Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Psicometria modulo 1 Scienze tecniche e psicologiche Prof. Carlo Fantoni Dipartimento di Scienze della Vita Università di Trieste 2014-2015 1.Varianza e Gradi di Libertà 2.Requisiti degli indici di dispersione 3.Proprietà notevoli della varianza (dimostrazioni Excel) 4.Teorema della somma delle Varianze (Dimostratore Excel) 5.Deviazione Standard 6.Punti z, standardizzazione, distribuzione normale standard e sue applicazioni 7.Tavole dei punti z 8.Metodo probit 9.Retta dei minimi quadrati, euqzione di previsione e stima dei parametri (a e b)
 4.Teorema della somma delle Varianze (Dimostratore Excel) 5.Deviazione Standard 6.Punti z, standardizzazione, distribuzione normale standard e sue applicazioni 7.Tavole dei punti z 8.Metodo probit 9.Retta dei minimi quadrati, euqzione di previsione e stima dei parametri (a e b).")
2
indici di dispersione relativi al centro IQR e campo di variazione sono misure di variabilità assoluta: non tengono in considerazione di come le misure si distribuiscono attorno al centro (media) dato che (come già dimostrato) la somma delle deviazioni dalla media è nulla la più rilevante misura di variabilità fa uso dello scarto quadratico dalla media o devianza Perché non basta la devianza ? dipende dalla numerosità del campione l'unità di misura è il quadrato di quella della variabile avete verifichato usando il documento Mean&MedianPropertyDemonstration.xls (Foglio: proprietà della devianza) ? Mean&MedianPropertyDemonstration.xls
 . Mean&MedianPropertyDemonstration.xls.")
3
facciamo in modo che la dispersione dei dati sia proporzionale alla media dei punteggi: quindi k corrisponderà al rapporto fra = F2/F4 devianza e n Mean&MedianPropertyDemonstration.xls Foglio: proprietà della devianza

4
Calcoliamo per ciascun punteggio lo scarto dalla media al quadrato in colonna V e cumuliamo gli scarti in W Otteniamo così le devianze per campioni di grandezza da 1 a n Costruiamo quindi il grafico di dispersione con la devianza cumulata in y e il numero di osservazioni in x = SUM ($V$ i :V n )= (H i -$T$2)^2 devianza e n Mean&MedianPropertyDemonstration.xls Foglio: proprietà della devianza
= (H i -$T$2)^2 devianza e n Mean&MedianPropertyDemonstration.xls Foglio: proprietà della devianza")
5
osserviamo la relazione fra devianza, grandezza del campione e parametri e ) la pendenza della retta dipende dalla media della popolazione? devianza e n Mean&MedianPropertyDemonstration.xls Foglio: proprietà della devianza

6
risultato 200 0 1000 2000 3000 4000 5000 051015 Numerosità campione Devianza simulazione con = /9 450 150 250 100 93

7
varianza, g.d.l., popolazine o campione? È necessario pesare gli scarti con il numero delle osservazioni popolazione campione Gradi di libertà

8
media delle deviazioni al quadrato nulla i valori sono uguali piccola i valori sono simili e quindi distribuiti vicino alla media grande i valori sono diversi e quindi distribuiti lontano dalla media

9
perché g.d.l.? campione popolazione

10
perché g.d.l.? campione (N) popolazione errore
 popolazione errore")
11
perché g.d.l.? campione popolazione campione (N-1) > cresce la probabilità che valori della popolazione siano correttamente campionati
 > cresce la probabilità che valori della popolazione siano correttamente campionati.")
12
varianza e requisiti Un indice per la misura della variabilita deve avere le seguenti caratteristiche: deve assumere valori maggiori o uguali a 0 di facile interpretazione (come la devianza la sua unità di misura è il quadrato della variabile ) deve essere invariante alla traslazione preferibilmente invariante alla scala applicabile a variabili discrete (distribuzioni di frequenze)
 deve essere invariante alla traslazione preferibilmente invariante alla scala applicabile a variabili discrete (distribuzioni di frequenze)")
13
varianza e invarianze stessa varianza dopo aver aggiunto 10 a ciascun valore (invarianza alla traslazione) la varianza dopo aver moltiplicato tutti gli elementi per 10 corriponde a: s 2 K 2 (no invarianza alla scala)
 la varianza dopo aver moltiplicato tutti gli elementi per 10 corriponde a: s 2 K 2 (no invarianza alla scala)")
14
varianza e requisiti Un indice per la misura della variabilita deve avere le seguenti caratteristiche: deve assumere valori maggiori o uguali a 0 di facile interpretazione (come la devianza la sua unità di misura è il quadrato della variabile ) deve essere invariante alla traslazione preferibilmente invariante alla scala applicabile a variabili discrete (distribuzioni di frequenze)
 deve essere invariante alla traslazione preferibilmente invariante alla scala applicabile a variabili discrete (distribuzioni di frequenze)")
15
varianza e distribuzioni di frequenze relative vedi Eq. a pag. 109, Agresti (Es. 4.55) e/o Eq. 4.17 Borazzo (pag. 102) verifichiamo il significato dell’equazione nel nostro dataset corrisponde alla media x
 e/o Eq Borazzo (pag. 102) verifichiamo il significato dell’equazione nel nostro dataset corrisponde alla media x.")
16
NUMFREND_DATASET_AGE.xls Tabella pivot che calcola le % del numero di amici per ogni categoria di età (colonna) per tutte le possibili ooservazioni di numero di amici Tabella che riporta i valori della tabella pivot nel formato desiderato Tabella che converte i valori di frequenza nel prodotto fra frequenza relativa e valore al quadrato dall’osservazione = O6*$I6^2 = VARP('media e mediana'!B5:B859) = SUM(Q5:Q32) - = VARP('media e mediana'!B5:B859) Foglio: Verifica_VARI_distrib_discreta
 per tutte le possibili ooservazioni di numero di amici Tabella che riporta i valori della tabella pivot nel formato desiderato Tabella che converte i valori di frequenza nel prodotto fra frequenza relativa e valore al quadrato dall’osservazione = O6*$I6^2 = VARP( media e mediana !B5:B859) = SUM(Q5:Q32) - = VARP( media e mediana !B5:B859) Foglio: Verifica_VARI_distrib_discreta")
17
Tabella pivot che calcola le % del numero di amici per ogni categoria di età (colonna) per tutte le possibili ooservazioni di numero di amici Tabella che riporta i valori della tabella pivot nel formato desiderato Tabella che converte i valori di frequenza nel prodotto fra frequenza relativa e valore assunto dall’osservazione I valori sono uguali quindi è vero che NUMFREND_DATASET_AGE.xls Foglio: Verifica_VARI_distrib_discreta
 per tutte le possibili ooservazioni di numero di amici Tabella che riporta i valori della tabella pivot nel formato desiderato Tabella che converte i valori di frequenza nel prodotto fra frequenza relativa e valore assunto dall’osservazione I valori sono uguali quindi è vero che NUMFREND_DATASET_AGE.xls Foglio: Verifica_VARI_distrib_discreta")
18
varianza e requisiti Un indice per la misura della variabilita deve avere le seguenti caratteristiche: deve assumere valori maggiori o uguali a 0 di facile interpretazione (come la devianza la sua unità di misura è il quadrato della variabile ) deve essere invariante alla traslazione preferibilmente invariante alla scala applicabile a variabili discrete (distribuzioni di frequenze)
 deve essere invariante alla traslazione preferibilmente invariante alla scala applicabile a variabili discrete (distribuzioni di frequenze)")
19
perché è così importante ?(1) La varianza della somma di variabili casuali indipendenti (non correlate) è uguale alla somma delle loro varianze Teorema della somma delle varianze (I) domanda tipo: misuriamo separatamente la prestazione degli studenti in due classi diverse (stesso docente/stessa materia). Quale è la varianza risultante dalla somma delle due due distribuzioni?

20
domanda 0.000 0.025 0.050 0100200300400 sommando le due distribuzioni otteniamo una distribuzione: più variabile della verde o meno? più a sinistra o più a destra? più variabile più a destra

21
domanda spostando la media di una delle due distribuzioni: cambia la variabilità della distribuzione somma? di quanto si è spostata? NO 0.000 0.025 0.050 0100200300400 tanto quanto la verde

22
dimostrazione il foglio ha caratteristiche simili a Sampling_Size_&_Density.xls ma include 2 (non 1) serie di valori numerici distribuiti normalmente SumOFVAriances.xls
 serie di valori numerici distribuiti normalmente SumOFVAriances.xls")
23
dimostrazione SumOFVAriances.xls 200 punteggi indipendentemente conseguiti dalle due classi Somma dei punteggi; SUM(C1 i : C2 i ) la somma delle varianze calcolate indipendentemente sulle 2 classi (504) è molto vicina alla varianza calcolata sommando i punteggi dei due campioni di dati (492) Il teorema è dimostrato
 la somma delle varianze calcolate indipendentemente sulle 2 classi (504) è molto vicina alla varianza calcolata sommando i punteggi dei due campioni di dati (492) Il teorema è dimostrato")
24
dimostrazione SumOFVAriances.xls verifica la stabilità della legge variando la media, e la varianza delle due distribuzioni teoriche di riferimento

25
definisce la variabilità/scala della distribuzione normale a cui ogni distribuzione campionaria tende (teorema del limite centrale) all’aumentare del numero di osservazioni perché è così importante ?(2) un limite della varianza è legato alla sua difficoltà di interpretazione dato che essa è espressa nell'unita di misura al quadrato della variabile cui si riferisce. per ovviare a questo problema si utilizza la deviazione standard: la redice quadrata della varianza

26
riscriviamo la formula della normale in termini di deviazioni standard varianza deviazione standard

27
gode delle stesse proprietà della varianza con il vantaggio che è espressa nella stessa unità di misura della variabile media del valore assoluto degli scarti di ciascuna osservazione dalla media

28
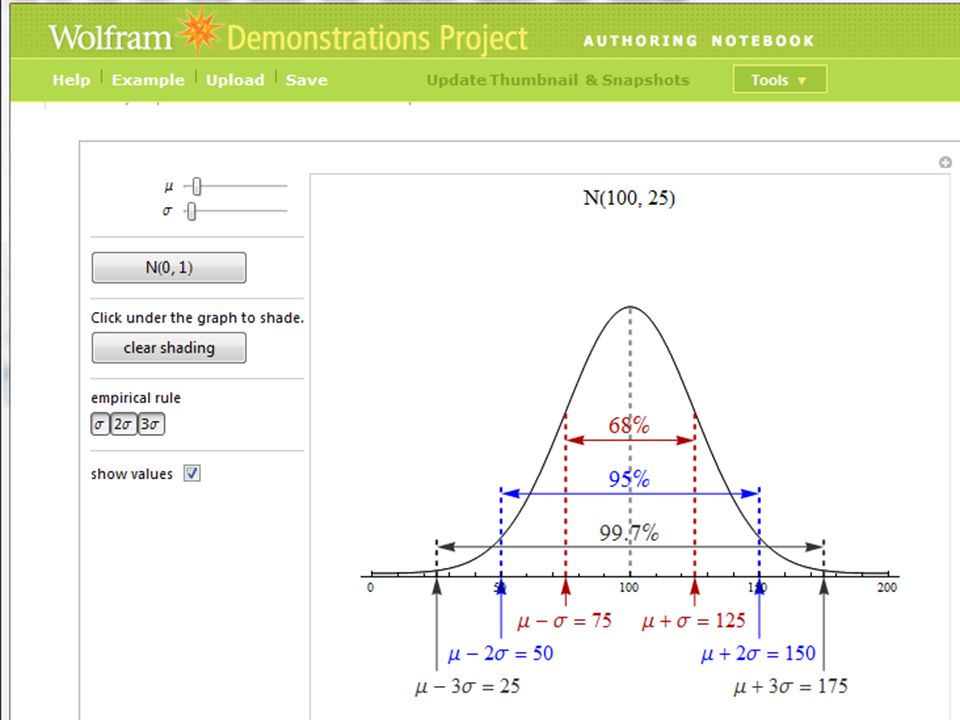
interpretare s: regola empirica se l'istogramma della distribuzione ha una forma approssimativamente campanulare: Circa il 68% delle osservazioni assume valori compresi tra e Circa il 95% delle osservazioni assume valori compresi tra e La quasi totalità delle osservazioni assume valori compresi tra e

29
s nella distribuzione di frequenze

30
dimostratore in Mathematica http://demonstrations.wolfram.com/# TheEmpiricalRuleForNormalDistributions-author

32
Esempio voto in trentesimi all’esame di statistica in una classe di 25 studenti 14 voti su 25 (56%) sono nell’intervallo compreso fra ± 1 s dalla media. nessun voto appartiene a più di 2 s dalla media

33
trasformazione lineare del punteggio in termini del numero di deviazioni standard dalla media fornisce un criterio (relativo no assoluto) per l’identificazione degli outlier essendo una trasformazione lineare, non cambia la forma della distribuzione delle osservazioni la distribuzione degli z ha media 0 e dev.st 1. alla base dell’ inferenza statistica z-score: standardizzazione

34
applicazione (1) Si supponga che i punteggi della classe siano distribuiti in maniera normale con media 65 (centesimi) e deviazione standard 10. +1sd; 75 -1sd; 55 +2sd; 85 -2sd; 45 +3sd; 95 -3sd; 35 0.000 0.025 0.050 0255075100 95% Che percentuale di studenti riceve un punteggio compreso tra 45 e 85? ~ il 95%

35
applicazione (2) Si supponga che i punteggi della classe siano distribuiti in maniera normale con media 65 (centesimi) e deviazione standard 10. +1sd; 75 -1sd; 55 +2sd; 85 -2sd; 45 +3sd; 95 -3sd; 35 0.000 0.025 0.050 0255075100 Come rispondere alla domanda: che percentuale di studenti riceve un punteggio minore/maggiore di 85? per rispondere a questa domanda mi devo riferire alla distribuzione dei punti z, ossia alla distribuzione normale standard ???

36
distribuzione normale standard: N(0;1) un punteggio è esprimibile nei termini del numero di deviazioni standard che lo separano dalla media (z) a ciascun valore della variabile x può essere quindi associato il corrispondente valore della variabile standardizzata z, ottenuto applicando la standardizzazione
 un punteggio è esprimibile nei termini del numero di deviazioni standard che lo separano dalla media (z) a ciascun valore della variabile x può essere quindi associato il corrispondente valore della variabile standardizzata z, ottenuto applicando la standardizzazione")
37
mapping N(0,1) → N(x,s) = = = = la standardizzazione consente di trovare le aree sottese alla distribuzione normale usando delle tabelle
 → N(x,s) = = = = la standardizzazione consente di trovare le aree sottese alla distribuzione normale usando delle tabelle")
38
mapping N(0,1) → N(x,s) ad esempio ad x= 85 corrisponde un z score di 2.00 = x x
 → N(x,s) ad esempio ad x= 85 corrisponde un z score di 2.00 = x x")
39
= x x Tavole N(0,1) pag 526 testo solo il 2.28% degli studenti riceve un punteggio maggiore di 85
 pag 526 testo solo il 2.28% degli studenti riceve un punteggio maggiore di 85")
40
cumulativa (z) P ( Z < z) con z si denota il [100(1 - )]-esimo percentile di N(0, 1) (z)(z) z 0.05
![cumulativa (z) P ( Z < z) con z si denota il [100(1 - )]-esimo percentile di N(0, 1) (z)(z) z 0.05](http://images.slideplayer.it/39/10884565/slides/slide_40.jpg "cumulativa (z) P ( Z < z) con z si denota il [100(1 - )]-esimo percentile di N(0, 1) (z)(z) z 0.05")
41
valori più comunemente usati z 0.05 = 1.645 z 0.025 = 1.96 z 0.005 = 2.576

42
Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 380.085 500.34500 620.44000 740.11500 860.00500 probit: mapping x → z
), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto VotoFrequenza Frequenza Cumulata Z(Freq Cum) probit: mapping x → z")
43
VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 380.085 500.34500 620.44000 740.11500 860.00500 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto
 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto")
44
VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 2.325 380.085 500.34500 620.44000 740.11500 860.00500 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto
 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto")
45
VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 2.325 380.0850.095 500.34500 620.44000 740.11500 860.00500 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto
 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto")
46
probit: mapping x → z VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 2.325 380.0850.095 500.34500 620.44000 740.11500 860.00500 Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto
 Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto")
47
VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 2.325 380.0850.095 1.310 500.34500 620.44000 740.11500 860.00500 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto
 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto")
48
VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 2.325 380.0850.095 1.310 500.345000.440 -0.151 620.44000 0.880 1.175 740.11500 0.995 2.575 860.00500 1 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto
 probit: mapping x → z Dato che la relazione che lega i punteggi x e gli z è lineare la relazione fra x e gli z-score delle proporzioni cumulate associate a ciascun x, Z(P(X < x i )), sarà lineare anch’essa Da questa relazione sarà possibile inferire i parametri della popolazione da cui il campione è stato estratto")
49
soluzione dei minimi quadrati e stima Il punto in cui la retta che meglio descrive la relazione fra punteggi e punteggi trasformati interseca l’asse delle x (i.e., z= 0) corrisponde alla stima della media Il reciproco del coefficiente angolare (1/b) da la deviazione standard capitolo 9 testo b
 corrisponde alla stima della media Il reciproco del coefficiente angolare (1/b) da la deviazione standard capitolo 9 testo b")
50
calcoliamo b e a minimizza la somma degli scarti al quadrato fra valore osservato y i e valore predetto dal modello lineare, f(x i ) (residui) z (x i,z i ) ax i + b - z i f(x,z)= ax + b x b a codevianza da tale processo di minimizzazione si può dimostrare che pag 263-270 vostro testo
 (residui) z (x i,z i ) ax i + b - z i f(x,z)= ax + b x b a codevianza da tale processo di minimizzazione si può dimostrare che pag vostro testo")
51
VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 2.325 380.0850.095 1.310 500.345000.440 -0.151 620.44000 0.880 1.175 740.11500 0.995 2.575 nel nostro caso media 50 -0.0742 -24 -12 0 12 24 -2.32 -1.31 -0.15 1.17 2.58 55.7 15.7 0.0 14.1 61.8 576 144 0 576 147.3 1440 b= = 0.1024
 nel nostro caso media b= =")
52
VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 2.325 380.0850.095 1.310 500.345000.440 -0.151 620.44000 0.880 1.175 740.11500 0.995 2.575 nel nostro caso media 50 -0.0742 -24 -12 0 12 24 -2.32 -1.31 -0.15 1.17 2.58 55.7 15.7 0.0 14.1 61.8 576 144 0 576 147.3 1440 b= = 0.1024 ; a= - 0.102 =-5.1
 nel nostro caso media b= = ; a= =-5.1")
53
verifichiamo z(f) = 0.1024x - 5.12 -5.10 -3.70 -2.30 -0.90 0.50 1.90 0255075100 Punteggio Z(fp)
 = x Punteggio Z(fp)")
54
verifichiamo z(f) = 0.1024x - 5.12 -5.10 -3.70 -2.30 -0.90 0.50 1.90 0255075100 Punteggio Z(fp) 5.12 0.1024 = 50.07 1 0.1024 = 9.78 corrispondono esattamente ai parametri della distribuzione da cui abbiamo campionato le osservazioni
 = x Punteggio Z(fp) = = 9.78 corrispondono esattamente ai parametri della distribuzione da cui abbiamo campionato le osservazioni")
55
utilità del metodo illustrato stabilità: permette di ottenere stime stabili dei parametri della distribuzione anche quando si hanno poche classi di eventi -5.10 -3.70 -2.30 -0.90 0.50 1.90 0255075100 Punteggio Z(fp) anche se vengono eliminati punti la retta non cambia e le stime rimangono invariate
 anche se vengono eliminati punti la retta non cambia e le stime rimangono invariate")
56
utilità del metodo illustrato stabilità: permette di ottenere stime stabili dei parametri della distribuzione anche quando si hanno poche classi di eventi precisione: fornisce stime più precise dei parametri di quelle ottenibili mediante l’applicazione degli indici di tendenza centrale e dispersione applicati e distribuzioni di frequenze VotoFrequenza Frequenza Cumulata Z(Freq Cum) 260.01 2.325 380.0850.095 1.310 500.345000.440 -0.151 620.44000 0.880 1.175 740.11500 0.995 2.575 0.26 3.23 17.25 27.28 8.51 6.76 122.74 862.5 1691.36 629.74 56.53 10.84
")
Presentazioni simili










>")








