Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
I NTRODUZIONE AL W EKA Umberto Panniello DIMEG, Politecnico di Bari Modelli di e-business e business intelligence Cdl Ingegneria Informatica

2
K NOWLEDGE DISCOVERY IN DB

3
D AI DATI ALL ’ INFORMAZIONE La società produce una grossa quantità di dati fonti: business, science, medicina, economia, geografia, ambiente, sports, … Potenzialmente sono fonti di grande valore Servono tecniche per estrarre informazione interessante automaticamente dai dati Cosa vuol dire interessante? Nuova Implicita Potenzialmente utile Comprensibile

4
WEKA: THE BIRD

5
WEKA: IL SOFTWARE E’ un software di Machine learning/data mining scritto in Java Utilizzato nella ricerca, nella didattica, e nelle applicazioni “Data Mining” by Witten & Frank Principali caratteristiche: Set completo di strumenti per il pre-processing, algoritmi di apprendimento e metodi di valutazione Graphical user interfaces (incl. data visualization) Ambiente per confrontare i risultati degli algoritmi
 Ambiente per confrontare i risultati degli algoritmi.")
6
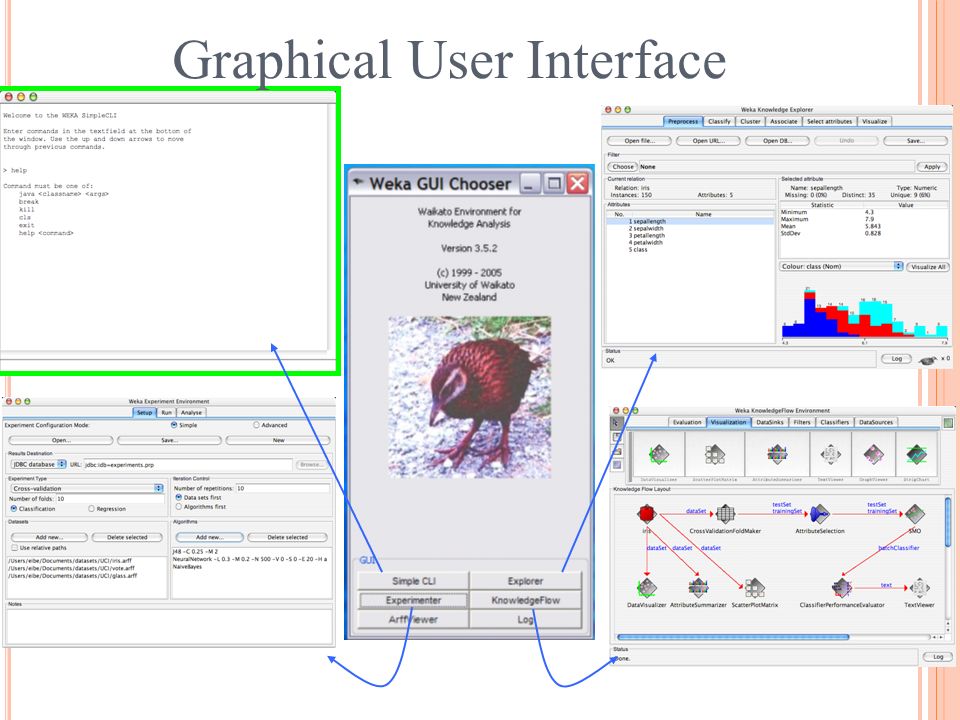
Graphical User Interface

8
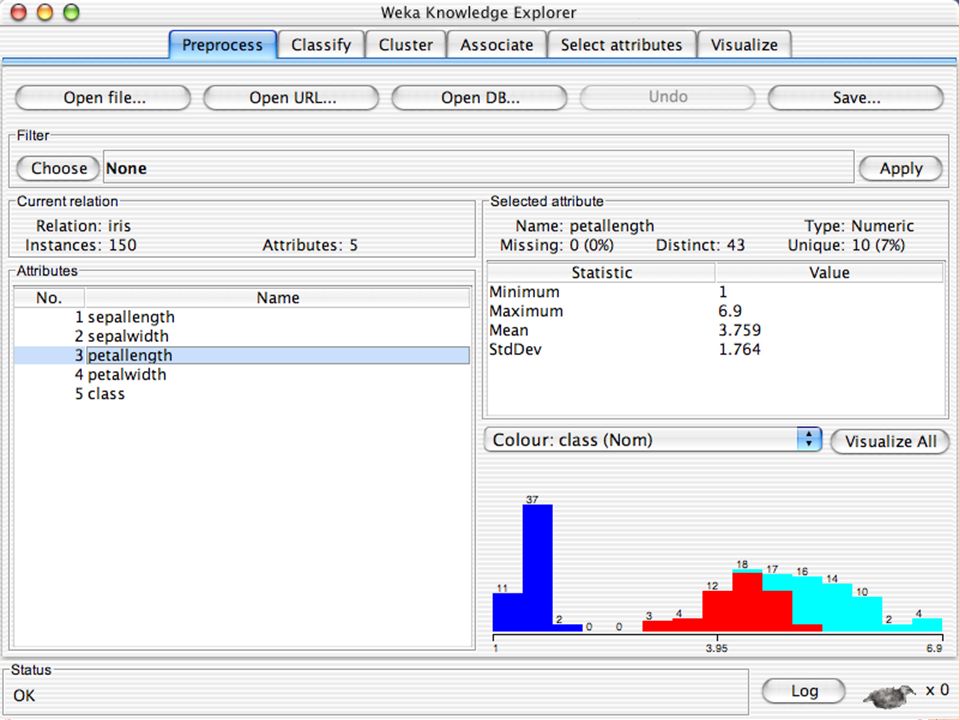
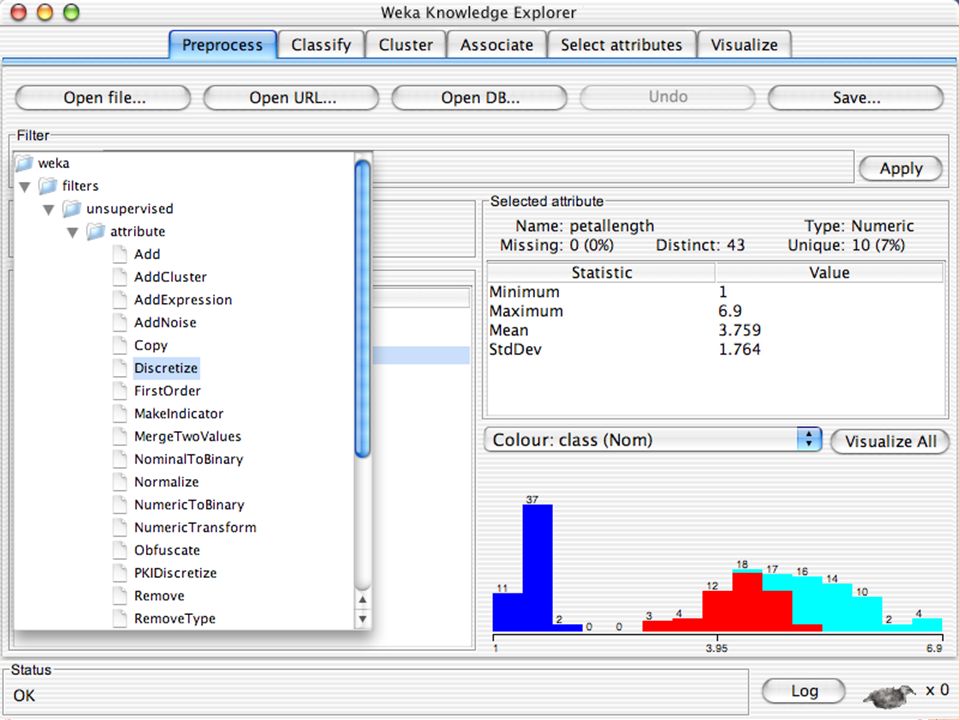
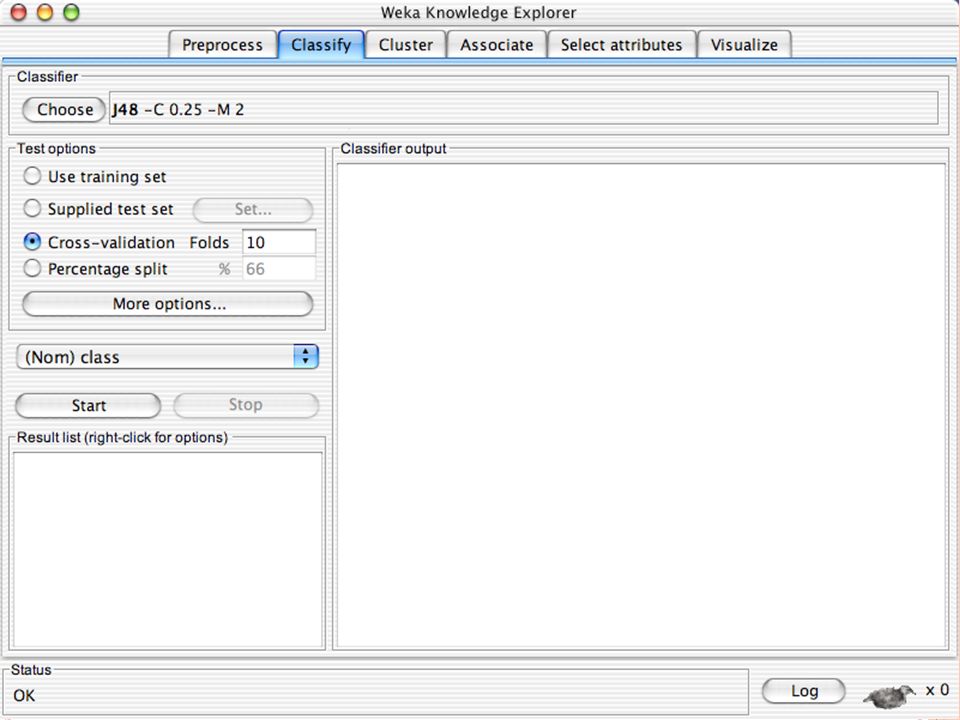
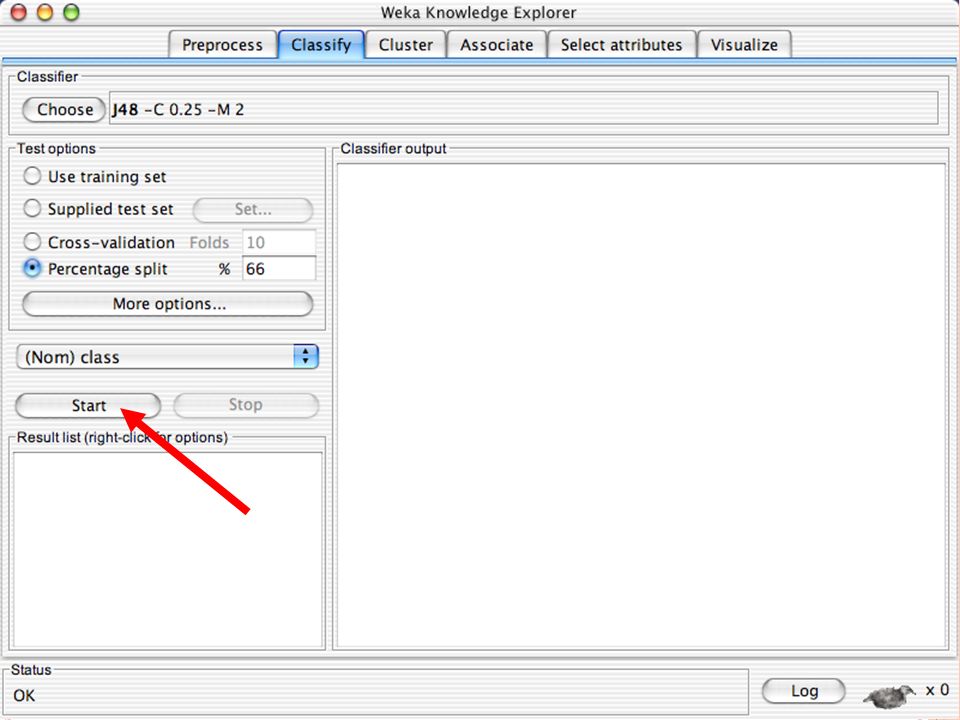
E XPLORER Comprende le seguenti funzioni Pre-process Classify Cluster Associate Select attributes Visualize

9
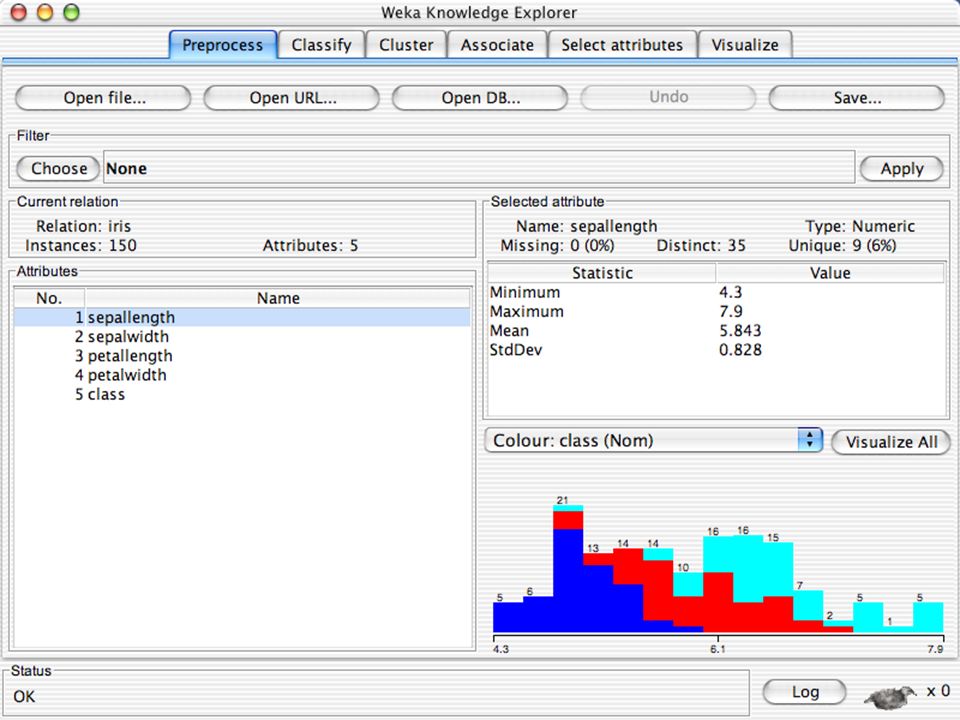
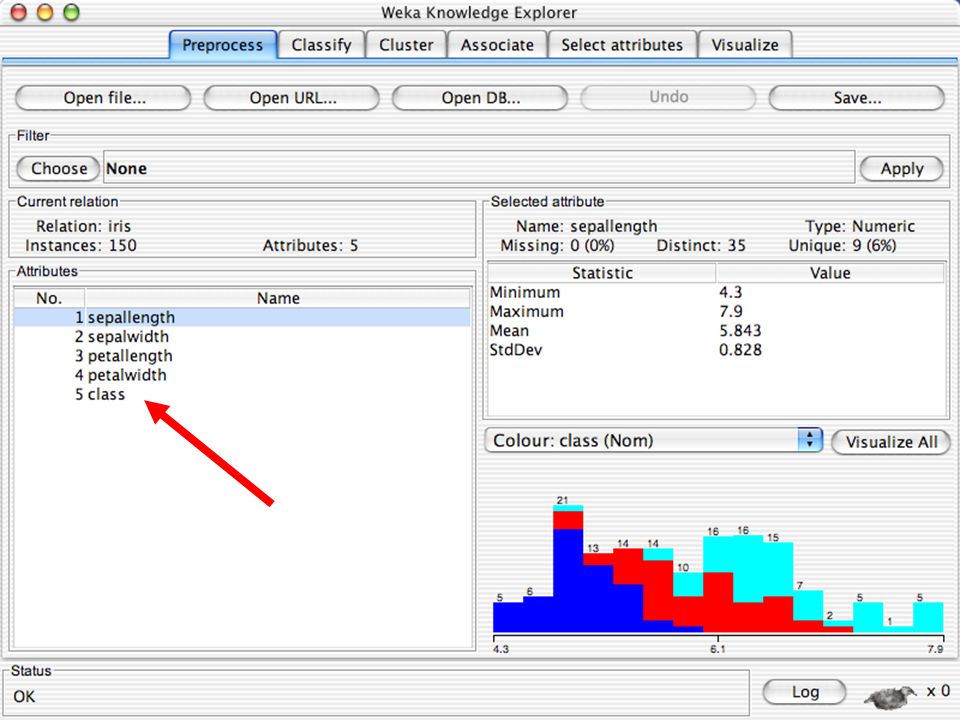
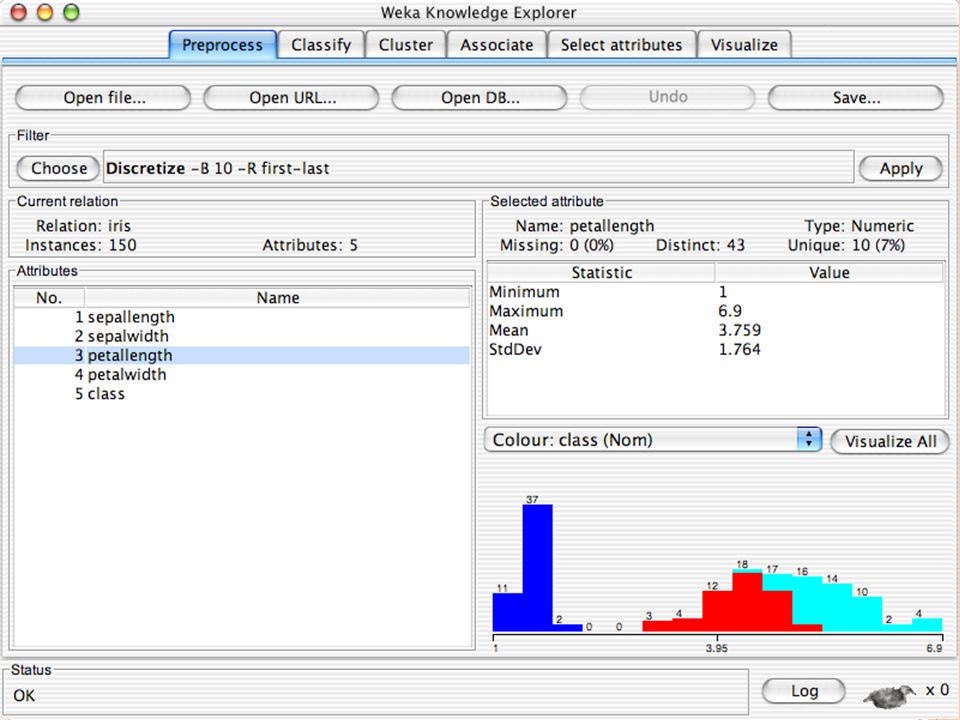
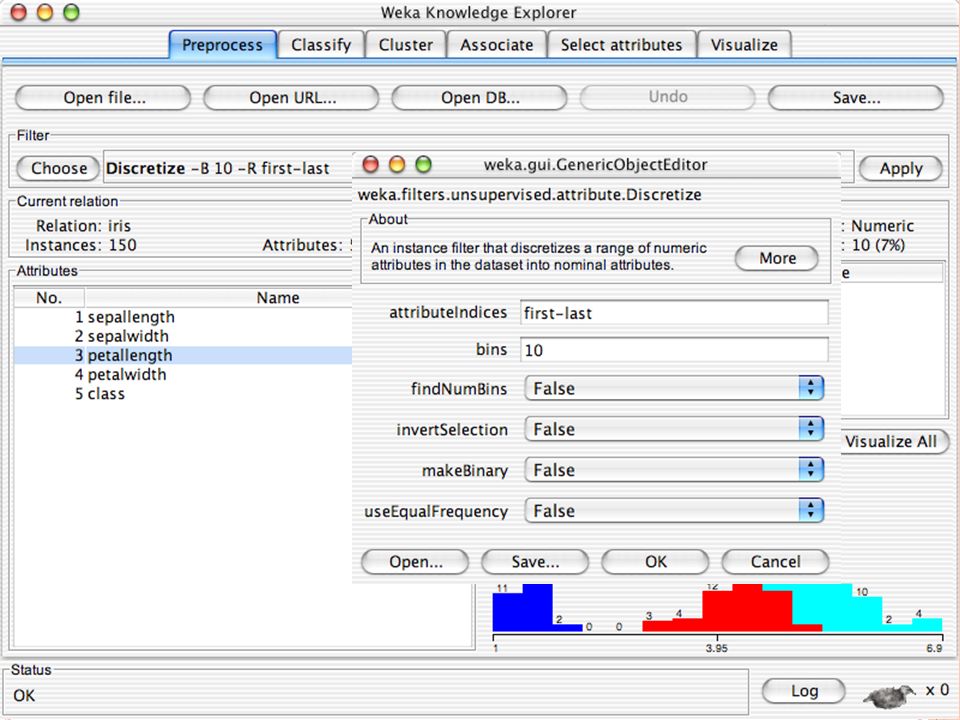
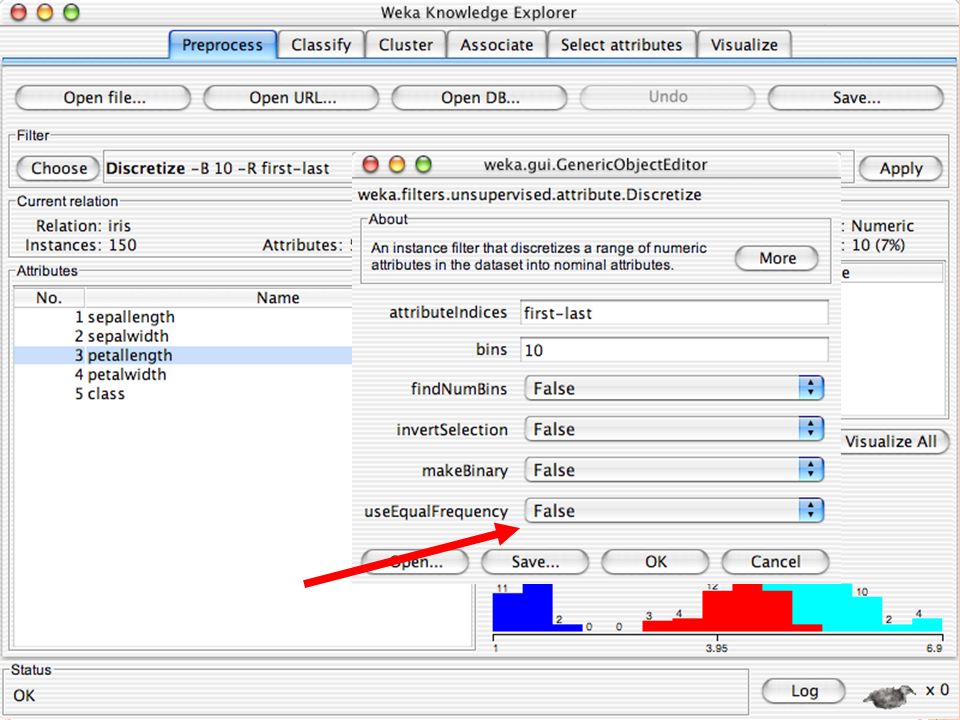
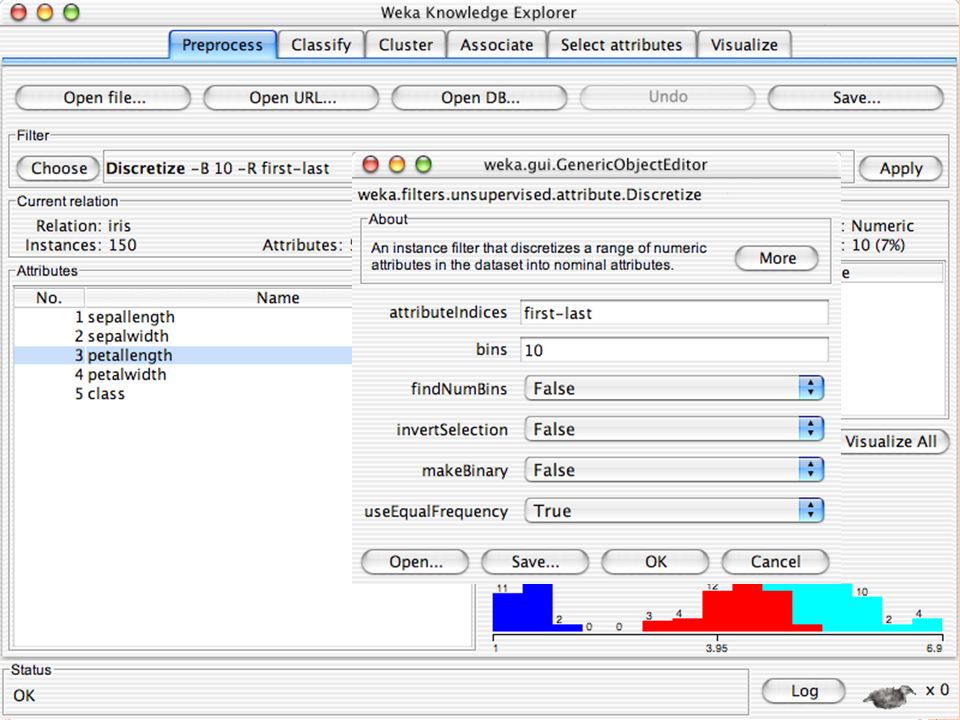
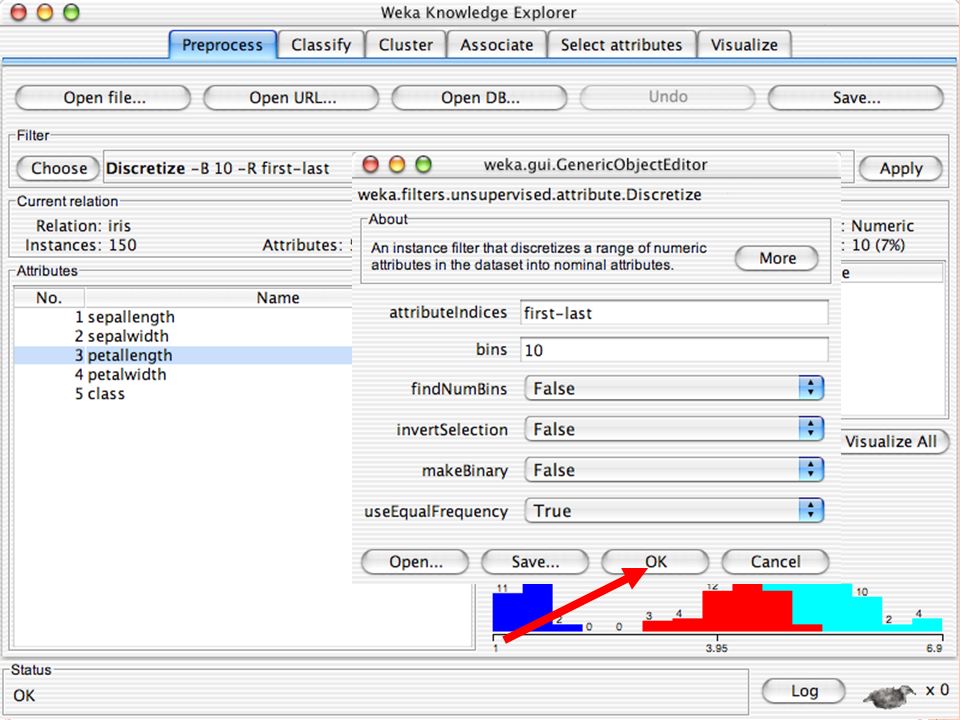
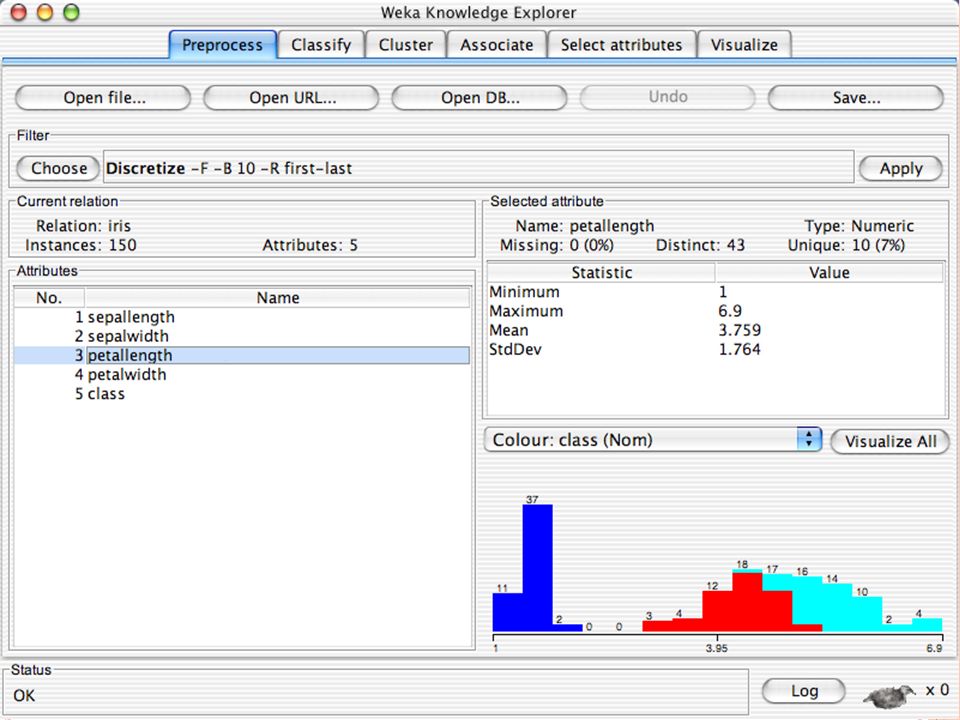
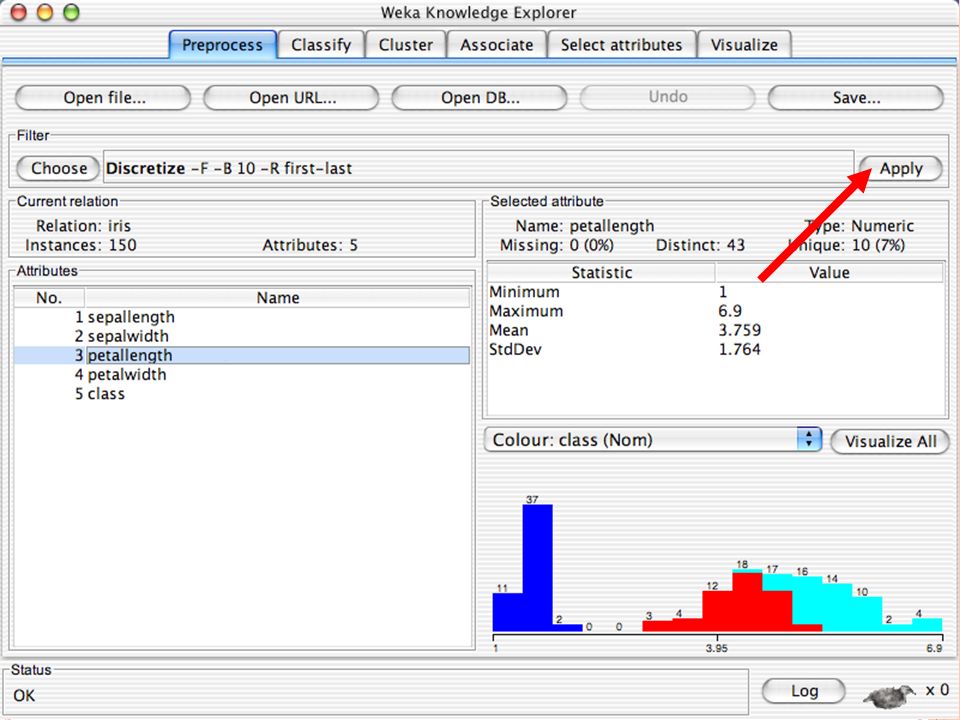
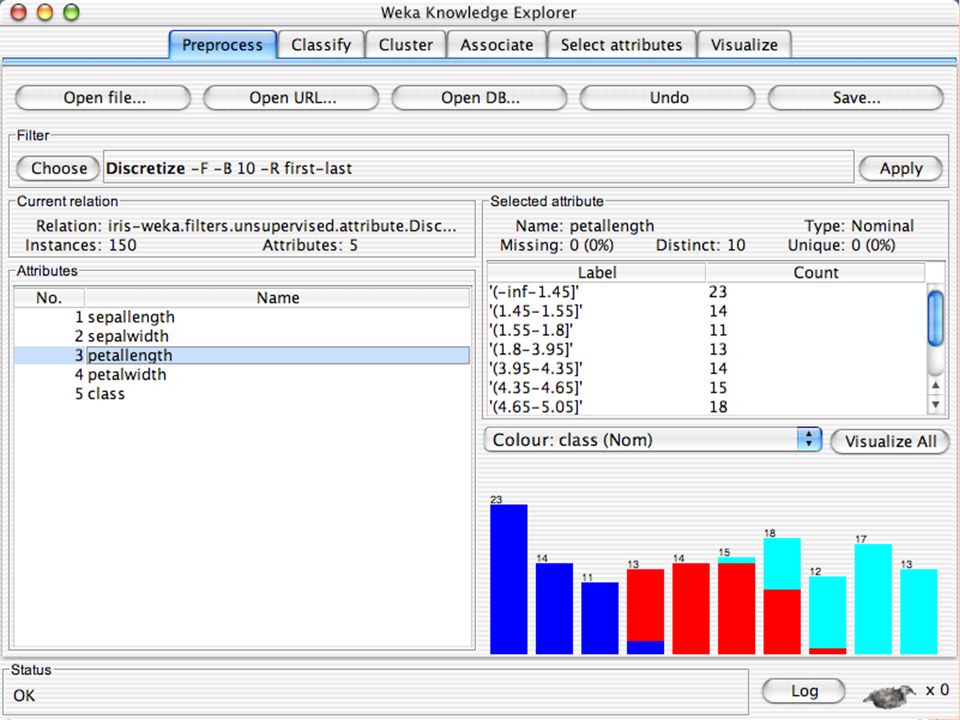
E XPLORER : P RE - PROCESSING Possono essere importati dati in input di diversi estensioni: ARFF, CSV, C4.5, binary I dati possono essere letti da un URL o da un data base SQL Gli strumenti di pre processing sono chiamati “ filtri ” WEKA contiene filtri per: Discretization, normalization, resampling, attribute selection, transforming and combining attributes

10
I F ILTRI Servono a “trasformare” i dati. Si dividono in: Unsupervised (no conosco classe) Supervised (conosco classe) Inoltre, si distingue tra: Attribute filters Instance filters
 Supervised (conosco classe) Inoltre, si distingue tra: Attribute filters Instance filters.")
11
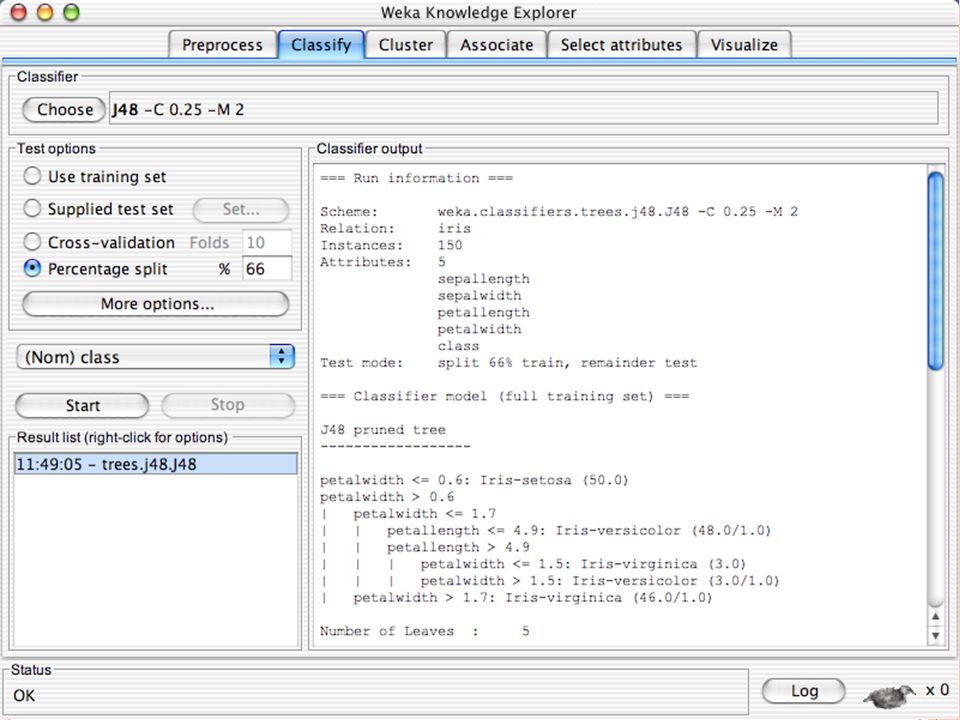
E SEMPIO DI INPUT Y= F ( X ) AgeSpectacle prescriptionAstigmatismTear production rate Recommended lenses YoungMyopeNoReducedNone YoungMyopeNoNormalSoft YoungMyopeYesReducedNone YoungMyopeYesNormalHard YoungHypermetropeNoReducedNone YoungHypermetropeNoNormalSoft YoungHypermetropeYesReducedNone YoungHypermetropeYesNormalhard Pre-presbyopicMyopeNoReducedNone Pre-presbyopicMyopeNoNormalSoft Pre-presbyopicMyopeYesReducedNone Pre-presbyopicMyopeYesNormalHard Pre-presbyopicHypermetropeNoReducedNone Pre-presbyopicHypermetropeNoNormalSoft Pre-presbyopicHypermetropeYesReducedNone Pre-presbyopicHypermetropeYesNormalNone PresbyopicMyopeNoReducedNone PresbyopicMyopeNoNormalNone PresbyopicMyopeYesReducedNone PresbyopicMyopeYesNormalHard PresbyopicHypermetropeNoReducedNone PresbyopicHypermetropeNoNormalSoft PresbyopicHypermetropeYesReducedNone PresbyopicHypermetropeYesNormalNone Raw Istanze Columns = Attributi Class
 AgeSpectacle prescriptionAstigmatismTear production rate Recommended lenses YoungMyopeNoReducedNone YoungMyopeNoNormalSoft YoungMyopeYesReducedNone YoungMyopeYesNormalHard YoungHypermetropeNoReducedNone YoungHypermetropeNoNormalSoft YoungHypermetropeYesReducedNone YoungHypermetropeYesNormalhard Pre-presbyopicMyopeNoReducedNone Pre-presbyopicMyopeNoNormalSoft Pre-presbyopicMyopeYesReducedNone Pre-presbyopicMyopeYesNormalHard Pre-presbyopicHypermetropeNoReducedNone Pre-presbyopicHypermetropeNoNormalSoft Pre-presbyopicHypermetropeYesReducedNone Pre-presbyopicHypermetropeYesNormalNone PresbyopicMyopeNoReducedNone PresbyopicMyopeNoNormalNone PresbyopicMyopeYesReducedNone PresbyopicMyopeYesNormalHard PresbyopicHypermetropeNoReducedNone PresbyopicHypermetropeNoNormalSoft PresbyopicHypermetropeYesReducedNone PresbyopicHypermetropeYesNormalNone Raw Istanze Columns = Attributi Class")
12
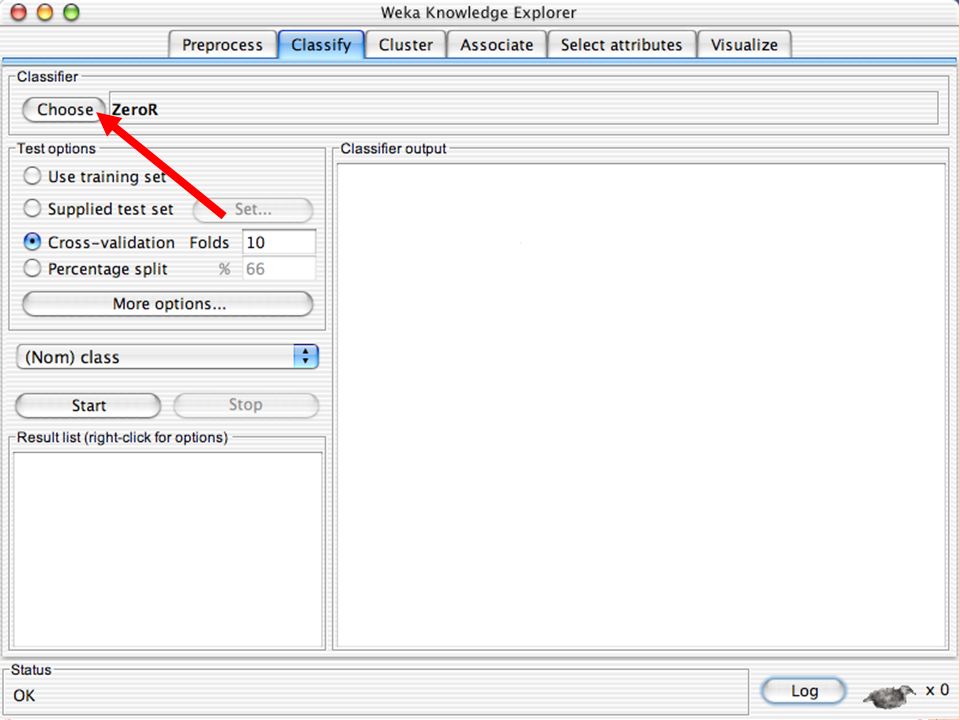
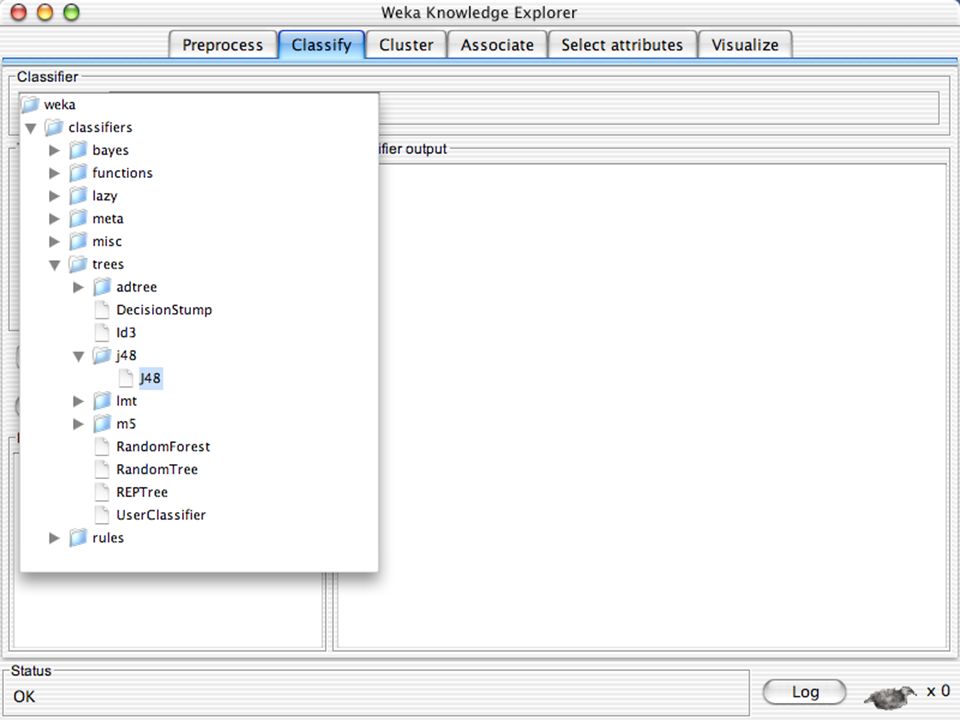
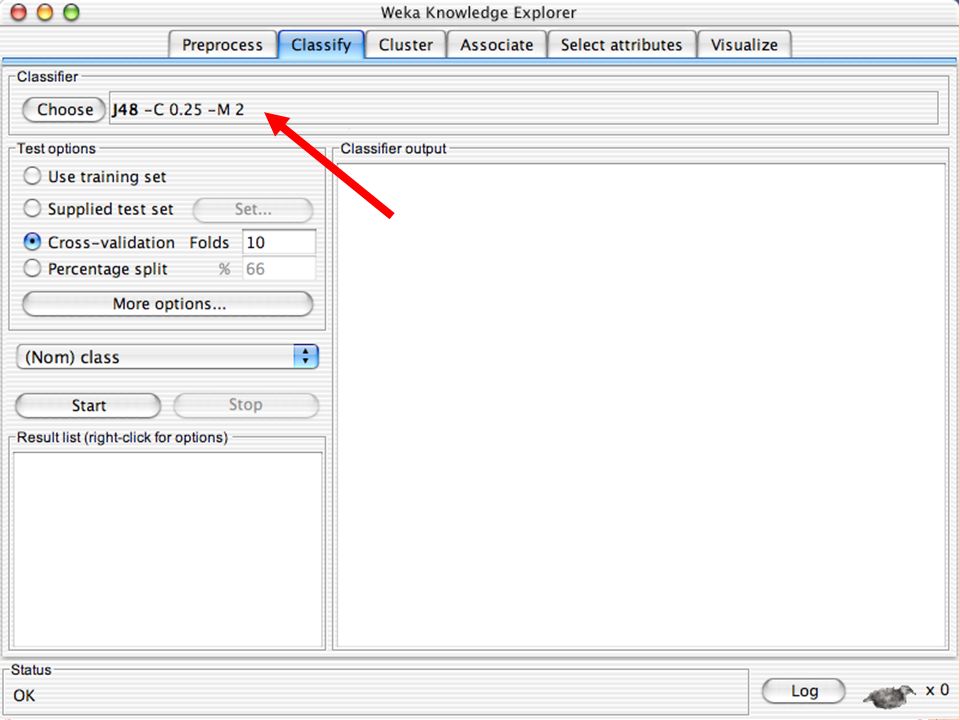
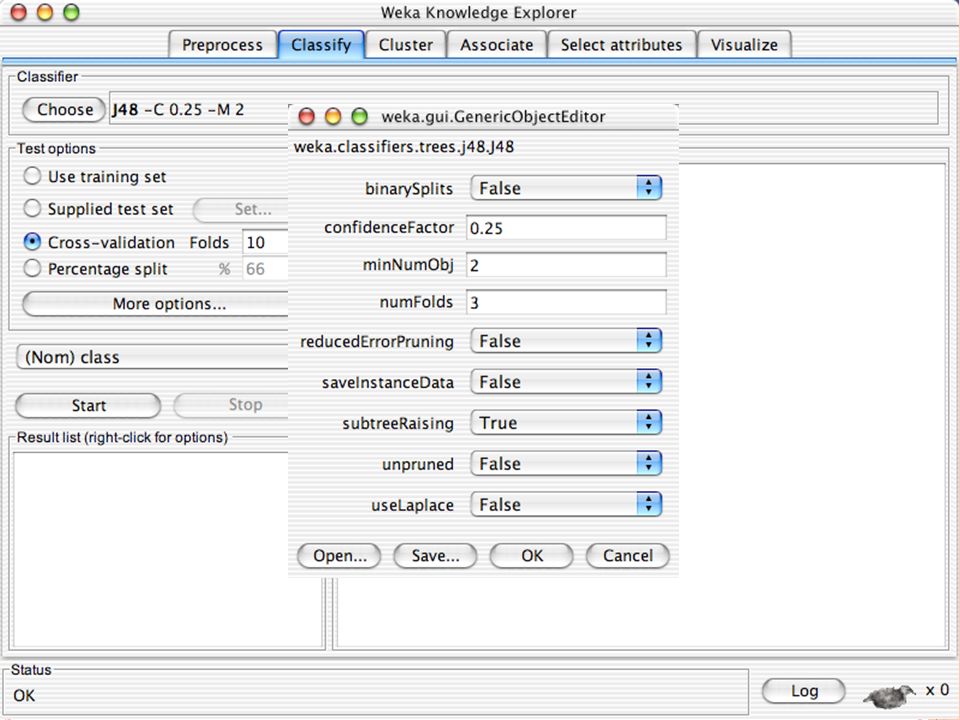
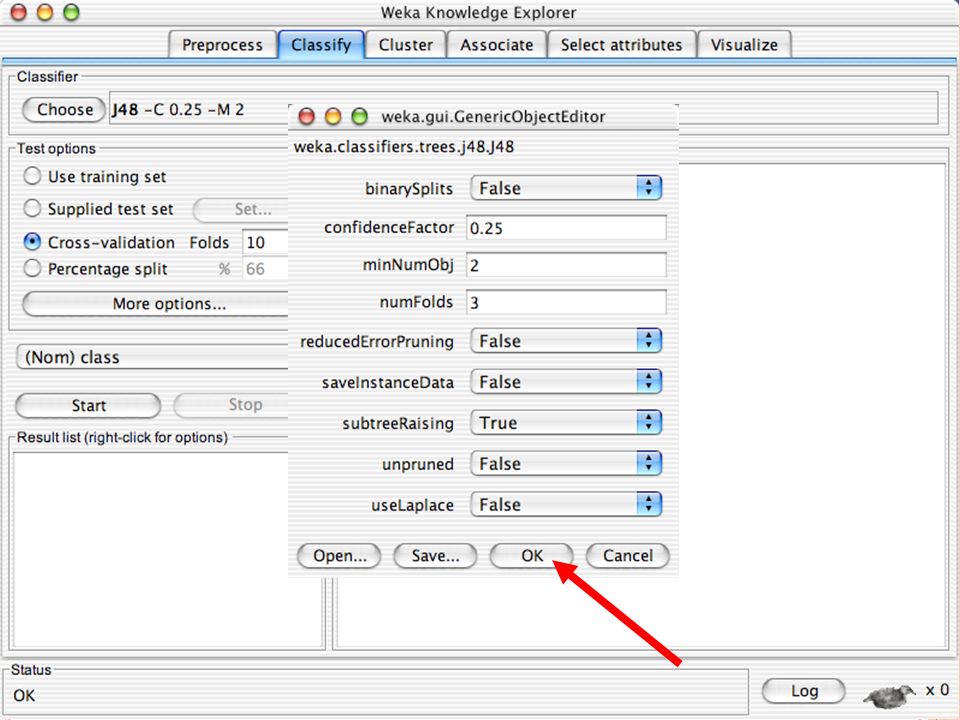
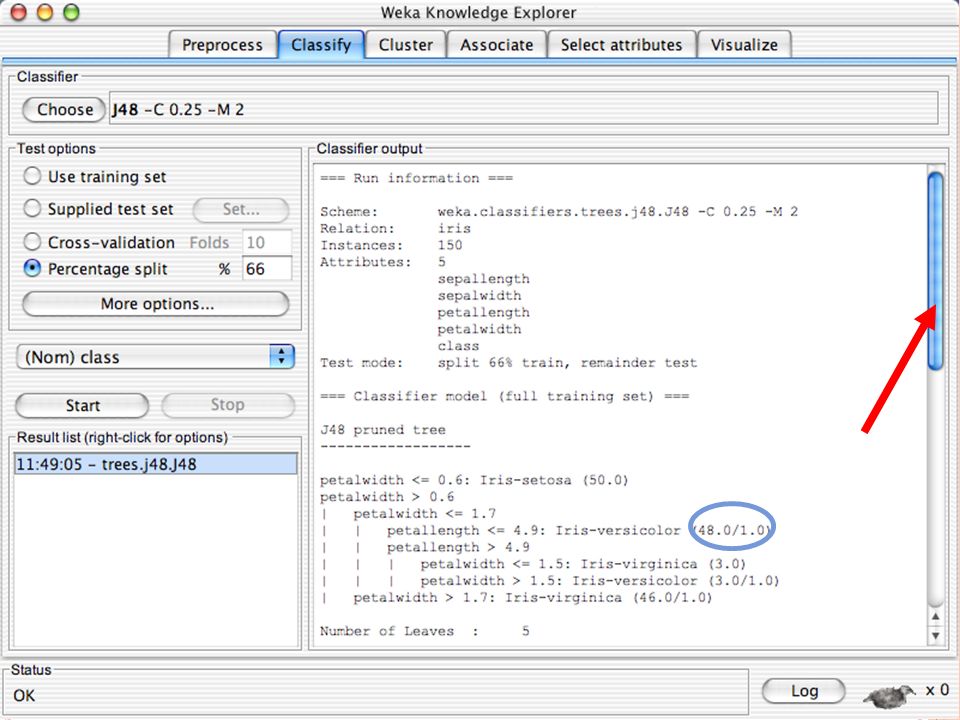
E XPLORER : C LASSIFIERS Classifiers: sono modelli per predire quantità numeriche o nominali Algoritmi implementati sono: Decision trees and rules, instance-based classifiers, support vector machines, multi-layer perceptrons (reti neurali), logistic regression,…
, logistic regression,…")
13
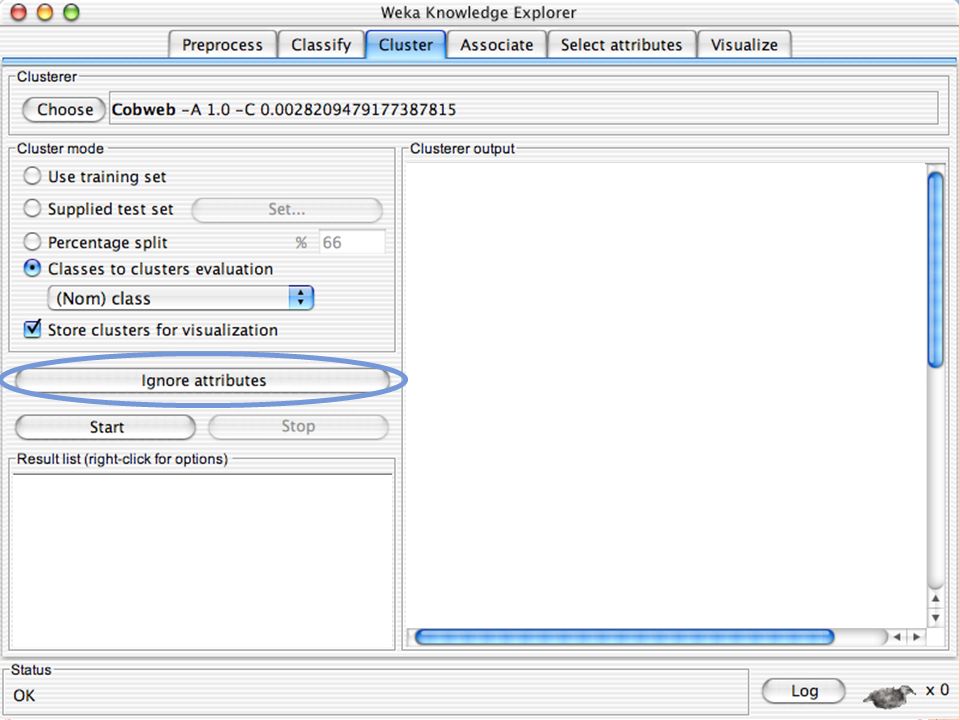
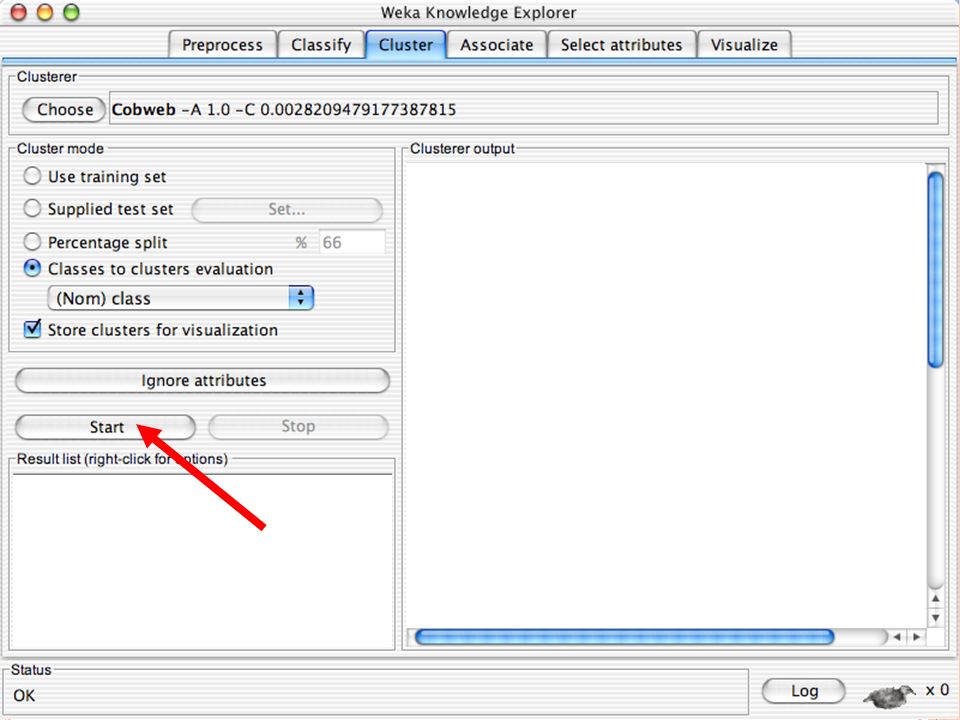
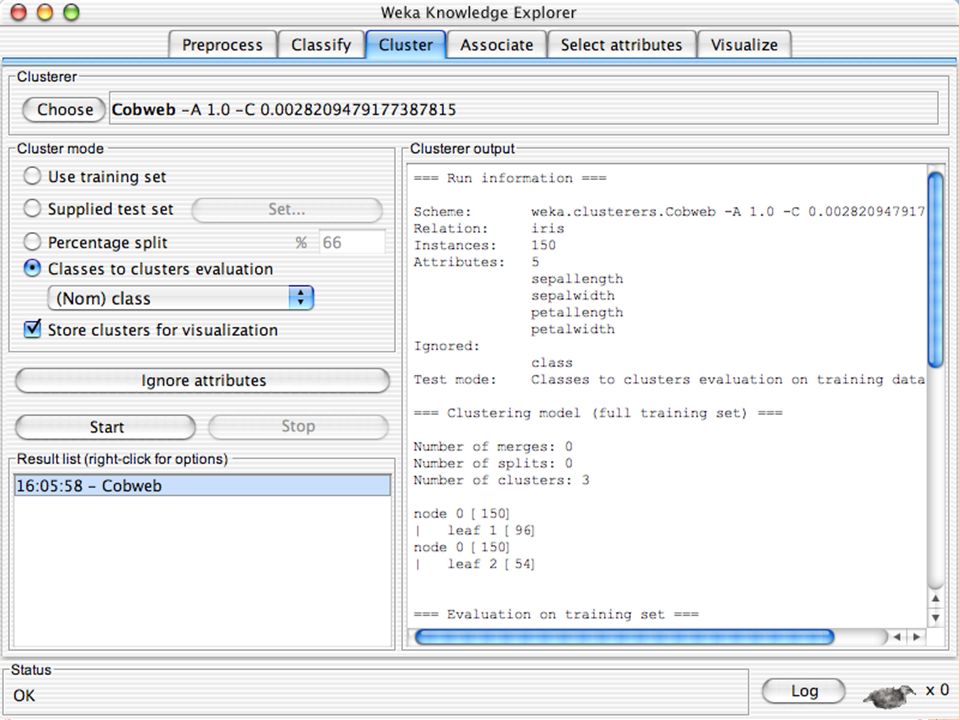
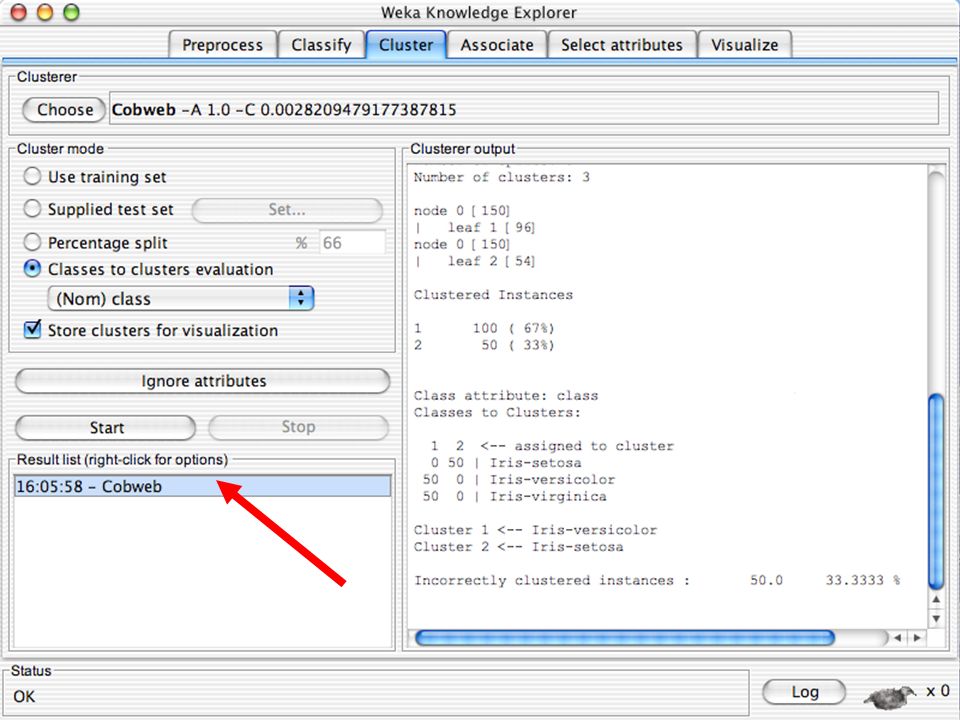
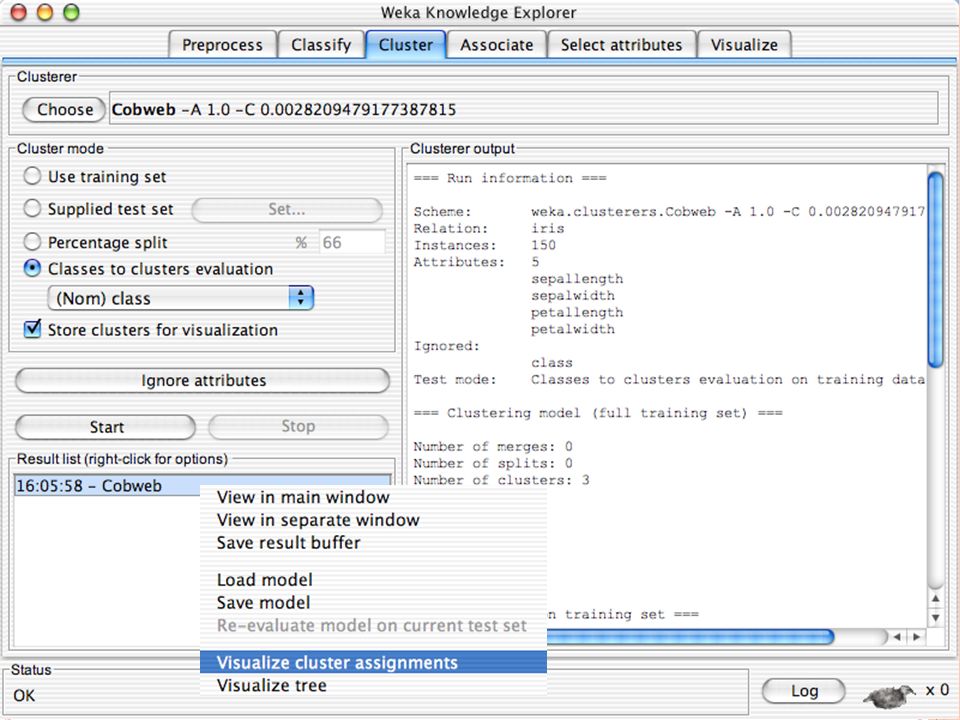
E XPLORER : C LUSTERING I “clusterers” creano insieme di istanze tali che: le istanze dello stesso cluster sono simili tra loro alta somiglianza intra-classe le istanze di cluster diversi sono dissimili bassa somiglianza inter-classe Alcuni algoritmi implementati sono: k -Means, EM, Cobweb, X -means, FarthestFirst

14
E XPLORER : A SSOCIATIONS Permettono di trovare associazioni di dipendenza statistica fra attributi Es: Sia data la regola: compra(x,”pannolino”) => compra(x,”birra”) Supporto : la percentuale di acquisti che comprendono sia i pannolini che la birra. Confidenza : tra gli acquisti che includono i pannolini, la percentuale di quelli che includono anche la birra.

15
E XPLORER : A TTRIBUTE SELECTION Algoritmi che permettono di investigare quali sottoinsiemi di attributi hanno maggiore capacità predittiva Tali algoritmi constano di 2 parti: Un metodo di valutazione: correlation-based, wrapper, information gain, chi-squared, … Un metodo di ricerca: best-first, forward selection, random, exhaustive, genetic algorithm, ranking

16
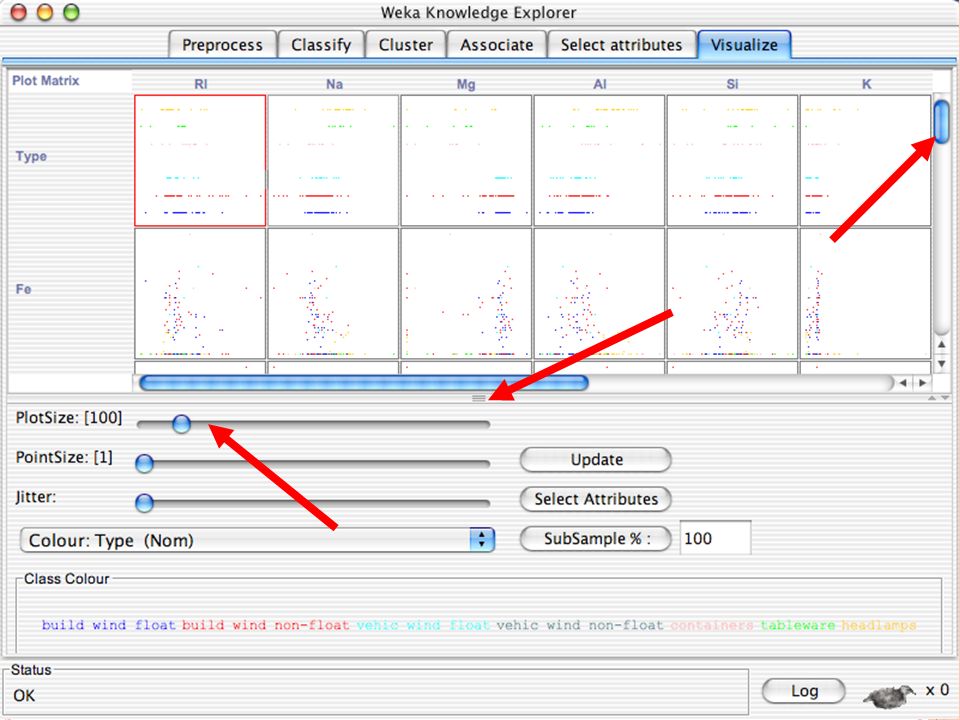
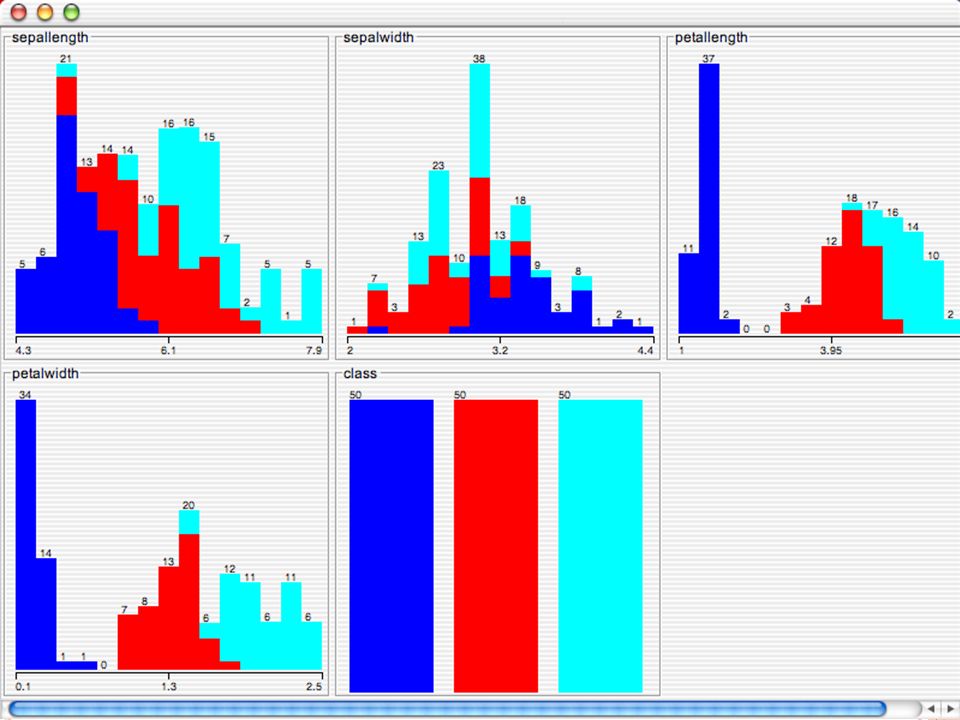
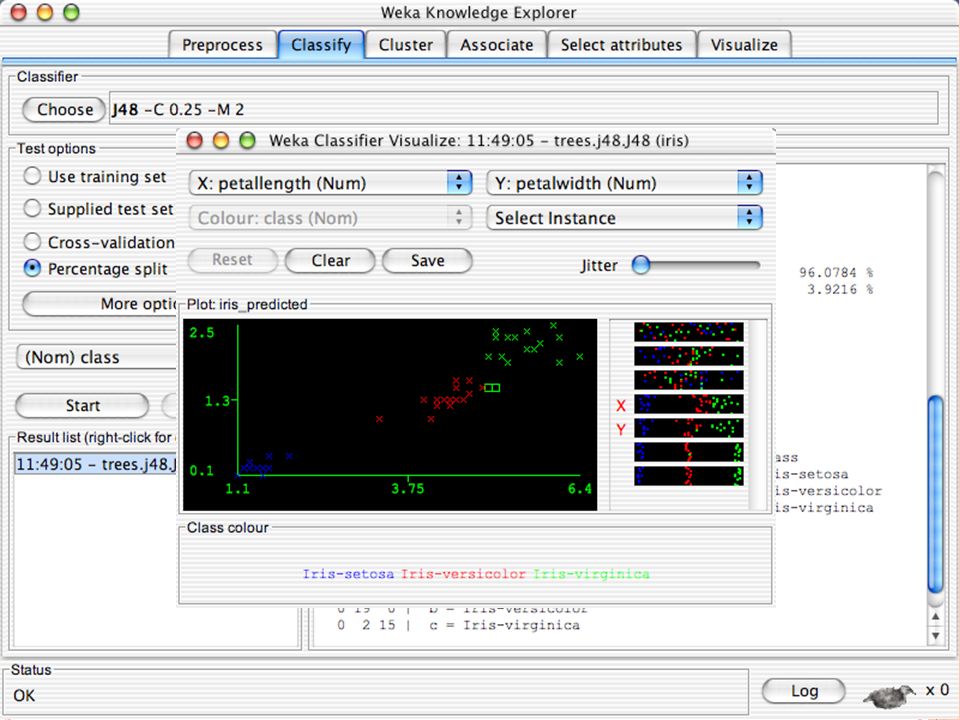
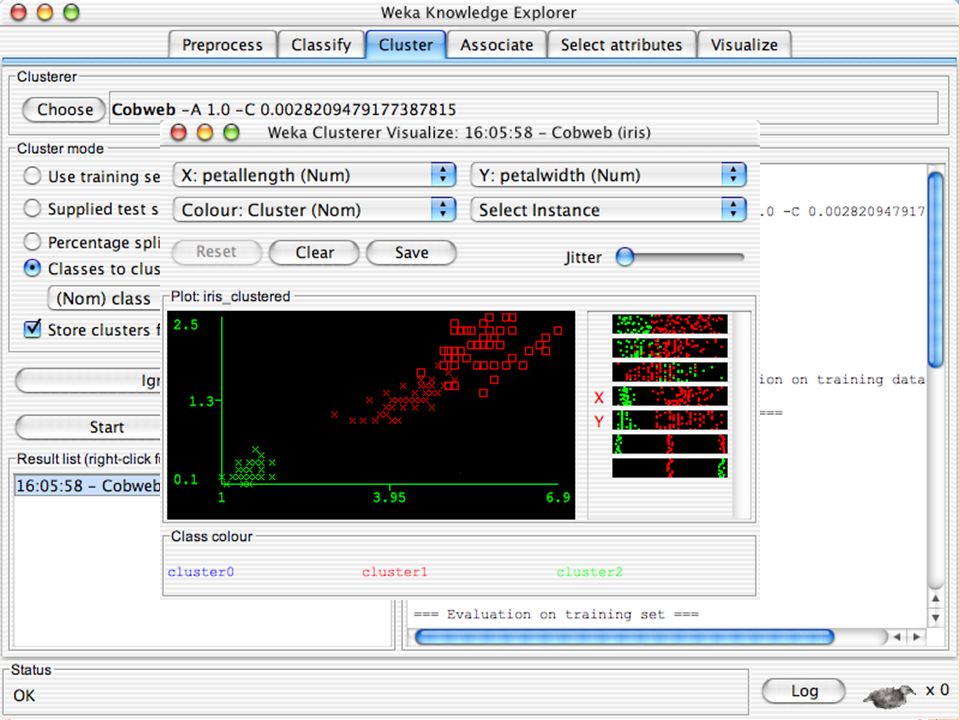
E XPLORER : DATA VISUALIZATION WEKA permette di visualizzare singoli attributi (1-d) e coppie di attributi (2-d) “Jitter” per aumentare il grado di dettaglio delle rappresenazioni dei dati Funzioni di “Zoom-in” function Selezione dei dati da grafico
 e coppie di attributi (2-d) Jitter per aumentare il grado di dettaglio delle rappresenazioni dei dati Funzioni di Zoom-in function Selezione dei dati da grafico")
18
Graphical User Interface

19
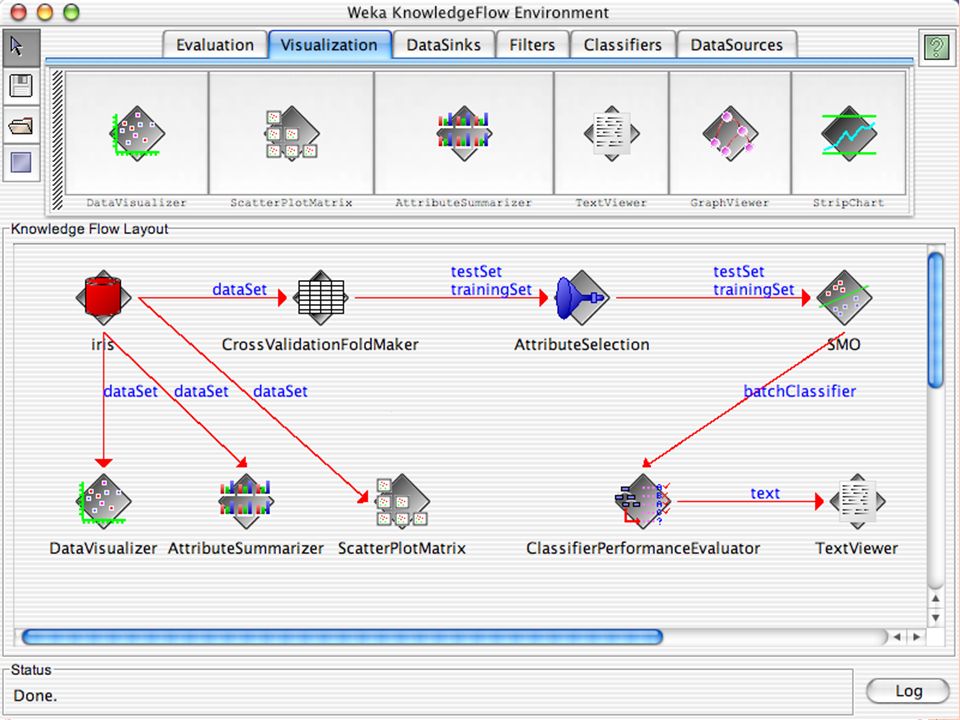
T HE K NOWLEDGE F LOW GUI Permette di impostare un esperimento in maniera grafica Permette di unire le diverse funzioni dell’explorer graficamente “data input” -> “filter” -> “classifier” -> “evaluator” I Layout possono essere salvati e caricati successivamente

21
Graphical User Interface

63
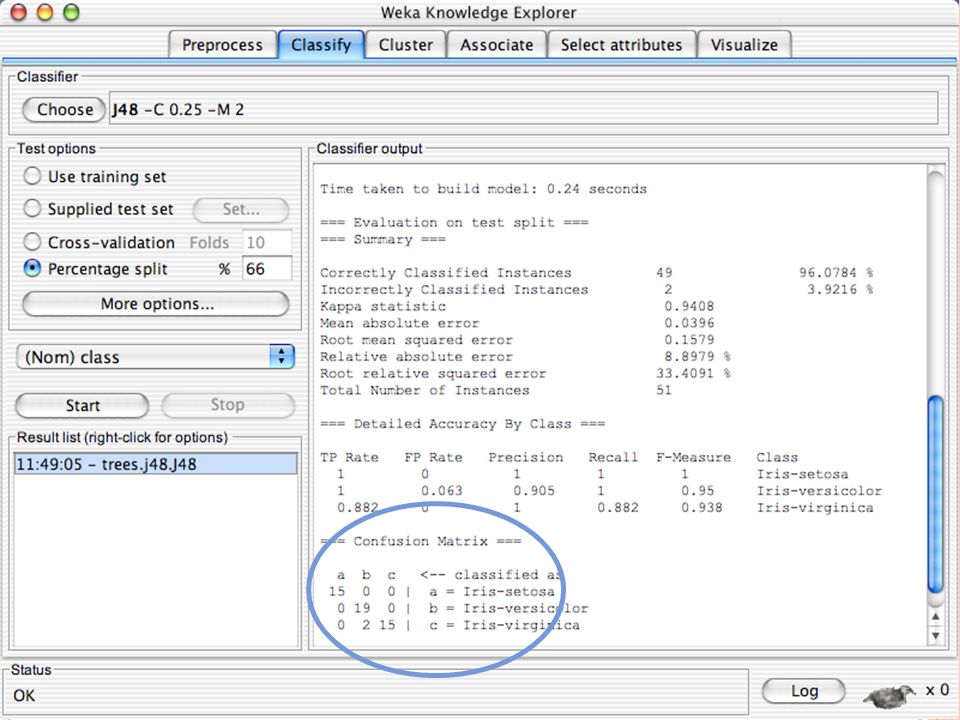
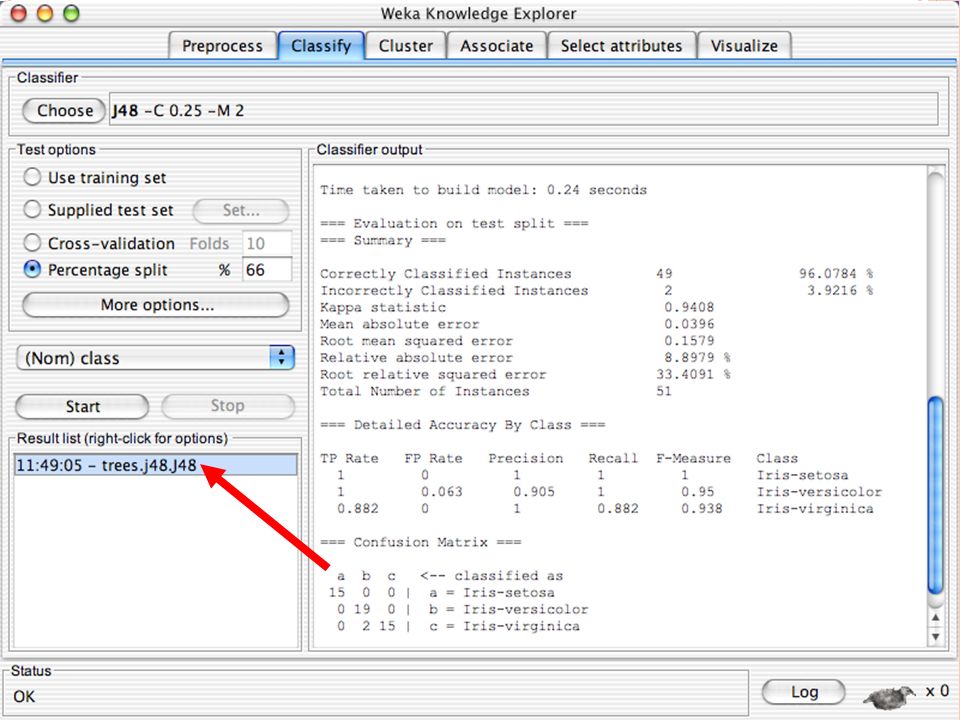
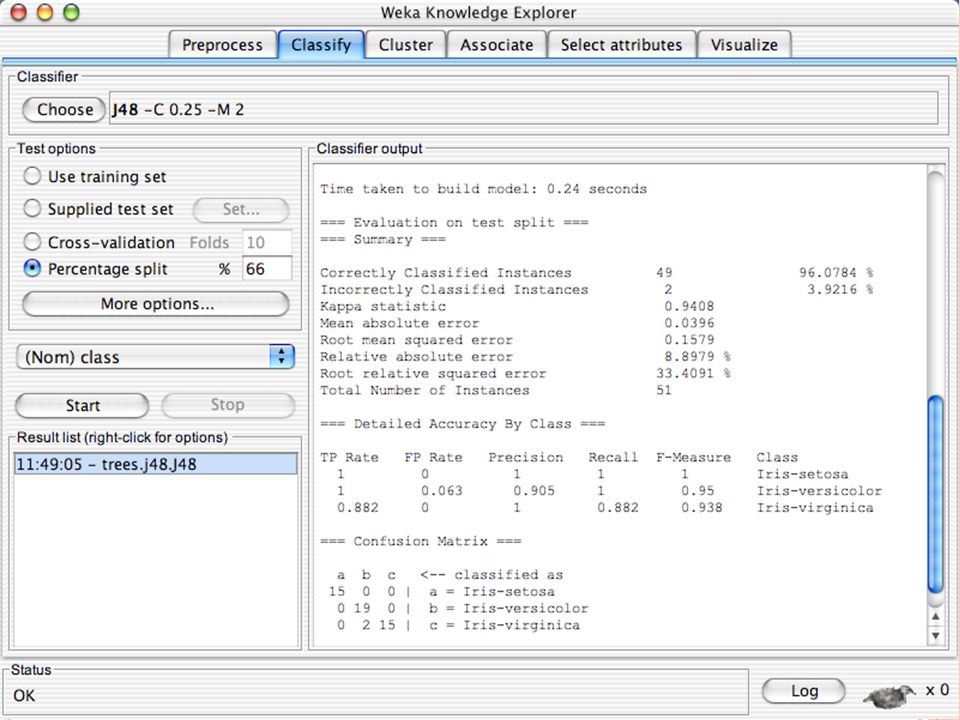
C ONFUSION MATRIX

64
P RECISION, R ECALL AND F-M EASURE

Presentazioni simili


















>")
