arrestano per tempi diversi a seconda del tipo di failure e quindi del meccanismo di recovery coinvolto, comunque inferiore al minuto, e poi riprendonole operazioni di I/O si arrestano per tempi diversi a seconda del tipo di failure e quindi del meccanismo di recovery coinvolto, comunque inferiore al minuto, e poi riprendono
Layout test di affidabilita’
Failure del controller
Failure dello switch
Failure del disk server
Prestazioni Sono stati fatti test di prestazioni utilizzando lmdd (un front-end per dd), per scrivere e rileggere file di 4 GB, in diverse configurazioni Sono stati fatti test di prestazioni utilizzando lmdd (un front-end per dd), per scrivere e rileggere file di 4 GB, in diverse configurazioni I/O operata direttamente dai server, per mettere in relazione ext3 con GPFS (1 server e due server)I/O operata direttamente dai server, per mettere in relazione ext3 con GPFS (1 server e due server) I/O concomitanti operate da 1, 2 e 4 client, anche con piu’ processi per client, per mettere in relazione NFS/ext3, NFS/GPFS e GPFS nativoI/O concomitanti operate da 1, 2 e 4 client, anche con piu’ processi per client, per mettere in relazione NFS/ext3, NFS/GPFS e GPFS nativo
Problemi Sono stati sostituiti i due banchi di RAM da 512 MB (partita difettosa, problema noto ad Infortrend) Sono stati sostituiti i due banchi di RAM da 512 MB (partita difettosa, problema noto ad Infortrend) Fibra difettosa (identificazione difficile per via delle ridondanze che si attivavano automaticamente) Fibra difettosa (identificazione difficile per via delle ridondanze che si attivavano automaticamente) Un HBA (su 3) ha rotto l’NVRAM: sostituita Un HBA (su 3) ha rotto l’NVRAM: sostituita Un disco si e’ rotto: sostituito Un disco si e’ rotto: sostituito In occasione di I/O intensivo e prolungato, i controller si congelavano dopo uno/due giorni: dopo alcune prove effettuate dalla manutenzione Infortrend ha sostituito i controller In occasione di I/O intensivo e prolungato, i controller si congelavano dopo uno/due giorni: dopo alcune prove effettuate dalla manutenzione Infortrend ha sostituito i controller Infortrend ha inviato uno dei due controller con Board Revision ID vecchia (1 anziche’ 2) e su questa non si possono utilizzare i banchi da 512 MB di RAM, quindi i test conclusivi presentati sono stati fatti con 256 MB di cache totali; invieranno un controller sostitutivoInfortrend ha inviato uno dei due controller con Board Revision ID vecchia (1 anziche’ 2) e su questa non si possono utilizzare i banchi da 512 MB di RAM, quindi i test conclusivi presentati sono stati fatti con 256 MB di cache totali; invieranno un controller sostitutivo
Problemi seri Il protocollo Fiber Channel Il protocollo Fiber Channel formalmente il protocollo prevede che un oggetto possa essere attaccato alla SAN e tutto va bene, maformalmente il protocollo prevede che un oggetto possa essere attaccato alla SAN e tutto va bene, ma i manuali dei vendor suggeriscono o esplicitamente supportano solo configurazioni dei parametri operazionali della HBA ben definite, non necessariamente compatibili i manuali dei vendor suggeriscono o esplicitamente supportano solo configurazioni dei parametri operazionali della HBA ben definite, non necessariamente compatibili il tentativo di connettere un controller Fiber Channel diverso (StorageTeK) sugli stessi switch e’ fallito (problema non ancora indagato a fondo) il tentativo di connettere un controller Fiber Channel diverso (StorageTeK) sugli stessi switch e’ fallito (problema non ancora indagato a fondo) Il driver degli HBA per linux (qla2300.o) Il driver degli HBA per linux (qla2300.o) in occasione di uno spegnimento brutale del disk server durante operazioni di I/O ha portato il sistema in condizioni di instabilita’ (kernel panic piu’ che occasionale) al caricamento del driver; il problema deve ancora essere indagatoin occasione di uno spegnimento brutale del disk server durante operazioni di I/O ha portato il sistema in condizioni di instabilita’ (kernel panic piu’ che occasionale) al caricamento del driver; il problema deve ancora essere indagato