Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
La Statistica esiste in quanto in natura i fenomeni tendono a manifestarsi con diverse modalità ad essere cioè variabili. Senza la statistica non esiste metodo sperimentale. Il tentativo della statistica è di separare - VARIABILITA’ SISTEMATICA insieme di differenze dovute a fattori che agiscono sulla grandezza in esame e dei quali è possibile accertare l’effetto - VARIABILITA’ CASUALE insieme di differenze dovute a fattori incontrollabili “Un singolo individuo è una entità inestricabile, un insieme di individui è un sistema facilmente prevedibile” A. Conan-Doyle

2
Definizione di Statistica
Disciplina che si occupa della trattazione dei dati rilevati su fenomeni misurabili allo scopo di rappresentare e sintetizzare i fenomeni di interesse (Statistica descrittiva) interpretare la natura della relazione esistente tra i fenomeni (Statistica inferenziale) prendere delle decisioni in merito ad ipotesi di interesse (Statistica inferenziale)
 interpretare la natura della relazione esistente tra i fenomeni (Statistica inferenziale) prendere delle decisioni in merito ad ipotesi di interesse (Statistica inferenziale)")
3
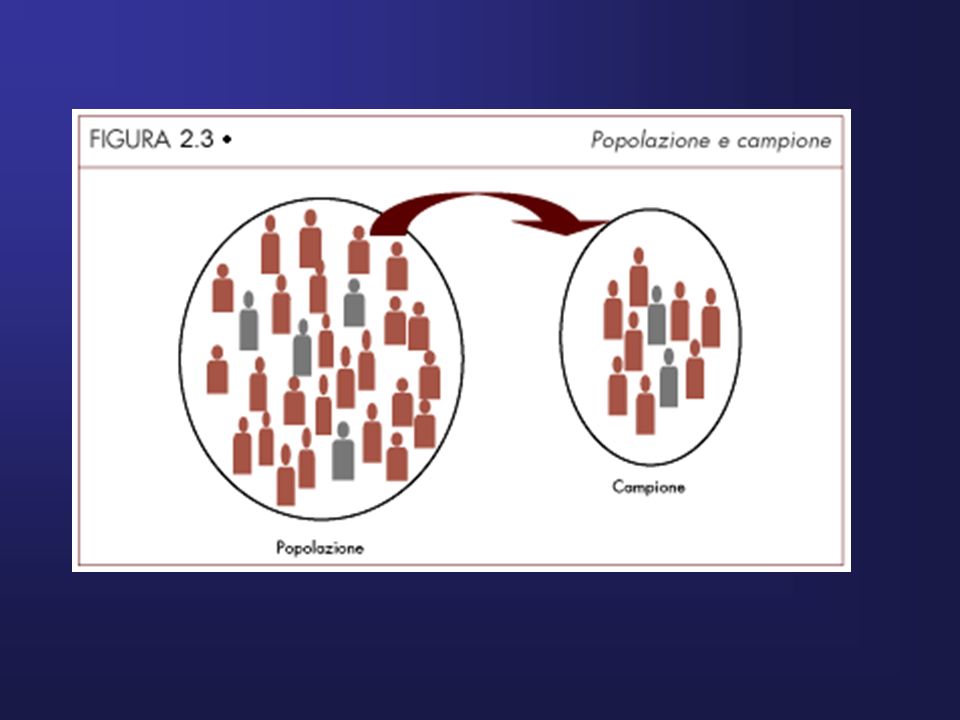
POPOLAZIONE E CAMPIONE
Insieme di enti che condividono una o più caratteristiche comuni Popolazioni finite : bambini di V C di una certa scuola Popolazioni infinite: tutti i multipli di 13 CAMPIONE: Piccola frazione di una popolazione le cui caratteristiche si avvicinano a quelle della popolazione. L’approssimazione migliore si ha quando il campione è casuale cioè quando la probabilità che un elemento venga scelto è uguale per tutti gli elementi della popolazione L’approssimazione è tanto maggiore quanto maggiore è la dimensione del campione

5
Tipi di variabili Nominali: la proprietà assume stati discreti non ordinabili. Un tipo particolare sono le variabili dicotomiche (o binarie) (p.e. il genere) Ordinali: la proprietà assume stati discreti ordinabili (p.s. il livello di istruzione) Cardinali: i numeri che identificano le modalità (i valori della variabile) non sono semplici etichette, ma hanno un pieno significato numerico. La variabile cardinale può assumere stati discreti (p.e. il numero di figli) o stati continui (p.e. l’età, il peso). Se lo zero corrisponde all’assenza della caratteristica, la variabile è detta razionale (p.e. scala Kelvin della temperatura),
 (p.e. il genere) Ordinali: la proprietà assume stati discreti ordinabili (p.s. il livello di istruzione) Cardinali: i numeri che identificano le modalità (i valori della variabile) non sono semplici etichette, ma hanno un pieno significato numerico. La variabile cardinale può assumere stati discreti (p.e. il numero di figli) o stati continui (p.e. l’età, il peso). Se lo zero corrisponde all’assenza della caratteristica, la variabile è detta razionale (p.e. scala Kelvin della temperatura),")
6
Misure di tendenza centrale: media, mediana e moda
Media (aritmetica): somma dei valori delle osservazioni diviso il numero di osservazioni Mediana: il valore che divide a metà le osservazioni (50% sono più basse, 50% sono maggiori) Moda: il (i) valore(i) più frequenti in una serie di osservazioni
: somma dei valori delle osservazioni diviso il numero di osservazioni. Mediana: il valore che divide a metà le osservazioni (50% sono più basse, 50% sono maggiori) Moda: il (i) valore(i) più frequenti in una serie di osservazioni.")
7
MISURE DI POSIZIONE Analogamente alla mediana si definiscono e si calcolano: quartili decili percentili 1° quartile: superiore o uguale al 25% delle osservazioni inferiore al restante 75% 2° quartile coincide con la mediana 3° quartile : inferiore o uguale al 25% delle osservazioni e superiore al 75% 1° decile: superiore o uguale al 10% e inferiore al 90% delle osservazioni 1° percentile inferiore o uguale al 99% e superiore all’1% delle osservazioni, ecc.

8
MISURE DI DISPERSIONE Le misure di dispersione danno un’idea di quanto i dati si scostano dal valore centrale. - RANGE o intervallo di variazione: differenza fra valore massimo e minimo. DEVIANZA o somma dei quadrati degli scarti dalla media. VARIANZA è la devianza divisa per il numero di osservazioni.

9
MISURE DI DISPERSIONE DEVIAZIONE STANDARD è la radice quadrata della varianza: In questo modo ds ha le stesse dimensioni fisiche delle osservazioni. In genere si scrive la media di un campione seguita dalla sua deviazione standard, es. 14 3.

10
DISTRIBUZIONE NORMALE

11
La distribuzione Normale
La distribuzione normale è importante in statistica per tre motivi fondamentali: Diversi fenomeni continui sembrano seguire, almeno approssimativamente, una distribuzione normale. La distribuzione normale può essere utilizzata per approssimare numerose distribuzioni di probabilità discrete. La distribuzione normale è alla base dell’inferenza statistica classica in virtù del teorema del limite centrale. Le fondamentali proprietà teoriche della distribuzione normale sono La distribuzione normale ha una forma campanulare e simmetrica. Le sue misure di posizione centrale (media, mediana, moda) coincidono. La variabile aleatoria con distribuzione normale assume valori compresi tra - e + .
 coincidono. La variabile aleatoria con distribuzione normale assume valori compresi tra - e + .")
12
DISTRIBUZIONE NORMALE
Una proprietà fondamentale della gaussiana è la seguente: La probabilità che uno scarto dalla media sia maggiore di un certo valore è inversamente proporzionale al rapporto fra questo valore e la deviazione standard. Quindi esiste una probabilità definita e uguale per tutte le curve normali che un certo scarto sia inferiore a una (2, 3) deviazione standard.
 deviazione standard.")
14
I TEST STATISTICI

15
Si può definire test statistico una procedura che
- sulla base di dati campionari - e con un certo grado di probabilità, consente di decidere se è ragionevole o meno respingere l’ipotesi nulla H0 (ed accettare implicitamente l’ipotesi alternativa H1)
")
16
L’ipotesi nulla è, in generale, l’ipotesi che si vorrebbe rifiutare
L’ipotesi nulla è, in generale, l’ipotesi che si vorrebbe rifiutare. Essa afferma che gli effetti osservati nei campioni sono dovuti a fluttuazioni casuali ovvero che il valore del parametro (media, varianza, simmetria, curtosi, correlazione, ecc., …) nel campione estratto dalla popolazione studiata è uguale a quella di controllo. L’ipotesi nulla H0 deve essere rifiutata solamente se esiste l’evidenza che la contraddice. E’ importante comprendere che l’ipotesi nulla non è necessariamente vera, quando i dati campionari (eventualmente pochi) non sono tali da contraddirla. L’ipotesi nulla H0 non è mai provata o verificata; è solo possibile negarla o disapprovarla, sulla base di dati sperimentali. Per consolidata convenzione internazionale, i livelli di soglia delle probabilità α ai quali di norma si ricorre sono tre: 0.05 (5%); 0.01 (1%); (0.1%).
 nel campione estratto dalla popolazione studiata è uguale a quella di controllo. L’ipotesi nulla H0 deve essere rifiutata solamente se esiste l’evidenza che la contraddice. E’ importante comprendere che l’ipotesi nulla non è necessariamente vera, quando i dati campionari (eventualmente pochi) non sono tali da contraddirla. L’ipotesi nulla H0 non è mai provata o verificata; è solo possibile negarla o disapprovarla, sulla base di dati sperimentali. Per consolidata convenzione internazionale, i livelli di soglia delle probabilità α ai quali di norma si ricorre sono tre: 0.05 (5%); 0.01 (1%); (0.1%).")
17
La statistica è la scienza che permette di scegliere e prendere decisioni non perché immune da errori, ma perché fornisce la probabilità di errare, associata ad ogni scelta. Quindi di valutare il rischio che si corre, se la scelta si dimostrasse errata.

18
Nel controllo di un’ipotesi statistica è possibile commettere due tipi di errore:
- l'errore di primo tipo o errore α (alfa), se si rifiuta l'ipotesi nulla quando in realtà essa è vera; l'errore di secondo tipo o errore β (beta), se si accetta l'ipotesi nulla, quando in realtà essa è falsa. La probabilità di commettere l’errore di I tipo è chiamata livello di significatività ed è indicata convenzionalmente con α (alfa). La probabilità di commettere l’errore di II tipo è indicato convenzionalmente con β (beta). Il complemento di β (quindi 1-β) è detto potenza di un test.
, se si rifiuta l ipotesi nulla quando in realtà essa è vera; l errore di secondo tipo o errore β (beta), se si accetta l ipotesi nulla, quando in realtà essa è falsa. La probabilità di commettere l’errore di I tipo è chiamata livello di significatività ed è indicata convenzionalmente con α (alfa). La probabilità di commettere l’errore di II tipo è indicato convenzionalmente con β (beta). Il complemento di β (quindi 1-β) è detto potenza di un test.")
19
La condizione migliore sarebbe di ridurre contemporaneamente sia l’errore di I tipo sia l’errore di II. Tuttavia le probabilità α e β sono legate da una relazione inversa: se una cresce, l’altra cala. L’unico modo per ridurli entrambi è quello di aumentare il numero dei dati. Tuttavia non sempre è possibile ampliare le dimensioni del campione, perché già raccolto oppure perché i costi ed il tempo necessari diventano eccessivi, per le disponibilità reali del ricercatore.

20
La scelta di α e di β sono soggettive.
Ma alcuni esperti di statistica applicata hanno fornito indicazioni operative. Il criterio di Cohen - è una indicazione che ha il solo pregio di apparire ragionevole; - è basata sul buon senso pratico, ma che non ha nessuna base teorica. Secondo tale proposta, - il valore di β è legato alla scelta di α, secondo la relazione: β = 4α - che, tradotto in rapporto alla potenza, diventa 1 - β = 1 - 4α

21
Goal Measurement (from Gaussian Population) Rank, Score, or Measurement (from Non- Gaussian Population) Binomial (Two Possible Outcomes) Compare one group to a hypothetical value One-sample t test Wilcoxon test Chi-square or Binomial test Compare two unpaired groups Unpaired t test Mann-Whitney test Fisher's test (chi-square for large samples) Compare two paired groups Paired t test McNemar's test Compare three or more unmatched groups One-way ANOVA Kruskal-Wallis test Chi-square test Compare three or more matched groups Repeated-measures ANOVA Friedman test Cochrane Q Quantify association between two variables Pearson correlation Spearman correlation Contingency coefficients Predict value from another measured variable Simple linear regression or Nonlinear regression Nonparametric regression Simple logistic regression Predict value from several measured or binomial variables Multiple linear regression or Multiple nonlinear regression Multiple logistic regression
 Compare one group to a hypothetical value. One-sample t test. Wilcoxon test. Chi-square or Binomial test. Compare two unpaired groups. Unpaired t test. Mann-Whitney test. Fisher s test (chi-square for large samples) Compare two paired groups. Paired t test. McNemar s test. Compare three or more unmatched groups. One-way ANOVA. Kruskal-Wallis test. Chi-square test. Compare three or more matched groups. Repeated-measures ANOVA. Friedman test. Cochrane Q. Quantify association between two variables. Pearson correlation. Spearman correlation. Contingency coefficients. Predict value from another measured variable. Simple linear regression or Nonlinear regression. Nonparametric regression. Simple logistic regression. Predict value from several measured or binomial variables. Multiple linear regression or Multiple nonlinear regression. Multiple logistic regression.")
22
Alcuni errori statistici
1) Non esecuzione dei test per valutare la normalità del campione. Distrib. Normale: Statistica parametrica Distrib. Non normale : Statistica non parametrica
 Non esecuzione dei test per valutare la normalità del campione. Distrib. Normale: Statistica parametrica. Distrib. Non normale : Statistica non parametrica.")
23
Come si valuta la normalità di una curva
1) Visivamente: costruendo un istogramma di frequenza; 2) Con il test di Kolmogorov-Smirnov nella variante ad un campione (significatività=non normalità); 3) Dividendo la kurtosis e la skewness per i relativi S.E. (significatività=non normalità);
 Visivamente: costruendo un istogramma di frequenza; 2) Con il test di Kolmogorov-Smirnov nella variante ad un campione (significatività=non normalità); 3) Dividendo la kurtosis e la skewness per i relativi S.E. (significatività=non normalità);")
24
Quando i dati sono pochi?
2) Usare la statistica parametrica quando il numero di dati è “scarso”. Quando i dati sono pochi? <=5 : sicuramente sì 6-10 : probabilmente sì
 Usare la statistica parametrica quando il numero di dati è scarso . Quando i dati sono pochi <=5 : sicuramente sì : probabilmente sì.")
25
3) Usare la statistica parametrica in presenza di variabili di tipo ordinale (ad es. gravità di una malattia)
.")
26
4) Utilizzare confronti multipli senza correzioni
Se si cercano differenze fra più di 2 gruppi è indispendabile usare l’ANOVA (e non tanti t di Student). Se l’ANOVA è significativa si può procedere alle procedure per confronti multipli: test di Bonferroni, test di Student-Neuman-Keuls (SNK), MODLSD, test di Scheffe, ecc.
. Se l’ANOVA è significativa si può procedere alle procedure per confronti multipli: test di Bonferroni, test di Student-Neuman-Keuls (SNK), MODLSD, test di Scheffe, ecc.")
27
5) Errori nel Chi quadrato
Considerare le percentuali e non i numeri reali dei casi Usare tale test quando uno dei gruppi è <5 (o peggio uguale a 0) o per essere più precisi: il chi quadro va usato quando non più del 20 % delle frequenze attese può essere < 5 e nessuna cella deve avere una frequenza attesa < 1 . ° In tali casi va usato il test esatto di Fisher.
 o per essere più precisi: il chi quadro va usato quando non più del 20 % delle frequenze attese può essere < 5 e nessuna cella deve avere una frequenza attesa < 1 . ° In tali casi va usato il test esatto di Fisher.")
Presentazioni simili

 e nel verificare se con i dati a disposizione è possibile rifiutarla o no.>")















>")


