Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

4
Una “soluzione d’angolo” y1y1 y2y2 0 B Di solito la scelta del consumatore è identificata dal punto di tangenza tra retta del bilancio e curva di indifferenza. Ma non sempre. Nella figura, la tangenza sarebbe nel punto B, in cui y 2 < 0. Ma un consumo negativo è impossibile. Il paniere preferito sulla retta del bilancio è A, Una corner solution A in cui y 2 = 0.

10
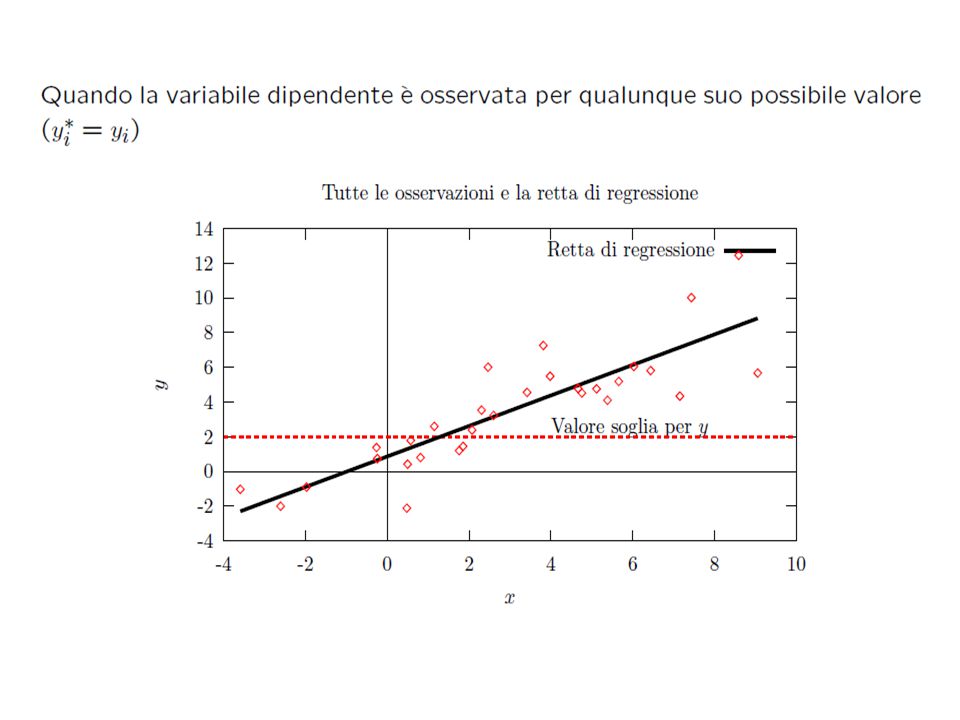
Il modello di Regressione Ricordando che: TRONCAMENTO : E(x/x>a) = + (a) e V(x/x>a) = ²[1- (a)] CENSURA:
![Il modello di Regressione Ricordando che: TRONCAMENTO : E(x/x>a) = + (a) e V(x/x>a) = ²[1- (a)] CENSURA:](http://images.slideplayer.it/10/2705644/slides/slide_10.jpg "Il modello di Regressione Ricordando che: TRONCAMENTO : E(x/x>a) = + (a) e V(x/x>a) = ²[1- (a)] CENSURA:")
11
ATTENZIONE notazione importantissima: Finora abbiamo considerato distribuzioni con un punto di troncamento a che viene poi standardizzato sottraendo la media e dividendo per Quando consideriamo i modelli di regressione 1.Il punto di troncamento rimane unico 2.Lo scarto rimane unico Ma…. 1.Il valor medio cambia, infatti sappiamo che E(y i ) = x i cioè è diverso per ciascun soggetto QUINDI il punto (UNICO) di troncamento ha un valore standardizzato DIVERSO per ciascun individuo e quindi avremo:
 = x i cioè è diverso per ciascun soggetto QUINDI il punto (UNICO) di troncamento ha un valore standardizzato DIVERSO per ciascun individuo e quindi avremo:.")
12
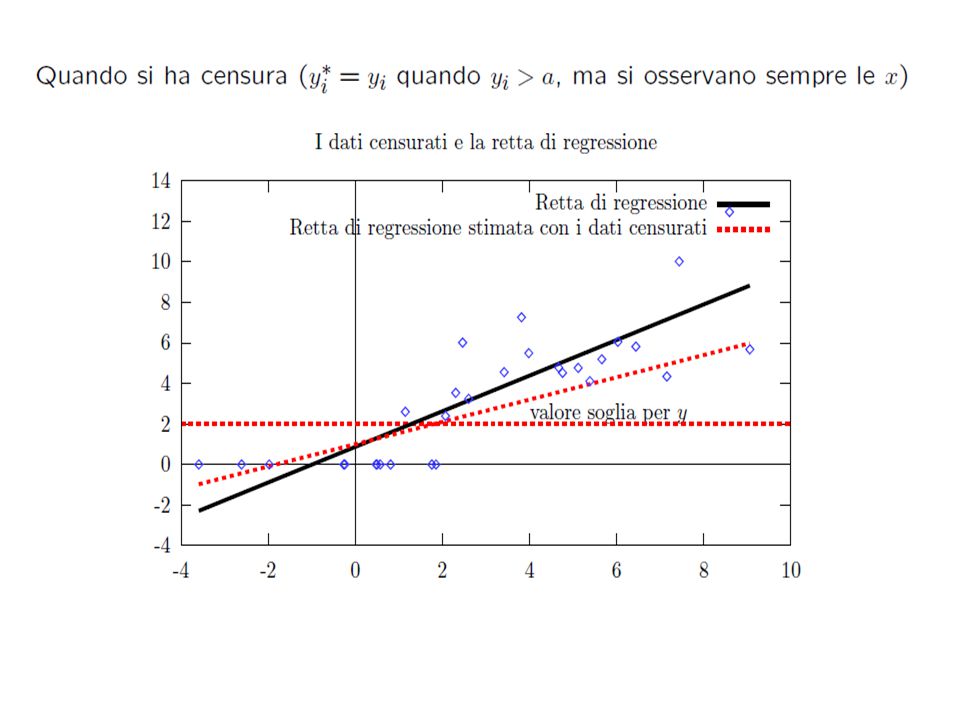
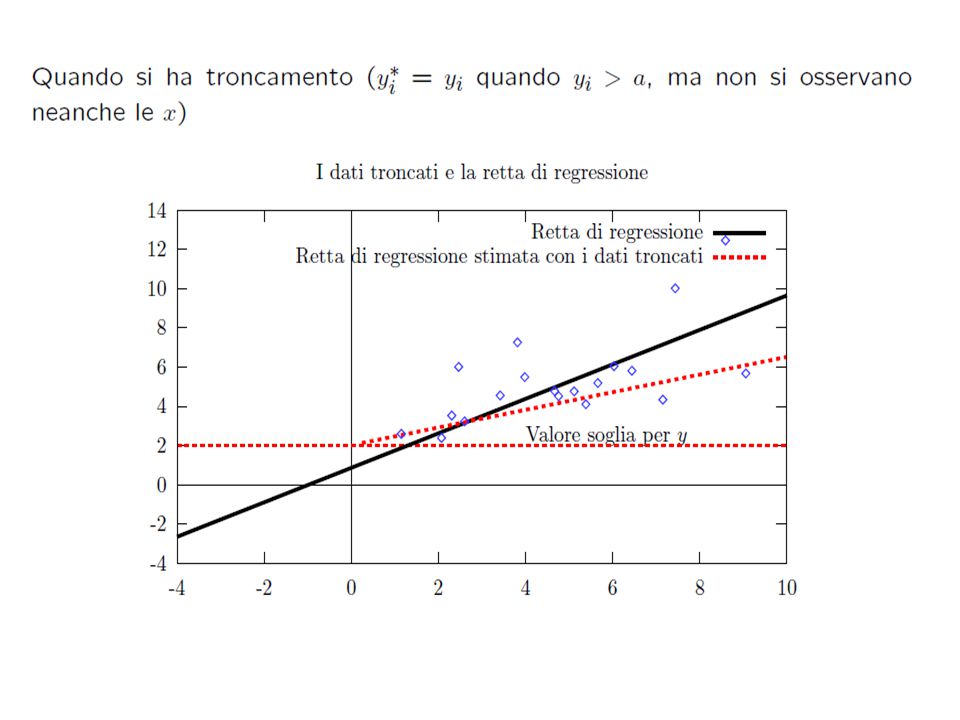
Regressione troncata: Regressione censurata: modello modello Tobin o Tobit (censura al punto 0) Quindi OLS distorti e inconsistenti
 Quindi OLS distorti e inconsistenti")
13
Regressione troncata: verosimiglianza Regressione censurata: verosimiglianza

14
Regressione troncata: effetto marginale: Il fattore 1- (che deriva dalla varianza troncata) è compreso tra 0 e 1 quindi per ciascuna variabile l’effetto marginale è MINORE del corrispondente coefficiente, si verifica una sorta di ATTENUAZIONE dell’effetto Questo avviene nella sottopopolazione NON troncata, naturalmente a volte siamo interessati a tutta la popolazione e quindi guarderemo semplicemente al coefficiente β che rappresenta l’effetto marginale nell’intera popolazione
 è compreso tra 0 e 1 quindi per ciascuna variabile l’effetto marginale è MINORE del corrispondente coefficiente, si verifica una sorta di ATTENUAZIONE dell’effetto Questo avviene nella sottopopolazione NON troncata, naturalmente a volte siamo interessati a tutta la popolazione e quindi guarderemo semplicemente al coefficiente β che rappresenta l’effetto marginale nell’intera popolazione")
15
Un risultato utile: abbiamo visto che Questo implica che: distorsione La varianza contiene le x (incluse nei i) quindi è ETEROSCHEDASTICO
 quindi è ETEROSCHEDASTICO")
16
Alcune domande fondamentali: Quale variabile è di interesse (cosa vogliamoprevedere)? –y*? (I non censurati) Probabilmente NO – di solito non rilevante –y? (la distribuzione latente) Di solito SI, il valore per una unità scelta a caso dalla popolazione –y | y>0? Forse. Dipende da ciò che ci interessa Qual’è il residuo? –(y – previsto)? Probabilmente no, come consideriamo gli zeri? –(qualcosa - x ) ? Probabilmente no. x Non è la media. Quindi quali sono gli effetti marginali e le medie condizionate alle x?
 Probabilmente NO – di solito non rilevante –y. (la distribuzione latente) Di solito SI, il valore per una unità scelta a caso dalla popolazione –y | y>0. Forse. Dipende da ciò che ci interessa Qual’è il residuo. –(y – previsto). Probabilmente no, come consideriamo gli zeri. –(qualcosa - x ) . Probabilmente no. x Non è la media. Quindi quali sono gli effetti marginali e le medie condizionate alle x .")
17
Regressione censurata: effetto marginale con censura a sx nel punto 0 Che può essere scomposta in due parti: Si vede così che un cambiamento nelle x ha un DOPPIO effetto: 1.Condiziona la media della parte NON censurata 2.Modifica la prob. di essere censurati

19
In altri termini l’effetto marginale non è costante, quindi la lettura dei coefficienti del modello NON è sufficiente. L’effetto sulle Y di una variazione delle X DIPENDE dal valore delle X, quindi, ad esempio, è diversa per ogni individuo (perché ha un vettore di X diverso) Se vogliamo una indicazione di sintesi rappresentiamo l’effetto delle X nel “punto medio” o per “l’individuo medio”. Cioè sostituiamo nelle formule di calcolo Se il modello ha più esplicativedue possibilità: 1.valutazione effettuata nel punto medio per UN coefficiente, e per un valore pari a 0 per le altre variabili 2.Valutazione nei punti medi di tutte le variabili, questo ultimo processo equivale a calcolare la media dei valori stimati individuali, modificando una sola variabile indipendente Con lo stesso principio è possibile misurare l’effetto di modificazioni delle variabili per tipologie di unità.
 Se vogliamo una indicazione di sintesi rappresentiamo l’effetto delle X nel punto medio o per l’individuo medio . Cioè sostituiamo nelle formule di calcolo Se il modello ha più esplicativedue possibilità: 1.valutazione effettuata nel punto medio per UN coefficiente, e per un valore pari a 0 per le altre variabili 2.Valutazione nei punti medi di tutte le variabili, questo ultimo processo equivale a calcolare la media dei valori stimati individuali, modificando una sola variabile indipendente Con lo stesso principio è possibile misurare l’effetto di modificazioni delle variabili per tipologie di unità..")
20
Lo stesso principio si utilizza per il calcolo dei valori previsti e dei residui: Il metodo di calcolo dei valori previsti e quindi dei residui Poiché il modello precede una “mistura” il metodo deve simultaneamente rendere conto della parte censurata (Ripartizione) e della parte ossservata: Naturalmente dipende dalla distribuzione ipotizzata a priori: Per residui normali è: In sostanza avremo un y=0 per coloro che date le x non superano la soglia stimata di censura
 e della parte ossservata: Naturalmente dipende dalla distribuzione ipotizzata a priori: Per residui normali è: In sostanza avremo un y=0 per coloro che date le x non superano la soglia stimata di censura")
21
Esempio di stima: modello per le ore lavorate da un campione di donne (USA) Quester e Greene (1982) Obiettivo: verificare se le le donne il cui matrimonio sta per dissolversi, tendono a passare più o meno ore al lavoro
 Quester e Greene (1982) Obiettivo: verificare se le le donne il cui matrimonio sta per dissolversi, tendono a passare più o meno ore al lavoro")
22
VariabileMLE stima Effetto Marginale Punto medio OLSOLS / % non censurati Figli piccoli -824.19-376.53-352.63-766.59 Titolo studio 22.5910.3211.4724.93 Salario286.39130.93123.95269.46 Secondo matrimonio 25.3311.5713.1428.57 Bassa prob. divorzio 481.02219.75219.22476.57 Alta prob. divorzio 578.66264.36244.17530.80

23
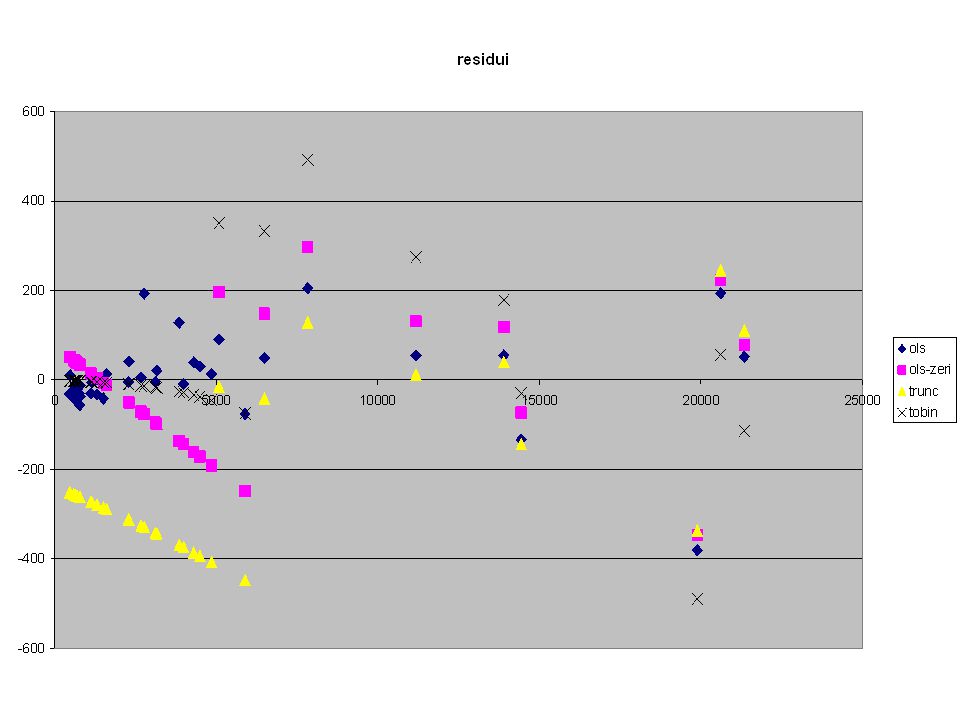
Esempio 2: Acquisto di carne = f(reddito) Dati artificiali, censura artificiale
 Dati artificiali, censura artificiale")
24
troncatacensurataOLS con zeri Ols "Vero"OLS solo Osservati Log L-257,1-173,8-206,3-198,9-116,4 AIC520,2353,6418,5403,8238,9 Intercept-115,1-72,954,313,7101,9 Se60,136,716,719,033,9 t-1,9-2,03,30,73,0 sig(t)0,05530,04680,00220,47650,0063 Reddito0,062360,060040,050370,053430,04675 Se0,005000,004520,002430,002770,00369 t12,513,320,719,312,7 sig(t)<,0001 _Sigma130,459153,92989,833102,377114,325
0,05530,04680,00220,47650,0063 Reddito0,062360,060040,050370,053430,04675 Se0,005000,004520,002430,002770,00369 t12,513,320,719,312,7 sig(t)<,0001 _Sigma130,459153,92989,833102,377114,325")
25
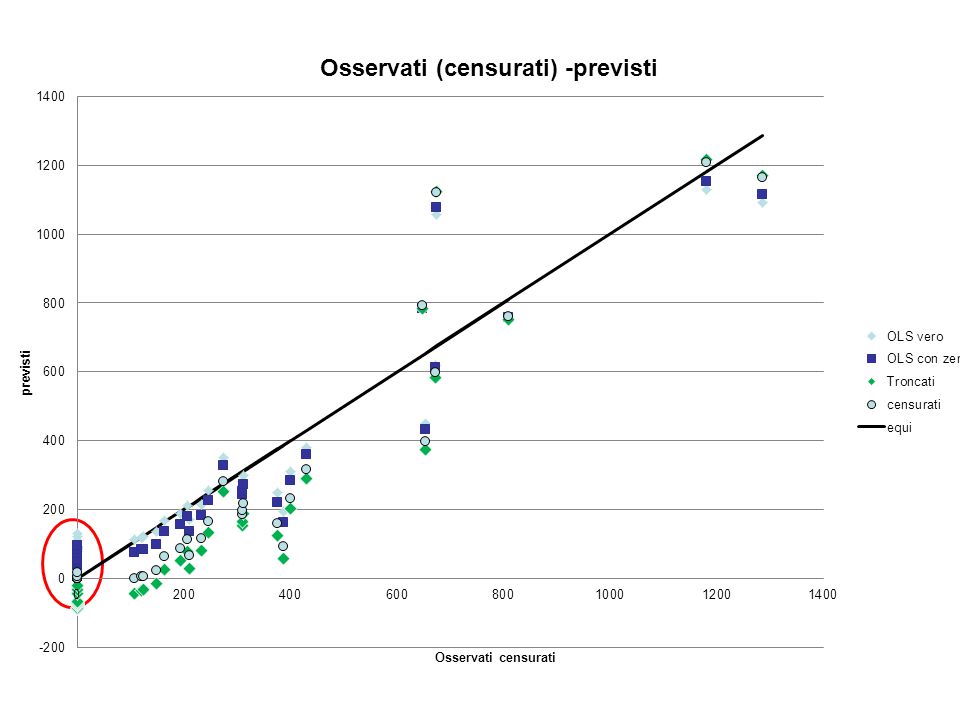
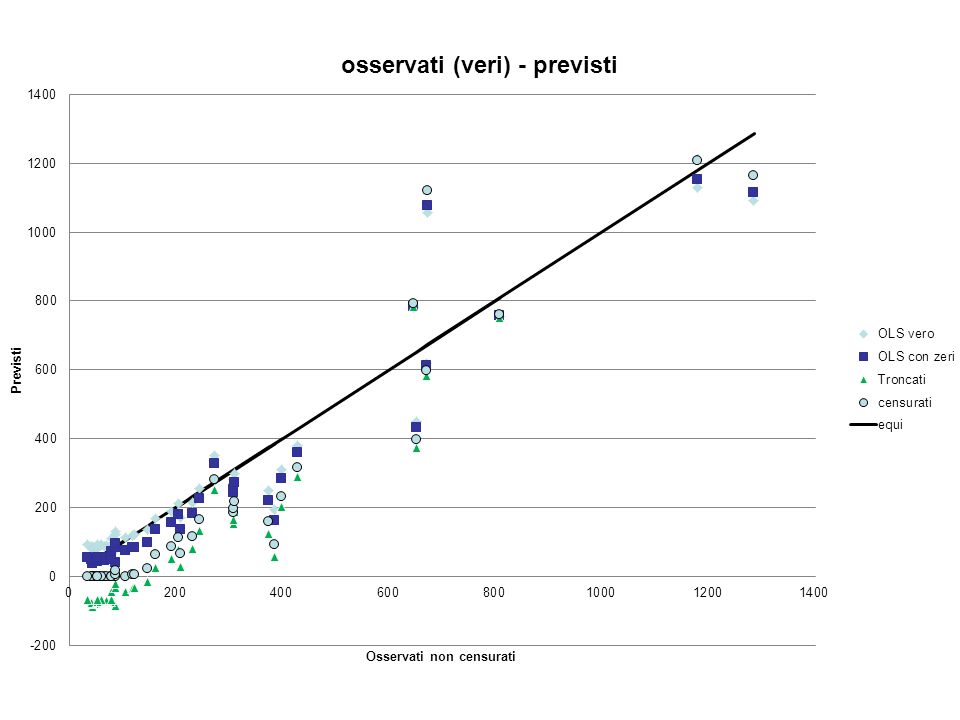
Esempio 2: Sportelli bancari = f(addetti) Dati effettivi, censura artificiale
 Dati effettivi, censura artificiale")
26
Esempio 2: Sportelli bancari = f(addetti) Zoom sulla parte troncata/censurata
 Zoom sulla parte troncata/censurata")
28
Zoom sulla censura

32
Eteroschedasticità Problema, in generale risolto sostituendo nella MLE Naturalmente è necessario specificare una “forma per l’eteroschedasticità Ad esempio: Non normalità stimatore robusto: LAD (Least Absolute Deviation) estimator Molto complesso Test di chester e Irish (1987) sui residui generalizzati Stima con dati panel = problema ancora aperto Problema principale sono i processi “double hurdle” con doppia decisione Sample selection models
 estimator Molto complesso Test di chester e Irish (1987) sui residui generalizzati Stima con dati panel = problema ancora aperto Problema principale sono i processi double hurdle con doppia decisione Sample selection models")
Presentazioni simili

















>")

>")
>")

![Il modello di Regressione Ricordando che: TRONCAMENTO : E(x/x>a) = + (a) e V(x/x>a) = ²[1- (a)] CENSURA:](/1/572219/big_thumb.jpg "Il modello di Regressione Ricordando che: TRONCAMENTO : E(x/x>a) = + (a) e V(x/x>a) = ²[1- (a)] CENSURA:>")

>")

