Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Statistica Economica I
Università degli Studi di Siena Facoltà di Economia “R.M. GOODWIN” Corso di Statistica Economica I Laura Neri

2
MODELLO DI REGRESSIONE LINEARE SEMPLICE
Introduzione al modello di regressione lineare (da deterministico a stocastico) Modello di regressione lineare semplice (ipotesi di base, stima OLS dei parametri, stimatori BLUE, test, intervalli di confidenza, previsione, scomposizione devianza, coeff. determinazione
 Modello di regressione lineare semplice (ipotesi di base, stima OLS dei parametri, stimatori BLUE, test, intervalli di confidenza, previsione, scomposizione devianza, coeff. determinazione.")
3
RELAZIONI DI TIPO DETERMINISTICO
TRA VARIABILI VARIABILI ESPLICATIVE O INDIPENDENTI VARIABILE DIPENDENTE SE IL LEGAME È DI TIPO LINEARE ED IL NUMERO DELLE ESPLICATIVE È PARI AD UNO, IL MODELLO DIVIENE: CHE IN UN SISTEMA DI ASSI CARTESIANI RAPPRESENTA UNA RETTA CON COEFFICIENTE ANGOLARE ED INTERCETTA (ORDINATA ALL’ORIGINE)
")
4
BISETTRICE 1° e 3° QUADRANTE
y = X BISETTRICE 1° e 3° QUADRANTE Y1 Y2 X X2 Y Y5 Y4 Y3 Y2 Y1 } } } X1 X X X X

5
La vera relazione tra Y e l’insieme di covariate X può essere
approssimata tramite il modello di regressione Dove si ipotizza come l’errore casuale che rappresenta la discrepanza dell’approssimazione. Avendo introdotto il termine di errore il suddetto modello esprime una relazione STOCASTICA. Se f(.) esprime una funzione lineare, il modello di regressione è di tipo lineare e si presenta nella forma coefficienti di regressione o parametri di regressione
 esprime una funzione lineare, il modello di regressione è di tipo lineare e si presenta nella forma. coefficienti di regressione o. parametri di regressione.")
6
ANALISI DI REGRESSIONE
La regressione è sostanzialmente un metodo per investigare relazioni funzionali tra variabili. La relazione viene espressa sotto forma di equazione o modello che lega la variabile dipendente ad una o più variabili indipendenti. ESEMPIO: se vogliamo verificare se il consumo di sigarette è legato a variabili demografiche individuali ed a variabili socioeconomiche, possiamo specificare come Y il numero di sigarette fumate al giorno e come insieme di variabili X, l’età dell’individuo, il genere, il reddito, il titolo di studio, ecc. Se osserviamo tali variabili su un campione di n unità statistiche, avremo n osservazioni per ognuna delle variabili osservate

7
IL MODELLO DI REGRESSIONE
LINEARE SEMPLICE La relazione tra la variabile dipendente (o di risposta) e la variabile indipendente è espressa da un modello lineare Dove rappresentano i coefficienti di regressione o parametri e rappresenta la componente casuale del modello. Si assume che relativamente alle osservazioni campionarie tra Y e X vi sia approssimativamente un legame lineare. Y X Y1 X1 … Yn Xn Per ogni singola osservazione i il modello può essere scritto così
 e la variabile indipendente è espressa da un modello lineare. Dove rappresentano i coefficienti di regressione o parametri e rappresenta la componente casuale del modello. Si assume che relativamente alle osservazioni campionarie tra Y e X vi sia approssimativamente un legame lineare. Y. X. Y1. X1. … Yn. Xn. Per ogni singola osservazione i il modello può essere scritto così.")
8
Scatter plot A questo punto l’obiettivo è determinare l’equazione della retta che meglio approssima i punti di coordinate (X, Y). Per determinare l’equazione della retta è sufficiente stimare I parametri intercetta coefficiente angolare.
. Per determinare l’equazione della retta. è sufficiente stimare I parametri intercetta coefficiente angolare.")
9
Per questo si adotta il METODO DEI
MINIMI QUADRATI ORDINARI (Ordinary Least Square-OLS) BASATO SULLA MINIMIZZAZIONE DELLA FUNZIONE AUSILIARIA: Il minimo della funzione ausiliaria si ottiene derivando rispetto ai parametri incogniti , ponendo pari a zero le due equazioni e risolvendo il sistema. Le soluzioni che si ottengono sono:
 BASATO SULLA MINIMIZZAZIONE DELLA FUNZIONE AUSILIARIA: Il minimo della funzione ausiliaria si ottiene derivando rispetto ai parametri incogniti , ponendo pari a zero le due equazioni e risolvendo il sistema. Le soluzioni che si ottengono sono:")
10
CON Tornando alla natura probabilistica del modello ed all’esempio del consumo individuale di sigarette. Se ad esempio fosse Y il numero di sigarette fumate al giorno e X l’età dell’individuo, è plausibile che, nel campione osservato, per ogni valore di X (per ogni età) vi siano molti valori di Y (numero di sigarette fumate al giorno). Quando, per questo esempio, si specifica un modello probabilistico è come se si assumesse che ogni età, il consumo di sigarette varia in ‘modo casuale’. Cerchiamo di approfondire questa idea.
 vi siano molti valori di Y (numero di sigarette fumate al giorno). Quando, per questo esempio, si specifica un modello probabilistico è come se si assumesse che ogni età, il consumo di sigarette varia in ‘modo casuale’. Cerchiamo di approfondire questa idea.")
11
UN MODELLO DI TIPO STOCASTICO SI ADEGUA MOLTO MEGLIO DI UN MODELLO DETERMINISTICO AL TIPO DI REALTÀ RAPPRESENTATA DA n COPPIE DI OSSERVAZIONI Xi E Yi NON ESATTAMENTE ALLINEATE SU DI UNA RETTA. OVVIAMENTE L’INTRODUZIONE DI PROVOCA NOTEVOLI COMPLICAZIONI, MA ANCHE RISULTATI FORTEMENTE PIÙ UTILI E DENSI DI SIGNIFICATO. PRIMA CONSIDERAZIONE: COME SI GIUSTIFICA L?INTRODUZIONE DELLA COMPONENTE STOCASTICA? 1.1 PRESENZA DI ERRORI NEL MODELLO 1.2 LIMITATEZZA NEL NUMERO DELLE VARIABILI ESPLICATIVE (REGRESSORI); 1.3 CASUALITÀ DERIVANTE PREVALENTEMENTE DALLA RILEVAZIONE CAMPIONARIA DELLE OSSERVAZIONI EMPIRICHE; 1.4 PRESENZA DI ERRORI DI MISURA
; 1.3 CASUALITÀ DERIVANTE PREVALENTEMENTE DALLA RILEVAZIONE CAMPIONARIA DELLE OSSERVAZIONI EMPIRICHE; 1.4 PRESENZA DI ERRORI DI MISURA.")
12
SECONDA CONSIDERAZIONE:
L’INTRODUZIONE DI PROVOCA LA RIDEFINIZIONE DI Y IN TERMINI DI VARIABILE CASUALE (V.C.) NON SOLO, MA OGNI VALORE ESPRESSO IN FUNZIONE DI Y, DIVIENA ANCH’ESSO V.C. TERZA CONSIDERAZIONE: PER POTER UTILIZZARE AL MASSIMO LA PORTATA INTERPRETATIVA ED ESPLICATIVA DI UN MODELLO LINEARE STOCASTICO, DEVONO ESSERE INTRODOTTE ALCUNE ASSUNZIONI: 1. LINEARITÀ DELLA RELAZIONE FUNZIONALE 2. NATURA DETERMINISTICA DEI REGRESSORI 3. NORMALITÀ DELLA DISTRIBUZIONE DEI TERMINI DI ERRORE per ogni i=1….n 4. VALORE ATTESO NULLO DI TALI ERRORI: 5. OMOSCHEDASTICITÀ DEI MEDESIMI: Per ogni i diverso da j DATA LA NATURA NORMALE DEGLI ASSICURA ANCHE L’INDIPENDENZA
 NON SOLO, MA OGNI VALORE ESPRESSO IN FUNZIONE DI Y, DIVIENA ANCH’ESSO V.C. TERZA CONSIDERAZIONE: PER POTER UTILIZZARE AL MASSIMO LA PORTATA INTERPRETATIVA ED ESPLICATIVA DI UN MODELLO LINEARE STOCASTICO, DEVONO ESSERE INTRODOTTE ALCUNE ASSUNZIONI: 1. LINEARITÀ DELLA RELAZIONE FUNZIONALE. 2. NATURA DETERMINISTICA DEI REGRESSORI. 3. NORMALITÀ DELLA DISTRIBUZIONE DEI TERMINI DI ERRORE per ogni i=1….n. 4. VALORE ATTESO NULLO DI TALI ERRORI: 5. OMOSCHEDASTICITÀ DEI MEDESIMI: Per ogni i diverso da j. DATA LA NATURA NORMALE DEGLI ASSICURA ANCHE L’INDIPENDENZA.")
13
ANCORA SULLE ASSUNZIONI
LA 1. È ABBASTANZA BANALE ANCHE SE SOLO PARZIALMENTE REALISTICA. VEDREMO CHE MOLTE RELAZIONI NON LINEARI POSSONO RIDURSI, CON OPPORTUNE TRASFORMAZIONI, A RELAZIONI LINEARI. LA 2. È FORSE LA PIÙ IRREALISTICA IN AMBITO SOCIO-ECONOMICO MA MOLTO UTILE A FINI COMPUTAZIONALI infatti comporta: LA 3. DERIVA DALLA TEORIA DELLA PROBABILITÀ SULLA DISTRIBUZIONE DEGLI ERRORI. DATE LE CARATTERISTICHE DALLA V.C. NORMALE (CONTINUITÀ, DEFINIZIONE NEL DOMINIO INFINITO, SIMMETRIA, FORMA CAMPANULARE) RISULTA PLAUSIILE. LA 4. CI ASSICURA CHE L’ERRORE MASSIMAMENTE PROBABILE (DAL MOMENTO CHE IN UNA V.C. NORMALE IL VALOR MEDIO COINCIDE CON IL VALORE MODALE) È QUELLO DI ENTITÀ ZERO. SI NOTI COMUNQUE CHE SE SI PUO’ SPECIFICARE IL MODELLO IN MODO DA TORNARE ALL’ASSUNZIONE
 RISULTA PLAUSIILE. LA 4. CI ASSICURA CHE L’ERRORE MASSIMAMENTE PROBABILE (DAL MOMENTO CHE IN UNA V.C. NORMALE IL VALOR MEDIO COINCIDE CON IL VALORE MODALE) È QUELLO DI ENTITÀ ZERO. SI NOTI COMUNQUE CHE SE. SI PUO’ SPECIFICARE IL MODELLO IN MODO DA TORNARE ALL’ASSUNZIONE.")
14
CON E CIOÈ SI PUO’ SEMPRE DEFINIRE UN MODELLO CON MEDIA NULLA DEGLI ERRORI. LA 5., POCO REALISTICA IN CASO DI OSSERVAZIONI “CROSS SECTION”, COMPORTA PROBLEMI DI ENTITÀ RILEVANTE, SE TRALASCIATA. ANALIZZEREMO COMUNQUE A FONDO TALE CIRCOSTANZA. LA 6., POCO REALISTICA IN CASO DI OSSERVAZIONI DIPENDENTI DAL TEMPO (SERIE STORICHE), COMPORTA PROBLEMI RILEVANTI SE TRALASCIATA.
, COMPORTA PROBLEMI RILEVANTI SE TRALASCIATA.")
15
Y Y X X ETEROSCHEDASTICITÀ VARIANZA FUNZIONE VARIANZA FUNZIONE DECRESCENTE DI X CRESCENTE DI X Yt Yt Xt Xt AUTOCORRELAZIONE POSITIVA NEGATIVA

16
Esaminiamo le caratteristiche degli stimatori dei parametri incogniti della retta di regressione ottenuti con OLS. Per questo ricordiamo che le stime ottenute derivano da un’ennupla di osservazioni campionarie (estratte con campionamento probabilistico da una popolazione target) osservate sulle variabili (X, Y). Se estraessimo un altro campione dalla stessa popolazione di riferimento, il campione sarebbe diverso dal precedente e le stime dei parametri sarebbero diverse, quindi si può dire che quelle stime sono associate ad una variabile casuale. Concludendo quando si scrive si intende: i) il coefficiente angolare della retta di regressione, stimato a partire da una determinata un’ennupla di osservazioni campionarie, ii) lo stimatore che segue una certa distribuzione di probabilità.
 osservate sulle variabili (X, Y). Se estraessimo un altro campione dalla stessa popolazione di riferimento, il campione sarebbe diverso dal precedente e le stime dei parametri sarebbero diverse, quindi si può dire che quelle stime sono associate ad una variabile casuale. Concludendo quando si scrive si intende: i) il coefficiente angolare della retta di regressione, stimato a partire da una determinata un’ennupla di osservazioni campionarie, ii) lo stimatore che segue una certa distribuzione di probabilità.")
17
SI CONSIDERINO GLI STIMATORI OLS
TEOREMA DI GAUSS-MARKOV : Date le assunzioni 1., 2., 4., 5., gli stimatori OLS sono i MIGLIORI (più efficienti) STIMATORI LINEARI e CORRETTI (BLUE – BEST LINEAR UNBIASED ESTIMATOR) dei parametri Il senso del teorema è che tali stimatori sono quelli a varianza minima nella classe degli stimatori lineari e corretti.
 STIMATORI LINEARI e CORRETTI (BLUE – BEST LINEAR UNBIASED ESTIMATOR) dei parametri. Il senso del teorema è che tali stimatori sono quelli a varianza minima nella classe degli stimatori lineari e corretti.")
18
Dimostrazione del TEOREMA DI GAUSS-MARKOV:
SI CONSIDERI LO STIMATORE OLS DI β E LO SI RISCRIVA COME: LINEARITA’ DELLO STIMATORE OSSERVAZIONI SISTEMA DI PESI CON PROPRIETÀ:

19
SI DIMOSTRA ANALOGAMENTE CHE:
OSSERVAZIONI PESI COSTANTI MEDIA STIMATORI CORRETTEZZA DELLO STIMATORE

20
+ ANALOGAMENTE SI OTTIENE PER CHE
QUINDI E SONO ENTRAMBI STIMATORI CORRETTI VARIANZA STIMATORI +

21
STIMATORI OLS COME BLUE
Altro stimatore lineare SIA CON QUINDI SE E SOLO SE E stimatore corretto

22
QUINDI OVVERO HA VARIANZA MINIMA NELLA CLASSE DEGLI STIMATORI LINEARI E CORRETTI. ANALOGHI RISULTATI SI OTTENGONO PER SI PUÒ PERVENIRE AI RISULTATI MINIMIZZANDO CON I VINCOLI

23
DISTRIBUZIONE DEGLI STIMATORI OLS
Poiché è una media pesata di y e le y sono normalmente distribuite, ha una distribuzione normale OLS = ML OLS SONO MIGLIORI, LINEARI, CORRETTI E ASINTOTICAMENTE CONSISTENTI analogamente In virtù del Teorema del Limite Centrale, anche se le y non fossero distribuite normalmente (sotto condizioni abbastanza generali) si avrebbe comunque una distribuzione asintoticamente normale per i suddetti parametri
 si avrebbe comunque una distribuzione asintoticamente normale per i suddetti parametri.")
24
STIMA DELLA VARIANZA DELL’ERRORE
L’analisi non è ancora completa, resta da stimare la varianza del termine stocastico del modello. Il computo di questo stimatore coinvolge l’applicazione del Metodo della Massima Verosimiglianza (che omettiamo). Riportiamo direttamente lo stimatore varianza residua rappresenta il residuo La varianza residua è uno stimatore corretto e consistente della varianza del termine di errore.
. Riportiamo direttamente lo stimatore varianza residua. rappresenta il residuo. La varianza residua è uno stimatore corretto e consistente della varianza del termine di errore.")
25
OSSERVAZIONE Perché il denominatore della varianza residua deve essere pari a (n-2) per ottenere uno stimatore corretto? Perché le osservazioni campionarie sulle quali si basa la stima sono n, ma la stima dell’intercetta e del coefficiente angolare impongono 2 vincoli, quindi restano (n-2) gradi di libertà.
 gradi di libertà.")
26
Osservazione sulla FUNZIONE DIRETTA DELLA ;
ERRORI MOLTO VARIABILI PROVOCANO DIMINUZIONE DI PRECISIONE E DI AFFIDABILITÀ PER . FUNZIONE INVERSA DELLA ; SE LE Xi SONO CONCENTRATE IN UN PICCOLO INTERVALLO, PEGGIORA LA QUALITÀ DI . Xi

27
STANDARD ERROR DEGLI STIMATORI OLS
Avendo ottenuto una stima della varianza del termine stocastico del modello di regressione si sostituisce nell’espressione della varianza degli stimatori OLS per ottenere gli errori standard (standard error) Gli errori standard FORNISCONO UNA MISURA DELLA DISPERSIONE DELLE STIME INTORNO ALLE RISPETTIVE MEDIE.
 Gli errori standard FORNISCONO UNA MISURA DELLA DISPERSIONE DELLE STIME INTORNO ALLE RISPETTIVE MEDIE.")
28
INFERENZA NEL MODELLO DI REGRESSIONE LINEARE SEMPLICE
E’ necessaria l’ipotesi di normalità dei termini stocastici Interpretazione dell’intervallo di confidenza, fissato il livello di significatività (ad esempio per ). Se estraessi più campioni; ognuno fornirebbe valori diversi della stima OLS di e quindi diversi intervalli di confidenza; l’(1-)% di questi intervalli includerebbe , mentre solo nell’ % dei casi devierebbe da per più di un certo .
. Se estraessi più campioni; ognuno fornirebbe valori diversi della stima OLS di e quindi diversi intervalli di confidenza; l’(1-)% di questi intervalli includerebbe , mentre solo nell’ % dei casi devierebbe da per più di un certo .")
29
Verifica d’ipotesi, fissato il livello di significatività (ad esempio per ).
Sia data una congettura (ipotesi nulla), che si assume vera, attraverso la verifica d’ipotesi si valuta l’entità della discrepanza tra quanto osservato nei dati campionari e quanto previsto sotto ipotesi nulla. Se, fissato il livello di significatività , la “discrepanza” è significativa l’ipotesi nulla viene rifiutata, altrimenti l’ipotesi nulla non può essere rifiutata.
, che si assume vera, attraverso la verifica d’ipotesi si valuta l’entità della discrepanza tra quanto osservato nei dati campionari e quanto previsto sotto ipotesi nulla. Se, fissato il livello di significatività , la discrepanza è significativa l’ipotesi nulla viene rifiutata, altrimenti l’ipotesi nulla non può essere rifiutata.")
30
INTERVALLI DI CONFIDENZA
SICCOME standardizzando /g.l. OVVERO: T-Student con (n-2) g.l.
 g.l.")
31
Quindi l’intervallo di confidenza per
all’(1-)% si determina nel seguente modo: Limite inferiore Limite superiore In sostanza l’intervallo di confidenza fornisce il range di valori in cui verosimilmente cade il vero valore del parametro
% si determina nel seguente modo: Limite inferiore. Limite superiore. In sostanza l’intervallo di confidenza fornisce il range di valori in cui verosimilmente cade il vero valore del parametro.")
32
Regione di Accettazione o di Rifiuto del test
VERIFICA DI IPOTESI Fissato il livello di significatività Ipotesi nulla Ipotesi alternativa Statistica test Regione di Accettazione o di Rifiuto del test

33
VERIFICA DI IPOTESI: SIGNIFICATIVITA’ di
NON ESISTE RELAZIONE LINEARE TRA X ED Y STATISTICA TEST REGIONE CRITICA SI RESPINGE L’IPOTESI NULLA SE: REGOLA D’ORO QUANDO n è grande, t-student ad una Normale, quindi se fissiamo il 5% come livello di significatività, possiamo adottare la “regola d’oro”: se ALLORA SI RIFIUTA L’IPOTESI NULLA:

34
VERIFICA DI IPOTESI H0: = 0
Se 0 è una costante si può verificare: H0: = 0 STATISTICA TEST SI RESPINGE L’IPOTESI NULLA SE: N.B. ancora una volta se n è grande la distribuzione t-Student si approssima alla distribuzione normale standardizzata

35
Significato del coefficiente
esprime di quanto varia mediamente Y in conseguenza di una variazione unitaria di X. Se >0, al crescere di X cresce anche Y (relazione lineare diretta) Se <0, al crescere di X, Y decresce (relazione lineare inversa)
 Se <0, al crescere di X, Y decresce (relazione lineare inversa)")
36
REGRESSIONE E CORRELAZIONE
N COPPIE DI PUNTI Y Q P V i=1, …, N S R B T A X I QUADRANTE: IL PRODOTTO II QUADRANTE: IL PRODOTTO III QUADRANTE: IL PRODOTTO IV QUADRANTE: IL PRODOTTO

37
COEFFICIENTE DI CORRELAZIONE DI BRAVAIS-PEARSON
LA FUNZIONE MISURA l’intensità del LEGAME LINEARE TRA X ED Y. COVARIANZA COEFFICIENTE DI CORRELAZIONE DI BRAVAIS-PEARSON R è un indice relativo, ossia non dipende dall’unità di misura delle variabili X, Y

38
SE SULLE N COPPIE DI OSSERVAZIONI STIMIAMO UN MODELLO LINEARE
SICCOME ALLORA ABBIAMO: MISURA DEL LEGAME LINEARE TRA X ED Y MISURA DELLA DIPENDENZA LINEARE DI Y DA X Osservazione: SE SI È ACCERTATA L’ESISTENZA DI UN LEGAME LINEARE SONO POSSIBILI DUE TIPI DI DIPENDENZA LINEARE: QUELLO DI Y DA X E QUELLO DI X DA Y; CONSIDERAZIONE: NELL’ANALISI DI REGRESSIONE È NECESSARIO DECIDERE “EX ANTE” QUALE TIPO DI DIPENDENZA SI VUOLE CONSIDERARE;

39
CONSIDERAZIONE: L’ANALISI DI CORRELAZIONE PRESCINDE DA LEGAMI CAUSALI; QUELLA DI REGRESSIONE È BASATA SUI LEGAMI CAUSALI; CONSIDERAZIONE: CORRELAZIONE E CAUSALITÀ. ESEMPIO: NUMERO DI MALATI DI UNA DATA PATOLOGIA PER ZONA (X), NUMERO DI MEDICI PRESENTI PER ZONA (Y). SE r INDICA ALTA CORRELAZIONE QUESTO NON SIGNIFICA CHE UN ELEVATO NUMERO DI MEDICI CAUSA UN ELEVATO NUMERO DI MALATI MA SIGNIFICA SOLO CHE TRA LE DUE VARIABILI ESISTE UN ALTO LEGAME LINEARE;
, NUMERO DI MEDICI PRESENTI PER ZONA (Y). SE r INDICA ALTA CORRELAZIONE QUESTO NON SIGNIFICA CHE UN ELEVATO NUMERO DI MEDICI CAUSA UN ELEVATO NUMERO DI MALATI MA SIGNIFICA SOLO CHE TRA LE DUE VARIABILI ESISTE UN ALTO LEGAME LINEARE;")
40
• • • • • • • • • • • • • • • • • PROPRIETÀ DEI RESIDUI Y P(xi,yi) Q R
RESIDUO S X Sono somme degli scarti dalla media, quindi sono zero

42
SCOMPOSIZIONE DELLA DEVIANZA
Dal precedente grafico: DEVIANZA DEVIANZA DEVIANZA TOTALE RESIDUA SPIEGATA TSS = RSS + ESS Total Sum = Residual Sum Explained Sum Square Square Square

43
Dividendo tutto per TSS si ottiene:
Si definisce COEFFICIENTE DI DETERMINAZIONE Tale coefficiente rappresenta la proporzione di devianza totale spiegata dal modello di regressione lineare di Y su X. Dato che Quando il modello non spiega niente della variabilità di Y Tutta la variabilità di Y è spiegata dal modello

44
SE R²=0 SIGNIFICA CHE IL CONTRIBUTO ESPLICATIVO ALLA DEVIANZA COMPLESSIVA APPORTATO DAL MODELLO È IDENTICAMENTE NULLO; LA DEVIANZA COMPLESSIVA È SOLO SPIEGATA DALLA COMPONENTE CASUALE (RESIDUO). SE R²=1 TUTTI GLI N VALORI EMPIRICI OSSERVATI GIACCIONO ESATTAMENTE SULLA RETTA DI REGRESSIONE; IL CONTRIBUTO ALLA DEVIANZA COMPLESSIVA È SOLO FORNITO DAL MODELLO. NEI CASI INTERMEDI, QUANTO PIÙ R² È PROSSIMO AD UNO O A ZERO, TANTO PIÙ/MENO LA VARIABILITÀ COMPLESSIVA È SPIEGATA DAL MODELLO PRESCELTO. AD ESEMPIO, UN VALORE r²=0.80 SIGNIFICA CHE IL MODELLO PRESCELTO RIESCE A SPIEGARE L’80 PER CENTO DELLA VARIABILITÀ COMPLESSIVA.

45
Il coefficiente di determinazione rappresenta un indice di fitting (da prendere con cautela!), in quanto misura l’adattabilità del modello specificato ai dati. Vediamo che relazione c’è tra ed i parametri della retta di regressione. Per fare questo consideriamo il modello in forma di scarti Ogni osservazione della variabile dipendente può essere scomposta in

46
Ne consegue che QUINDI IL COEFFICIENTE DI DETERMINAZIONE È UGUALE AL QUADRATO DEL COEFFICIENTE DI CORRELAZIONE. UNA SEMPLICE ED EFFICIENTE RELAZIONE PER IL COEFFICIENTE DI DETERMINAZIONE SI PUÒ RICAVARE ANCHE DA:

47
ANALISI DELLA VARIANZA (ANOVA)
La scomposizione O equivalentemente MOSTRA LA SCOMPOSIZIONE DELLA VARIABILITÀ TOTALE (in forma di DEVIANZA) NEI CONTRIBUTI della COMPONENTE DI ERRORE e del MODELLO specificato. INOLTRE: SAPPIAMO CHE:
 NEI CONTRIBUTI della COMPONENTE DI ERRORE e del MODELLO specificato. INOLTRE: SAPPIAMO CHE:")
48
Pertanto per verificare l’ipotesi
Quadrato di una N(0,1) ALLORA: SI PUÒ DIMOSTRARE CHE: Pertanto per verificare l’ipotesi Si può utilizzare la suddetta statistica test che sotto ipotesi nulla è Rapporto tra Chi-Quadrato divise per i propri g.l.
 ALLORA: SI PUÒ DIMOSTRARE CHE: Pertanto per verificare l’ipotesi. Si può utilizzare la suddetta statistica test che sotto ipotesi nulla è. Rapporto tra Chi-Quadrato divise per i propri g.l.")
49
Intuitivamente un forte legame lineare tra X e Y determinerà valori elevati per la statistica testbontà del modello. Pertanto valori grandi della statistica test portano al rifiuto dell’ipotesi nulla. Formalmente, se viene rifiutata, Valore teorico Valore empirico Osservazione: nel caso del modello di regressione lineare semplice, applicare il test t o F è equivalente, in entrambi i casi si verifica la significatività dell’unico parametro di regressione, ma nel caso del modello di regressione lineare multipla il test F servirà per verificare la ‘bontà’ del modello nel suo complesso e quindi la significatività congiunta di tutti i parametri di regressione.

50
TAVOLA ANOVA MODELLO 1 RESIDUO (n-2) TOTALE (n-1)
CAUSA DEVIANZE GRADI DI STIME CORRETTE VARIAZIONE LIBERTÀ DELLA VARIANZA MODELLO RESIDUO (n-2) TOTALE (n-1)
 TOTALE (n-1)")
51
PREVISIONE Il modello di regressione stimato spesso viene utilizzato a fini previsivi, ovvero per stimare il valore della variabile dipendente che corrisponde ad un determinato valore della variabile indipendente Lo standard error di tale valore previsto è Pertanto i limiti dell’intervallo di confidenza per il valore previsto, fissato un livello di confidenza pari a 1-

52
Si osservi che il valore dello s. e
Si osservi che il valore dello s.e. aumenta al crescere della distanza tra X0 e il valor medio di X, pertanto la qualità della previsione diverrà sempre peggiore. Inoltre può accadere che la linearità della relazione tra Y e X sia limitata alla nuvola di punti osservati e che fuori tale relazione non sia valida, pertanto può essere totalmente fuorviante prevedere un valore di Y partendo da un valore di X che è al di fuori del range dei valori osservati

53
} ESEMPIO NUMERICO Y 0 X ANNI Yi Xi yi xi xiyi xi²
n= Σ= Σ= Σ= Σ= MEDIAy= MEDIAx=519.2 Y→ INCIDENTI STRADALI (X1000) X →VEICOLI CIRCOLANTI (X1000) Y } X
 X →VEICOLI CIRCOLANTI (X1000) Y. } 0 X.")
54
FONTE SS DF MS MODELLO RESIDUO TOTALE ; 95% INTERVALLO DI CONFIDENZA 95 VOLTE SU 100 IL VALORE DI β È COMPRESO TRA 0.25 E 0.37

55
VERIFICA D’IPOTESI DISGIUNTA PER β
LEGAME LINEARE POSITIVO E MOLTO ELEVATO, PARI AL 97% DEL MASSIMO VALORE POSSIBILE VERIFICA D’IPOTESI DISGIUNTA PER β È RESPINTA Quindi la variabile veicoli circolanti risulta significativa

Presentazioni simili
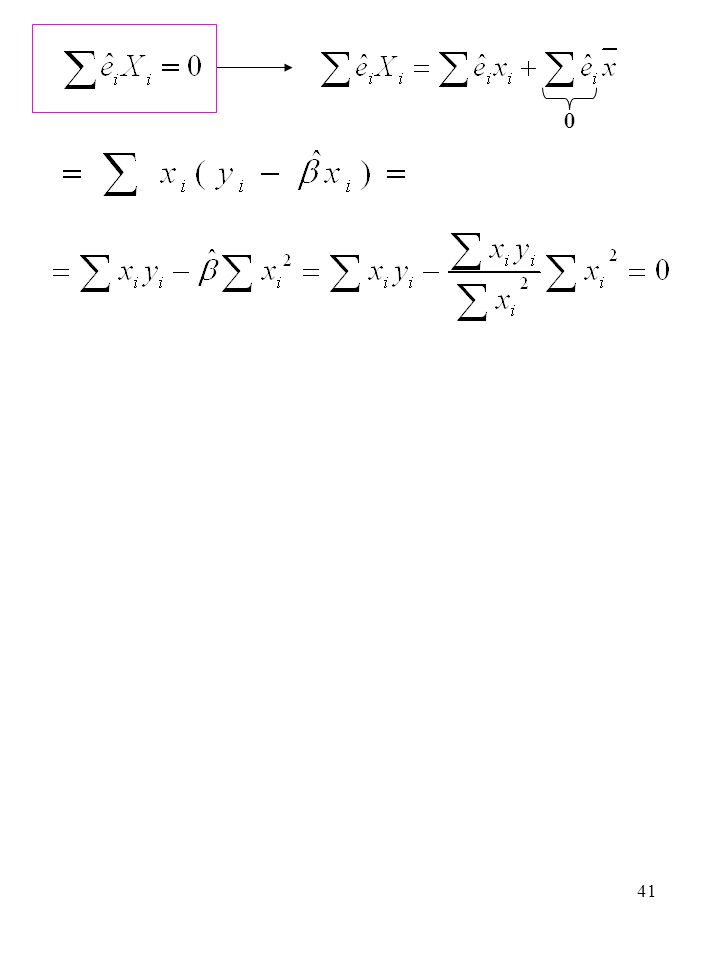
 e nel verificare se con i dati a disposizione è possibile rifiutarla o no.>")

 GLI INTERVALLI DI CONFIDENZA>")
















>")