Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Il campionamento

2
Il campionamento Vantaggi (per es. rispetto a un censimento):
Riduzione dei costi Riduzione dei tempi Maggiore accuratezza e approfondimento Rischi: Errori di copertura (es. la lista di campionamento) Errori di non risposta (rifiuti, mancati contatti, missing o altro) Errore di campionamento (il campione non riflette adeguatamente la popolazione target, es. autoselezione) Dimensione campionaria inadeguata (ampiezza)
 Errori di non risposta (rifiuti, mancati contatti, missing o altro) Errore di campionamento (il campione non riflette adeguatamente la popolazione target, es. autoselezione) Dimensione campionaria inadeguata (ampiezza)")
3
…qualche definizione L’universo= la popolazione “teorica” oggetto di indagine La popolazione = l’insieme dei soggetti sui quali viene effettivamente svolta la ricerca sulla base di una lista di campionamento Unità di analisi= il singolo caso rilevante per la ricerca, i soggetti dentro la lista di campionamento della popolazione Il campione = il sottoinsieme della popolazione cui vengono applicati gli strumenti d’indagine I casi= le unità di analisi scelte che finiscono nel campione Il campionamento = il procedimento di selezione (nelle intenzioni, rappresentativa) dei casi dalla popolazione al campione
 dei casi dalla popolazione al campione.")
4
(procedimento induttivo) (procedimento deduttivo)
Universo: i lavoratori atipici della provincia di Genova Popolazione di riferimento: i lavoratori atipici rilevabili nelle liste dei CPI 13 23 17 Stima (procedimento induttivo) 4 11 campione 22 3 18 15 1 1 16 7 25 CAMPIONAMENTO 11 14 12 16 21 7 2 5 10 9 91 20 Inferenza (procedimento deduttivo) 19 24 25 20 6 8 casi Unità di analisi
 campione CAMPIONAMENTO Inferenza. (procedimento deduttivo) casi. Unità di analisi.")
5
La rappresentatività (I)
Occorre che il campione possegga le caratteristiche della popolazione di origine e le riproduca in piccola scala. 2 fattori: Numerosità: quante unità di analisi finiscono nel campione, tanto più cresce n avvicinandosi a N, tanto più il campione è rappresentativo Eterogeneità: quanto le unità di analisi sono diverse tra loro all’origine, tanto più il campione rispecchia l’eterogeneità, tanto più è rappresentativo

6
La rappresentatività (II)
Alcuni criteri per un’adeguata rappresentatività: occorre che i dati di partenza siano generalmente validi non si devono verificare effetti di selezione campione e popolazione devono avere distribuzioni simili si rifletta la presenza di possibili caso idealtipici adeguata copertura della popolazione (riflettere le variazioni) usare un campione probabilistico (p>0 e noto)
 usare un campione probabilistico (p>0 e noto)")
7
Il campionamento La selezione delle unità di analisi che divengono casi del campione può avvenire con 2 metodi Probabilistico: le unità della popolazione hanno prefissate, medesime e conoscibili probabilità di essere incluse nel campione Non probabilistico: non si conoscono le probabilità di inclusione

8
La numerosità …dove n = la numerosità che si vuole ottenere z = costante (corrispondente al valore della variabile casuale normale standardizzata) che dipende dal livello di fiducia desiderato per la stima es. 1,96 per un livello di fiducia del 95%; 1 per il 68% = lo scarto quadratico medio (l’indice di variabilità) e= l’errore atteso
 che dipende dal livello di fiducia desiderato per la stima es. 1,96 per un livello di fiducia del 95%; 1 per il 68% = lo scarto quadratico medio (l’indice di variabilità) e= l’errore atteso")
9
Esempio errore di stima dalla media= 0,2
livello di fiducia del 95% =1,96 variabilità = 3 n= 1,96 * (3/0,2) = 29,4 che elevato al quadrato= 864,36 non è sensato fare elaborazioni sotto 30 casi per un minimo di descrizione meglio ancora non andare sotto i 100 per una popolazione estesa spesso oltre 1000 casi non si aggiunge rappresentatività (per variabili poco eterogenee)
 = 29,4. che elevato al quadrato= 864,36. non è sensato fare elaborazioni sotto 30 casi per un minimo di descrizione. meglio ancora non andare sotto i 100 per una popolazione estesa. spesso oltre 1000 casi non si aggiunge rappresentatività (per variabili poco eterogenee)")
10
La ponderazione es. da una popolazione di 500 M e 1000 F… …un campione stratificato x età di 100 M e 100 F …farà sì che le risposte delle 100 F valgano doppio

11
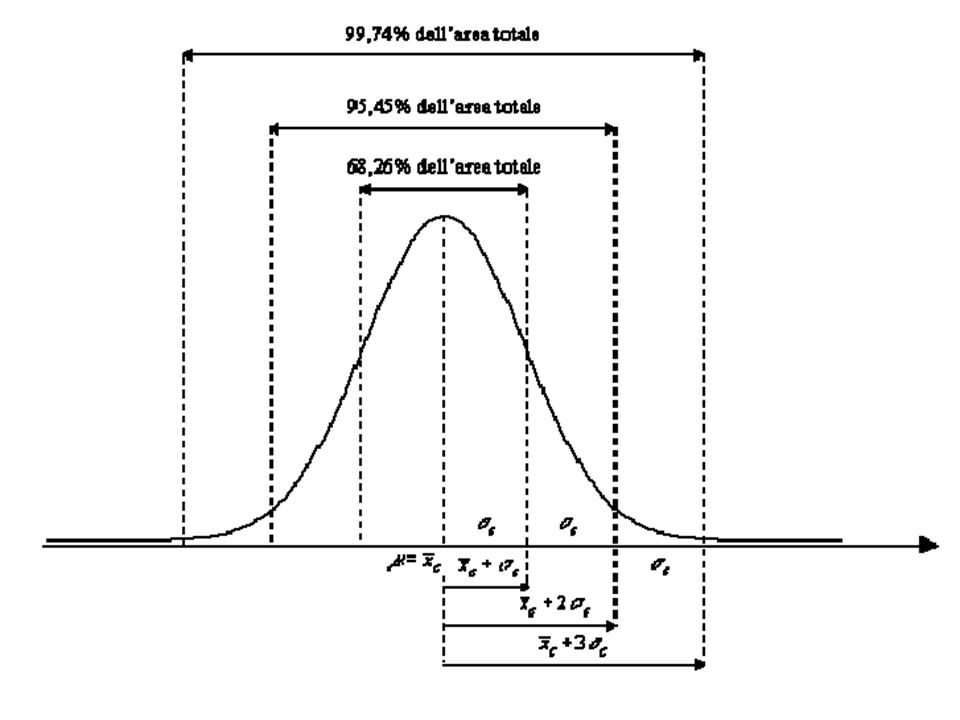
N La curva normale M, Mo, Me -1Sq e +1 Sq = 68% dei casi
-3Sq Sq Sq +1Sq Sq Sq

13
Campionamenti probabilistici (tipici della ricerca standard)
Casuale semplice (con o senza ripetizione) Sistematico Stratificato (proporzionale/non proporzionale) A grappoli A stadi Areale
 Sistematico. Stratificato (proporzionale/non proporzionale) A grappoli. A stadi. Areale.")
14
Probabilistici: Casuale semplice
Estraggo a caso dalla lista di campionamento garantendo a tutte le unità di analisi la stessa possibilità di entrare a far parte del campione Con o senza ripetizione, ovvero estraggo e tolgo o estraggo e rimetto (raro)
")
15
Probabilistici: sistematico
Estraggo a caso ogni tot dalla lista, ovvero definisco un passo di campionamento, cioè estraggo un caso ogni k, dove k=n/N (*100) Es. per n=1000 e N=50000, k=50 Se N non è noto posso usare un k arbitrario Definito k estraggo a caso un numero tra 1 e k (nel nostro caso 1tra 1 e 50) e inizio il passo di campionamento (ne prendo 1 ogni 50 a partire dal numero estratto) …proseguo a estrarre con il passo fino a raggiungere la numerosità Si può fare anche quando non c’è una lista
 Es. per n=1000 e N=50000, k=50. Se N non è noto posso usare un k arbitrario. Definito k estraggo a caso un numero tra 1 e k (nel nostro caso 1tra 1 e 50) e inizio il passo di campionamento (ne prendo 1 ogni 50 a partire dal numero estratto) …proseguo a estrarre con il passo fino a raggiungere la numerosità. Si può fare anche quando non c’è una lista.")
16
Probabilistici: Stratificato
Definisco strati su popolazione rispetto a variabili fondamentali Rispetto alle unità di analisi gli strati devono essere omogenei al loro interno (intra) e eterogenei tra loro (inter) Posso seguire un criterio di ripartizione proporzionale o non proporzionale all’incidenza degli strati rispetto alla popolazione di origine Piano fattoriale ovvero definisco a priori delle variabili che ritengo influenzino il fenomeno. Es. genere (2 modalità, M/F), età (2 modalità, under 40/over 40) ; titolo di studio (3 modalità, basso,medio,alto). Si ottengono 2X2X3=12 combinazioni e in ognuna dovrò selezionare lo stesso numero di casi (in questo modo posso valutare meglio l’influenza delle variabili equiparandone il peso)
 e eterogenei tra loro (inter) Posso seguire un criterio di ripartizione proporzionale o non proporzionale all’incidenza degli strati rispetto alla popolazione di origine. Piano fattoriale ovvero definisco a priori delle variabili che ritengo influenzino il fenomeno. Es. genere (2 modalità, M/F), età (2 modalità, under 40/over 40) ; titolo di studio (3 modalità, basso,medio,alto). Si ottengono 2X2X3=12 combinazioni e in ognuna dovrò selezionare lo stesso numero di casi (in questo modo posso valutare meglio l’influenza delle variabili equiparandone il peso)")
17
Probabilistici: a grappoli
Suddivido popolazione in sottoinsiemi (grappoli) es. divido una popolazione di scuole per regioni/province/comuni Scelta casuale sui grappoli es. seleziono casualmente Rilevo su tutte le unità dei grappoli scelti Es. scelti a caso 1 e 3, rilevo su tutte le unità di 1 e 3 4 3 1 2
 es. divido una popolazione di scuole per regioni/province/comuni. Scelta casuale sui grappoli es. seleziono casualmente. Rilevo su tutte le unità dei grappoli scelti. Es. scelti a caso 1 e 3, rilevo su tutte le unità di 1 e")
18
Probabilistici: a stadi (2 o +)
Suddivido popolazione in sottoinsiemi (unità di primo stadio)…es. regioni Scelta casuale dei sottoinsiemi su unità di primo stadio Scelta casuale delle unità selezionate in primo stadio (secondo stadio) Es. su 3 stadi per studenti scuole medie italiane: I stadio - scelta casuale tra comuni d’Italia II stadio - scelta casuale tra scuole medie dei comuni scelti III stadio - scelta casuale tra gli studenti delle scuole scelte dei comuni scelti
…es. regioni. Scelta casuale dei sottoinsiemi su unità di primo stadio. Scelta casuale delle unità selezionate in primo stadio (secondo stadio) Es. su 3 stadi per studenti scuole medie italiane: I stadio - scelta casuale tra comuni d’Italia. II stadio - scelta casuale tra scuole medie dei comuni scelti. III stadio - scelta casuale tra gli studenti delle scuole scelte dei comuni scelti.")
19
Probabilistici …naturalmente, niente e nessuno mi impedisce di poter combinare le tecniche anzidette…es un campionamento areale stratificato con passo sistematico

20
Guida alla definizione di un campione
Definire la popolazione in spazio e tempo Elencare criteri inclusione/esclusione rispondenti Specificare unità di analisi Costruire lista campionamento Identificare variabili chiave e loro eterogeneità Valutare errore Stabilire numerosità campionaria Definire criterio campionamento

21
Campionamenti non probabilistici (tipici della ricerca non standard)
A casaccio Per quote Auto-selezionato Testimoni privilegiati A valanga

22
Non probabilistici: a casaccio
è il cosiddetto campionamento accidentale Es. : mi metto all’angolo di una strada e scelgo il primo caso che capita, senza criteri definiti, ma solo in ragione di praticità e velocità

23
Non probabilistici: per quote
È come uno ovvero definisco delle quote di popolazione in base alle variabili che mi interessano Es: in genere non è proporzionale, ma può riflettere le caratteristiche della popolazione Diplomati Laureati Maschi 50 Femmine

24
Non probabilistici:autoselezionato
…Laddove i casi si selezionano da soli rispondendo alla somministrazione… Esempi: il televoto alcune survey online alcuni questionari di gradimento

25
Non probabilistici:Testimoni privilegiati
Campione di esperti Campione sociologico Si basa essenzialmente sulle caratteristiche predefinite degli individui Tipico dei Delphi o dei Focus group

26
Non probabilistici: a valanga
Scelgo alcuni casi di partenza (possibilmente “idealtipici” o testimoni privilegiati) Chiedo loro di fornirmi altri conoscenti da intervistare con tali caratteristiche Più fasi possibili Rischi di condizionamento sulla base del capitale relazionale delle persone
 Chiedo loro di fornirmi altri conoscenti da intervistare con tali caratteristiche. Più fasi possibili. Rischi di condizionamento sulla base del capitale relazionale delle persone.")
Presentazioni simili
 e nel verificare se con i dati a disposizione è possibile rifiutarla o no.>")






 IUT Nice – Côte dAzur Département STID.>")











