Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Il progetto Turin University Treebank: corpora e NLP Cristina Bosco Dipartimento di Informatica Università di Torino Corso di informatica applicata alla comunicazione multimediale 14 marzo 2013

2
ACQUISIZIONE della conoscenza: la comprensione del linguaggio comporta una grande quantità di conoscenza (perlomeno linguistica) AMBIGUITÀ: si trova a tutti i livelli e può impedire di produrre per una frase una singola analisi IRREGOLARITÀ: il linguaggio è influenzato da scopi di comunicazione e non sempre usato seguendo le regole Problemi
 AMBIGUITÀ: si trova a tutti i livelli e può impedire di produrre per una frase una singola analisi IRREGOLARITÀ: il linguaggio è influenzato da scopi di comunicazione e non sempre usato seguendo le regole Problemi")
3
L’approccio basato su corpora in NLP è un metodo per l’acquisizione della conoscenza che offre soluzione anche al problema dell’irregolarità e dell’ambiguità del linguaggio Per questo motivo è oggi ampliamente utilizzato con successo da molti sistemi Approccio basato su corpora

4
L’approccio basato su corpora si differenzia in modo sostanziale dall’approccio basato su regole. Esso è infatti un approccio empirico in quanto non parte da nessuna assunzione su come il linguaggio funziona, ma si fonda esclusivamente sull’osservazione diretta del linguaggio. Approccio basato su corpora

5
In cosa consiste? Si assume che un CORPUS C di un linguaggio L possa contenere la conoscenza necessaria a trattare L, e si acquisisce la conoscenza da C Il risultato è duplice: la conoscenza delle regole ed irregolarità del linguaggio contenuto nel corpus C la percezione della frequenza delle strutture linguistiche presenti nel corpus C Approccio basato su corpora

6
Il risultato è duplice: la conoscenza delle regole ed irregolarità del linguaggio contenuto nel corpus C > questo risolve il problema dell’acquisizione della conoscenza la percezione della frequenza delle strutture linguistiche presenti nel corpus C > questo consente di trattare l’ambiguità Approccio basato su corpora

7
Per aumentare l’utilità di un corpus lo si arricchisce associando ai dati delle informazioni Un corpus si chiama TREEBANK quando le informazioni morfologiche e sintattiche sono rese esplicite tramite annotazione I treebank sono oggi le basi di dati linguistici più utilizzate nel NLP Treebank

8
Perché annotare il corpus? Per rendere possibile l’acquisizione della conoscenza in modo veloce, semplice e certo Quindi per rendere possibile l’utilizzo del corpus per molti più scopi. Treebank

9
Nell’ambito di ricerche linguistiche un corpus annotato morfo-sintatticamente consente: la rilevazione automatica della frequenza di determinate strutture linguistiche la scoperta di certi fenomeni e la verifica di teorie Treebank

10
Nell’ambito del NLP un corpus annotato morfo- sintatticamente consente: la rilevazione automatica delle regole ed irregolarità del linguaggio sulla base delle quali addestrare sistemi di analisi che utilizzano modelli statistici, oppure raffinare sistemi che utilizzano regole Treebank

11
È un circolo virtuoso (o vizioso)? SI per costruire validi sistemi di analisi del linguaggio occorrono i treebank (è dimostrato che i sistemi di NLP che ottengono i migliori risultati sono quelli che prendono le informazioni da treebank) per costruire dei treebank occorrono validi sistemi di analisi del linguaggio (è impossibile costruire treebank in modo esclusivamente manuale per motivi di tempo e di correttezza) Treebank
 per costruire dei treebank occorrono validi sistemi di analisi del linguaggio (è impossibile costruire treebank in modo esclusivamente manuale per motivi di tempo e di correttezza) Treebank.")
12
È un circolo virtuoso (o vizioso)? SI in pratica l’annotazione dei treebank è prodotta da sistemi automatici di analisi morfologica e sintattica, che hanno attualmente percentuali minime di errore intorno al 5% per la morfologia e intorno al 10% annotatori umani che correggono le analisi prodotte in modo automatico Treebank

13
ES: annotation processes MORPHOSYNTSEM PRAGUE semi- automatic NEGRA automaticinteractive (probabilistic) PENN automaticautomatic (skeletal)
 PENN automaticautomatic (skeletal)")
14
Il TUT è un treebank costruito per la lingua italiana La sua costruzione si è ispirata a quella di altri treebank e comporta vari passi Turin University Treebank

15
Costruire TUT: 1.scegliere i testi per il corpus 2.definire uno schema di annotazione (scegliere quali informazioni annotare e in che modo) 3.applicare lo schema ai testi (automatico + manuale con doppia annotazione) 4. verificare il risultato dell’applicazione (tool di verifica, conversione in altro formato, training di sistemi) e correggere gli errori Turin University Treebank
 e correggere gli errori Turin University Treebank.")
16
1. Scegliere i testi per il corpus di TUT: 3.542 frasi (102.150 token) di cui: 1.100 da quotidiani, 1.983 da prosa giuridica (codice civile, costituzione, Acquis) 459 da wikipedia Turin University Treebank (1)
 di cui: da quotidiani, da prosa giuridica (codice civile, costituzione, Acquis) 459 da wikipedia Turin University Treebank (1).")
17
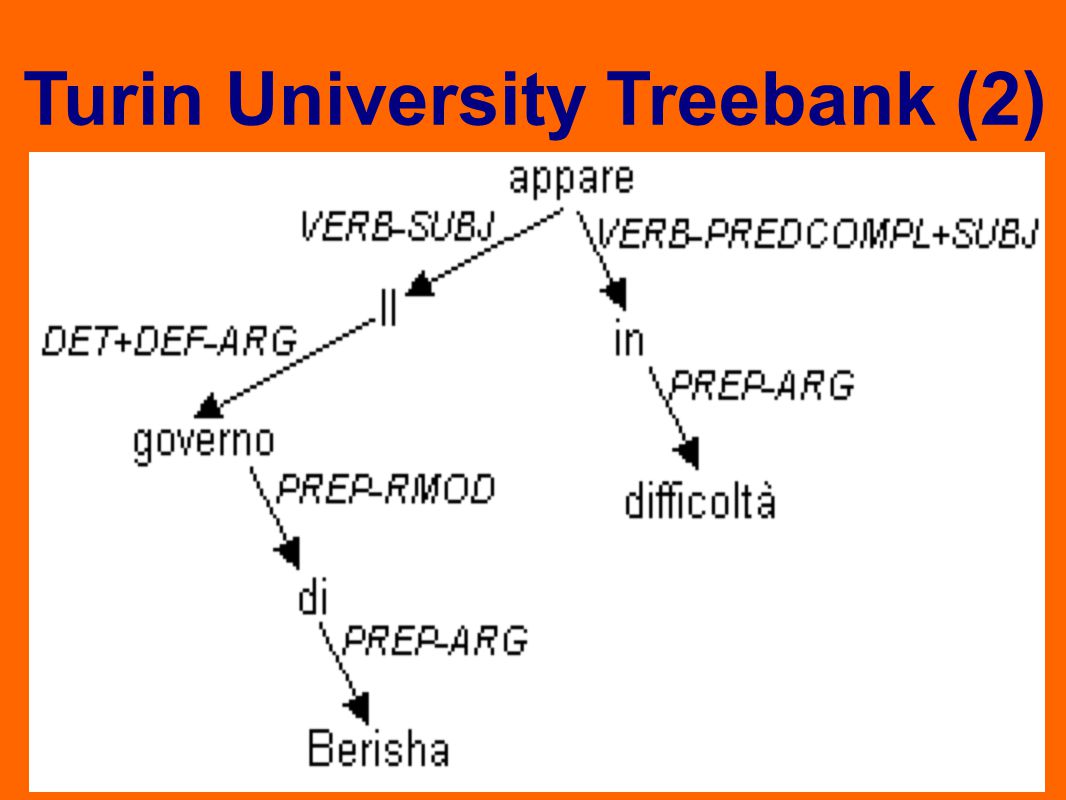
2. Definire lo schema di annotazione di TUT: È stato progettato per la lingua italiana in modo da poterne rappresentare tutte le peculiarità e fenomeni È basato sul paradigma a dipendenze Include una collezione di relazioni grammaticali (~320) che rappresentano la struttura predicativo argomentale Turin University Treebank (2)
 che rappresentano la struttura predicativo argomentale Turin University Treebank (2).")
18
Schema di annotazione e paradigmi sintattici Il paradigma a costituenti evidenzia l’organizzazione gerarchica delle unità della frase (sintagmi) Il paradigma a dipendenze evidenzia la funzione degli elementi della frase (relazioni grammaticali) Turin University Treebank (2)
 Il paradigma a dipendenze evidenzia la funzione degli elementi della frase (relazioni grammaticali) Turin University Treebank (2)")
19
Giorgio ama Maria SUBJOBJ

20
relazioni grammaticali ruoli semantici uguali o distinti? Turin University Treebank (2)
")
21
Le relazioni sono identificabili da varie proprietà Sono realizzate diversamente nelle varie lingue, a seconda dell’uso di casi, inflessioni …: give someone something dare a qualcuno qualcosa Turin University Treebank (2)
")
24
Ogni relazione di TUT può essere composta di 3 elementi: Morfo-sintattico: features che esprimono la categoria grammaticale Verb, Noun, … Funzionale-sintattico: relazioni sintattiche come Subject, Object Semantico: relazioni semantiche come Location, Time, Cause Turin University Treebank (2)
")
25
La nazione sogna ricchezza I sogni di ricchezza della nazione Velocemente / in modo veloce VERB-SUBJ NOUN-OBJ NOUN-OBJ NOUN-SUBJ NOUN-SUBJ VERB-OBJ VERB VERB NOUN NOUN ADV-role ADV-role Turin University Treebank (2)
")
26
Componente morfo-sintattica

27
Dati 944 differenti Verbi per un totale di 4.169 occorrenze nel corpus di TUT Il 30% di questi Verbi (e le strutture predicative argomentali ad essi associate) risulta presente anche in forma nominale Turin University Treebank (2) Componente morfo-sintattica
 risulta presente anche in forma nominale Turin University Treebank (2) Componente morfo-sintattica")
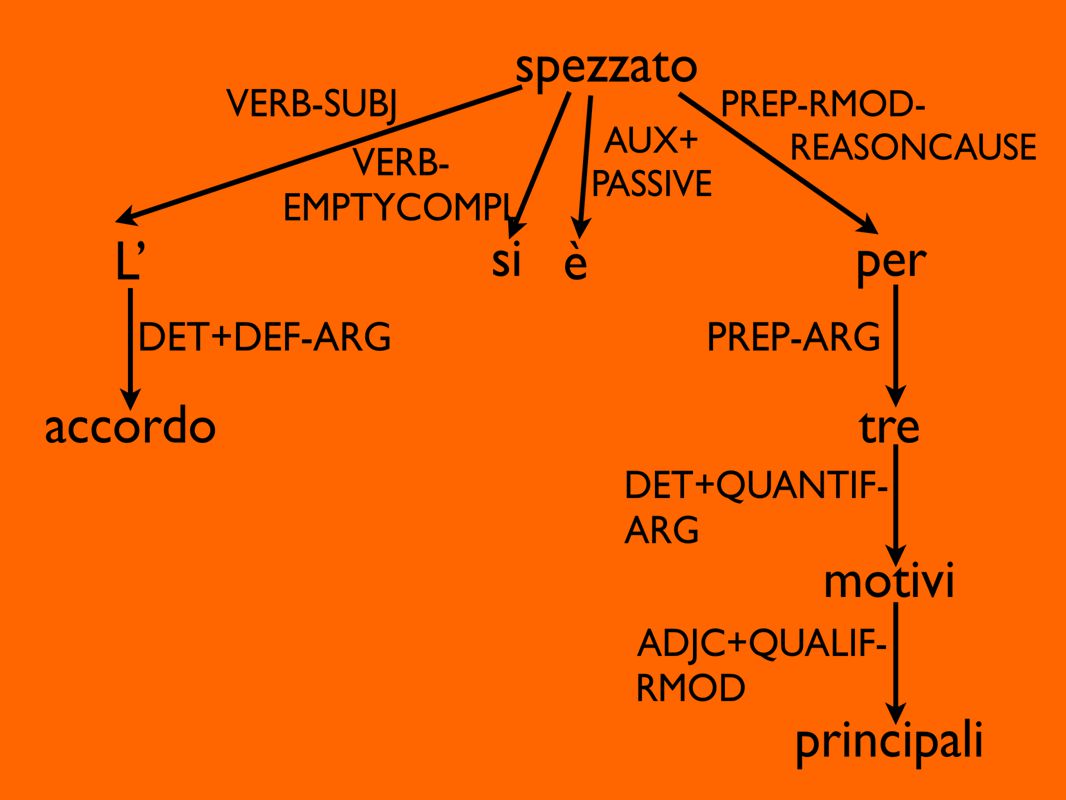
28
Egli non è stato visto da nessuno Egli non è stato visto da ieri ARG ARG MOD MOD Turin University Treebank (2) Componente funzionale-sintattica
 Componente funzionale-sintattica")
29
Turin University Treebank (2) Componente funzionale-sintattica
 Componente funzionale-sintattica")
30
Da qui è partito l’assalto Succedeva dall’altra parte del mondo I miliardi stanziati dal 1991 Era impazzito dal dolore Trarrà beneficio dalla bonifica LOC+FROM LOC+IN TIME REASONCAUSE SOURCE Turin University Treebank (2) Componente semantica
 Componente semantica")
31
Turin University Treebank (2) Componente funzionale-sintattica
 Componente funzionale-sintattica")
32
Dati 600 sintagmi preposizionali introdotti dalla preposizione DA e che svolgono il ruolo di modificatori È stato rilevato che essi possono assumere i seguenti 7 differenti valori semantici: LOC+FROM, LOC+IN, LOC+METAPH, TIME, THEME, REASONCAUSE, SOURCE Turin University Treebank (2) Componente funzionale-sintattica
 Componente funzionale-sintattica")
33
1 In (IN PREP MONO) [7;PREP-RMOD-TIME] 2 quei (QUELLO ADJ DEMONS M PL) [1;PREP-ARG] 3 giorni (GIORNO NOUN COMMON M PL) [2;DET+DEF-ARG] [2;DET+DEF-ARG] 4 Sudja (|Sudja| NOUN PROPER) [7;VERB-SUBJ] 5 la (IL ART DEF F SING) [4;APPOSITION] 6 zingara (ZINGARO NOUN COMMON F SING [5;DET+DEF-ARG] [5;DET+DEF-ARG] 7 annunciava (ANNUNCIARE VERB MAIN IND IMPERF TRANS 3 SING) [0;TOP-VERB] IMPERF TRANS 3 SING) [0;TOP-VERB] 8 il (IL ART DEF F SING) [7;VERB-OBJ] 9 fallimento (FALLIMENTO NOUN COMMON FALLIRE) [8;DET+DEF-ARG] [8;DET+DEF-ARG]
![1 In (IN PREP MONO) [7;PREP-RMOD-TIME] 2 quei (QUELLO ADJ DEMONS M PL) [1;PREP-ARG] 3 giorni (GIORNO NOUN COMMON M PL) [2;DET+DEF-ARG] [2;DET+DEF-ARG] 4 Sudja (|Sudja| NOUN PROPER) [7;VERB-SUBJ] 5 la (IL ART DEF F SING) [4;APPOSITION] 6 zingara (ZINGARO NOUN COMMON F SING [5;DET+DEF-ARG] [5;DET+DEF-ARG] 7 annunciava (ANNUNCIARE VERB MAIN IND IMPERF TRANS 3 SING) [0;TOP-VERB] IMPERF TRANS 3 SING) [0;TOP-VERB] 8 il (IL ART DEF F SING) [7;VERB-OBJ] 9 fallimento (FALLIMENTO NOUN COMMON FALLIRE) [8;DET+DEF-ARG] [8;DET+DEF-ARG]](http://images.slideplayer.it/12/4004582/slides/slide_33.jpg "1 In (IN PREP MONO) [7;PREP-RMOD-TIME] 2 quei (QUELLO ADJ DEMONS M PL) [1;PREP-ARG] 3 giorni (GIORNO NOUN COMMON M PL) [2;DET+DEF-ARG] [2;DET+DEF-ARG] 4 Sudja (|Sudja| NOUN PROPER) [7;VERB-SUBJ] 5 la (IL ART DEF F SING) [4;APPOSITION] 6 zingara (ZINGARO NOUN COMMON F SING [5;DET+DEF-ARG] [5;DET+DEF-ARG] 7 annunciava (ANNUNCIARE VERB MAIN IND IMPERF TRANS 3 SING) [0;TOP-VERB] IMPERF TRANS 3 SING) [0;TOP-VERB] 8 il (IL ART DEF F SING) [7;VERB-OBJ] 9 fallimento (FALLIMENTO NOUN COMMON FALLIRE) [8;DET+DEF-ARG] [8;DET+DEF-ARG]")
34
Applicare lo schema di annotazione a TUT significa che ogni sua frase: viene parsificata in modo automatico dal parser TULE, sviluppato in parallelo con TUT corretta da almeno 2 annotatori umani verificata da tool automatici appositi sottoposta a conversioni e applicazione di altri sistemi Turin University Treebank (3 e 4)
")
35
Le ricadute del progetto TUT Le ricadute del progetto TUT riguardano il suo utilizzo in 3 diverse direzioni: Come raccolta di dati linguistici Come banco di prova per sistemi di NLP Come modello per lo sviluppo di altre risorse

36
Come raccolta di dati linguistici TUT ha consentito Studi sul comportamento dei verbi della lingua italiana (estrazione di conoscenza) Studio dell’ordine delle parole nella lingua italiana Le ricadute del progetto TUT
 Studio dell’ordine delle parole nella lingua italiana Le ricadute del progetto TUT")
37
(in 3500 sentences) Le ricadute del progetto TUT
 Le ricadute del progetto TUT")
38
Come banco di prova per sistemi di NLP TUT ha consentito di raggiungere i risultati oggi allo stato dell’arte per il parsing dell’italiano, con percentuali di errore intorno al 10% TUT è il treebank di riferimento nelle competizioni per parser di italiano (Evalita 07, 09, 11)
")
39
Le ricadute del progetto TUT Come modello per lo sviluppo di altre risorse, TUT è attualmente utilizzato in due principali direzioni: in prospettiva cross-linguistica, è in corso di sviluppo un treebank parallelo per le lingue italiano, francese e inglese (ParTUT) per lo studio di fenomeni legati all’espressione di sentimenti, opinioni ed emozioni, è in corso di sviluppo un corpus di testi di Twitter annotato morfologicamente (SentiTUT)
 per lo studio di fenomeni legati all’espressione di sentimenti, opinioni ed emozioni, è in corso di sviluppo un corpus di testi di Twitter annotato morfologicamente (SentiTUT)")
40
Le ricadute del progetto TUT INOLTRE: TUT è stato tradotto in formati di altri treebank grazie a tool di conversione automatica Questo ha reso possibile l’applicazione di strumenti sviluppati per tali formati ed il confronto tra paradigmi e modelli linguistici differenti nell’ambito del dibattito su quale formato si rivela più adeguato per il NLP in generale e per le diverse lingue naturali

41
Il Turin University Treebank (TUT), ParTUT e SentiTUT sono tutti progetti dell’Interaction Models Group (L. Lesmo, C. Bosco, A. Mazzei, V. Lombardo, L. Robaldo, M. Sanguinetti) del Dipartimento di Informatica dell’Università di Torino
 del Dipartimento di Informatica dell’Università di Torino.")
42
Per ulteriori informazioni: http://www.di.unito.it/~tutreeb

Presentazioni simili