Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Sistemi per il recupero delle informazioni SISTEMI PER IL RECUPERO DELLINFORMAZIONE

2
Information Retrieval LInformation Retrieval (IR) si occupa della rappresentazione, memorizzazione e organizzazione dellinformazione, al fine di rendere agevole allutente il soddisfacimento dei propri bisogni informativi. le informazioni devono essere rappresentate ed organizzate in modo da fornire all'utente un facile accesso all'informazione cui è interessato. le richieste di informazione dell'utente vengono tradotte in queries che vengono elaborate da un motore di ricerca o sistema di IR. Nella forma più comune le queries sono espresse come insiemi di parole chiave (keywords o termini indice) che riassumono l'informazione desiderata. Data una collezione di documenti e un bisogno informativo dellutente, obiettivo dellIR è di recuperare, allinterno di una collezione, tutti e solo i documenti rilevanti. rispetto alla teoria classica delle basi di dati, lenfasi non è sulla ricerca di dati ma sulla ricerca di informazioni.
 che riassumono l informazione desiderata. Data una collezione di documenti e un bisogno informativo dellutente, obiettivo dellIR è di recuperare, allinterno di una collezione, tutti e solo i documenti rilevanti. rispetto alla teoria classica delle basi di dati, lenfasi non è sulla ricerca di dati ma sulla ricerca di informazioni..")
3
Rilevanza Per essere efficace nel suo intento di soddisfare il bisogno di informazione dell'utente, un sistema di IR deve in qualche modo interpretare il contenuto dei documenti ed ordinarli a seconda del grado di rilevanza rispetto a ciascuna query. Per ottenere l'interpretazione del contenuto del documento è necessario estrarre l'informazione sintattica e semantica dal testo. La difficoltà non sta solo nella scelta del modo in cui estrarre tali informazioni, ma anche in come utilizzarle per stabilirne la rilevanza. Pertanto la nozione di rilevanza è fondamentale per l'IR. Lo scopo principale di un sistema di IR è di recuperare tutti i documenti rilevanti per la query dell'utente cercando di recuperare il minor numero possibile di documenti non rilevanti.

4
IRS: descrizione funzionale

5
I vari passi

6
IL PROBLEMA INFORMATIVO Il problema informativo corrisponde ad un particolare bisogno di informazione dellutente. Tramite un processo di rappresentazione, il problema informativo viene tradotto in una richiesta espressa nel linguaggio di interrogazione dellIRS. Analogamente, dai documenti, tramite un altro processo di rappresentazione, spesso chiamato di classificazione o indicizzazione, si passa al surrogato dei documenti, cioè alla loro rappresentazione nellIRS. Sia nella classificazione di un documento da parte di un esperto che nella formulazione della richiesta da parte di un utente può essere usato un vocabolario controllato organizzato in un thesaurus.

7
IL PROBLEMA INFORMATIVO I metodi di rappresentazione dei documenti si possono separare in due categorie: quelli che danno una rappresentazione diretta del contenuto dei documenti e quelli che ne danno una rappresentazione indiretta. Nel primo caso il documento è rappresentato dalle parole in esso contenute mentre nel secondo il documento è rappresentato da termini di indicizzazione derivati manualmente o automaticamente e che ne descrivono in modo sintetico e completo il contenuto Rappresentazione dei documenti in forma sintetica: indicizzazione: lidea è quella di associare a ciascun documento un insieme di termini significativi che saranno utilizzati per selezionare il documento.

8
IL PROBLEMA INFORMATIVO Possiamo pensare ad un IRS come ad un sistema in cui da un lato entrano documenti che vengono sottoposti ad un processo di indicizzazione, per ottenerne una rappresentazione sintetica, dallaltro entrano le richieste dellutente che devono essere codificate in modo analogo, cioè come un insieme di termini. In fase di recupero: formalizzazione delle richieste confronto tra richieste e rappresentazione di documenti

9
IL PROBLEMA INFORMATIVO Si definisce tecnica di recupero (retrieval technique) di un IRS la tecnica adottata dal sistema per confrontare linterrogazione utente con il surrogato dei documenti. La tecnica di recupero adottata da un IRS, è il meccanismo interno del sistema che lo guida nel giudicare come rilevanti o non rilevanti i documenti di una raccolta, in rapporto ad una specifica interrogazione. Le tecniche di recupero sono di due tipi: per corrispondenza esatta (exact match) per similitudine o corrispondenza parziale (partial match) Risultato Binario (si/no) – il risultato soddisfa o non soddisfa la richiesta (corrispondenza esatta) Probabilistico – il risultato soddisfa la richiesta in una qualche misura (corrispondenza parziale)
 per similitudine o corrispondenza parziale (partial match) Risultato Binario (si/no) – il risultato soddisfa o non soddisfa la richiesta (corrispondenza esatta) Probabilistico – il risultato soddisfa la richiesta in una qualche misura (corrispondenza parziale).")
10
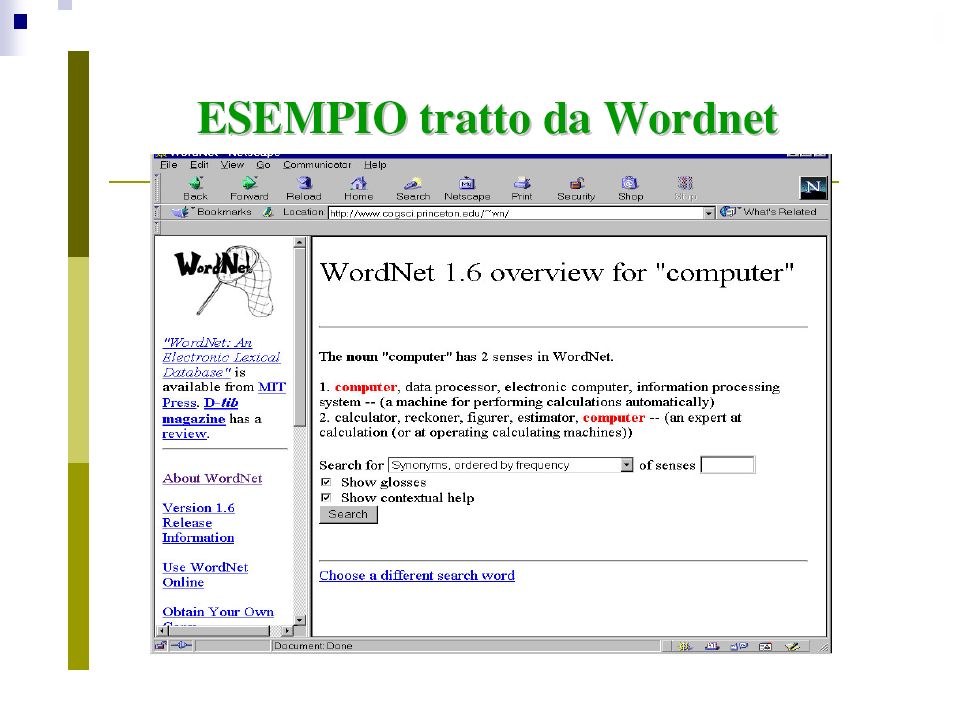
Polisemia Il fatto che l'informazione all'interno dei documenti e le queries siano rappresentate da espressioni del linguaggio umano costituisce un'ulteriore complicazione del task dell Information Retrieval. Un primo problema è quello della polisemia: a differenza dei linguaggi formali, dove alle parole del linguaggio corrisponde un unico significato, nel caso dei linguaggi naturali le parole possono avere più di un significato (in questo caso si dice che la parola è polisemica), col risultato che l'ambiguità di una singola parola può venire propagata al resto della frase. per esempio l'aggettivo vecchio può avere sia il significato di vecchio utilizzato per descrivere qualcosa come appartenente ad un periodo od un'epoca precedente, sia quello di vecchio nel senso di usato, logoro; mentre pellicola può essere sia un film che il supporto su cui vengono registrate le immagini in una macchina fotografica. Quindi dicendo una vecchia pellicola ci si può riferire sia ad un film d'annata, sia ad un rullino rovinato.
, col risultato che l ambiguità di una singola parola può venire propagata al resto della frase. per esempio l aggettivo vecchio può avere sia il significato di vecchio utilizzato per descrivere qualcosa come appartenente ad un periodo od un epoca precedente, sia quello di vecchio nel senso di usato, logoro; mentre pellicola può essere sia un film che il supporto su cui vengono registrate le immagini in una macchina fotografica. Quindi dicendo una vecchia pellicola ci si può riferire sia ad un film d annata, sia ad un rullino rovinato..")
11
Sinonimia La sinonimia, ovvero l'esistenza di parole con significato equivalente od identico (ad esempio convegno e riunione), ha per certi versi un effetto contrario: infatti in questo caso, in risposta ad una query che contenga una parola con sinonimi, la probabilità che l'insieme dei documenti ritornati sia incompleto rispetto all'insieme dei documenti rilevanti per la query è sicuramente superiore al caso in cui la query non contenga parole con sinonimi.
, ha per certi versi un effetto contrario: infatti in questo caso, in risposta ad una query che contenga una parola con sinonimi, la probabilità che l insieme dei documenti ritornati sia incompleto rispetto all insieme dei documenti rilevanti per la query è sicuramente superiore al caso in cui la query non contenga parole con sinonimi.")
12
Polisemia e Sinonimia Il problema della sinonimia può essere risolto facendo ricorso a risorse lessicali come i thesauri, i quali, data una certa parola, permettono di trovarne i sinonimi. Invece la risoluzione della polisemia avviene attraverso il processo di disambiguazione semantica (in inglese Word Sense Disambiguation WSD). La realizzazione di un algoritmo efficiente per la disambiguazione semantica è tuttora un problema aperto nel campo dell'elaborazione del linguaggio naturale.
. La realizzazione di un algoritmo efficiente per la disambiguazione semantica è tuttora un problema aperto nel campo dell elaborazione del linguaggio naturale..")
13
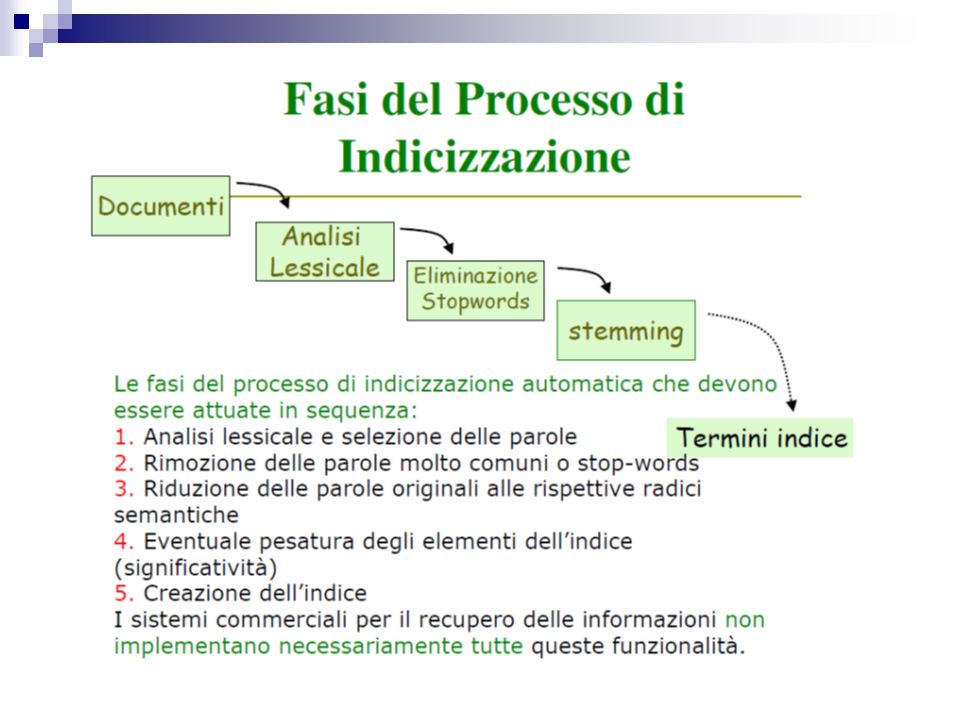
… Descriviamo ora il processo di indicizzazione

14
Processo di indicizzazione Manuale: è una persona che sceglie quali termini meglio caratterizzano il contenuto di un documento Più semantico e quindi migliore Soggettivo, costoso Linguaggio controllato Automatico: fatto da un programma Più sintattico, su base statistica e quindi peggiore Economico, scalabile Linguaggio libero

15
Indicizzazione: controllata versus non controllata Controllata: controllabilità del dizionario, quindi possibilità di decidere a priori quali descrittori utilizzare per indicizzare una collezione di documenti; linsieme di descrittori che forma il dizionario è prefissato ma, interrogazioni e documenti sono indicizzati con descrittori che devono appartenere al dizionario indicizzazione manuale di solito controllata per ridurre lincoerenza tra gli indicizzatori precisa, ma può essere incompleta e le interrogazioni potrebbero non essere soddisfatte

16
Indicizzazione: controllata versus non controllata Incontrollata o non controllata: forma il dizionario man mano che i documenti sono elaborati il dizionario è costituito da tutti i descrittori che appaiono almeno una volta in almeno un documento può essere imprecisa, ma le interrogazioni sono soddisfatte con maggiore successo

17
Qualità dellindicizzazione Finalità: rappresentare il contenuto semantico di un documento con due obbiettivi: Esaustività: assegnare un grande numero di termini indice Specificità: il grado di specificità del linguaggio utilizzato termini generici: non sono adatti a distinguere i documenti rilevanti da quelli irrilevanti termini specifici: permettono di reperire pochi documenti, ma la maggior parte di questi è rilevante Modalità: estrazione diretta dal documento intero (full text) o mediante lutilizzo di fonti esterne (es: dizionari controllati) tecniche associative (tesauri, pseudo-tesauri, clustering)
 o mediante lutilizzo di fonti esterne (es: dizionari controllati) tecniche associative (tesauri, pseudo-tesauri, clustering)")
18
Esaustività E la capacità dellindice di rappresentare il contenuto informativo della collezione Lesaustività dipende dal numero di descrittori assegnati a ciascun documento e dal numero di documenti a cui è stato assegnato un descrittore Se si rappresentasse un indice con una matrice in cui le righe sono i documenti, le colonne sono i descrittori e un elemento è la frequenza del descrittore nel documento, unindicizzazione ad elevata esaustività sarebbe rappresentata da una matrice densa, ovvero un indice in cui un descrittore è assegnato a molti documenti e un documento è descritto da molti descrittori

19
Specificità Capacità dellindice di discriminare i documenti tra loro sulla base del contenuto informativo Se lindice è in grado di discriminare i documenti, allora la collezione viene indirettamente organizzata in sottocollezioni in cui i documenti condividono aspetti comuni del proprio contenuto informativo Nellindicizzazione ad elevata specificità, un descrittore è assegnato a pochi documenti e, se il descrittore è utilizzato nellinterrogazione, il numero di documenti reperiti è più basso del numero di documenti reperiti nel caso di unindicizzazione esaustiva

20
Esaustività versus Specificità In generale la decisione principale che deve essere presa da un indicizzatore, sia esso manuale che automatico, è relativa allassegnazione di un descrittore ad un documento Se la decisione è quella dassegnare il descrittore, allora aumenta lesaustività e diminuisce la specificità; ciò comporta un maggiore richiamo ed una minore precisione Se si decide di non assegnare il descrittore, diminuisce lesaustività e aumenta la specificità, avendo un minore richiamo ed una maggiore precisione Ogni decisione comporta, quindi, un costo che si riflette sullefficacia del reperimento; assegnare il descrittore al documento con un peso aiuta

21
Indicizzazione manuale Lindicizzazione manuale può essere fatta usando parole estratte dal testo o termini controllati, o descrittori, estratti da un thesaurus preesistente. In generale viene utilizzato un linguaggio controllato; questa scelta presenta diversi vantaggi: semplificazione del processo di indicizzazione indipendenza, o minor dipendenza, dal soggetto che effettua lindicizzazione semplificazione dell uso da parte degli utenti ( se conoscono il linguaggio di indicizzazione)
.")
22
Indicizzazione manuale: pro e contro Vantaggio: permette una rappresentazione indiretta del contenuto dei documenti con termini che evidenziano i concetti in essi trattati Svantaggio: può portare a rappresentazioni non accurate né consistenti se non è fatta da persone con una buona conoscenza dellargomento trattato nel documento. Una rappresentazione è accurata quando viene fatta usando un numero adeguato di termini; contrariamente si pregiudica il richiamo del sistema. Una rappresentazione è consistente se documenti che trattano lo stesso argomento vengono rappresentati, anche da persone diverse, con gli stessi termini; contrariamente si pregiudica la precisione del sistema. In generale, comunque, con lindicizzazione manuale è difficile garantire rappresentazioni accurate e consistenti.

23
Indicizzazione automatica Lindicizzazione automatica (automatic indexing) di un documento testuale è il processo che esamina automaticamente gli oggetti informativi che compongono il documento e, utilizzando degli algoritmi appositi, produce una lista di termini indici (index terms). Questa lista può essere utilizzata per una rappresentazione più compatta del contenuto informativo del documento di partenza. Tipicamente: indicizzazione full-text. I termini indice sono utilizzati come surrogati per la rappresentazione del documento originale e quindi possono essere utilizzati al suo posto durante la fase di recupero Luso del thesaurus è previsto anche per lindicizzazione automatica per sostituire termini estratti automaticamente con termini più specifici o più generali.

24
Schema del processo di indicizzazione automatica di documenti testuali

25
Indicizzazione automatica Lindicizzazione automatica si basa su tecniche statistiche, partendo dal presupposto che la frequenza di occorrenza delle parole in un testo in linguaggio naturale sia correlata con limportanza di queste parole nel rappresentare il suo contenuto. Se invece che un singolo documento si considera una raccolta di documenti, per stabilire quali parole chiave scegliere nellindicizzazione, si tiene conto anche di come esse siano distribuite nella raccolta: se una parola appare con una frequenza alta in tutti i documenti, allora diminuisce la sua importanza. Si pensi alla parola calcolatore in una raccolta di testi di informatica.

26
Considerazioni sulla frequenza dei termini Termini funzionali avverbi, articoli, preposizioni ecc. es., "and", "or", "of", "but", … la frequenza di questi termini è alta in tutti i documenti le parole in assoluto più frequenti sono anche poco significative le 250 parole più comuni coprono in media il 40- 50% di un testo Quello che conta non è la frequenza assoluta ma la frequenza relativa Termini indicatori del contenuto parole che identificano i contenuti del documento hanno frequenza variabile da un documento allaltro della collezione la loro frequenza è indicativa dellimportanza nel rappresentare il contenuto del documento

28
Analisi lessicale e selezione della parole E il processo di trasformazione di un flusso di caratteri di input (il testo originario del documento) in un flusso di parole (token) ovvero una sequenza di caratteri portatore di uno specifico significato Nel testo le parole possono essere facilmente identificate grazie alla presenza di spazi, a capo, segni di interruzione, etc…
 in un flusso di parole (token) ovvero una sequenza di caratteri portatore di uno specifico significato Nel testo le parole possono essere facilmente identificate grazie alla presenza di spazi, a capo, segni di interruzione, etc…")
31
Esempio Eliminazione delle parole comuni Stralcio di una lista di esclusione per la lingua inglese: A ALMOST AMONGST ANYWHERE ABOUT ALONE AN ARE ACROSS ALONG AND AROUND AFTER ALREADY ANOTHER AS AFTERWORDSALSO ANY AT AGAIN ALTHOUGH ANYHOW BE AGAINST ALWAYS ANYONE BECAME ALL AMONG ANYTHING BECAUSE

33
Esempio Riduzione delle parole alla radice Si utilizzano liste di suffissi: Es. calcol[are] calcol[atore] calcol[atrice] calcol[abilità] calcol[o]

49
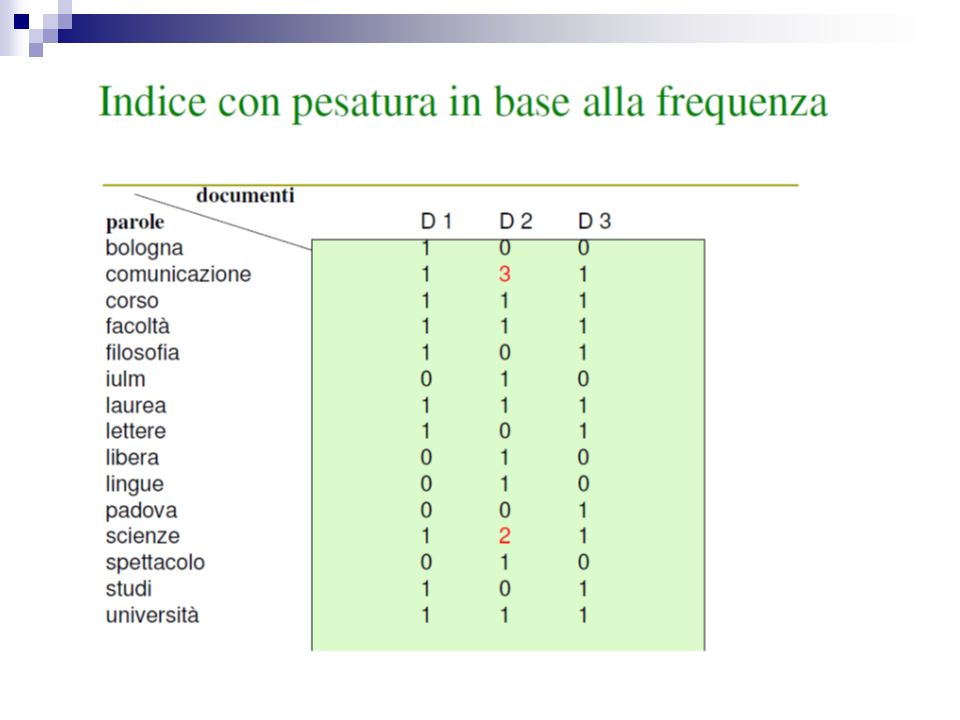
Termini pesati Lefficacia dellindicizzazione aumenta se ai termini che caratterizzano un documento si assegna un peso che rifletta limportanza del termine per il documento. Se n sono i termini usati per lindicizzazione, il documento D della raccolta viene rappresentato dal vettore D = (T1, …, Tn), dove ogni Ti è il peso del termine nel documento. Una raccolta di documenti si riduce cosi ad una matrice di termini con tante righe quanto sono i documenti e tante colonne quanti sono i termini usati per lindicizzazione.
, dove ogni Ti è il peso del termine nel documento. Una raccolta di documenti si riduce cosi ad una matrice di termini con tante righe quanto sono i documenti e tante colonne quanti sono i termini usati per lindicizzazione..")
50
Termini pesati Fra le funzioni proposte per il calcolo del peso di un termine la più usata tiene conto sia della sua rappresentatività considerando la frequenza di occorrenza in un documento sia della capacità del termine di discriminare un documento dagli altri Se ad es il linguaggio di indicizzazione è: {Arbusto, Architettura, botanica, coltivazione, colonna, pianta, Rinascimento, Roma,....}, il vettore rappresenta un documento in cui arbusto ha peso 0, architettura ha peso 4, botanica ha peso 0,.........

51
Termini pesati I pesi w possono essere binari o valori reali o interi positivi: sono calcolati in fase di indicizzazione

52
Indicizzazione automatica: un algoritmo

53
Indicizzazione automatica: i problemi Identificare le soglie di frequenza minima e massima eliminare i termini molto frequenti abbassa il Richiamo eliminare i termini poco frequenti abbassa la Precisione Un buon termine indice: deve rendere reperibile il documento (Richiamo) deve essere in grado di distinguere il documento all interno dell intera collezione (Precisione) non può essere un termine presente in tutti i documenti è molto frequente in alcuni documenti (ipotesi del minimo sforzo) non è molto frequente nell intera collezione di documenti
 deve essere in grado di distinguere il documento all interno dell intera collezione (Precisione) non può essere un termine presente in tutti i documenti è molto frequente in alcuni documenti (ipotesi del minimo sforzo) non è molto frequente nell intera collezione di documenti")
54
Osservazioni Sono stati effettuati numerosi esperimenti per valutare le prestazioni dei sistemi che adottano lindicizzazione automatica. Esperimenti eseguiti su piccole collezioni (meno di 1.000 documenti) hanno mostrato che non sempre lindicizzazione manuale porta a risultati migliori dellindicizzazione automatica, totale o incompleta. Lapproccio manuale, anche se qualitativamente superiore, non è scalabile In certi domini (es. Web) lindicizzazione automatica è lunica possibile
 hanno mostrato che non sempre lindicizzazione manuale porta a risultati migliori dellindicizzazione automatica, totale o incompleta. Lapproccio manuale, anche se qualitativamente superiore, non è scalabile In certi domini (es. Web) lindicizzazione automatica è lunica possibile.")
57
Sistemi per il recupero delle informazioni RECUPERO

58
Processo di ricerca di informazioni 1. Lutente specifica un bisogno informativo... 2. che viene analizzato e trasformato utilizzando le stesse operazioni sul testo applicate alla collezione; 3. la query viene eventualmente trasformata … 4. per poi essere eseguita, utilizzando indici precedentemente costruiti, al fine di trovare documenti rilevanti; 5. i documenti trovati vengono ordinati in base alla probabilità che siano rilevanti e ritornati in tale ordine allutente; 6. lutente esamina i documenti ritornati ed eventualmente raffina la query, dando il via ad un nuovo ciclo.

59
TECNICA DI RECUPERO Allinterno dellIRS, lesecuzione di una richiesta utente di una ricerca di documenti avviene confrontando la rappresentazione del contenuto dei documenti (surrogato) con la rappresentazione della richiesta utente (interrogazione). In questo processo di confronto, lIRS adotta una particolare tecnica di recupero dei documenti, che serve per giudicare quali documenti sono rilevanti, e in che misura, rispetto allinterrogazione. La presenza di documenti non rilevanti come risultato di una richiesta utente e, contemporaneamente, lassenza di alcuni documenti rilevanti, è da imputare sia al processo di trasformazione dal problema informativo allinterrogazione, sia al processo di trasformazione dal contenuto dei documenti al loro surrogato. DEFINIZIONE Si definisce tecnica di recupero (retrieval technique) di un IRS la tecnica adottata dal sistema per confrontare linterrogazione utente con il surrogato dei documenti.
 di un IRS la tecnica adottata dal sistema per confrontare linterrogazione utente con il surrogato dei documenti..")
60
TIPI DI TECNICHE DI RECUPERO La tecnica di recupero adottata da un IRS è il meccanismo interno del sistema che lo guida nel giudicare come rilevanti o non rilevanti i documenti di una raccolta, in rapporto ad una specifica interrogazione. Le tecniche di recupero sono di due tipi: per corrispondenza esatta (exact match) per similitudine o corrispondenza parziale (partial match)
 per similitudine o corrispondenza parziale (partial match).")
61
TECNICHE DI RECUPERO ESATTE Le tecniche di recupero per corrispondenza esatta sono quelle basate sullassunzione che le informazioni specificate nella richiesta siano esattamente contenute nella componente testuale del documento. Presenta tuttavia alcuni svantaggi: molti documenti rilevanti sono ignorati, se il testo corrisponde solo parzialmente allinterrogazione; i documenti ritrovati non sono ordinati per rilevanza rispetto allinterrogazione; non è possibile tenere in considerazione limportanza relativa di concetti sia nellinterrogazione che nei documenti; la logica del linguaggio di interrogazione risulta spesso complicata; lefficacia dipende dalla misura in cui le due rappresentazioni da confrontare siano basate o meno sullo stesso vocabolario

62
TECNICHE DI RECUPERO RECUPERO PER CORRISPONDENZA ESATTA La richiesta è formulata specificando una condizione sui termini che devono essere presenti nel surrogato del testo da recuperare. Una condizione può essere: semplice, cioè riguardare un solo termine composta, cioè una composizione di condizioni semplici con gli operatori logici AND, OR, NOT. Di solito lettere minuscole e maiuscole vengono trattate allo stesso modo. Il modello booleano è il modello più semplice; si basa sulla teoria degli insiemi e lalgebra booleana. Storicamente, è stato il primo ed il più utilizzato per decenni.

63
TECNICHE DI RECUPERO RECUPERO PER CORRISPONDENZA ESATTA Il recupero per corrispondenza esatta ha due svantaggi. 1. documenti attinenti allargomento, ma privi di termini nella relazione specificata, non sono recuperati e, viceversa, è possibile che siano recuperati documenti contenenti i termini nella relazione specificata ma che in realtà non hanno niente in comune con largomento a cui ci si interessa. 2.il recupero basato sulla coincidenza fra quanto espresso nella richiesta e quanto contenuto nella rappresentazione del testo trascura i documenti la cui rappresentazione corrisponde solo parzialmente alla richiesta, ma che trattano ugualmente largomento voluto.

64
TECNICHE DI RECUPERO PARZIALI Le tecniche di recupero per corrispondenza parziale sono basate sullassunzione che le informazioni specificate nella richiesta possano essere contenute parzialmente nel documento e che i documenti ritrovati possano essere ordinati per valori decrescenti di rilevanza. Queste tecniche consentono una maggiore flessibilità, rispetto alle tecniche per corrispondenza esatta, e sono quelle su cui si concentra, attualmente, il maggiore sforzo di ricerca.

65
TECNICHE DI RECUPERO RECUPERO PER SIMILITUDINE Le richieste vengono di solito formulate elencando alcuni termini che si ritiene descrivano il contenuto dei testi voluti Se il sistema prevede un thesaurus, questo può essere anche usato per sostituire un termine con un suo sinonimo usato per indicizzare i documenti oppure per sostituire termini troppo specialistici, e quindi poco frequenti, con termini più generali, per ridurre il fenomeno del silenzio. Per decidere se un documento debba essere recuperato, il sistema fa una valutazione del grado di similitudine dei documenti presenti con la descrizione di quelli richiesti.

66
COME VALUTARE IL GRADO DI SIMILITUDINE Modo più semplice: contare i termini della richiesta presenti nel documento. Un altro modo è di sommare il numero delle occorrenze nel documento di ogni termine della richiesta: se D i =(T i1, T i2, …, T in ) rappresenta il documento e Q = (q 1,q 2, …, q n ) la richiesta, in cui q i = 1 se il termine corrispondente è nellinterrogazione, q i = 0altrimenti, oppure, se si usano termini pesati, q i = peso del termine Si calcola la similitudine fra il vettore dellinterrogazione e il vettore di ogni documento come il coseno dellangolo fra i due vettori e si recuperano tutti i documenti con una similitudine superiore ad una soglia stabilita dallutente: TECNICHE DI RECUPERO RECUPERO PER SIMILITUDINE
 rappresenta il documento e Q = (q 1,q 2, …, q n ) la richiesta, in cui q i = 1 se il termine corrispondente è nellinterrogazione, q i = 0altrimenti, oppure, se si usano termini pesati, q i = peso del termine Si calcola la similitudine fra il vettore dellinterrogazione e il vettore di ogni documento come il coseno dellangolo fra i due vettori e si recuperano tutti i documenti con una similitudine superiore ad una soglia stabilita dallutente: TECNICHE DI RECUPERO RECUPERO PER SIMILITUDINE.")
67
OSSERVAZIONI Le tecniche di recupero dei documenti per corrispondenza parziale, basate sul calcolo di un coefficiente di similitudine di un documento rispetto alla richiesta, sono da preferire alle tecniche per corrispondenza esatta. La migliore strategia di ordinamento dei documenti è risultata quella basata sul calcolo della correlazione del coseno, assegnando ai termini associati ad un documento un peso pari alla loro frequenza nel documento e ai termini nella richiesta un peso pari allinversa della loro frequenza nella raccolta.

68
Modelli di IR Uno dei problemi principali dei sistemi di IR è quello di predire quali documenti siano rilevanti e quali no; la rilevanza si ottiene a partire da un algoritmo di ranking, il quale tenta di stabilire, sulla base di una misura di similarità, un ordinamento dei documenti recuperati I documenti in cima alla lista hanno una probabilità maggiore di essere rilevanti. Un tale algoritmo opera secondo dei criteri di rilevanza dei documenti, ossia insiemi di regole che permettono di stabilire quali documenti siano rilevanti e quali no criteri diversi producono differenti modelli di IR. Il modello definisce la filosofia di fondo di un IRS, ovvero attorno a quali principi generali si è sviluppato il sistema. L'uso di un modello concettuale influenza o determina il linguaggio di interrogazione, la rappresentazione dei documenti, la struttura dei file ed i criteri di recupero dei documenti.

69
Modelli: sviluppo temporale Modello booleano – anni: 1950 ancora usato in sistemi industriali e motori di ricerca su documenti Web Modello vettoriale – anni: 1960 sistemi industriali e era il modello utilizzato inizialmente dai motori di ricerca Web Modello probabilistico – anni: 1970 sistemi sperimentali e prototipi di ricerca Modello di analisi della semantica latente – fine anni 1980 Modello statistico della lingua – fine anni 1990 Modello basati su reti ipermediali – fine anni 1980/anni 1990

70
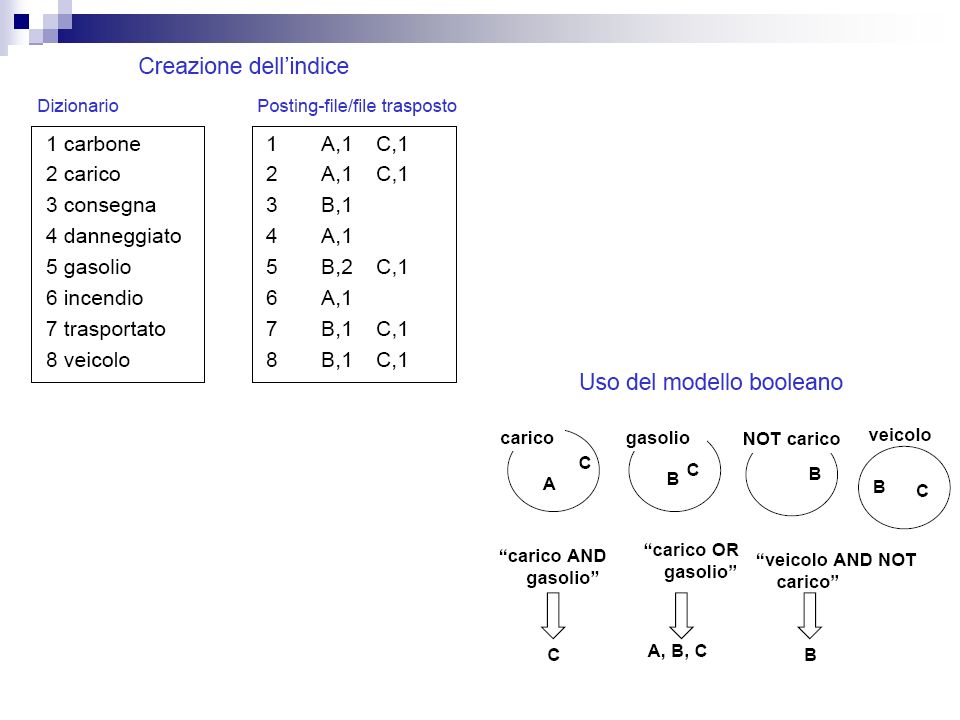
Modello booleano Rappresentazione dei documenti I documenti vengono rappresentati come insiemi di termini che ne rappresentano il contenuto (scelti durante lindicizzazione) Interrogazioni Le query vengono specificate come espressioni booleane, cioè come un elenco di termini connessi dagli operatori booleani AND, OR e NOT. Criterio di corrispondenza La strategia di ricerca è basata su un criterio di decisione binario, senza alcuna nozione di grado di rilevanza: un documento viene considerato rilevante o non rilevante. AND: i termini sono entrambi presenti OR: almeno uno dei due termini è presente NOT: il termine non è presente

71
Esempio (film AND amore) documenti che contengono film e amore (dramma OR drammatico) documenti che contengono dramma o drammatico NOT (dramma OR drammatico) … che non contengono dramma o drammatico ((film AND amore) AND NOT (dramma OR drammatico))
 documenti che contengono film e amore (dramma OR drammatico) documenti che contengono dramma o drammatico NOT (dramma OR drammatico) … che non contengono dramma o drammatico ((film AND amore) AND NOT (dramma OR drammatico))")
72
Modello booleano: indicizzazione I concetti sono rappresentati da descrittori estratti mediante un processo di indicizzazione Lindicizzazione perde dellinformazione e descrive i concetti in modo parziale Se lindicizzazione non conserva informazione su sinonimia e polisemia, i descrittori sono trattati dal modello come espressioni univoche di concetti. Di conseguenza un descrittore t è linsieme di tutti e solo i documenti in cui è presente il concetto espresso da t.

73
Modello booleano Un sistema basato sul modello booleano chiede allutente di: esprimere le proprie esigenze informative utilizzando i descrittori presenti nellindice e costruire nuovi insiemi mediante operatori booleani che allora vengono utilizzati per esprimere nuovi concetti I termini sinonimi sono raggruppati mediante loperatore OR: espressioni disgiuntive del tipo (A OR B) dove A e B sono termini o espressioni disgiuntive Le espressioni disgiuntive si concatenano mediante loperatore AND Il risultato: espressione in forma normale congiuntiva, come, ad esempio: (A OR B) AND (C) Operatore di negazione che si esprime solitamente con NOT esempio: NOT A
 dove A e B sono termini o espressioni disgiuntive Le espressioni disgiuntive si concatenano mediante loperatore AND Il risultato: espressione in forma normale congiuntiva, come, ad esempio: (A OR B) AND (C) Operatore di negazione che si esprime solitamente con NOT esempio: NOT A")
74
Analisi lessicale e/o selezione delle parole Doc. Contenuto/testo del documento A carico di carbone danneggiato in un incendio B consegna di gasolio trasportato da un veicolo a gasolio C carico di carbone trasportato da un veicolo a gasolio Rimozione delle stop-words o delle parole molto comuni Lista o dizionario delle stop-words = {a, da, di, in, un} A carico carbone danneggiato incendio B consegna gasolio trasportato veicolo gasolio C carico carbone trasportato veicolo gasolio

75
Ordinamento lessicografico delle parole Doc. Parole che vengono considerate in ordine A carbone carico danneggiato incendio B consegna gasolio(2) trasportato veicolo C carbone carico gasolio trasportato veicolo Eventuale riduzione alle radici
 trasportato veicolo C carbone carico gasolio trasportato veicolo Eventuale riduzione alle radici.")
77
Osservazioni Il modello booleano ha il vantaggio di essere efficace in ambienti controllati e con utenti bene addestrati ma per contro vi è poco controllo sul numero dei documenti recuperati. E impossibile lordinamento per una qualche misura di similarità la pesatura dei termini Manifesta limitazioni dovute alla bassa amichevolezza della logica booleana. Richiede agli utenti di sapere precisamente cosa cercano. In tale logica un documento è ritenuto rilevante da IRS e quindi recuperato se i termini indice sono elementi semantici e quindi se il documento ha subito quella mappatura necessaria che porta alla sua evidenza semantica.

78
Il modello vettoriale Idea: invece di cercare di predire se un documento è rilevante o no, ordiniamo i documenti secondo il loro grado di similarità rispetto alla query Dobbiamo quindi assegnare uno score (ad esempio compreso tra 0 e 1) ad ogni documento della collezione rispetto alla query formulata Successivamente ritorneremo un elenco di documenti ordinato in base alla probabilità che siano di interesse per l'utente.
 ad ogni documento della collezione rispetto alla query formulata Successivamente ritorneremo un elenco di documenti ordinato in base alla probabilità che siano di interesse per l utente.")
79
Modello vettoriale: documenti Rappresentazione dei documenti una sequenza di numeri lunga quanto il numero di tutti i termini utilizzati per rappresentare i documenti nella collezione, un vettore appunto. D = (t1, t2, …, tn) n numero di termini tk=0 se il termine non è presente altrimenti tk è il peso del termine k-esimo nel documento, una misura di importanza
 n numero di termini tk=0 se il termine non è presente altrimenti tk è il peso del termine k-esimo nel documento, una misura di importanza.")
80
Il modello vettoriale: interrogazione Interrogazione: un insieme di termini Rappresentazione dellinterrogazione: un vettore, simile ai documenti (con moltissimi 0 e qualche 1 in corrispondenza dei termini specificati dallutente) Q(t1, t2, … tn)
 Q(t1, t2, … tn)")
81
Il modello vettoriale: confronto Una misura di similitudine tra documenti e richiesta. Esempio Di(ti1, ti2, ti3, …, tin) Q(q1, q2, q3, …, qn) S(Q, Di) = q1*ti1 + q2*ti2 +... + qn*tin = Σj qj * tij con 0<j <=n
 Q(q1, q2, q3, …, qn) S(Q, Di) = q1*ti1 + q2*ti qn*tin = Σj qj * tij con 0<j <=n.")
82
Esempio Due documenti che trattano di Messina, Stretto e Pilone … Vettori: D1 = [… 0.1, …, 0.1, …, 0.2, …] D2 = [… 0.1, …, 0.9, …, 0.9, …] Interrogazione Q=[… 1, …, 1, …, 1, …] Similitudine Sim(D1, Q)=0,1+0,1+0,2=0,4 Sim(D2,Q)=0,1+0,9+0,9=1,9
![Esempio Due documenti che trattano di Messina, Stretto e Pilone … Vettori: D1 = [… 0.1, …, 0.1, …, 0.2, …] D2 = [… 0.1, …, 0.9, …, 0.9, …] Interrogazione Q=[… 1, …, 1, …, 1, …] Similitudine Sim(D1, Q)=0,1+0,1+0,2=0,4 Sim(D2,Q)=0,1+0,9+0,9=1,9](http://images.slideplayer.it/1/533753/slides/slide_82.jpg "Esempio Due documenti che trattano di Messina, Stretto e Pilone … Vettori: D1 = [… 0.1, …, 0.1, …, 0.2, …] D2 = [… 0.1, …, 0.9, …, 0.9, …] Interrogazione Q=[… 1, …, 1, …, 1, …] Similitudine Sim(D1, Q)=0,1+0,1+0,2=0,4 Sim(D2,Q)=0,1+0,9+0,9=1,9")
83
Sistemi per il recupero delle informazioni Cataloghi

84
Cataloghi e bibliografie come sistemi IR Catalogo Elenco ordinato e sistematico di una o più serie di oggetti, con le indicazioni ad essi relative (tra cui, anche, lindicazione della collocazione di almeno 1 esemplare) Bibliografia Elenco sistematico di opere, saggi e articoli relativi a un determinato autore o argomento Cataloghi online accessibili da ogni punto dove sia collocato un terminale Possono mostrare i dati anche di stato Ricerca flessibile e postcoordinata Gli utenti giocano col catalogo http://www.laterza.it/bibliotecheinrete/index.htm http://www.aib.it/aib/opac/repertorio.htm Repertorio OPAC italiani
 Bibliografia Elenco sistematico di opere, saggi e articoli relativi a un determinato autore o argomento Cataloghi online accessibili da ogni punto dove sia collocato un terminale Possono mostrare i dati anche di stato Ricerca flessibile e postcoordinata Gli utenti giocano col catalogo Repertorio OPAC italiani")
85
Cataloghi Online Public Access Catalog (OPAC) catalogo in rete ad accesso pubblico è il catalogo informatizzato delle biblioteche che ha sostituito i vecchi cataloghi cartacei a partire dagli anni 80 hanno man mano sostituito la maggior parte dei cataloghi a schede i primi OPAC erano accessibili solo da terminali dedicati oppure via telnet gli OPAC oggi sono consultabili da tutti tramite Internet all'interno del proprio browser. Trasferire i cataloghi in banche dati digitali in linea è però un lavoro che richiede molto tempo: in Italia le prime biblioteche hanno cominciato a catalogare in modo automatizzato solo dal 1981 e i volumi acquisiti prima spesso non sono compresi: per cercare queste opere, quindi, l'unica possibilità è recarsi sul posto a consultare i cataloghi a schede.

86
OPAC La prima generazione dei cataloghi in linea è la traduzione compiuta dalla macchina delle schede catalografiche cartacee il loro impiego nelle biblioteche non sfrutta la potenzialità dei DB per cui non apportano sostanziali vantaggi rispetto al catalogo cartaceo il recupero delle informazioni da questi OPAC è possibile solo introducendo nel form lesatto termine nellesatta forma di linguaggio comprensibile dalla macchina non sono disponibili ricerche per parole chiave non è possibile raffinare la query

87
OPAC Lo sviluppo dellinformatica si fa sentire con la seconda generazione di OPAC in quanto tale scienza rende possibile la configurazione di un sistema più sofisticato di recupero dellinformazione Sintroduce la ricerca per parola chiave, la ricerca con operatori booleani, la ricerca incrociata con diversi indici (es. autore e titolo) Laggiornamento informatico della gestione delle banche dati attraverso software di ricerca rende possibile alla seconda generazione di OPAC di arricchire le notizie bibliografiche con sommari, note, links, abstracts. Linterfaccia è resa più immediata dalla presenza di strumenti come lhelp on line.
 Laggiornamento informatico della gestione delle banche dati attraverso software di ricerca rende possibile alla seconda generazione di OPAC di arricchire le notizie bibliografiche con sommari, note, links, abstracts. Linterfaccia è resa più immediata dalla presenza di strumenti come lhelp on line..")
88
OPAC Gli OPAC di terza generazione aggiungono la possibilità di compiere interrogazioni con linguaggio naturale A partire dagli anni ottanta si sviluppano le WIMP (windows, icons, mouse and pointers) interfaces (GUI) che semplificano e rendono la ricerca molto più veloce (quarta generazione) Con queste interfacce lutente ha la possibilità di accedere allinformazione bibliografica da punti diversi dellinterfaccia ognuno dei quali attiva una diversa funzione. Questi sistemi aumentano laccesso per parola chiave Le possibilità di ricerca sono di gran lunga superiori rispetto alle vecchie generazioni. Viene introdotta la funzione ipertesto in base alla quale lutente digitando il termine accede ai richiami correlati trovati allinterno del DB. In questo modo lutente può navigare per la base dati e raggiungere nuove informazioni.

89
OPAC L'OPAC offre molte opportunità in più rispetto ai vecchi cataloghi a schede: fra i criteri di ricerca di solito ci sono l'autore, il titolo, il soggetto, la classificazione, l'ISBN, l'editore, l'abstract, la lingua, l'anno di pubblicazione e la parole chiave (campo ricerca libera); si può filtrare la ricerca con vari criteri o sottocataloghi (ad esempio: Libro moderno, Libro antico, Audio-Video-PC, Grafica, Materiale sonoro e musicale); si possono ricercare libri anche da casa.
; si può filtrare la ricerca con vari criteri o sottocataloghi (ad esempio: Libro moderno, Libro antico, Audio-Video-PC, Grafica, Materiale sonoro e musicale); si possono ricercare libri anche da casa.")
90
OPAC Compilando uno o più campi di ricerca, l'utente ottiene l'elenco delle notizie corrispondenti ai parametri di ricerca inseriti: da qui è possibile raffinare la ricerca inserendo ulteriori filtri, oppure esaminare le informazioni recuperate e restituite in un formato sintetico (spesso una lista comprendente pochi campi principali, quali titolo, autore e anno). L'esame analitico dei record permette all'utente di esaminare l'intera descrizione bibliografica della notizia, e da qui navigare, attraverso i link interni, fra i vari campi della descrizione.

91
OPAC L'Opac consente, a partire dalla notizia recuperata, di visualizzare le sue localizzazioni, ossia le informazioni relative alla biblioteca che possiede quel documento e ai dati gestionali che ne permettono la richiesta (numero d'inventario, collocazione) oltre ad altre informazioni di servizio quali le condizioni di circolazione dell'opera (disponibile per il prestito, attualmente in prestito, ecc.). Molti Opac consentono servizi aggiuntivi quali la prenotazione dei documenti attualmente in prestito, la richiesta di prenotazione, il salvataggio delle ricerche effettuate su spazi personali accessibili con login. Sono sempre più frequenti le integrazioni degli Opac con altri strumenti di recupero dell'informazione, quali il collegamento con altri motori di ricerca, siti di e-commerce, risorse elettroniche on-line, servizi di accesso all full-text attraverso il protocollo Open-URL.

92
Sistemi per il recupero delle informazioni Information Retrieval su web

93
Linformazione bibliografica sul web Siti espressamente bibliografici PubMed Editori commerciali SpringerLink Editori commerciali specializzati IEEE Xplore

94
PUBMED www.ncbi.nlm.nih.gov/pubmed Ambito scientifico: medicina, biologia copertura: dalla metà degli anni 50 tutte le più importanti testate in materia Lingua: Inglese Modalità di interrogazione assai varie abstracts (quasi sempre) link al full text (dove possibile)
 link al full text (dove possibile)")
95
PUBMED - Modalità di interrogazione Ricerca semplice in tutti i campi: AND Key words scelte dallutente Default AND Tutti i campi Troncamento (*) Stopwords ignorate (preposizioni, ecc.) Raffinazione (p.e. data o lingua) Campi, Tipologia di articolo, Data di pubblicazione, Lingua, Periodico, Subset Ricerca in uno specifico campo Ricerca in più campi scelti dallutente Related articles Ricerca per soggetto MeSH
 Campi, Tipologia di articolo, Data di pubblicazione, Lingua, Periodico, Subset Ricerca in uno specifico campo Ricerca in più campi scelti dallutente Related articles Ricerca per soggetto MeSH.")
96
Editori commerciali Gratis search / Advanced search Abstracts A pagamento Full text Spesso sample copy gratuita Springer www.springerlink.com Wiley www3.interscience.wiley.com Elsevier www.scirus.com Kluwer journals.kluweronline.com NPG www.nature.com

97
Editori commerciali – Modalità di ricerca Ricerca semplice (default AND) Ricerca avanzata Citation matcher Per key words Books Ambito disciplinare (p.e. Wiley) CrossRef search (p.e. Wiley) Scirus (www.scirus.com) Motore basato sul full text dei periodici Elsevier + altre basi dati + web Basic search: default AND Exact match Advanced search Abstracts/full text/documentazione scientifica
 CrossRef search (p.e. Wiley) Scirus ( Motore basato sul full text dei periodici Elsevier + altre basi dati + web Basic search: default AND Exact match Advanced search Abstracts/full text/documentazione scientifica.")
98
Enti/Editori commerciali –Modalità di ricerca IEEE (www.ieee.org): ingegneria elettronica BMJ (www.bmj.com): medicina, biologia APS (www.aps.org): fisica RSC (www.rsc.org): chimica APA (www.psycinfo.com): psicologia ASCE (www.asce.org): ingegneria civile Modalità di ricerca IEEE Xplore TOC (periodici, conferences, standard) Search (autore/base/avanzata) Full text search BMJ.com Search (base/avanzata) High Wire hosted journals
 Search (autore/base/avanzata) Full text search BMJ.com Search (base/avanzata) High Wire hosted journals")
99
Information Retrieval su Web LInformation Retrieval è nata per gestire collezioni statiche e ben conosciute: testi di legge, enciclopedie ecc. Quando la collezione di riferimento diventa il Web, le cose cambiano completamente. Per IR su Web si intende la ricerca di pagine Web la collezione che si considera è la parte pubblica del web. Operazione base: un client (browser) invia a un WEB server una richiesta di una pagina web tramite il protocollo HTTP:
 invia a un WEB server una richiesta di una pagina web tramite il protocollo")
100
Information Retrieval su Web Per IR su Web si intende la ricerca di pagine Web LIR su Web considera come collezione di documenti la parte del Web che è pubblicamente indicizzabile esclude le pagine che richiedono autorizzazioni, (es. intranets) e le pagine dinamiche ecc. Tassonomie o direttori Yahoo (+ di 1000 nodi) About.com, Open Directory project DMOZ Nel 2000 Google fu il primo Search Engine (SE) su Web a indicizzare più di 1 miliardo di Pagine Web
 e le pagine dinamiche ecc. Tassonomie o direttori Yahoo (+ di 1000 nodi) About.com, Open Directory project DMOZ Nel 2000 Google fu il primo Search Engine (SE) su Web a indicizzare più di 1 miliardo di Pagine Web.")
101
Information Retrieval su Web Le principali differenze tra Information Retrieval classico e Web Information Retrieval possono essere riassunte nei seguenti punti: dinamicità la dimensione del Web non è costante, a differenza delle collezioni testuali; dimensioni la dimensione del Web era di 4 miliardi di pagine ad Aprile 2001 eterogeneità Internet contiene un'ampia varietà di tipi di documenti: immagini, file audio, testuali, etc.; linguaggi sul Web è possibile incontrare quasi ogni linguaggio parlato sulla superficie del pianeta, mentre le collezioni utilizzate nell'Information Retrieval tradizionale sono spesso scritte in una sola lingua; ridondanza si stima che sul Web il 30% delle pagine siano duplicate;

102
Information Retrieval su Web ipertesto i documenti nel Web sono collegati tra loro: si stima che una pagina Web abbia in media più di 8 links ad altre pagine; query formulation le query sul Web sono in genere più corte e non particolarmente strutturate; varietà degli utenti gli utenti del Web variano sensibilmente in conoscenze, necessità ed aspettative, mentre, ad esempio,un utente di una biblioteca digitale avrà bisogni ed aspettative costanti; pigrizia degli utenti si stima che l'85% degli utenti del Web si fermano alla prima schermata di risultati ritornati dal motore di ricerca. Il 78% non riformula la query iniziale.

103
Caratteristiche del Web Può essere visto come una collezione non-strutturata e distribuita molto grande +3 milioni di servers interconnessi su internet (gestiti da circa 1,5 milioni di istituzioni diverse) 800 milioni di pagine pubbliche (Lawrence and Giles, Nature, 1999) tasso di crescita biennale pari al 100% per il Web. Contiene diversi tipi di dati (testi, immagini, suoni, video) molte pagine non sono accessibili ai motori di ricerca Una pagina Web corrisponde a un documento nellIR tradizionale
 molte pagine non sono accessibili ai motori di ricerca Una pagina Web corrisponde a un documento nellIR tradizionale.")
104
DATI Web Pagine Web struttura delle singole pagine (Intra-page) disomogenea per genere, struttura, tipo, formato, lingua, qualità, veridicità/affidabilità contenuto Struttura del Web (Inter-page) numero medio di in-link e out-link a una pagina è tra 8 e 15, i link non sono distribuiti in modo casuale, Dati sullUtilizzo delle pagine (#accessi) Dati supplementari User Profile, Informazioni di Registrazione, Cookies
 disomogenea per genere, struttura, tipo, formato, lingua, qualità, veridicità/affidabilità contenuto Struttura del Web (Inter-page) numero medio di in-link e out-link a una pagina è tra 8 e 15, i link non sono distribuiti in modo casuale, Dati sullUtilizzo delle pagine (#accessi) Dati supplementari User Profile, Informazioni di Registrazione, Cookies")
105
RICERCHE SU WEB Problematiche relative ai dati: grandi quantità (miliardi di pagine ) scalabilità i dati sono distribuiti affidabilità/appropriatezza delle sorgenti e delle connessioni volatilità dei dati ( Garcia e Molina 2002 hanno stimato che il 40% delle pagine nei domini.com e il 23% in media cambia giornalmente) aggiornamento dei dati e degli indirizzi ridondanza dei dati (circa il 40% dei dati è duplicato) e ridondanza semantica eliminazione duplicati qualità dei dati (dati non validi, obsoleti, con errori) stima dellaffidabilità (trust) eterogeneità dei dati (media, formati, strutture, lingue, alfabeti diversi) Le pagine Web differiscono in: dimensione, struttura, tipo (testo, grafici, suoni, immagini, video), formato (HTML, GIF, JPEG, ASCII, PDF, ecc), lingua, alfabeto, genere Problematiche relative allinterazione con utente: Utenti non esperti (query media 2 –3 termini) come specificare le richieste? Come presentare grandi quantità di documenti reperiti?

106
RICERCHE SU WEB Esistono varie modalità di ricerca: ricerca diretta dato URL o navigazione (browsing) percorrendo la struttura definita dai link Sistemi di filtering utilizzo di servizi WEB per la ricerca: motori di ricerca che indicizzano una porzione di pagine Web e permettono allutente di formulare query e reperire indirizzi di pagine web pertinenti (Altavista, Google) portali Web (directory) che oltre a mettere a disposizione un motore di ricerca, classificano per argomento le pagine Web di qualità e forniscono uninterfaccia per la navigazione del catalogo delle pagine (Yahoo, infoseek, Virgilio) Meta-motori di ricerca utilizzano diversi motori di ricerca per valutare la query e fondono le liste (MetaCrawler, Mamma, Dogpile)
 percorrendo la struttura definita dai link Sistemi di filtering utilizzo di servizi WEB per la ricerca: motori di ricerca che indicizzano una porzione di pagine Web e permettono allutente di formulare query e reperire indirizzi di pagine web pertinenti (Altavista, Google) portali Web (directory) che oltre a mettere a disposizione un motore di ricerca, classificano per argomento le pagine Web di qualità e forniscono uninterfaccia per la navigazione del catalogo delle pagine (Yahoo, infoseek, Virgilio) Meta-motori di ricerca utilizzano diversi motori di ricerca per valutare la query e fondono le liste (MetaCrawler, Mamma, Dogpile)")
108
Motore di Ricerca per il Web ATTIVITA Raccolta dei Documenti: (copertura di circa il 20 % del web) Durante la visita le pagine sono arricchite di vari tag con meta- informazioni Indicizzazione dei Documenti statica e periodica dinamica: vengono mantenuti 2 indici (completo + ridotto per valutare FAQ) + dati ausiliari (data di raccolta, URL, titoli, autore) Ricerca processo di retrieval (algoritmi di ricerca e ranking di pagine web) Gestione di Documenti e di query visualizzazione dei risultati gestione della collezione virtuale (i documenti vengono eliminati dopo essere stati indicizzati) vs. collezione reale (i documenti vengono mantenuti dopo lindicizzazione)
.")
109
Motore di Ricerca per il Web Le componenti basilari di un motore di ricerca sono tre un indicizzatore processa i documenti recuperati dal crawler e li rappresenta in una struttura dati efficiente un crawler programma che naviga nel Web alla ricerca di pagine da collezionare. un server per le query accetta le query dell'utente e ritorna i risultati attraverso l'esame delle strutture dati. Le prestazioni del query server sono critiche dal momento che un grande numero di utenti può essere collegato contemporaneamente e i tempi di attesa lunghi allontanano gli utenti dal sistema.

110
Raccolta dei Documenti Esistono due modalità: Le pagine Web vengono fornite (spedite) direttamente al motore di ricerca dai proprietari (funzione di upload URL) Il motore di ricerca è dotato di un un agente software (information agent) detto crawler, (alias spider o robot) che attraversa il web per spedire pagine nuove o aggiornate a un server che le indicizza. Il crawler naviga su web usando come punti di partenza URL note per essere punti di accesso interessanti (es. Open Directory Project www.dmoz.org), e successivamente visita altre pagine web percorrendo i link che vanno da una pagina allaltra

111
Problemi del Crawling Correttezza (non sovraccaricare di richieste un web server o visitare pagine riservate) Efficienza: la banda e la latenza della connessione del server remoto può variare Si deve decidere quanto in profondità nella gerarchia di un web server ci si deve spingere Ci possono essere siti mirror e pagine duplicate Pagine di SPAM Trappole per i crawler incluse le pagine generate dinamicamente E un processo che richiede lapplicazione di tecniche distribuite
 Efficienza: la banda e la latenza della connessione del server remoto può variare Si deve decidere quanto in profondità nella gerarchia di un web server ci si deve spingere Ci possono essere siti mirror e pagine duplicate Pagine di SPAM Trappole per i crawler incluse le pagine generate dinamicamente E un processo che richiede lapplicazione di tecniche distribuite")
112
Crawling

114
Indicizzazione di pagine Web Per Indicizzazione si intende l'inserimento di un sito web nel database di un motore di ricerca, mediante l'uso di apposite parole-chiave. generalmente è un procedimento che le aziende di web hosting forniscono a pagamento, ma che si può svolgere anche in proprio. gli algoritmi di indicizzazione di pagine web sono brevettati Si usano le stesse tecniche dellIR testuale full-text, ma ogni SE ha un suo algoritmo. alcuni SE non indicizzano in full text le pagine, ma solo parte di esse (prime 3-4 migliaia di parole) Il parser scarta tutti i comandi HTML Alcuni motori di ricerca eliminano le stopwords per ridurre la dimensione dellindice. Possono venir applicate operazioni di normalizzazione. Alcuni SE calcolano pesi per i termini
 Il parser scarta tutti i comandi HTML Alcuni motori di ricerca eliminano le stopwords per ridurre la dimensione dellindice. Possono venir applicate operazioni di normalizzazione. Alcuni SE calcolano pesi per i termini.")
117
Classificazione dei siti Dopo aver scansionato la rete e quindi indicizzato (nel senso di raggruppato) una grandissima mole di pagine web, il motore di ricerca passa alla seconda fase: classificarle e posizionarle in base a delle parole chiave che rispecchino il più possibile il sito. In questo modo i motori di ricerca, tramite particolari algoritmi, assicurano ai loro utenti contenuti validi e aggiornati. Ogni motore utilizza algoritmi particolari, come il PageRank di Google, che attribuisce ad una pagina un'importanza che dipende dal numero di collegamenti che puntano a tale pagina dagli altri siti internet. I tempi di indicizzazione di un sito internet possono variare da poche settimane ai tre mesi. Nel caso si utilizzi il servizio pay per inclusion l'indicizzazione avviene dopo pochi giorni, versando una somma per ogni pagina che si intende far indicizzare. Con questo metodo l'inserimento della pagina è garantito.

119
Raffinazione della ricerca La possibilità di raffinazione della ricerca varia da motore a motore, ma la maggior parte permette di utilizzare operatori booleani ad esempio è possibile cercare "Ganimede AND satellite NOT coppiere" per cercare informazioni su Ganimede inteso come pianeta e non come figura mitologica. Su Google e sui motori più moderni è possibile raffinare la ricerca a seconda della lingua del documento, delle parole o frasi presenti o assenti, del formato dei file (Microsoft Word, PDF, PostScript, ecc.), a seconda della data di ultimo aggiornamento, e altro ancora. È anche possibile cercare contenuti presenti in un determinato sito, ad esempio "Ganimede site:nasa.gov" cercherà le informazioni su Ganimede presenti sul sito della NASA.
, a seconda della data di ultimo aggiornamento, e altro ancora. È anche possibile cercare contenuti presenti in un determinato sito, ad esempio Ganimede site:nasa.gov cercherà le informazioni su Ganimede presenti sul sito della NASA..")
121
Posizionamento Con il termine posizionamento s'intende l'acquisizione di visibilità tra i risultati dei motori di ricerca. E l'operazione attraverso la quale il sito viene ottimizzato per comparire nei risultati in una posizione il più possibile favorevole e rilevante. Le pagine di risposta di una ricerca online ospitano sia risultati veri e propri sia inserzioni a pagamento. Quindi il posizionamento può essere di due tipi: posizionamento puro o naturale che si ottiene mediante azioni di ottimizzazione del sito nel caso delle inserzioni a pagamento, il posizionamento è influenzato dalle leggi del marketing sui motori di ricerca dove la visibilità è direttamente proporzionale alla spesa sostenuta.

122
Prospettive di sviluppo Le più recenti innovazioni nella produzione di algoritmi e di sistemi di Information Retrieval si basano sull'analisi semantica dei termini e sulla conseguente creazione di reti semantiche. Lo stesso Google ha adottato sistemi per la prevenzione dell'errore e la contestualizzazione dei risultati. È lecito prevedere che nel giro di alcuni anni i motori di ricerca baseranno le proprie tecnologie sia sull'analisi quantitativa dei contenuti (le parole in sé), sia soprattutto su quella qualitativa (il senso delle parole). i motori di ricerca saranno, ad esempio, in grado di distinguere il senso della parola "pesca" a seconda di quale sia il contesto in cui la parola è contenuta (capire se sia il frutto, la disciplina sportiva, o altro).
, sia soprattutto su quella qualitativa (il senso delle parole). i motori di ricerca saranno, ad esempio, in grado di distinguere il senso della parola pesca a seconda di quale sia il contesto in cui la parola è contenuta (capire se sia il frutto, la disciplina sportiva, o altro)..")
123
Google Google è un motore di ricerca per Internet che non si limita a catalogare il World Wide Web, ma si occupa anche di immagini, foto, newsgroup, notizie, mappe, video, oltre a mantenere una copia cache di tutte le pagine che conosce. Con un indice che comprende più di otto miliardi di pagine Web, è riconosciuto come il più grande e affidabile tra i motori di ricerca, occupandosi attraverso il suo sito di oltre il 70% di tutte le ricerche effettuate su internet.

124
Query in Google Per cercare testi dove compaiono in sequenza due o più parole chiave occorre separarle col segno "+ es. l'istruzione "wikipedia+google" fa comparire le pagine in cui compare la parola wikipedia subito seguita da google. Nelle posizioni più basse (con minore ranking) si trovano le pagine che risultano anche da una ricerca senza l'operatore "+" Loperatore + non è l'operatore booleano "AND", in quanto oltre a cercare entrambi i termini nel testo, li cerca uno di seguito all'altro. Per cercare invece solo i risultati che contengono le due parole in sequenza si usano le virgolette ("), si scrive quindi la frase desiderata tra virgolette, e google troverà solo i risultati che contengono l'intera frase. In maniera complementare, l'operatore "-" esclude i testi che contengono una certa parola chiave, e funziona da filtro es. "wikipedia -google" ricerca alcune pagine di Wikipedia, in ciascuna delle quali non compare la parola "google".
 si trovano le pagine che risultano anche da una ricerca senza l operatore + Loperatore + non è l operatore booleano AND , in quanto oltre a cercare entrambi i termini nel testo, li cerca uno di seguito all altro. Per cercare invece solo i risultati che contengono le due parole in sequenza si usano le virgolette ( ), si scrive quindi la frase desiderata tra virgolette, e google troverà solo i risultati che contengono l intera frase. In maniera complementare, l operatore - esclude i testi che contengono una certa parola chiave, e funziona da filtro es. wikipedia -google ricerca alcune pagine di Wikipedia, in ciascuna delle quali non compare la parola google ..")
125
Query in Google Se il testo è racchiuso fra doppie virgolette, Google ricerca le pagine Web che contengono esattamente la sequenza di caratteri digitata, senza altri spazi o caratteri intermedi. Esempio: "enciclopedia wikipedia" fornirà tutte le pagine che contengono di seguito le due parole digitate. Il carattere jolly è il simbolo di asterisco. Esempio: "enciclopedia * wikipedia" fornirà tutte le pagine che contengono le due parole digitate di seguito e con un ulteriore stringa di caratteri intermedia. Fornirà quindi anche "enciclopedia multilingue wikipedia", "enciclopedia, wikipedia", ma non "enciclopedia libera e multilingue wikipedia", che contiene più di un termine fra le due parole separate da asterisco

126
Query in Google Per effettuare una ricerca di parole chiave all'interno di un sito occorre digitare l'istruzione: site:nomesito.com uno spazio bianco e le parole chiave. Per cercare la definizione di un termine o il significato di un acronimo basta digitare nel campo di ricerca di Google "define: termine" dove "termine" indica la parola da cercare. Ad esempio "define: TCP" darà come risultato la definizione della sigla. I risultati di Google-define spesso sono di Wikipedia. Digitando "1 to USD" google convertirà il valore di un euro in dollari americani. Funziona con tutte le valute e con le unità di misura di tutto il mondo. Per indicizzare una pagina occorre scrivere nella barra degli indirizzi www.google.it/addurl.html e nella pagina aperta digitare URL della pagina web e parole chiave. Se Google indicizza la pagina, digitando le parole chiave scelte essa comparirà fra i risultati.

127
Page rank Il PageRank è un voto su una scala da 0 a 10 che Google attribuisce a una pagina web in base al suo grado di pertinenza e ai suoi contenuti. Il PageRank è calcolato sulla base di diversi criteri: visite giornaliere, collegamenti alla pagina da altre pagine web, l'estensione del dominio, il PageRank dell'homepage, e altro. Il pagerank è facilmente riconducibile al concetto di popolarità tipico delle relazioni sociali umane, ed indica, o si ripromette di indicare, le pagine o i siti di maggiore rilevanza in relazione ai termini ricercati. Gli algoritmi che rendono possibile l'indicizzazione del materiale presente in rete utilizzano anche il grado di popolarità di una pagina web per definirne la posizione nei risultati di ricerca.

128
Page rank Questo metodo può esser descritto come analogo ad una elezione nella quale ha diritto al voto chi può pubblicare di una pagina web, e il voto viene espresso attraverso i collegamenti in essa presenti. I voti non hanno tutti lo stesso peso: le pagine web più popolari esprimeranno, coi propri link, voti di valore maggiore. L'interpretazione e la definizione della popolarità di un sito non sono però legate soltanto a queste votazioni, ma tengono conto anche della pertinenza del contenuto di una pagina, nonché delle pagine correlate, con i termini ed i criteri della ricerca effettuata. Altro importante elemento che lega un sito alla sua popolarità è relativo alla diffusione, alla popolarità dell'argomento trattato in esso. Per argomenti poco richiesti i siti raggiungono facilmente le prime posizioni nelle ricerche, ma altrettanto verosimilmente posseggono e mantengono un page rank che potrebbe essere bassissimo. Tutto questo permette, o perlomeno ha lo scopo, di attuare un controllo incrociato che garantisca la validità dei risultati di ricerca.

129
Sistemi per il recupero delle informazioni MULTIMEDIA INFORMATION RETRIEVAL

130
Stato dellarte Stato dell'arte del multimedia information retrieval processo di rivoluzione dei sistemi di trattamento dell'informazione digitale, necessitata dalla già avvenuta rivoluzione dei documenti digitali e dei processi informativi e comunicativi. Fino a non molto tempo fa l'information retrieval si è prospettato come un dominio privilegiato dei bibliotecari, dei documentalisti e degli specialisti dell'informazione Negli ultimi anni l'IR si è notevolmente evoluto, parallelamente alle sfide poste dall'espansione del Web e dallo sviluppo delle tecnologie dell'informazione e della comunicazione. il delinearsi di nuove modalità di comunicazione e condivisione delle informazioni ha dato luogo a quella che è stata definita la «convergenza al digitale».

131
Stato dellarte La centralità dei documenti multimediali nell'odierna società dell'informazione e gli strumenti offerti dalle tecnologie digitali hanno favorito la creazione di basi di dati multimediali, di ben altro livello di complessità rispetto alle basi di dati tradizionali, sviluppando pienamente le premesse del concetto di digital library. Le multimedia digital library sono caratterizzate da una gestione e un accesso integrati per documenti eterogenei, attraverso l'impiego di specifici sistemi per l'indicizzazione, la ricerca e l'estrazione automatica di dati rappresentativi del complesso contenuto dei documenti multimediali (immagini, video, audio), che si vanno ad affiancare ai tradizionali sistemi manuali di analisi e indicizzazione terminologica dei documenti testuali o audiovisivi.
, che si vanno ad affiancare ai tradizionali sistemi manuali di analisi e indicizzazione terminologica dei documenti testuali o audiovisivi..")
132
Stato dellarte Poiché la qualità del recupero delle informazioni è largamente influenzata dall'interazione dell'utente con il sistema, anche nei confronti dell'utente molto deve cambiare, e il sistema di approccio ai database multimediali deve essere riformulato sulla base delle più complesse esigenze di definire la query con dati visivi e sonori e non soltanto con dati terminologici. Alle tradizionali interfacce dei database testuali, che consentono la ricerca in un indice composto esclusivamente di termini estratti dai documenti, si devono quindi sostituire interfacce che permettano di formulare le query in diverse dimensioni, non solo tramite i termini ma anche attraverso le immagini e i suoni la ricerca sarà così effettuata in indici composti da testi estratti dalle didascalie o dal parlato, da immagini chiave di una sequenza, da semplici figure, da melodie, da forme, colori e suoni

133
Multimedia IR Il crescente utilizzo dell'IR in ambito commerciale e scientifico ha stimolato un preciso interesse da parte della computer science, che a differenza della biblioteconomia e della documentazione ha affrontato tali tematiche con una prospettiva focalizzata sugli algoritmi e sulle tecniche di elaborazione dei dati. In tale ottica il problema consiste nella costruzione di indici efficienti, nell'elaborazione di query con un alto livello di performance e nello sviluppo di algoritmi di ranking che migliorino la qualità della risposta. Le ricerche si sono perciò estese alla modellizzazione dei dati, alla categorizzazione dei documenti, alle architetture di sistema, alle interfacce interattive, ai processi di filtering e alle multimedial query.

134
Multimedia IR Il distacco principale tra i sistemi di archiviazione e recupero di documenti testuali e quelli di documenti multimediali si focalizza nel sistema di analisi ed estrazione degli elementi indicatori del contenuto del documento e dei descrittori specifici delle sue caratteristiche. Se i sistemi di indicizzazione e ricerca tradizionali sono basati sui termini, sulla logica delle parole chiave i sistemi di recupero più innovativi richiedono invece una riflessione più avanzata sulle caratteristiche intrinseche dei file digitali, sulla semantica e sulla strutturazione degli elementi che compongono un documento, sulle modalità di interazione e restituzione dei risultati delle query all'utente.

135
Multimedia IR sistemi di information retrieval term-based, basati su informazioni testuali (termini estratti dal linguaggio naturale, schemi di classificazione e soggettazione, thesauri), per la ricerca di documenti testuali (e finora spesso anche di documenti audiovisivi); sistemi di information retrieval content-based o multimedia information retrieval: sistemi di visual retrieval in cui i file d'immagine 2D e 3D sono cercati e recuperati tramite dati visivi interni al file, quali ad esempio colore, texture e pattern, forma, orientamento e distribuzione spaziale, ecc.; sistemi di video retrieval dove per il recupero di documenti audiovisivi si utilizza il linguaggio audiovisivo, cioè elementi di ricerca ricavati dalle immagini del filmato, dal movimento degli oggetti nelle inquadrature, dall'analisi degli stacchi di montaggio o della traccia sonora; sistemi di audio retrieval nei quali l'informazione sonora è ricercata in misure di suoni, ricavando quindi i dati di query dall'analisi dei volumi, delle sonorità, dei ritmi o delle melodie.
, per la ricerca di documenti testuali (e finora spesso anche di documenti audiovisivi); sistemi di information retrieval content-based o multimedia information retrieval: sistemi di visual retrieval in cui i file d immagine 2D e 3D sono cercati e recuperati tramite dati visivi interni al file, quali ad esempio colore, texture e pattern, forma, orientamento e distribuzione spaziale, ecc.; sistemi di video retrieval dove per il recupero di documenti audiovisivi si utilizza il linguaggio audiovisivo, cioè elementi di ricerca ricavati dalle immagini del filmato, dal movimento degli oggetti nelle inquadrature, dall analisi degli stacchi di montaggio o della traccia sonora; sistemi di audio retrieval nei quali l informazione sonora è ricercata in misure di suoni, ricavando quindi i dati di query dall analisi dei volumi, delle sonorità, dei ritmi o delle melodie.")
136
Multimedia IR Per raggiungere un buon livello di precisione nel recupero dei documenti da una base di dati multimediale, sembra comunque auspicabile la compresenza dei sistemi di information retrieval term- based e content-based: l'interrogazione term-based può costituire un ottimo metodo preliminare per selezionare una parte della grande quantità di documenti di un archivio, e per centrare la ricerca in base a dati quali gli ambiti d'appartenenza, le tipologie, le classi, i titoli, gli autori; successivamente può essere un sistema di ripulitura finale dall'inevitabile rumore specifico di un'interrogazione content-based. In tutto ciò i due procedimenti possono operare sempre in armonia e in interazione costante, in un'unica interfaccia utente.

137
Multimedia IR Negli ultimi anni il multimedia information retrieval è stato oggetto di un numero crescente di ricerche e applicazioni a livello internazionale, attestando l'interesse di varie comunità d'uso che si occupano della gestione di documenti multimediali per le nuove possibilità di valorizzazione di archivi e attività professionali: dalle applicazioni biochimiche (ad esempio per l'indicizzazione delle molecole) all'architettura e all'archeologia (per la ricerca di costruzioni, siti e piante in base alle similarità nei particolari), dagli archivi di film e di video al giornalismo (dove vengono notevolmente potenziate le ricerche di personaggi e situazioni dispersi in migliaia di minuti di girato), dai beni culturali al design, dalla didattica all'e-commerce e al settore dello spettacolo, dai GIS ai sistemi di remote sensing, dal settore medico (giacchéle diagnosi vengono spesso effettuate servendosi di ricognizioni audiovisuali di condizioni anormali) ai sistemi di identificazione e di sorveglianza.
 all architettura e all archeologia (per la ricerca di costruzioni, siti e piante in base alle similarità nei particolari), dagli archivi di film e di video al giornalismo (dove vengono notevolmente potenziate le ricerche di personaggi e situazioni dispersi in migliaia di minuti di girato), dai beni culturali al design, dalla didattica all e-commerce e al settore dello spettacolo, dai GIS ai sistemi di remote sensing, dal settore medico (giacchéle diagnosi vengono spesso effettuate servendosi di ricognizioni audiovisuali di condizioni anormali) ai sistemi di identificazione e di sorveglianza.")
138
Nuove frontiere: Structured IR Abbiamo presentato lInformation Retrieval come una scienza che ha a che fare con dati non strutturati. Tuttavia, negli ultimi anni sta emergendo la necessità di applicare tecniche di IR anche a dati semistrutturati, in particolare a documenti XML; si parla allora allora di Structured Information Retrieval (SIR). Molte cose cambiano. Ad es. in IR la risposta ad una query è un elenco di documenti; in SIR, la risposta è un elenco di… ? Documenti XML? O frammenti di documenti XML? O singoli elementi?
. Molte cose cambiano. Ad es. in IR la risposta ad una query è un elenco di documenti; in SIR, la risposta è un elenco di… . Documenti XML. O frammenti di documenti XML. O singoli elementi .")
139
Sistemi per il recupero delle informazioni BIBLIOTECA DIGITALE

140
Definizione e contesti La biblioteca ha rappresentato nelle formulazioni dei primi teorici delle tecnologie informatiche lo spazio elettivo per sperimentare e applicare la convergenza al digitale dei processi di elaborazione, memorizzazione, recupero e distribuzione della conoscenza Il termine biblioteca digitale si attesta tra il 1992 e il 1993, in forte e non casuale contiguità con la nascita del Web, sancendo così la convergenza teorica e tecnica tra biblioteche digitali e sistemi ipertestuali distribuiti con lo sviluppo delle tecnologie dell informazione e della comunicazione è entrato a far parte del lessico biblioteconomico in un contesto semantico che lo vedrà affiancato ai termini biblioteca elettronica, virtuale, multimediale, ibrida.

141
Definizione e contesti Google, Microsoft e Yahoo! coinvolgono importanti istituzioni bibliotecarie e mettono a confronto due universi informativi assai diversi per storia e per finalità: quello dellimpresa privata da una parte e quello delle istituzioni della memoria e dei beni culturali dall altra, con lintento comune, sia pure da punti vista e da ideologie diverse, di integrare linformazione disponibile in rete e linformazione disponibile fuori dalla rete una massa critica documentaria, che mentre genera nuovo capitale culturale, causa vistosi fenomeni di entropia dellinformazione. Non sono cambiate e non stanno cambiando le funzioni fondamentali della biblioteca, quanto la loro portata e soprattutto lo scenario, il contesto in cui esse si esprimono La convergenza al digitale ridefinisce di fatto competenze professioni, e obbliga a metodologie di lavoro fondate sulla trasversalità delle pratiche e delle conoscenze. Del pari, sono aumentate le aspettative degli utenti, sempre più smaliziati sia nellinterazione con la struttura ipertestuale del Web, sia con luso degli strumenti di ricerca

142
Definizione e contesti Lespressione biblioteca digitale individua da una parte il modello logico e astratto, costituito da collezioni di documenti (non solo testuali) e dai metadati ad essi relativi; dallaltra, la struttura di servizio organizzata, in cui le collezioni sono al centro di un coerente sistema di relazioni ontologiche, che supportano lintero ciclo di vita dei documenti digitali e i servizi creati per laccesso e per il recupero delle informazioni.
 e dai metadati ad essi relativi; dallaltra, la struttura di servizio organizzata, in cui le collezioni sono al centro di un coerente sistema di relazioni ontologiche, che supportano lintero ciclo di vita dei documenti digitali e i servizi creati per laccesso e per il recupero delle informazioni.")
143
Architetture Le biblioteche hanno sempre investito in quella che oggi si definisce architettura dellinformazione, nella sensibilità e nella capacità di gestire le informazioni, catalogando il sapere, creando nuove connessioni semantiche tra i documenti, fornendo dunque loro valore aggiunto attraverso gli strumenti indicali, i linguaggi di indicizzazione semantica e di classificazione Progettazione di nuovi contesti digitali e di spazi logici di interazione tra gli utenti e luniverso documentario e dei servizi, per consentire un accesso intuitivo ai contenuti e un loro facile recupero nuovi modelli di creazione della conoscenza fondati sulla partecipazione collettiva, secondo il fortunato esempio delle network communities.

144
Architetture La qualità di una biblioteca digitale non si misura tanto dalla quantità di documenti digitalizzati, quanto dalla capacità di strutturare e di modellizzare i dati, di renderli accessibili La qualità si misura anche dalladozione o meno di infrastrutture tecnologiche che siano quanto più flessibili, modulari, incrementali, i cui codici sorgente siano liberamente accessibili e modificabili (open source) La flessibilità di un sistema significa la sua capacità di adattarsi al cambiamento; la modularità indica che il numero e la disposizione delle sue parti costitutive possono essere modificati e ricombinati; il modello incrementale ne qualifica le potenzialità di sviluppo e di espansione nel tempo.
 La flessibilità di un sistema significa la sua capacità di adattarsi al cambiamento; la modularità indica che il numero e la disposizione delle sue parti costitutive possono essere modificati e ricombinati; il modello incrementale ne qualifica le potenzialità di sviluppo e di espansione nel tempo.")
145
Architetture Il modello OAI fornisce la cornice logica e tecnologica dei cosiddetti open archives, ovvero archivi di testi costituiti dalle comunità accademiche, al fine di favorire la libera circolazione dei contenuti, frutto delle attività di ricerca degli atenei pre-print (destinati a una successiva pubblicazione sottoposta a peer-review) post-print (versioni aggiornate di testi già apparsi su periodici o atti di convegni) e-print (termine più ampio, che include sia le versioni elettroniche dei due precedenti, sia, genericamente, ogni sorta di contributo anche multimediale finalizzato alla distribuzione esclusivamente attraverso open archives o similari strumenti digitali privi di peer-review
 post-print (versioni aggiornate di testi già apparsi su periodici o atti di convegni) e-print (termine più ampio, che include sia le versioni elettroniche dei due precedenti, sia, genericamente, ogni sorta di contributo anche multimediale finalizzato alla distribuzione esclusivamente attraverso open archives o similari strumenti digitali privi di peer-review")
Presentazioni simili

































>")









