Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Coefficienti di inbreeding per alcune popolazioni umane Canada cattolico 0.00004 - 0.0007 Stati Uniti Cattolici 0 - 0.0008 Hutterites 0.02 Dunkers 0.03 America latina 0 - 0.003 Europa meridionale 0.001 - 0.002 Giappone 0.005 Samaritani 0.04

4
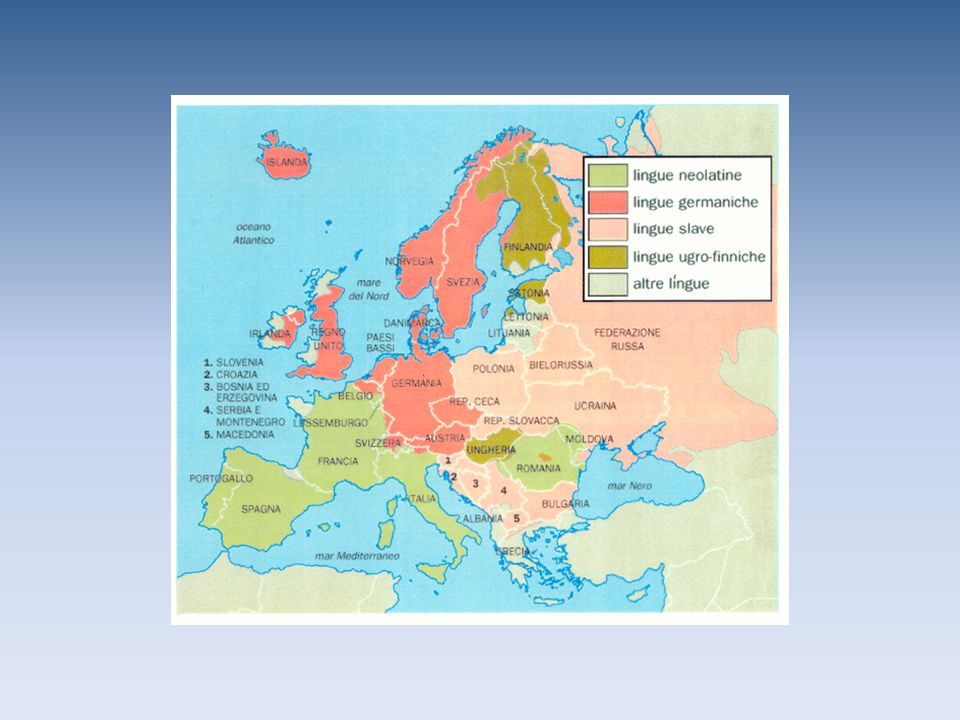
Lingue di ceppo Indo-Europeo

5
Lingue di ceppo non Indo-Europeo

6
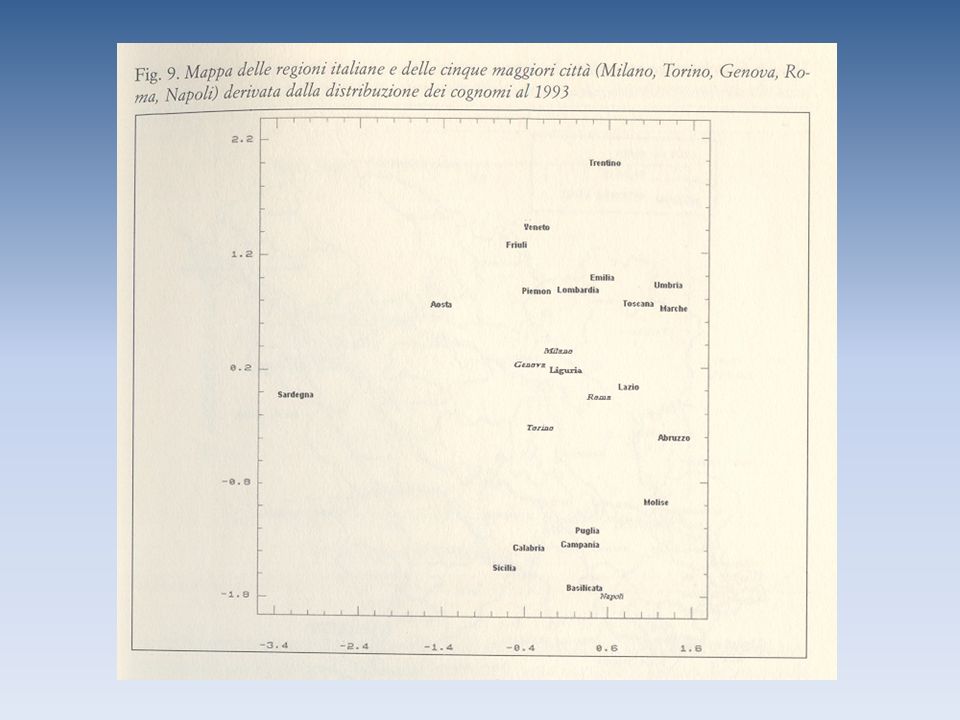
L’uso dei cognomi in studi biodemografici Definizione Il cognome può essere interpretato come un gene dotato di un elevato grado di polimorfismo posto sul cromosoma Y. Tale localizzazione è in funzione delle modalità di trasmissione ereditaria, che avviene, per la stragrande maggioranza delle popolazioni, per via patrilineare. Il cognome viene quindi utilizzato tipicamente per studi biodemografici e di genetica di popolazione, quali analisi di similarità e distanza evolutiva tra popolazioni, migrazioni, isolamento, mating choice e consanguineità. Vantaggi Rispetto alle normali analisi genetiche, i dati sui cognomi sono di facile reperibilità, possono riguardare l’intera popolazione e non solo campioni di essa. Svantaggi Per queste analisi i cognomi sono supposti di origine monofiletica, mentre in realtà essa è di natura polifiletica.

7
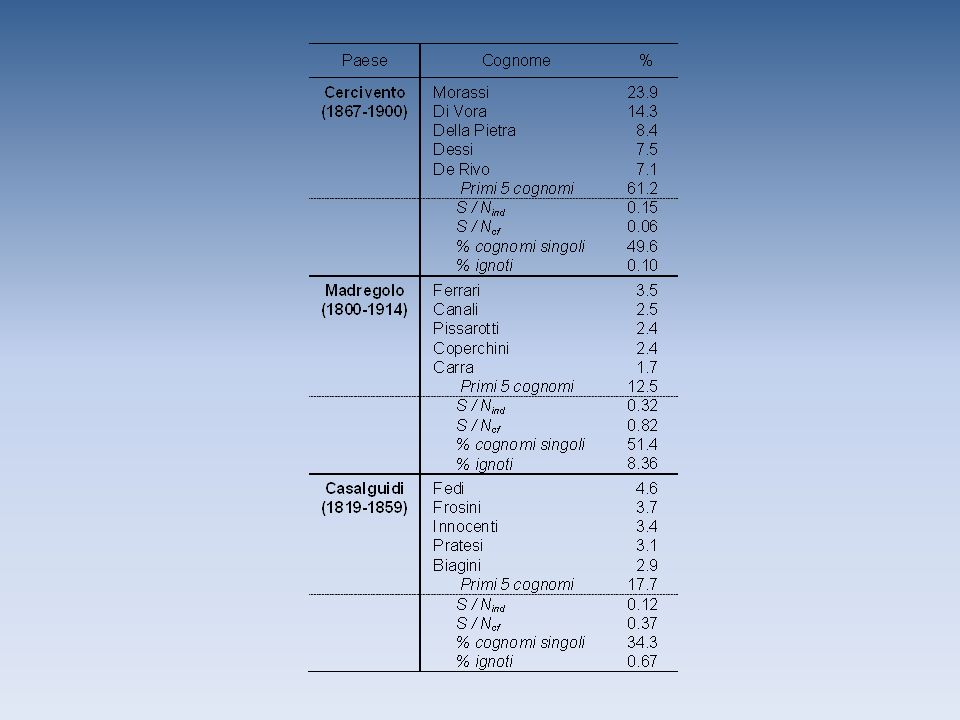
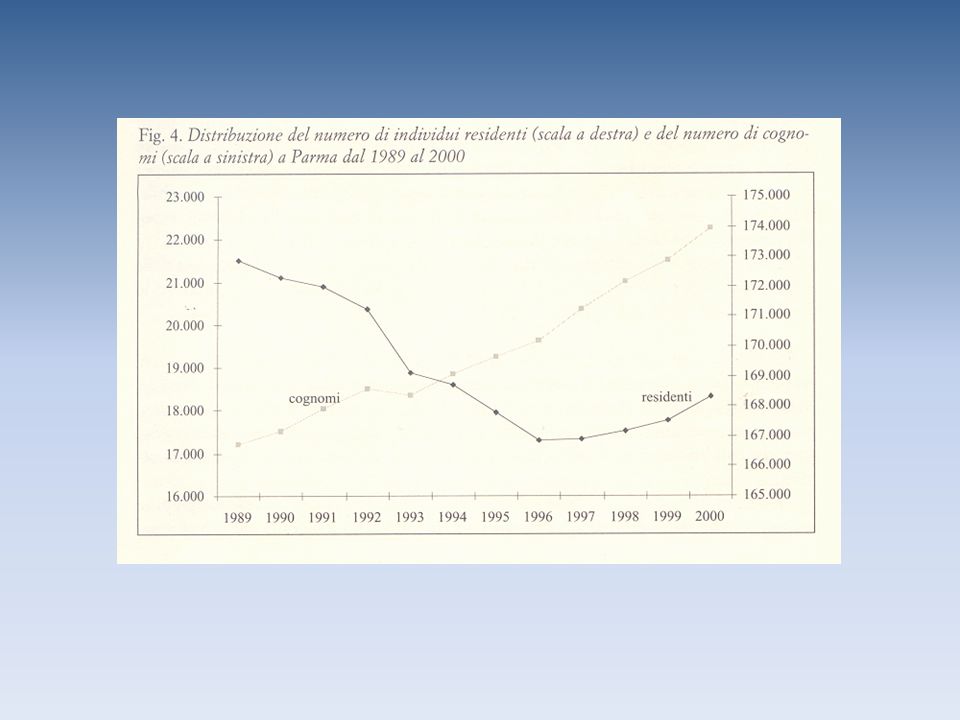
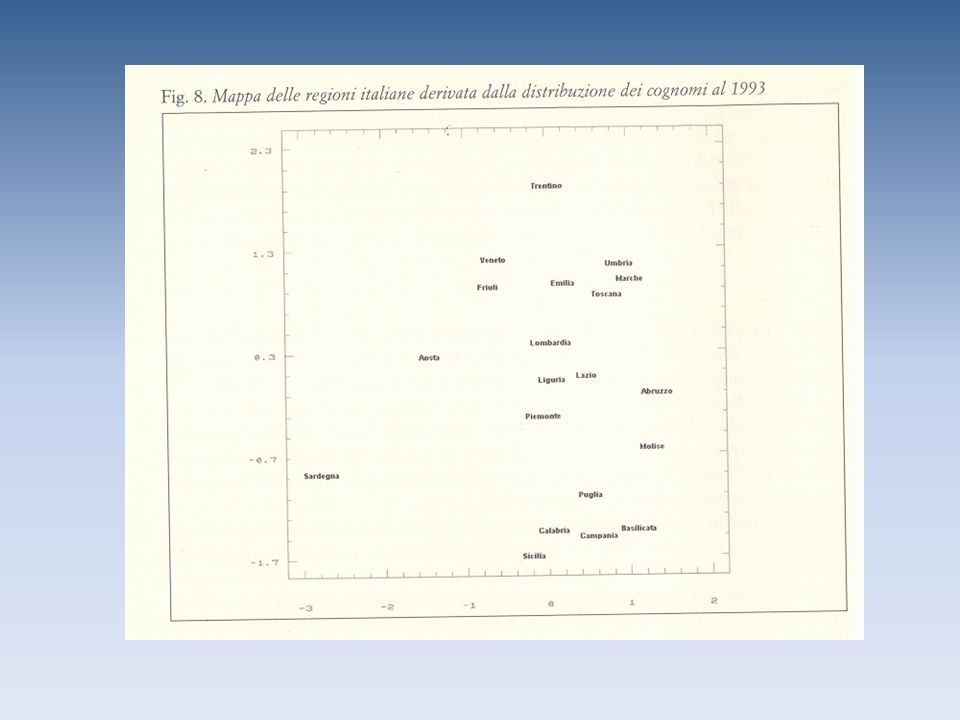
L’analisi di partenza Il primo approccio all’utilizzo dei cognomi ha riguardato lo studio della variabilità interna di una popolazione. Tale analisi è stata effettuata mediante il rapporto S/N, dove S indica il numero di forme cognominali esistenti nella popolazione esaminata, e N il numero di individui in essa presenti. Tanto più il rapporto è elevato tanto maggiore è la variabilità interna della popolazione.

9
Alcune metodiche Relazione tra consanguineità ed isonimia (Crow & Mange, 1965) F = I / 4 Metodo delle coppie ripetute (Lasker & Kaplan, 1985) Indici di similarità in cognomi (Lasker, 1977)
 F = I / 4 Metodo delle coppie ripetute (Lasker & Kaplan, 1985) Indici di similarità in cognomi (Lasker, 1977)")
Presentazioni simili








 IL CAMPIONE CASUALE SEMPLICE CON RIPETIZIONE>")









>")


