Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Traduttore diretto dalla sintassi (seconda parte)
Giuseppe Morelli

2
Traduzione di linguaggi guidata da Grammatiche Context Free
La traduzione diretta della sintassi avviene associando regole e/o frammenti di codice alle produzioni di una grammatica 2 possibilità -> 2 concetti: Attributi: un attributo è una qualsiasi quantità associata ad un costrutto di programmazione (ad un simbolo della grammatica terminale o non terminale) Es. tipo di una variabile o di una espressione Schemi di traduzione: uno schema di traduzione definisce una notazione da seguire per associare ad una produzione un frammento di codice che sarà eseguito quando l’analisi sintattica userà la relativa produzione
 Es. tipo di una variabile o di una espressione. Schemi di traduzione: uno schema di traduzione definisce una notazione da seguire per associare ad una produzione un frammento di codice che sarà eseguito quando l’analisi sintattica userà la relativa produzione.")
3
Useremo Traduttori diretti della sintassi per:
La combinazione dei risultati ottenuti dall’esecuzione dei frammenti di codice nell’ordine indotto dalla analisi sintattica, è la traduzione del programma iniziale. Useremo Traduttori diretti della sintassi per: Portare una espressione dalla notazione infissa alla post fissa Valutare espressioni Costruire alberi di parsing di costrutti di programmazione

4
Notazione Post Fissa Data una espressione E la sua notazione post fissa può essere definita come: Se E è una variabile o un costante la sua notazione post fissa è E stessa Se E è una espressione del tipo E1 op E2, con op operatore binario allora la sua notazione post fissa è E’1 E’2 op dove E’1 ed E’2 sono le notazioni post-fisse di E1 ed E2 rispettivamente. Se E è una espressione del tipo (E1) allora la sua notazione post fissa è la stessa notazione di E1 La notazione post fissa non necessita di parentesi.
 allora la sua notazione post fissa è la stessa notazione di E1. La notazione post fissa non necessita di parentesi.")
5
Per la corretta interpretazione:
L’arietà di un operatore e la notazione stessa permettono di interpretare una espressione in maniera univoca. Esempi: (9-5)+2 95-2+ 9-(5+2) 952+- Per la corretta interpretazione: Guardare la stringa da sinistra fino a trovare il primo operatore: prendere un numero di operatori pari all’arietà dell’operatore, valutare l’operazione e sostituire operatore ed operandi con il risultato. Ripetere il procedimento ricercando altri operatori.
+2 (5+2) Per la corretta interpretazione: Guardare la stringa da sinistra fino a trovare il primo operatore: prendere un numero di operatori pari all’arietà dell’operatore, valutare l’operazione e sostituire operatore ed operandi con il risultato. Ripetere il procedimento ricercando altri operatori.")
6
Definizione diretta della sintassi
Una SDD (Syntax-Directed Definition) è una grammatica context free arricchita di attributi e regole semantiche. Attributi sono associati ai simboli della grammatica Le regole semantiche sono associate alle produzioni e permettono di calcolare il valore degli attributi associati ai simboli che stanno nella produzione Se X è un simbolo della grammatica ed a è un suo attributo con X.a si indicherà il valore di a in un nodo specifico dell’albero di parsing etichettato con X
 è una grammatica context free arricchita di attributi e regole semantiche. Attributi sono associati ai simboli della grammatica. Le regole semantiche sono associate alle produzioni e permettono di calcolare il valore degli attributi associati ai simboli che stanno nella produzione. Se X è un simbolo della grammatica ed a è un suo attributo con X.a si indicherà il valore di a in un nodo specifico dell’albero di parsing etichettato con X.")
7
Definizione diretta della sintassi
Tale tecnica permette di associare: Ad ogni simbolo della grammatica un insieme di attributi Ad ogni produzione, un insieme di regole semantiche per il calcolo dei valori associati ai simboli che compaiono nella produzione Gli attributi possono essere così valutati: Per una data stringa x Costruire l’albero di parse per x Applicare le regole semantiche per valutare gli attributi di ogni nodo dell’albero

8
Attributi di sintesi (sythesized attribute)
Un attributo di sintesi per un dato simbolo non terminale A associato ad un nodo N di un parse tree è definito attraverso una regola semantica associata con la produzione in N che utilizza solo i valori degli attributi di N e dei figli di N (A:head della produzione) Un albero di parse che mostra il valore degli attributi di ogni nodo si dice “annotated” parse tree
 Un albero di parse che mostra il valore degli attributi di ogni nodo si dice annotated parse tree.")
9
Esempio : notazione post Fissa
Consideriamo la grammatica “arricchita”: expr -> expr1 + term expr.t = expr1.t || term.t || ‘+’ expr -> expr1 – term expr.t = expr1.t || term.t || ‘-’ expr -> term expr.t = term.t term -> 0 term.t = ‘0’ term -> 1 term.t = ‘1’ …. term -> 9 term.t = ‘9’ Obiettivo costruire un SDD: aggiungiamo attributi e regole semantiche per trasformare una espressione in notazione post fissa Associamo ad ogni simbolo della grammatica un attributo t

10
Consideriamo la stringa e proviamo a costruire l’annotated parse tree ovvero annotiamo gli attributi e calcoliamo quelli di sintesi expr.t =95-2+ expr.t =95- Term.t=2 expr.t =9 term.t=5 term.t = 9 9 - 5 + 2

11
Definizione Aspetto chiave è l’ordine di valutazione degli attributi ovvero di applicazione delle regole semantiche (tree traversal –Dependency graphs). Una SDD, come quella dell’esempio precedente, in cui la traduzione di un simbolo non terminale della testa di una produzione è ottenuto come concatenazione delle traduzioni dei non terminali del corpo della produzione nello stesso ordine in cui essi appaiono nella stessa produzione di dice “semplice” (simple)
. Una SDD, come quella dell’esempio precedente, in cui la traduzione di un simbolo non terminale della testa di una produzione è ottenuto come concatenazione delle traduzioni dei non terminali del corpo della produzione nello stesso ordine in cui essi appaiono nella stessa produzione di dice semplice (simple)")
12
Schemi di traduzione(translation schemes)
Approccio alternativo all’SDD che non necessita di associare e manipolare stringhe alla grammatica. Permette di produrre la stessa traduzione in maniera incrementale tramite l’esecuzione di frammenti di codice (azioni semantiche) associati alle produzioni. L’ordine di valutazione (esecuzione) delle azioni semantiche è specificato esplicitamente. Una azione semantica compare tra ‘{‘’}’ e può occupare una qualunque posizione nel body di una produzione
 associati alle produzioni. L’ordine di valutazione (esecuzione) delle azioni semantiche è specificato esplicitamente. Una azione semantica compare tra ‘{‘’}’ e può occupare una qualunque posizione nel body di una produzione.")
13
Es: R -> + T { system.out.println(“+”);} R1
Quando si costruisce un albero di parse per una grammatica con schema di traduzione, per l’azione semantica viene costruito un ulteriore figlio connesso attraverso una line trateggiata al simbolo della testa della produzione che la contiene Es: R -> + T { system.out.println(“+”);} R1 R R1 + T { system.out.println(“+”);}
;} R1. R. R1. + T. { system.out.println( + );}")
14
Esempio: notazione Post fissa
Consideriamo la grammatica vista in precedenza ed associamo le azioni semantiche expr -> expr1 + term {print(‘+’)} expr -> expr1 – term {print(‘-’)} expr -> term term -> 0 {print(‘0’)} term -> 1 {print(‘1’)} …. term -> 9 {print(‘9’)}
} expr -> expr1 – term {print(‘-’)} expr -> term. term -> 0 {print(‘0’)} term -> 1 {print(‘1’)} …. term -> 9 {print(‘9’)}")
15
Albero di parse (visita post-order)
expr + expr term {print(‘+’)} 2 - {print(‘2’)} expr term {print(‘-’)} term 5 {print(‘5’)} 9 {print(‘9’)}
} 2. - {print(‘2’)} expr. term. {print(‘-’)} term. 5. {print(‘5’)} 9. {print(‘9’)}")
16
SDD ed ordine di valutazione
Una SDD non impone uno specifico ordine di valutazione degli attributi. Ogni valutazione che prevede di calcolare il valore di un generico attributo a dopo tutti quelli che dipendono da a stesso sarebbe accettabile. Per esempio gli attributi di sintesi possono essere valutati attraverso una visita bottom-up che valuta gli attributi di un dato nodo dopo aver valutato quello dei figli

17
Attributi ereditati (inherited attributes)
Un attributo ereditato per un simbolo non terminale B associato ad un nodo N di un parse tree è definito attraverso una regola semantica associata con le produzioni dei genitori di N; un attributo ereditato è definito solo in termini di valori degli dei genitori di N, di N e dei fratelli di N Un attributo di sintesi di un nodo N può essere definito anche in termini di valori di attributi ereditati di N stesso

18
Una SDD che coinvolge solo attributi di Sintesi è chiamata S-attributed.
In tali tipo di SDD ogni regola semantica calcola il valore di un attributo per un simbolo non terminale della testa di una produzione solo attraverso la combinazione di attributi che compaiono nel corpo della stessa produzione Per visualizzare la traduzione indotta da una SDD, si possono utilizzare le regole per costruire, prima, il relativo “annotated parse tree” e poi per valutare gli attributi ad ogni nodo

19
Il valore dell’attributo di un nodo può essere valutato solo dopo aver valutato il valore degli attributi da cui esso dipende Mentre in una SDD che contiene solo attributi di sintesi si può utilizzare un metodo bottom up, per SDD che contengono sia attributi di sintesi che ereditati non è garantito che si sia un solo ordine di valutazione per gli attributi

20
Esempio Consideriamo la grammatica n indica la fine della stringa
Attributo per i simboli non terminali val Attributo per i simboli terminali lexval

21
…continua Annotated parse tree per : 3 * n

22
Esempio Consideriamo adesso:
Permette di derivare stringhe del tipo 4*8 4*9*2 Costruiamo l’albero di parse per la stringa 3 * 5

23
3 * 5

24
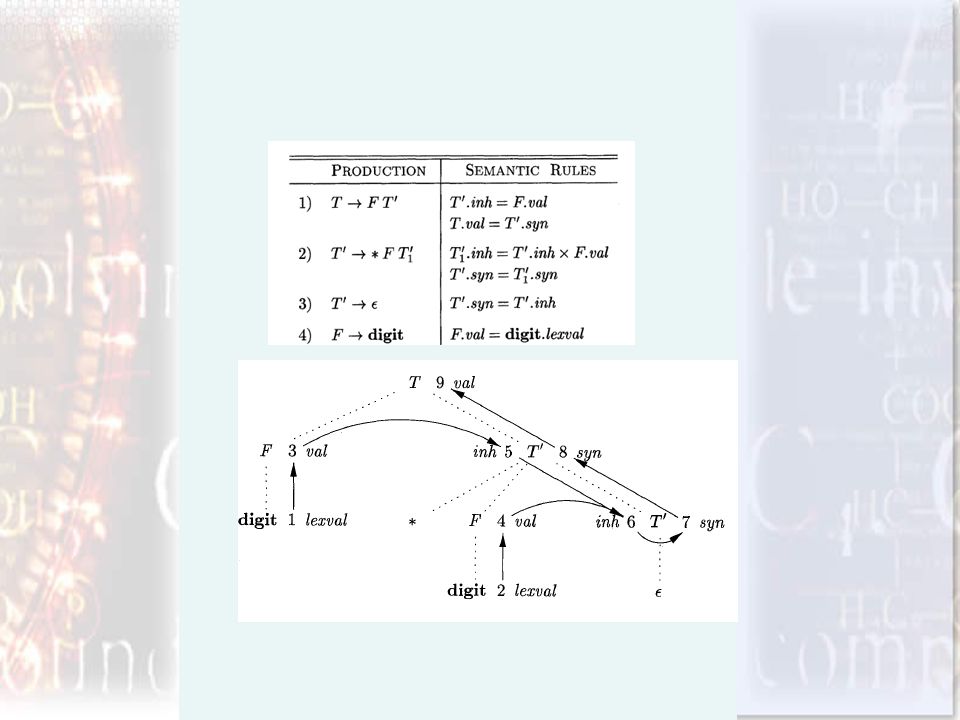
Cerchiamo di costruire un SDD per valutare la stringhe che la grammatica è in grado di derivare.
Notiamo subito che gli attributi di sintesi non sono sufficienti Le regole semantiche che dobbiamo costruire devono prevedere attributi ereditati Associamo ai simboli non terminali T ed F l’attributo di sintesi val Associamo ai simboli terminali l’attributo lexval Associamo al simbolo non terminale T’ l’attributo di sintest syn e quello ereditato inh

25
L’idea è quella che la radice dell’albero per T’ eredita l’attributo di F

26
3 * 5 Tutti i fattori vengono accumulati ed alla fine il risultato viene restituito e risale l’abero attraverso attributi di sintesi

27
Grafo delle dipendenze
Permette di determinare l’ordine con cui si devono calcolare i valori degli attributi di una SDD. Si costruisce: Dato un nodo N dell’albero di parse relativo ad un simbolo X della grammatica, il grafo avrà un nodo per ogni attributo di X. Supposto che una regola semantica associata ad una produzione p definisca il valore per l’attributo di sintesi A.b utilizzando l’attributo X.c allora il grafo ha un arco che va da X.c ad A.b. Supposto che una regola semantica associata ad una produzione p definisca il valore per l’attributo ereditato B.c utilizzando l’attributo X.a allora il grafo ha un arco che va da X.a ad B.c.

28
Il grafo così fatto caratterizza i possibili ordini di valutazione.
L’ordine di valutazione è determinato dalla sequenza di nodi N1,N2, …Nk tale che se esiste un arco da Ni a Nj allora Ni<Nj (ordinamento topologico). Se il grafo presenta un ciclo non sarà possibile ordinarlo topologicamente e pertanto non c’è modo di valutare l’SDD su quell’albero
. Se il grafo presenta un ciclo non sarà possibile ordinarlo topologicamente e pertanto non c’è modo di valutare l’SDD su quell’albero.")
30
Parsing Procedimento che permette di determinare come una stringa di terminali può essere generata da una grammatica Possiamo distinguere due grandi classi di parser: Top Down:la costruzione dell’albero di parse inizia dalla root per poi proseguire verso le foglie Bottom Up:la costruzione dell’albero di parse avviene in senso in verso si inizia dalle foglie per proseguire verso la radice

31
Parser Top Down La costruzione di un albero di parse con la tecnica Top-Down avviene iniziando dalla root che viene etichettata con il simboli iniziale della grammatica e ripetendo i due passi seguenti: Dato un nodo N dell’albero di parse relativo ad un simbolo non terminale A scegliere una produzione per A e costruire i figli di N per tutti i simboli presenti nel corpo della produzione Trovare il nodo successivo cui costruire il sotto albero (tipicamente il sottoalbero più a sinistra etichettato con un non terminale e non ancora espanso)
")
32
Ad ogni passo del procedimento è problema chiave determinare la produzione che deve essere applicata per un non terminale (A) Una volta che la produzione (A produzione) è stata individuata il resto del processo di parsing consiste nell’individuare il corrispondente simbolo terminale nel corpo della produzione della stringa di input. Il simbolo terminale corrente della stringa da riconoscere e che deve essere individuato nella produzione è detto simbolo di lookahead.
 è stata individuata il resto del processo di parsing consiste nell’individuare il corrispondente simbolo terminale nel corpo della produzione della stringa di input. Il simbolo terminale corrente della stringa da riconoscere e che deve essere individuato nella produzione è detto simbolo di lookahead.")
33
Esempio Si consideri la grammatica

34
for(; expr; expr) other
 other")
35
Parser a discesa ricorsiva:parser predittivo
Un insieme di procedure ricorsive è utilizzato per l’elaborazione dell’input: in particolare ad ogni simbolo non terminale viene associata una procedura. Nei parser predittivi il simbolo di lookahead determina in maniera non ambigua il flusso di controllo attraverso le procedure dei non terminali. La sequenza della chiamate a procedure durante l’analisi di una stringa di input definisce implicitamente un albero di parse per essa

36
Considerando la grammatica:
Dovremmo definire delle procedure per i simboli stmt e optexpr In più si definirà una funzione match(t) per riconoscere il carattere di lookahead e cambiarlo per il successivo riconoscimento
 per riconoscere il carattere di lookahead e cambiarlo per il successivo riconoscimento.")
38
Considerando l’input for(; expr; expr) other
Il parsing inizia con la chiamata della procedura associata al simbolo iniziale e con for carattere di lookahead Viene quindi considerata la produzione Ogni terminale è quindi accoppiato con il simbolo di lookahead e per ogni terminale viene chiamata la relativa procedura

39
Alcune considerazioni
Nel caso in cui nella grammatica esistono due produzioni con la stessa “testa”, il parser deve applicare quella in cui controllando il primo simbolo che il corpo della produzione è in grado di generare ed il carattere di lookahead Esiste un metodo formale: Sia α una stringa della grammatica(terminali/non terminali). Si definisce FIRST(α) l’insieme di simboli terminali che sono nella prima posizione (primo simbolo) di una o più stringhe di terminali generate da α
. Si definisce FIRST(α) l’insieme di simboli terminali che sono nella prima posizione (primo simbolo) di una o più stringhe di terminali generate da α.")
40
FIRST(stmt) = {expr, if, for , other}
FIRST(optexpr) = {expr} Gli insiemi FIRST(α) e FIRST (β) sono utilizzati in presenza di due produzioni A -> α e A1 -> β; Viene scelta a A -> α se lookahed Є FIRST(A); A -> β se lookahed Є FIRST(A1)
 = {expr} Gli insiemi FIRST(α) e FIRST (β) sono utilizzati in presenza di due produzioni A -> α e A1 -> β; Viene scelta a A -> α se lookahed Є FIRST(A); A -> β se lookahed Є FIRST(A1)")
41
Calcolo di FIRST… per X Sia X un simbolo della grammatica:
Se X è un simbolo terminale allora FIRST(X) = {X} Se X è un non terminale ed X->Y1 Y2 …. Yk (k>=1) è una produzione aggiungere a ad FIRST(X) se per un qualche indice i a Є FIRST(Yi) ε appartiene a FIRST(Y1),…,FIRST(Yi-1); se ε Є FIRST(Yj) J=1,..,k --- aggiungere ε a FIRST(X) Se esiste X -> ε aggiungere ε a FIRST(X)
 = {X} Se X è un non terminale ed X->Y1 Y2 …. Yk (k>=1) è una produzione aggiungere a ad FIRST(X) se per un qualche indice i. a Є FIRST(Yi) ε appartiene a FIRST(Y1),…,FIRST(Yi-1); se ε Є FIRST(Yj) J=1,..,k --- aggiungere ε a FIRST(X) Se esiste X -> ε aggiungere ε a FIRST(X)")
42
Esempio Consideriamo la grammatica .

43
Generalizzando Un parser predittivo è di fatto un programma consistente in procedure associate ai simboli non terminali. Tali procedure sostanzialmente fanno 2 cose Decidono quale produzione applicare esaminando il simbolo di lookahed. Una A-produzione con corpo α viene applicata se tale simbolo appartiene a FIRST(α) (gli insiemi FIRST devono essere disgiunti). Una ε pruduzione per un A viene applicara se il simbolo di lookahed non appartiene a nessun insieme FIRST delle produzioni per A.
 (gli insiemi FIRST devono essere disgiunti). Una ε pruduzione per un A viene applicara se il simbolo di lookahed non appartiene a nessun insieme FIRST delle produzioni per A.")
44
Scelta la produzione, i simboli del corpo sono “eseguiti” in ordine da sinistra a destra
Un simbolo non terminale viene eseguito chiamando la relativa procedura Un simbolo terminale coincidente con il simbolo di lookahead viene eseguito leggendo il simbolo successivo Se in un dato istante un simbolo terminale non coincide con il simbolo di lookahead deve essere generato un errore sintattico

45
Costruzione tabella di parsing

46
Ricorsione sinistra Una grammatica si dice ricorsiva sinistra se essa contiene un simbolo non terminale A dal quale è possibile derivare Aα per qualche stringa α. Caso più semplice: nella grammatica esiste una produzione del tipo A -> Aα (ricorsione sinistra immediata) A α può essere derivato anche attraverso produzione intermedie (A -> B , B -> Aα) La ricorsione a sinistra nei parser a discesa ricorsiva provoca loop infiniti. La ricorsione sinistra immediata può essere risolta eliminando e riscrivendo opportunamente la produzione interessata
 A α può essere derivato anche attraverso produzione intermedie (A -> B , B -> Aα) La ricorsione a sinistra nei parser a discesa ricorsiva provoca loop infiniti. La ricorsione sinistra immediata può essere risolta eliminando e riscrivendo opportunamente la produzione interessata.")
47
A -> Aα | β Notiamo subito la produzione ricorsiva a sinistra La grammatica scritta è in grado di generare stringhe del tipo: β α* Lo stesso risultato può essere ottenuto con la grammatica: A -> βR R -> αR | ε La grammatica ottenuta è ricorsiva a destra. Ciò complica il processo di traduzione e valutazione di espressioni associative a sinistra

48
Algoritmo generale per eliminare la ricorsione su grammatiche senza cicli ed ε produzioni
Es. pag abbozzare processo di eliminazione

49
Consideriamo

Presentazioni simili





>")



>")
 dove: L indica il verso dellanalisi della stringa.>")






>")

 Gabriella Pasi e Carla Simone>")
