Scaricare la presentazione
1
Code con priorità Ordinamento
Lezione 9 Code con priorità Ordinamento

2
Sommario Code con priorità Ordinamento Selection Sort Bubble Sort
Heap Sort Quick Sort

3
Coda con priorità Una coda con priorità è una struttura dati dinamica che permette di gestire una collezione di dati con chiave numerica. Una coda con priorità offre le operazioni di inserimento: di un elemento nell’insieme massimo: restituisce l’elemento con chiave più grande cancellazione-massimo: restituisce l’elemento con chiave più grande e lo rimuove dalla collezione

4
Applicazioni della Coda con Priorità
Le Code con priorità sono strutture dati molto comuni in informatica. Es: Gestione di processi: ad ogni processo viene associata una priorità. Una coda con priorità permette di conoscere in ogni istante il processo con priorità maggiore. In qualsiasi momento i processi possono essere eliminati dalla coda o nuovi processi con priorità arbitraria possono essere inseriti nella coda. Per implementare una coda con priorità utilizzeremo una struttura dati chiamata heap

5
Nota su gli alberi binari
Intuitivamente (vedremo meglio successivamente) un albero binario è una struttura dati formata da nodi collegati fra di loro (come per la struttura dati lista) come per una lista, per ogni nodo esiste un unico nodo predecessore a differenza di una lista, ogni nodo è collegato con uno o due nodi successori
 un albero binario è una struttura dati formata da nodi collegati fra di loro (come per la struttura dati lista) come per una lista, per ogni nodo esiste un unico nodo predecessore. a differenza di una lista, ogni nodo è collegato con uno o due nodi successori.")
6
Heap La struttura dati heap binario è un albero binario quasi completo
un albero binario quasi completo è un albero binario riempito completamente su tutti i livelli tranne eventualmente l’ultimo che è riempito da sinistra a destra

7
Heap Perché un albero binario quasi completo sia uno heap deve valere la seguente: Proprietà dell’ordinamento parziale dello heap il valore di un nodo figlio (successore) è minore o uguale a quello del nodo padre (predecessore)
 è minore o uguale a quello del nodo padre (predecessore)")
8
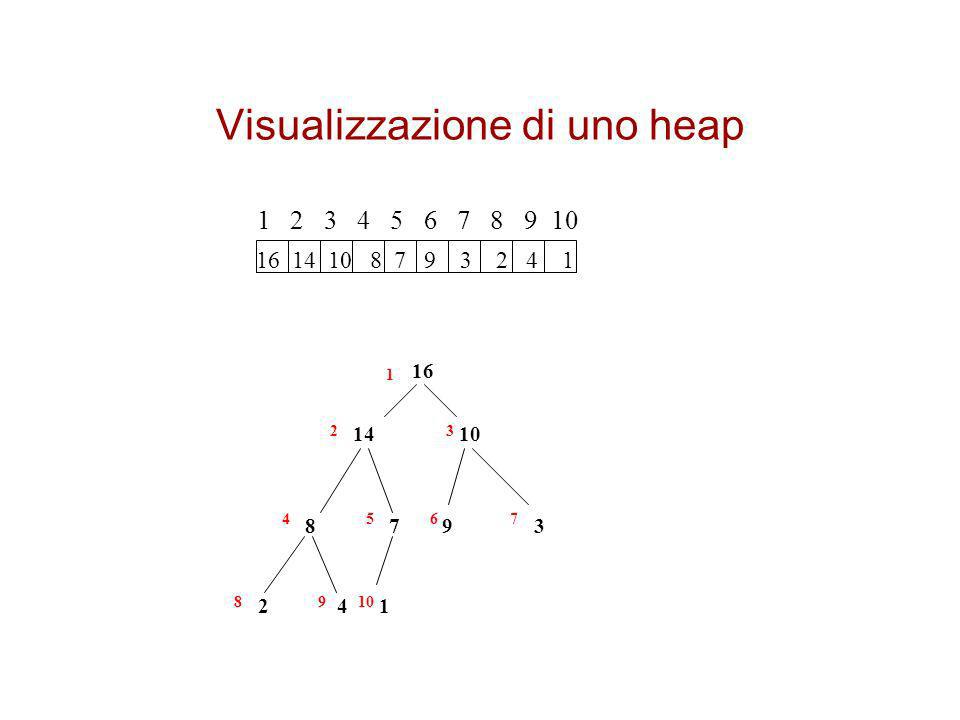
Heap Si implementa l’albero tramite un vettore
Uno heap A ha un attributo heap-size[A] che specifica il numero di elementi contenuto nello heap nessun elemento in A[1,length[A]] dopo heap-size[A] è un elemento valido dello heap La radice dell’albero è A[1] L’indice del padre di un nodo di posizione i è i/2 L’indice del figlio sinistro di un nodo i è 2 i L’indice del figlio destro di un nodo i è 2 i +1

9
Visualizzazione di uno heap
16 14 10 8 7 2 4 1 9 3 1 2 3 4 5 6 7 8 9 10
10
Pseudocodice Operazioni Heap
Parent(i) 1 return i/2 Left(i) 1 return 2 i Right(i) 1 return 2 i + 1
 1 return i/2 Left(i) 1 return 2 i. Right(i) 1 return 2 i + 1.")
11
Mantenimento proprietà heap
A seguito di varie operazioni sullo heap può accadere che un nodo violi la proprietà dello heap La procedura Heapify prende in ingresso uno heap A e l’indice i di un nodo che potenzialmente viola la proprietà e ristabilisce la proprietà di ordinamento parziale sull’intero heap si assume che i sottoalberi figli del nodo i siano radici di heap che rispettano la proprietà di ordinamento parziale

12
Spiegazione L’idea è di far “affondare” il nodo che viola la proprietà di ordinamento parziale fino a che la proprietà non viene ripristinata per fare questo si determina il nodo figlio più grande e si scambia il valore della chiave fra padre e figlio si itera ricorsivamente il procedimento sul nodo figlio sostituito

13
Pseudocodice Heapify Heapify(A,i) 1 l Left(i) 2 r Right(i)
3 if l heap-size[A] e A[l]>A[i] 4 then largest l 5 else largest i 6 if r heap-size[A] e A[r]>A[largest] 7 then largest r 8 if largest i 9 then scambia A[i] A[largest] 10 Heapify(A,largest)
")
14
Visualizzazione Heapify
16 16 i 4 10 14 10 14 7 9 3 i 4 7 9 3 2 8 1 2 8 1 16 14 10 8 7 9 3 2 4 1

15
Nota sugli alberi binari
Un albero binario completo di altezza h ha 2h+1-1 nodi infatti intuitivamente: un albero binario completo di altezza 0 ha un unico nodo: la radice un albero binario completo di altezza 1 è composto dalla radice e dai suoi due figli all’aumentare di un livello ogni figlio genera altri due figli e quindi si raddoppia il numero di nodi del livello precedente Ogni livello di un albero binario completo contiene tanti nodi quanti sono contenuti in tutti i livelli precedenti +1 infatti passando da h a h+1 si passa da 2h+1-1 a 2h+2-1 nodi ovvero a 2(2h+1) -1 nodi quindi il nuovo livello ha aggiunto 2h+1 nodi ad un albero che prima ne conteneva 2h+1-1
 -1 nodi quindi il nuovo livello ha aggiunto 2h+1 nodi ad un albero che prima ne conteneva 2h+1-1.")
16
Tempo di calcolo di Heapify
Le istruzioni per determinare il maggiore fra i, l e r impiegano un tempo (1) Ricorsivamente si chiama Heapify su uno dei sottoalberi radicati in l o r Il sottoalbero dei figli hanno al più dimensione 2n/3 il caso peggiore è quando l’ultimo livello è pieno per metà ovvero uno dei sottoalberi è completo Il tempo di esecuzione è pertanto: T(n)=T(2n/3)+ (1) per il Teorema Principale si ha T(n)= (lg n)
 Ricorsivamente si chiama Heapify su uno dei sottoalberi radicati in l o r. Il sottoalbero dei figli hanno al più dimensione 2n/3. il caso peggiore è quando l’ultimo livello è pieno per metà ovvero uno dei sottoalberi è completo. Il tempo di esecuzione è pertanto: T(n)=T(2n/3)+ (1) per il Teorema Principale si ha T(n)= (lg n)")
17
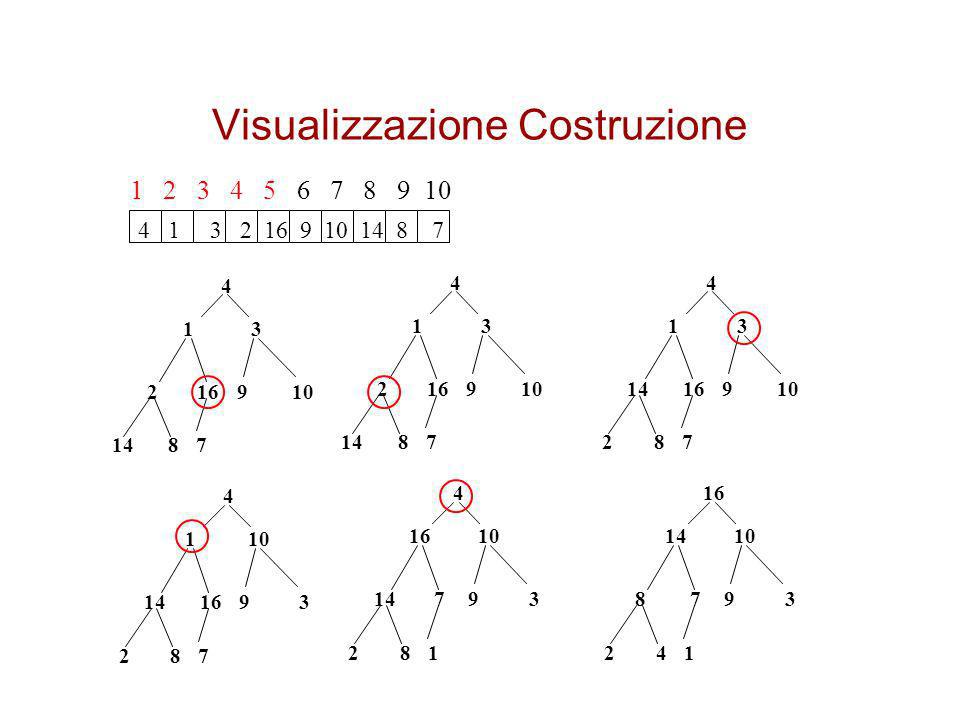
Costruzione di uno heap
Si può usare la procedura Heapify in modo bottom-up, cioè a partire dai livelli più bassi dell’albero, per convertire un Array in uno Heap Gli elementi A[ n/2 n] sono tutte foglie dell’albero e pertanto ognuno di essi è già uno heap di 1 elemento Si inizia dagli elementi padri dei nodi A[ n/2 n] Dato che procediamo in modo bottom-up allora sicuramente i sottoalberi di un nodo sottoposto a Heapify sono heap

18
Pseudocodice Costruzione Heap
Build-Heap(A) 1 heap-size[A] Length[A] 2 for i length[A]/2 downto 1 3 do Heapify(A,i)
 1 heap-size[A] Length[A] 2 for i length[A]/2 downto 1. 3 do Heapify(A,i)")
19
Visualizzazione Costruzione
4 1 3 2 16 14 8 7 9 10 4 1 3 2 16 14 8 7 9 10 4 1 3 14 16 2 8 7 9 10 4 1 10 14 16 2 8 7 9 3 4 16 10 14 7 2 8 1 9 3 16 14 10 8 7 2 4 1 9 3
20
Coda con priorità con heap
Risulta semplice implementare le varie operazioni di una coda con priorità utilizzando uno heap Extract Max: basta restituire la radice dello heap Heap Extract Max: dopo la restituzione dell’elemento massimo, posiziona l’ultimo elemento dello heap nella radice ed esegue Heapify per ripristinare la proprietà di ordinamento parziale Heap Insert: la procedura inserisce il nuovo elemento come elemento successivo all’ultimo e lo fa salire fino alla posizione giusta facendo “scendere” tutti padri

21
Pseudo codice operazioni di coda con priorità
Heap-Extract-Max(A) 1 max A[1] 2 A[1] A[heap-size[A]] 3 heap-size[A] heap-size[A]-1 4 Heapify(A,1) 5 return max Heap-Insert(A,key) 1 heap-size[A] heap-size[A]+1 2 i heap-size[A] 3 while i>1 e A[Parent(i)]<key 4 do A[i] A[Parent(i)] 5 i Parent(i) 6 A[i] key
 1 max A[1] 2 A[1] A[heap-size[A]] 3 heap-size[A] heap-size[A]-1. 4 Heapify(A,1) 5 return max. Heap-Insert(A,key) 1 heap-size[A] heap-size[A]+1. 2 i heap-size[A] 3 while i>1 e A[Parent(i)]<key. 4 do A[i] A[Parent(i)] 5 i Parent(i) 6 A[i] key.")
22
Visualizzazione Heap Insert
16 16 14 10 14 10 Key:15 8 7 9 3 8 7 9 3 2 4 1 2 4 1 / 16 16 / 10 15 10 8 14 9 3 8 14 9 3 2 4 1 7 2 4 1 7

23
Ordinamento Il problema consiste nell’elaborare insiemi di dati costituiti da record Esiste un elemento del record è detto chiave L’obiettivo dei metodi di ordinamento consiste nel riorganizzare i dati in modo che le loro chiavi siano disposte secondo un ordine specificato (generalmente numerico o alfabetico)
")
24
Metodi Si distinguono metodi:
interni: se l’insieme di dati è contenuto nella memoria principale esterni: se l’insieme di dati è immagazzinato su disco o nastro Per metodi interni è possibile l’accesso casuale ai dati, mentre per i metodi esterni è possibile solo l’accesso sequenziale o a grandi blocchi

25
Tipo di ordinamento Si distinguono i metodi di ordinamento in stabili o non stabili. Un metodo di ordinamento si dice stabile se preserva l’ordine relativo dei dati con chiavi uguali all’interno del file da ordinare Se si usa un metodo stabile per ordinare per anno di corso una lista di studenti già ordinata alfabeticamente otterremo una lista in cui gli studenti dello stesso anno sono ordinati alfabeticamente

26
Tipo di ordinamento Si distinguono i metodi di ordinamento in diretti o indiretti. Un metodo di ordinamento si dice diretto se accede all’intero record del dato da confrontare, indiretto se utilizza dei riferimenti (puntatori) per accedervi Metodi indiretti sono utili quando si devono ordinare dati di grandi dimensioni In questo modo non è necessario spostare i dati in memoria ma solo i puntatori ad essi.
 per accedervi. Metodi indiretti sono utili quando si devono ordinare dati di grandi dimensioni. In questo modo non è necessario spostare i dati in memoria ma solo i puntatori ad essi.")
27
Tipo di ordinamento Si distinguono i metodi di ordinamento sul posto e non, che fanno cioè uso di strutture ausiliare Un metodo si dice che ordina sul posto se durante l’elaborazione riorganizza gli elementi del vettore in ingresso all’interno del vettore stesso Se il metodo, per poter operare, ha necessità di allocare un vettore di appoggio dove copiare i risultati parziali o finali dell’elaborazione (della stessa dimensione del vettore in ingresso) abbiamo il secondo caso
 abbiamo il secondo caso.")
28
Selection Sort E’ uno degli algoritmi più semplici Il principio è:
si determina l’elemento più piccolo di tutto il vettore lo si scambia con l’elemento in prima posizione del vettore si cerca il secondo elemento più grande lo si scambia con l’elemento in seconda posizione del vettore si procede fino a quando l’intero vettore è ordinato Il nome deriva dal fatto che si seleziona di volta in volta il più piccolo elemento fra quelli rimanenti

29
Pseudocodice per SelectionSort
SelectionSort(A) 1 for i 1 to length[A] 2 do min i 3 for j i+1 to length[A] 4 do if(A[j]<A[min]) 5 then min j 6 scambia A[i] A[min]
 1 for i 1 to length[A] 2 do min i. 3 for j i+1 to length[A] 4 do if(A[j]<A[min]) 5 then min j. 6 scambia A[i] A[min]")
30
Caratteristiche del SelectionSort
Il tempo di calcolo è T(n)= (n2) infatti: per ogni dato di posizione i si eseguono n-1-i confronti il numero totale di confronti è pertanto (posto j= n-1-i ) j=n-1..1 j = n(n-1)/2 = (n2) Più precisamente il Selection Sort effettua circa n2/2 confronti e n scambi
= (n2) infatti: per ogni dato di posizione i si eseguono n-1-i confronti. il numero totale di confronti è pertanto (posto j= n-1-i ) j=n-1..1 j = n(n-1)/2 = (n2) Più precisamente il Selection Sort effettua circa n2/2 confronti e n scambi.")
31
Caratteristiche del SelectionSort
Uno svantaggio è che il tempo di esecuzione non dipende (in modo significativo) dal grado di ordinamento dei dati iniziali Un vantaggio è che ogni elemento è spostato una sola volta. Se è necessario spostare i dati, allora per dati molto grandi questo è l’algoritmo che asintoticamente effettua il minor numero di spostamenti possibili. Se il tempo di spostamento è dominante rispetto al tempo di confronto diventa un algoritmo interessante
 dal grado di ordinamento dei dati iniziali. Un vantaggio è che ogni elemento è spostato una sola volta. Se è necessario spostare i dati, allora per dati molto grandi questo è l’algoritmo che asintoticamente effettua il minor numero di spostamenti possibili. Se il tempo di spostamento è dominante rispetto al tempo di confronto diventa un algoritmo interessante.")
32
BubbleSort E’ un metodo elementare Il principio di funzionamento è:
si attraversa il vettore scambiando coppie di elementi adiacenti ci si ferma quando non è più richiesto alcuno scambio Il nome deriva dal seguente fenomeno: quando durante l’attraversamento si incontra l’elemento più piccolo non ancora ordinato questo viene sempre scambiato con tutti, affiorando fino alla posizione giusta come una bolla nel processo gli elementi maggiori affondano e quelli più leggeri salgono a galla

33
PseudoCodice per il BubbleSort
BubbleSort(A) 1 for i 1 to length[A] 2 do for j length[A] downto i-1 4 do if(A[j-1] > A[j]) then scambia A[j-1] A[j]
 1 for i 1 to length[A] 2 do for j length[A] downto i-1. 4 do if(A[j-1] > A[j]) 5 then scambia A[j-1] A[j]")
34
Caratteristiche del BubbleSort
Il tempo di calcolo è T(n)= (n2) infatti: per ogni dato di posizione i si eseguono i confronti e i scambi il numero totale di confronti è pertanto i=1..n-1 i = n(n-1)/2 = (n2) Il Bubble Sort effettua circa n2/2 confronti e n2/2 scambi in generale è peggiore del selection sort
= (n2) infatti: per ogni dato di posizione i si eseguono i confronti e i scambi. il numero totale di confronti è pertanto. i=1..n-1 i = n(n-1)/2 = (n2) Il Bubble Sort effettua circa n2/2 confronti e n2/2 scambi. in generale è peggiore del selection sort.")
35
Heap Sort Il metodo di ordinamento Heap Sort sfrutta la proprietà di ordinamento parziale dello Heap L’idea è di selezionare l’elemento più grande, eliminarlo dallo heap e poi utilizzare la procedura Heapify per ripristinare la proprietà di ordinamento parziale in pratica piuttosto che eliminare gli elementi si inseriscono come elemento più prossimo oltre i limiti dello heap

36
Pseudocodice per HeapSort
HeapSort(A) 1 BuildHep(A) 2 for i length[A] downto 2 3 do scambia A[1] A[i] 4 heap-size[A] heap-size[A]-1 5 Heapify(A,1)
 1 BuildHep(A) 2 for i length[A] downto 2. 3 do scambia A[1] A[i] 4 heap-size[A] heap-size[A]-1. 5 Heapify(A,1)")
37
Visualizzazione HeapSort
16 14 10 8 7 2 4 1 9 3 14 8 10 4 7 2 1 16 9 3 10 8 9 4 7 2 14 16 1 3 9 8 3 4 7 10 14 16 1 2 8 7 3 4 2 10 14 16 1 9 7 4 3 1 2 10 14 16 8 9 4 2 3 1 7 10 14 16 8 9 3 2 1 4 7 10 14 16 8 9 2 1 3 4 7 10 14 16 8 9

38
Tempo di Calcolo dell’HeapSort
L’algoritmo chiama n-1 volte la procedura Heapify Si deve determinare il tempo di calcolo di Heapify Abbiamo visto che per Heapify si ha T(n)= (lg n) Pertanto il tempo di calcolo per HeapSort è: T(n)= (n lg n)
= (lg n) Pertanto il tempo di calcolo per HeapSort è: T(n)= (n lg n)")
39
QuickSort Il QuickSort, come il MergeSort, è un algoritmo basato sul paradigma Divide et Impera Fasi: Divide: il vettore A[p..r] è riorganizzato in modo da avere due sottosequenze A[p..q] e A[q+1..r] tali che qualsiasi elemento in A[p..q] è minore di un qualsiasi elemento in A[q+1..r]. L’indice q è calcolato da questa procedura di partizionamento Impera: le due sottosequenze sono ordinate ricorsivamente Combina: non ce ne è bisogno. Infatti, poiché le sottosequenze sono già ordinate internamente e qualsiasi elemento in A[p..q] è minore di un qualsiasi elemento in A[q+1..r], l’intero vettore A[p..r] è subito ordinato

40
PseudoCodice QuickSort(A,p,r) 1 if p<r 2 then q Partition(A,p,r)
3 QuickSort(A,p,q) 4 QuickSort(A,q+1,r)
 4 QuickSort(A,q+1,r)")
41
Spiegazione Intuitiva della Procedura Partition
Si prende un elemento, ad es. il primo elemento della prima sottosequenza, come elemento perno si vuole dividere il vettore A in due sottosequenze: nella prima devono esserci solo elementi <= 5 nella seconda solo elementi >=5 p r x=A[p]=5

42
Spiegazione Intuitiva della Procedura Partition
Si fanno crescere due regioni da entrambi gli estremi, utilizzando gli indici i,j a partire dagli estremi i i j j Elementi <=5 Elementi >=5

43
Spiegazione Intuitiva della Procedura Partition
Mentre le due regioni crescono si verifica il valore degli elementi Se un elemento non deve appartenere alla regione in cui si trova (o se l’elemento ha un valore eguale al valore perno) si smette di far crescere la regione Quando non è possibile far crescere nessuna delle due regioni si scambiano gli elementi fra loro i i j j 7 3 3 7 Elementi <=5 Elementi <=5 Elementi >=5 Elementi >=5
 si smette di far crescere la regione. Quando non è possibile far crescere nessuna delle due regioni si scambiano gli elementi fra loro. i. i. j. j Elementi <=5. Elementi <=5. Elementi >=5. Elementi >=5.")
44
Spiegazione Intuitiva della Procedura Partition
Quando i diventa maggiore di j allora abbiamo completato le due regioni La procedura termina i j Elementi <=5 Elementi >=5

45
PseudoCodice per Partition
Partition(A,p,r) 1 x A[p] 2 i p-1 3 j r+1 4 while TRUE 5 do repeat j j-1 6 until A[j] x 7 repeat i i+1 8 until A[i] x 9 if i < j 10 then scambia A[i] A[j] 11 else return j
 1 x A[p] 2 i p-1. 3 j r+1. 4 while TRUE. 5 do repeat j j-1. 6 until A[j] x. 7 repeat i i+1. 8 until A[i] x. 9 if i < j. 10 then scambia A[i] A[j] 11 else return j.")
46
Visualizzazione i j i j 5 3 2 6 4 1 3 7 5 3 2 6 4 1 3 7 i j i j
i j i j i j i j i j j i

47
Prestazioni del QuickSort
Il tempo di esecuzione del QuickSort dipende dal fatto che il partizionamento sia più o meno bilanciato il partizionamento dipende dagli elementi pivot. Se il partizionamento è bilanciato si hanno le stesse prestazioni del MergeSort altrimenti può essere tanto lento quanto l’InsertionSort

48
Caso peggiore Il caso di peggior sbilanciamento si ha quando il partizionamento produce due sottosequenze di lunghezza 1 e n-1 Il partizionamento richiede un tempo (n) e il passo base della ricorsione richiede T(1)=(1) pertanto: T(n)=T(n-1)+ (n) ad ogni passo si decrementa di 1 la dimensione dell’input, occorreranno pertanto n passi per completare la ricorsione T(n)= k=1..n(k) = (k=1..nk) = (n2)
 e il passo base della ricorsione richiede T(1)=(1) pertanto: T(n)=T(n-1)+ (n) ad ogni passo si decrementa di 1 la dimensione dell’input, occorreranno pertanto n passi per completare la ricorsione. T(n)= k=1..n(k) = (k=1..nk) = (n2)")
49
Caso migliore Il caso migliore si ha se ad ogni partizionamento di divide in due sottosequenze di dimensione identica l’input in questo caso si ha, come nel caso del MergeSort T(n)=2T(n/2)+ (n) ovvero, per il Teorema Principale: T(n)= (n lg n)
=2T(n/2)+ (n) ovvero, per il Teorema Principale: T(n)= (n lg n)")
50
Caso medio Per avere una intuizione di cosa accade nel caso medio può risultare utile introdurre il concetto di albero di ricorsione

51
Albero di ricorsione Un albero di ricorsione è un modo di visualizzare cosa accade in un algoritmo divide et impera L’etichetta della radice rappresenta il costo non ricorsivo della fase divide e combina la radice ha tanti figli quanti sottoproblemi generati ricorsivamente ogni sottoproblema ha come etichetta il costo della fase divide e combina del problema per la nuova dimensione per ogni livello si indica la somma dei costi si conteggia il numero di livelli necessari per terminare la ricorsione

52
Esempio di albero di ricorsione
Per T(n)=2T(n/2)+n2 si ha: n2 n2 T(n/2) T(n/2) (n/2)2 (n/2)2 T(n/4) T(n/4) T(n/4) T(n/4)
=2T(n/2)+n2 si ha: n2. n2. T(n/2) T(n/2) (n/2)2. (n/2)2. T(n/4) T(n/4) T(n/4) T(n/4)")
53
Esempio di albero di ricorsione
lg n (n/4)2 (n/4)2 (n/4)2 (n/4)2 1/4 n2 ... Totale = n2 i=1.. lg n 1/2i < n2 i=1.. 1/2i=2 n2 Totale = (n2)
2. (n/4)2. (n/4)2. (n/4)2. 1/4 n Totale = n2 i=1.. lg n 1/2i < n2 i=1.. 1/2i=2 n2. Totale = (n2)")
54
Esempio di albero di ricorsione
Per il calcolo dell’altezza dell’albero di ricorsione, ovvero del numero di passi necessario per terminare la ricorsione, si considera il cammino più lungo dalla radice ad una foglia n2 >> (1/2n)2 >> ((1/2)2n)2 >> ((1/2)3n)2 >> ... >> 1 Dato che ((1/2)i n)2 = 1 2i = n log2 2i = log2 n i = lg n ovvero h= lg n
2 >> ((1/2)2n)2 >> ((1/2)3n)2 >> ... >> 1. Dato che. ((1/2)i n)2 = 1. 2i = n. log2 2i = log2 n. i = lg n. ovvero h= lg n.")
55
Concetti intuitivi sul caso medio
Si consideri un partizionamento “abbastanza” sbilanciato che divida il problema in due sotto sequenze di dimensione 1/10 e 9/10 T(n)=T(n/10)+T(9n/10)+n dall’albero di ricorsione si ha che ogni livello costa n il numero di livelli è: n>>9/10 n >>(9/10)2 n >>(9/10)3 n>>…>>1 ovvero (9/10)i n = 1 n = (10/9)i i = log10/9 n
=T(n/10)+T(9n/10)+n. dall’albero di ricorsione si ha che ogni livello costa n. il numero di livelli è: n>>9/10 n >>(9/10)2 n >>(9/10)3 n>>…>>1. ovvero (9/10)i n = 1. n = (10/9)i. i = log10/9 n.")
56
Albero di ricorsione n n (n/10) (9n/10) n log10/9 n (n/100) (9n/100)
... Totale = (n lg n)
")
57
Concetti intuitivi sul caso medio
Con un partizionamento di 1 a 9 il quicksort viene eseguito in un tempo asintoticamente eguale al caso migliore di partizionamento bilanciato Anche una suddivisione 1 a 99 mantiene la proprietà di esecuzione in tempo n lg n Il motivo è che qualsiasi suddivisione in proporzioni costanti produce un albero di altezza lg n in cui ogni livello costa (n) Tuttavia non possiamo aspettarci un partizionamento costante nei casi reali
 Tuttavia non possiamo aspettarci un partizionamento costante nei casi reali.")
58
Concetti intuitivi sul caso medio
Si suppone che in media si abbiano delle partizioni buone e cattive distribuite durante lo svolgimento dell’algoritmo si suppone per semplificare che le partizioni buone si alternino a quelle cattive si suppone che la partizione buona sia la migliore possibile, cioè quella derivante da un bilanciamento perfetto e quella cattiva la peggiore possibile, cioè quella derivante da una partizione 1, n-1

59
Concetti intuitivi sul caso medio
Si ha pertanto un primo passo in cui si partiziona il problema in due sottosequenze 1 e n-1 di costo n poi un secondo passo in cui si risolve in tempo costante il problema sulla sottosequenza unitaria si partiziona ulteriormente la sequenza di lunghezza n-1 in due sottosequenze di (n-1)/2 e (n-1)/2 elementi ad un costo di n-1 Il risultato è di aver raddoppiato il numero di passi rispetto al caso di partizionamento ottimo, ma di essere sostanzialmente arrivati nella stessa situazione di buon partizionamento (n/2 contro (n-1)/2) con un costo complessivo (n)
/2 e (n-1)/2 elementi ad un costo di n-1. Il risultato è di aver raddoppiato il numero di passi rispetto al caso di partizionamento ottimo, ma di essere sostanzialmente arrivati nella stessa situazione di buon partizionamento (n/2 contro (n-1)/2) con un costo complessivo (n)")
60
Concetti intuitivi sul caso medio
In sintesi il costo del QuickSort per un caso medio in cui si alternano partizioni buone a cattive è dello stesso ordine di grandezza del caso migliore, e cioè O(n lg n) anche se con costanti più grandi
 anche se con costanti più grandi.")
61
Algoritmo Randomizzato
Il caso medio si ottiene quando una qualsiasi permutazione dei dati in ingresso è equiprobabile tuttavia nei casi reali questo può non essere vero: ad esempio ci sono situazioni in cui i dati sono parzialmente ordinati in questi casi le prestazioni del quicksort peggiorano piuttosto che ipotizzare una distribuzione dei dati in ingresso è possibile imporre una distribuzione si chiama randomizzato un algoritmo il cui comportamento è determinato non solo dall’ingresso ma anche da un generatore di numeri casuale

62
Randomized QuickSort 1 Prima di avviare la procedura di sort si esegue una permutazione casuale degli elementi del vettore di ingresso Il calcolo della permutazione deve avere un costo O(n) Nessuna sequenza in ingresso comporta il caso peggiore: tuttavia si può avere una cattiva permutazione prodotta dal generatore casuale Tuttavia si può garantire che si generino pochissime permutazioni cattive in media
 Nessuna sequenza in ingresso comporta il caso peggiore: tuttavia si può avere una cattiva permutazione prodotta dal generatore casuale. Tuttavia si può garantire che si generino pochissime permutazioni cattive in media.")
63
PseudoCodice per la permutazione casuale
Randomize(A,p,r) 1 for i 1 to length[A] 2 do j Random(p,r) 3 scambia A[i] A[j]
 1 for i 1 to length[A] 2 do j Random(p,r) 3 scambia A[i] A[j]")
64
Randomized QuickSort 2 Ad ogli passo, prima di partizionare l’array si scambia A[p] con un elemento scelto a caso in A[p..r] si sceglie cioè l’elemento pivot in modo casuale ad ogni partizionamento Questo assicura che il pivot sia in modo equiprobabile uno qualsiasi degli elementi in A[p..r] Ci si aspetta cosi’ che in media la suddivisione dell’array sia ben bilanciata
![Randomized QuickSort 2 Ad ogli passo, prima di partizionare l’array si scambia A[p] con un elemento scelto a caso in A[p..r]](http://slideplayer.it/slide/555572/1/images/64/Randomized+QuickSort+2+Ad+ogli+passo%2C+prima+di+partizionare+l%E2%80%99array+si+scambia+A%5Bp%5D+con+un+elemento+scelto+a+caso+in+A%5Bp..r%5D.jpg "si sceglie cioè l’elemento pivot in modo casuale ad ogni partizionamento. Questo assicura che il pivot sia in modo equiprobabile uno qualsiasi degli elementi in A[p..r] Ci si aspetta cosi’ che in media la suddivisione dell’array sia ben bilanciata.")
65
PseudoCodice Randomized-Partition(A,p,r) 1 i Random(p,r)
2 scambia A[p] A[i] 3 return Partition(A,p,r) Randomized-QuickSort(A,p,r) 1 if p<r 2 then q RandomizedPartition(A,p,r) 3 Randomized-Quicksort(A,p,r) 4 Randomized-Quicksort(A,q+1,r)
 Randomized-QuickSort(A,p,r) 1 if p<r. 2 then q RandomizedPartition(A,p,r) 3 Randomized-Quicksort(A,p,r) 4 Randomized-Quicksort(A,q+1,r)")




>")
 Definizione>")














