Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Scheduling in GrADS Il progetto GrADS (Grid Application Development Software) ha lo scopo di semplificare lo sviluppo di unapplicazione Grid. Tra le funzionalità considerate sono comprese quelle per lo scheduling. Lo scheduling si basa su tre possibili approcci: sviluppo di uno scheduling iniziale (launch-time); modifica dello scheduling durante lesecuzione (rescheduling); negoziazione tra le applicazioni (meta-scheduling). Il progetto parte da unanalisi dei requisiti delle applicazioni e propone delle soluzioni software mirate a soddisfare tali requisiti.
; modifica dello scheduling durante lesecuzione (rescheduling); negoziazione tra le applicazioni (meta-scheduling). Il progetto parte da unanalisi dei requisiti delle applicazioni e propone delle soluzioni software mirate a soddisfare tali requisiti..")
2
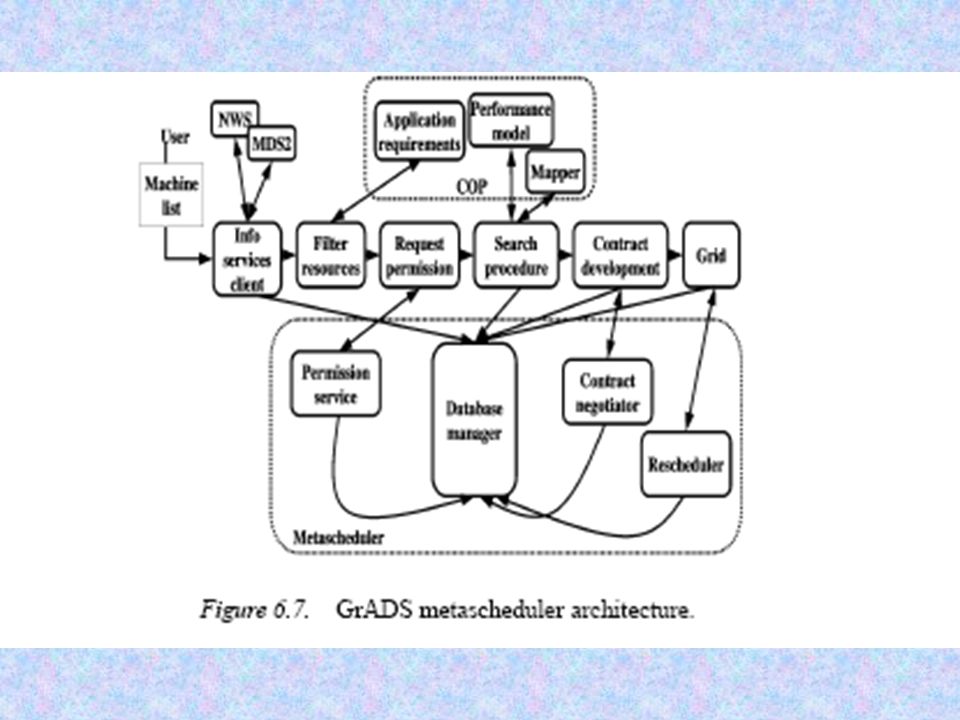
Struttura generale di Grads

3
Launch Time scheduler in Grads Il COP dovrebbe essere generato automaticamente dal compilatore

4
COP - Application requirement specifications Descrizione di application requirements attraverso il linguaggio ClassAds per un programma parallelo iterativo che utilizza MPICH-G2

5
COP - Performance modeling Prende in input una schedulazione proposta, le informazioni sulla Grid e fornisce la stima del tempo di escuzione per la schedulazione prevista. Lapproccio più consolidato si basa su: –Sviluppo di un modello analitico di performance per gli aspetti ben identificati di un applicazione sistema (ad esempio il tempo di esecuzione); –Test del modello analitico tramite esperimenti; –Sviluppo di un modello empirico per gli aspetti meno definibili del comportamento del sistema (ad esempio loverhead dovuto al middleware) In alcuni casi il modello analitico può non bastare (vedi scalapack) per descrivere la computazione modello di simulazione I modelli di performance sono implementati come shared library
; –Test del modello analitico tramite esperimenti; –Sviluppo di un modello empirico per gli aspetti meno definibili del comportamento del sistema (ad esempio loverhead dovuto al middleware) In alcuni casi il modello analitico può non bastare (vedi scalapack) per descrivere la computazione modello di simulazione I modelli di performance sono implementati come shared library.")
6
COP - Mapper Il mapper prende in input una lista di macchine e informazioni sul Grid e produce un mapping dei processi applicativi alle macchine e e unallocazione dei dati ai processi. In alcuni casi lutente può cooperare ad esempio fornendo un ordinamento tra le macchine. In altri casi lapplicazione sceglie il mapping internamente (ad esempio Scalapack). In questi casi il mapper non è usato.
. In questi casi il mapper non è usato..")
7
COP - Mapper Le strategie utilizzate comprendono: –Equal allocation: alloca i dati in modo uniforme sulle diverse macchine. E la strategia più elementare. –Time balancing: cerca di allocare i dati in modo tale che la computazione termini il più possibile allo stesso tempo sui nodi. Molte applicazioni sono limitate dal nodo più lento: questo è molto importante per le applicazioni iterative. Il problema è spesso formulato come un problema di ottimizzazione con vincoli e risolto attraverso metodi di programmazione lineare. –Data locality: in alcuni casi il vincolo è sulla località dei dati (ad esempio search su database); anche in questo caso usa la programmazione lineare.
; anche in questo caso usa la programmazione lineare..")
8
Search Procedure La procedura di ricerca si basa su criteri generali e non su ipotesi relative allapplicazione per poter essere utilizzata in diverse situazioni Questa scelta può avere degli effetti negativi sulle performance ottenute Sono proposti diversi approcci per la ricerca delle risorse in ogni caso i passi fondamentali sono: –Identificazione di un grande numero di insiemi di risorse che potrebbero essere adeguate allapplicazione; –Utilizzo del mapper e del performance model specifici per lapplicazione per avere una previsione dei tempi di esecuzione per gli insiemi di risorse considerati; –Scelta dellinsieme per cui è previsto il tempo di esecuzione minore. Problema della schedulazione per il tempo minimo su un multiprocessore è NP-hard obiettivo avere un basso overhead

9
Resource aware search Si basa sulla constatazione che esistono caratteristiche delle risorse utili a tutte le applicazioni: velocità del processore, memoria disponibile (intese come risorse individuali),banda di comunicazione (intesa come risorsa del gruppo) CGM= Candidate Group Machine
,banda di comunicazione (intesa come risorsa del gruppo) CGM= Candidate Group Machine")
10
Resource aware scheduling Lobiettivo è quello di selezionare gruppi di macchine candidate (CGM) e valutarli; Le macchine sono divise in sottoinsiemi disgiunti o sites (usando ad esempio il dominio criterio generale low latency connection)- metodo FindSites; Il metodo ComputeSiteCollections calcola il power set per linsieme dei sites (2 s elementi con s = numero di siti) I tre cicli in cascata raffinano la ricerca in base a: –Connessione (esterno); –Velocità del processore, capacità di memoria e combinazione delle due delle macchine individuali (intermedio); –Taglia dellinsieme di risorse (interno) La funzione SortDescending ordina la collection consideratain base alla machineMetric (ad esempio dual)
 e valutarli; Le macchine sono divise in sottoinsiemi disgiunti o sites (usando ad esempio il dominio criterio generale low latency connection)- metodo FindSites; Il metodo ComputeSiteCollections calcola il power set per linsieme dei sites (2 s elementi con s = numero di siti) I tre cicli in cascata raffinano la ricerca in base a: –Connessione (esterno); –Velocità del processore, capacità di memoria e combinazione delle due delle macchine individuali (intermedio); –Taglia dellinsieme di risorse (interno) La funzione SortDescending ordina la collection consideratain base alla machineMetric (ad esempio dual)")
11
Resource aware scheduling GetFirstN ritorna le prime r macchine della lista ordinata ( list ) Per valutare ogni CGM il metodo GenerateSchedule utilizza: –Il mapper per produrre un mapping dei dati sul CGM; –Il performance model per fornire una stima del tempo di esecuzione ( predtime ) –Produce una struttura (currSched) che contiene il CGM, il mapping ed il tempo previsto Il tempo di esecuzione è utilizzato per selezionare il best schedule La complessità di una ricerca esaustiva è di 2 p con p = numero di processori, in questo caso la complessità è 3p*2 s con s = numero di siti ( s<<p )
 Per valutare ogni CGM il metodo GenerateSchedule utilizza: –Il mapper per produrre un mapping dei dati sul CGM; –Il performance model per fornire una stima del tempo di esecuzione ( predtime ) –Produce una struttura (currSched) che contiene il CGM, il mapping ed il tempo previsto Il tempo di esecuzione è utilizzato per selezionare il best schedule La complessità di una ricerca esaustiva è di 2 p con p = numero di processori, in questo caso la complessità è 3p*2 s con s = numero di siti ( s<<p )")
12
Simulated annealing (vedi wikepedia) Questa strategia non utilizza, in prima istanza, alcuna preferenza indicata dallapplicazione per la selezione delle risorse ( nel caso precedente connessione). Si basa su un algoritmo di carattere generale che affronta un problema di ottimizzazione globale su uno spazio di ricerca (search space) e attraverso un approccio probabilistico individua una buona approssimazione della soluzione ottima.
 e attraverso un approccio probabilistico individua una buona approssimazione della soluzione ottima..")
13
Simulated annealing Lalgoritmo generale è derivato dallosservazione del processo di riscaldamento e progressivo raffreddamento utilizzato per trattare alcuni materiali ed ottenere cristalli con configurazioni migliori (annealing). Il riscaldamento sblocca gli atomi dalla loro posizione iniziale (di minimo locale rispetto allenergia interna) e permette loro di muoversi a caso attraverso stati con energia maggiore; il processo di lento raffreddamento permette agli atomi di disporsi in configurazioni con energia interna minore rispetto a quella iniziale La funzione da ottimizzare è lenergia interna del sistema; ogni punto dello spazio di ricerca definisce lo stato del sistema; da un punto ci si sposta verso un vicino in modo da ridurre lenergia interna. Lenergia può aumentare per evitare di scegliere un minimo locale. Il procedimento è ripetuto fino ad ottenere un risultato accettato, o fino ad un numero di iterazioni prefissato.
 e permette loro di muoversi a caso attraverso stati con energia maggiore; il processo di lento raffreddamento permette agli atomi di disporsi in configurazioni con energia interna minore rispetto a quella iniziale La funzione da ottimizzare è lenergia interna del sistema; ogni punto dello spazio di ricerca definisce lo stato del sistema; da un punto ci si sposta verso un vicino in modo da ridurre lenergia interna. Lenergia può aumentare per evitare di scegliere un minimo locale. Il procedimento è ripetuto fino ad ottenere un risultato accettato, o fino ad un numero di iterazioni prefissato..")
14
Simulated annealing –s := s0 e := E(s) k := 0 while k emax sn := neighbour(s) en := E(sn) if en < e or random() < P(en - e, temp(k/kmax)) then s := sn; e := en k := k + 1 return s Il valore della funzione di probabilità P determina la transizione al nuovo stato in modo da evitare la scelta di minimi locali (possibilità di passare ad uno stato con energia più alta), ma garantendo che quando lenergia è abbastanza bassa vengono scelti preferibilmente valori minori (downhill)
 k := 0 while k emax sn := neighbour(s) en := E(sn) if en < e or random() < P(en - e, temp(k/kmax)) then s := sn; e := en k := k + 1 return s Il valore della funzione di probabilità P determina la transizione al nuovo stato in modo da evitare la scelta di minimi locali (possibilità di passare ad uno stato con energia più alta), ma garantendo che quando lenergia è abbastanza bassa vengono scelti preferibilmente valori minori (downhill)")
15
Simulated annealing Nella formulazione originale del metodo (Kirkpatrick et. al, 1983) la probabilità P(δE, T) è definita come 1 se δE < 0 (i.e., downhill moves were always performed); altrimenti la probabilità è Questa formula deriva dallalgoritmo Metropolis- Hastings, utilizzato per generare campioni dalla distribuzione Maxwell-Boltzmann che governa la distribuzione dellenergia delle molecole in un gas.
 la probabilità P(δE, T) è definita come 1 se δE < 0 (i.e., downhill moves were always performed); altrimenti la probabilità è Questa formula deriva dallalgoritmo Metropolis- Hastings, utilizzato per generare campioni dalla distribuzione Maxwell-Boltzmann che governa la distribuzione dellenergia delle molecole in un gas..")
17
Simulated annealing search In questo caso la ricerca tramite SA viene effettuata per tutte le possibile taglie di risorse (da 1 allintero set). Fissata una taglia r viene creata una lista di macchine che soddisfano i requisiti di memoria. Viene quindi creato un CGM (stato) iniziale e quindi viene generato lo scheduling e valutato per questo CGM Il CGM viene quindi perturbato ed eventualmente viene scelto un nuovo CGM; loperazione è ripetuta abbassando progressivamente la temperatura (loop di annealing) Il best scheduling prodotto viene ritornato al chiamante
 iniziale e quindi viene generato lo scheduling e valutato per questo CGM Il CGM viene quindi perturbato ed eventualmente viene scelto un nuovo CGM; loperazione è ripetuta abbassando progressivamente la temperatura (loop di annealing) Il best scheduling prodotto viene ritornato al chiamante.")
18
Rescheduling Per applicazioni long running lo scheduling iniziale può non essere più efficace a causa di variazioni del carico delle risorse. A questo scopo può essere necessario ridefinire lo scheduling (rescheduling) attraverso due azioni che coinvolgono lapplicazione in esecuzione: –Migrazione –Bilanciamento dinamico del carico
 attraverso due azioni che coinvolgono lapplicazione in esecuzione: –Migrazione –Bilanciamento dinamico del carico.")
19
Rescheduling Esistono diversi problemi che devono essere affrontati per consentire il rescheduling di applicazioni parallele: –Disponibilità di meccanismi adatti a permettere migrazione di processi e ribilanciamento nella distribuzione dei dati; –Monitoraggio delle risorse attive e passive; –Overhead relativo alle operazioni precedenti

20
Rescheduling

21
Larchitettura mostrata in figura comprende N processi in esecuzione sui nodi; si suppone anche che esista un contratto di performance stabilito in una fase precedente di gestione dellapplicazione; appositi application sensor sono co-allocati con i processi applicativi per poterne verificare lo stato di avanzamento; resource sensor sono presenti sulle risorse (attive e passive) per poterne verificare il livello di utilizzo. I dati prodotti dagli application sensor e il performance contract sono a disposizione del contract monitor che a fronte di una contract violation interpella il rescheduler Il rescheduler valuta se un azione di rescheduling può essere conveniente oppure no, utilizzando i dati provenienti dai resource sensor e considerando loverhead derivato dallazione di rescheduling

22
Rescheduling Il rescheduler contatta i rescheduler actuators per eseguire le azioni necessarie al rescheduling Allo stato attuale della tecnologia per effettuare le azioni di monitoraggio, migrazione e ribilanciamento del carico è necessaria la collaborazione dellapplicazione. Per applicazioni con struttura regolare una soluzione di tipo generale è più facilmente definibile, anche se tuttora esistono solo strumenti di ricerca, non consolidati che implementano questa possibilità

23
Contract monitoring In GraDS il monitoraggio del contratto di performance è basato su sensori dellapplicazione realizzati utilizzando il sistema Autopilot. Questi sensori sono eseguiti in un thread separato nello spazio del processo applicativo. Per il loro utilizzo è necessario inserire alcune chiamate a funzioni specifiche nel codice applicativo. I sensori possono essere configurati in modo da poter leggere e fornire allesterno i valori di alcune variabili: un valore di interesse in questi casi è quello che dei contatori associati a fasi di calcolo iterative. Altri sensori possono riportare valori hw quali ad esempio il processor flop rate e il volume di comunicazioni in Mb/sec I valori rilevati dai sensori sono inviati al contract monitor che li verifica e prende le opportune decisioni

24
Rescheduling attraverso migrazione dellapplicazione Il rescheduling può essere implementato attraverso una migrazione basata su unoperazione di stop/restart. Quando viene deciso il rescheduling di unapplicazione tutti i processi effettuano un checkpoint si fermano, e quindi lapplicazione riparte utilizzando i dati salvati al checkpoint. GRaDS fornisce una user-level checkpointing library chiamata Stop Restart Software (SRS) Lutilizzo di SRS prevede i passi descritti di seguito
 Lutilizzo di SRS prevede i passi descritti di seguito.")
25
Rescheduling con migrazione Dopo la MPI_Init() deve esser chiamata la funzione SRS_Init() e prima della MPI_Finalize() deve esser chiamata la funzione SRS_Finish() Lutente può utilizzare opportunamente gli statement condizionali per distinguere il codice da eseguire allavvio del programma, da quello da eseguire in caso di restart (ad esempio inizializzazione dei valori di un array = 0 allavvio e utilizzando un checkpoint al restart) A questo scopo il sistema fornisce la funzione SRS_Restart_Value() che ritorna il valore 0 allavvio e 1 dopo il restart
 deve esser chiamata la funzione SRS_Init() e prima della MPI_Finalize() deve esser chiamata la funzione SRS_Finish() Lutente può utilizzare opportunamente gli statement condizionali per distinguere il codice da eseguire allavvio del programma, da quello da eseguire in caso di restart (ad esempio inizializzazione dei valori di un array = 0 allavvio e utilizzando un checkpoint al restart) A questo scopo il sistema fornisce la funzione SRS_Restart_Value() che ritorna il valore 0 allavvio e 1 dopo il restart")
26
Migrazione E fornita la primitiva SRS_Check_Stop() che permette di verificare se dallesterno è stata richiesta unoperazione di migrazione (dal momento in cui la primitiva era stata chiamata precedentemente). Questa primitiva deve essere chiamata in punti ragionevoli ( ad esempio dove esiste una sincronizzazione anche lasca tra i processi paralleli). E fornita la primitiva SRS_Register() per registrare le variabili che saranno salvate (checkpointed) dalla libreria. Quando una componente esterna ferma lapplicazione vengono salvate solo le variabili registrate.
. E fornita la primitiva SRS_Register() per registrare le variabili che saranno salvate (checkpointed) dalla libreria. Quando una componente esterna ferma lapplicazione vengono salvate solo le variabili registrate..")
27
Migrazione SRS_Read() è utilizzata dopo un restart per leggere i dati salvati nel checkpoint. Fornisce anche laccesso alla distribuzione dei dati ed al numero di processori utilizzati nel checkpoint. La distribuzione dei dati può essere ripristinata o modificata al restart Lheader file della libreria deve essere incluso nel codice e la libreria deve essere linkata allapplicazione E prevista lesistenza di un demone (Runtime Support System RSS) sulle macchine che possono essere coinvolte nelloperazione di rescheduling
 sulle macchine che possono essere coinvolte nelloperazione di rescheduling.")
28
Migrazione – interazione con il contract monitor Il contract monitor può contattare il migration rescheduler in caso di violazione del contratto E possibile interrogare il contract monitor per avere informazioni sul tempo di esecuzione rimanente E possibile modificare dinamicamente il contratto di performance, nel caso in cui lo scheduler non sia in grado di applicarlo Il migration rescheduler opera in due modi: –On request: quando si rileva una violazione del contratto e viene richiesta unoperazione di aggiustamento; –Opportunistic: se il CM. si accorge che unapplicazione è terminata e ha liberato delle risorse può proporre allo scheduler di utilizzarle –In entrambe i casi il CM interagisce con un tool opportuno (ad es. NWS)
.")
29
Rescheduling attraverso process swapping Una strategia alternativa al rescheduling è il process swapping. Meno flessibile ma più economica e meno intrusiva. Lapplicazione è lanciata su un numero maggiore di macchine rispetto a quelle utilizzate. Su alcuni nodi lapplicazione è attiva mentre su altri è inattiva. Lutilizzatore vede solo i nodi attivi nel comunicatore MPI (MPI_Comm_World), mentre il sistema diffonde i messaggi su tutti i nodi.
, mentre il sistema diffonde i messaggi su tutti i nodi..")
30
Rescheduling - swapping E fornita una libreria per lo swapping che permette di: –Registrare le variabili interessate dallo swapping: swap_register(); questa operazione deve essere fatta per le variabili che controllano cicli di iterazioni, e per tutte le variabili potenzialmente interessate dallo swapping; –Effettuare loperazione di swap allinterno del ciclo di calcolo (MPI_Swap()) Lutente deve linkare la libreria di swap ed includere il file mpi_swap.h al posto di mpi.h
; questa operazione deve essere fatta per le variabili che controllano cicli di iterazioni, e per tutte le variabili potenzialmente interessate dallo swapping; –Effettuare loperazione di swap allinterno del ciclo di calcolo (MPI_Swap()) Lutente deve linkare la libreria di swap ed includere il file mpi_swap.h al posto di mpi.h")
31
Swapping Sono forniti diversi servizi run-time: –Lo swap_handler che svolge il ruolo application sensor, resource sensor e rescheduling actuator –Lo swap manager che svolge il ruolo di rescheduler. Esiste uno swap manager attivo per ogni applicazione e dedicato allapplicazione. Lo swap handler fornisce le informazioni allo swap manager che, agendo in modo opportunistico, determina se effettuare loperazione di swap. Nel caso interagisce con lo swap handler. Lo swap handler memorizza la richiesta di swap e la prossima volta in cui lapplicazione verifica se uno swap è stato richiesto (MPI_Swap()) questo viene eseguito.
) questo viene eseguito..")
32
Metascheduling Lo scheduling launch time e il rescheduling considerano le applicazioni una alla volta. Questo genera diversi possibili problemi: –2 applicazioni concorrenti sottomesse allo stesso tempo; –Se il launch time scheduler dice che non ci sono abbastanza risorse si rischia la starvation –Un job molto lungo può penalizzare fortemente le altre eventuali richieste Problema chiave: non esiste una conoscenza globale in grado di bilanciare le esigenze delle applicazioni Lobiettivo del metascheduling è quello di prendere in considerazione sia le esigenze dellapplicazione e le performance complessive del sistema.

34
Metascheduling Best case analysis: il metascheduler gestisce tutto ciò che avviene nel sistema. E basato su quattro componenti aggiuntivi: Il Database manager contiene le informazioni su tutte le applicazioni nel sistema; per ogni applicazione il suo stato, le risorse schedulate a launch time e il tempo previsto di terminazione. Il database è aggiornato durante lesecuzione dellapplicazione, e fornisce informazioni agli altri componenti del metascheduler. Il Permission service determina se le risorse filtrate hanno capacità adeguate allapplicazione e fornisce o nega il permesso allapplicazione per proseguire con i passi successivi. Se le risorse non sono sufficienti il permission service agisce in modo pro-attivo eventualmente fermando unaltra applicazione che sta consumando una grande quantità di risorse

35
Metascheduling Il contract negotiator riceve dal contract developer le informazioni sui contratti di performance dellapplicazione (in termini di stima di performance e schedulazione). Questo componente può rifiutare un contratto nel caso in cui: –A suo giudizio utilizza informazioni non aggiornate; –Lapplicazione chiede troppe risorse; –La richiesta di risorse ha un forte impatto su unapplicazione in esecuzione. Allo stesso tempo può aumentare le risorse fornite se questo è possibile, eventualmente interrompendo unapplicazione in esecuzione. Il rescheduler agisce allinterno del metascheduler

Presentazioni simili


 di programmi Misure del tempo: Misure del tempo: metodi principali 1.Benchmarking 2.Analisi.>")

















>")