Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
(adesso diamo i numeri…) Scuola Toscana di Formazione
Cos’è la statistica? (adesso diamo i numeri…) Scuola Toscana di Formazione
 Scuola Toscana di Formazione.")
2
La statistica: perché? Lo scopo della statistica è di rispondere a domande precise come: il farmaco A è migliore del farmaco B? La chemioterapia per un certo tumore aumenta la sopravvivenza rispetto al placebo? Esiste una correlazione tra un fattore di rischio e una determinata malattia? ecc.

3
Studio su @$&€#@ e frattura dell’anca.
Studio policentrico, in doppio cieco randomizzato e controllato vs placebo, finalizzato a valutare l’efficacia del nella prevenzione di fratture dell’anca in donne anziane con osteoporosi e/o rischio di frattura dell’anca. È stato condotto su donne. (McClung MR et al. N Engl J Med 2001;344:333-40 …Insomma il meglio che c’è

4
Conclusioni. “…il farmaco somministrato per 3 anni determina una diminuzione del rischio di frattura del 40.6%…”

5
Due calcoli banali sul lavoro originale: RRR (riduzione del rischio relativo) = 40.6% ARR (riduzione del rischio assoluto) = 1.3% NNT (reciproco dell'ARR) 1/0.013 = 77...devo trattare 77 persone per 3 anni per ridurre 1 frattura di femore Detto in altri termini, se tratto donne per 3 anni, evito 13 nuove fratture, 987 sono trattate senza alcun beneficio perchè 32 avranno una frattura comunque e 955 non avranno fratture nello stesso periodo (a prescindere dall’assunzione del farmaco!).
 = 40.6% ARR (riduzione del rischio assoluto) = 1.3% NNT (reciproco dell ARR) 1/0.013 = 77...devo trattare 77 persone per 3 anni per ridurre 1 frattura di femore Detto in altri termini, se tratto donne per 3 anni, evito 13 nuove fratture, 987 sono trattate senza alcun beneficio perchè 32 avranno una frattura comunque e 955 non avranno fratture nello stesso periodo (a prescindere dall’assunzione del farmaco!).")
6
Ops, dimenticavo: Domanda T score: – 4 oppure
Erano donne con età tra 70 e 79 anni T score: – 4 oppure T score: – 3 con altro fattore di richio Domanda E in donne osteopeniche (T score ) od osteoporotiche lievi e senza altri fattori di rischio l’NNT sarà uguale a…?
 od osteoporotiche lievi e senza altri fattori di rischio l’NNT sarà uguale a…")
7
Non lo sappiamo! Non è stato fatto alcun studio mirato al target della medicina generale. Ma continuiamo a prescrivere seguendo la chimera del 40.6% di fratture in meno.

8
Attenzione alle percentuali
Le percentuali sono usate correntemente per misurare l’efficacia di farmaci o test diagnostici. Chiunque considererebbe un test con affidabilità al 99% altamente soddisfacente. Per intenderci, il test è corretto 99 volte su 100, cioè dice “si” se si ha la malattia e “no” se non la si ha, mentre sbaglia 1 volta su 100, dicendo “si” se non si ha la malattia e “no” se la si ha.

9
Vediamo cosa succede quando si metta alla prova un tale test nel caso di una malattia che abbia una incidenza dell’1 per 1.000, su un campione di persone. 100 persone avranno la malattia (1/1000 di = 100), e di queste 99 verranno diagnosticate positive, perché il test è corretto al 99%. non avranno la malattia, e di queste 999 verranno diagnosticate positive, perché il test è scorretto all’1%.
, e di queste 99 verranno diagnosticate positive, perché il test è corretto al 99% non avranno la malattia, e di queste 999 verranno diagnosticate positive, perché il test è scorretto all’1%.")
10
In tutto, (cioè ) persone saranno diagnosticate positive, mentre soltanto 99, cioè appena l’11%, hanno la malattia. In altre parole, un paziente al quale venisse diagnosticata la malattia è quasi sicuro di non averla, nonostante il test sia molto affidabile!

11
Che cosa è successo? Non c’è trucco, non c’è inganno!
La discrepanza fra le due percentuali di affidabilità (99% e 11%) sono entrambe corrette. Ma esse significano cose diverse. Nel primo caso: si considera l’affidabilità assoluta, riguardante sia le risposte positive che negative. Nel secondo caso si considera l’affidabilità relativa, riguardante le sole risposte positive. Un’alta affidabilità assoluta non implica che ci sia anche un’alta affidabilità relativa
 sono entrambe corrette. Ma esse significano cose diverse. Nel primo caso: si considera l’affidabilità assoluta, riguardante sia le risposte positive che negative. Nel secondo caso si considera l’affidabilità relativa, riguardante le sole risposte positive. Un’alta affidabilità assoluta non implica che ci sia anche un’alta affidabilità relativa.")
12
Attenzione alle Metanalisi!

13
1° studio: 7. 000 uomini e 3. 000 donne, il farmaco è efficace su 4
1° studio: uomini e donne, il farmaco è efficace su uomini (57%) e su donne (67%) 2° studio: uomini e donne, lo stesso farmaco è efficace su uomini (33%) e su donne (36%). In entrambi i casi, il farmaco risulta essere più efficace sulle donne che sugli uomini. Ma gli stessi dati si possono interpretare anche diversamente. Metanalisi: in tutto ci sono uomini e donne, e il farmaco è efficace su uomini (46%) e su donne (43%). In questo caso, il farmaco risulta essere più efficace sugli uomini che sulle donne!
 e su donne (67%) 2° studio: uomini e donne, lo stesso farmaco è efficace su uomini (33%) e su donne (36%). In entrambi i casi, il farmaco risulta essere più efficace sulle donne che sugli uomini. Ma gli stessi dati si possono interpretare anche diversamente. Metanalisi: in tutto ci sono uomini e donne, e il farmaco è efficace su uomini (46%) e su donne (43%). In questo caso, il farmaco risulta essere più efficace sugli uomini che sulle donne!")
14
Rendere il più semplice possibile la comprensione della statistica medica
Solo conoscendola e sapendola manipolare tecnicamente possiamo evitare di divenirne vittime inconsapevoli.

15
Il concetto di rischio

16
1896: L’inizio della storia
In un colpo solo ha prodotto due effetti irreversibili: ha introdotto il modo di pensare quantitativo in medicina ha determinato l’introduzione del concetto di cura delle persone in “stato di benessere” per ridurre i loro fattori di rischio

17
Fin dall’inizio del secolo scorso le Compagnie di assicurazione sulla vita avevano osservato che “più alta è la tensione, maggiore è il RISCHIO”

18
Cambiamento epocale della medicina:
La convinzione che si possa intervenire su persone che stanno bene, sottoponendole a controlli periodici e a cure... …che però hanno la possibilità di produrre vantaggi solo in alcuni di essi.

19
RISCHIO Frequenza di nuovi casi di malattia in una popolazione suscettibile di sviluppare quella malattia in un periodo di tempo prestabilito.

20
Chiariamo bene un punto
Se un farmaco riduce il rischio di infarto dell’8%, non significa che tutti i 100 pazienti trattati abbiano una riduzione dell’evento infausto di tale percentuale, ma che la terapia risultera’ vantaggiosa in 8 pazienti mentre a 92 non apportera’ alcun beneficio. Quali siano gli 8 e quali i 92 non si sa.

21
Non potendo classificare tutto come malattia, in assenza di sintomi, si è coniato il concetto di fattori di rischio Da cui derivano i concetti di RISCHIO e di BENEFICIO

22
Beneficio, rischio, danno
Il concetto di rapporto “rischio/beneficio” è particolarmente errato perché, molto spesso, beneficio e rischio non sono della stessa natura e non si possono realmente “soppesare”.

23
Il beneficio è una “cosa” reale, che avviene sempre e comunque, mentre il rischio è una “probabilità”, la probabilità che qualcosa di nocivo possa accadere. L’asimmetria è evidente. Il beneficio dovrebbe essere allora posto a confronto con il danno e la probabilità del beneficio con la probabilità del danno.

24
Insieme di individui che hanno uno o più caratteri in comune
Che cosa si intende con il termine popolazione ? POPOLAZIONE Insieme di individui che hanno uno o più caratteri in comune Esempio: la popolazione dei soggetti affetti da ipertensione arteriosa comprende tutte le persone che hanno l’ipertensione arteriosa.

25
In uno studio statistico-epidemiologico, indipendente-mente dagli obiettivi proposti, è raramente possibile esaminare ogni singolo individuo dell’intera popolazione (necessità di enormi risorse economiche, di personale e di laboratorio, etc.) Esaminare ogni singolo individuo della popolazione CENSIMENTO L’esame di un campione invece dell’intera popolazione consente di superare questi problemi. Esaminare gli individui di un campione INDAGINE ( o inchiesta o sondaggio )
")
26
Il campionamento inferenza studio del campione campionamento campione
POPOLAZIONE campionamento campione inferenza Il principale obiettivo di un campionamento è quello di raccogliere dati che consentiranno di generalizzare all’intera popolazione i risultati ottenuti dal campione . Questo processo di generalizzazione è detto inferenza.

27
Errore di campionamento L’errore di campionamento
si verifica per VARIAZIONE CASUALE deriva da un elemento naturale ineliminabile: il CASO SELEZIONE VIZIATA fatta su un settore non rappresentativo della popolazione. Il campione si dice DISTORTO questo è un BUON CAMPIONE perché l’errore dovuto alla variazione casuale può essere STIMATO Questo è un CATTIVO CAMPIONE perché l’errore non può essere stimato!

28
bias (o distorsione o errore sistematico)
Se la moneta è bilanciata: 1000 lanci -> in circa il 50% dei casi ci aspettiamo che venga testa (o croce) Se ripetiamo l’esperimento più volte, escludendo i casi in cui si ha il 50%, in media metà delle volte la % sarà superiore e metà della volte sarà inferiore al 50%. Se la moneta fosse sbilanciata nel peso: Allora ci aspetteremmo due percentuali diverse, di entità proporzionale allo sbilanciamento.
 Se ripetiamo l’esperimento più volte, escludendo i casi in cui si ha il 50%, in media metà delle volte la % sarà superiore e metà della volte sarà inferiore al 50%. Se la moneta fosse sbilanciata nel peso: Allora ci aspetteremmo due percentuali diverse, di entità proporzionale allo sbilanciamento.")
29
bias (o distorsione o errore sistematico)
BIAS DI INFORMAZIONE distorsione nella raccolta dei dati (es. misurare la pressione con uno sfigmomanometro difettoso, confrontare rilevazioni del peso corporeo pesando o chiedendo il peso con dei questionari, etc.) BIAS DI SELEZIONE distorsione nella scelta del campione (es. usare pazienti ospedalizzati per infarto miocardico acuto come campione per valutare l’efficacia di un intervento per smettere di fumare; utilizzare come campione controllo broncopatici in uno studio caso-controllo per trovare l’associazione fra fumo e cancro del polmone, etc.)
 BIAS DI SELEZIONE. distorsione nella scelta del campione. (es. usare pazienti ospedalizzati per infarto miocardico acuto come campione per valutare l’efficacia di un intervento per smettere di fumare; utilizzare come campione controllo broncopatici in uno studio caso-controllo per trovare l’associazione fra fumo e cancro del polmone, etc.)")
30
bias (o distorsione o errore sistematico)
Stesso tiratore. Bersaglio a sx con un buon fucile. Bersaglio a dx con un fucile con il mirino disassato. Supponiamo di non conoscere la vera posizione del centro bersaglio.

31
Media aritmetica (media analitica)
La media aritmetica semplice è l’indice di tendenza centrale più utilizzato. La media si ottiene mediante la sommatoria di tutte le osservazioni (x) diviso il loro numero (N) 2, 4, 4, 5, 5, 5, 5, 7, 7, 7, 7, 7, 7, 11, 11, 11, 12 in questo caso 117/17= 6.88 0.7, 10, 20, 37.9, 400 In questo caso 468.6/5 = 93.72
 diviso il loro numero (N) 2, 4, 4, 5, 5, 5, 5, 7, 7, 7, 7, 7, 7, 11, 11, 11, 12. in questo caso 117/17= , 10, 20, 37.9, 400. In questo caso 468.6/5 =")
32
Media geometrica (media analitica)
In certi casi quando i dati sono distribuiti su diversi ordini di grandezza è bene utilizzare la media geometrica. La media geometrica è data dalla radice ennesima del prodotto delle N osservazioni. 10, 100, 1000 Media aritmetica 1.110/3 = 370 troppo spostata verso il valore più alto e quindi non dà un valore reale di centralità. Media geometrica: radice cubica di 10*100*1000 = 100

33
Moda (media di posizione)
Nel caso di misure nominali (rosso, giallo, giallo, verde, verde, verde, blu) l’unico criterio per sintetizzare la tendenza centrale consiste nell’individuare il dato che compare maggiormente e che viene definito moda. Lo stesso vale per i valori numerici. Essa individua il valore più ricorrente, o ripetitivo, di una matrice o di un intervallo di dati. Analogamente alla mediana, la moda è una misura relativa alla posizione dei valori.
 l’unico criterio per sintetizzare la tendenza centrale consiste nell’individuare il dato che compare maggiormente e che viene definito moda. Lo stesso vale per i valori numerici. Essa individua il valore più ricorrente, o ripetitivo, di una matrice o di un intervallo di dati. Analogamente alla mediana, la moda è una misura relativa alla posizione dei valori.")
34
Moda 1, 1, 1, 2, 2, 3, 3, 4, 4, 4, 5, 5, 6, 6, 6, 6, 6, 8, 10, 10, 20, 20, 30, 40, 50 Questa serie numerica è la sopravvivenza di 25 pazienti dopo la diagnosi di neoplasia polmonare espressa in mesi (1° paziente 1 mese, 2° paziente 1 mese, 3° paziente 1 mese, 4° paziente 2 mesi ecc.). Moda = 6, unica misurazione che compare 4 volte. La media aritmetica è 10 e sovrastima la sopravvivenza.
. Moda = 6, unica misurazione che compare 4 volte. La media aritmetica è 10 e sovrastima la sopravvivenza.")
35
Mediana (media di posizione)
Tale indice separa in due parti numericamente uguali le osservazioni. Nell’esempio precedente corrisponde al valore presente alla 13° posizione, cioè 6. La mediana presenta diversi svantaggi rispetto alla media: Non tiene conto esattamente della grandezza delle osservazioni e quindi sciupa delle informazioni Si presta meno facilmente ad una elaborazione matematica e perciò è meno utilizzabile per valutazioni statistiche elaborate.

36
Le medie di posizione, non risentendo dei valori estremi della serie e sono utilizzabili in presenza di valori della variabile molto diversi. Un’estensione del concetto di mediana è costituito dai percentili che hanno la prerogativa di suddividere in modo definito una serie ordinata. Esempio: i percentili dell’altezza. Il 75° significa che il 75% della popolazione è più bassa di quel valore.

37
Gli indici di dispersione
Immaginiamo di valutare l’altezza dei Milanesi e dei Cagliaritani. Prendiamo un campione rappresentativo di 200 persone a Milano e di 150 persone a Cagliari e misuriamone l’altezza.

38
Otteniamo 170 cm per Milano e 165 cm per Cagliari

39
A questo punto immaginiamo di calcolare le altezze degli abitanti di Firenze prendendo un campione di 100 Fiorentini. La media è ma la mediana è 165. La media non descrive correttamente la popolazione

40
I pochi individui che sono molto più alti degli altri rendono più elevate media e DS.
Ciò fa sembrare che la maggior parte degli individui sia più alta e la variabilità tra le stature più alta rispetto a quanto si verifica nella realtà.

41
Distribuzione Normale o Gaussiana
In questa distribuzione il 68% delle stature cade entro una deviazione standard e il 95% entro 2 deviazioni standard dalla media.

42
Ricapitolando: La deviazione standard è un indice di variabilità o dispersione del campione, più è piccola più il campione è omogeneo. L’errore standard ci informa sulla probabilità che la media vera (dell’universo statistico) sia veramente in quel range calcolato.
 sia veramente in quel range calcolato.")
43
R.C.T. (Randomised Controlled Trial )
INTERVENTO eleggibilità Randomizzazione Cecità. CONTROLLI

44
RRR= Riduzione Relativa del Rischio
ARR =Riduzione Assoluta del Rischio EER = Experimental Event Rate CER = Control Event Rate NNT = Number Needed to Treat Incidenza di EER= numero di eventi nel gruppo sperimentale/numero di soggetti del gruppo sperimentale Incidenza di CER= numero di eventi nel gruppo di controllo/numero di soggetti nel gruppo di controllo RRR= (CER - EER)/CER ARR= CER - EER NNT=1/ARR
/CER. ARR= CER - EER. NNT=1/ARR.")
45
Tre sono le possibili cause:
Nei risultati dei due bracci è impossibile che non vi sia una qualche differenza. Tre sono le possibili cause: Variabilità casuale dei fenomeni biologici Effetto dell’intervento sperimentale Errori metodologici (bias di sistema)
")
46
Con i test di significatività statistica.
Variabilità casuale dei fenomeni biologici Come valutare questa variabilità biologica o stocastica o dovuta al caso? Con i test di significatività statistica.

47
IPOTESI NULLA Si parla di ipotesi nulla per indicare l’ipotesi di base che considera che non vi siano differenze tra i due gruppi.

48
Test di significatività statistica
Valore di “ p “ Esprime la probabilità che un evento sia avvenuto per caso.

49
Test di significatività
Quando si esegue uno studio dove si paragona un trattamento A rispetto ad un trattamento B, alla fine si esegue un test statistico e si dice che il farmaco A è statisticamente più efficace di B con p<0.05. Ma, che cosa significa p<0.05?

50
Supponiamo di studiare un diuretico e prendiamo da una popolazione di 200 persone un campione di 10 persone (A) che verranno trattate con il diuretico e 10 persone (B) che faranno da controllo e trattate con placebo. Si tratta di calcolare l’incremento della diuresi dei due campioni e di calcolare se il diuretico è più efficace del placebo. Il ragionamento statistico si basa sull’ipotesi iniziale o “nulla” (H0) che i due campioni appartengono alla stessa popolazione e che ciò che si osserva dipende dal caso. Quindi l’ipotesi iniziale H0 è che la media della diuresi di A è uguale alla media della diuresi di B.
 che i due campioni appartengono alla stessa popolazione e che ciò che si osserva dipende dal caso. Quindi l’ipotesi iniziale H0 è che la media della diuresi di A è uguale alla media della diuresi di B.")
51
Se dal test t risulta che il diuretico è più efficace del placebo con p<0.05 significa che essendo i due campioni appartenenti alla stessa popolazione, l’unica differenza che li distingue è il trattamento con diuretico. P<0.05 è la probabilità di sbagliare nell’affermare che il diuretico è più efficace. In altre parole ho 5 probabilità su cento di sbagliare. Equivale ad una scommessa “a venti contro uno”. Questa probabilità, però, è solo una convenzione arbitraria entrata nell’uso, ma ha il difetto di scoraggiare il ragionamento ed a sovrastimare un risultato.

52
Test di significatività statistica
Valore di “ p “ p > 0,1 Assenza di evidenza contro l’ipotesi nulla, dati consistenti con l’ipotesi nulla. 0,05 < p < 0,1 Debole evidenza contro l’ipotesi nulla, in favore di quella alternativa. 0,01 < p < 0,05 Moderata evidenza contro l’ipotesi nulla, in favore di quella alternativa. 0,001 < p < 0,01 Forte evidenza contro l’ipotesi nulla, in favore di quella alternativa. p < 0.001 Fortissima evidenza contro l’ipotesi nulla, in favore di quella alternativa.

53
È pericoloso attribuire alla significatività statistica un’importanza clinica o una rilevanza biologica. Uno studio potrebbe dimostrare che un farmaco anti-ipertensivo è in grado di abbassare la pressione arteriosa di qualche mmHg ed essere altamente significativo, ma avrebbe scarsa importanza clinica. Piccole differenze possono essere statisticamente significative solo in considerazione dell’ampio numero del campione. Mentre effetti rilevanti dal punto di vista clinico, possono risultare statisticamente non significative per lo scarso numero del campione.

54
La significatività statistica dipende dall’entità delle differenze tra i gruppi, dalla variabilità degli esiti all’interno dei gruppi e dal numero dei pazienti. Differenze clinicamente irrilevanti possono divenire statisticamente significative se le dimensioni dei campioni sono sufficientemente grandi. Al contrario, differenze clinicamente rilevanti possono essere statisticamente non significative se i campioni sono troppo piccoli.

55
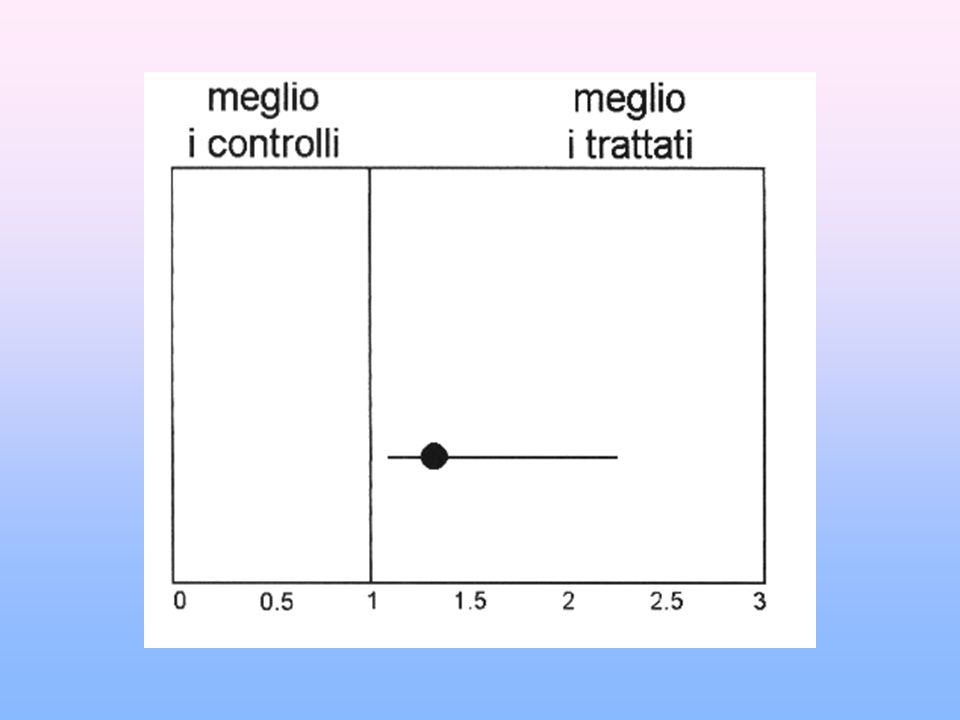
L’intervallo di confidenza
L'intervallo di confidenza fornisce informazioni riguardo alla precisione dei valori ottenuti attraverso lo studio di un campione. Ad esempio, un intervallo di confidenza 95% comprende un intervallo di valori che tiene conto della variabilità del campione, in modo tale che si può confidare - con un margine di certezza ragionevole - che quell'intervallo contenga il valore vero della popolazione, a patto che nello studio non siano presenti errori sistematici.

56
La domanda iniziale: “il farmaco A è migliore del farmaco B
La domanda iniziale: “il farmaco A è migliore del farmaco B?” andrebbe reimpostata nel modo seguente: “di quanto il farmaco A è più efficace rispetto al farmaco B?” Alla domanda occorre dare una singola stima con l’aggiunta dell’indicazione dell’accuratezza della stima che viene espressa dall’intervallo di confidenza. Cosi l’intervallo di confidenza al 95% (esempio da 2 a 12) ci indica che abbiamo il 95% di probabilità di trovare il vero valore tra 2 e 12 e solo il 5% che non lo contenga. L’intervallo di confidenza è un test di significatività a tutti gli effetti ed inoltre ci dà molte più informazioni, facilitando la distinzione tra significatività statistica e significatività clinica.
 ci indica che abbiamo il 95% di probabilità di trovare il vero valore tra 2 e 12 e solo il 5% che non lo contenga. L’intervallo di confidenza è un test di significatività a tutti gli effetti ed inoltre ci dà molte più informazioni, facilitando la distinzione tra significatività statistica e significatività clinica.")
58
Significatività statistica

59
Intervalli di confidenza (IC)
Come possono aiutarci ? Come espressione di significatività statistica Come espressione di significatività clinica

60
Efficacia di un farmaco antiipertensivo:
Differenza dei valori medi di PAS tra i due gruppi di un RCT Meglio con il trattamento Peggio con il trattamento 20 mmHg 27 mmHg 2 mmHg “Significativo statisticamente” coincide con “significativo clinicamente” ?

61
per riflettere un po’ …. RRR ARR NNT n° pazienti 10000
Trial XXX Trial YYY Trial ZZZ trattati controllo n° pazienti 10000 Eventi sfavorevoli 1000 (10 %) 2000 (20 %) 100 (1 %) 200 (2 %) 10 (0,1 %) 20 (0,2 %) RRR 50 % ARR 10 % 1 % 0,1 % NNT 10 100 1000
 (20 %) 100. (1 %) 200. (2 %) 10. (0,1 %) 20. (0,2 %) RRR. 50 % ARR. 10 % 1 % 0,1 % NNT")
Presentazioni simili

 e nel verificare se con i dati a disposizione è possibile rifiutarla o no.>")















>")

>")