Scaricare la presentazione
1
EPG di Metodologia della ricerca e Tecniche Multivariate dei dati
Dott.ssa Paola Grassi

2
LED edizioni universitarie 2006
Programma del corso Introduzione al software SPSS Trattamento preliminare dei dati La regressione lineare L’analisi fattoriale L’analisi della varianza. Testo consigliato Barbaranelli C., “Analisi dei dati con SPSS II. Le analisi multivariate.” LED edizioni universitarie 2006

3
Date lezioni Aula informatica Sabato 21 gennaio ore 9,00 – 13,00
Venerdì gennaio ore 15,00 – 19,00 Sabato gennaio ore 9,00 – 13,00 Sabato febbraio ore 9,00 – 13,00 Aula informatica

4
SPSS è un software statistico che permette di:
Cosa è SPSS (Statistical Package for Social Science) SPSS è un software statistico che permette di: Inserire ed importare i dati; Di eseguire analisi statistiche, di illustrare i risultati anche tramite rappresentazione grafica. SPSS è composto da finestre, aventi ciascuna differenti funzioni: Editor dei Dati; Output – Viewer; Syntax.
 SPSS è un software statistico che permette di: Inserire ed importare i dati; Di eseguire analisi statistiche, di illustrare i risultati anche tramite rappresentazione grafica. SPSS è composto da finestre, aventi ciascuna differenti funzioni: Editor dei Dati; Output – Viewer; Syntax.")
5
SPSS è un programma statistico studiato per soddisfare le esigenze di elaborazione dati nei seguenti settori applicativi: Psicologia Sociologia e scienza politica Medicina/biologia Analisi/ricerche di mercato Può eseguire le elaborazioni dati riguardanti le seguenti tecniche di analisi: analisi monovariata analisi bivariata analisi multivariata test statistici parametrici e non parametrici analisi di serie temporali funzioni di sopravvivenza modelli lineari

6
Per inserire i dati si deve avviare la schermata iniziale e selezionare dal menù la voce “inserimento dati”.

7
Per passare dalla modalità visualizzazione dati a quella di visualizzazione delle variabili oppure passare alla barra di stato o degli strumento o modificare il carattere Per aprire, salvare, stampare e chiudere il file. Contiene tutti i comandi per definire le variabili, per selezionare e richiamare i dati o le variabili in esame, per ordinare le variabili in senso crescente o decrescente, ecc. Per selezionare, copiare e tagliare parte dei dati

8
Per di creare nuove variabili, effettuare una serie di calcoli
sulle variabili o di modificare le variabili (come nel caso del trattamento dei dati mancanti). per eseguire una serie di analisi dei dati. Permette di definire alcune funzioni per l’esecuzione di alcune procedure statistiche. Per scegliere e costruire i grafici.
. per eseguire una serie di analisi dei dati. Permette di definire alcune funzioni per l’esecuzione di alcune procedure statistiche. Per scegliere e costruire i grafici.")
9
Barra degli strumenti Barra dei menù Barra di stato Spostarsi sul post-it “visualizzazione variabili” per la generazione delle stesse imputando, in sequenza, il nome assegnato e modificando, eventualmente, le caratteristiche impostate automaticamente. Permette di visualizzare i dati già imputati relativi ad una variabile.

10
La schermata ottenuta con “visualizzazione variabili” permette di inserire:
Nome della variabile composto da max 8 caratteri. Numero di caratteri usati per visualizzare la variabile Per descrivere meglio le categorie numeriche di variabili che invece non sono numeriche

11
La schermata ottenuta con “visualizzazione variabili” permette di inserire:
Per specificare meglio il significato della variabile (max 256 caratteri) Indica quante cifre decimali sono visualizzate Per specificare i valori delle variabili che sono considerati indicatori di “valori mancanti” Si possono utilizzare: la stessa grandezza dei valori validi della variabile (media) oppure numeri fuori dalla scala della variabile (si usa preferibilmente il numero 9 0 il 99 o 999)
 Indica quante cifre decimali. sono visualizzate. Per specificare i valori delle variabili che sono considerati indicatori di valori mancanti Si possono utilizzare: la stessa grandezza dei valori validi della variabile (media) oppure numeri fuori dalla scala della variabile (si usa preferibilmente il numero 9 0 il 99 o 999)")
12
Creazione delle variabili relative al questionario

13
È possibile attribuire ai valori stringa o numerici delle variabili delle etichette, per esteso, che compariranno nell’output anziché i valori assegnati. Ad esempio maschio anziché M

14
La struttura dati è pronta per l’inserimento manuale

15
Spostarsi, quindi sul post-it “visualizzazione dati” per inserire i valori di ciascuna variabile e per visualizzarli.

16
Cosa si può fare con SPSS
E’ NECESSARIO: Specificare il modello teorico alla base della ricerca, lo strumento usato e le scale di misura; Corretta codifica dei dati Scelta del programma per l’inserimento dati (SPSS, Excel,…) INSERIMENTO DEI DATI E CREAZIONE DI FILE DATI. Permette di controllare errori di inserimento dei dati, la presenza di dati mancanti, di outlier mediante l’analisi delle frequenze. PULIZIA DEI DATI:
 INSERIMENTO DEI DATI E CREAZIONE DI FILE DATI. Permette di controllare errori di. inserimento dei dati, la presenza di. dati mancanti, di outlier mediante. l’analisi delle frequenze. PULIZIA DEI DATI:")
17
TRASFORMAZIONE DEI DATI: CALCOLO DELLE STATISTICHE DESCRITTIVE:
Permette di ottenere delle nuove variabili effettuando delle operazioni o trasformazioni sulle variabili pre-esistenti. TRASFORMAZIONE DEI DATI: Per ciascuna variabile si possono calcolare le statistiche descrittive quali: media, varianza, deviazione standard. Permette di verificare se i dati si distribuiscono normalmente CALCOLO DELLE STATISTICHE DESCRITTIVE:

18
ANALISI STATISTICHE: CORRELAZIONE; ATTENDIBILITA’; DESCRITTIVE;
ANALISI DELLA VARIANZA; ANALISI FATTORIALE; REGRESSIONE ANALISI STATISTICHE:

19
Inserimento dati e creazioni di un file con SPSS
Di norma in un file di dati vengono inseriti i valori relativi alle codifiche socio-anagrafiche dei partecipanti alla ricerca. Ad esempio: genere, età, provenienza, stato civile, livello socio-economico, n° figli a carico etc. Questo genere di variabili permettono, in genere, di rilevare differenze o uguaglianze sulle variabili metriche in dipendenza dell’appartenenza a gruppi differenti determinati a priori. Tali variabili necessitano di una codifica preliminare di tipo stringa o numerica definita dallo sperimentatore. Si tenga presente che alcune procedure di analisi ammettono soltanto codifiche numeriche e non di tipo stringa (ad esempio l’analisi di varianza).
.")
20
Le Scala di misura possono essere:
Successivamente vanno generate le variabili numeriche, o scale, relative allo strumento impiegato. Le Scala di misura possono essere: Nominale: i valori rappresentano categorie senza alcun ordine intrinseco (Sesso, Professione,….); Ordinale i valori rappresentano categorie con qualche ordine intrinseco (basso/medio/alto); Ad Intervalli i valori permettono di stabilire una relazione di distanza tra più oggetti misurati, a partire da uno 0 arbitrario e stabilendo un’unità di misura costante; A Rapporti i valori permettono di effettuare operazioni aritmetiche, avendo come origine uno 0 assoluto;
; Ordinale i valori rappresentano categorie con qualche. ordine intrinseco (basso/medio/alto); Ad Intervalli i valori permettono di stabilire una relazione di distanza tra più oggetti misurati, a partire da. uno 0 arbitrario e stabilendo un’unità di misura. costante; A Rapporti i valori permettono di effettuare operazioni aritmetiche, avendo come origine uno 0 assoluto;")
21
Tali scale vanno codificate esclusivamente con valori numerici e possono essere:
binarie (vero/falso, accordo/disaccordo, scale di Rasch) che è corretto trattare come ordinali (con valori diversi dalla coppia da 0-1 la quale, invece, possiede caratteristiche metriche delle scale ad intervallo); politomiche (scale di Gutmann, Likert) che vengono codificate da SPSS come scale di tipo ordinale; continue (che ammettono valori decimali quali altezza, peso, indice di massa corporea).
 che è corretto trattare come ordinali (con valori diversi dalla coppia da 0-1 la quale, invece, possiede caratteristiche metriche delle scale ad intervallo); politomiche (scale di Gutmann, Likert) che vengono codificate da SPSS come scale di tipo ordinale; continue (che ammettono valori decimali quali altezza, peso, indice di massa corporea).")
22
Organizzazione generale del file-dati:
Righe: ciascuna riga del file di dati raccoglie le informazioni inerenti ogni singolo soggetto lungo l’intera collezione di variabili indagate che assume il nome di “data record”. Il numero di campi interni al record deve corrispondere al numero di variabili imputabili. I dati mancanti possono essere codificati a scelta dello sperimentatore, tra queste codifiche sono comuni le assegnazioni di valori “fuori scala” ne sono esempi codifiche del tipo 999. In caso di scale definite solo positivamente, si può utilizzare per la codifica del dato mancante il primo valore utile ( in questo caso -1). In SPSS la codifica del dato mancante è stabilita automaticamente dal sistema assumendo come valore il carattere “.” in corrispondenza di una cella di imputazione lasciata vuota dall’operatore.
. In SPSS la codifica del dato mancante è stabilita automaticamente dal sistema assumendo come valore il carattere . in corrispondenza di una cella di imputazione lasciata vuota dall’operatore.")
23
Colonne: contengono tutte le rilevazione, trasversalmente raccolte su tutti i soggetti relativamente ad una data variabile o unità d’informazione. Si utilizzano le colonne anche qualora il disegno della ricerca dovesse contenere informazioni replicate di uno stesso soggetto, in condizioni sperimentali diversificate (Test re-test o multilivello). In generale non esiste un’unica formulazione per definire la nomenclatura del file di dati, ma questa dipende dallo specifico modello di analisi da impiegare o dalle peculiarità strutturali del disegno sperimentale impiegato.
. In generale non esiste un’unica formulazione per definire la nomenclatura del file di dati, ma questa dipende dallo specifico modello di analisi da impiegare o dalle peculiarità strutturali del disegno sperimentale impiegato.")
24
Per la codifica è necessario che:
Le variabili siano in formato numerico I casi (soggetti) devono avere un numero identificativo progressivo codici devono essere mutualmente escludentesi (ogni risposta cade solo e soltanto in una categoria)
 devono avere un numero. identificativo progressivo. codici devono essere mutualmente. escludentesi (ogni risposta cade solo e. soltanto in una categoria)")
25
La descrizione e lo screening dei dati sono delle fasi
DESCRIZIONE DEI DATI La descrizione e lo screening dei dati sono delle fasi molto importanti in quanto permettono di: Individuare i valori mancanti; Individuare variabili che assumono valori fuori scala; Verificare se la distribuzione è normale Individuare gli outlier

26
Simmetrica rispetto alla media Presenta due punti di flesso x = μ – σ
La normalità della distribuzione è fondamento di molte analisi. La distribuzione normale univariata assume la classica forma a campana: CARATTERISTICHE Unimodale Simmetrica rispetto alla media Presenta due punti di flesso x = μ – σ x = μ + σ

27
Creazione completa delle variabili

28
Struttura dei dati dopo l’inserimento delle variabili

29
A seconda dello strumento utilizzato, come in questo caso, le variabili necessitano di essere ri-codificate per ancorare tutti i valori numerici con la stessa valenza semantica: tutte in positivo o in negativo. Per fare questo è necessario verificare prima quali variabili siano da invertire ed eseguire l’operazione attraverso il menù trasforma (ri-codifica nelle stesse variabili).
.")
30
Avendo individuato le variabili che necessitano di trasformazione, man mano si selezionano e tramite la freccia si posizionano nel campo variabili

31
Per completare la trasformazione è necessario sostituire ai valori precedentemente assegnati, i nuovi digitando sul pulsante “valori vecchi e nuovi”.

32
Si invertono i valori di scala per l’intera gamma comune delle variabili lasciando invariato il dato mancante di sistema.

33
È sempre opportuno verificare che la procedura sia stata eseguita correttamente.
La formula per verificare il risultato è la seguente: (Valore massimo – valore attuale) + valore minimo Es: (4-3)+0= 1
 + valore minimo. Es: (4-3)+0= 1.")
34
Adesso è possibile calcolare il punteggio totale del questionario ed il punteggio medio per ciascun soggetto impiegando il menù “trasforma” sotto la voce “calcola variabile. Per calcolare il punteggio totale al test, porre nel campo “variabile di destinazione” il nome da assegnare e operare la scelta della funzione “sum”.

35
I nomi delle variabili vengono riportate come argomenti della funzione multi-argomento che opera sulle variabili.

36
Nell’ultima colonna possiamo osservare la somma dei punteggi di ciascun soggetto attraverso le variabili prese in considerazione.

37
A questo punto, con lo stesso procedimento, possiamo calcolare la media

38
Il programma ha generato una nuova colonna nella quale viene espressa la media delle risposte fornite da ciascun soggetto.

39
Per calcolare i principali indici statistici campionari di ciascuna variabile, si opera attraverso il menù analizza tramite il comando “frequenze”.

40
Si selezionano le variabili per le quali interessa calcolare gli indici statistici principali congiuntamente alla distribuzione di frequenze.

41
Si marcano le statistiche desiderate

42
OUTPUT

43
OUTPUT Vengono riportate le statistiche per ciascun item

44
Distribuzione delle frequenze
Si considerano solo i casi che non presentano valori mancanti Si considerano anche i casi che presentano valori mancanti Non essendoci valori mancanti, in questo caso, coincidono

47
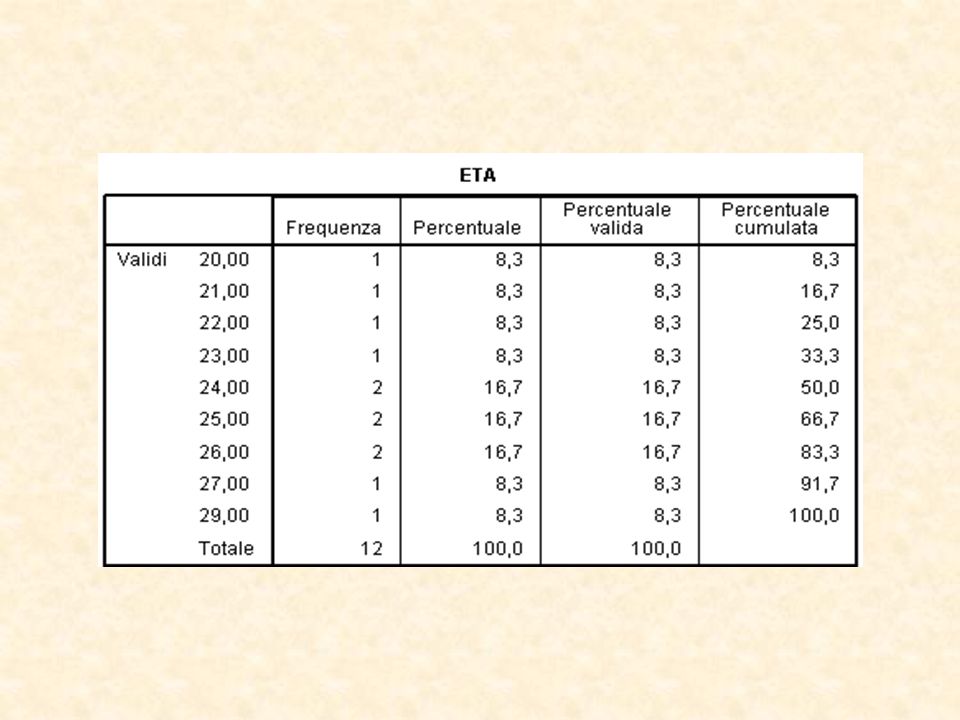
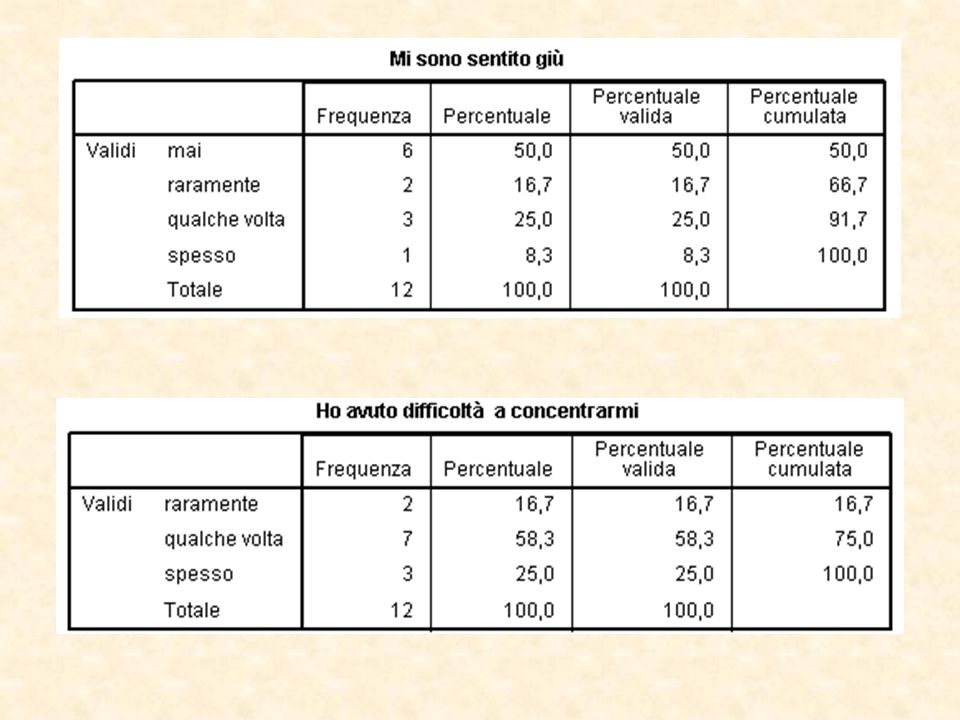
Volendo effettuare la descrizione dei dati raccolti:

48
Ancora una volta, dopo aver selezionato le variabili oggetto d’indagine

49
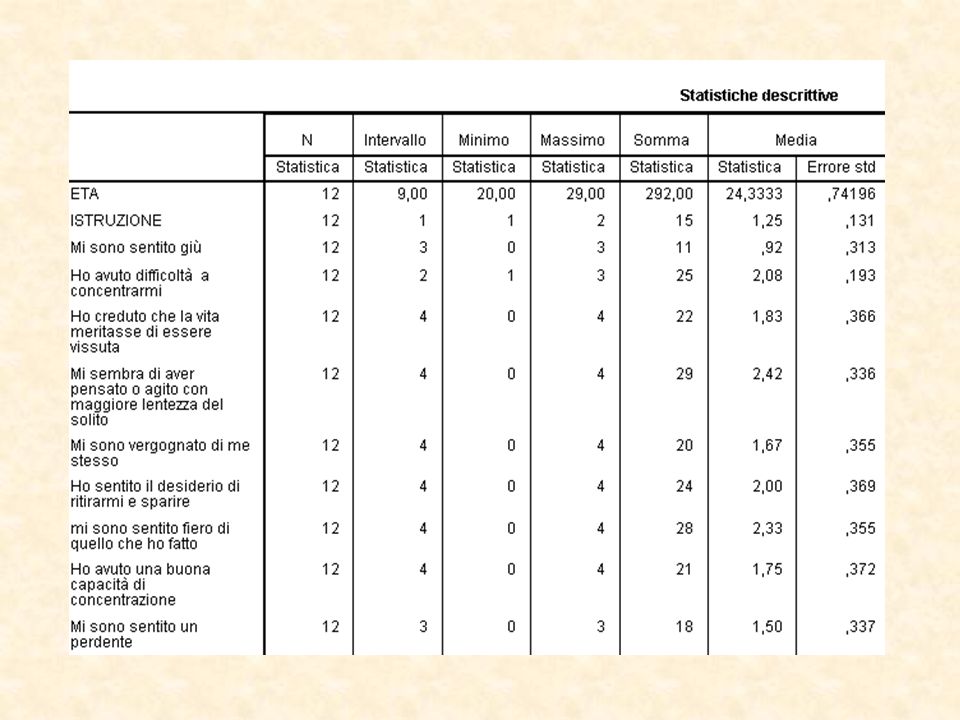
Si selezionano le statistiche descrittive che interessano

51
Con valori degli indici di Asimmetria e Curtosi compresi tra -1 e 1 la distribuzione è normale

52
Valore di Curtosi negativo Valore di Curtosi positivo
Curva Normale Valori compresi tra -1 e 1 Valore di Curtosi negativo La distribuzione è schiacciata verso il basso rispetto a quella normale. La distribuzione è detta PLATICURTICA. Valore di Curtosi positivo La distribuzione è più appuntita rispetto a quella normale. La distribuzione è detta LEPTOCURTICA.

53
Per una più accurata descrizione del campione si possono eseguire:

54
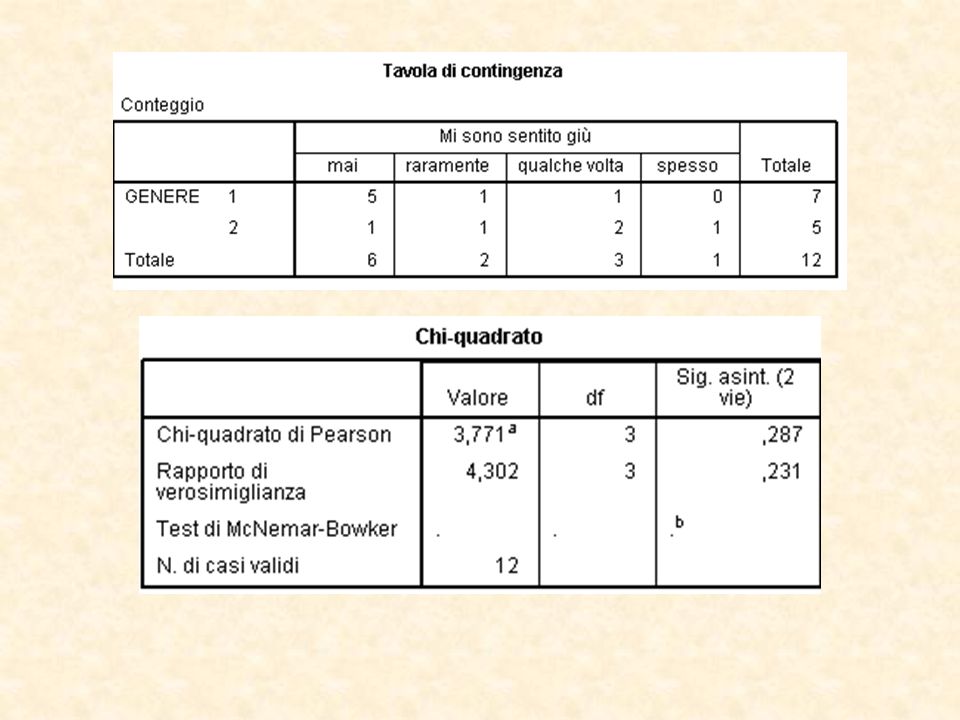
Ad esempio, si possono mettere in relazione variabili socio-demografiche quali genere ed età con le prime due domante al test.

55
Dopo aver selezionato le variabili che interessa mettere in relazione si clicca su “continua”

57
Dei ricercatori hanno ipotizzato vi sia relazione tra le abilità matematiche (X1), le abilità scientifiche (X2) e la percezione di autoefficacia (Y). Al fine di analizzare ciò, hanno somministrato 3 test ad un gruppo di 8 studenti. Verificare, per un livello di significatività pari ad α = 0,05, se l’ipotesi dei ricercatori è fondata. Nella tabella che segue sono espressi i punteggi ottenuti nei 3 test: Y X1 X2 4 5 3 2 6 8 7 9 10 12 11 13