Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Docente: Dr. Stefania Bortoluzzi Dipartimento di Biologia Universita' di Padova viale G. Colombo 3, 35131, Padova Tel. 0039 049 8276214 Email: stefibo@bio.unipd.it Corso di Laurea in Biotecnologie Sanitarie Universita' di Padova Corso di Bioinformatica 16 ore

2
Utilizzare Database per recuperare informazioni biomediche Utilizzare specifici programmi per analizzare le informazioni disponibili nei database, per avvantaggiarsi nel disegno e nella programmazione dellattivita sperimentale Utilizzare metodologie e programmi per analizzare sequenze e navigare genomi completi Bioinformatica - OBIETTIVI

3
http://telethon.bio.unipd.it/bioinfo/AA2006-2007/HomeBioinformatica.html Home page del corso

4
I LEZIONE Database primari e Database secondari Database di sequenze nucleotidiche e proteiche GenBank SWISSPROT ENTREZ Information retrieval system

5
INTRODUZIONE ALLUTILIZZO DI DATABASE Struttura e organizzazione di database I database sono insiemi di dati memorizzati su un computer con diversi livelli di astrazione al di sopra di essi; ogni livello di astrazione consente di organizzare i dati contenuti e di accedervi. Database diversi organizzano i dati in modi differenti database Flat-File il tipo piu semplice di database database relazionali (Oracle, mySQl) permettono la composizione di interrogazioni o query che collegano piu' tabelle, stabilendo delle "relazioni" tra i contenuti delle singole tabelle. database Object Oriented, le informazioni sono gestite come "oggetti" con varie "proprieta'", invece che records con campi. Tutti i sistemi di database impiegano delle interfacce (API, Application Programming Interface) per accedere ai dati e modificarli
 permettono la composizione di interrogazioni o query che collegano piu tabelle, stabilendo delle relazioni tra i contenuti delle singole tabelle. database Object Oriented, le informazioni sono gestite come oggetti con varie proprieta , invece che records con campi. Tutti i sistemi di database impiegano delle interfacce (API, Application Programming Interface) per accedere ai dati e modificarli.")
6
INTRODUZIONE ALLUTILIZZO DI DATABASE Database flat-file Il tipo piu' semplice di database e' il database flat-file, formato da files di testo ASCII in formato standard che il programa esamina per cercare informazioni. Il formato e' di solito costituito da un insieme di campi, contenenti ciascuno una specifica categoria di informazioni, delimitati attraverso caratteri speciali o con lunghezza fissa assegnata. Il pregio principale dei database flat-file e' la semplicita' di gestione, controbilanciata pero' dallincapacita' di gestire accesso concorrente e dalla mancanza di indicizzazione dei dati, che non consentono interrogazioni sequenziali.

7
LEVELS OF PROTEIN SEQUENCE AND STRUCTURAL ORGANISATION PRIMARY sequence primary database SECONDARY motif secondary database TERTIARY domain module secondary database DATABASE PRIMARI E DATABASE SECONDARI ORGANIZZANO RISPETTIVAMENTE DATI ORIGINALI E CONOSCENZA GENERATA A PARTIRE DA ANALISI DI DATI O INTEGRAZIONE DI DATI DIVERSI

8
DATABASE PRIMARI DATABASE DI SEQUENZE NUCLEOTIDICHE Collezioni di singoli record, ognuno dei quali contiene un tratto di DNA o RNA con delle annotazioni. Ogni record viene anche chiamato ENTRY, e ha un codice che lo identifica univocamente (ACCESSION NUMBER). Le tre principali banche dati primarie di sequenze nucleotidiche sono: EMBL nucleotide database, ora gestita dallEBI (1980) EMBL = European Molecular Biology Laboratory (Heidelberg) EBI = European Bioinformatics Institute (Hinxton, UK) GenBank = banca dell NIH gestita dal NCBI (1982) NIH = National Institutes of Health (Stuttura USA) NCBI = National Center for Biotechnology Information, Bethesda, Maryland DDBJ = banca DNA giapponese (1986) DDBJ = DNA DataBase of Japan SCAMBIO DI DATI Nel 1988, i gruppi responsabili dei 3 database si sono organizzati nellInternational Collaboration of DNA Sequence Databases per utilizzare un formato comune e scambiarsi giornalmente le sequenze.
. Le tre principali banche dati primarie di sequenze nucleotidiche sono: EMBL nucleotide database, ora gestita dallEBI (1980) EMBL = European Molecular Biology Laboratory (Heidelberg) EBI = European Bioinformatics Institute (Hinxton, UK) GenBank = banca dell NIH gestita dal NCBI (1982) NIH = National Institutes of Health (Stuttura USA) NCBI = National Center for Biotechnology Information, Bethesda, Maryland DDBJ = banca DNA giapponese (1986) DDBJ = DNA DataBase of Japan SCAMBIO DI DATI Nel 1988, i gruppi responsabili dei 3 database si sono organizzati nellInternational Collaboration of DNA Sequence Databases per utilizzare un formato comune e scambiarsi giornalmente le sequenze..")
9
DATABASE DI SEQUENZE NUCLEOTIDICHE GenBank SUBMISSION DIRETTA La gran parte delle sequenze finisce in uno dei tre database perché lautore (il laboratorio dove tale sequenza é stata ottenuta) la invia direttamente. La sequenza viene quindi inserita e il record corrispondente resta di proprietà solo di quel database, lunico con il diritto di modificarlo. Il database che riceve la sequenza la invia poi agli altri due. Circa il 98% delle sequenze in un database sono presenti anche negli altri due. ANNOTAZIONE Ci sono poi anche degli annotatori che prendono le sequenze dalle riviste scientifiche e le trasferiscono nel database. Problema della ridondanza

10
DATABASE DI SEQUENZE NUCLEOTIDICHE – GenBank

11
DATABASE DI SEQUENZE NUCLEOTIDICHE GenBank contiene diverse sezioni in passato divise per gruppi tassonomici e strategie di sequenziamento ora tre grandi sezioni : EST, GSS e CoreNucleotide dbEST database pubblico di "Expressed Sequence Tags" (sequenze espresse contrassegnate), contiene tutte le sequenze ottenute dal sequenziamento parziale o totale di cloni di cDNA, molto utili per: Identificare nuovi geni Studiare la struttura esoni/introni di geni Studiare lespressione genica
, contiene tutte le sequenze ottenute dal sequenziamento parziale o totale di cloni di cDNA, molto utili per: Identificare nuovi geni Studiare la struttura esoni/introni di geni Studiare lespressione genica")
12
Come e fatta unentry di GenBank ? http://www.ncbi.nlm.nih.gov/Sitemap/samplerecord.html

15
DATABASE PRIMARI DATABASE DI SEQUENZE PROTEICHE SWISS-PROT Database di sequenze proteiche annotate, scarsamente ridondanti e cross-referenced Contiene TrEMBL, supplemento a SWISS-PROT costituito dalle sequenze annotate al computer, come traduzione di tutte le sequenze codificanti presenti allEMBL TrEMBL contiene due sezioni: SP-TrEMBL, sequenze da incorporare in SWISSPROT, con AC. REM-TrEMBL, remaining (immunoglobuline, proteine sintetiche,...), senza AC. TrEMBLnew, generato ogni settimana.
, senza AC. TrEMBLnew, generato ogni settimana..")
16
DATABASE SECONDARI UniProt (Universal Protein Resource) Il piu grande catalogo di informazioni sulle proteine. Contiene informazioni sulla sequenza e sulla funzione di proteine ed e ottenuto dallinsieme delle informazioni contenute in Swiss-Prot, TrEMBL e PIR. UniProt ha 3 componenti: UniProt Knowledgebase (UniProt) the central access point for extensive curated protein information, including function, classification, and cross-reference. UniProt Non-redundant Reference (UniRef) databases combine closely related sequences into a single record to speed searches. UniProt Archive (UniParc) is a comprehensive repository, reflecting the history of all protein sequences.
 the central access point for extensive curated protein information, including function, classification, and cross-reference. UniProt Non-redundant Reference (UniRef) databases combine closely related sequences into a single record to speed searches. UniProt Archive (UniParc) is a comprehensive repository, reflecting the history of all protein sequences..")
17
UniProt (Universal Protein Resource) UniProt Knowledgebase, due parti: Records annotati manualmente, informazioni dalla letteratura (UniProtKB/Swiss-Prot) Records risultato di analisi computazionali, in attesa di annotazione completa (UniProtKB/TrEMBL). http://www.expasy.uniprot.org/index.shtml http://www.expasy.uniprot.org/search/tools.shtml

19
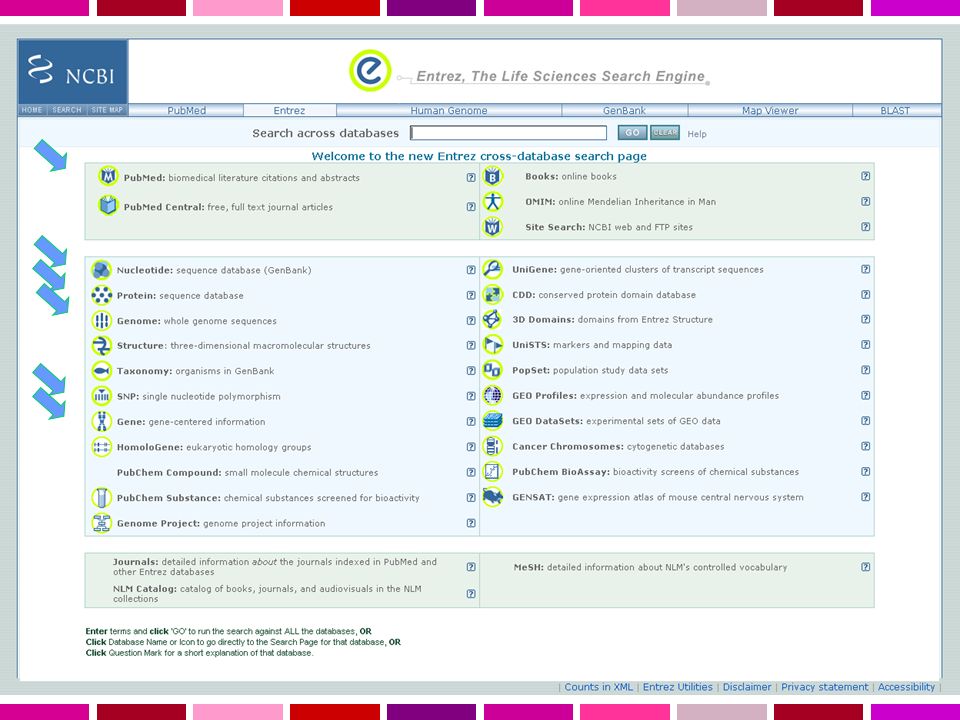
DATABASE SECONDARI ENTREZ - Information retrieval system E' stato sviluppato allNCBI (National Center for Biotechnology Information, USA) per permettere l'accesso a dati di biologia molecolare e citazioni bibliografiche. Sfrutta il concetto di neighbouring: possibilita' di collegare tra loro oggetti diversi di database differenti, indipendentemente dal fatto che essi siano direttamente cross-referenced. Tipicamente, ENTREZ permette l'accesso a database di sequenze nucleotidiche, di sequenze proteiche, di mappaggio di cromosomi e di genomi, di struttura 3D e bibliografici (PubMed).
..")
Presentazioni simili






 Laurea Magistrale in Informatica Reti 2 (2006/07) dott. Federico Paoloni>")
.www.jcp.org Tentativo di unificare EJB2.1 con.>")




 relazionale client/server.>")









