Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

2
1.1

4
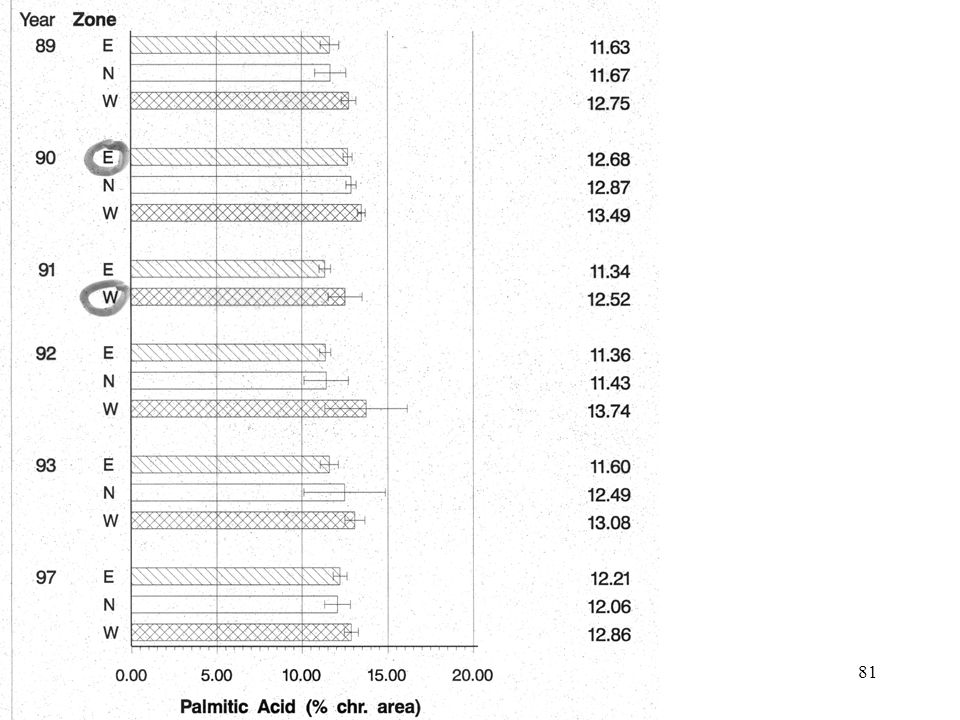
annata

9
Possono essere a loro volta considerate:
variabili dipendenti (contesto ANOVA, MANOVA, etc.) o variabili di risposta (contesto m.d. regressione) o variabili di analisi (contesto m.d. classificazione) (o specifiche di prodotto) (contesto produttivo/economico/S.Q.) Se una fonte di variazione viene definita in termini qualitativi o ordinali, le modalità che la caratterizzano possono prendere il nome di livelli.
 o variabili di risposta (contesto m.d. regressione) o variabili di analisi (contesto m.d. classificazione) (o specifiche di prodotto) (contesto produttivo/economico/S.Q.) Se una fonte di variazione viene definita in termini qualitativi o ordinali, le modalità che la caratterizzano possono prendere il nome di livelli.")
10
1.2

12
Ma è poi assolutamente necessario isolare le variabili ?

13
Talvolta è addirittura impossibile definire con chiarezza e rigore
NO Talvolta è addirittura impossibile L’importante è definire con chiarezza e rigore l’oggetto di studio anche nel quadro di un approccio meno atomistico e più sistemico al problema e pianificare di conseguenza il campionamento

14
Esempio di un tentativo ...
(Alessandri, S.; 2000; "Qualita' e variabilita' degli oli vergini di oliva della Toscana e modelli di classificazione: una discussione metodologica"; Bollettino dei Chimici Igienisti parte scientifica, Vol. 52 1S/2001, pp31-44.)
")
15
1.3 Io era tra color che son sospesi, e donna mi chiamò beata e bella,
tal che di comandare io la richiesi.

16
E’ qui che il pensiero razionale si perde facilmente

22
1.4

23
E’ necessario che un parametro di dispersione divenga unità di misura nella scala delle posizioni, e quindi unità di misura della distanza-diversità. Particolarmente conveniente risulta essere la varianza

24
Se consideriamo che la differenza (distanza, diversità) tra medie può essere misurata a sua volta come dispersione delle medie stesse attorno alla media delle medie, e quindi associata ad una varianza, allora possiamo interpretare la differenza tra medie come rapporto tra varianze: Varianza tra i gruppi / Varianza entro i gruppi

25
1.5 m u l t i v a r i a t o

26
L'informazione multivariata delle informazioni univariate
Numerosità , dispersioni posizioni uguali, struttura interna (co-dispersione) diversa L'informazione multivariata è maggiore della somma delle informazioni univariate singolarmente prese
 diversa. L informazione multivariata. è maggiore della somma. delle informazioni univariate. singolarmente prese.")
27
L'informazione multivariata può rivelare
una direzione preferenziale lungo la quale la dispersione (separazione) delle osservazioni è maggiore di quella lungo le direzioni delle variabili considerate separatamente, direzioni coincidenti con quelle degli assi del sistema di riferimento.
 delle osservazioni. è maggiore di quella lungo le direzioni delle. variabili considerate separatamente, direzioni. coincidenti con quelle degli assi del sistema. di riferimento.")
28
dei gruppi di osservazioni
L'informazione multivariata può rivelare una direzione preferenziale lungo la quale la dispersione (separazione) dei gruppi di osservazioni è maggiore di quella lungo le direzioni delle variabili considerate separatamente, direzioni coincidenti con quelle degli assi del sistema di riferimento.
 dei gruppi di osservazioni. è maggiore di quella lungo le direzioni delle. variabili considerate separatamente, direzioni. coincidenti con quelle degli assi del sistema di riferimento.")
29
1.6

34
ANOVA

35
Stime per intervalli, prova delle ipotesi e concetto di significatività
costituiscono gli strumenti per formulare ed affrontare un (il?) problema di fondo: Qual’é la probabilità di ottenere: questo risultato (campionario) questo/i insieme/i di risultati (campionari) questa/e configurazione/i di risultati (campionari) questa/e relazione/i tra risultati (campionari) questa/e variazione/i nei risultati (campionari) … per puro caso ? E’ sempre qui che il pensiero razionale si perde facilmente
 problema di fondo: Qual’é la probabilità di ottenere: questo risultato (campionario) questo/i insieme/i di risultati (campionari) questa/e configurazione/i di risultati (campionari) questa/e relazione/i tra risultati (campionari) questa/e variazione/i nei risultati (campionari) … per puro caso E’ sempre qui che il pensiero razionale si perde facilmente.")
36
Stime per intervalli, prova delle ipotesi e concetto di significatività
costituiscono gli strumenti per stimare e valutare la diversità-distanza fra popolazioni partendo dalle corrispondenti statistiche campionarie. (Per i problemi di classificazione sono necessari ANCHE altri strumenti di validazione, per incrementare la rappresentatività )
")
37
critico La numerosità campionaria gioca sempre un ruolo
per la rappresentatività

38
Anche questo è un problema di rappresentatività
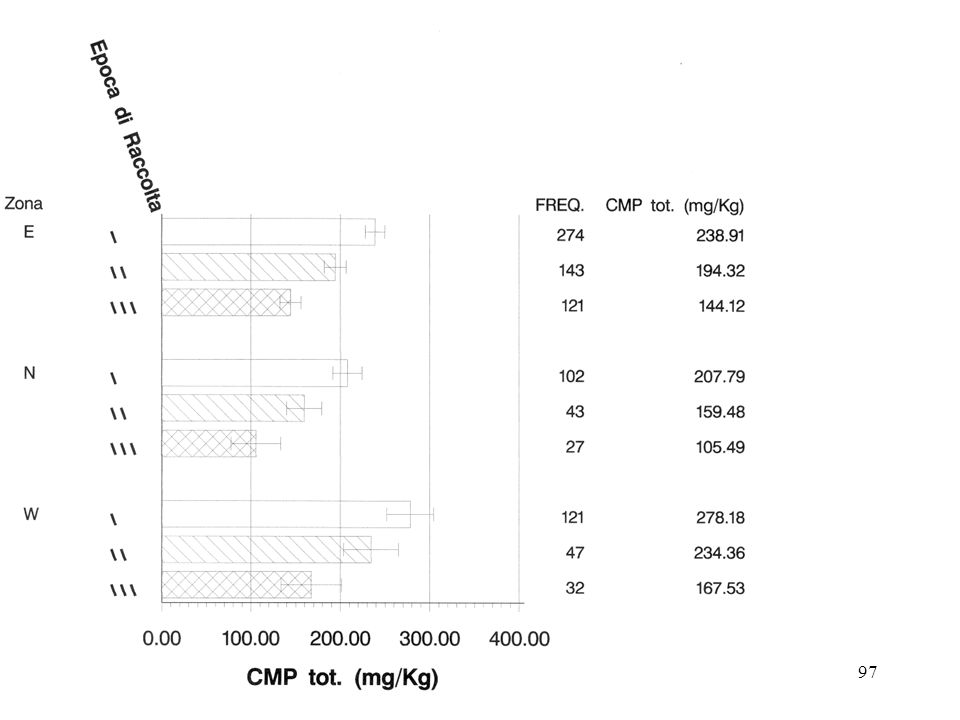
INOLTRE: il “sapere” metodologico maturato in campo agronomico da Fisher in poi, per quanto riguarda in particolare le produzioni agrarie, ed in special modo quelle da colture arboree, fornisce gli strumenti per impostare ed affrontare un problema specifico: Qual’é l’incidenza della variabilità annuale su: questo risultato questo/i insieme/i di risultati questa/e configurazione/i di risultati questa/e relazione/i tra risultati questa/e variazione/i nei risultati … ? Anche questo è un problema di rappresentatività In altri termini, fino a che punto E’ possibile trascurare o “accorpare” l’ ”effetto-anno” ?

39
1.7

40
La “numerosità” delle variabili di analisi gioca anch’essa un ruolo
critico E’ un argomento molto discusso, che presenta aspetti estremamente contraddittori sintetizzati da espressioni molto suggestive ... per la rappresentatività per la computabilità per la possibilità stessa di fare inferenze nel senso della statistica classica per la predittività

41
The blessings of Dimensionality
Tecniche di data analisys applicate a problemi di riconoscimento, basate su “poche” osservazioni descritte da moltissime variabili E’un fatto che le tecniche di data analisys: hanno molto successo aumentano i loro campi di applicazione The curses of Dimensionality Intrattabilità di stime ed inferenze davanti alla proliferazione delle variabili di analisi

42
2.1

44
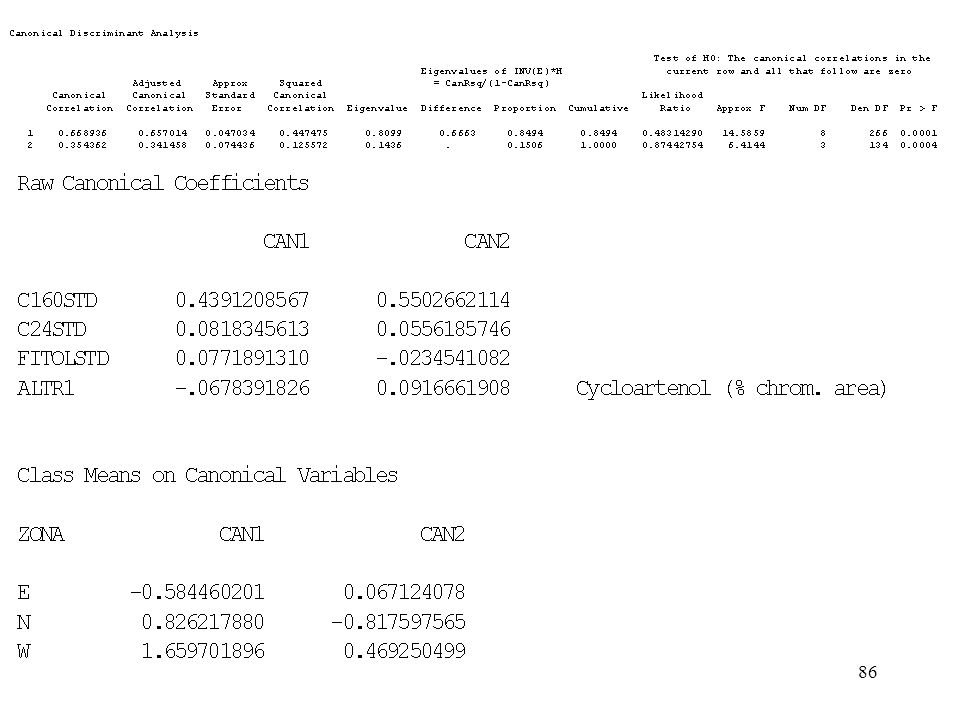
Analisi Discriminante
Uno strumento importante per il calcolo di modelli di classificazione è costituito da un insieme di tecniche statistiche genericamente denominate Analisi Discriminante Il termine non ha lo stesso univoco significato per tutti gli autori.

45
L' Analisi Discriminante tratta insiemi di osservazioni in cui:
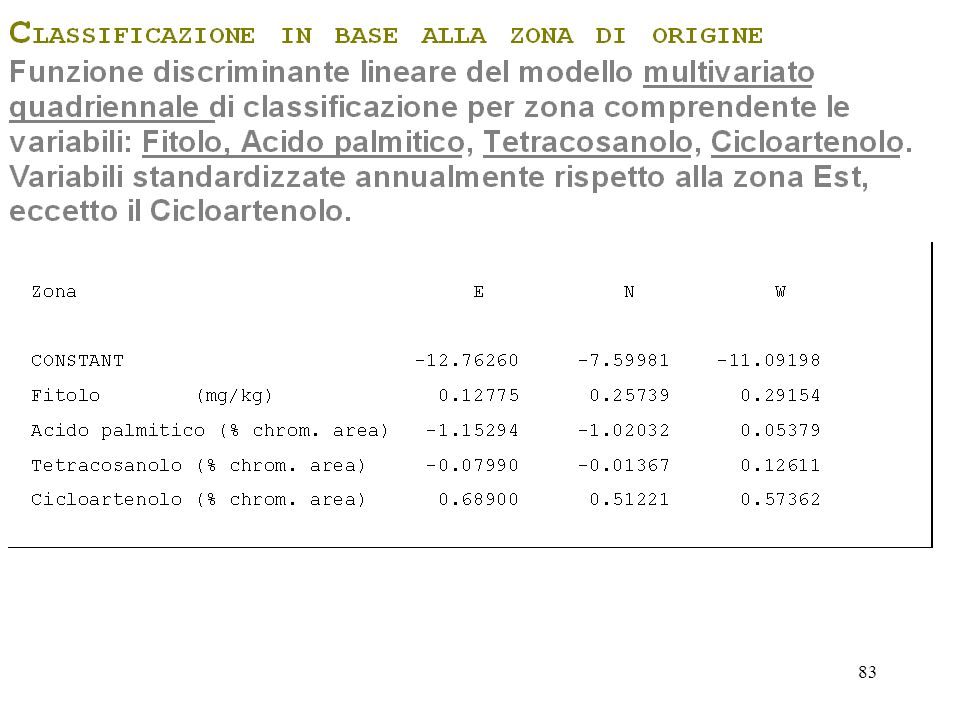
-sono definiti dei gruppi o classi -sono definite una o piu' variabili quantitative Si distinguono almeno tre tipologie di Analisi Discriminante: l'Analisi Discriminante classificatoria orientata alla produzione di modelli di classificazione, l'Analisi Discriminante Canonica l'Analisi Discriminante Step-Wise orientate alla preventiva riduzione della dimensionalità dei modelli. Hand, (1981); Lachenbruch e collaboratori (1968); Lachenbruch (1975); Seber (1984),
; Lachenbruch e collaboratori (1968); Lachenbruch (1975); Seber (1984),")
46
con la minima possibilità di errore.
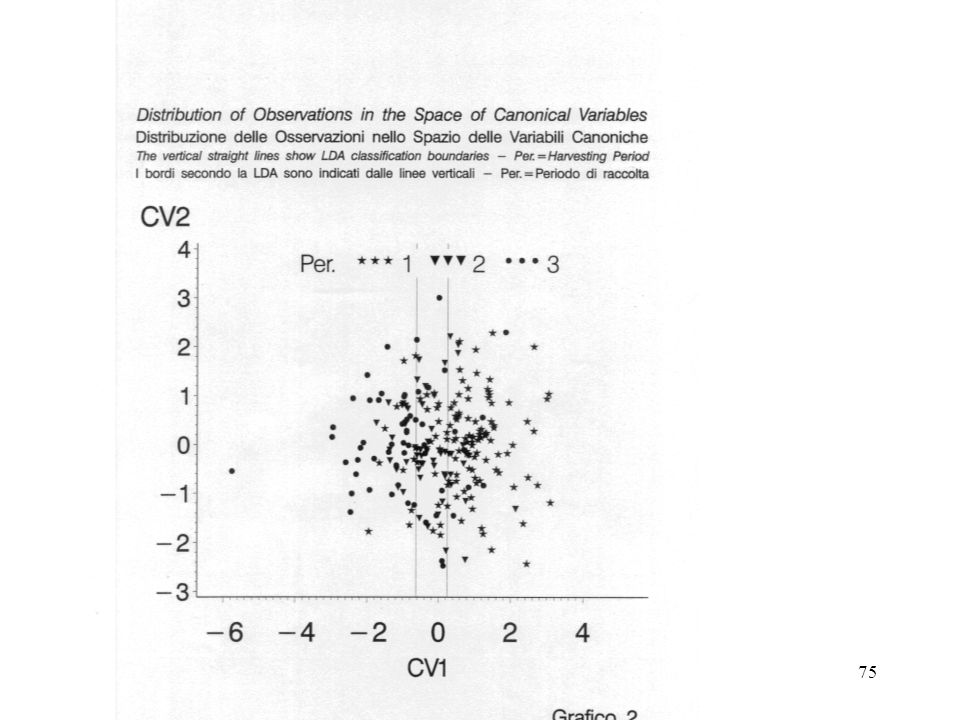
L' analisi discriminante classificatoria (da ora in avanti "Analisi Discriminante") sviluppa una regola matematica (funzione discriminante), basata sulle (funzione delle) variabili quantitative prese in considerazione, che permette di attribuire un'osservazione ad una delle classi (restituisce una probabilità di attribuzione per ciascuna classe), con la minima possibilità di errore.
 sviluppa una regola matematica (funzione discriminante), basata sulle (funzione delle) variabili quantitative prese in considerazione, che permette di attribuire un osservazione ad una delle classi (restituisce una probabilità di attribuzione per ciascuna classe), con la minima possibilità di errore.")
47
L' analisi discriminante classificatoria
Si articola in numerosi metodi, parametrici e non: funzione discriminante lineare => LDA, da Linear Discriminant Analysis funzione discriminante quadratica => QDA, da Quadratic Discriminant Analysis non sono necessarie assunzioni circa l'omogeneità delle matrici di covarianze entro le classi metodi non parametrici => (kernel, KNN, …) non sono necessarie assunzioni circa la normalita' delle distribuzioni entro le classi.
 non sono necessarie assunzioni circa la normalita delle distribuzioni entro le classi.")
48
Analisi discriminante canonica
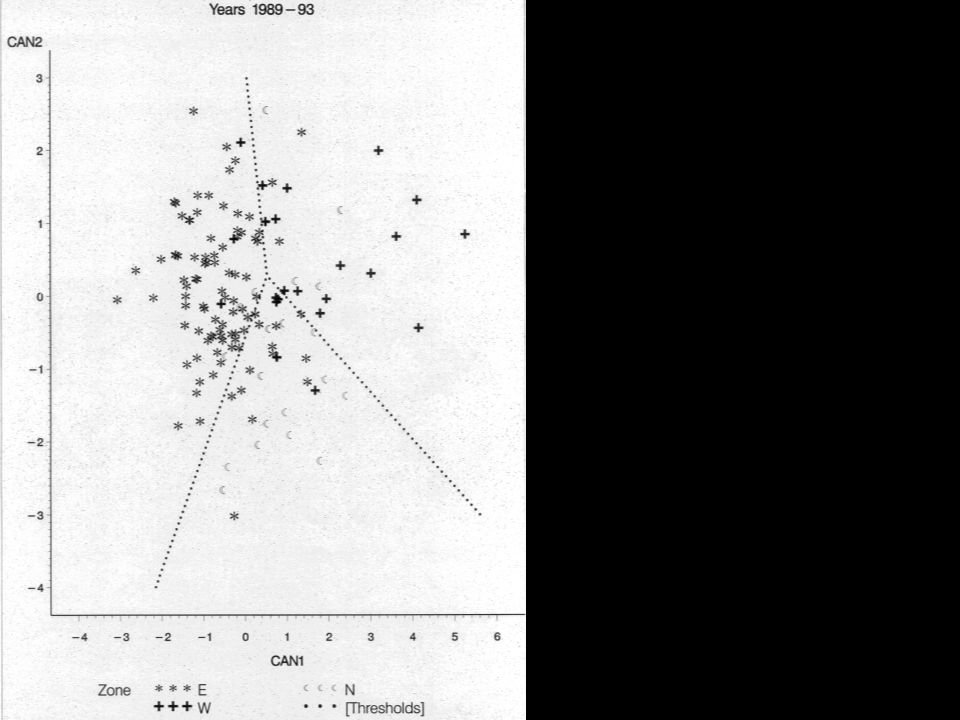
(CDA, da Canonical Discriminant Analysis ") Obiettivi: determinare le combinazioni lineari (definite Variabili Canoniche, Canonical variables, Canonical variates) delle variabili quantitative considerate, che meglio sintetizzano la variabilità tra le classi selezionare un insieme di poche variabili canoniche, che possano vantaggiosamente sostituire, ai fini della classificazione dei dati, le molte (relativamente a quelle canoniche) variabili quantitative di partenza; Le variabili canoniche hanno la caratteristica di essere tra loro incorrelate. Klecka (1980); Seber (1984).
 Obiettivi: determinare le combinazioni lineari (definite Variabili Canoniche, Canonical variables, Canonical variates) delle variabili quantitative considerate, che meglio sintetizzano la variabilità tra le classi. selezionare un insieme di poche variabili canoniche, che possano vantaggiosamente sostituire, ai fini della classificazione dei dati, le molte (relativamente a quelle canoniche) variabili quantitative di partenza; Le variabili canoniche hanno la caratteristica di essere tra loro incorrelate. Klecka (1980); Seber (1984).")
49
Analisi discriminante step-wise
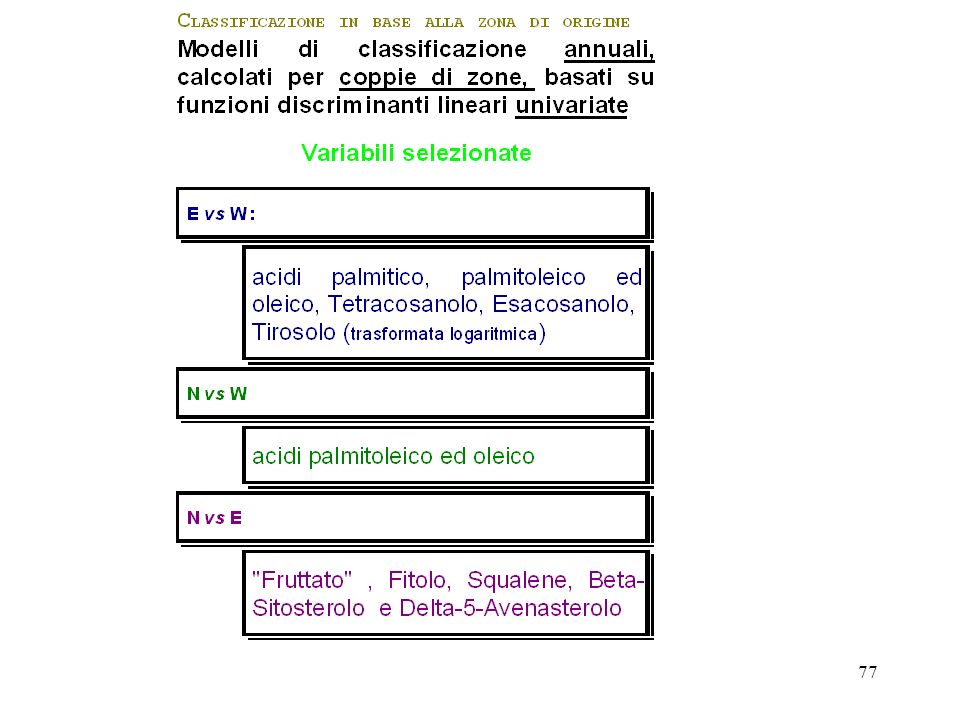
Obiettivi: determinare le variabili quantitative più efficaci per una corretta classificazione delle osservazioni selezionare un insieme di poche variabili (originali non canoniche), che possano vantaggiosamente sostituire, ai fini della classificazione dei dati, le molte variabili quantitative di partenza L'analisi discriminante step-wise persegue direttamente questo obiettivo con eliminazioni e/o immissioni progressive (passo-passo) di una variabile alla volta nel modello, per mezzo di diversi possibili criteri di valutazione. I metodi step-wise NON garantiscono LA selezione della combinazione OTTIMALE di variabili originali in senso assoluto, ma solamente in senso relativo.
, che possano vantaggiosamente sostituire, ai fini della classificazione dei dati, le molte variabili quantitative di partenza. L analisi discriminante step-wise persegue direttamente questo obiettivo con eliminazioni e/o immissioni progressive (passo-passo) di una variabile alla volta nel modello, per mezzo di diversi possibili criteri di valutazione. I metodi step-wise NON garantiscono LA selezione della combinazione OTTIMALE di variabili originali in senso assoluto, ma solamente in senso relativo.")
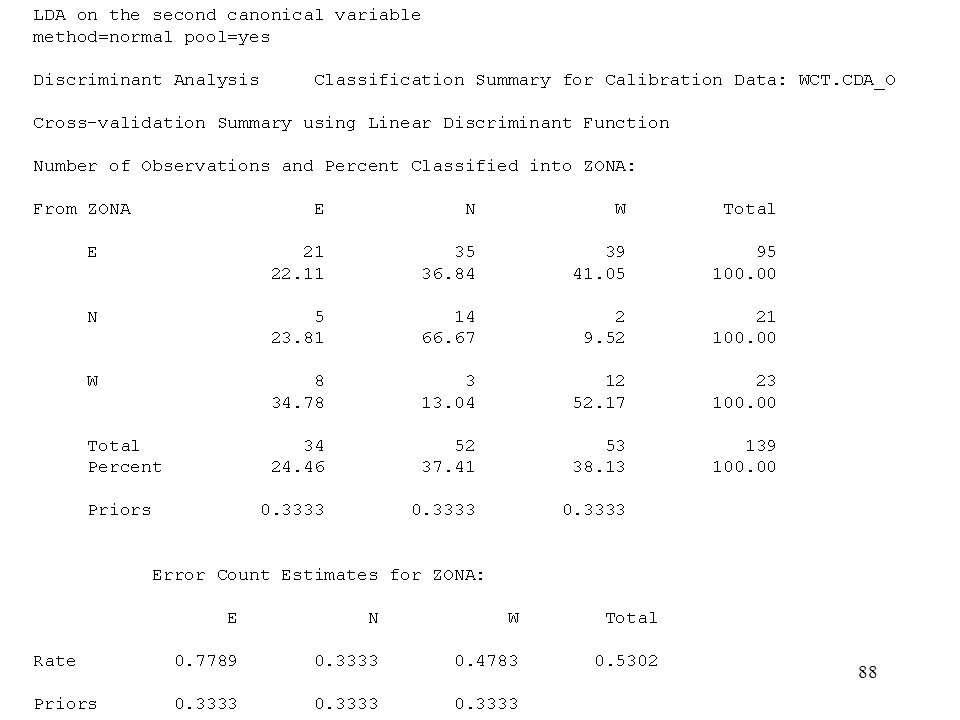
51
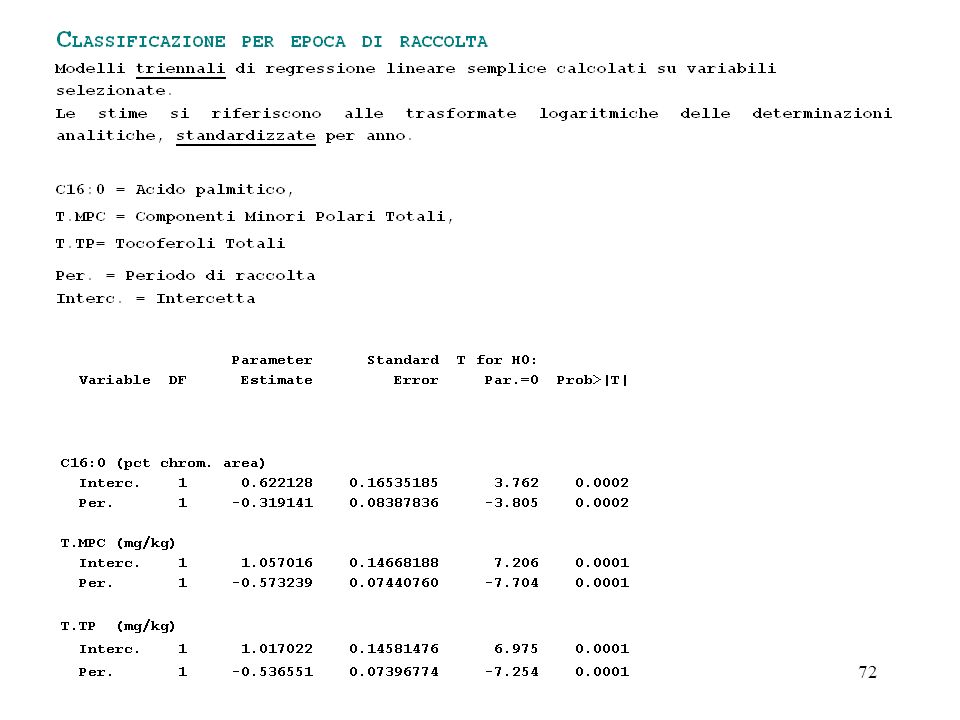
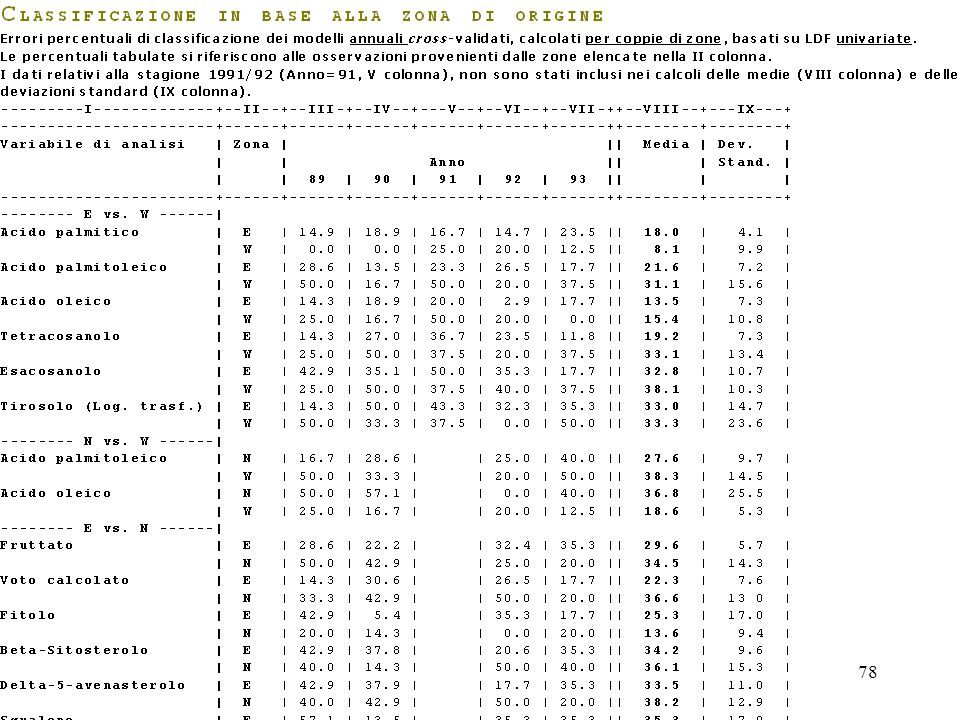
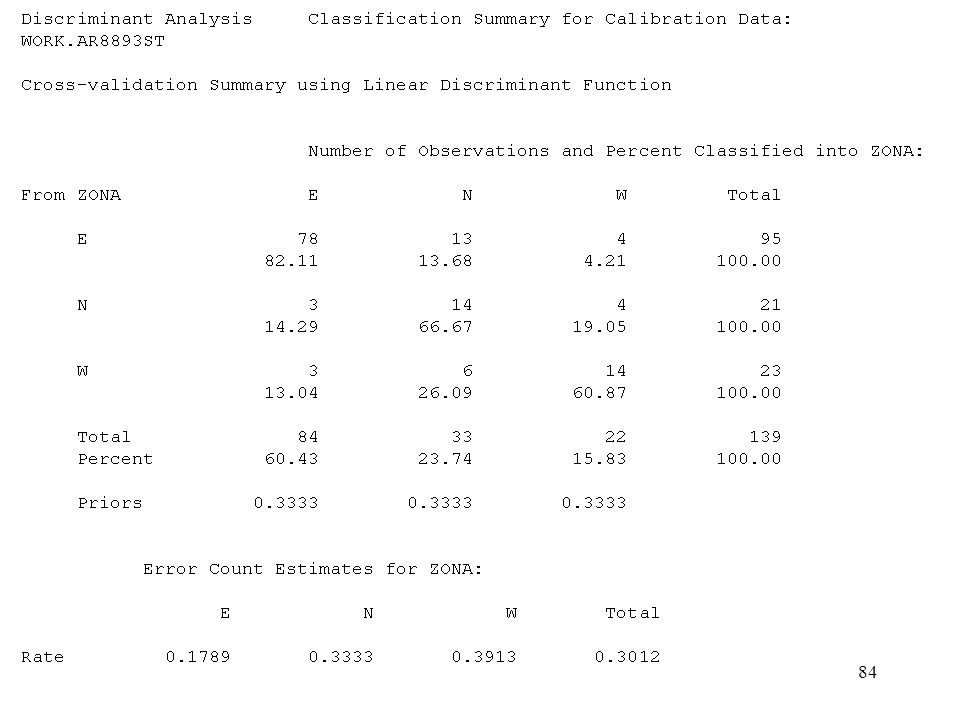
La crossvalidazione (metodo "Leaving-one-out") e' un procedimento che consiste nel classificare ogni osservazione (di un collettivo di numerosita' n), in base al criterio discriminante tratto dalle altre (n-1) osservazioni. Richiede quindi che la funzione discriminante sia ricalcolata tante volte quante sono le osservazioni stesse. La crossvalidazione leaving-one-out evita l'insorgere di errori di attribuzione artificiosamente bassi, che non cosituiscono una buona stima del reale potere discriminatorio del modello.

54
Cenni a tecniche diverse e/o ausiliarie
Modelli di classificazione Cenni a tecniche diverse e/o ausiliarie Analisi delle Componenti Principali Analisi dei Cluster

55
Componenti Principali
Descrivono in maniera ottimale la variabilita' totale del collettivo in osservazione: la prima PC estratta e' pensabile come la retta meglio adattata allo scatter delle osservazioni nello spazio n-dimensionale delle variabili di analisi considerate, la seconda come quella meglio adattata alla variabilita' residua, e cosi' via.

56
esplorare le relazioni tra variabili e tra osservazioni
Analisi delle Componenti Principali Scopi esplorare le relazioni tra variabili e tra osservazioni isolare l'informazione utile alla separazione delle osservazioni dal "rumore", all'interno di un gruppo di variabili (tra le quali non viene fatta alcuna suddivisione fra dipendenti ed indipendenti) selezionare un piccolo gruppo di combinazioni lineari (Componenti Principali) da un insieme di variabili (quantitative) di partenza identificare gli "outliers"
 selezionare un piccolo gruppo di combinazioni lineari (Componenti Principali) da un insieme di variabili (quantitative) di partenza. identificare gli outliers")
57
Sulle componenti principali e' poi possibile applicare qualunque analisi statistica appropriata:
operare analisi dei cluster determinare modelli di regressione calcolare modelli di classificazione Le Componenti Principali a differenza delle variabili canoniche, definiscono un sistema di riferimento che massimizza la separazione media tra le singole osservazioni, NON necessariamente tra le classi.

58
Analisi dei Cluster (parametriche e non parametriche)
scopi: esplorare le relazioni tra osservazioni stabilire se e' possibile riconoscere dei raggruppamenti (cluster) in un certo insieme di osservazioni in cui non è nota né definita a priori alcuna classe o gruppo individuare i raggruppamenti stessi in termini di rapporti reciproci (gerarchie, sovrapposizioni, distanze, …) descriverli statisticamente L’ analisi dei cluster può venire utilizzata per “riscoprire” dei raggruppamenti noti a priori, o per scoprirne di nuovi, magari rivelati dall’analisi di errori di classificazione.
 in un certo insieme di osservazioni in cui non è nota né definita a priori alcuna classe o gruppo. individuare i raggruppamenti stessi in termini di rapporti reciproci (gerarchie, sovrapposizioni, distanze, …) descriverli statisticamente. L’ analisi dei cluster può venire utilizzata per riscoprire dei raggruppamenti noti a priori, o per scoprirne di nuovi, magari rivelati dall’analisi di errori di classificazione.")
59
3.1

91
3.2

Presentazioni simili





























































>")











