Scaricare la presentazione
1
DISTRIBUZIONI TEORICHE DI PROBABILITA’

2
DISTRIBUZIONI TEORICHE DI PROBABILITA’
DEFINIZIONI: Qualsiasi caratteristica misurabile è denominata variabile. Se una variabile può assumere numerosi valori tali che qualsiasi risultato è determinato dal caso, essa è nota come variabile casuale Una V.C. è un numero X che assume un valore in R, determinato sulla base di un evento E che si è presentato in seguito all’esperimento al quale si riferisce. Tale numero è assunto da X con probabilità P Una distribuzione di probabilità è una funzione che sintetizza la relazione tra i valori di una variabile casuale e la probabilità che questi si presentino Una distribuzione di probabilità applica la teoria della probabilità per descrivere il comportamento di una variabile.

3
… La conoscenza della distribuzione di probabilità di una variabile casuale fornisce ai clinici e ai ricercatori uno strumento potente per riassumere e descrivere il set di dati e per trarre conclusioni a partire dal campione della popolazione studiata Una distribuzione di probabilità può essere rappresentata con una tabella, un grafico o una formula

4
OSSERVAZIONI Una distribuzione è analoga ad una distribuzione di frequenze relative , ma mentre questa si ricava da un campione di osservazioni estratte da un popolazione, una distribuzione di probabilità è in relazione alla popolazione di tutti i possibili risultati Una distribuzione continua non permette la stima della probabilità di estrarre un particolare valore, ma solo quelli compresi in un dato intervallo. Per esempio, nella distribuzione delle altezze di una popolazione di studenti, non è possibile stimare la probabilità di avere un individuo alto esattamente 176,000 cm ma quella di avere un individuo tra 180 e 190 centimetri

5
La forma di una distribuzione di probabilità continua è usualmente definita da una curva senza sbalzi, mentre per una variabile discreta la probabilità è definita per i valori puntuali della variabile , e il grafico della distribuzione rassomiglia ad una serie di impulsi La forma di una distribuzione può essere simmetrica rispetto al valore centrale o ci può essere una coda più lunga da un lato piuttosto che da un altro. Se la coda è a sinistra (destra) la distribuzione viene detta asimmetrica a sinistra (destra) - Alcune distribuzioni teoriche di probabilità comunemente usate per descrivere dati sanitari sono: Distribuzione Gaussiana, la distribuzione log-normale, la distribuzione Binomiale e la distribuzione di Poisson
 la distribuzione viene detta asimmetrica a sinistra (destra) - Alcune distribuzioni teoriche di probabilità comunemente usate per descrivere dati sanitari sono: Distribuzione Gaussiana, la distribuzione log-normale, la distribuzione Binomiale e la distribuzione di Poisson.")
6
DISTRIBUZIONI DI PROBABILITA’ PER VARIABILI CONTINUE
Nel caso si osservino Variabili continue le distribuzioni permettono di determinare le probabilità associate a determinati “range” di valori della variabile (Distribuzione Normale) V.C. continua: Livello di colesterolo nel sangue
 V.C. continua: Livello di colesterolo nel sangue.")
7
La Distribuzione Gaussiana
Le distribuzioni normali sono una famiglia di curve simmetriche a forma di campana e unimodali (moda media e mediana coincidono). Hanno tutte la stessa forma ma sono caratterizzate (e completamente individualizzate) dai due valori: media e varianza N(μ,σ2). Densità di Probabilità L’area totale sotto la curva è 1
. Hanno tutte la stessa forma ma sono caratterizzate (e completamente individualizzate) dai due valori: media e varianza N(μ,σ2). Densità di Probabilità. L’area totale sotto la curva è 1.")
8
1. Caratteristiche di una distribuzione Normale
La curva Normale è Unimodale e simmetrica rispetto alla sua media (μ) Frequenza relativamente più elevata dei valori centrali e frequenze progressivamente minori verso gli estremi. La media, la mediana e la moda della distribuzione coincidono La Deviazione Standard, rappresentata da , indica la quantità di dispersione delle osservazioni intorno alla media I parametri μ e σ definiscono in modo completo la curva
 Frequenza relativamente più elevata dei valori centrali e frequenze progressivamente minori verso gli estremi. La media, la mediana e la moda della distribuzione coincidono. La Deviazione Standard, rappresentata da , indica la quantità di dispersione delle osservazioni intorno alla media. I parametri μ e σ definiscono in modo completo la curva.")
9
2. Caratteristiche di una distribuzione Normale
La funzione di densità è simmetrica rispetto alla media: cresce da zero fino alla media e poi decresce fino a +∞. Ha due flessi: il primo, ascendente, nel punto μ-σ; il secondo, discendente, nel punto μ+σ. Se μ varia e σ rimane costante, si hanno infinite curve normali con la stessa forma e la stessa dimensione, ma con l'asse di simmetria in un punto diverso. Quando due distribuzioni hanno media differente, è possibile ottenere l'una dall'altra mediante traslazione o trasformazione lineare dei dati. Se invece μ rimane costante e σ varia, tutte le infinite curve hanno lo stesso asse di simmetria; ma hanno forma più o meno appiattita, secondo il valore di σ.

10
Le due curve della figura 11 hanno media μ identica e deviazione standard σ differente.

11
Le due curve della figura 12 hanno deviazione standard σ identica e media μ differente.

12
In Figura 13 sono riportate 2 distribuzioni normali che differiscono sia per la media sia per la dispersione dei dati

13
3. Caratteristiche di una distribuzione Normale
La probabilità che un valore estratto a caso da una N(μ,σ2) sia compreso nell’intervallo (μ -σ , μ+σ) è pari a 0.683 e che sia compreso tra (μ -2σ , μ+2σ) è pari a 0,954 Il 95% dei valori centrali di una distribuzione Normale cadono nell’intervallo (μ σ , μ+1.96σ) ed il 99% nell’intervallo (μ – 2.58σ , μ+2.58σ)
 sia compreso nell’intervallo (μ -σ , μ+σ) è pari a e che sia compreso tra (μ -2σ , μ+2σ) è pari a 0,954. Il 95% dei valori centrali di una distribuzione Normale. cadono nell’intervallo (μ σ , μ+1.96σ) ed il 99% nell’intervallo (μ – 2.58σ , μ+2.58σ)")
14
AREE SOTTO LA CURVA NORMALE COMUNEMENTE USATE

15
Poiché i valori di μ e σ dipendono dal particolare problema in considerazione le probabilità di trovare dei valori in un determinato intervallo, anche diverso da quelli comunemente usati, e descritti nel grafico precedente, diventa complicato. Non ci sono tavole di probabilità per tutti i possibili valori di μ e σ , esiste una tavola unica che può essere usata per tutte le variabili Normali. Tale tavola si riferisce ad una particolare distribuzione: la ditribuzione Normale Standardizzata. La distribuzione normale standardizzata o normale ridotta, si ottiene mediante il cambiamento di variabile dato da

16
La standardizzazione è una trasformazione che consiste nel:
- rendere la media nulla (μ = 0), poiché ad ogni valore viene sottratta la media; - prendere la deviazione standard σ come unità di misura (σ = 1) della nuova variabile. La distribuzione normale ridotta viene indicata con N(0,1), che indica appunto una distribuzione normale con media 0 e varianza uguale a 1. In ogni distribuzione Normale con media μ e d.s. σ, la probabilità tra x1 e x2 è la stessa che tra z1 e z2 nella distribuzione Normale Standardizzata, dove z1=(x1- μ)/ σ z2=(x2- μ)/ σ
, poiché ad ogni valore viene sottratta la media; - prendere la deviazione standard σ come unità di misura (σ = 1) della nuova variabile. La distribuzione normale ridotta viene indicata con N(0,1), che indica appunto una distribuzione normale con media 0 e varianza uguale a 1. In ogni distribuzione Normale con media μ e d.s. σ, la probabilità tra x1 e x2 è la stessa che tra z1 e z2 nella distribuzione Normale Standardizzata, dove. z1=(x1- μ)/ σ. z2=(x2- μ)/ σ.")
17
Caratteristiche di una Distribuzione Normale Standard
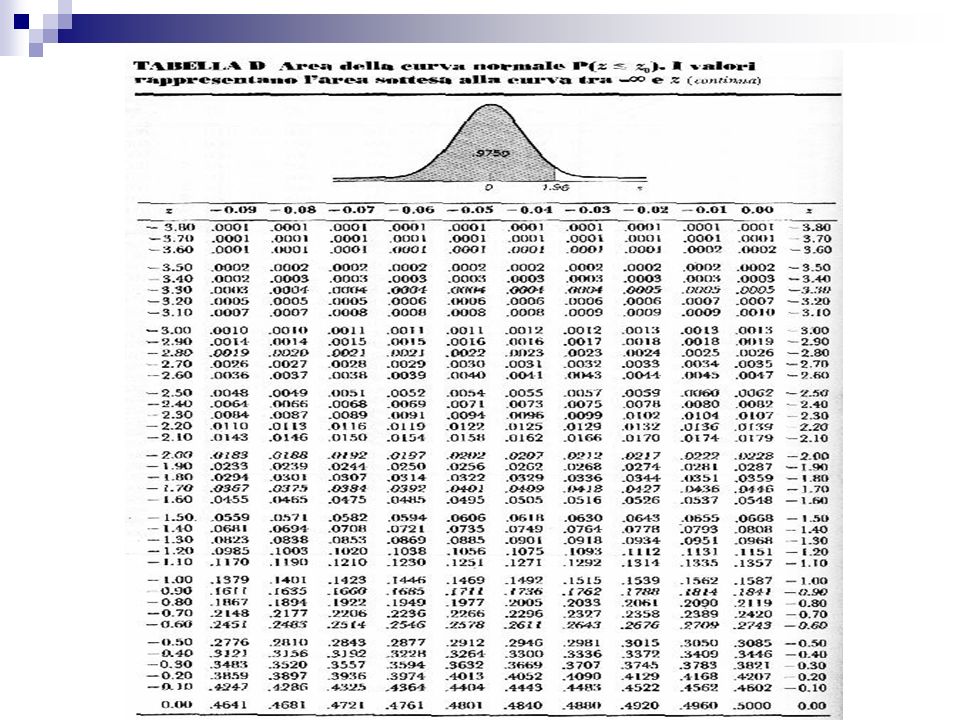
In una Distribuzione Normale Standardizzata: La probabilità che un valore estratto a caso sia compreso tra -1 e 1 è pari a 0,683 e che sia compreso tra -2 e 2 è pari a 0,954 Il 95% dei valori centrali di una distribuzione Normale standard cadono nell’intervallo (-1.96 ,+1.96) ed il 99% nell’intervallo (– 2.58 , +2.58) Tutti i valori di probabilità per z sono riportati in una tavola, detta tavola di probabilità I valori nel corpo della tabella mostrano l’area sotto la curva N.S. alla destra di z. Queste sono le probabilità di trovare un valore uguale o superiore a z
 ed il 99% nell’intervallo (– 2.58 , +2.58) Tutti i valori di probabilità per z sono riportati in una tavola, detta tavola di probabilità. I valori nel corpo della tabella mostrano l’area sotto la curva N.S. alla destra di z. Queste sono le probabilità di trovare un valore uguale o superiore a z.")
18
Area a dx di Z

21
Uso della tavola di Probabilità Gaussiana
Due sono gli usi della tavola di probabilità: Definito un intervallo di valori di X, serve per calcolare la probabilità che un valore x cada al suo interno Definita una probabilità, serve per calcolare l’intervallo dei valori X che corrisponde a tale probabilità.

25
Esercizio Si consideri una popolazione con altezza distribuita in maniera Gaussiana con media (µ) =172,5 cm e deviazione standard (σ) = 6,25 cm. Qual è la probabilità di incontrare un individuo estratto da tale popolazione e di altezza superiore a cm 190? Z = (190 – 172,5) / 6,25 = 2,8 Dalle tavole trovo p= 0,00256, quindi la probabilità di trovare un soggetto più alto di 190cm è dello 0,2%
 / 6,25 = 2,8. Dalle tavole trovo p= 0,00256, quindi la probabilità di trovare un soggetto più alto di 190cm è dello 0,2%")
26
Qual è la probabilità di incontrare un individuo estratto da tale popolazione con un’altezza compresa tra cm 165 e175? Z1= (165 – 172,5) / 6,25 = -1.2 Z2= (175 – 172,5) / 6,25 = 0.4 P(Z1)=0.115 P(Z2)=0.345 P(165≤ X ≤ 175) = P(-1.2≤ Z ≤ 0.4) = 1- [ ]=0.54
 / 6,25 = Z2= (175 – 172,5) / 6,25 = 0.4. P(Z1)= P(Z2)= P(165≤ X ≤ 175) = P(-1.2≤ Z ≤ 0.4) = 1- [ ]=0.54.")
27
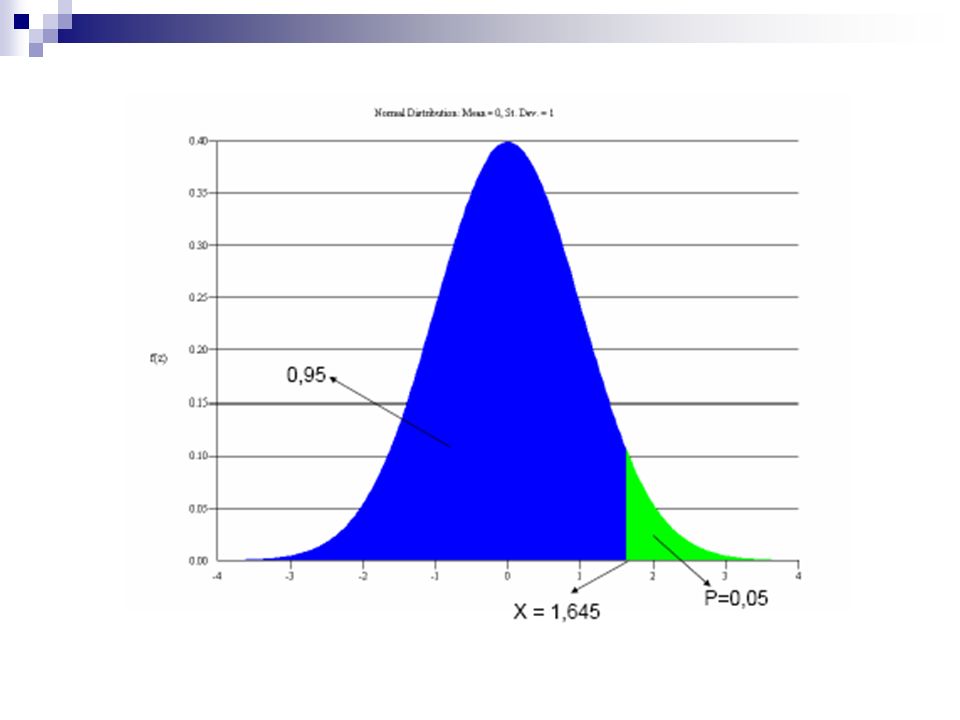
Qual è quel valore di altezza che delimita il 5% superiore della distribuzione?
p=0.05 z =1.645 z =(x-172.5)/6.25 1.645=(x-172.5)/6.25 x = (6.25*1.645) x = Circa il 5% della popolazione in studio ha un’altezza superiore di cm
/6.25 1.645=(x-172.5)/6.25. x = (6.25*1.645) x = Circa il 5% della popolazione in studio ha un’altezza superiore di cm.")
34
LA DISTRIBUZIONE LOG NORMALE
Quando i dati hanno una distribuzione differente dalla normale, spesso una semplice trasformazione riconduce ad una distribuzione normale. E' il caso delle trasformazioni con la radice quadrata o cubica, oppure con il reciproco, l’elevamento a potenza o con i logaritmi. Nel caso in cui una distribuzione abbia una lunga coda a destra (asimmetrica a destra), si ottiene una distribuzione più simmetrica, se invece della distribuzione originale sui dati (x) si considera la distribuzione dei dati trasformati in logaritmi (y = log(x)) Nel caso in cui la distribuzione della variabile trasformata (y) risulti Normale, la distribuzione dei dati originali (x) è detta log-Normale
, si ottiene una distribuzione più simmetrica, se invece della distribuzione originale sui dati (x) si considera la distribuzione dei dati trasformati in logaritmi (y = log(x)) Nel caso in cui la distribuzione della variabile trasformata. (y) risulti Normale, la distribuzione dei dati. originali (x) è detta log-Normale.")
35
VANTAGGI DELLA TRASFORMAZIONE LOG
Molte tecniche statistiche inferenziali si basano sull’assunzione di “normalità dei dati”. Anche se tali tecniche sono “robuste” verso le deviazioni dalla normalità, forti asimmetrie porterebbero a stime distorte Se una variabile ha una d.s. che è proporzionale alla sua media, la sua trasformazione log, y = log(x) dà luogo a una variabile y con d.s. costante al variare della media La trasforamzione logaritmica linearizza le curve che hanno una forma esponenziale , i dati trasformati saranno più semplici da analizzare ed interpretare
 dà luogo a una variabile y con d.s. costante al variare della media. La trasforamzione logaritmica linearizza le curve che hanno una forma esponenziale , i dati trasformati saranno più semplici da analizzare ed interpretare.")
36
SVANTAGGI DELLA TRASFORMAZIONE LOG
Il logaritmo di 0 è -∞, il che causa problemi quando sono presenti dei dati con un numero limitato di zeri. Un’approssimazione può essere realizzata assegnando ai valori zero la metà del valore della più piccola osservazione. Non esiste il logaritmo di un numero negativo L’interpretazione dei risultati su scala logaritmica è difficile e quasi sempre richiede l’uso dell’anti logaritmo

37
DATI GREZZI DATI LOG-TRASFORMATI

38
DISTRIBUZIONI DI PROBABILITA’ PER VARIABILI DISCRETE
Nel caso si osservino Variabili discrete le distribuzioni specificano tutti i possibili risultati della variabile casuale insieme alla probabilità che ciascuno di essi si verifichi V.C. discreta: Numero di figli maschi in famiglie con 4 figli residenti in Toscana nel 1991 # MASCHI FR 0.05 1 0.23 2 0.37 3 0.28 4 0.07

39
DISTRIBUZIONE BINOMIALE (1)
Consideriamo un esperimento con solo due tipi di risultati possibili (es: Successo (1) - Non Successo (0)) rispettivamente con probabilità p e q=1-p. Ripetendo n volte l'esperimento in modo che le ripetizioni diano luogo a risultati indipendenti la somma delle realizzazioni 0,1 coinciderà con il numero di successi k. Tale numero è una nuova variabile casuale (o meglio aleatoria), somma di n variabili casuali bernoulliane indipendenti La v.c. Binomiale è definita dalla seguente funzione di probabilità : tale funzione esprime la probabilità della concomitanza di k successi (indipendentemente dall'ordine) che si alternano agli n - k insuccessi. Il coefficiente binomiale: (coefficienti binomiali) esprime le distinguibili maniere in cui possono essere ripartiti i k successi negli n tentativi, ed, ovviamente,
 - Non Successo (0)) rispettivamente con probabilità p e q=1-p. Ripetendo n volte l esperimento in modo che le ripetizioni diano luogo a risultati indipendenti la somma delle realizzazioni 0,1 coinciderà con il numero di successi k. Tale numero è una nuova variabile casuale (o meglio aleatoria), somma di n variabili casuali bernoulliane indipendenti. La v.c. Binomiale è definita dalla seguente funzione di probabilità : tale funzione esprime la probabilità della concomitanza di k successi (indipendentemente dall ordine) che si alternano agli n - k insuccessi. Il coefficiente binomiale: (coefficienti binomiali) esprime le distinguibili maniere in cui possono essere ripartiti i k successi negli n tentativi, ed, ovviamente,")
40
DISTRIBUZIONE BINOMIALE (2)
per il binomio di Newton vale: k è un numero intero non negativo (k=0,1,2,3,...,n) p è un valore compreso tra 0 e 1 esclusi (0<p<1) Esempio 1. Determinare la probabilità che su 12 lanci di una moneta buona si ottengano esattamente 8 teste. Si tratta di un esperimento di Bernoulli in cui il “successo” coincide con “esce T”; quindi p =1/2 e q = 1/2 e si ha:
 p è un valore compreso tra 0 e 1 esclusi (0<p<1) Esempio 1. Determinare la probabilità che su 12 lanci di una moneta buona si ottengano esattamente 8 teste. Si tratta di un esperimento di Bernoulli in cui il successo coincide con esce T ; quindi p =1/2 e q = 1/2. e si ha:")
42
LE DISTRIBUZIONI t di STUDENT e Χ2 (chi-quadrato)
Le distribuzioni t, Χ2 e F non sono distribuzioni per dati osservati ma sono distribuzioni che si usano per calcolare intervalli di confidenza ed eseguire test di significatività Queste distribuzioni sono utili quando si considerano distribuzioni di probabilità di certe STATISTICHE calcolati su campioni casuali estratti da popolazioni Gaussiane La distribuzione t si usa per fare inferenza sulle medie quando non si conosce la deviazione standard della popolazione La distribuzione Χ2 si utilizza per fare inferenza su frequenze osservate e su conteggi


























>")




