Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Esistono delle banche dati derivate simili a pfam, cioe’ banche dati in cui le proteine sono organizzate per famiglie ma che a differenza di pfam comprendono solo proteine a struttura nota. banche di questo tipo sono CAMPASS e Homstrad. per avere un’idea di come è costruita Campass andate all’indirizzo http://www-cryst.bioc.cam.ac.uk/~kenji/ssdb/

2
Se avete Explorer, cliccando sul nome di una famiglia, per esmpio SH3, potrete vedere che le strutture delle proteine possono essere sovrapposte come si sovrappongono due oggetti tridimensionali. Se cliccate sui vari atomi, i vertici dei segmenti che rappresentano i carboni alpha, potete vedere che si capire quali sono gli aa corrispondenti nelle due proteine quindi potete costruire un allineamento. questo e’ l’allineamento piu’ “ vero” possibile e non avete utilizzato matrici di punteggio e gap penalities.

3
1lck-2( 63 ) dnlViAlhsyepshdgDLgFekgeqLrIleqs---------------- 1pht-0( 3 ) aeGYqYrAlydykkereeDIdLhlgDiLtVn---kgsLvalgfsdgqear 1lck-2( 95 ) ---gewwkAqSlttgqegfIpfnfVakan 1pht-0( 50 ) PeeIgwLnGyNettgergdFpGtyVeyi-grkkispp Key solvent inaccessible UPPER CASE X solvent accesible lower case x alpha helix red x beta strand blue x 3 - 10 helix maroon x hydrogen bond to main chain amide bold x disulphide bond cedilla ç positive phi italic x
 dnlViAlhsyepshdgDLgFekgeqLrIleqs pht-0( 3 ) aeGYqYrAlydykkereeDIdLhlgDiLtVn---kgsLvalgfsdgqear 1lck-2( 95 ) ---gewwkAqSlttgqegfIpfnfVakan 1pht-0( 50 ) PeeIgwLnGyNettgergdFpGtyVeyi-grkkispp Key solvent inaccessible UPPER CASE X solvent accesible lower case x alpha helix red x beta strand blue x helix maroon x hydrogen bond to main chain amide bold x disulphide bond cedilla ç positive phi italic x")
4
Adesso andiamo nella banca homstradhomstrad col Browse Families vediamo come sono organizzate le famiglie.Browse Families Ricordiamoci che le proteine possono essere tutte alfa, tutte beta, alfa/beta (alfa eliche e strutture beta intercalate), alfa +beta (proteine con regioni prevalentemente alfa e con regioni prevalentemente beta) poi cerchiamo una famiglia con la quale abbiamo gia’ lavorato quella del ap-nucleasi: AP endonuclease family 1:AP endonuclease family 1 e studiamoci com’è organizzata Homstrad
, alfa +beta (proteine con regioni prevalentemente alfa e con regioni prevalentemente beta) poi cerchiamo una famiglia con la quale abbiamo gia’ lavorato quella del ap-nucleasi: AP endonuclease family 1:AP endonuclease family 1 e studiamoci com’è organizzata Homstrad")
5
adesso domandiamoci, se noi abbiamo una sequenza, per esempio quella della esercitazione scorsa: MNSSVISKPILPVAGVHRSSADDRSTGRPATGSRQ NDDGPLNPPGRGLSENSARSEALLRCRKPFITATF NANTAREEVRASEIAHCFESCGIKILGIQEHRRVH EDPVVFSRLEGQYLITASAWRNQSQASVGGVGLL LSTRARKALRRATRHSDRILVAEFDSNPVTTVIVT YSPTNTSPEEVVENYYDDLSDVIRGVPAHNFLAVL GDFNARLGTEDASFTWHDKTNRNGELLAEIMTE HSLLAANTQFRKKQGKRWTYLDRGTGMKRQLD YILVRRKWWNSILNAEPYNTFCTVGSDHRVVSM RVRLSLRVPKQNSEQSLTGINSL copiatela

6
possiamo cercare in una banca dati di famiglie di proteine a struttura nota una famiglia a cui la nostra proteina e’ omologa? Cioè la stessa cosa che facevamo quando cercavamo in pfam? Si pero’ dobbiamo andarci a cercare il programma che fa questo, che si chiama fugue e che trovate all’indirizzo: http://www-cryst.bioc.cam.ac.uk/~fugue/prfsearch.html questo programma non lavora interattivamente ma ha bisogno di un indirizzo e-mail a cui manda come risposta i risultati. cercateli all’indirizzo che vi ha rimandato per posta il programma http://raven.bioc.cam.ac.uk/~kenji/work/fugue/10417/fugue.html i vostri risultati sono conservati e possono essere ritrovati a questo indirizzo per 5 giorni. quindi nel giorno in cui farete lezione, essi dovrebbero essere accessibili, dopo no. delle note copiate da questi risulati sono state copiate nelle prossime diapositive, in mod da essere sempre consultabili.

7
Profile Hit PLEN RAWS RVN ZSCORE ZORI AL AP_endonucleas1 294 1 410 27.99 30.71 00 CERTAIN Alignment AP_endonucleas1Alignment hs1i9zahs1i9za 336 -266 206 6.59 9.07 00 CERTAIN AlignmentAlignment hsd2dnja 253 -272 62 3.83 6.21 00 MARGINAL Alignmenthsd2dnjaAlignment ANATOANATO 74 -295 43 3.43 5.79 02 GUESS AlignmentAlignment hsd1d0gr1 41 -265 40 2.48 3.61 02 GUESS Alignmenthsd1d0gr1Alignment hs1ueoahs1ueoa 63 -264 8 2.42 4.11 02 GUESS AlignmentAlignment His_biosynthHis_biosynth 262 -325 73 2.29 5.00 00 GUESS AlignmentAlignment hs1i26a 34 -285 18 2.23 3.36 02 GUESS Alignmenths1i26aAlignment hs1ex2ahs1ex2a 185 -258 39 2.22 4.70 02 GUESS AlignmentAlignment hs1a81jhs1a81j 16 31 9 2.04 3.16 22 GUESS AlignmentAlignment

10
Fugue vi fornisce anche un modello della vostra proteina. notate che e’ un modello approssimato perche’ mancano alcuni loop dove l’allineamento e’ meno affidabile. per averlo dovete cliccare su pdb. AP_endonucleas1AP_endonucleas1 aa ma mh hh aa ma mh hh aa ma mh hh CERTAIN PDB Chime 27.99aamamhhhaamamhhhaamamhhhPDB Chime

11
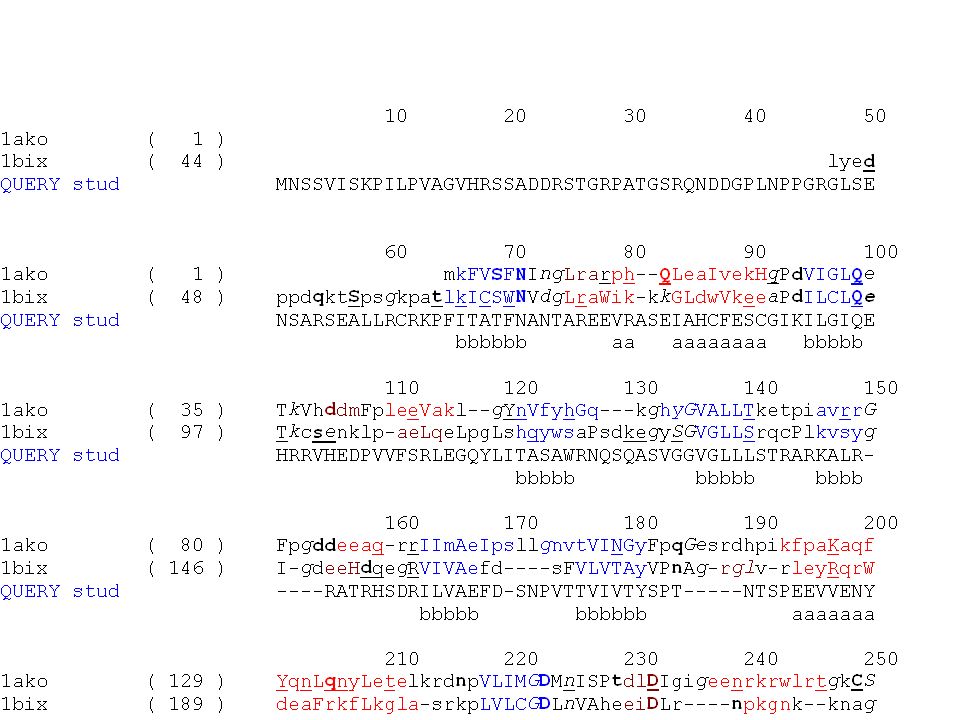
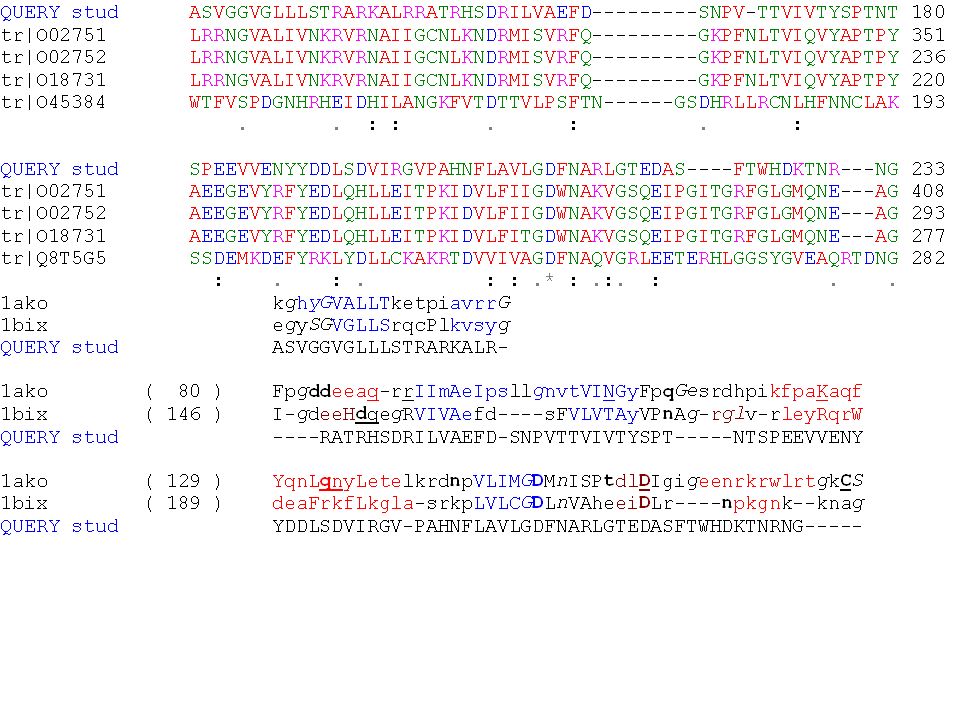
Nelle opzioni di Fugue avrete visto che quando si invia come query una sequenza singola, quello che avviene di default e’ prima una ricerca con psi-blast di altre sequenze simili alla query. Quindi il vero input diventa non una sequenza singola, ma una famiglia di sequenze simili allineata. quello che fa fugue e’ di cercare una famiglia in Homstrad che si adatta bene alla famiglia di sequenze che abbiamo di fatto usato come imput. Poi quello che vediamo e’ solo quello che ci interessa, la nostra sequenza query allineata alla famiglia di Homstrad. Nella prossima diapositiva c’e’ un pezzetto dell’allineamento di sequenze ottenuto con psi-blast ed un pezzetto dell’allineamento della query studenti con la famiglia Homstrad delle ap1_endonucleasi

13
ESISTONOALTRI SSERVER CHE CONSENTONO DI OTTENERE UN MODELLO TRIDIMENSIONALE PER UNA PROTEINA A STRUTTURA INCOGNITA. OLTRE A SWISS MODEL SI PUO’ PROVARE http://www.bmm.icnet.uk/servers/3djigsaw/ ANCHE IN QUESTO SACO COME PER LA RICERCA IN HOMSTRAD CON FUGUE I RISULTATI NON SI OTTENGONO INTERATTIVAMENTE. BISOGNA FORNIRE UN INDIRIZZO E-MAIL E PER POSTA CI VIENE NOTIFICATO IL SITO DOVE IL MODELLO E’ REPERIBILE

14
This is an automatic split of your sequence in protein domains Follow the link below and select the modelling templates for each modelable domain 2 domain/s found in your query sequence (1 has homologous templates). See them at: http://www.bmm.icnet.uk/~3djigsaw/dom_fish/display2.cgi?output/ 149f2cc2 (this file will be erased in a week time) Your submission: >studentiap1 MNSSVISKPILPVAGVHRSSADDRSTGRPATGSRQNDDGPLNPPGRGLSENSARSEALLR CRKPFITATFNANTAREEVRASEIAHCFESCGIKILGIQEHRRVHEDPVVFSRLEGQYLI TASAWRNQSQASVGGVGLLLSTRARKALRRATRHSDRILVAEFDSNPVTTVIVTYSPTN T SPEEVVENYYDDLSDVIRGVPAHNFLAVLGDFNARLGTEDASFTWHDKTNRNGELLAE IM TEHSLLAANTQFRKKQGKRWTYLDRGTGMKRQLDYILVRRKWWNSILNAEPYNTFCT VGS DHRVVSMRVRLSLRVPKQNSEQSLTGINSL Send comments mailto: 3djigsaw@cancer.org.uk See you soon http://www.bmm.icnet.uk/~3djigsaw/dom_fish/display2.cgi?output/ 149f2cc2 3djigsaw@cancer.org.uk
 Your submission: >studentiap1 MNSSVISKPILPVAGVHRSSADDRSTGRPATGSRQNDDGPLNPPGRGLSENSARSEALLR CRKPFITATFNANTAREEVRASEIAHCFESCGIKILGIQEHRRVHEDPVVFSRLEGQYLI TASAWRNQSQASVGGVGLLLSTRARKALRRATRHSDRILVAEFDSNPVTTVIVTYSPTN T SPEEVVENYYDDLSDVIRGVPAHNFLAVLGDFNARLGTEDASFTWHDKTNRNGELLAE IM TEHSLLAANTQFRKKQGKRWTYLDRGTGMKRQLDYILVRRKWWNSILNAEPYNTFCT VGS DHRVVSMRVRLSLRVPKQNSEQSLTGINSL Send comments mailto: See you soon output/ 149f2cc2")
Presentazioni simili








 her = a direct.>")


 è un ambiente di programmazione per le pagine web. La.>")








>")