Scaricare la presentazione
1
Riassumendo: ipotesi per OLS 1.Modello lineare 2.X e Y sono frutto di osservazioni indipendenti 3.X è di rango pieno 4.I residui hanno media = 0 5.I residui sono omoschedastici e incorrelati 6.X è non-stocastica Neghiamo la 5: E( ’ )=
= ")
2
Naturalmente è una matrice simmetrica positiva definita Allora si può scomporre secondo i suoi autovalori/autovettori:

3
PARENTESI: Autovalori ( ) e autovettori (C) Sono la soluzione del sistema: Il numero di soluzioni (autovalori) è pari alla dimensione della matrice
 e autovettori (C) Sono la soluzione del sistema: Il numero di soluzioni (autovalori) è pari alla dimensione della matrice")
4
PARENTESI: Autovalori e autovettori Abbiamo torniamo all’equazione iniziale e troviamo C Per trovare i valori di C (autovalori) dobbiamo sfruttare il vincolo:
 dobbiamo sfruttare il vincolo:")
5
Si possono utilizzare OLS sui dati trasformati !!!!

6
Stimatore GLS

7
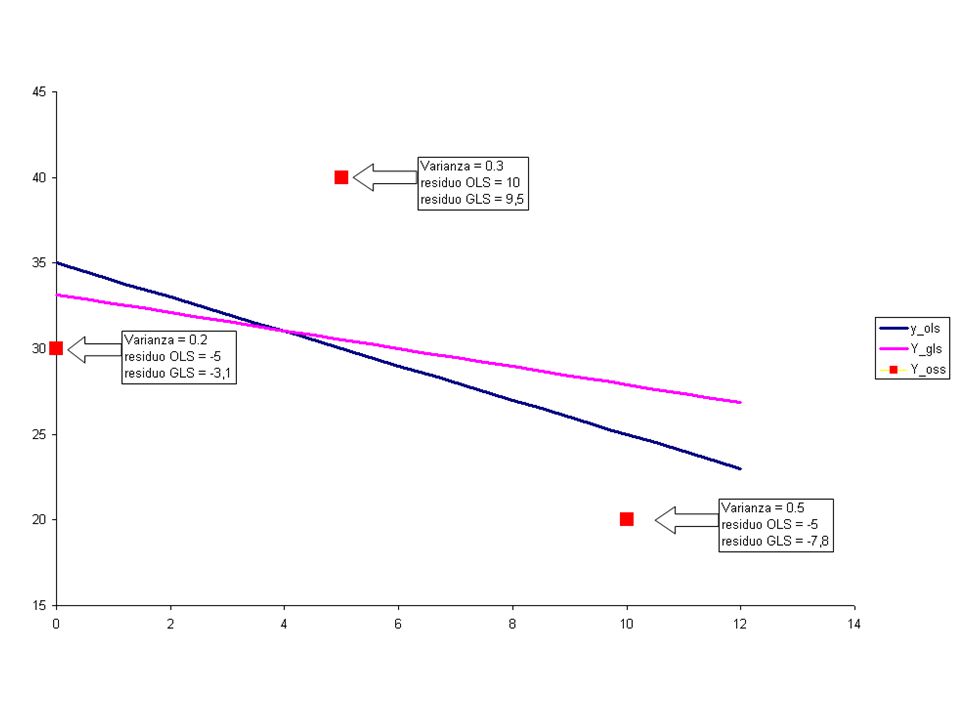
Un esempio numerico OLS: yxx' 20110111 30101005 4015 OLS X'X(X'X)-1X'YB 3150,83-0,109035 15125-0,100,02400
-1X YB 3150,83-0, ,100,02400")
8
Un esempio numerico GLS_1:

10
NB: La varianza della stima NON va calcolata come in OLS ma tenendo conto della Ω Non esiste un corrispondente dell’indice di Determinazione Lineare la funzione minimizzata e le sue statistiche riguarda i residui dei dati pesati * non gli Che il modello “pesato” abbia un buon adattamento, poco dice su quello originale

11
Caso di non noto, stima FGLS Cioè va stimata, con non pochi problemi: , in generale, ha n(n+1)/2 parametri, ovviamente non è possibile stimarla Direttamente a partire da n osservazioni Dobbiamo imporre qualche restrizione, cioè ipotizzare che dipenda da un numero (ristretto) di parametri, cioè che sia esprimibile nella forma = ( ) Cioè dobbiamo ipotizzare un modello per la Var-Covar del fenomeno
/2 parametri, ovviamente non è possibile stimarla Direttamente a partire da n osservazioni Dobbiamo imporre qualche restrizione, cioè ipotizzare che dipenda da un numero (ristretto) di parametri, cioè che sia esprimibile nella forma = ( ) Cioè dobbiamo ipotizzare un modello per la Var-Covar del fenomeno")
12
Determinata la forma della non noto, la stima FGLS consiste in processo iterativo Con i seguenti passi: NB!! Solo MLE garantisce la convergenza, alcune strutture di non sono “trattabili” partendo da OLS

13
Attenzione !!! MOLTO IMPORTANTE: In Assume la funzione di una ponderazione che viene “applicata” ai dati In quanto ponderazione NON è necessario che i suoi elementi siano esattamente Varianze e Covarianze Per garantire “buone proprietà” alla stima è SUFFICIENTE che la matrice utilizzata come “ponderazione” sia PROPORZIONALE alla matrice di VAR-COVAR Ad esempio possiamo ipotizzare una situazione in cui la varianza individuale sia proporzionale alla X: p.es. (reddito-consumo) i più ricchi sono più variabili nel determinare l’ammontare del loro consumo (legge Engels)
 i più ricchi sono più variabili nel determinare l’ammontare del loro consumo (legge Engels).")
14
Alcuni esempi di modelli di VAR-COVAR Diversa per ogni Gruppo-Effetto fisso costante ogni Gruppo Effetto fisso Max eterogeneità A bande Autoregressivo Ordine 1

15
Moving average Ordine q-1 Moving average Ordine 2 Correlazione spaziale F(distanza)
")
16
AR(1) eterogeneo Simmetrico eterogeneo fattoriale eterogeneo
 eterogeneo Simmetrico eterogeneo fattoriale eterogeneo")
















>")
>")

>")

