Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
UNIVERSITA’ DEGLI STUDI DI MODENA E REGGIO EMILIA FACOLTA’ DI INGEGNERIA – SEDE DI MODENA CORSO DI LAUREA IN INGEGNERIA INFORMATICA Anno Accademico 2002/2003 Relatore: Chiar.mo Prof. Sonia Bergamaschi Tesi di Laurea di: Roberta Benassi Controrelatore: Chiar.mo Prof. Paolo Tiberio TUCUXI: un agente basato su ontologie di dominio per la ricerca di nuove sorgenti Web

2
SEWASIE (http://www.sewasie.org) SEWASIE (Semantic Webs and AgentS in Integrated Economies) è un progetto finanziato dalla Commissione Europea (Maggio 2002/Aprile 2005). Goal: progettare e implementare un avanzato motore di ricerca basato sulla semantica. I partecipanti: Università degli Studi di Modena e Reggio Emilia CNA SERVIZI Modena s.c.a.r.l. Università degli Studi di Roma “La Sapienza” Rheinisch Westfaelische Technische Hochschule Aachen Libera Università di Bolzano Thinking Networks AG Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung eingetragener Verein IBM Italia SPA

3
SEWASIE (http://www.sewasie.org)

4
MOMIS (Mediator envirOnment for Multiple Information Sources ) Data level Wrapper Relational Source Relational Source Wrapper XML Source XML Source Wrapper Object Source Object Source Wrapper generic Source generic Source legenda CORBAObject User GUI Software tools CORBA interaction User interaction WordNet Service level ODB-Tools ODB-Tools Global Schema METADATA REPOSITORY Global Schema METADATA REPOSITORY Global Schema Builder QueryManager SLIMWordNet interaction SIMODB-Tools validation ARTEMISClustering TUNIMMap. table tuning SLIMWordNet interaction SIMODB-Tools validation ARTEMISClustering TUNIMMap. table tuning SI-Designer MOMIS mediator creates User Application Integration Designer Integration Designer USER level

5
MIKS (Mediator Agent for Integration of Knowledge Sources)
")
6
MOMIS (Mediator envirOnment for Multiple Information Sources ) Approccio virtuale: Global Virtual View Approccio Semantico: –Costruzione di un Common Thesaurus Relazioni intra-schema Relazioni lessicali –WordNet »Memoria lessicale umana » organizzazione in synset Relazioni aggiunte dal progettista Relazioni inferite Ontologia di dominio –Insieme di termini e relazioni fra essi
 Approccio virtuale: Global Virtual View Approccio Semantico: –Costruzione di un Common Thesaurus Relazioni intra-schema Relazioni lessicali –WordNet »Memoria lessicale umana » organizzazione in synset Relazioni aggiunte dal progettista Relazioni inferite Ontologia di dominio –Insieme di termini e relazioni fra essi")
7
Ricerca di Informazioni nel Web STRUMENTI GENERAL-PURPOSE –Web directories (Yahoo!, ODP,…) Tassonomia – Navigazione in cataloghi Massiccio intervento di operatori umani Servizio di qualità con scarsa copertura –Motori di ricerca veri e propri (Google, AltaVista, …) Spiders, crawlers, robots,… Ricerca per keywords Costruzione e manutenzione di indici –MetaMotori di ricerca (MetaCrawler, Profusion, SavvySearch, …) Integrazione degli strumenti precedenti Aumento della copertura STRUMENTI SPECIAL-PURPOSE –Specializzati per argomento (CiteSeer, …) –Personal Assistants (Letizia, WebWatcher,…)
 Tassonomia – Navigazione in cataloghi Massiccio intervento di operatori umani Servizio di qualità con scarsa copertura –Motori di ricerca veri e propri (Google, AltaVista, …) Spiders, crawlers, robots,… Ricerca per keywords Costruzione e manutenzione di indici –MetaMotori di ricerca (MetaCrawler, Profusion, SavvySearch, …) Integrazione degli strumenti precedenti Aumento della copertura STRUMENTI SPECIAL-PURPOSE –Specializzati per argomento (CiteSeer, …) –Personal Assistants (Letizia, WebWatcher,…)")
8
Obiettivi Agente JADE (Java Agent DEvelopment Framework) http://jade.cselt.it http://jade.cselt.it Ricerca non supervisionata di sorgenti HTML Comportamento etico verso le sorgenti visitate Utilizzo di un Common Thesaurus come strumento per esprimere le richieste di un utente Valutazione dell’affinità delle sorgenti individuate per l’integrazione in una Global Virtual View di MOMIS TUCUXI (InTelligent HUnter Agent for Concept Understanding and LeXical ChaIning)
 Ricerca non supervisionata di sorgenti HTML Comportamento etico verso le sorgenti visitate Utilizzo di un Common Thesaurus come strumento per esprimere le richieste di un utente Valutazione dell’affinità delle sorgenti individuate per l’integrazione in una Global Virtual View di MOMIS TUCUXI (InTelligent HUnter Agent for Concept Understanding and LeXical ChaIning)")
9
Estrazione della semantica Pagine HTML –Human readable –Forte componente visiva Comprensione del testo (Natural Language Processing – NLP) –Full semantic understanding »Grande complessità »Forte dipendenza dalla lingua –Partial semantic understanding »Determinare la struttura del discorso
 –Full semantic understanding »Grande complessità »Forte dipendenza dalla lingua –Partial semantic understanding »Determinare la struttura del discorso")
10
Coesione e Coerenza Proprietà fondamentali di un testo –Coesione (micro livello) –Coerenza (macro livello) Coesione –“the set of possibilities that exists in one language for making the text hang together” R. Hasan e M. Halliday, 1976 –Grammaticale –Lessicale

11
Catene lessicali (Lexical Chain) Insieme di termini e le relazioni che intercorrono fra di essi Effetto secondario: disambiguazione dei termini Algoritmo di clustering Greedy –Rapidi ma imprecisi Dinamici – complessità computazionale esponenziale
 Insieme di termini e le relazioni che intercorrono fra di essi Effetto secondario: disambiguazione dei termini Algoritmo di clustering Greedy –Rapidi ma imprecisi Dinamici – complessità computazionale esponenziale")
12
TUCUXI – Estrazione della semantica Algoritmo lineare di Silber e McCoy - Basato su WordNet (file dei nomi) - (2002) Segmentazione di una pagina HTML »Titoli e/o headers »Liste »Corpo del documento Inclusione delle relazioni di holonymy e meronymy (RT), oltre a synonymy, hyponymy, hypernymy Utilizzo di eventuali estensioni a WordNet
 - (2002) Segmentazione di una pagina HTML »Titoli e/o headers »Liste »Corpo del documento Inclusione delle relazioni di holonymy e meronymy (RT), oltre a synonymy, hyponymy, hypernymy Utilizzo di eventuali estensioni a WordNet")
13
TUCUXI – Algoritmo per l’estrazione delle catene lessicali Estrazione delle parole candidate Meccanismo di voto Disambiguazione dei termini Pruning Le catene lessicali sono cluster di termini in relazione Fusione dei cluster al fine di estrarre una mappa concettuale Mappa concettuale come rappresentazione sintetizzata del testo

14
TUCUXI – Affinità Un nuovo modo di calcolare l’affinità –Ipotesi sul Common Thesaurus –Derivato dalle proprietà coesive del testo –Derivato da una misura di synset match Due misure proposte

15
Confronto con Google Base comune per il confronto Query a Google con keywords estratte dal Common Thesaurus Es: ricerca dei corsi di computer science di una facoltà: –Faculty “computer science” course Buone capacità di filtro Non è necessario per TUCUXI la presenza di keywords, bastano i sinonimi

16
TUCUXI – Ricerca di sorgenti HTML Comportamento etico –Rispetto del meta tag Robots HTML –Rispetto del file robots.txt User-agent = * Disallow = /cgi-bin/ –Iscrizione al Web Robots Database http://www.robotstxt.orghttp://www.robotstxt.org Capacità di muoversi da un ambiente ad un altro (ad esempio attraverso Internet) verso dati e risorse »Modalità page mode »Modalità site mode
 verso dati e risorse »Modalità page mode »Modalità site mode")
17
Focused Crawling Scopi –Recuperare il numero maggiore di documenti rilevanti visitando il numero minore di pagine non rilevanti Vantaggi –Utilizzo limitato delle risorse –Nuovi strumenti per esprimere le esigenze di un utente Limiti –Machine Learning da set di esempi

18
Intelligent Focused Crawling Evoluzione delle strategie di esplorazione best-first Costruzione di un modello statistico basato sulla proprietà condizionata »Content based Learning »Linking based Learning »Sibling based Learning »URL Token based Learning TUCUXI Intelligent Focused Crawling basato su »Content based learning »Linking based learning »Sibling based learning »Synset based learning Capacità di comportamenti reattivi e pro-attivi »Variazione dinamica del calcolo delle priorità »Riuso delle informazioni raccolte in successive sessioni di crawling

19
Confronto fra fattori di learning Il fattore semantic based learning è robusto rispetto agli altri parametri

20
Confronto fra strategie La strategia di TUCUXI è migliore rispetto alle altre sia in modalità page mode che in modalità site mode

21
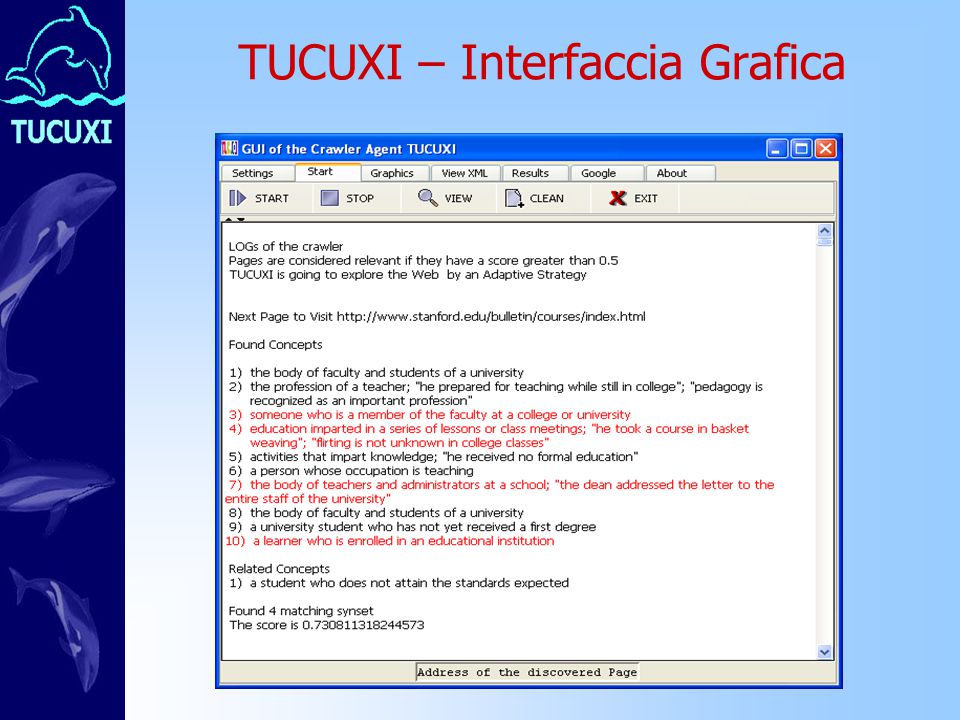
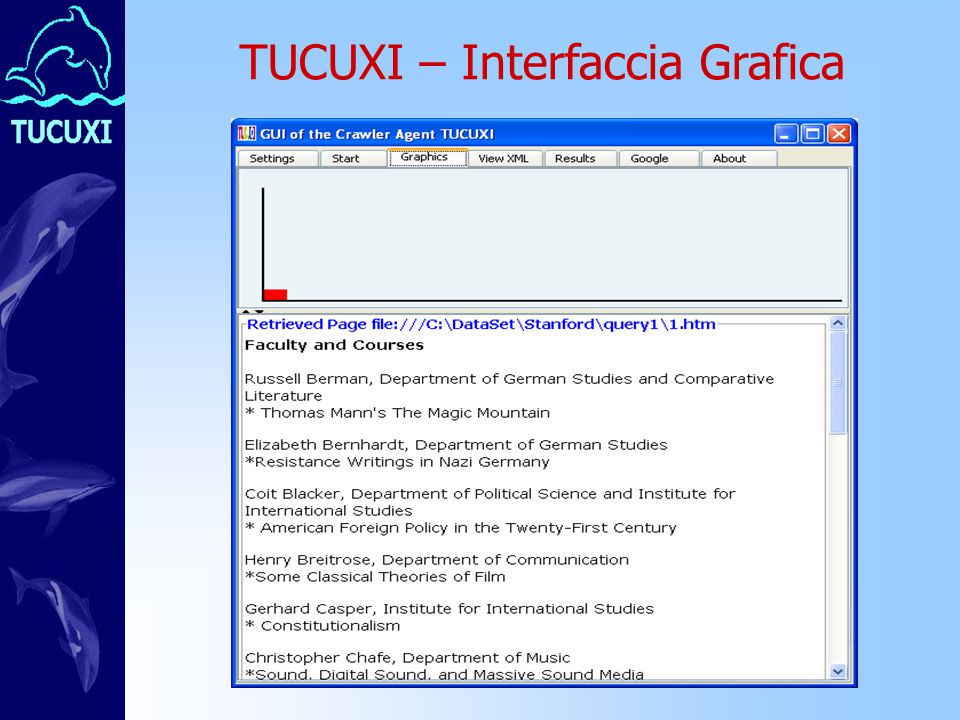
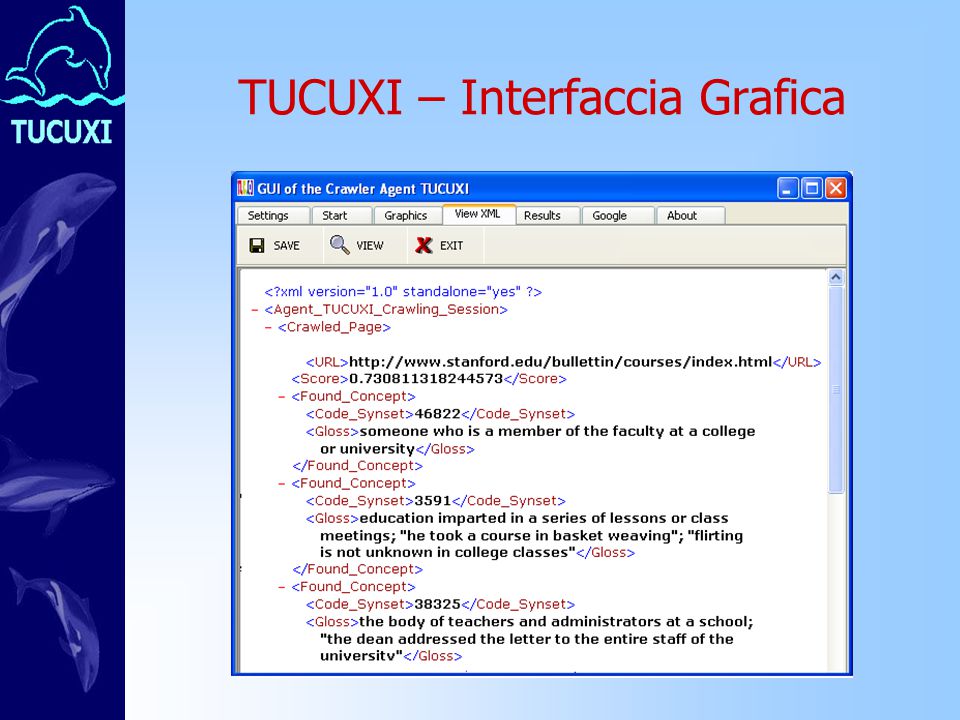
TUCUXI – Interfaccia Grafica

26
TUCUXI – Interazione con Google

27
Conclusioni TUCUXI offre svariate funzionalità TUCUXI adotta un comportamento intelligente sia per la ricerca che per la valutazione del grado di affinità (approccio NLP) TUCUXI è anche un meta-motore di ricerca (Google e ODP) TUCUXI “sbaglia” se sbaglia il part of speech tagger
 TUCUXI è anche un meta-motore di ricerca (Google e ODP) TUCUXI sbaglia se sbaglia il part of speech tagger")
28
Sviluppi Futuri Nuovi parametri per la strategia di esplorazione (es. Location Metric). Matching con Mappe Concettuali parziali. Sviluppo su piattaforma Jade di sistemi multiagente basati su EuroWordNet.
. Matching con Mappe Concettuali parziali. Sviluppo su piattaforma Jade di sistemi multiagente basati su EuroWordNet..")
Presentazioni simili



















 consiste nella realizzazione di un sistema intelligente di.>")
