Scaricare la presentazione
1
ALGORITMI DI RICERCA Nella programmazione s’incontra spesso la necessità di ricercare un elemento (chiave) in un elenco, oppure di ordinare gli elementi di un elenco. Osserviamo che non è necessario ordinare gli elementi di un elenco prima di eseguirvi una ricerca; tuttavia, come vedremo, la ricerca risulta più veloce se gli elementi sono ordinati. I due metodi più comunemente impiegati per cercare una chiave in un elenco - quale un nome in una rubrica telefonica - sono la ricerca lineare e quella binaria. Ricerca lineare. In una ricerca lineare, o sequenziale, si esamina ogni elemento dell’elenco nell’ordine in cui si presenta, fino a che si trova la chiave cercata, oppure si raggiunge la fine dell’elenco. Ovviamente, questo metodo non è il più efficiente per una ricerca in un lungo elenco ordinato alfabeticamente, tuttavia presenta i seguenti vantaggi:
 in un elenco, oppure di ordinare gli elementi di un elenco. Osserviamo che non è necessario ordinare gli elementi di un elenco prima di eseguirvi una ricerca; tuttavia, come vedremo, la ricerca risulta più veloce se gli elementi sono ordinati. I due metodi più comunemente impiegati per cercare una chiave in un elenco - quale un nome in una rubrica telefonica - sono la ricerca lineare e quella binaria. Ricerca lineare. In una ricerca lineare, o sequenziale, si esamina ogni elemento dell’elenco nell’ordine in cui si presenta, fino a che si trova la chiave cercata, oppure si raggiunge la fine dell’elenco. Ovviamente, questo metodo non è il più efficiente per una ricerca in un lungo elenco ordinato alfabeticamente, tuttavia presenta i seguenti vantaggi:")
2
l’algoritmo è semplice;
l’elenco non deve essere in un particolare ordine. In una ricerca lineare si inizia dal primo elemento e si continua in modo sequenziale, elemento dopo elemento, attraverso l’elenco. Lo pseudo codice per una funzione che esegua una ricerca lineare è: imposta un flag “trovato” a FALSO; imposta un indice a -1; comincia con il primo elemento della lista; while vi sono ancora elementi nella lista AND il flag “trovato” è FALSO confronta l’elemeno della lista con la chiave cercata; if la chiave è stata trovata imposta l’indice alla posizione dell’elemento nella lista; imposta il flag “trovato” a VERO; fine dell’if fine del while fornisci il valore dell’indice;

3
Ecco il corrispondente diagramma di flusso:

4
Osserviamo che il valore fornito dalla funzione indica se la chiave sia stato trovata o no:
se il valore fornito è -1, la chiave non era nell’elenco; altrimenti il valore fornito costituisce l’indice della posizione in cui la chiave si trova nell’elenco. A titolo di esempio, vediamo la seguente funzione in C, che implementa l’algoritmo della ricerca lineare: ricerca_lineare(int *lista, int dim_lista, int chiave) { for (int i = 0 ; i < dim_lista ; i++) if(lista[i] == chiave) return true; return false; } Se in una ricerca lineare la chiave cercata si trova all’inizio dell’elenco, si dovranno effettuare solo pochi confronti; il caso peggiore è invece se si trova alla fine dell’elenco.
 { for (int i = 0 ; i < dim_lista ; i++) if(lista[i] == chiave) return true; return false; } Se in una ricerca lineare la chiave cercata si trova all’inizio dell’elenco, si dovranno effettuare solo pochi confronti; il caso peggiore è invece se si trova alla fine dell’elenco.")
5
In media, assumendo che la chiave si possa trovare con uguale probabilità in un punto qualsiasi dell’elenco, il numero di confronti necessari sarà N/2, se N è il numero di elementi dell’elenco. Ebbene, questo numero può essere sensibilmente ridotto usando un algoritmo di ricerca binario.

6
Ricerca binaria. In una ricerca binaria l’elenco deve essere già ordinato. In tale caso la chiave cercata viene confrontata dapprima con l’elemento centrale o mediano dell’elenco (se questo ha un numero pari di elementi, va bene uno qualsiasi dei due elementi centrali). Si possono presentare tre casi: ALLORA la ricerca ha avuto successo e termina; SE la chiave cercata è uguale all’elemento centrale la chiave è maggiore dell’elemento centrale se essa è presente nell’elenco, si deve trovare nella sua parte superiore, e quella inferiore può essere trascurata; la chiave è minore dell’elemento centrale se essa è presente nell’elenco, si deve trovare nella sua parte inferiore, e quella superiore può essere trascurata.

7
Un esempio di ricerca binaria è costituito da un semplice indovinello, in cui un giocatore deve indovinare un intero positivo scelto da un altro giocatore tra 1 e n, usando solo domande con risposta sì o no. Supponendo che n sia 16 e che sia stato scelto il numero 11, il gioco può procedere come segue: il numero è maggiore di 8? (sì) il numero è maggiore di 12? (no) il numero è maggiore di 10? (sì) il numero è maggiore di 11? (no) A ogni passo scegliamo il numero che si trova al centro dell’intervallo dei valori possibili: ad es., una volta che sappiamo che il numero è maggiore di 8 ma minore o uguale a 12, sappiamo di dovere scegliere un numero al centro dell’intervallo 9-12, cioè 10 o 11. Dato che il numero è maggiore di 10, ma non maggiore di 11, esso deve essere 11. Dato che ogni domanda dimezza lo spazio di ricerca, sono necessarie al massimo log2n domande per trovare il numero.
 il numero è maggiore di 12 (no) il numero è maggiore di 10 (sì) il numero è maggiore di 11 (no) A ogni passo scegliamo il numero che si trova al centro dell’intervallo dei valori possibili: ad es., una volta che sappiamo che il numero è maggiore di 8 ma minore o uguale a 12, sappiamo di dovere scegliere un numero al centro dell’intervallo 9-12, cioè 10 o 11. Dato che il numero è maggiore di 10, ma non maggiore di 11, esso deve essere 11. Dato che ogni domanda dimezza lo spazio di ricerca, sono necessarie al massimo log2n domande per trovare il numero.")
8
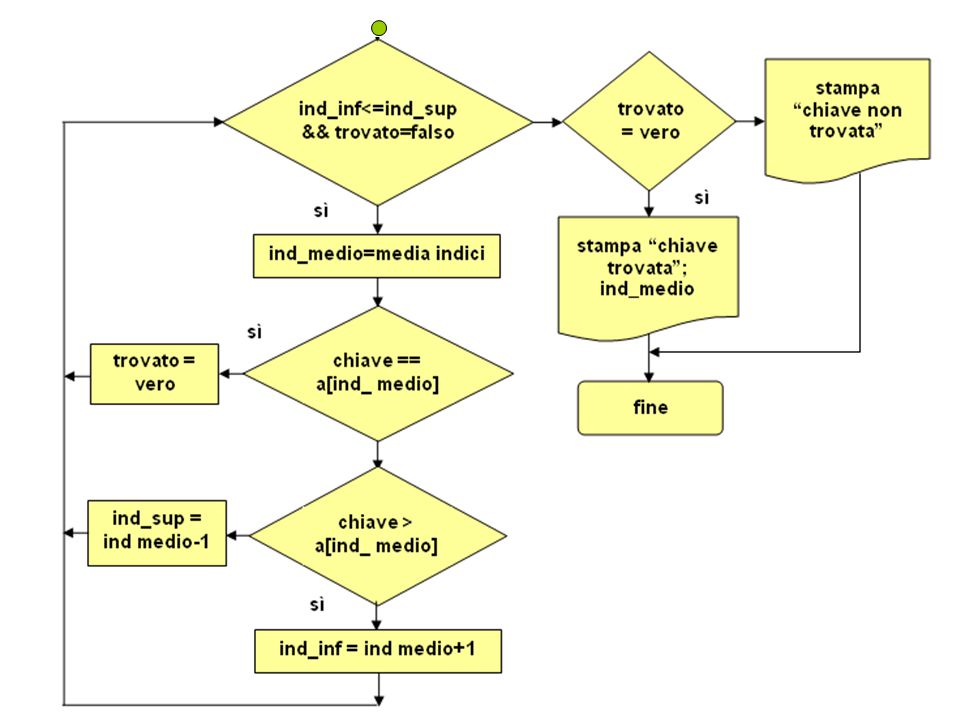
Questa strategia di ricerca si può implementare con l’algoritmo definito dal seguente pseudo codice:
imposta un flag “trovato” a FALSO; imposta un indice a -1; imposta l’indice inferiore a 0; imposta l’indice superiore al numero di elementi dell’elenco -1; comincia con il primo elemento dell’elenco; while l’indice inferiore è <= all’indice superiore AND non si è ancora trovata una corrispondenza imposta l’indice medio alla media degli indici inferiore e superiore; confronta la chiave cercata con l’elemento di indice medio; if la chiave cercata è uguale all’elemento di indice medio la chiave è stata trovata; altrimenti, se la chiave è > dell’elemento di indice medio imposta l’indice inferiore all’indice medio +1; altrimenti, se la chiave è < dell’elemento di indice medio imposta l’indice superiore all’indice medio -1; fine dell’if fine del while fornisci il valore dell’indice;

9
Ecco il corrispondente diagramma di flusso:

11
Come si vede dallo pseudo codice e dal diagramma di flusso, la ricerca viene controllata con un ciclo while. La lista inziale è definita impostando l’indice inferiore a 0 e quello superiore al numero di elementi della lista -1. L’elemento medio ha come indice la media (arrotondata a un intero) dei valori inferiore e superiore. Una volta effettuato il confronto con l’elemento medio, la ricerca viene ristretta spostando: o l’indice inferiore a un valore superiore di 1 all’indice medio o l’indice superiore a un valore inferiore di 1 all’indice medio. Il processo continua fino a che si trova la chiave cercata, oppure i valori degli indici inferiore e superiore diventano uguali. La versione in C di questo algoritmo è contenuta nella funzione ricercaBin, che vedremo in seguito. La ricerca binaria è detta anche taglio binario, strategia divide et impera o ricerca dicotomica.
 dei valori inferiore e superiore. Una volta effettuato il confronto con l’elemento medio, la ricerca viene ristretta spostando: o l’indice inferiore a un valore superiore di 1 all’indice medio. o l’indice superiore a un valore inferiore di 1 all’indice medio. Il processo continua fino a che si trova la chiave cercata, oppure i valori degli indici inferiore e superiore diventano uguali. La versione in C di questo algoritmo è contenuta nella funzione ricercaBin, che vedremo in seguito. La ricerca binaria è detta anche taglio binario, strategia divide et impera o ricerca dicotomica.")
12
Ecco un semplice pseudocodice per una funzione di tipo iterativo, che usa un ciclo while per determinare l’indice di una data chiave in un elenco ordinato a tra gli indici ind_inf e ind_sup. function RicercaBin(a, chiave, ind_inf, ind_sup) while ind_inf ≤ ind_sup ind_medio = floor((ind_inf + ind_sup)/2); if chiave == a[ind_medio] return ind_medio; if chiave < a[ind_medio] ind_sup = ind_medio-1; else ind_inf = ind_medio+1; return “non trovato”;
 while ind_inf ≤ ind_sup. ind_medio = floor((ind_inf + ind_sup)/2); if chiave == a[ind_medio] return ind_medio; if chiave < a[ind_medio] ind_sup = ind_medio-1; else. ind_inf = ind_medio+1; return non trovato ;")
13
Ma lo stesso algoritmo di ricerca si può implementare anche con il seguente pseudocodice, di tipo ricorsivo: function RicercaBin(a, chiave, ind_inf, ind_sup) if ind_sup < ind_inf return “non trovato”; ind_medio = floor((ind_inf + ind_sup)/2); if chiave == a[ind_medio] return ind_medio; if chiave < a[ind_medio] RicercaBin(a, chiave, ind_inf, ind_medio-1) else RicercaBin(a, chiave, ind_medio+1, ind_sup)
 if ind_sup < ind_inf. return non trovato ; ind_medio = floor((ind_inf + ind_sup)/2); if chiave == a[ind_medio] return ind_medio; if chiave < a[ind_medio] RicercaBin(a, chiave, ind_inf, ind_medio-1) else. RicercaBin(a, chiave, ind_medio+1, ind_sup)")
14
In entrambi i casi l’algoritmo ha termine, dato che sia nella chiamata ricorsiva, sia nell’iterazione la differenza tra l’indice superiore e quello inferiore diventa sempre più piccola, fino a diventare alla fine negativa. Osservazione. L’algoritmo iterativo sovrascrive i dati in ingresso con quelli in uscita, e pertanto occupa una quantità di memoria aggiuntiva piccola e predeterminata. Esso si chiama pertanto algoritmo sul posto. Invece l’algoritmo ricorsivo non sovrascrive i dati, e può occupare una quantità aggiuntiva di memoria anche molto grande. Esso si chiama non sul posto.

15
Tempo di esecuzione. Il vantaggio di usare un algoritmo di ricerca binaria è che il numero di elementi tra cui cercare viene diviso per 2 ogni volta che si ripete il ciclo while. Così, la prima volta che si esegue il ciclo si deve cercare fra n elementi; la seconda volta n/2 elementi sono stati eliminati e ne rimangono solo n/2; la terza volta si elimina un’altra metà degli elementi rimanenti, e così via. In generale, dopo p ripetizioni del ciclo, il numero di elementi che rimangono da confrontare è n/(2p). Nel caso peggiore, la ricerca continua finché gli elementi che rimangono da confrontare siano <=1. Matematicamente ciò si esprime dicendo che n/(2p) <= 1 o, in modo altenativo, che p è l’intero più piccolo tale che 2p >= n.
. Nel caso peggiore, la ricerca continua finché gli elementi che rimangono da confrontare siano <=1. Matematicamente ciò si esprime dicendo che. n/(2p) <= 1. o, in modo altenativo, che p è l’intero più piccolo tale che 2p >= n.")
16
Per esempio, per un vettore di n = 1
Per esempio, per un vettore di n = elementi il numero massimo, p, di passi necessari per una ricerca binaria è 10. La tabella confronta i numeri di passi di cicli necessari per le ricerche lineare e binaria per varie dimensioni degli elenchi. Come si vede, per un vettore di 50 elementi il numero massimo di passi è circa 10 volte superiore per una ricera lineare che per una binaria, e ancora di più per vettori lunghi. In linea di massima, 50 elementi sono considerati di solito la linea di confine: per vettori più brevi la ricerca lineare è accettabile, per vettori più lunghi si usa la ricerca binaria.

17
Notazione O-grande. Le prestazioni degli algoritmi possono essere confrontate con diversi metodi. Uno di questi consiste nell’eseguire molti test per ogni algoritmo e nel confrontarne i tempi di esecuzione misurati. Un altro modo è stimare il tempo richiesto. Per esempio, può succedere che il tempo di ricerca, all’aumentare del numero di elementi n dell’elenco, sia proporzionale a n (cosicché ci aspettiamo che il tempo di ricerca raddoppi se la dimensione dell’elenco aumenta di un fattore 2). In tale caso si dice che il tempo di ricerca è O(n) (“O-grande di n”). La notazione O-grande non descrive il tempo esatto richiesto da un algoritmo, ma indica solo un limite superiore al tempo di esecuzione, entro un fattore costante. Per esempio, se il tempo di esecuzione di un algoritmo è O(n2), allora esso non cresce più del quadrato della dimensione dell’elenco.
. In tale caso si dice che il tempo di ricerca è O(n) ( O-grande di n ). La notazione O-grande non descrive il tempo esatto richiesto da un algoritmo, ma indica solo un limite superiore al tempo di esecuzione, entro un fattore costante. Per esempio, se il tempo di esecuzione di un algoritmo è O(n2), allora esso non cresce più del quadrato della dimensione dell’elenco.")
18
La tabella seguente illustra i valori con cui crescono alcune funzioni di n.

19
Se i valori nella tabella rappresentano microsecondi, allora per processare 1.048.476 elementi,
un algoritmo O(lg n) può impiegare 20 microsecondi un algoritmo O(n1.25) può impiegare 33 secondi un algoritmo O(n2) può impiegare fino a 12 giorni. Come abbiamo visto, nella ricerca binaria un confronto in più consente di ricercare fra un numero doppio di valori. Dato che la funzione lg2n cresce di 1 quando n raddoppia, la ricerca binaria è un algoritmo di complessità O(lg2n) o anche, come si dice, caratterizzato da un fattore di crescita O(lg2n). Essa è assai più veloce della ricerca lineare, che ha complessità O(n). In seguito vedremo una stima della complessità in termini di tempo per ogni algoritmo, usando la notazione O-grande.
 può impiegare 20 microsecondi. un algoritmo O(n1.25) può impiegare 33 secondi. un algoritmo O(n2) può impiegare fino a 12 giorni. Come abbiamo visto, nella ricerca binaria un confronto in più consente di ricercare fra un numero doppio di valori. Dato che la funzione lg2n cresce di 1 quando n raddoppia, la ricerca binaria è un algoritmo di complessità O(lg2n) o anche, come si dice, caratterizzato da un fattore di crescita O(lg2n). Essa è assai più veloce della ricerca lineare, che ha complessità O(n). In seguito vedremo una stima della complessità in termini di tempo per ogni algoritmo, usando la notazione O-grande.")
20
ALGORITMI DI ORDINAMENTO
Quello di ordinare in modo crescente o decrescente dei numeri, o delle parole in ordine alfabetico diretto o inverso, è uno dei problemi più frequenti dalla programmazione. Formalmente esso si enuncia in questi termini: dato il vettore a di n componenti a[0], ... , a[n-1] trasformarlo in un vettore ordinato in modo non decrescente, cioè tale che risulti a[i] <= a[i+1] per qualsiasi valore di i. Per ordinare dei dati esistono due tecniche principali, dette rispettivamente ordinamenti interni e ordinamenti esterni. Gli ordinamenti interni si usano quando la lista dei dati non è troppo lunga e può essere memorizzata per intero nella memoria del computer, di solito in un vettore. Gli ordinamenti esterni si usano per insiemi di dati molto grandi, memorizzati in file su dischi esterni o su nastri, che non conviene caricare nella loro interezza nella memoria del computer.

21
Il primo caso (ordinamento di un vettore) corrisponde a ordinare le carte di un mazzo disponendole su un tavolo, in modo che siano tutte visibili e utilizzabili contemporaneamente da chi riordina. Il secondo caso (ordinamento di file) corrisponde invece a ordinare le carte disponendole in mucchietti o pile, in modo che solo la carta in cima a ogni pila sia visibile e utilizzabile.
 corrisponde invece a ordinare le carte disponendole in mucchietti o pile, in modo che solo la carta in cima a ogni pila sia visibile e utilizzabile.")
22
Un’altra classificazione degli algoritmi di ordinamento si basa sulla loro efficienza o economia di tempo. Una buona misura dell’efficienza si ottiene contando numeri di confronti tra chiavi e di movimenti (trasposizioni) necessari per il riordino. Queste quantità sono funzioni del numero n di elementi da ordinare. Anche se buoni algoritmi di ordinamento richiedono un numero di confronti dell’ordine di n log n, vedremo dapprima alcune tecniche semplici e ovvie, chiamate metodi diretti, che richiedono un numero di confronti dell’ordine di n2. Di seguito vedremo i seguenti algoritmi:

23
Ordinamenti O(n2)
")
24
Ordinamenti O(n log n)
")
25
Ordinamento a bolle (bubble sort)
Ordinamento a bolle (bubble sort). L’ordinamento a bolle è l’algoritmo di ordinamento più semplice, ma anche il più lento. Esso confronta le prime due componenti e, se la prima è maggiore della seconda, le scambia; continua così con tutte le coppie fino all’ultima; ripete i passi precedenti fino alla penultima coppia, poi fino alla terzultima,… fino a femarsi alla prima coppia. Il processo esegue quindi n-1 passate del vettore, in ciascuna delle quali il valore più grande si muove verso la fine del vettore, come le bolle all’interno di un liquido.
. L’ordinamento a bolle è l’algoritmo di ordinamento più semplice, ma anche il più lento. Esso. confronta le prime due componenti e, se la prima è maggiore della seconda, le scambia; continua così con tutte le coppie fino all’ultima; ripete i passi precedenti fino alla penultima coppia, poi fino alla terzultima,… fino a femarsi alla prima coppia. Il processo esegue quindi n-1 passate del vettore, in ciascuna delle quali il valore più grande si muove verso la fine del vettore, come le bolle all’interno di un liquido.")
26
Consideriamo, ad esempio, il seguente vettore:
Il 1° confronto, eseguito tra le prime due componenti (690 e 307), determina il loro scambio: Anche il 2° confronto, tra la seconda coppia di componenti del vettore riordinato (690 e 32), determina il loro scambio: Così pure il 3° confronto, tra la terza coppia di componenti del vettore (690, 155), determina il loro scambio:
, determina il loro scambio: Anche il 2° confronto, tra la seconda coppia di componenti del vettore riordinato (690 e 32), determina il loro scambio: Così pure il 3° confronto, tra la terza coppia di componenti del vettore (690, 155), determina il loro scambio:")
27
Lo stesso avviene per il 4° confronto tra la 4a coppia di componenti (690, 426).
Perciò al termine della prima passata l’elemento più grande (690) si trova alla fine del vettore. La seconda passata è analoga alla prima ma si ferma, nei confronti, alla penultima coppia di componenti del vettore. Il processo continua, fermandosi sempre a una coppia di componenti prima, fino a che sono state compiute n-1 passate.
 si trova alla fine del vettore. La seconda passata è analoga alla prima ma si ferma, nei confronti, alla penultima coppia di componenti del vettore. Il processo continua, fermandosi sempre a una coppia di componenti prima, fino a che sono state compiute n-1 passate.")
28
Per costruire lo pseudocodice, osserviamo che le componenti del nostro vettore sono a[0], a[1], a[2], a[3], a[4], e che n=5. Se diciamo che ogni confronto avviene tra una componente e la precedente, ossia - chiamando j l’indice della componente via via confrontata - tra a[j] e a[j-1], allora nella prima passata j varia da 1 a n-1. Dato che a ogni passata j si deve fermare a un valore precedente, fino a che nell’ultima passata assume il valore 1, possiamo indicare con i il valore finale assunto da j (ossia dire che j varia da 1 a i), e dire che i varia da n-1 a 1. Lo pseudocodice è quindi: for i (indice ultima componente confrontata) da n-1 a 1 for j (indice componente via via confrontata) da 1 a i if a[j-1] > a[j] { scambia a[j-1] con a[j] } end for
![Per costruire lo pseudocodice, osserviamo che le componenti del nostro vettore sono a[0], a[1], a[2], a[3], a[4], e che n=5. Se diciamo che ogni confronto avviene tra una componente e la precedente, ossia - chiamando j l’indice della componente via via confrontata - tra a[j] e a[j-1], allora nella prima passata j varia da 1 a n-1.](http://slideplayer.it/slide/3224135/11/images/28/Per+costruire+lo+pseudocodice%2C+osserviamo+che+le+componenti+del+nostro+vettore+sono+a%5B0%5D%2C+a%5B1%5D%2C+a%5B2%5D%2C+a%5B3%5D%2C+a%5B4%5D%2C+e+che+n%3D5.+Se+diciamo+che+ogni+confronto+avviene+tra+una+componente+e+la+precedente%2C+ossia+-+chiamando+j+l%E2%80%99indice+della+componente+via+via+confrontata+-+tra+a%5Bj%5D+e+a%5Bj-1%5D%2C+allora+nella+prima+passata+j+varia+da+1+a+n-1..jpg "Dato che a ogni passata j si deve fermare a un valore precedente, fino a che nell’ultima passata assume il valore 1, possiamo indicare con i il valore finale assunto da j (ossia dire che j varia da 1 a i), e dire che i varia da n-1 a 1. Lo pseudocodice è quindi: for i (indice ultima componente confrontata) da n-1 a 1. for j (indice componente via via confrontata) da 1 a i. if a[j-1] > a[j] { scambia a[j-1] con a[j] } end for.")
29
Ecco il corrispondente diagramma di flusso:
Ed ecco il corrispondente segmento di programma in C: void bubbleSort(int a[], int n) { int i, j, temp; for (i = (n-1); i >= 0; i--) for (j = 1; j <= i; j++) if (a[j-1] > a[j] temp = a[j-1]; a[j-1]= a[j]; a[j] = temp; }
 { int i, j, temp; for (i = (n-1); i >= 0; i--) for (j = 1; j <= i; j++) if (a[j-1] > a[j] temp = a[j-1]; a[j-1]= a[j]; a[j] = temp; }")
30
Esercizio. Ordinare il seguente vettore:
Quante passate sono state necessarie? Malgrado sia semplice da comprendere e facile da implementare, l’ordinamento a bolle è considerato di solito l’algoritmo di ordinamento più inefficiente. Nel caso migliore, in cui la lista sia già parzialmente ordinata, esso può raggiungere un livello di complessità O(n), mentre nel caso generale ha complesità O(n2), come mostra il grafico seguente.
, mentre nel caso generale ha complesità O(n2), come mostra il grafico seguente.")
31
Efficienza dell’algoritmo ordinamento a bolle

32
Miglioramenti. L’algoritmo si presta ad alcuni semplici miglioramenti.
Il primo deriva dall’osservazione che il vettore potrebbe risultare ordinato anche prima di avere eseguito tutte le n-1 passate; in tale caso le passate successive sarebbero superflue. Il miglioramento consiste allora nell’annotare se in una passata si siano efettuati degli scambi, e nel terminare l’algoritmo dopo avere eseguito una passata in cui non siano avvenuti scambi. Ecco lo pseudocodice: poni un contatore di scambi = 0 for i (indice ultima componente confrontata) da n-1 a 1 for j (indice componente via via confrontata) da 1 a i if a[j-1] > a[j] { scambia a[j-1] con a[j] incrementa il contatore di scambi } end or if contatore di scambi = 0 fine end for
 da n-1 a 1. for j (indice componente via via confrontata) da 1 a i. if a[j-1] > a[j] { scambia a[j-1] con a[j] incrementa il contatore di scambi. } end or. if contatore di scambi = 0 fine. end for.")
33
Esso corrisponde a modificare nel seguente modo il precedente diagramma di flusso:

34
Un secondo miglioramento si ottiene annotando non solo se sono stati eseguiti scambi, ma anche la posizione (indice) dell’ultimo scambio: infatti tutte le coppie di elementi adiacenti che si trovano prima di questo indice sono nell’ordine desiderato, cosicché le passate successive potranno partire dall’indice in questione. Si può osservare una particolare asimmetria: un elemento che si trovi in un posto “sbagliato” nell’estremità “pesante” di un vettore altrimenti già ordinato viene messo al posto giusto in una sola passata, mentre un elemento al posto “sbagliato” nell’estremità “leggera” si avvicina verso la posizione corretta di un solo posto per passata. Ad es., il vettore: verrebbe ordinato dal bubble sort migliorato in una sola passata, mentre il vettore richiederebbe sette passate per essere ordinato.

35
Questa asimmetria non intuitiva suggerisce, come terzo miglioramento, di alternare le passate successive, dando luogo a un algoritmo detto shakesort o cocktail sort. Il suo comportamento è illustrato in figura: i= r=

36
Secondo i puristi degli algoritmi, l’ordinamento a bolle non andrebbe mai usato anche se, in realtà, non c’è una notevole differenza di prestazioni tra i vari algoritmi di ordinamento fino a circa 100 elementi, e la semplicità dell’ordinamento a bolle lo rende attraente. Esso comunque non andrebbe usato per ordinamenti ripetitivi, o che coinvolgano più di 200 elementi. Molto più efficienti dell’ordinamento a bolle, sebbene anche essi abbiano complessità O(n2), sono gli algoritmi di ordinamento per selezione, inserimento e shell.
, sono gli algoritmi di ordinamento per selezione, inserimento e shell.")
37
Ordinamento per selezione
Ordinamento per selezione. Un altro ordinamento semplice, che migliora le prestazioni del bubble sort, è l’ordinamento per selezione. In esso: si seleziona la più piccola tra le componenti a[1], ... , a[n] (o una delle più piccole, se ve ne sono più uguali) e la si scambia con a[1]; 2. tra le componenti a[2], ... , a[n] del vettore così modificato si seleziona la successiva componente più piccola e la si scambia con a[2], e così si prosegue. Perciò all’inizio della generica (i-esima) iterazione le componenti a[1], ... , a[i-1] risultano ordinate, mentre le restanti componenti sono in un ordine qualsiasi:
 e la si scambia con a[1]; 2. tra le componenti. a[2], ... , a[n] del vettore così modificato si seleziona la successiva componente più piccola e la si scambia con a[2], e così si prosegue. Perciò all’inizio della generica (i-esima) iterazione le componenti. a[1], ... , a[i-1] risultano ordinate, mentre le restanti componenti sono in un ordine qualsiasi:")
38
Si continua così fino alla iterazione n-1-esima, dopo la quale tutto il vettore risulta ordinato.
Consideriamo, ad es., il seguente elenco iniziale di numeri:

39
Nel 1° passo si seleziona il numero 32 e lo si scambia con il 1° elemento dell’elenco.
Nel 2° passo si seleziona il numero 155 tra il 2° e il 5° elemento dell’elenco riordinato e lo si scambia con il 2°. Nel 3° passo si seleziona il numero 307 tra il 3° e il 5° elemento dell’elenco e lo si scambia con il 3°. Finalmente, nel 4° e ultimo passo si seleziona il restante valore minimo e lo si scambia con il 4° elemento.

40
Lo pseudo codice dell’ordinamento per selezione è il seguente:
Sebbene in questo esempio sia stato effettuato uno scambio in ciascun passo, lo scambio non si sarebbe effettuato se il valore più piccolo si fosse già trovato nella posizione corretta. Ovviamente ciascun passo comporta diversi confronti e sostituzioni, non indicati nello schema precedente. Lo pseudo codice dell’ordinamento per selezione è il seguente: for ogni elemento, dal primo all’ultimo [trova l’elemento minimo, dal corrente fino all’ultimo] scambia il valore minimo con l’elemento corrente; salva l’indice dell’elemento corrente; for ogni elemento, da quello corrente +1 fino all’ultimo if elemento[indice ciclo interno] < valore minimo poni valore minimo = elemento[indice ciclo interno] salva l’indice del nuovo valore minimo trovato fine dell’if fine del for scambia il valore corrente con il nuovo valore minimo

41
Ecco il relativo codice in C e il corrispondente diagramma di flusso.
void SelectSort(int A) { int i, j, min, t; for (i = 1; i<= n; i++) min = i; for (j = i+1; j <= n; j++) if (A[j] < A[min]) min = j; Swap(&A[min],&A[i]); }
 { int i, j, min, t; for (i = 1; i<= n; i++) min = i; for (j = i+1; j <= n; j++) if (A[j] < A[min]) min = j; Swap(&A[min],&A[i]); }")
42
Vedremo più avanti il programma in C completo.
L’ordinamento per selezione ha complessità di O(n2), come si vede dal grafico seguente.
, come si vede dal grafico seguente.")
43
L’ordinamento per selezione è l’unico nel quale il tempo di esecuzione non sia influenzato dal grado di ordine nell’elenco. Infatti la semplicità della sua struttura gli fa eseguire in ogni caso lo stesso numero di operazioni. Fornisce un miglioramento di prestazioni del 60% rispetto all’ordinamento a bolle, ma è oltre due volte più lento dell’ordinamento per inserimento, che è ugualmente facile da implementare. Perciò non vi è alcuna ragione per preferire l’ordinamento per selezione all’ordinamento per inserimento. L’ordinamento per selezione è stato definito “il figliastro non voluto” degli ordinamenti n2, e non andrebbe usato per ordinare elenchi con oltre elementi, o per ordinare ripetutamente elenchi con oltre 200 elementi.

44
Ordinamento per inserimento
Ordinamento per inserimento. Uno dei metodi più semplici per ordinare un vettore è l’ordinamento per inserimento che, come dice il nome, inserisce ciascun elemento nel suo posto “giusto” dell’elenco finale. La implementazione più semplice richiede due vettori distinti: il vettore sorgente e uno in cui inserire gli elementi ordinati. Un altro tipo di implementazione usa un ordinamento sul posto, che dapprima copia l’elemento corrente in una variabile temporanea, quindi confronta quest’ultima con tutti gli elementi precedenti fino a trovare il posto giusto dove inserire l’elemento. In tal modo il vettore viene ordinato senza utilizzare memoria aggiuntiva.

45
Partendo dall’inizio del vettore, esaminiamo la prima coppia di elementi ed estraiamo il 3. Spostiamo quindi verso il basso gli elementi che si trovano al di sopra finché non troviamo la posizione corretta in cui inserire il 3. Ripetiamo il procedimento con la seconda coppia di elementi (4-1), estraendo da essa il numero 1.
, estraendo da essa il numero 1.")
46
Infine completiamo l’ordinamento estraendo dall’ultima coppia (4-2) il 2 e inserendolo nella posizione corretta. Indichiamo con indice una variabile dove copiamo, temporaneamente, il valore di volta in volta considerato. Ecco il segmento di programma in C che esegue l’ordinamento per inserimento.

47
Ed ecco il corrispondente diagramma di flusso:
void OrdIns (int a[], int n) { int i, j, indice; for (i = 1; i < n; i++) indice = a[i]; j = i; while ((j>0) && (indice < a([j-1])) a[j] = a[j-1]; j = j - 1; } a[j] = indice; Ed ecco il corrispondente diagramma di flusso:
 { int i, j, indice; for (i = 1; i < n; i++) indice = a[i]; j = i; while ((j>0) && (indice < a([j-1])) a[j] = a[j-1]; j = j - 1; } a[j] = indice; Ed ecco il corrispondente diagramma di flusso:")
48
L’ordinamento per inserimento è di tipo stabile, nel senso che mantiene l’ordinamento originale quando vi siano elementi uguali nei dati in ingresso. Un esempio familiare si ha nel gioco delle carte: per ordinare le carte che si tengono in mano se ne estrae una, si scorrono le precedenti e s’inserisce la carta estratta nella posizione corretta. Questo processo viene ripetuto finché tutte le carte saranno nella giusta sequenza. Se il vettore da ordinare contiene n elementi, dobbiamo indicizzarne n-1; per ognuno di essi dobbiamo esaminarne e spostarne, al più, altri n-1. Ciò porta a un algoritmo di complessità O(n2), sia nel caso medio sia in quello peggiore, chiaramente evidenziata nella figura seguente. Osserviamo che, pur avendo la stessa complessità dell’ordinamento a bolle, l’ordinamento per inserimento è oltre due volte più efficiente di esso, anche se risulta inefficiente per liste lunghe.
, sia nel caso medio sia in quello peggiore, chiaramente evidenziata nella figura seguente. Osserviamo che, pur avendo la stessa complessità dell’ordinamento a bolle, l’ordinamento per inserimento è oltre due volte più efficiente di esso, anche se risulta inefficiente per liste lunghe.")
49
Efficienza dell’algoritmo di ordinamento per inserimento

50
Shell Sort. Shell sort, ideato da Donald L
Shell Sort. Shell sort, ideato da Donald L. Shell, è un algoritmo di ordinamento non-stabile e sul posto. Esso migliora l’efficienza dell’ordinamento per inserimento spostando velocemente gli elementi nelle loro destinazioni. La complessità media è O(n1.25), mentre quella del caso peggiore diventa O(n1.5). Nella figura è mostrato un esempio di ordinamento per inserimento.
, mentre quella del caso peggiore diventa O(n1.5). Nella figura è mostrato un esempio di ordinamento per inserimento.")
51
Per primo viene estratto il valore 1, il 3 e il 5 vengono spostati verso il basso di una posizione, e nel posto rimasto libero viene inserito il valore 1, per un totale di due spostamenti. Come mostra l’iterazione successiva, sono necessari due spostamenti per inserire il valore 2. Il processo continua fino all’ultima iterazione, per cui il totale degli spostamenti fatti sarà = 5. La figura seguente illustra invece un esempio di shell sort, eseguito sullo stesso vettore precedente.

52
Si inizia facendo un ordinamento per inserimento usando una spaziatura di 2. Nel primo passo vengono esaminati i valori 3-1. Estraendo 1, spostiamo il 3 verso il basso, per un totale di uno spostamento. Vengono quindi esaminati i valori 5-2. Si estrae il 2, si sposta il 5 verso il basso, e quindi si inserisce il 2. Dopo avere ordinato con una spaziatura 2, viene fatto un passo finale con una spaziatura 1, come nell’ordinamento per inserimento tradizionale. Il numero totale di spostamenti fatti usando shell sort è = 3. Quindi l’avere aumentato la spaziatura iniziale di una unità ha permesso di spostare più velocemente i valori nella posizione corretta.

53
Per implementare lo shell sort si possono usare diverse spaziature.
Di solito si ordina dapprima il vettore con una spaziatura grande, quindi si riduce la spaziatura e lo si riordina. Per l’ordinamento finale, la spaziatura vale 1. Sebbene lo shell sort sia facile da capire intuitivamente, una sua analisi formale risulta difficile. In particolare, la valutazione dei valori ottimali di spaziatura sfugge ai teorici. Knuth ha provato sperimentando diversi valori e raccomanda, per ottenere la spaziatura h per un vettore di dimensione n, di basarsi sulla seguente formula: valore di partenza h1 = 1 valore generico hs = 3hs-1 + 1 ultimo valore ht quando ht+2 >= n In questo modo, i valori di h vengono calcolati nel modo seguente:

54
h1 = 1 h2 = (3 x 1) + 1 = 4 h3 = (3 x 4) + 1 = 13 h4 = (3 x 13) + 1 = 40 h5 = (3 x 40) + 1 = 121
Per ordinare 100 elementi, troviamo il primo valore di hs tale che hs >= 100 ossia h5. Il valore finale (ht) si trova due passi più in basso, vale a dire h3. La sequenza dei valori di h sarà, pertanto: Determinato il valore iniziale di h, i valori successivi si possono calcolare con la formula: hs-1 = floor(hs/3) Ecco il relativo codice in C.
 si trova due passi più in basso, vale a dire h3. La sequenza dei valori di h sarà, pertanto: Determinato il valore iniziale di h, i valori successivi si possono calcolare con la formula: hs-1 = floor(hs/3) Ecco il relativo codice in C.")
55
void ShellSort(int A[])
{ int i, j, h=1, v; do h = 3*h+1; while (h <= n); h /= 3; for (i=h+1; i<= n; i++) v = A[i]; j = i; while ((j>h) && (A[j-h] > v)) A[j] = A[j-h]; j - = h; } A[j] = v; while (h > 1);
![void ShellSort(int A[])](http://slideplayer.it/slide/3224135/11/images/55/void+ShellSort%28int+A%5B%5D%29.jpg "{ int i, j, h=1, v; do. h = 3*h+1; while (h <= n); h /= 3; for (i=h+1; i<= n; i++) v = A[i]; j = i; while ((j>h) && (A[j-h] > v)) A[j] = A[j-h]; j - = h; } A[j] = v; while (h > 1);")




 Luigi Sante>")





>")



 ma, a differenza degli altri (fusione e quick sort) non richiede.>")


>")


