Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
TRATTAMENTO DEI DATI ANALITICI I compiti del chimico analista vanno oltre la corretta esecuzione di una metodica analitica. Sono altrettanto importanti i passi successivi: Registrazione accurata dei dati sperimentali e corretta esecuzione dei calcoli Scelta del valore migliore qualora la stessa determinazione sia stata eseguita piu’ volte Valutazione dei risultati ottenuti e calcolo dei limiti probabili dell’errore che poi vanno indicati insieme al risultato Elaborazione di una strategia per controllare le fonti di errore e migliorare così la qualità delle prestazioni analitiche

2
COSA VUOL DIRE FARE STATISTICA Quando si fanno affermazioni del tipo: il profitto di questa classe è in media sufficiente; quest’anno sono di moda le vacanze di tipo agrituristico si fanno affermazioni di tipo statistico.

3
STATISTICA La statistica si occupa della -raccolta, -classificazione -analisi dei dati che esprimono aspetti di fenomeni collettivi scelti come oggetto di studio e che si manifestano negli elementi di un determinato insieme. Scopo della statistica è quello di descrivere questi fenomeni o di individuare regolarità di comportamento in essi.

4
Indagine statistica Raccolta dei dati Spoglio e trascrizione dei dati Elaborazione dei dati

5
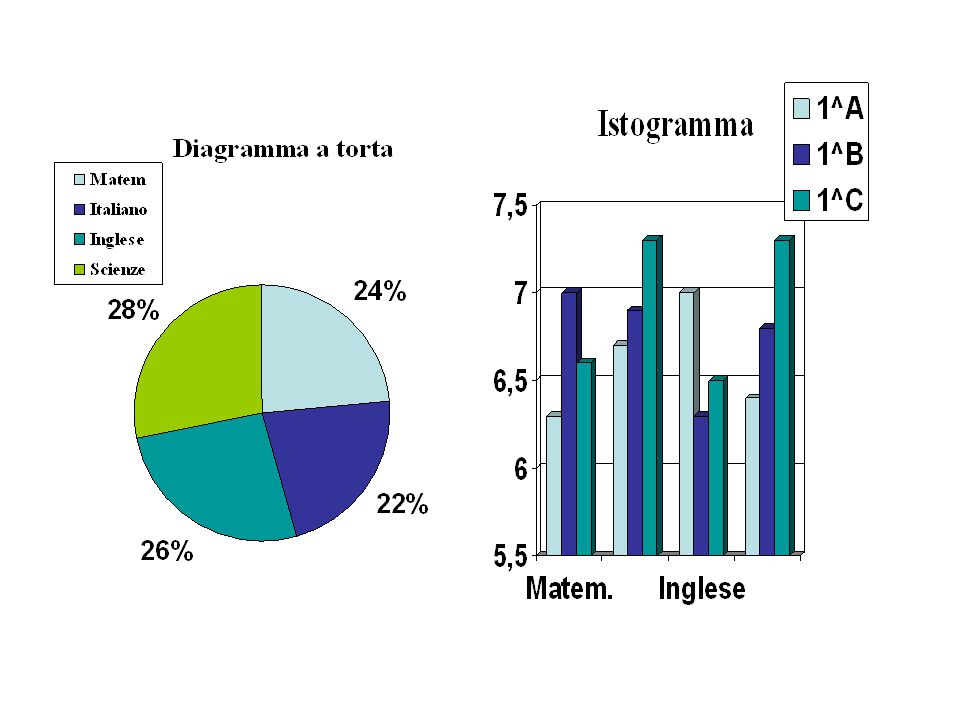
Rappresentazione dei dati (grafici) perché con l’immagine si riesce a dare un quadro generale della situazione indagata riuscendo a dare informazioni facilmente, rapidamente comprensibili. Quali grafici? Istogrammi, diagrammi a torta, grafici cartesiani, cartogrammi, ecc.

7
Cartogramma

8
Indici Statistici Per sintetizzare i dati ed evidenziare una certa caratteristica: Indici di tendenza centrale Indici di dispersione

9
La media Non esiste una sola media buona per ogni occasione, ma esistono più medie e verrà scelta la più adatta a mettere in evidenza la situazione cercata.

10
La media Gli obiettivi che ci si prefigge nel calcolo di una media sono sostanzialmente due: 1)sostituire a più dati rilevati un solo numero che dia però una efficace rappresentazione del fenomeno dato; esprimere l’ordine di grandezza o tendenza centrale dell’insieme dei dati relativi a un fenomeno. Tale ordine di grandezza può a volte sfuggire perché i dati sono spesso differenti fra loro.

11
La Media A questo punto bisogna dare dei criteri pratici per calcolare tale valor medio; i più importanti, quindi quelli più usati, sono i seguenti: a)si può calcolare il valor medio come funzione matematica dei dati rilevati e in tal caso si parla di media analitica; si possono ordinare i dati rilevati e ottenere la media in relazione alla posizione che occupa fra essi e in tal caso si parla di media di posizione.
si può calcolare il valor medio come funzione matematica dei dati rilevati e in tal caso si parla di media analitica; si possono ordinare i dati rilevati e ottenere la media in relazione alla posizione che occupa fra essi e in tal caso si parla di media di posizione.")
12
La media aritmetica La media aritmetica semplice M di n valori è il rapporto fra la loro somma e il loro numero n: x= i=1 N xixi n

13
La media aritmetica ponderata Quando ciascuna modalità si presenta con una certa frequenza o peso, è più vantaggioso calcolare la media aritmetica considerando le frequenze (assolute o relative): in tal caso si parla di media aritmetica ponderata perché ogni valore entra nella media con il suo peso, cioè la sua frequenza. La media aritmetica ponderata M di n valori è:

14
Calcolo della media ponderata

15
Attenzione! Non sempre il calcolo della media aritmetica rappresenta in modo significativo l’insieme dei valori a cui si riferisce. Per esempio, assegnati i valori:

16
È opportuno allora definire altri valori medi che non siano frutto di calcolo matematico, ma che siano individuati in base alla loro posizione nella sequenza dei valori osservati. Tali medie si dicono medie di posizione le più utilizzate sono: La moda La mediana

17
La MODA Moda di un fenomeno è la modalità con frequenza più elevata. Mo = 6

18
La MEDIANA Mediana: è il valore divisorio in quanto bipartisce la successione dei dati in due gruppi ugualmente numerosi; è il valore che taglia in due parti uguali la distribuzione dei dati ordinati, cioè il termine preceduto e seguito dallo stesso numero di dati.

19
Mediana Me di n valori ordinati in modo non decrescente è: Esempio: dati i valori ordinati: 1, 2, 2, 3, 4, 5, 6 Me = 3 Se n è dispari la mediana è il valore centrale Se n è pari la mediana è la media dei due valori centrali

20
La variabilità Il calcolo della media ci permette di sintetizzare una quantità di dati, ma dall’altro riduce l’informazione racchiudendo tanti valori in un solo ‘dato’, rende simili situazioni che proprio simili non sono. Per ridurre la perdita di informazioni, si ricorre allo studio della variabilità del fenomeno.

21
Variabilità è la tendenza di un fenomeno ad assumere modalità diverse fra loro. La variabilità può essere rappresentata graficamente mediante il diagramma di dispersione.

22
Indici statistici di variabilità Campo di variazione o range R Varianza Scarto quadratico medio …. Permettono di valutare le disuguaglianze dei dati rilevati in relazione al loro scostamento o dispersione da una media.

23
Campo di variazione o range R di un insieme di valori osservati è la differenza fra il valore massimo e il valore minimo: R= x max - x min

24
Attenzione tale indice presenta due grossi difetti: 1) dipende esclusivamente dai valori massimo e minimo registrati, senza considerare i valori intermedi; 2) su di esso influisce pesantemente la presenza anche di un solo valore anomalo. Altri indici di variabilità, più raffinati, si possono trovare utilizzando un altro criterio,cioè la variabilità rispetto a un centro che può essere la media.

25
La varianza La varianza è la media aritmetica degli scarti dalla media al quadrato, 2 (sigma quadrato).
.")
26
Scarto quadratico medio Lo scarto quadratico medio o deviazione standard è la radice quadrata (positiva) della varianza.
 della varianza.")
27
Normalizzazione La normalizzazione è un’operazione statistica che permette di mettere a confronto distribuzioni diverse. Avendo due prove il cui punteggio grezzo massimo raggiungibile dagli studenti è diverso, 30 nella prima prova e 45 nella seconda prova, non permette di confrontare i risultati ottenuti. Per superare questo inconveniente ricorro alla normalizzazione. Essa si basa su una proporzione: (Punti studente) : (p.ti totali) = (P.ti studente normalizzati) : 100
 : (p.ti totali) = (P.ti studente normalizzati) : 100.")
28
Per A1 I p. 25 : 30 = x : 100 x = 25/30x100 = 83,3 II p. 40 : 45 = x : 100 x = 40/45x100 = 88,9 Normalizzazione

29
Come leggere i risultati Nella tabella successiva sono riportati i dati relativi alla media, alla deviazione standard, al valore minimo e massimo, alla mediana e alla moda. Vediamo come leggere questi dati aiutandoci con le definizioni di tali valori statistici ed un esempio di risultati ottenuti da una scuola. I punteggi sono normalizzati a 100: la scala di riferimento ha come valore minimo 0 (le risposte a tutti i quesiti della prova sono errate) e come valore massimo 100 (le risposte a tutti i quesiti della prova sono corrette).
 e come valore massimo 100 (le risposte a tutti i quesiti della prova sono corrette)..")
30
Media (o punteggio medio) È la somma dei punteggi ottenuti dagli studenti diviso il numero totale degli stessi. Una media elevata indica la presenza nella scuola di elevate competenze, al contrario una media bassa indica la presenza di scarse competenze nella scuola. Nell'esempio la Media (o punteggio medio) è 59,3; Moda È il punteggio ottenuto più frequentemente dagli studenti, nell'esempio la scuola ha ottenuto come valore modale 73,3. Ovvero tra tutti i punteggi possibili tra 0 e 100, tale punteggio è quello ottenuto da più studenti. Mediana È il punteggio in corrispondenza del quale gli studenti vengono esattamente divisi in due parti uguali. Nell'esempio la mediana corrisponde a 61,3 e indica che il 50% degli studenti ha ottenuto un punteggio inferiore a 61,3% e che il restante 50% ha ottenuto un punteggio superiore al 61,3;
 è 59,3; Moda È il punteggio ottenuto più frequentemente dagli studenti, nell esempio la scuola ha ottenuto come valore modale 73,3. Ovvero tra tutti i punteggi possibili tra 0 e 100, tale punteggio è quello ottenuto da più studenti. Mediana È il punteggio in corrispondenza del quale gli studenti vengono esattamente divisi in due parti uguali. Nell esempio la mediana corrisponde a 61,3 e indica che il 50% degli studenti ha ottenuto un punteggio inferiore a 61,3% e che il restante 50% ha ottenuto un punteggio superiore al 61,3;.")
31
Minimo E' il punteggio più basso ottenuto dagli studenti. Nell'esempio il punteggio minimo è 20,0; Massimo E' il punteggio più alto ottenuto dagli studenti. Nell'esempio il punteggio massimo è 98,2; Deviazione standard È una misura della dispersione del punteggio intorno al punteggio medio. Un basso valore della deviazione standard indica che i punteggi sono concentrati intorno alla media e che le competenze degli studenti sono omogenee; al contrario una deviazione standard alta indica che le competenze degli studenti sono disomogenee. Nel nostro esempio, aggiungendo e sottraendo al punteggio medio (59,3) la deviazione standard (16,9) si ottiene un intervallo (42,4 - 76,2) in cui si trova il 68% degli studenti. Analogamente aggiungendo e sottraendo 2 volte la deviazione standard si ottiene un intervallo (25,5 - 93,1) in cui si trova il 95% degli studenti.
 la deviazione standard (16,9) si ottiene un intervallo (42,4 - 76,2) in cui si trova il 68% degli studenti. Analogamente aggiungendo e sottraendo 2 volte la deviazione standard si ottiene un intervallo (25,5 - 93,1) in cui si trova il 95% degli studenti..")
32
Confronto con il campione nazionale Nel confronto tra i dati della scuola e quelli del campione nazionale si dovrà tener conto dell’errore di campionamento. Esempio: se la scuola ha M = 80 e la media del campione è M c = 70 con un errore di 10, il dato della scuola non si discosta significativamente dal dato del campione 80 70 10

33
Coefficiente di variazione Il coeff.di variazione è dato dal rapporto tra deviazione standard e media moltiplicato per 100. Se supera una certa percentuale % indica una variablità eccessiva, fuori ai parametri di normalita’.

34
L’errore sperimentale e la sua valutazione nelle determinazioni analitiche Ogni misura presenta una qualche incertezza, chiamata errore sperimentale Risultati di 6 determinazioni replicate del ferro in campioni acquosi di una soluzione standard contenente 20,00 ppm di Fe(III).
.")
35
GLI ERRORI NELL’ANALISI CHIMICA Ogni analisi chimica (ogni misurazione!) è affetta da errori sperimentali. Gli errori sperimentali si combinano tra loro in modo da rendere ogni nuova misura pi ù o meno diversa dalla precedente. L ’ incertezza della misura sperimentale non può mai essere eliminata completamente perciò il valore vero di una quantit à è sempre sconosciuto. Tuttavia, spesso può essere valutata l'entit à probabile dell'errore. È possibile definire i limiti entro cui il valore vero di una quantit à misurata cade con un dato livello di probabilit à. E’ sempre indispensabile effettuare una stima dell’affidabilità dei dati sperimentali anche se la stima dell’accuratezza dei dati sperimentali non è sempre facile 35 Una delle domande a cui rispondere prima di cominciare un'analisi è : "qual è il massimo errore tollerabile nel risultato ”. La risposta a questo quesito determina il tempo richiesto per il lavoro: nessuno può permettersi di produrre dati che siano più accurati di quanto occorra. Ogni volta che collezioniamo i risultati di un’analisi è necessario stimarne precisione ed accuratezza Dati con precisione ed accuratezza ignote sono privi di significato

36
Sia dato un insieme di misure x 1, x 2, … x N. Media: Mediana: avendo ordinato le misure in ordine crescente o decrescente N parila mediana è la media della coppia centrale dei valori N dispari la mediana è il valore centrale Nel caso delle misure:10, 10, 12, 13, 13, 13, 15, 18, 25, 26, 26, 27, 28, 28, 35 la media è 19,93 e la mediana è 18. DEFINIZIONI 36

37
Media aritmetica o media di N valori sperimentali 18,3018,4018,5018,6018,70 media

38
Mediana Il risultato centrale dei dati replicati ordinati Nel caso di un numero pari di dati replicati si calcola la media della coppia centrale 18,3018,4018,5018,6018,70 media mediana

39
La dispersione dei valori misurati intorno al valore medio Descrive il grado di riproducibilità delle misure ed è una valutazione dell’ accordo dei dati ottenuti. Grandezze utilizzate per indicare la precisione di una serie di dati replicati (MISURANO la dispersione dei dati ottenuti e permettono di definire i limiti probabili dell’errore associato al risultato): deviazione standard varianza coefficiente di variazione Precisione
: deviazione standard varianza coefficiente di variazione Precisione.")
40
Rappresenta lo scostamento tra il valore misurato ed il valore vero o accettato In altri termini è una misura della bontà dell’accordo tra il risultato, x i, o il valore medio dei risultati di un’analisi, ed il valore vero o supposto tale, x t. X t = valore vero…. Risultato che possiede un certo numero di cifre significative E’ espressa in termini di errore assoluto o errore relativo Accuratezza Errore assoluto:oppure Errore relativo:oppure

41
Precisione: bont à dell ’ accordo tra i risultati di misurazioni successive. Accuratezza: bont à dell ’ accordo tra il risultato, x i, o il valore medio dei risultati di un ’ analisi, ed il valore vero o supposto tale, x t. Né accurato né preciso Non accurato ma preciso Accurato ma non preciso Accurato e preciso 41

42
Tipi di errori nei dati sperimentali

43
Errore sistematico o errore determinato: è un errore ricorrente (riproducibile) che può essere rivelato e corretto (strumentazione non tarata, errori di metodo, errore personali) e influenza l’accuratezza dei risultati ACCURATEZZA: indica la vicinanza della misura al valore vero (accettato) Errore casuale o indeterminato: deriva dall’effetto prodotto da una serie di variabili incontrollate (e talvolta incontrollabili: variazioni temperatura e tensione elettrica, vibrazioni) e influenza la precisione di una misura PRECISIONE: descrive la riproducibilità delle misurazioni Errore grossolano: si presenta occasionalmente, è spesso elevato e fa sì che un singolo dato si discosti da tutti gli altri dati di una serie di misure replicate
 che può essere rivelato e corretto (strumentazione non tarata, errori di metodo, errore personali) e influenza l’accuratezza dei risultati ACCURATEZZA: indica la vicinanza della misura al valore vero (accettato) Errore casuale o indeterminato: deriva dall’effetto prodotto da una serie di variabili incontrollate (e talvolta incontrollabili: variazioni temperatura e tensione elettrica, vibrazioni) e influenza la precisione di una misura PRECISIONE: descrive la riproducibilità delle misurazioni Errore grossolano: si presenta occasionalmente, è spesso elevato e fa sì che un singolo dato si discosti da tutti gli altri dati di una serie di misure replicate")
44
ERRORE SISTEMATICO 44 Gli errori sistematici hanno un valore definito ed una causa identificabile. Per misure replicate effettuate nello stesso modo hanno lo stesso ordine di grandezza e generalmente influenzano tutti i risultati di un set di misura allo stesso modo. Provocano uno scostamento unidirezionale dal valore vero che può essere costante o proporzionale e che può assumere valore sia positivo che negativo. Gli errori sistematici introducono un bias nella tecnica di misura. Bias: misura dell’errore sistematico associato ad una analisi. Può avere segno positivo o negativo.

45
Errore sistematico (o determinato) Causa lo scostamento della media di un set di dati sperimentali dal valore vero (o accettato) Influenza l’accuratezza di una misura 18,3018,4018,5018,6018,70 x0x0 xmxm
 Causa lo scostamento della media di un set di dati sperimentali dal valore vero (o accettato) Influenza l’accuratezza di una misura 18,3018,4018,5018,6018,70 x0x0 xmxm")
46
Cause degli errori sistematici Errori strumentali: dovuti a imperfezioni e malfunzionamento degli strumenti di misura –Variazioni di temperatura –Contaminazione dell’equipaggiamento –Fluttuazioni nella tensione di alimentazione –Guasto o malfunzionamento di componenti Errori di metodo: dovuti a comportamento chimico o fisico non ideale dei reagenti e delle reazioni utilizzate in un procedimento analitico Errori personali: causati da valutazioni personali dell’analista nel corso del procedimento analitico adottato

47
Rivelazione e correzione degli errori sistematici analisi di campioni standard, se disponibili; analisi del campione mediante un metodo indipendente, ovvero che prevede l'utilizzo di strumentazione di provata affidabilit à o di riferimento; analisi del bianco, cio è di una soluzione contenente tutti i componenti presenti nel campione in esame eccetto l'analita di interesse; il bianco ideale è costituito dalla stessa matrice in cui è contenuto l'analita di interesse; l'analisi del bianco nelle titolazioni volumetriche consente, per esempio, di correggere l'errore connesso al volume di titolante necessario per far virare l'indicatore colorimetrico stesso; analisi di campioni contenenti un diverso ammontare della variabile misurata (per es. si pensi alla perdita connessa alla solubilit à durante il lavaggio con volumi diversi di acque di lavaggio). Gli errori sistematici possono essere identificati ed annullati mediante
. Gli errori sistematici possono essere identificati ed annullati mediante.")
48
Rivelazione e correzione degli errori sistematici 18,3018,4018,5018,6018,70 x0x0 xmxm 18,3018,4018,5018,6018,70 x0x0 xmxm Analisi di standard Calibrazione

49
Errore sistematico o determinato L’errore sistematico viene rivelato utilizzando opportuni std. di riferimento (analita a concentrazione nota) e calcolando l’accuratezza L’accuratezza di una misura è il grado di accordo tra essa e il valore vero e viene espressa dall’errore (assoluto o relativo) Errore assoluto = valore osservato – valore vero valore osservato – valore vero Errore relativo = valore vero x100
 e calcolando l’accuratezza L’accuratezza di una misura è il grado di accordo tra essa e il valore vero e viene espressa dall’errore (assoluto o relativo) Errore assoluto = valore osservato – valore vero valore osservato – valore vero Errore relativo = valore vero x100.")
50
Determinazioni dell’ azoto in due composti puri con il metodo di Kjeldahl I punti mostrano gli errori assoluti dei risultati (X i -X t ) replicati ottenuti da 4 analisti Linea blu rappresenta la deviazione media assoluta dei dati dal valore vero (X m -X t ) Analista 1 accurato e preciso Analista 2 accurato ma poco preciso Analista 3 preciso ma poco accurato Analista 4 poco accurato e poco preciso
 replicati ottenuti da 4 analisti Linea blu rappresenta la deviazione media assoluta dei dati dal valore vero (X m -X t ) Analista 1 accurato e preciso Analista 2 accurato ma poco preciso Analista 3 preciso ma poco accurato Analista 4 poco accurato e poco preciso")
51
Errore casuale (o indeterminato) Provoca la dispersione dei dati sperimentali intorno al valore medio. Riflette la precisione di una misura 18,3018,4018,5018,6018,70 18,3018,4018,5018,6018,70 xtxt xtxt xmxm xmxm

52
Errore casuale o indeterminato L’errore casuale ha pari probabilità di essere positivo o negativo (dispersione dei dati più o meno simmetrica intorno al valore medio) e non può essere corretto. -4 piccoli errori si combinano per dare le deviazioni indicate dal valore medio. -Ciascun errore ha la stessa probabilità di verificarsi e la somma finale sia > o < di una quantità fissa ±U -in tabella tutte le possibili combinazioni e la frequenza relativa con cui avvengono.

53
Distribuzione teorica relativa per 4 incertezze Distribuzione teorica relativa per 10 incertezze. La deviazione più frequente dalla media è 0, mentre la deviazione max 10U si verifica una volta ogni 500 misure Distribuzione teorica relativa ad un numero molto grande di incertezze ne risulta una curva Gaussiana o curva normale dell’ errore.

54
Distribuzione dei risultati sperimentali Nella maggior parte degli esperimenti analitici quantitativi la distribuzione dei dati replicati è simile a quella di una curva Gaussiana e questo perché la deviazione dalla media è conseguente all’errore casuale

55
L’ esperimento di calibrazione di una pipetta da 10 ml prevede che un recipiente con tappo venga pesato vuoto, nel recipiente si trasferiscano 10 ml di acqua con la pipetta da 10 ml, e il tutto venga ripesato. Si misuri la temperatura dell’ acqua per stabilirne la densità, quindi si faccia la differenza tra le due masse e si calcolino i ml dividendo la massa per la densità. L’ esperimento viene ripetuto per 50 volte. La media si calcola con la funzione =MEDIA(B3:B19; E3:E19; H3:H18) La mediana si calcola con la funzione =MEDIANA(B3:B19; E3:E19; H3:H18) La deviazione standard con opportuna funzione. Il valore max si calcola con la funzione =MAX(B3:B19; E3:E19; H3:H18) Il valore min si calcola con la funzione =MIN(B3:B19; E3:E19; H3:H18) La dispersione è la differenza tra valore max e minimo, e corrisponde alla Sommatoria di tutte le incertezze dell’ esperimento.
 La mediana si calcola con la funzione =MEDIANA(B3:B19; E3:E19; H3:H18) La deviazione standard con opportuna funzione. Il valore max si calcola con la funzione =MAX(B3:B19; E3:E19; H3:H18) Il valore min si calcola con la funzione =MIN(B3:B19; E3:E19; H3:H18) La dispersione è la differenza tra valore max e minimo, e corrisponde alla Sommatoria di tutte le incertezze dell’ esperimento..")
56
1) I dati si possono riorganizzare in gruppi di distribuzione di frequenza ovvero numero di dati che rientrano in una serie di celle adiacenti di ampiezza 0.003 ml. 2) Si calcolano le % di misure contenute in ogni cella (3/50 x 100)=6. Si nota che il 26% dei Risultati si trova nell’ intervallo 9.981-9.983. Questo è il gruppo che contiene media e mediana. Più di meta dei risultati è contenuto in un intervallo di ± 0.004 ml rispetto al valore medio.
 Si calcolano le % di misure contenute in ogni cella (3/50 x 100)=6. Si nota che il 26% dei Risultati si trova nell’ intervallo Questo è il gruppo che contiene media e mediana. Più di meta dei risultati è contenuto in un intervallo di ± ml rispetto al valore medio..")
57
Con questi dati costruiamo un istogramma (A). Con l’ aumentare del numero delle misure l’istogramma assumerà una forma simile alla curva (B) che è una Gaussiana o curva normale dell’ errore che deriva da un insieme infinito dei dati. La Gaussiana ha la stessa media, la precisione e la stessa area Sottesa alla curva dell’ istogramma.
 che è una Gaussiana o curva normale dell’ errore che deriva da un insieme infinito dei dati. La Gaussiana ha la stessa media, la precisione e la stessa area Sottesa alla curva dell’ istogramma..")
58
Il trattamento statistico dell’errore casuale Popolazione: è l’insieme di tutte le misure di interesse Campione: sottoinsieme della popolazione selezionato per l’analisi e rappresentativo della popolazione stessa In uno studio scientifico deduciamo informazioni su una popolazione mediante le osservazioni acquisite su un sottoinsieme o campione.

59
y = 2 e -(x - µ) 2 /2 2 Curva normale di errore di una popolazione 2 curve Gaussiane che riportano la frequenza relativa y di varie deviazioni dalla media in funzione della deviazione dalla media. Queste curve vengono descritte da un equazione che contiene solo due parametri:µ = media della popolazione e = deviazione standard della popolazione La deviazione standard per la curva B è doppia rispetto a quella di A. Equazione della curva Gaussiana

60
È necessario sapere che la media e la deviazione standard sopra definite, essendo valutate sulla base di un numero finito, e normalmente molto basso, di misurazioni, cioè di un campione delle infinite misurazioni che costituiscono l’intera popolazione delle misurazioni, sono solo stime della media e della deviazione della popolazione. Per un numero molto alto di misurazioni si può scrivere: Media:Deviazione standard: Normalmente, queste due ultime equazioni valgono per N > 20. 60

61
La deviazione std. di un campione La media di un campione è la media aritmetica di un campione limitato preso da una popolazione di dati ed è indicata con x e la ds con s s = i=1 N (x i - x) 2 N-1 ( N-1)= gradi di libertà ovvero il problema inizia con N dati Indipendenti. Dopo aver calcolato la media rimangono solo N-1 dati indipendenti perché se si conoscono N-1 dati e la media è possibile calcolare l’N-esimo dato. La varianza = s 2 deviazione std. relativa = s / x Coefficiente di variazione (CV%) = ( s / x) 100
 2 N-1 ( N-1)= gradi di libertà ovvero il problema inizia con N dati Indipendenti. Dopo aver calcolato la media rimangono solo N-1 dati indipendenti perché se si conoscono N-1 dati e la media è possibile calcolare l’N-esimo dato. La varianza = s 2 deviazione std. relativa = s / x Coefficiente di variazione (CV%) = ( s / x) 100.")
62
Nel caso sia effettuato un numero di misurazioni sufficientemente elevato, è spesso possibile verificare che i valori sperimentali sono rappresentati da una distribuzione continua di tipo Gaussiano (calcolo della frequenza relativa per ogni dato sperimentale) La distribuzione Gaussiana è simmetrica intorno alla media (media e mediana coincidono) ed essendo una distribuzione di probabilità racchiude un'area unitaria. Se vale l’ipotesi che gli errori indeterminati seguano una distribuzione Gaussiana, possiamo usare le proprietà di quest’ultima per stimarne i parametri caratteristici, ovvero media e deviazione standard. 62 Distribuzione normale o di Gauss

63
Distribuzione di probabilità teorica che piu’ si avvicina alla curva di frequenza sperimentale Valori osservati Frequenza relativa Max= media σ (deviaz. standard) determina l’ampiezza della curva ai due lati della media
 determina l’ampiezza della curva ai due lati della media.")
64
Distribuzione normale o di Gauss con diversa deviazione standard Per una distribuzione gaussiana ideale il 68,3% delle misure è compresa all’ interno dell’ intervallo ± ; il 95,5% ±2 ; il 99,7% ±3 .

65
Calcolare la deviazione standard dei seguenti risultati. X 1 = 23,23; X 2 = 21,29; X 3 = 20,66; X 4 = 29,05; X 5 = 23,33;Esempi 65

66
Livello di fiducia (o di confidenza) Nelle normali operazioni di laboratorio è spesso impossibile eseguire numerose misurazioni. Tuttavia, è possibile determinare x e s ovvero la media e la deviazione standard del campione. E ’ possibile definire un intervallo in cui poter assumere ragionevolmente che in esso sia compreso il valore vero. L ’ intervallo di fiducia è un ’ espressione usata per definire la probabilit à che la media vera giaccia entro una certa distanza dalla media misurata x. 66

67
Tale intervallo si chiama intervallo di fiducia, ed i suoi limiti estremi sono chiamati limiti dell'intervallo di fiducia. La probabilità che il valore atteso di un parametro stimato sia incluso in un intervallo stimato del parametro stesso si chiama livello di fiducia, e si indica con 1- . Il livello di fiducia è espresso da un numero tra 0 e 1 (o in percento). La quantità complementare, , si chiama livello di significatività. Quindi la scelta di un determinato livello di fiducia non esclude totalmente la possibilità di fare previsioni sbagliate: se abbiamo scelto 1- = 95% avremo comunque 5 possibilità su cento che il valore vero cada al di fuori dell'intervallo di fiducia.
. La quantità complementare, , si chiama livello di significatività. Quindi la scelta di un determinato livello di fiducia non esclude totalmente la possibilità di fare previsioni sbagliate: se abbiamo scelto 1- = 95% avremo comunque 5 possibilità su cento che il valore vero cada al di fuori dell intervallo di fiducia..")
68
z è la variabile standard normalizzata; è la deviazione di un dato dalla media espressa in unità di deviazione standard. 68

69
Se noi abbiamo un risultato x proveniente da una serie di dati con una deviazione standard possiamo assumere che 90 volte su 100 la media vera si trovi nell’ intervallo x± . La probabilità è chiamata livello di fiducia (90%) e l’ intervallo di fiducia è compreso tra -1,64 e +1,64 .
 e l’ intervallo di fiducia è compreso tra -1,64 e +1,64 ..")
70
Intervalli di fiducia In analisi farmaceutica solitamente non si determina la media e d.s. di una popolazione bensì di un campione rappresentativo E’ tuttavia possibile con l’analisi statistica determinare un intervallo di fiducia attorno ad x nel quale si prevede di determinare il valore medio µ con una certa probabilità (dal 95%) L’intervallo di fiducia per una media x è quindi l’intervallo entro il quale ci si aspetta di trovare, con una certa probabilità, la media µ della popolazione (le linee di confine sono chiamati i limiti di fiducia) Trovare l’intervallo di fiducia quando è nota o quando s è una buona stima di Intervallo di fiducia = z N x
 L’intervallo di fiducia per una media x è quindi l’intervallo entro il quale ci si aspetta di trovare, con una certa probabilità, la media µ della popolazione (le linee di confine sono chiamati i limiti di fiducia) Trovare l’intervallo di fiducia quando è nota o quando s è una buona stima di Intervallo di fiducia = z N x .")
71
Il t di Student è lo strumento statistico usato per esprimere gli intervalli di fiducia e confrontare i risultati di diversi esperimenti. Es. confronto tra le medie di due popolazioni di dati.

72
Trovare l’intervallo di fiducia quando non è nota Intervallo di fiducia di = x x t st s N z

73
Esempio di calcolo degli intervalli di fiducia Si considerino i seguenti risultati relativi al contenuto di alcol etilico in un campione di sangue: 0.084%, 0.089%, 0.079%. Calcolare l’intervallo di fiducia per la media al 95% assumendo che a)dalle esperienze precedenti acquisite su un centinaio di campioni, si sa che la deviazione std. del metodo s= 0.005% è una buona stima di b)I tre risultati ottenuti rappresentano il solo modo per valutare le precisione del metodo Caso A Intervallo di fiducia (95%) = z N x 1.96 0.005 3 0.084 = = 0.084 0.006% 0.078 0.09 µ Esiste una probabilità del 95% che la media vera µ rientri nell’ intervallo 0,078-0.09 Se è nota l’ intervallo di fiducia decresce.
dalle esperienze precedenti acquisite su un centinaio di campioni, si sa che la deviazione std. del metodo s= 0.005% è una buona stima di b)I tre risultati ottenuti rappresentano il solo modo per valutare le precisione del metodo Caso A Intervallo di fiducia (95%) = z N x 1.96 = = 0.006% µ Esiste una probabilità del 95% che la media vera µ rientri nell’ intervallo 0, Se è nota l’ intervallo di fiducia decresce..")
74
Caso B Intervallo di fiducia (95%) = t st s N x 4.303 0.005 3 0.084 = = 0.084 0.012% s = 0.005% 0.072 0.096 µ
 = t st s N x = = 0.012% s = 0.005% µ")
75
Confronto di medie utilizzando la t di Student Il test t viene utilizzato per confrontare due serie di misure al fine di decidere se sono o non sono significativamente differenti tra loro Il test si basa sull’ipotesi nulla che postula che le due serie di misure siano uguali H 0 : µ = µ 0 per convenzione, si rifiuta l’ipotesi nulla quando la probabilità che la differenza tra le due serie di misure sia casuale è inferiore al 5% (p<0.05) Confronto tra le media sperimentale (risultato misurato) ed il valore noto: t calcolata = | x – valore noto | s N Se t calcolata > t tabulata (al 95%) la differenza è significativa Es: verificare se un metodo analitico nuovo fornisca risultati in accordo con il valore noto
 Confronto tra le media sperimentale (risultato misurato) ed il valore noto: t calcolata = | x – valore noto | s N Se t calcolata > t tabulata (al 95%) la differenza è significativa Es: verificare se un metodo analitico nuovo fornisca risultati in accordo con il valore noto")
76
Caso 1) Esempio di confronto di una serie di misure con un valore noto Si consideri un nuovo metodo analitico che viene applicato ad uno std. di riferimento (valore noto= 3.19%). I valori ottenuti sono i seguenti: 3.29%, 3.22%, 3.30%, 3.23% (x = 3.26; s= 0.04). Il metodo è accurato? (il risultato è in accordo con il valore noto?) t calcolata = 3.26 – 3.19 0.04 4 = 3.41 Poiché t calcolata (3.41) > t tabulata (3.182) il risultato ottenuto è differente da quello noto. La possibilità di commettere un errore nel trarre questa conclusione è minore del 5%
. I valori ottenuti sono i seguenti: 3.29%, 3.22%, 3.30%, 3.23% (x = 3.26; s= 0.04). Il metodo è accurato. (il risultato è in accordo con il valore noto ) t calcolata = 3.26 – = 3.41 Poiché t calcolata (3.41) > t tabulata (3.182) il risultato ottenuto è differente da quello noto. La possibilità di commettere un errore nel trarre questa conclusione è minore del 5%.")
77
Caso 2 Confronto di misure ripetute (test t non accoppiato) Serve a decidere se due serie di dati misurati sono uguali o differenti (stesso livello di fiducia) Si considerino una serie di dati che consistono di n 1 e n 2 misure (aventi la media x 1 e x 2 ) t calcolata = x 1 – x 2 s comune n1n2n1n2 n 1 + n 2 s comune = s 1 2 (n 1 -1)+ s 2 2 (n 2 -1) n 1 + n 2 -2 massa gas isolati aria: x 1 = 2.31011 g; s 1 = 0.000143 (n 1 =7) massa gas per via chimica: x 2 = 2.29947 g; s 2 = 0.00138 (n 1 =8) s comune = 0.00102 t calcolata = 20.2 Poiché t calcolata > t tabulata (95%, t tabulata compresa tra 2.228 e 2.131) la è significativa n.b gradi di libertà = (n 1 +n 2 ) -2
 Serve a decidere se due serie di dati misurati sono uguali o differenti (stesso livello di fiducia) Si considerino una serie di dati che consistono di n 1 e n 2 misure (aventi la media x 1 e x 2 ) t calcolata = x 1 – x 2 s comune n1n2n1n2 n 1 + n 2 s comune = s 1 2 (n 1 -1)+ s 2 2 (n 2 -1) n 1 + n 2 -2 massa gas isolati aria: x 1 = g; s 1 = (n 1 =7) massa gas per via chimica: x 2 = g; s 2 = (n 1 =8) s comune = t calcolata = 20.2 Poiché t calcolata > t tabulata (95%, t tabulata compresa tra e 2.131) la è significativa n.b gradi di libertà = (n 1 +n 2 ) -2")
78
Caso 3 Confronto di singole differenze (test t accoppiato) Questo è il caso in cui si utilizzano due metodi differenti per effettuare singole misure sugli stessi campioni (confronto tra due metodi). t calcolata = d sdsd N sdsd = i=1 N (d i - d) 2 N-1 s d = 0.122 t calcolata = 0.060 0.122 6 = 1.20 Dato che t calcolata <t tabulata (2.571 per un livello di f. al 95% e 5 gradi di libertà) i due metodi non sono significativamente diversi tra loro d è la differenza media tra le due serie di dati e n è il numero di coppie di dati
 2 N-1 s d = t calcolata = = 1.20 Dato che t calcolata <t tabulata (2.571 per un livello di f. al 95% e 5 gradi di libertà) i due metodi non sono significativamente diversi tra loro d è la differenza media tra le due serie di dati e n è il numero di coppie di dati.")
79
Il Test F per il confronto delle deviazioni std. Il test t permette di confrontare le medie e quindi di rilevare l’errore sistemico Se si vuole confrontare la precisione si devono confrontare le deviazioni std. con il test F F calcolata = s12s12 s22s22 Si pone la d.s. maggiore al numeratore in modo che F 1 Se F calcolata > F tabulata allora la è significativa

80
Il Test Q per i dati sospetti (outliers) talvolta data una serie di misure, un dato risulta non essere consistente con gli altri a causa di un errore grossolano si può usare il test Q per decidere di mantenere o scartare il dato sospetto Q calcolata = divario intervallo Intervallo: la differenza tra valori estremi Divario: la differenza fra il valore sospetto e quello più vicino Se Q calcolata >Q tabulata il dato sospetto andrebbe eliminato 12.4712.4812.5312.5612.67 Intervallo = 0.2 divario = 0.11 Qcalcolata: 0.11/0.2 = 0.55 Poiché Q calcolata <Q tabulata il dato deve essere mantenuto Esempio
 talvolta data una serie di misure, un dato risulta non essere consistente con gli altri a causa di un errore grossolano si può usare il test Q per decidere di mantenere o scartare il dato sospetto Q calcolata = divario intervallo Intervallo: la differenza tra valori estremi Divario: la differenza fra il valore sospetto e quello più vicino Se Q calcolata >Q tabulata il dato sospetto andrebbe eliminato Intervallo = 0.2 divario = 0.11 Qcalcolata: 0.11/0.2 = 0.55 Poiché Q calcolata <Q tabulata il dato deve essere mantenuto Esempio")
81
Analisi della varianza (ANOVA) L’analisi della varianza permette di confrontare più di due medie di popolazioni cioè se esiste una differenza nelle medie di più di due popolazioni. Si considerino 4 serie di dati e le 4 medie delle popolazione µ 1, µ 2, µ 3, µ 4 L’ipotesi nulla di ANOVA : H 0 : µ1= µ2 = µ3 = µ4 L’ipotesi alternativa: H A : almeno due medie tra loro Alcuni esempi di applicazione ANOVA: - vi è differenza nei risultati ottenuti da 5 analisti nella determinazione del Ca 2+ ? - quattro composizioni di solventi hanno influenza sulla reazione? - I risultati delle determinazioni di Manganese sono usando tre metodi analitici? -Ci sono differenze nella fluorescenza di uno ione complesso a 6 valori di pH Popolazioni presentano valori diversi di una caratteristica comune chiamata fattore Il fattore è la variabile indipendente la risposta è la variabile dipendente. I differenti valori del fattore di interesse vengono chiamati livelli.

82
Quando sono coinvolti più di un fattore si utilizza ANOVA a due vie (es. effetto della temperatura e pH sulla velocità di reazione) L’ analista è un fattore i diversi analisti sono i livelli del fattore. Il principio dell’ANOVA è di confrontare la variazione tra i diversi gruppi (livelli) rispetto alla variazione all’interno di ciascun gruppo (livello). Triangoli risultati individuali mentre i pallini sono le medie. Le variazioni tra le medie sono confrontate con quella all’ interno dei gruppi (Principio dell’ ANOVA). L’ipotesi nulla è vera quando le variazioni tra le medie dei gruppi è simile alla variazione all’interno dei gruppi L’ipotesi nulla è falsa quando la variazione tra le medie dei gruppi è > rispetto alle variazione tra i singoli gruppi
 L’ analista è un fattore i diversi analisti sono i livelli del fattore. Il principio dell’ANOVA è di confrontare la variazione tra i diversi gruppi (livelli) rispetto alla variazione all’interno di ciascun gruppo (livello). Triangoli risultati individuali mentre i pallini sono le medie. Le variazioni tra le medie sono confrontate con quella all’ interno dei gruppi (Principio dell’ ANOVA). L’ipotesi nulla è vera quando le variazioni tra le medie dei gruppi è simile alla variazione all’interno dei gruppi L’ipotesi nulla è falsa quando la variazione tra le medie dei gruppi è > rispetto alle variazione tra i singoli gruppi.")
83
Il test di base dell’ ANOVA è il test F. Un valore alto di F rispetto al tabulato fa scartare l’ ipotesi nulla a favore di quella alternativa. In primo luogo si deve stimare la variazione tra i gruppi e all’interno del singolo gruppo nel seguente modo 1. Si calcola il valore medio complessivo x N1N1 N x1x1 () = N2N2 N x2x2 () NiNi N xixi () + + ….. x N 1 è il numero di misure nel gruppo 1; N 2 è il numero di misure nel gruppo 2 etc. Il valore può anche essere determinato sommando tutti i dati e dividendo per N 2. La variazione tra i gruppi si determina calcolando la somma dei quadrati dovuti al fattore SQF = N 1 ( ) 2 + N 2 ( ) 2 + ……..N i ( ) 2 x 1 -x 2 - x i - xx x Quadrato della media dei livelli del fattore QMF= = SQF I -1 I = numero dei fattori
 = N2N2 N x2x2 () NiNi N xixi () + + ….. x N 1 è il numero di misure nel gruppo 1; N 2 è il numero di misure nel gruppo 2 etc. Il valore può anche essere determinato sommando tutti i dati e dividendo per N 2. La variazione tra i gruppi si determina calcolando la somma dei quadrati dovuti al fattore SQF = N 1 ( ) 2 + N 2 ( ) 2 + ……..N i ( ) 2 x 1 -x 2 - x i - xx x Quadrato della media dei livelli del fattore QMF= = SQF I -1 I = numero dei fattori.")
84
3. La variazione all’interno dei gruppi viene determinata calcolando la somma dei quadrati dell’errore SQE = (N 1 -1)s 1 2 + (N 2 -1)s 2 2 …. (N i -1)s i 2 Errore del quadrato della media EQM= = SQE N -1n F = EQM QMF L’ipotesi nulla è scartata quando F calcolato > F tabulato Dove n è il numero di livelli
s (N 2 -1)s 2 2 …. (N i -1)s i 2 Errore del quadrato della media EQM= = SQE N -1n F = EQM QMF L’ipotesi nulla è scartata quando F calcolato > F tabulato Dove n è il numero di livelli.")
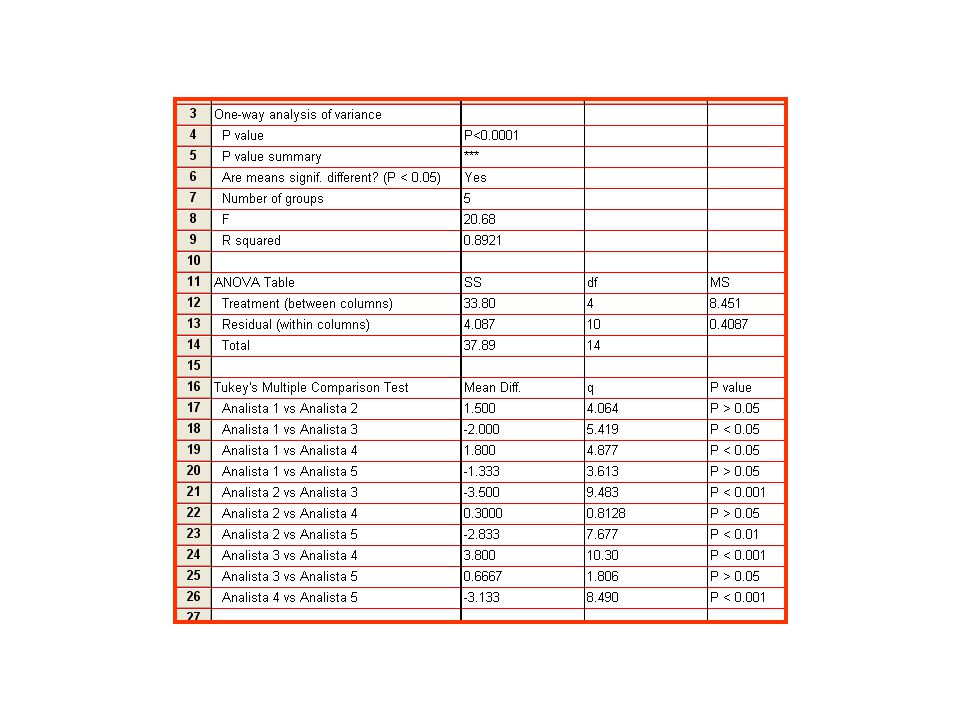
85
Applicazioni analisi ANOVA N. ProvaAnalista 1Analista 2Analista 3Analista 4Analista 5 110.39.512.19.611.6 29.88.613.08.312.5 311.48.912.48.211.4 Media10.5912.58.711.833 Dev. Std.0.8185350.458258 0.7810250.585947 Ad un livello del 95%, le medie sono diverse? x = 10.507 mmoli Ca 2+ SQF= 33.80267 (5-1= 4 gradi di libertà); QMF= 33.80267/4= 8.450667 SQE= 4.086667 (15-5= 10 gradi di libertà); EQM= 4.086667/10 = 0.408667 F calcolato = 8.450667 / 0.408667 = 20.68
; QMF= /4= SQE= (15-5= 10 gradi di libertà); EQM= /10 = F calcolato = / =")
86
Dato che F calcolato >F tabulato (livello di fiducia al 95%) Scartiamo H 0 quindi esiste un differenza significativa Tra quali gruppi esiste una differenza significativa?: Post-test
 Scartiamo H 0 quindi esiste un differenza significativa Tra quali gruppi esiste una differenza significativa : Post-test")
87
Bonferroni, Tukey: compara tutte le colonne Dunnett: compara tutte le colonne vs il controllo

89
celle Foglio di lavoro Cella attiva L’uso di fogli di calcolo in analisi chimica Le celle possono contenere testo, numeri o formule

90
In Excel le formule iniziano con il segno = Alcune funzioni statistiche preimpostate

91
Uso di $ per variabili statiche

92
Un test accoppiato : è appropriato qualora esista un naturale appaiamento tra le osservazioni dei campioni, quale il caso di una duplice verifica di un gruppo campione o prima e dopo un esperimento. È necessario che i due intervalli di input contengano lo stesso numero di dati. Un test non accoppiato: quando non esiste un appaiamento tra le due serie di misure. Le misure posso anche avere una numerosità differente Test a una o due code: Date due serie di misure le cui medie sono X 1 e X 2, si scegli il test a una coda quando l’ipotesi alternativa è x 1 > x 2 (oppure x 1 < x 2 ). Il test a una coda si utilizza quando misure precedenti, limiti fisici o il buon senso indica che se esiste una differenza questa può andare in una sola direzione. Il test a due code si utilizza quando la differenza può andare in entrambe le direzioni e quindi x1 x2
. Il test a una coda si utilizza quando misure precedenti, limiti fisici o il buon senso indica che se esiste una differenza questa può andare in una sola direzione. Il test a due code si utilizza quando la differenza può andare in entrambe le direzioni e quindi x1 x2.")
93
Categorie di errori nei dati sperimentali Errore grossolano (o occasionale) Si verifica occasionalmente, è spesso grande e provoca un significativo scostamento di un singolo dato (outlier) da tutti gli altri 18,3018,4018,5018,6018,70 x0x0 Può capitare, nel corso di una misura, di avere un valore che si discosta significativamente da tutti gli altri dati replicati (outlier) E’ necessario stabilire se il valore ottenuto deve essere utilizzato per il calcolo della media oppure se va considerato un dato anomalo e quindi scartato La scelta va fatta seguendo uno dei criteri codificati ed accettati
 Si verifica occasionalmente, è spesso grande e provoca un significativo scostamento di un singolo dato (outlier) da tutti gli altri 18,3018,4018,5018,6018,70 x0x0 Può capitare, nel corso di una misura, di avere un valore che si discosta significativamente da tutti gli altri dati replicati (outlier) E’ necessario stabilire se il valore ottenuto deve essere utilizzato per il calcolo della media oppure se va considerato un dato anomalo e quindi scartato La scelta va fatta seguendo uno dei criteri codificati ed accettati")
94
Regola del 2.5 d Si scarta il valore sospetto (outlier) e si calcola la media sui valori replicati rimanenti (x m ) Si calcola la deviazione media: d m Se il valore sospetto (outlier) differisce da x m per più di 2.5 d m il valore viene scartato e la media della misura calcolata solo sui valori rimanenenti Se il valore sospetto (outlier) differisce da x m per meno di 2.5 d m il valore viene incluso nel calcolo della media
 e si calcola la media sui valori replicati rimanenti (x m ) Si calcola la deviazione media: d m Se il valore sospetto (outlier) differisce da x m per più di 2.5 d m il valore viene scartato e la media della misura calcolata solo sui valori rimanenenti Se il valore sospetto (outlier) differisce da x m per meno di 2.5 d m il valore viene incluso nel calcolo della media")
95
Esempio Regola del 2.5 d

96
accertarsi di non aver commesso un errore grossolano; ripetere l’analisi; eseguire il test-Q; nel caso il dato sia confermato come outliers, eseguire una nuova replica; Raccomandazioni per il trattamento degli outliers. Se un dato appare anomalo: 96

97
Il metodo dei minimi quadrati La maggior parte delle determinazioni analitiche è effettuata utilizzando tecniche strumentali. Nel caso pi ù frequente, la misurazione è di tipo indiretto. Si costruisce prima un diagramma di calibrazione analizzando campioni a concentrazione nota e riportando in grafico il segnale misurato (assorbanza, corrente, tensione, area di un picco, ecc.) in funzione della concentrazione. Si può quindi utilizzare il diagramma ottenuto per ricavare il valore della concentrazione del campione incognito da quello del segnale ad esso relativo. L’equazione della retta di calibrazione è: Y = m. x + b I punti sperimentali non sono mai allineati perfettamente: è necessario usare metodi obiettivi per tracciare la retta migliore che rappresenta i risultati sperimentali 97
 in funzione della concentrazione. Si può quindi utilizzare il diagramma ottenuto per ricavare il valore della concentrazione del campione incognito da quello del segnale ad esso relativo. L’equazione della retta di calibrazione è: Y = m. x + b I punti sperimentali non sono mai allineati perfettamente: è necessario usare metodi obiettivi per tracciare la retta migliore che rappresenta i risultati sperimentali 97.")
98
Il metodo di regressione ai minimi quadrati è un metodo che permette di identificare la miglior retta che passa attraverso i punti corrispondenti ai dati sperimentali mediante minimizzazione dei quadrati delle distanze tra i punti sperimentali e la retta supposta ideale (solo deviazioni verticali). Data una serie di risultati sperimentali, (x i /y i ) = concentrazione/segnale Si può dimostrare che pendenza ed intercetta sono calcolabili per mezzo delle equazioni: I calcoli sono normalmente eseguiti per mezzo di software commerciali. 98
 = concentrazione/segnale Si può dimostrare che pendenza ed intercetta sono calcolabili per mezzo delle equazioni: I calcoli sono normalmente eseguiti per mezzo di software commerciali. 98.")
99
COEFFICIENTE DI DETERMINAZIONE R 2 Per stabilire fino a che punto l’equazione di regressione calcolata con il metodo dei minimi quadrati può essere usata al fine di prevedere un valore di y conoscendo un determinato valore di x, si calcola il parametro R 2 mediante la relazione: [Σxy - (Σx)(Σy) ] 2 n “ [Σx 2 - (Σx)2 ] [Σy 2 - (Σy)2 ] 2 nn R2=R2= R 2 può assumere valori tra 0 e 1 che indicano la “bontà” dell’equazione calcolata Es: R 2 = 0 non c’e’ alcuna relazione tra le variabili x e y R 2 = 1 perfetta relazione tra le variabili x e y, quindi ad un determinato valore di x esiste solo un valore di y
![COEFFICIENTE DI DETERMINAZIONE R 2 Per stabilire fino a che punto l’equazione di regressione calcolata con il metodo dei minimi quadrati può essere usata al fine di prevedere un valore di y conoscendo un determinato valore di x, si calcola il parametro R 2 mediante la relazione: [Σxy - (Σx)(Σy) ] 2 n [Σx 2 - (Σx)2 ] [Σy 2 - (Σy)2 ] 2 nn R2=R2= R 2 può assumere valori tra 0 e 1 che indicano la bontà dell’equazione calcolata Es: R 2 = 0 non c’e’ alcuna relazione tra le variabili x e y R 2 = 1 perfetta relazione tra le variabili x e y, quindi ad un determinato valore di x esiste solo un valore di y](http://images.slideplayer.it/16/5073915/slides/slide_99.jpg "COEFFICIENTE DI DETERMINAZIONE R 2 Per stabilire fino a che punto l’equazione di regressione calcolata con il metodo dei minimi quadrati può essere usata al fine di prevedere un valore di y conoscendo un determinato valore di x, si calcola il parametro R 2 mediante la relazione: [Σxy - (Σx)(Σy) ] 2 n [Σx 2 - (Σx)2 ] [Σy 2 - (Σy)2 ] 2 nn R2=R2= R 2 può assumere valori tra 0 e 1 che indicano la bontà dell’equazione calcolata Es: R 2 = 0 non c’e’ alcuna relazione tra le variabili x e y R 2 = 1 perfetta relazione tra le variabili x e y, quindi ad un determinato valore di x esiste solo un valore di y")
100
Accuratezza e Precisione!

101
Selettività Sensibilità Precisione Accuratezza RIASSUMENDO: ATTENDIBILITA’ DI UN DATO ANALITICO

102
Selettività: indica la capacità per un metodo analitico di riconoscere e/o quantificare una specie chimica in presenza di altre, che sono potenzialmente in grado di falsare i risultati delle analisi (interferenti). segnale concentrazione Sensibilità: è la pendenza della curva di calibrazione in uno specifico intervallo di concentrazione. Se la calibrazione è lineare, la sensibilità è il coefficiente angolare della retta di calibrazione. metodo a metodo b

103
Errori casuali: controllo della precisione La diminuzione della precisione viene segnalata dall’aumento della dispersione dei dati attorno al valore medio. La distribuzione che generalmente rappresenta il risultato della determinazione analitica è quella gaussiana (o normale). distribuzione GAUSSIANA = media 2 = varianza = dev. standard y = frequenza x = risultato
. distribuzione GAUSSIANA = media 2 = varianza = dev. standard y = frequenza x = risultato.")
104
stima della media stima della varianza stima della deviazione standard funzione di distribuzione normale deviazione standard relativa percentuale (RSD%) o coefficente di variazione percentuale (CV%)
 o coefficente di variazione percentuale (CV%)")
105
a b curva a: media = 3.0 s = 0.5 RSD% = 10% risultato = 3.0 ± 0.5 curva b: media = 3.0 s = 1.0 RSD% = 33% risultato = 3 ± 1 La precisione della stima a é superiore a quella della stima b, quindi il metodo che ha fornito il risultato a è il più preciso. Controllare: precisione contenitori e distributori di volume Stabilità apparecchi di misura Eventuali contaminazioni dei reattivi e contenitori

106
Errori sistematici: esattezza (accuratezza) Oltre agli ineludibili errori casuali, possono essere presenti errori riproducibili che determinano uno scarto tra il valore vero della quantità di analita presente ed il valore stimato espresso dalla media=perdita di accuratezza quando viene denunciato uno spostamento sistematico dei valori rispetto alla media. Errori strumentali (errata calibrazione o taratura) Errori operativi (utilizzo scorretto della strumentazione e delle apparecchiature di laboratorio) Errori metodologici (procedure di analisi non adeguate) Verifica periodica delle calibrazioni Esperienza nella pratica di laboratorio Utilizzo di materiali certificati
 Errori operativi (utilizzo scorretto della strumentazione e delle apparecchiature di laboratorio) Errori metodologici (procedure di analisi non adeguate) Verifica periodica delle calibrazioni Esperienza nella pratica di laboratorio Utilizzo di materiali certificati.")
Presentazioni simili










 GLI INTERVALLI DI CONFIDENZA>")











>")

>")



