Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Protocolli di routing e stack TCP/IP
Data Link RIP ICMP BGP OSPF IGRP Hello ARP RARP FTP Telnet X-Windows TCP NFS NIS Transport Nework Upper Layers SNMP EGP IP UDP RPC Un protocollo di routing gestisce lo scambio di informazioni tra router per la costruzione delle tabelle di instradamento. Il protocollo più diffuso è il Routing Information Protocol (RIP), del tipo distance-vector e usato su reti di piccole dimensioni; altri protocolli distance-vector, con caratteristiche migliori del RIP ma proprietari CISCO e quindi utilizzabili solo con router della stessa casa, sono Interior Gateway Routing Protocol (IGRP) e Enhanced-IGRP (EIGRP). Il protocollo più diffuso del tipo link state è Open Shortest Path First (OSPF), usato su reti di media-grande dimensione. I protocolli di routing usano lo stack TCP/IP per il trasporto delle informazioni di routing, quindi di distance-vector e di link state packet, nonché di pacchetti di hello usati per il discovery dei vicini. Come si vede dalla figura, alcuni protocolli vengono imbustati in TCP, il RIP in UDP e altri direttamente in IP. Questi ultimi, come il RIP in UDP, non hanno il recupero di errore garantito solo dal TCP; questo significa che a livello più alto e quindi a livello del protocollo di routing deve essere gestita l’eventuale perdita di un pacchetto. Usare il TCP ha comunque un inconveniente legato al controllo di flusso: se c’è un link in congestione il trasmettitore rallenta il rate di trasmissione quando invece le informazioni di routing sono vitali e andrebbero consegnate comunque.
, del tipo distance-vector e usato su reti di piccole dimensioni; altri protocolli distance-vector, con caratteristiche migliori del RIP ma proprietari CISCO e quindi utilizzabili solo con router della stessa casa, sono Interior Gateway Routing Protocol (IGRP) e Enhanced-IGRP (EIGRP). Il protocollo più diffuso del tipo link state è Open Shortest Path First (OSPF), usato su reti di media-grande dimensione. I protocolli di routing usano lo stack TCP/IP per il trasporto delle informazioni di routing, quindi di distance-vector e di link state packet, nonché di pacchetti di hello usati per il discovery dei vicini. Come si vede dalla figura, alcuni protocolli vengono imbustati in TCP, il RIP in UDP e altri direttamente in IP. Questi ultimi, come il RIP in UDP, non hanno il recupero di errore garantito solo dal TCP; questo significa che a livello più alto e quindi a livello del protocollo di routing deve essere gestita l’eventuale perdita di un pacchetto. Usare il TCP ha comunque un inconveniente legato al controllo di flusso: se c’è un link in congestione il trasmettitore rallenta il rate di trasmissione quando invece le informazioni di routing sono vitali e andrebbero consegnate comunque.")
2
Protocolli di routing Algoritmo Protocollo Link State Dijkstra SPF
OSPF Distance Vector Bellman-Ford, EGP, RIP, IGRP Gli algoritmi di routing possono essere divisi in tre gruppi: algoritmi isolati in cui ogni router calcola in maniera indipendente le proprie tabelle di instradamento senza scambiare informazioni con altri router; può essere realizzato in maniera molto semplice ma inefficiente, ad esempio quando un router riceve un pacchetto da un’interfaccia lo inoltra su una libera tra le altre, oppure in maniera più complessa come accade nel backward learning: il router conosce la rete studiando il traffico che lo attraversa e in particolare andando a guardare gli indirizzi sorgente dei pacchetti; algoritmi centralizzati opposti ai precedenti in cui esiste un nodo centrale che riceve informazioni da tutti i router e conosce così la topologia della rete; calcola le tabelle di instradamento che poi distribuisce ai corrispondenti router; algoritmi distribuiti rappresentano una scelta di compromesso tra i due tipi precedenti; le tabelle di instradamento vengono calcolate sui router sfruttando informazioni apprese attraverso un colloquio tra router realizzato mediante un protocollo di routing. L’approccio distribuito è il più usato in due varianti: protocolli Distance Vector tradizionali: utilizzano l’algoritmo di Bellmann-Ford avanzati: utilizzano l’algoritmo Distributed Update Algorithm (DUAL) protocolli Link State utilizzano l’algoritmo di Dijkstra DUAL EIGRP
 protocolli Link State. utilizzano l’algoritmo di Dijkstra. DUAL. EIGRP.")
3
Distance Vector costo = 15 costo = 5 costo. = 5 4 10 30 10 30 15 35 9
C N C R3 4 10 30 10 30 15 35 N C NH Vettore delle distanze di R1 costo. = 5 9 R1 Vettore delle distanze di R2 15 R4 Un protocollo di routing distance vector si basa su un algoritmo conosciuto anche come algoritmo di Bellman-Ford. Secondo tale algoritmo, ogni router in una rete invia su tutte le interfacce l’elenco delle destinazioni che può raggiungere e la loro distanza da sé stesso (l’elenco costituisce il vettore delle distanze o distance vector). La destinazione è rappresentata da un indirizzo e la distanza è rappresentata dal minimo “costo” associato ad una destinazione. Ciascun router quindi, riceve dai suoi vicini l’elenco delle destinazioni che questi sono in grado di raggiungere. Il distance vector viene memorizzato dopo aver sommato alle distanze annunciate dal vicino quella che separa il router considerato dal vicino. La tabella definitiva si ottiene con un’operazione di “fusione” dei distance vector: l’interfaccia su cui saranno istradati i pacchetti destinati verso un determinato indirizzo sarà quella dalla quale è stato ricevuto il vettore contenente il minimo costo associato al suddetto indirizzo di destinazione. Un router ricalcola le sue tabelle ogni volta che: cade una linea attiva si riceve un distance vector da un nodo adiacente diverso da quello memorizzato. Il calcolo consiste nella fusione di tutti i distance vector delle linee attive. Se le tabelle risultano diverse da quelle precedenti, viene inviato un nuovo distance vector ai nodi adiacenti. In particolare, un protocollo distance vector prevede che il router operi nel seguente modo: 1) quando riceve un messaggio da un router adiacente confronta ogni coppia (destinazione, costo) col contenuto della tabella di routing: a) se la destinazione non è in tabella e il costo dell’annuncio non è infinito allora crea una nuova entry per la nuova destinazione e fa partire un timout timer per la nuova entry; b) se la destinazione è in tabella e il next hop è il router adiacente che ha fatto l’annuncio allora aggiorna il costo ed il next hop nella entry e fa ripartire il timeout timer; c) se la destinazione è nella tabella e il costo indica un percorso migliore allora aggiorna il costo e fa ripartire il timeout timer; 2) quando scatta il timeout timer pone il costo a infinito e fa partire il garbage collection timer; 3) quando scatta il garbage collection timer cancella la entry dalla tabella di routing; 4) ad intervalli regolari trasmette ai router adiacenti un messaggio che riporta tutte le coppie (destinazione, costo) contenute nella tabella di routing. 25 R2 N C 15 R4 15 Tabella di routing di R3 10 N = Network C = Costo NH = Next Hop R4 30 10 Vettore delle distanze di R4
. La destinazione è rappresentata da un indirizzo e la distanza è rappresentata dal minimo costo associato ad una destinazione. Ciascun router quindi, riceve dai suoi vicini l’elenco delle destinazioni che questi sono in grado di raggiungere. Il distance vector viene memorizzato dopo aver sommato alle distanze annunciate dal vicino quella che separa il router considerato dal vicino. La tabella definitiva si ottiene con un’operazione di fusione dei distance vector: l’interfaccia su cui saranno istradati i pacchetti destinati verso un determinato indirizzo sarà quella dalla quale è stato ricevuto il vettore contenente il minimo costo associato al suddetto indirizzo di destinazione. Un router ricalcola le sue tabelle ogni volta che: cade una linea attiva. si riceve un distance vector da un nodo adiacente diverso da quello memorizzato. Il calcolo consiste nella fusione di tutti i distance vector delle linee attive. Se le tabelle risultano diverse da quelle precedenti, viene inviato un nuovo distance vector ai nodi adiacenti. In particolare, un protocollo distance vector prevede che il router operi nel seguente modo: 1) quando riceve un messaggio da un router adiacente confronta ogni coppia (destinazione, costo) col contenuto della tabella di routing: a) se la destinazione non è in tabella e il costo dell’annuncio non è infinito allora crea una nuova entry per la nuova destinazione e fa partire un timout timer per la nuova entry; b) se la destinazione è in tabella e il next hop è il router adiacente che ha fatto l’annuncio allora aggiorna il costo ed il next hop nella entry e fa ripartire il timeout timer; c) se la destinazione è nella tabella e il costo indica un percorso migliore allora aggiorna il costo e fa ripartire il timeout timer; 2) quando scatta il timeout timer pone il costo a infinito e fa partire il garbage collection timer; 3) quando scatta il garbage collection timer cancella la entry dalla tabella di routing; 4) ad intervalli regolari trasmette ai router adiacenti un messaggio che riporta tutte le coppie (destinazione, costo) contenute nella tabella di routing. 25. R2. N C. 15. R Tabella di. routing di R N = Network. C = Costo. NH = Next Hop. R Vettore delle. distanze di R4.")
4
Distance vector algorithm
quando riceve un messaggio da un router adiacente confronta ogni coppia (destinazione, costo) col contenuto della tabella di routing: se la destinazione non è in tabella e il costo dell’annuncio non è infinito allora crea una nuova entry per la nuova destinazione e fa partire un timout timer per la nuova entry; b) se la destinazione è in tabella e il next hop è il router adiacente che ha fatto l’annuncio allora aggiorna il costo ed il next hop nella entry e fa ripartire il timeout timer; c) se la destinazione è nella tabella e il costo indica un percorso migliore allora aggiorna il costo e fa ripartire il timeout timer; 2) quando scatta il timeout timer pone il costo a infinito e fa partire il garbage collection timer; 3) quando scatta il garbage collection timer cancella la entry dalla tabella di routing; 4) ad intervalli regolari trasmette ai router adiacenti un messaggio che riporta tutte le coppie (destinazione, costo) contenute nella tabella di routing. Distance vector algorithm
 col contenuto della tabella di routing: se la destinazione non è in tabella e il costo dell’annuncio non è infinito. allora crea una nuova entry per la nuova destinazione e fa partire un timout timer. per la nuova entry; b) se la destinazione è in tabella e il next hop è il router adiacente che ha fatto. l’annuncio allora aggiorna il costo ed il next hop nella entry e fa ripartire il. timeout timer; c) se la destinazione è nella tabella e il costo indica un percorso migliore. allora aggiorna il costo e fa ripartire il timeout timer; 2) quando scatta il timeout timer pone il costo a infinito e fa partire il. garbage collection timer; 3) quando scatta il garbage collection timer cancella la entry dalla tabella di routing; 4) ad intervalli regolari trasmette ai router adiacenti un messaggio che riporta tutte le. coppie (destinazione, costo) contenute nella tabella di routing. Distance vector algorithm.")
5
Loop L1 L2 A B C B --> ? B A C Link local 1 2 Cost= hops 0 1 inf.
Tabella di instradamento di B dopo la caduta del link Distance Vector proveniente da A B --> ? B A C Link local 1 2 Cost= hops 0 1 inf. A --> ? A B C Link local 1 1 Cost= hops 0 1 2 Nel protocollo del tipo distance vector ogni router ha una conoscenza solo locale della rete, cioè sa che per raggiungere una certa destinazione deve passare attraverso un particolare router, ma non sa cosa succede dopo quel router; ciò può portare a problemi di topologia, ossia, in seguito alla variazione della topologia il protocollo non riesce a portare i router in una situazione stabile cioè unica. Si possono creare dei loop che sono il classico esempio di situazione non stabile: il router A pensa che per raggiungere la rete X si debba passare per il router B, mentre il router B pensa che per raggiungere la stessa destinazione X si debba passare per il router A: un pacchetto che giunge al router A o al router B con indirizzo di destinazione nella rete X viene intrappolato dai due router. In figura viene mostrato come si può finire in una tale situazione. Si supponga l’interruzione del link B-C: B elimina i DV ricevuti su quella linea (quindi quello di C) settando tutte le destinazioni prima raggiungibili da quella linea ad un costo infinito; B trasmette il nuovo DV ad A e la rete si stabilizza; oppure se A trasmette il suo DV a B prima che questo abbia tempo di propagare l’errore: nel DV di A il costo per raggiungere C è pari a 2; nel nuovo DV di B il costo sarà pari a 3, quindi C risulterà ancora raggiungibile, però via A; B annuncia ad A che C è raggiungibile mediante A con costo 3; A aggiorna la sua tabella, si accorge che C è raggiungibile mediante B con costo 4; ……durante questo transitorio un pacchetto dati per C viene ‘intrappolato’ tra A e B. Questo transitorio in realtà cessa nel momento in cui il parametro hop count non raggiunge il valore 16 (count to infinity), in corrispondenza del quale la destinazione viene dichiarata irraggiungibile.
 settando tutte le destinazioni prima raggiungibili da quella linea ad un costo infinito; B trasmette il nuovo DV ad A e la rete si stabilizza; oppure. se A trasmette il suo DV a B prima che questo abbia tempo di propagare l’errore: nel DV di A il costo per raggiungere C è pari a 2; nel nuovo DV di B il costo sarà pari a 3, quindi C risulterà ancora raggiungibile, però via A; B annuncia ad A che C è raggiungibile mediante A con costo 3; A aggiorna la sua tabella, si accorge che C è raggiungibile mediante B con costo 4; ……durante questo transitorio un pacchetto dati per C viene ‘intrappolato’ tra A e B. Questo transitorio in realtà cessa nel momento in cui il parametro hop count non raggiunge il valore 16 (count to infinity), in corrispondenza del quale la destinazione viene dichiarata irraggiungibile.")
6
Distance Vector: cold start
condizione in cui gli apparati inziano a funzionare tutti contemporaneamente Inizialmete tutti i sistemi dispongono di distance vector che rappresentano se stessi e le stazioni ad essi direttamente collegate Protocolli “neighbour greetings” Configurazione manuale

7
Distance Vector: caratteristiche
Vantaggi: semplice da implementare; non appesantisce il router in termini di capacità elaborativa e memoria occupata. Svantaggi: possono innescarsi dei loop a causa di particolari variazioni della topologia; converge alla velocità del link più lento e del router più lento; difficile capirne e prevederne il comportamento su reti grandi: nessun nodo ha una mappa della rete (conoscenza locale); l’implementazione di meccanismi migliorativi appesantisce notevolmente il protocollo; hop-count-limit impone l’impiego di questo algoritmo in reti piccole con pochi hop.
; l’implementazione di meccanismi migliorativi appesantisce notevolmente il protocollo; hop-count-limit impone l’impiego di questo algoritmo in reti piccole con pochi hop.")
8
Routing InformationProtocol (RIP)
è stato originariamente progettato da Xerox per la rete XNS. È stato introdotto dall’università di Berkeley nell’architettura TCP/IP nel 1982, Definito come RFC 1058 nel 1988 e aggiornato come RFC 1388 nel 1993.

9
RIP (costo=num hops) 64kb/s 1 Mb/S A B 1 L8 L2 F L3 L4 C L7 L6 L5 D E
Distance Vector di A A B 1 A --> ? A B D C E Cost 0 1 1 2 64kb/s 1 Mb/S L8 L2 F L3 L4 C L7 L6 L5 D E Distance Vector di D Tabella di instradamento di F Il Routing Information Protocol (RIP) è stato originariamente progettato da Xerox per la rete XNS. È stato introdotto dall’università di Berkeley nell’architettura TCP/IP nel 1982, definito come RFC 1058 nel 1988 e aggiornato come RFC 1388 nel RIP è il protocollo del tipo distance-vector più diffuso, in cui ogni router invia solo ai router adiacenti una parte della tabella di instradamento detta distance-vector formata dalle coppie destinazione-costo. Il RIP ha una metrica molto semplice basata sull’hop-count: il costo verso una certa destinazione viene valutato con il numero di salti, ossia il numero di router da attraversare per raggiungerla. Il RIP mantiene nella tabella di instradamento un solo percorso verso ogni destinazione, scegliendo tra diverse possibilità quella a minor costo. La semplicità della metrica porta a scelte che possono essere non ottimali. Nell’esempio mostrato in figura, il RIP sul router F porta a scegliere come percorso verso A il PATH-L8 perché ha costo 1 essendo costituito da un solo salto. Il PATH-L7 non viene scelto perché ha costo 2; quest’ultimo percorso ha però una banda passante di 1 Mbps, mentre il PATH-L8 ha solo 64 Kbps. La scelta è chiaramente non ottimale; il tutto deriva dal fatto che nel tipo di metrica non compare come parametro di merito la banda. La banda passante è un parametro importante per il trasferimento di dati. Esistono applicativi time-sensitive che più che di banda hanno bisogno di bassi ritardi. Questo per dire che una metrica complessa dovrebbe tenere conto nel decidere un certo percorso della banda netta, del ritardo introdotto sul collegamento e di altri parametri come l’affidabilità. Per compensare le differenze tra le tecnologie trasmissive utilizzate alcune implementazioni RIP permettono al gestore di configurare artificialmente alti valori di hop count quando annunciano percorsi che utilizzano reti lente F --> ? F A B C D E Link local 8 8 7 Cost 0 1 2 3 1 D --> ? D A B E C Cost 0 1 2 1 A parità di metriche si prende l’entry del DV arrivato per primo
 è stato originariamente progettato da Xerox per la rete XNS. È stato introdotto dall’università di Berkeley nell’architettura TCP/IP nel 1982, definito come RFC 1058 nel 1988 e aggiornato come RFC 1388 nel RIP è il protocollo del tipo distance-vector più diffuso, in cui ogni router invia solo ai router adiacenti una parte della tabella di instradamento detta distance-vector formata dalle coppie destinazione-costo. Il RIP ha una metrica molto semplice basata sull’hop-count: il costo verso una certa destinazione viene valutato con il numero di salti, ossia il numero di router da attraversare per raggiungerla. Il RIP mantiene nella tabella di instradamento un solo percorso verso ogni destinazione, scegliendo tra diverse possibilità quella a minor costo. La semplicità della metrica porta a scelte che possono essere non ottimali. Nell’esempio mostrato in figura, il RIP sul router F porta a scegliere come percorso verso A il PATH-L8 perché ha costo 1 essendo costituito da un solo salto. Il PATH-L7 non viene scelto perché ha costo 2; quest’ultimo percorso ha però una banda passante di 1 Mbps, mentre il PATH-L8 ha solo 64 Kbps. La scelta è chiaramente non ottimale; il tutto deriva dal fatto che nel tipo di metrica non compare come parametro di merito la banda. La banda passante è un parametro importante per il trasferimento di dati. Esistono applicativi time-sensitive che più che di banda hanno bisogno di bassi ritardi. Questo per dire che una metrica complessa dovrebbe tenere conto nel decidere un certo percorso della banda netta, del ritardo introdotto sul collegamento e di altri parametri come l’affidabilità. Per compensare le differenze tra le tecnologie trasmissive utilizzate alcune implementazioni RIP permettono al gestore di configurare artificialmente alti valori di hop count quando annunciano percorsi che utilizzano reti lente. F --> F A. B. C. D. E. Link. local Cost D --> D A. B. E. C. Cost A parità di metriche si prende l’entry del DV arrivato per primo.")
10
RIP: Timer routing update timer = 30s (intervallo di tempo per l’invio periodico dei distance vector); route invalid timer = 180s (intervallo di tempo dopo cui una route è dichiarata non più valida (cost = infinito)); route invalid timer : cosa succederebbe se un router che ha inviato agli altri un Distance Vector va in crash? Quando un router scrive un percorso sulla sua routing table fa partire il route invalid timer (180 sec); il timer viene azzerato ogni volta che il router riceve un messaggio RIP relativo a quell’istradamento. Se il timer scade l’istradamento e’ invalidato (costo=infinito)
); route invalid timer : cosa succederebbe se un router che ha inviato agli altri un Distance Vector va in crash Quando un router scrive un percorso sulla sua routing table fa partire il route invalid timer (180 sec); il timer viene azzerato ogni volta che il router riceve un messaggio RIP relativo a quell’istradamento. Se il timer scade l’istradamento e’ invalidato (costo=infinito)")
11
Routing update in broadcast
Un router invia i pacchetti che contengono i distance-vector in broadcast su tutte le sottoreti a cui è connesso. Tutte le macchine attestate sulla sottorete, avendo il pacchetto un indirizzo IP di broadcast, lo elaborano fino al livello quattro, siano esse calcolatori o router. Soltanto al livello UDP, grazie al port di destinazione, i calcolatori si accorgono che si tratta di informazioni RIP e non elaborano ulteriormente il pacchetto. I router invece usano tali informazioni per calcolare le proprie tabelle di instradamento. Un tale meccanismo appesantisce le macchine non interessate, ma è stato usato perché è semplice, non comporta per RIP l’uso di un protocollo a parte per il discovery dei vicini, e perché prima si pensava che anche i calcolatori dovessero fare un po’ di routing. Nella figura ad esempio, una macchina che debba inviare un pacchetto all’esterno della propria sottorete, può decidere quale dei tre router usare solo se ha qualche informazione di routing; quindi i pacchetti in broadcast possono essere intercettati ed elaborati da tutte le macchine che ne hanno bisogno. Oggi si preferisce configurare sulla macchina un solo router di uscita, detto gateway; se ci sono più router e il router-A riceve un pacchetto che sa dover passare attraverso il router-B, glielo invia e informa con un messaggio ICMP di Redirect la macchina sorgente che per quella connessione i pacchetti non devono passare per il gateway, ma vanno inviati direttamente al router-B. No discovery!

12
X Loop hop-count-limit in RIP è 15 (16=infinito)
A = 4 Hop A = 2 Hop Net A Net D R1 R2 R3 Net B Net C X E0 S0 S0 S1 S0 E0 A = 3 Hop In ogni protocollo del tipo distance vector, a causa della sola conoscenza locale che i router hanno della rete, si possono creare dei loop. L’unico metodo per impedire che si creino tali situazioni e che un pacchetto rimanga imprigionato è porre un limite al hop-count. Tutte le destinazioni che distano più di hop-count-limit sono considerate irraggiungibili. Ciò permette al protocollo di convergere ad una situazione stabile. Il valore di hop-count-limit in RIP è 15; quindi ogni destinazione lontana 16 salti è considerata irraggiungibile. Questo pone un limite alla dimensione massima della rete. In particolare, ipotizzando una distribuzione abbastanza uniforme dei nodi della rete, si può usare il RIP per reti al massimo di 1000 nodi. A = 5 Hop hop-count-limit in RIP è 15 (16=infinito) Limite nella dimensione della rete (RIP per reti al massimo di 1000 nodi.)
 Limite nella dimensione della rete. (RIP per reti al massimo di 1000 nodi.)")
13
Opzioni per la stabilità
Le opzioni usate in RIP per migliorare la stabilità sono: Split Horizon: un router non annuncia una destinazione sull’interfaccia da cui l’ha appresa Split Horizon with Poisonous Reverse: se un router perde la connettività verso una rete, dopo aver inserito il valore 16 (inf) nella entry, la mantiene invariata per un determinato numero di periodi di routing updated; inoltre annuncia in broadcast con valore infinito (16) il costo per raggiungere quella rete. Triggered update ( inviati immediatamente a fronte di cambiamenti nella rete) Convergenza ancora lenta… Le opzioni usate in RIP per migliorare la stabilità sono: Split Horizon: un router non annuncia una destinazione sull’interfaccia da cui l’ha appresa; Split Horizon with Poisonous Reverse: se un router perde la connettività verso una rete, dopo aver inserito il valore 16 (inf) nella entry, la mantiene invariata per un determinato numero di periodi di routing updated; inoltre annuncia in broadcast con valore infinito (16) il costo per raggiungere quella rete. Le suddette tecniche prevengono loop tra due nodi, ma non i loop più lunghi, e rendono la convergenza più veloce dell’aspettare che una route venga posta irraggiungibile perché si è superato l’hop-count-limit. Per velocizzare la convergenza del protocollo sono stati introdotti i triggered update: mentre i distance vector sono inviati periodicamente (ogni 30 s), i triggered update vengono inviati immediatamente a fronte di cambiamenti nella rete. I triggered update sono spaziati casualmente da 1 a 5 secondi dopo il cambiamento della topologia per non caricare in maniera impulsiva la rete e includono solo i record variati. Distance-vector e triggered update possono propagarsi simultaneamente, creando dei problemi perché i pacchetti periodici possono propagare informazioni vecchie. Loop che coinvolgono più di 2 router…
 nella entry, la mantiene invariata per un determinato numero di periodi di routing updated; inoltre annuncia in broadcast con valore infinito (16) il costo per raggiungere quella rete. Triggered update ( inviati immediatamente a fronte di cambiamenti nella rete) Convergenza ancora lenta… Le opzioni usate in RIP per migliorare la stabilità sono: Split Horizon: un router non annuncia una destinazione sull’interfaccia da cui l’ha appresa; Split Horizon with Poisonous Reverse: se un router perde la connettività verso una rete, dopo aver inserito il valore 16 (inf) nella entry, la mantiene invariata per un determinato numero di periodi di routing updated; inoltre annuncia in broadcast con valore infinito (16) il costo per raggiungere quella rete. Le suddette tecniche prevengono loop tra due nodi, ma non i loop più lunghi, e rendono la convergenza più veloce dell’aspettare che una route venga posta irraggiungibile perché si è superato l’hop-count-limit. Per velocizzare la convergenza del protocollo sono stati introdotti i triggered update: mentre i distance vector sono inviati periodicamente (ogni 30 s), i triggered update vengono inviati immediatamente a fronte di cambiamenti nella rete. I triggered update sono spaziati casualmente da 1 a 5 secondi dopo il cambiamento della topologia per non caricare in maniera impulsiva la rete e includono solo i record variati. Distance-vector e triggered update possono propagarsi simultaneamente, creando dei problemi perché i pacchetti periodici possono propagare informazioni vecchie. Loop che coinvolgono più di 2 router…")
14
RIP: formato del pacchetto
command version zero address family identifier(IP=2) zero IP address zero zero metric Il pacchetto RIP, imbustato in UDP con porta di destinazione 520, prevede i seguenti campi: command, che veniva usato in vecchie versioni del protocollo che prevedevano l’uso di due messaggi, uno di richiesta e l’altro di risposta; nella versione attuale non sono previsti messaggi di richiesta e in tutti i pacchetti è presente il codice che individua un messaggio di tipo response; version la versione più diffusa è il RIP 1, ma esiste anche una versione 2, che trasporta oltre all’indirizzo di una sottorete anche la maschera e risolve in questo alcuni problemi del RIP 1; address-family-identifier campo che individua la pila protocollare sottostante, visto che il RIP non è nato originariamente per lavorare su IP; address e metric, per ogni entry si invia l’indirizzo IP della sottorete e il costo verso la destinazione. Il pacchetto RIP non annuncia maschere. Perciò non è possibile suddividere la rete in sottoreti più piccole (in questo caso infatti tutte le sottoreti avranno per il RIP lo stesso indirizzo..!!). Queste limitazioni sono peraltro comuni a tutti i protocolli di routing che non trasportano le maschere. UDP port n° 520
 zero. IP address. zero. zero. metric Il pacchetto RIP, imbustato in UDP con porta di destinazione 520, prevede i seguenti campi: command, che veniva usato in vecchie versioni del protocollo che prevedevano l’uso di due messaggi, uno di richiesta e l’altro di risposta; nella versione attuale non sono previsti messaggi di richiesta e in tutti i pacchetti è presente il codice che individua un messaggio di tipo response; version la versione più diffusa è il RIP 1, ma esiste anche una versione 2, che trasporta oltre all’indirizzo di una sottorete anche la maschera e risolve in questo alcuni problemi del RIP 1; address-family-identifier campo che individua la pila protocollare sottostante, visto che il RIP non è nato originariamente per lavorare su IP; address e metric, per ogni entry si invia l’indirizzo IP della sottorete e il costo verso la destinazione. Il pacchetto RIP non annuncia maschere. Perciò non è possibile suddividere la rete in sottoreti più piccole (in questo caso infatti tutte le sottoreti avranno per il RIP lo stesso indirizzo..!!). Queste limitazioni sono peraltro comuni a tutti i protocolli di routing che non trasportano le maschere. UDP port n° 520.")
15
RIP: sintesi Largamente disponibile Facile da implementare
Metrica basata su numero di hop Update periodici (ogni 30 sec.) inviati in broadcast Convergenza lenta Routing loops Count to infinity No load balancing Il RIP è largamente disponibile e facile da implementare; la metrica basata su numero di hop comporta la scelta di percorsi non ottimali e soprattutto non basati sull’esigenza della particolare applicazione. Gli update periodici, i distance vector, inviati ogni 30 secondi in broadcast, caricano la rete e portano ad un aggiornamento delle variazioni della topologia tutt’altro che rapido; il meccanismo dei triggered-update migliora la cosa. Si possono creare dei loop; i meccanismi di split horizon possono tagliare solo i loop tra due router. Per i loop più lunghi ci vuole l’hop-count-limit, che fa convergere il protocollo verso una situazione stabile, ma ci vogliono diversi cicli, quindi la convergenza è lenta. Il protocollo mantiene in memoria un solo percorso verso una certa destinazione, quindi non sono possibili meccanismi di load-balancing in cui ,quando un link è in congestione, si sceglie un instradamento secondario.
 inviati in broadcast. Convergenza lenta. Routing loops. Count to infinity. No load balancing. Il RIP è largamente disponibile e facile da implementare; la metrica basata su numero di hop comporta la scelta di percorsi non ottimali e soprattutto non basati sull’esigenza della particolare applicazione. Gli update periodici, i distance vector, inviati ogni 30 secondi in broadcast, caricano la rete e portano ad un aggiornamento delle variazioni della topologia tutt’altro che rapido; il meccanismo dei triggered-update migliora la cosa. Si possono creare dei loop; i meccanismi di split horizon possono tagliare solo i loop tra due router. Per i loop più lunghi ci vuole l’hop-count-limit, che fa convergere il protocollo verso una situazione stabile, ma ci vogliono diversi cicli, quindi la convergenza è lenta. Il protocollo mantiene in memoria un solo percorso verso una certa destinazione, quindi non sono possibili meccanismi di load-balancing in cui ,quando un link è in congestione, si sceglie un instradamento secondario.")
16
RIP versione 2 RFC 1723 Può interoperare con RIPv1
Permette di trasferire anche le netmask Routing Update trasmessi in multicast all’indirizzo di classe D E’ possibile effettuare l’autenticazione dei messaggi E’ possibile il subnetting solo se tutti i router della rete hanno la stessa versione (es. RIP2). RIPv2 permette di autenticare i messaggi scambiati. Dove cio’ non e’ possibile (ad esempio RIP) e’ possibile che un utente malizioso puo’ inviare messaggi di routing che indicano con basso costo di istradare attraverso di esso I messaggi IP destinati ad una data sottorete
. RIPv2 permette di autenticare i messaggi scambiati. Dove cio’ non e’ possibile (ad esempio RIP) e’ possibile che un utente malizioso puo’ inviare messaggi di routing che indicano con basso costo di istradare attraverso di esso I messaggi IP destinati ad una data sottorete.")
17
RIPv2: routing update in multicast
I messaggi di update vengono trasmessi in multicast (indirizzo di classe D: )
")
18
RIPv2: formato del pacchetto
command version routing domain address family identifier route tag IP address subnet mask next hop metric

19
IGRP Protocollo Distance Vector proprietario Cisco
Supera i limiti di RIP Metriche sofisticate contenenti: ritardo (non misurato, ma associato secondo valori predefiniti a ciascun tipo di sottorete trasmissiva) banda affidabilità carico Trasporta anche: numero Hop lunghezza massima del pacchetto si tratta di parametri configurati dal gestore in modo statico; se fossero misurati automaticamente, per via dei diversi istanti di misura attuati dai router, si potrebbero innescare dei loop) La metrica si basa su 4 parametri D - delay ( ) (1 = 10 s) R - reliability ( ) (255 = 100%) L - load ( ) (255 = 100%) B - bandwidth ( ) (1 = 1 kbit/s) Il gestore può impostare 5 parametri di peso: k1, k2, k3, k4, k5 La metrica è calcolata come segue: Se k5 = 0 : Metrica = (107/ B) [k1+ k2 / (256-L)] + k3 x D Se k5 ‡ 0 : Metrica = Metrica x [ k5 / (R + k4) ] Per default : k1=k3=1; k2=k4=k5=0. Bandwidth e Delay sono per default associati al tipo di portante fisico. Es.: Ethernet -> B=10000, D=100 CDN 64 kbit/s -> B=64, D=2000 Per ciascun link B e D possono comunque essere impostati dal gestore Su un determinato percorso: B è calcolata come il minimo sul percorso D è calcolato come la somma sul percorso Annunci dell’IGRP vengono inviati ogni 90 secondi ESEMPIO FDDI (100 Mbit/s) B Nel routing di pacchetti fra 1 e 2: RIP sceglie la via A-C IGRP sceglie la via A-B-C la via migliore non è quindi detto che sia quella con il minor numero di transiti. ATM 155 Mbit/s A C CDN 9600 bit/s 1 2
 banda. affidabilità. carico. Trasporta anche: numero Hop. lunghezza massima del pacchetto. si tratta di parametri configurati dal gestore in modo statico; se fossero misurati automaticamente, per via dei diversi istanti di misura attuati dai router, si potrebbero innescare dei loop) La metrica si basa su 4 parametri. D - delay ( ) (1 = 10 s) R - reliability ( ) (255 = 100%) L - load ( ) (255 = 100%) B - bandwidth ( ) (1 = 1 kbit/s) Il gestore può impostare 5 parametri di peso: k1, k2, k3, k4, k5. La metrica è calcolata come segue: Se k5 = 0 : Metrica = (107/ B) [k1+ k2 / (256-L)] + k3 x D. Se k5 ‡ 0 : Metrica = Metrica x [ k5 / (R + k4) ] Per default : k1=k3=1; k2=k4=k5=0. Bandwidth e Delay sono per default associati al tipo di portante fisico. Es.: Ethernet -> B=10000, D=100. CDN 64 kbit/s -> B=64, D=2000. Per ciascun link B e D possono comunque essere impostati dal gestore. Su un determinato percorso: B è calcolata come il minimo sul percorso. D è calcolato come la somma sul percorso. Annunci dell’IGRP vengono inviati ogni 90 secondi. ESEMPIO. FDDI (100 Mbit/s) B. Nel routing di pacchetti fra 1 e 2: RIP sceglie la via A-C. IGRP sceglie la via A-B-C. la via migliore non è quindi detto che sia quella con il minor numero di transiti. ATM 155 Mbit/s. A. C. CDN 9600 bit/s")
20
Metrica IGRP D - delay (1 - 224) (1 = 10 s)
R - reliability ( ) (255 = 100%) L - load ( ) (255 = 100%) B - bandwidth ( ) (1 = 1 kbit/s) Bandwidth e Delay sono per default associati al tipo di portante fisico. Es.: Ethernet -> B=10000, D=100 CDN 64 kbit/s -> B=64, D=2000 Per ciascun link B e D possono comunque essere impostati dal gestore Su un determinato percorso: B è calcolata come il minimo sul percorso D è calcolato come la somma sul percorso Il gestore può impostare 5 parametri di peso: k1, k2, k3, k4, k5 Se k5 = 0 : Metrica = (107/ B) [k1+ k2 / (256-L)] + k3 x D Se k5 ‡ 0 : Metrica = Metrica x [ k5 / (R + k4) ] Per default : k1=k3=1; k2=k4=k5=0.
 (255 = 100%) L - load ( ) (255 = 100%) B - bandwidth ( ) (1 = 1 kbit/s) Bandwidth e Delay sono per default associati al tipo di portante fisico. Es.: Ethernet -> B=10000, D=100. CDN 64 kbit/s -> B=64, D=2000. Per ciascun link B e D possono comunque essere impostati dal gestore. Su un determinato percorso: B è calcolata come il minimo sul percorso. D è calcolato come la somma sul percorso. Il gestore può impostare 5 parametri di peso: k1, k2, k3, k4, k5. Se k5 = 0 : Metrica = (107/ B) [k1+ k2 / (256-L)] + k3 x D. Se k5 ‡ 0 : Metrica = Metrica x [ k5 / (R + k4) ] Per default : k1=k3=1; k2=k4=k5=0.")
21
IGRP: multipath routing e load balancing
Più entry per una stessa destinazione vengono installate nella tabella di routing (max 6 righe) Il carico può essere ripartito tra le diverse route in funzione della metrica associata: la distribuzione dei pacchetti su link differenti, verso la stessa destinazione avviene in misura inversamente proporzionale al costo espresso nella tabella. Sono usate per il multipath routing solo le route con metrica che rientra nel range definito dal gestore Con il RIP non è possibile ripartire il carico per sfruttare una eventuale doppia via; con IGRP è possibile una forma di bilanciamento. Infatti, La tabella di routing dell’IGRP può avere più righe (fino a sei) per la stessa entry destinazione. Il carico può essere ripartito tra le diverse route in funzione della metrica associata: la distribuzione dei pacchetti su link differenti, verso la stessa destinazione avviene in misura inversamente proporzionale al costo espresso nella tabella. Sono usate per il multipath routing solo le route con metrica che rientra nel range definito dal gestore Gli annunci dell’IGRP vengono inviati ogni 90 secondi per default; è possibile modificare tale valore ma occorre che ci sia congruenza fra tutti i router per evitare la crescita del tempo di stabilizzazione delle tabelle.
 Il carico può essere ripartito tra le diverse route in funzione della metrica associata: la distribuzione dei pacchetti su link differenti, verso la stessa destinazione avviene in misura inversamente proporzionale al costo espresso nella tabella. Sono usate per il multipath routing solo le route con metrica che rientra nel range definito dal gestore. Con il RIP non è possibile ripartire il carico per sfruttare una eventuale doppia via; con IGRP è possibile una forma di bilanciamento. Infatti, La tabella di routing dell’IGRP può avere più righe (fino a sei) per la stessa entry destinazione. Il carico può essere ripartito tra le diverse route in funzione della metrica associata: la distribuzione dei pacchetti su link differenti, verso la stessa destinazione avviene in misura inversamente proporzionale al costo espresso nella tabella. Sono usate per il multipath routing solo le route con metrica che rientra nel range definito dal gestore. Gli annunci dell’IGRP vengono inviati ogni 90 secondi per default; è possibile modificare tale valore ma occorre che ci sia congruenza fra tutti i router per evitare la crescita del tempo di stabilizzazione delle tabelle.")
22
Link State Protocols Link-state database Tabella di routing
LSP ricevuto da un’interfaccia Algoritmo di Dijkstra Link-state database Tabella di routing LSP ritrasmesso su tutte le altre interfacce Il Link State Packet (LSP) generato da ogni router contiene: identificativo del router che emette il LSP; stato di ogni link connesso al router; identità di ogni vicino connesso all’altro estremo del link costo del link; numero di sequenza per il LSP, utilizzato per individuare diverse versioni emesse dallo stesso router per scegliere la più recente. In un protocollo della famiglia link state si prevede che ogni router impari la propria situazione locale, con indirizzi delle sottoreti connesse e dei router direttamente raggiungibili; è necessario per questo un protocollo di Neighbor greetings. Queste informazioni vengono inserite in pacchetti, detti Link State Packet (LSP), che vengono trasmessi a tutti gli altri router presenti in rete. Ogni router memorizza per ogni router della rete il LSP più recente e grazie a questo database si costruisce una mappa della rete. Ogni router calcola poi indipendentemente le proprie tabelle di instradamento applicando alla mappa della rete l'algoritmo di Dijkstra o SPF (Shortest Path First), la cui complessità è ExLog(N), dove E è il numero di link e N è il numero di nodi presenti. Il Link State Packet (LSP) generato da ogni router contiene: identificativo del router che emette il LSP; stato di ogni link connesso al router; identità di ogni vicino connesso all’altro estremo del link costo del link; numero di sequenza per il LSP, utilizzato per individuare diverse versioni emesse dallo stesso router per scegliere la più recente.
 generato da ogni router contiene: identificativo del router che emette il LSP; stato di ogni link connesso al router; identità di ogni vicino connesso all’altro estremo del link. costo del link; numero di sequenza per il LSP, utilizzato per individuare diverse versioni emesse. dallo stesso router per scegliere la più recente. In un protocollo della famiglia link state si prevede che ogni router impari la propria situazione locale, con indirizzi delle sottoreti connesse e dei router direttamente raggiungibili; è necessario per questo un protocollo di Neighbor greetings. Queste informazioni vengono inserite in pacchetti, detti Link State Packet (LSP), che vengono trasmessi a tutti gli altri router presenti in rete. Ogni router memorizza per ogni router della rete il LSP più recente e grazie a questo database si costruisce una mappa della rete. Ogni router calcola poi indipendentemente le proprie tabelle di instradamento applicando alla mappa della rete l algoritmo di Dijkstra o SPF (Shortest Path First), la cui complessità è ExLog(N), dove E è il numero di link e N è il numero di nodi presenti. Il Link State Packet (LSP) generato da ogni router contiene: identificativo del router che emette il LSP; stato di ogni link connesso al router; identità di ogni vicino connesso all’altro estremo del link. costo del link; numero di sequenza per il LSP, utilizzato per individuare diverse versioni emesse dallo stesso router per scegliere la più recente.")
23
Flooding (1) LSP LSP LSP A B E D C
I LSP vengono diffusi in rete con un meccanismo di flooding (inondazione). Quando un router riceve un LSP da un certo router mittente, controlla la versione del pacchetto e quella del LSP che ha nel database in memoria e: se il LSP ricevuto è più recente di quello in memoria, allora aggiorna il database e invia di nuovo il LSP su tutte le interfacce tranne quella da cui lo ha ricevuto; se il LSP ricevuto è lo stesso di quello in memoria, allora lo scarta; se il LSP ricevuto è più vecchio di quello in memoria, allora lo scarta e invia la versione in memoria al router direttamente connesso che glielo aveva inviato. D C
. Quando un router riceve un LSP da un certo router mittente, controlla la versione del pacchetto e quella del LSP che ha nel database in memoria e: se il LSP ricevuto è più recente di quello in memoria, allora aggiorna il database e invia di nuovo il LSP su tutte le interfacce tranne quella da cui lo ha ricevuto; se il LSP ricevuto è lo stesso di quello in memoria, allora lo scarta; se il LSP ricevuto è più vecchio di quello in memoria, allora lo scarta e invia la versione in memoria al router direttamente connesso che glielo aveva inviato. D. C.")
24
Flooding (2) I router A, C, E ritrasmettono il LSP di D su tutte le
B E D C I router A, C, E ritrasmettono il LSP di D su tutte le interfacce tranne quella da cui lo hanno ricevuto

25
LSP Database LSP DataBase Costo A C 2 1 3 B D A B / 2 B A / 2 D / 3 E
G / 1 E E B / 2 F / 5 G / 2 F E / 5 H / 4 A valle della diffusione in flooding dei LSP, ogni router mantiene in memoria un database con le versioni più recenti dei LSP, da cui può trarre la maglia logica della rete. Se tutti i router hanno lo stesso database, allora vedono la rete con la stessa topologia. Un aspetto critico in protocolli del tipo Link State è la sincronizzazione tra i router; se i router hanno diversi LSP database, allora sono possibili dei loop. Il meccanismo di flooding è stato pensato per assicurare la più rapida diffusione e quindi aggiornamento di eventuali variazioni di topologia. La mappa logica non è ancora la tabella di instradamento; il router la ottiene applicando alla topologia di rete l’algoritmo di Dijkstra, che trasforma una rete magliata in una rete ad albero scegliendo i percorsi a più basso costo, e in cui il root è il router che sta applicando l’algoritmo. Da questo albero vengono estratte per ogni destinazione il next-hop e il costo totale del percorso. La tabella di routing è conseguenza diretta dell’albero dei costi. Con l’algoritmo di Dijkstra tutti i router hanno conoscenza di come è fatta la rete e in massimo 200 ms la rete può riconfigurarsi in seguito a cambiamenti o malfunzioni. 2 G D / 1 E / 2 H / 1 H F / 4 G / 1 5 G ( r e p l i c a t o s u o g n i Router ) 1 4 F H
 F. H.")
26
Tabella di routing: algoritmo di Dijkstra
H G F E D B A C 2 1 3 5 L Tabella di routing di B A L 1 C L 2 D L 2 E L 3 F L 3 G L 3 H L 3

27
Link State: caratteristiche
Vantaggi: può gestire reti di grandi dimensioni; ha una convergenza rapida; difficilmente genera loop; ogni nodo ha la mappa della rete. Svantaggi: molto complesso da realizzare (la prima implementazione ha richiesto a Digital 5 anni); È utilizzato nello standard ISO (IS-IS) e nel protocollo OSPF (molto diffuso su reti TCP/IP di grandi dimensioni).
; È utilizzato nello standard ISO (IS-IS) e nel protocollo OSPF (molto diffuso su reti TCP/IP di grandi dimensioni).")
28
OSPF [Open Shortest Path First]
Protocollo di tipo link state Definito dall’IETF: RFC 1247 (1991) RFC 1583 (1994) - OSPFv2 Open Shortest Path First è il più diffuso protocollo della famiglia link state. È stato definito da IETF con RFC 1247 nel 1991 e aggiornato (OSPFv2) con RFC 1583 nel Come in un qualsiasi protocollo link state, i router OSPF scambiano pacchetti di hello per scoprire quali sono i propri vicini e inviano tali informazioni in flooding su tutta la rete in Link State Packet. Ogni router mantiene in un database la versione più aggiornata del LSP di tutti i router presenti nel dominio; da questo database ricava la topologia della rete a cui applica l’algoritmo di Dijkstra; questo algoritmo, detto anche shortest path first, trasforma una struttura magliata in una ad albero scegliendo per ogni nodo il percorso a minimo costo. Ogni router, root dell’albero risultante dall’algoritmo, calcola così la tabella di instradamento.
![OSPF [Open Shortest Path First]](http://slideplayer.it/slide/541549/1/images/28/OSPF+%5BOpen+Shortest+Path+First%5D.jpg "Protocollo di tipo link state. Definito dall’IETF: RFC 1247 (1991) RFC 1583 (1994) - OSPFv2. Open Shortest Path First è il più diffuso protocollo della famiglia link state. È stato definito da IETF con RFC 1247 nel 1991 e aggiornato (OSPFv2) con RFC 1583 nel Come in un qualsiasi protocollo link state, i router OSPF scambiano pacchetti di hello per scoprire quali sono i propri vicini e inviano tali informazioni in flooding su tutta la rete in Link State Packet. Ogni router mantiene in un database la versione più aggiornata del LSP di tutti i router presenti nel dominio; da questo database ricava la topologia della rete a cui applica l’algoritmo di Dijkstra; questo algoritmo, detto anche shortest path first, trasforma una struttura magliata in una ad albero scegliendo per ogni nodo il percorso a minimo costo. Ogni router, root dell’albero risultante dall’algoritmo, calcola così la tabella di instradamento.")
29
OSPF [Open Shortest Path First]
Type of service routing Load balancing (più cammini con lo stesso costo) Network partition Message authentication Network/Subnetw/host_specific routing Designed_router to accomodate multiaccess net Virtual Link La specifica è disponibile liberamente in letteratura, rendendo così il protocollo uno standard aperto (da cui la lettera O dell’acronimo) che chiunque può implementare senza dover pagare diritti di licenza, al fine di incentivare la sostituzione dei protocolli proprietari. 'OSPF supporta il routing basato sul tipo di servizio richiesto, in modo tale da consentire ai gestori delle reti di installare cammini diversi per ciascun tipo di servizio verso una data destinazione (ad esempio, cammini a basso ritardo o ad alto throughput); l'OSPF è il primo protocollo TCP/IP che offre questa funzionalità e un router che ne esegue l'algoritmo per scegliere il cammino dovrà ispezionare sia il campo destination address dell'header sia il campo type of service. L'OSPF consente il bilanciamento del carico sulla rete splittandolo su più cammini; se un gestore specifica più cammini verso una data destinazione allo stesso costo, l'OSPF distribuisce equamente il carico su tutti i cammini. Anche questa è una caratteristica innovativa rispetto ai precedenti algoritmi di routing, che utilizzavano un solo cammino per ogni destinazione. Per permettere la crescita della rete e comunque preservarne la facilità di gestione, l'OSPF consente di partizionare la rete ed i routers in sottoparti numerate dette aree, ciascuna delle quali è autonoma rispetto alle altre: la conoscenza della topologia interna di un'area rimane nascosta alle altre aree. In questo modo, più gruppi all'interno di uno stesso sito possono cooperare nell'uso dell'OSPF per il routing pur mantenendo ciascuno la possibilità di modificare la propria topologia interna indipendentemente dagli altri. L'OSPF specifica che tutti gli scambi tra i routers devono essere autenticati; consente una certa varietà di schemi di autenticazione, tra i quali ogni area può scegliere liberamente. Ciò è volto a garantire che solo routers affidabili propaghino informazioni di routing. In algoritmi che non prevedono questi meccanismi, come ad esempio il RIP, se qualcuno in malafede utilizza un computer per propagare messaggi RIP con cui si annunciano cammini a basso costo, gli altri routers e gli hosts che eseguono il RIP modificheranno di conseguenza i loro cammini, cominciando così ad inviare pacchetti a quel computer. L'OSPF supporta cammini sia host-specific che subnet ed anche network-specific. Per adattarsi anche alle reti multiaccesso, come ad esempio quelle di tipo Ethernet, l'OSPF estende l'algoritmo SPF. Un Link State protocol periodicamente invia in broadcast un messaggio link-status a ciascun reachable neighbor; se in una rete Ethernet vi sono k routers, nella rete vi saranno k*k messaggi. L'OSPF invece minimizza il broadcast definendo un grafo con una topologia più complessa in cui ciascun nodo rappresenta un router o una rete. Di conseguenza, esso consente ad ogni rete multiaccesso di avere un "designated router" che invia ai routers connessi alla rete i messaggi di link-status relativi a tutti i links della rete. . Per ottenere la massima flessibilità possibile, l'OSPF consente ai gestori di descrivere una topologia di rete virtuale che astrae dai dettagli delle comunicazioni fisiche; ad esempio il collegamento tra due routers può essere descritto come un semplice link anche se in realtà tra di essi vi dovesse essere una rete di transito. L'OSPF consente ai routers di scambiare informazioni di routing apprese da altri siti esterni. Uno o più routers con connessioni verso altri siti apprendono informazioni circa quei siti e le includono quando inviano i loro messaggi di link state update. Il formato di tali messaggi consente di distinguere tra le informazioni acquisite da sorgenti esterne ed informazioni provenienti dai routers interni al sito.
![OSPF [Open Shortest Path First]](http://slideplayer.it/slide/541549/1/images/29/OSPF+%5BOpen+Shortest+Path+First%5D.jpg "Type of service routing. Load balancing (più cammini con lo stesso costo) Network partition. Message authentication. Network/Subnetw/host_specific routing. Designed_router to accomodate multiaccess net. Virtual Link. La specifica è disponibile liberamente in letteratura, rendendo così il protocollo uno standard aperto (da cui la lettera O dell’acronimo) che chiunque può implementare senza dover pagare diritti di licenza, al fine di incentivare la sostituzione dei protocolli proprietari. OSPF supporta il routing basato sul tipo di servizio richiesto, in modo tale da consentire ai gestori delle reti di installare cammini diversi per ciascun tipo di servizio verso una data destinazione (ad esempio, cammini a basso ritardo o ad alto throughput); l OSPF è il primo protocollo TCP/IP che offre questa funzionalità e un router che ne esegue l algoritmo per scegliere il cammino dovrà ispezionare sia il campo destination address dell header sia il campo type of service. L OSPF consente il bilanciamento del carico sulla rete splittandolo su più cammini; se un gestore specifica più cammini verso una data destinazione allo stesso costo, l OSPF distribuisce equamente il carico su tutti i cammini. Anche questa è una caratteristica innovativa rispetto ai precedenti algoritmi di routing, che utilizzavano un solo cammino per ogni destinazione. Per permettere la crescita della rete e comunque preservarne la facilità di gestione, l OSPF consente di partizionare la rete ed i routers in sottoparti numerate dette aree, ciascuna delle quali è autonoma rispetto alle altre: la conoscenza della topologia interna di un area rimane nascosta alle altre aree. In questo modo, più gruppi all interno di uno stesso sito possono cooperare nell uso dell OSPF per il routing pur mantenendo ciascuno la possibilità di modificare la propria topologia interna indipendentemente dagli altri. L OSPF specifica che tutti gli scambi tra i routers devono essere autenticati; consente una certa varietà di schemi di autenticazione, tra i quali ogni area può scegliere liberamente. Ciò è volto a garantire che solo routers affidabili propaghino informazioni di routing. In algoritmi che non prevedono questi meccanismi, come ad esempio il RIP, se qualcuno in malafede utilizza un computer per propagare messaggi RIP con cui si annunciano cammini a basso costo, gli altri routers e gli hosts che eseguono il RIP modificheranno di conseguenza i loro cammini, cominciando così ad inviare pacchetti a quel computer. L OSPF supporta cammini sia host-specific che subnet ed anche network-specific. Per adattarsi anche alle reti multiaccesso, come ad esempio quelle di tipo Ethernet, l OSPF estende l algoritmo SPF. Un Link State protocol periodicamente invia in broadcast un messaggio link-status a ciascun reachable neighbor; se in una rete Ethernet vi sono k routers, nella rete vi saranno k*k messaggi. L OSPF invece minimizza il broadcast definendo un grafo con una topologia più complessa in cui ciascun nodo rappresenta un router o una rete. Di conseguenza, esso consente ad ogni rete multiaccesso di avere un designated router che invia ai routers connessi alla rete i messaggi di link-status relativi a tutti i links della rete. . Per ottenere la massima flessibilità possibile, l OSPF consente ai gestori di descrivere una topologia di rete virtuale che astrae dai dettagli delle comunicazioni fisiche; ad esempio il collegamento tra due routers può essere descritto come un semplice link anche se in realtà tra di essi vi dovesse essere una rete di transito. L OSPF consente ai routers di scambiare informazioni di routing apprese da altri siti esterni. Uno o più routers con connessioni verso altri siti apprendono informazioni circa quei siti e le includono quando inviano i loro messaggi di link state update. Il formato di tali messaggi consente di distinguere tra le informazioni acquisite da sorgenti esterne ed informazioni provenienti dai routers interni al sito.")
30
Type of service routing
OSPF consente l’uso di una metrica per ciascuna delle codifiche ammesse nel campo TOS di IP (D, T, R) Ogni LSP puo’ contenere una o piu’ metriche Ogni router calcola un albero distinto per ciascuna metrica Percorsi diversi per pacchetti con requisiti di servizio diversi 'OSPF supporta il routing basato sul tipo di servizio richiesto, in modo tale da consentire ai gestori delle reti di installare cammini diversi per ciascun tipo di servizio verso una data destinazione (ad esempio, cammini a basso ritardo o ad alto throughput); l'OSPF è il primo protocollo TCP/IP che offre questa funzionalità e un router che ne esegue l'algoritmo per scegliere il cammino dovrà ispezionare sia il campo destination address dell'header sia il campo type of service.
 Ogni LSP puo’ contenere una o piu’ metriche. Ogni router calcola un albero distinto per ciascuna metrica. Percorsi diversi per pacchetti con requisiti di servizio diversi. OSPF supporta il routing basato sul tipo di servizio richiesto, in modo tale da consentire ai gestori delle reti di installare cammini diversi per ciascun tipo di servizio verso una data destinazione (ad esempio, cammini a basso ritardo o ad alto throughput); l OSPF è il primo protocollo TCP/IP che offre questa funzionalità e un router che ne esegue l algoritmo per scegliere il cammino dovrà ispezionare sia il campo destination address dell header sia il campo type of service.")
31
Esempio di metrica OSPF
RTA Costo interfaccia = 108/(bandwidth in bps). 10 8 RTB 5 5 RTC Ad esempio il costo (o metrica) di un’interfaccia in OSPF è definito inversamente proporzionale alla larghezza di banda ad essa associata. La formula utilizzata per calcolare il costo è: costo = 108/(bandwidth in bps). 10 10 RTD 5
 RTB RTC Ad esempio il costo (o metrica) di un’interfaccia in OSPF è definito inversamente proporzionale alla larghezza di banda ad essa associata. La formula utilizzata per calcolare il costo è: costo = 108/(bandwidth in bps) RTD")
32
Load balancing 10 L'OSPF consente il bilanciamento del carico sulla rete splittandolo su più cammini; se un gestore specifica più cammini verso una data destinazione allo stesso costo, l'OSPF distribuisce equamente il carico su tutti i cammini. Anche questa è una caratteristica innovativa rispetto ai precedenti algoritmi di routing, che utilizzavano un solo cammino per ogni destinazione. 15

33
Designed_router to accomodate multiaccess net
LSA Designated router LSA Designated router LSA La propagazione degli LSA sulle reti ad accesso multiplo (es Ethernet) e’ particolarmente critica perche’ implica una trasmissione affidabile a un insieme di router. Questo richiede che il mittente gestisca una gran mole di informazioni e di timer per sapere quali destinatari hanno ricevuto ogni LSA e quando i pacchetti devono essere eventualmente ritrasmessi. Per evitare di sottoporre igni router a questo carico OSPF prevede che su LAN in cui si affaccino piu’ router venga eletto un designed router che e’ responsabile della propagazione degli LSA. Quando un router deve mandare degli LSA ai vari router della Lan, li invia al designed router che esegue una trasmissione multicast a tutti i router sulla Lan, tiene traccia delle conferme ricevute e effettua eventuali ritrasmissioni. L’elezione del designed router e’ basata su una priorita’ fornita in fase di configurazione che ogni router include negli Hello packet inviati (in multicast: ) (vedi approfondimento: adiacenze LAN)
 e’ particolarmente critica perche’ implica una trasmissione affidabile a un insieme di router. Questo richiede che il mittente gestisca una gran mole di informazioni e di timer per sapere quali destinatari hanno ricevuto ogni LSA e quando i pacchetti devono essere eventualmente ritrasmessi. Per evitare di sottoporre igni router a questo carico OSPF prevede che su LAN in cui si affaccino piu’ router venga eletto un designed router che e’ responsabile della propagazione degli LSA. Quando un router deve mandare degli LSA ai vari router della Lan, li invia al designed router che esegue una trasmissione multicast a tutti i router sulla Lan, tiene traccia delle conferme ricevute e effettua eventuali ritrasmissioni. L’elezione del designed router e’ basata su una priorita’ fornita in fase di configurazione che ogni router include negli Hello packet inviati (in multicast: ) (vedi approfondimento: adiacenze LAN)")
34
Designed_router = Pseudo nodo
LAN Designated router A B D C LSP Vicino metrica A 1 C 1 D 1 B A Designated router Rappresentazione a stella della rete LAN (designed router=pseudo nodo) A B C LSP Vicino metrica A 1 C 1 B 1 D 1 D La complessita’ computazionale dell’alg Link State e’ direttamente proporzionale al numero di collegamentinei LSA. Aas es una LAN con 4 router viene rappresentata dagli LSP come una maglia completa; il trattamento con Dijkstra richiederebbe quindi una notevole complessita’. Per evitare cio’ l’algoritmo OSPF prevede una procedura grazie alla quale le reti LAN (ad accesso multiplo) vengono rappresentate a stella: ogni nodo dichiara di essere vicino allo pseudo nodo; lo pseudo nodo dichiara di essere vicino a tutti gli altri nodi. C LSP D Vicino metrica A 1 B 1 D 1 Rappresentazione secondo l’algoritmo Link State della rete LAN
 A. B. C. LSP. Vicino metrica. A 1. C 1. B 1. D 1. D. La complessita’ computazionale dell’alg Link State e’ direttamente proporzionale al numero di collegamentinei LSA. Aas es una LAN con 4 router viene rappresentata dagli LSP come una maglia completa; il trattamento con Dijkstra richiederebbe quindi una notevole complessita’. Per evitare cio’ l’algoritmo OSPF prevede una procedura grazie alla quale le reti LAN (ad accesso multiplo) vengono rappresentate a stella: ogni nodo dichiara di essere vicino allo pseudo nodo; lo pseudo nodo dichiara di essere vicino a tutti gli altri nodi. C. LSP. D. Vicino metrica. A 1. B 1. D 1. Rappresentazione secondo l’algoritmo. Link State della rete LAN.")
35
Routing gerarchico La grandezza del database in cui vengono memorizzati i LSP, il tempo per l’elaborazione delle informazioni di routing e il volume dei messaggi scambiati aumentano al crescere delle dimensioni del dominio! Backbone Area #0 LSP Database Area 0 LSP Database Area 0 LSP Database Area 0 Come in un qualsiasi protocollo link state, anche in OSPF la grandezza del database in cui vengono memorizzati i LSP, il tempo per l’elaborazione delle informazioni di routing e il volume dei messaggi scambiati aumentano al crescere delle dimensioni del dominio, mettendo in crisi le performance dei router. La risposta a tale problema è quello di introdurre una gerarchia e di dividere il dominio di routing in diverse aree indipendenti direttamente connesse, eventualmente attraverso tunnel, ad un’area di backbone. Questo permette a OSPF di poter essere usato su reti di grandi dimensioni. Un dominio OSPF è quindi suddiviso in aree; ogni area contiene un gruppo di reti contigue e deve essere individuata da un area-id di 32 bit. Sui router va specificato per ogni interfaccia a quale area appartiene, sfruttando il parametro area-id. L’area di backbone viene indicata con area-id pari a 0. Un router ha un LSP database distinto per ogni area alla quale appartiene. Tutti i router appartenenti alla stessa area hanno lo stesso database. Il calcolo SPF è effettuato separatamente per ciascuna area. Il flooding dei LSP è confinato all’interno di un’area. Un classico esempio di gerarchia utilizzata per il routing è dato dalla rete telefonica, in cui ogni nodo di accesso e raccolta “vede” almeno due nodi di gerarchia superiore ai quali demanda il problema del routing delle chiamate in caso di destinazione remota (nelle reti gerarchiche è praticamente impossibile, a meno di errori di configurazione, l’innesco di loop). LSP Database Area 3 LSP Database Area 2 LSP Database Area 1 Area #1 Area #2 Area #3
. LSP. Database. Area 3. LSP. Database. Area 2. LSP. Database. Area 1. Area #1. Area #2. Area #3.")
36
Network partition OSPF ha il concetto di gerarchia
un AS (dominio OSPF) è suddiviso in aree le aree contengono un gruppo di reti contigue le aree sono indicate da un area-id su 32 bit deve essere specificato per ogni interfaccia quando un AS ha più di un’area deve esistere una backbone area con area-id = 0 e tutte le altre debbono interconnettersi a questa B .).
 è suddiviso in aree. le aree contengono un gruppo di reti contigue. le aree sono indicate da un area-id su 32 bit. deve essere specificato per ogni interfaccia. quando un AS ha più di un’area deve esistere una backbone area con area-id = 0 e tutte le altre debbono interconnettersi a questa. B .).")
37
OSPF: Topology/Link State Database
Un router ha un LSP database distinto per ogni area alla quale appartiene Tutti i router appartenenti alla stessa area hanno lo stesso database Il calcolo SPF è effettuato separatamente per ciascuna area LSP flooding è confinato all’interno di un’area

38
Classificazione dei router
Verso altri domini Area 4 Area 0 Area 2 Area 3 Internal Router Backbone Router Area Border Router Autonomous System Boundary Router I router OSPF in funzione della topologia del dominio possono essere così classificati: Internal router, router con tutte le interfacce appartenenti ad una stessa area; Backbone Router, router con interfacce appartenenti alla backbone area; Area Border Router (ABR), router con interfacce appartenenti ad aree diverse; Autonomous System Boundary Router (ASBR), router che importa nel dominio OSPF informazioni di routing ricavate da altri protocolli. Ogni area non backbone ha bisogno di un router di frontiera ABR verso l’area 0 da cui riceve informazioni sulle destinazioni esterne e in cui inietta informazioni sulle proprie reti.
, router con interfacce appartenenti ad aree diverse; Autonomous System Boundary Router (ASBR), router che importa nel dominio OSPF informazioni di routing ricavate da altri protocolli. Ogni area non backbone ha bisogno di un router. di frontiera ABR verso l’area 0 da cui riceve. informazioni sulle destinazioni esterne e in cui. inietta informazioni sulle proprie reti.")
39
Aree non direttamente connesse con il backbone:Virtual Link
Area 0 RouterB Area 2 Virtual Link RouterA Ogni area non backbone ha bisogno di un router di frontiera ABR verso l’area 0 da cui riceve informazioni sulle destinazioni esterne e in cui inietta informazioni sulle proprie reti. È possibile che la topologia porti ad avere delle aree non direttamente connesse con il backbone. Per risolvere una tale situazione si introducono i virtual link, con lo scopo di assicurare una connessione logica diretta con l’area 0. La backbone area risulta composta quindi da un insieme di reti fisiche (come le altre aree) e da virtual link; i virtual link sono link logici punto-punto tra coppie di ABR che hanno un’area non backbone in comune (detta transit area). Nella fase di implementazione un virtual link va configurato su entrambi gli ABR. I virtual link sono spesso indispensabili per creare un’area backbone totalmente connessa. Questo e’ un caso tipico in cui OSPF sfrutta la sua capacita’ di consentire ai gestori di descrivere una topologia di rete virtuale che astrae dai dettagli delle comunicazioni fisiche; ad esempio il collegamento tra due routers può essere descritto come un semplice link anche se in realtà tra di essi vi dovesse essere una rete di transito. Area 1 I virtual link sono link logici punto-punto tra coppie di ABR che hanno un’area non backbone in comune (detta transit area)
 e da virtual link; i virtual link sono link logici punto-punto tra coppie di ABR che hanno un’area non backbone in comune (detta transit area). Nella fase di implementazione un virtual link va configurato su entrambi gli ABR. I virtual link sono spesso indispensabili per creare un’area backbone totalmente connessa. Questo e’ un caso tipico in cui OSPF sfrutta la sua capacita’ di consentire ai gestori di descrivere una topologia di rete virtuale che astrae dai dettagli delle comunicazioni fisiche; ad esempio il collegamento tra due routers può essere descritto come un semplice link anche se in realtà tra di essi vi dovesse essere una rete di transito. Area 1. I virtual link sono link logici punto-punto tra coppie di ABR. che hanno un’area non backbone in comune (detta transit area)")
40
OSPF protocol: Header comune
vers type length Router ID Area ID checksum autype authentication authentication I router OSPF comunicano usando il protocollo OSPF, che viene imbustato direttamente in IP, con campo protocol 89; in realtà OSPF è composto da tre sottoprotocolli con diverse funzionalità: hello, exchange e flooding. Tutti i pacchetti OSPF partono con un header comune composto dai campi: version, indica la versione del protocollo OSPF in uso; la più recente è la versione 2; type, indica il tipo di pacchetto, ossia se appartenente al sottoprotocollo di hello, exchange (sincronizzazione dei DB) o flooding e ack; packet length, indica la lunghezza in byte del pacchetto; router ID, è l’indirizzo IP di una delle interfacce del router, usato per identificarlo; in genere si sceglie l’indirizzo più grande; area ID, è l’identificativo dell’area in cui si trova il router; il valore 0 è riservato per l’area di backbone; checksum, è usato per il controllo di errore su tutto il pacchetto OSPF, tranne il campo di autenticazione che viene riempito dopo aver calcolato il checksum; autype, indica il tipo di algoritmo usato per l’autenticazione del pacchetto. E’ possibile utilizzare due metodi di autenticazione (correntemente, 0 = no authentication, 1 = simple password) :
 o flooding e ack; packet length, indica la lunghezza in byte del pacchetto; router ID, è l’indirizzo IP di una delle interfacce del router, usato per identificarlo; in genere si sceglie l’indirizzo più grande; area ID, è l’identificativo dell’area in cui si trova il router; il valore 0 è riservato per l’area di backbone; checksum, è usato per il controllo di errore su tutto il pacchetto OSPF, tranne il campo di autenticazione che viene riempito dopo aver calcolato il checksum; autype, indica il tipo di algoritmo usato per l’autenticazione del pacchetto. E’ possibile utilizzare due metodi di autenticazione (correntemente, 0 = no authentication, 1 = simple password) :")
41
OSPF protocol: Type Type Meaning 1 Hello 2 Database description 3
Link status request 4 Link status update 5 Link status acknowledgement

42
Hello Protocol Il protocollo di Hello è usato per:
monitorare quali router siano attivi; monitorare quali link siano in funzione; eleggere il designated-router e il backup-designated-router nelle reti multi-accesso broadcast e non broadcast. I pacchetti di Hello vengono trasmessi periodicamente (di default 10 sec su LAN e interfacce punto-punto e 30 sec su reti NBMA) attraverso ciascuna interfaccia del router all’indirizzo multicast AllSPFRouters ( ). Il protocollo di Hello è usato per: - monitorare quali router siano attivi; - monitorare quali link siano in funzione; eleggere il designated-router e il backup-designated-router nelle reti multi-accesso broadcast e non broadcast.
 attraverso ciascuna interfaccia del router all’indirizzo multicast AllSPFRouters ( ). Il protocollo di Hello è usato per: - monitorare quali router siano attivi; - monitorare quali link siano in funzione; eleggere il designated-router e il backup-designated-router. nelle reti multi-accesso broadcast e non broadcast.")
43
Principali campi del pacchetto di Hello
BACKUP ripetuto per ogni neighbor L’intestazione comune prevede nel campo type il valore 1 per indicare un pacchetto di hello. Tutti i campi sono formati da 32 bit tranne il campo di hello interval di 16 bit e i campi opzioni e priorità di 8 bit ciascuno. Il pacchetto è costituito dai seguenti campi: Il campo Network mask contiene una maschera per la rete sulla quale il messaggio è stato inviato. Il campo Dead timer contiene un tempo in secondi scaduto il quale un neighbor che non risponde deve essere considerato irraggiungibile. Il campo Hello inter è l'intervallo di tempo normale tra due messaggi Hello. Il campo Gway Prio è la priorità, espressa come intero, di questo router ed è utilizzato nella scelta di un designated rouoter o di backup. I campi Designated router e Backup designated router contengono gli indirizzi IP che indicano il designated router ed il backup designated router per la rete sulla quale il messaggio è stato inviato. Infine, i campi Neighbor(i) IP address forniscono gli indirizzi IP di tutti i neighbors dai quali il mittente ha ricevuto recentemente messaggi Hello. Due router sono vicini o neighbor quando ognuno si riconosce nel pacchetto di hello dell’altro. In tal caso si parla di connessione two-way. Se ciò avviene in una sola direzione, si parla allora di connessione half-way. } Due router sono vicini o neighbor quando ognuno si riconosce nel pacchetto di hello dell’altro.
 IP address forniscono gli indirizzi IP di tutti i neighbors dai quali il mittente ha ricevuto recentemente messaggi Hello. Due router sono vicini o neighbor quando ognuno si riconosce nel pacchetto di hello dell’altro. In tal caso si parla di connessione two-way. Se ciò avviene in una sola direzione, si parla allora di connessione half-way. } Due router sono vicini o neighbor quando ognuno si riconosce. nel pacchetto di hello dell’altro.")
44
Database Description message
L’adiacenza è lo step successivo al processo di neighboring. I router adiacenti vanno oltre lo scambio dei pacchetti di Hello e procedono allo scambio dei database. Due router diventano adiacenti quando si sincronizzano, cioè quando verificano la situazione dei propri database e si portano in uno stato comune . A tale scopo si utilizza il Database Description Message. In altri termini I routers scambiano messaggi di DATABASE DESCRIPTION per inizializzare il loro database relativo alla topologia della rete; in questo scambio un router serve da master ed un altro veste i panni di slave. Quest'ultimo invia gli acks per ogni messaggio di questo tipo con una risposta. Poiché questo messaggio potrebbe risultare molto lungo, esso può essere spezzato in vari messaggi utilizzando i bit I e M; il primo è settato ad 1 nel messaggio iniziale mentre il secondo è settato ad 1 se vi sono messaggi addizionali seguenti. Il bit S indica quando un messaggio è stato inviato da un master (1) o da uno slave (0). Il protocollo di sincronizzazione quindi prevede di eleggere (in base all’identificatore) un master e uno slave. Il master trasmette i pacchetti di Database Description (DD) che contengono solo gli header dei LSP del database, ognuno con il proprio numero di sequenza. Lo slave per ogni pacchetto DD ricevuto, invia un pacchetto in cui utilizza il numero di sequenza del pacchetto ricevuto per confermarne la ricezione e inserisce la descrizione dei propri LSP. Il master trasmette un nuovo pacchetto DD solo dopo aver ricevuto la conferma del precedente. Se il master ha trasmesso tutte le informazioni necessarie e lo slave no, il master continua ad inviare pacchetti DD vuoti. Se un router si accorge dal contenuto di un pacchetto DD che gli mancano alcuni LSP, allora ne richiede la trasmissione inviando uno o più pacchetti di link state request e le informazioni richieste gli vengono inviate tramite pacchetti link state update; se invece si accorge che al mittente mancano alcuni LSP, allora glieli invia tramite pacchetti link state update. La differenza tra ciò che accade in una rete Multiple Access (broadcast o non broadcast) e una rete punto-punto è che in una rete ad accesso multiplo bisogna decidere chi sia il Designated Router e il Backup Designated Router nella fase di hello, perché poi i vari router si sincronizzano e diventano adiacenti solo con il DR e il BDR. L’adiacenza è lo step successivo al processo di neighboring. I router adiacenti vanno oltre lo scambio dei pacchetti di Hello e procedono allo scambio dei database. Due router diventano adiacenti quando si sincronizzano, cioè quando verificano la situazione dei propri database e si portano in uno stato comune . A tale scopo si utilizza il Database Description Message.
 o da uno slave (0). Il protocollo di sincronizzazione quindi prevede di eleggere (in base all’identificatore) un master e uno slave. Il master trasmette i pacchetti di Database Description (DD) che contengono solo gli header dei LSP del database, ognuno con il proprio numero di sequenza. Lo slave per ogni pacchetto DD ricevuto, invia un pacchetto in cui utilizza il numero di sequenza del pacchetto ricevuto per confermarne la ricezione e inserisce la descrizione dei propri LSP. Il master trasmette un nuovo pacchetto DD solo dopo aver ricevuto la conferma del precedente. Se il master ha trasmesso tutte le informazioni necessarie e lo slave no, il master continua ad inviare pacchetti DD vuoti. Se un router si accorge dal contenuto di un pacchetto DD che gli mancano alcuni LSP, allora ne richiede la trasmissione inviando uno o più pacchetti di link state request e le informazioni richieste gli vengono inviate tramite pacchetti link state update; se invece si accorge che al mittente mancano alcuni LSP, allora glieli invia tramite pacchetti link state update. La differenza tra ciò che accade in una rete Multiple Access (broadcast o non broadcast) e una rete punto-punto è che in una rete ad accesso multiplo bisogna decidere chi sia il Designated Router e il Backup Designated Router nella fase di hello, perché poi i vari router si sincronizzano e diventano adiacenti solo con il DR e il BDR. L’adiacenza è lo step successivo al processo di neighboring. I router adiacenti vanno. oltre lo scambio dei pacchetti di Hello e procedono allo scambio dei database. Due router diventano adiacenti quando si sincronizzano, cioè quando verificano la. situazione dei propri database e si portano in uno stato comune . A tale scopo si utilizza. il Database Description Message.")
45
LINK STATE REQUEST Dopo aver scambiato i messaggi relativi alla descrizione del database con i vicini, un router può scoprire che parti dei suoi databases sono da aggiornare. Per richiedere al neighbor di fornire le informazioni aggiornate, il router invia un messaggio LINK STATE REQUEST, che elenca specifici links i tre campi mostrati sono ripetuti per ciascun link sul quale sono richieste le informazioni

46
LINK STATE UPDATE Link state advertisment
Il neighbor risponde con le informazioni più aggiornate in suo possesso circa il link richiesto (Link State Update) Ciascun router comunque periodicamente invia un messaggio LINK STATE UPDATE a ciascun router adiacente (anche in assenza di richiesta) , che include il proprio stato e fornisce i costi utilizzati nel database della topologia. I routers inviano tale messaggio anche quando si modificano i costi, vi è una nuova linea o una linea cade. Link state advertisment
 Ciascun router comunque periodicamente invia un messaggio LINK STATE UPDATE a ciascun router adiacente (anche in assenza di richiesta) , che include il proprio stato e fornisce i costi utilizzati nel database della topologia. I routers inviano tale messaggio anche quando si modificano i costi, vi è una nuova linea o una linea cade. Link state advertisment.")
47
Vengono eletti il DR e il BDR
Adiacenze su LAN 2-Way Ma non adiacenti DR BDR Vengono eletti il DR e il BDR In particolare: Sulle LAN vengono eletti: un Designated Router (DR) un Backup Designated Router (BDR) L’elezione viene effettuata tramite i pacchetti di Hello. Il DR e il backup DR ricevono all’indirizzo multicast AllDRouters ( ). Il DR invia gli annunci a tutti gli altri router connessi alla rete multiaccesso all’indirizzo multicast AllSPFRouters ( ). Gli altri router inviano gli annunci al DR e al BDR all’indirizzo AllDRouters. L’elezione del Designated Router può essere fatta: attraverso la priorità dell’interfaccia che viene fissata manualmente dal gestore, che quindi decide chi deve essere il designated router; nel caso di più interfacce con la stessa priorità il DR viene determinato tramite il più alto router ID, dove il Router ID è pari all’indirizzo IP di valore più alto tra quelli delle interfacce del router. Sulla LAN tutti i router stabiliscono relazioni di neighbor del tipo two-way tra di loro, ma un router diventa adiacente solo con il DR e con il BDR. La sincronizzazione di tutti i router con il DR e con il BDR fa sì che tutti i router abbiano tutti lo stesso database. Sulla LAN tutti i router stabiliscono relazioni di neighbor del tipo two-way tra di loro, ma un router diventa adiacente solo con il DR e con il BDR. La sincronizzazione di tutti i router con il DR e con il BDR fa sì che tutti i router abbiano tutti lo stesso database.
 un Backup Designated Router (BDR) L’elezione viene effettuata tramite i pacchetti di Hello. Il DR e il backup DR ricevono all’indirizzo multicast AllDRouters ( ). Il DR invia gli annunci a tutti gli altri router connessi alla rete multiaccesso all’indirizzo multicast AllSPFRouters ( ). Gli altri router inviano gli annunci al DR e al BDR all’indirizzo AllDRouters. L’elezione del Designated Router può essere fatta: attraverso la priorità dell’interfaccia che viene fissata manualmente dal gestore, che quindi decide chi deve essere il designated router; nel caso di più interfacce con la stessa priorità il DR viene determinato tramite il più alto router ID, dove il Router ID è pari all’indirizzo IP di valore più alto tra quelli delle interfacce del router. Sulla LAN tutti i router stabiliscono relazioni di neighbor del tipo two-way tra di loro, ma un router diventa adiacente solo con il DR e con il BDR. La sincronizzazione di tutti i router con il DR e con il BDR fa sì che tutti i router abbiano tutti lo stesso database. Sulla LAN tutti i router stabiliscono relazioni di neighbor del. tipo two-way tra di loro, ma un router diventa adiacente solo con il. DR e con il BDR. La sincronizzazione di tutti i router con il DR e con. il BDR fa sì che tutti i router abbiano tutti lo stesso database.")
48
Tipi di route (approfondimento )
Un cammino selezionato da OSPF può essere: intra-area: se è interno ad un’area OSPF inter-area: se oltrepassa i limiti delle aree external: se oltrepassa i limiti del dominio OSPF Route intra-area Deriva dai LSP che descrivono la topologia dell’area; il suo costo è la somma dei costi OSPF dei link lungo il percorso selezionato; i virtual link vengono annunciati con un costo pari a quello del loro percorso intra-area nell’area non backbone. Route inter-area Deriva dai summary advertisement introdotti nell’area dagli ABR. Il suo costo è dato dalla somma tra il costo del percorso intra-area verso l’ABR che produce il summary advertisement, più il costo dall’ABR alla destinazione. Route external Deriva dagli external advertisement prodotti dagli ASBR del dominio, che possono essere di tipo 1 o di tipo 2: il costo di una route verso una destinazione external type 1 è la somma del costo verso l’ASBR che produce l’advertisement e il costo da questo alla destinazione; il costo di una route verso una destinazione external type 2 è dato dal solo costo dell’ASBR che produce l’advertisement alla destinazione. OSPF può avere più route per la stessa destinazione. Le route vengono scelte nel seguente ordine: intra-area inter-area external type 1 external type 2 Quando esistono più route dello stesso tipo viene scelta quella a costo minore; quando più route dello stesso tipo hanno lo stesso costo (minimo) il traffico è ripartito in modo uguale tra esse.
 il traffico è ripartito in modo uguale tra esse.")
49
Design Tips Numero di router per area: Numero di neighbors:
tipicamente il numero massimo è di 40/50 router per area Numero di neighbors: minore è il numero di neighbors presenti su una LAN minori sono il numero di adiacenze che un DR o un BDR deve formare se possibile, evitare che uno stesso router sia DR su più di un segmento Numero di aree per ABR gli ABRs mantengono una copia del database per ciascuna delle aree servite un router non deve stare in più di tre aree, la backbone area più una o due aree non backbone

50
OSPF vs RIP OSPF RIP Scalabilità Banda Buona Bassa Bassa Alta Memoria
CPU Alta Bassa Il confronto tra OSPF e RIP è quello tra due particolari implementazioni di algoritmi della famiglia link state e distance vector. Analizzando una voce alla volta, OSPF assicura grazie al meccanismo di routing gerarchico, una scalabilità su reti di grandi dimensioni, mentre l’hop-count-limit limita la dimensione massima di una rete RIP. Il RIP prevede lo scambio periodico di distance vector, con grande occupazione di banda, mentre in OSPF si scambiano nuovi LSP solo quando c’è una effettiva variazione della topologia. Per contro il RIP è semplice e poco pesante per il router in termini di memoria e capacità elaborativa occupata. OSPF, come un qualsiasi protocollo link state, deve mantenere un database con le versioni più recenti dei LSP di tutti i router del dominio; il routing gerarchico dà una mano in questo senso a patto di avere aree formate al massimo da circa 50 router e di non avere router su più di due o tre aree. OSPF converge ad una situazione stabile molto velocemente grazie al meccanismo di flooding che assicura l’aggiornamento alle variazioni della topologia in tempi rapidi e per tutti i router, mentre RIP è lento in convergenza e ha problemi di stabilità con la possibilità di loop. Il RIP è sicuramente molto più semplice per quanto riguarda la configurazione e la ricerca di eventuali errori di implementazione. Convergenza Configurazione Veloce Moderata Lenta Facile

51
Algoritmi utilizzati per propagare le informazioni relative al routing nel core system.
Usato oggi nel Core in Internet Vector Distance (GGP) Shortest Path First (OSPF)
 Shortest. Path First. (OSPF)")
52
Gli interior router instradano pacchetti all’interno di un dominio
Gli interior router instradano pacchetti all’interno di un dominio. Le informazioni di instradamento vengono scambiate tra questi router attraverso protocolli di instradamento detti in maniera generica Interior Gateway Protocol (IGP). Gli exterior router devono scambiare informazioni sulle destinazioni esterne al dominio o all’AS, con dei protocolli detti Exterior Gateway Protocol (EGP). Il RIP e OSPF sono protocolli IGP, mentre protocolli del tipo exterior router, sono: EGP, il primo ad essere usato ma oggi abbandonato, e il Border Gateway Protocol (BGP), usato oggi nella sua versione più recente tra tutte le backbone in internet. EGP viene utilizzato per pesare i percorsi fra AS e far seguire al traffico percorsi scelti in conformità ad accordi commerciali stipulati fra gestori diversi. La tabella di routing viene determinata dagli attributi e dalle politiche di routing. Nel BGP la base è nell’aggregazione, perciò gli indirizzi devono essere conosciuti. Ciò comporta che non essendoci nel backbone un default router, le tabelle di routing avranno migliaia di righe.
. Gli exterior router devono scambiare informazioni sulle destinazioni esterne al dominio o all’AS, con dei protocolli detti Exterior Gateway Protocol (EGP). Il RIP e OSPF sono protocolli IGP, mentre protocolli del tipo exterior router, sono: EGP, il primo ad essere usato ma oggi abbandonato, e il Border Gateway Protocol (BGP), usato oggi nella sua versione più recente tra tutte le backbone in internet. EGP viene utilizzato per pesare i percorsi fra AS e far seguire al traffico percorsi scelti in conformità ad accordi commerciali stipulati fra gestori diversi. La tabella di routing viene determinata dagli attributi e dalle politiche di routing. Nel BGP la base è nell’aggregazione, perciò gli indirizzi devono essere conosciuti. Ciò comporta che non essendoci nel backbone un default router, le tabelle di routing avranno migliaia di righe.")
53
Problema dell’istradamento InterAS
Le dimensioni: un router della rete backbone deve essere in grado di istradare verso una qualsiasi rete in Internet (anche con l’ausilio di CIRD tali router gestiscono circa prefissi..) I vari AS utilizzano diversi protocolli di routing e quindi diverse metriche; confrontare i valori di tali metriche potrebbe non aver senso. Trovare un percorso “qualsiasi” che permetta di raggiungere la destinazione senza loop Il problema dell’routing interAS e’ troppo complesso, per cui ci si accontenta di ottenerela raggiungibilita’ piuttosto che la minimizzazione di una qualche metrica. Le principali difficolta’ riguardano: - Le dimensioni: un router della rete backbone deve essere in grado di istradare verso una qualsiasi rete in Internet (anche con l’ausilio di CIRD tali router gestiscono circa prefissi..) -I vari AS utilizzano diversi protocoli di routing e quindi diverse metriche; confrontare i valori di tali metriche potrebbe non aver senso. Il protocollo di routing interAS deve piuttosto dare la possibilita’ di definire “politiche” differenti (ad es.: un AS connesso a due AS puo’ non accettare traffico in transito tra questi, oppure utilizzare un AS come transito per un certo tipo di destinazioni e l’altro per le altre….) Tali politiche tendono quindi di specificare percorsi “buoni” non necessariamente ottimi
 I vari AS utilizzano diversi protocolli di routing e quindi diverse metriche; confrontare i valori di tali metriche potrebbe non aver senso. Trovare un percorso qualsiasi che permetta di raggiungere la destinazione senza loop. Il problema dell’routing interAS e’ troppo complesso, per cui ci si accontenta di ottenerela raggiungibilita’ piuttosto che la minimizzazione di una qualche metrica. Le principali difficolta’ riguardano: - Le dimensioni: un router della rete backbone deve essere in grado di istradare verso una qualsiasi rete in Internet (anche con l’ausilio di CIRD tali router gestiscono circa prefissi..) -I vari AS utilizzano diversi protocoli di routing e quindi diverse metriche; confrontare i valori di tali metriche potrebbe non aver senso. Il protocollo di routing interAS deve piuttosto dare la possibilita’ di definire politiche differenti (ad es.: un AS connesso a due AS puo’ non accettare traffico in transito tra questi, oppure utilizzare un AS come transito per un certo tipo di destinazioni e l’altro per le altre….) Tali politiche tendono quindi di specificare percorsi buoni non necessariamente ottimi.")
54
EGP AS34 AS1 Net1 AS16 Net1 Net16 AS8
For net in AS1 to send traffic to net in AS16: • AS16 must announce to AS8. • AS8 must accept from AS16. • AS8 must announce to AS1 or AS34. • AS1 must accept from AS8 or AS34. For two-way packet flow, similar policies must exist from AS1 to AS16. E’ stato il primo InterAS routing protocol usato in Internet; oggi e’ in disuso ed e’ stato sostituito da BGP

55
Funzioni del protocollo EGP
Neighbor acquisition Acquisition request Richiede ad un router di divenire un neighbor Acquisition confirm Il router accetta Acquisition refuse Il router rifiuta Cease request Richiede la fine della relazione Cease confirm Conferma la fine della relazione Neighbor reachability Hello Richiede al neighbor di confermare la relazione precedentemente stabilita I-heard-you Conferma Routing update Poll request Richiede l'update della network reachability Routing update Informazioni di network reachability (solo reti interne all’AS se il router non appartiene al Core system) Error response Error Risposta a messaggi scorretti
 Error response. Error Risposta a messaggi scorretti.")
56
EGP:routing update No Loop!

57
EGP HEADER

58
EGP: svantaggi EGP presuppone una relazione “padre/figlio tra i border gateway. Ciò perche’ EGP è stato definito quando Internet aveva una struttura ad albero!

59
port 179 (Path Vector) Il Border Gateway Protocol (BGP) è un exterior gateway protocol usato per lo scambio di informazioni di routing tra AS pensato per rimpiazzare il vecchio EGP. Il BGP è stato specificato per la prima volta in RFC 1105 del 1988, per poi essere aggiornato più volte fino alla versione più recente, la BGP4, in RFC BGP utilizza il protocollo di trasporto TCP (port 179); questo gli garantisce un trasferimento delle informazioni sicuro, con ritrasmissioni per il recupero di errore, ma crea problemi in fase di congestione dove il TCP rallenta il rate di trasmissione. Il BGP è un protocollo di tipo DV; in realtà è un Path-vector: per ogni destinazione vengono annunciati gli Autonomous System da attraversare (AS_PATH) nel percorso. Questo perché quando un exterior router riceve un annuncio verso una certa destinazione, lo inoltra, secondo le politiche di routing implementate, aggiungendo l’identificativo del proprio AS. Con un meccanismo path vector non si possono creare dei loop: un router BGP scarta un annuncio se trova il suo AS_NUMBER nel AS_PATH. I messaggi del tipo path vector sono molto più lunghi dei normali distance vector. Quindi per minimizzare il traffico e diminuire nello stesso tempo il numero di entry da tenere in memoria, non si annunciano le singole sottoreti, ma si cerca di fare quando possibile dei sommari, cioè di accorpare in un unico annuncio gli indirizzi relativi a diverse sottoreti.
 è un exterior gateway protocol usato per lo scambio di informazioni di routing tra AS pensato per rimpiazzare il vecchio EGP. Il BGP è stato specificato per la prima volta in RFC 1105 del 1988, per poi essere aggiornato più volte fino alla versione più recente, la BGP4, in RFC BGP utilizza il protocollo di trasporto TCP (port 179); questo gli garantisce un trasferimento delle informazioni sicuro, con ritrasmissioni per il recupero di errore, ma crea problemi in fase di congestione dove il TCP rallenta il rate di trasmissione. Il BGP è un protocollo di tipo DV; in realtà è un Path-vector: per ogni destinazione vengono annunciati gli Autonomous System da attraversare (AS_PATH) nel percorso. Questo perché quando un exterior router riceve un annuncio verso una certa destinazione, lo inoltra, secondo le politiche di routing implementate, aggiungendo l’identificativo del proprio AS. Con un meccanismo path vector non si possono creare dei loop: un router BGP scarta un annuncio se trova il suo AS_NUMBER nel AS_PATH. I messaggi del tipo path vector sono molto più lunghi dei normali distance vector. Quindi per minimizzare il traffico e diminuire nello stesso tempo il numero di entry da tenere in memoria, non si annunciano le singole sottoreti, ma si cerca di fare quando possibile dei sommari, cioè di accorpare in un unico annuncio gli indirizzi relativi a diverse sottoreti.")
60
eBGP eBGP Due router che scambiano informazioni con BGP (exterior routers) attraverso una connessione TCP sono detti peers o neighbors. Su un exterior router va configurato esplicitamente l’indirizzo del router o dei router di peer. Il protocollo prevede una fase di inizializzazione alla partenza di uno dei router per la sincronizzazione; questa fase prevede lo scambio delle routing table; successivamente verranno scambiati solo gli updates se ci sono variazioni. Il peer di un router può appartenere ad un altro AS (EBGP) o allo stesso AS (IBGP). In quest’ultimo caso la connessione passa internamente al AS, ma non va ad interessare gli interior router perché i pacchetti fanno parte di una connessione end-to-end tra i due exterior router coinvolti. Le route che un exterior router ha appreso attraverso BGP, vanno ridistribuite all’interno dell’AS. Per quanto riguarda il processo di decisione, occorre osservare quanto segue: BGP mantiene un solo path-vector per destinazione: il best-path. La scelta è effettuata in base ad attributi contenuti negli annunci (AS_PATH) e a politiche di routing implementate (route-map, access-list) sul router. Il path-vector di un annuncio indica quali AS bisogna attraversare per raggiungere una certa destinazione (differentemente dai IGP di tipo distance vector quindi, BGP annuncia il percorso completo, come EGP. Cio’ permette di evitare loop nell’istradamento). L’exterior router può scegliere, tra diversi annunci, di mantenere in memoria ed usare quello relativo a degli AS con cui il proprio AS ha degli accordi per il trasporto di traffico. Anche gli annunci da propagare vengono scelti in base a politiche di routing; in genere BGP annuncia ai suoi neighbor solo il best-path. iBGP
 attraverso una connessione TCP sono detti peers o neighbors. Su un exterior router va configurato esplicitamente l’indirizzo del router o dei router di peer. Il protocollo prevede una fase di inizializzazione alla partenza di uno dei router per la sincronizzazione; questa fase prevede lo scambio delle routing table; successivamente verranno scambiati solo gli updates se ci sono variazioni. Il peer di un router può appartenere ad un altro AS (EBGP) o allo stesso AS (IBGP). In quest’ultimo caso la connessione passa internamente al AS, ma non va ad interessare gli interior router perché i pacchetti fanno parte di una connessione end-to-end tra i due exterior router coinvolti. Le route che un exterior router ha appreso attraverso BGP, vanno ridistribuite all’interno dell’AS. Per quanto riguarda il processo di decisione, occorre osservare quanto segue: BGP mantiene un solo path-vector per destinazione: il best-path. La scelta è effettuata in base ad attributi contenuti negli annunci (AS_PATH) e a politiche di routing implementate (route-map, access-list) sul router. Il path-vector di un annuncio indica quali AS bisogna attraversare per raggiungere una certa destinazione (differentemente dai IGP di tipo distance vector quindi, BGP annuncia il percorso completo, come EGP. Cio’ permette di evitare loop nell’istradamento). L’exterior router può scegliere, tra diversi annunci, di mantenere in memoria ed usare quello relativo a degli AS con cui il proprio AS ha degli accordi per il trasporto di traffico. Anche gli annunci da propagare vengono scelti in base a politiche di routing; in genere BGP annuncia ai suoi neighbor solo il best-path. iBGP.")
61
Messaggi BGP Open Update Keepalive Notification

62
Header comune Marker dimensione tipo
Marker: campo a 16 byte riservato all’autenticazione Dimensione: dimensione complessiva del messaggio Tipo: tipo di pacchetto

63
Router che ha inviato mess. open
Messaggio Open Marker dimensione tipo versione mio AS Hold time Router che ha inviato mess. open options opt dimens. Un BGR crea una relazione di prossimità aprendo una connessione TCP con il vicino e inviandogli un messaggio di OPEN

64
Messaggio update Marker dimensione tipo Percorsi annullati
Unfeasible route len. Percorsi annullati Unfeasible route len Path attribute len. Attributi percorso Rete notificata Usato per annullare destinazioni già notificate o per notificare un percorso verso nuove destinazioni

65
Messaggio keep-alive Marker dimensione tipo

66
Messaggio Notification
Marker dimensione tipo Error code. Error data Error sub-code

68
AS200

69
Processo di decisione Per quanto riguarda il processo di decisione, occorre osservare quanto segue: BGP mantiene un solo path-vector per destinazione: il best-path. La scelta è effettuata in base ad attributi contenuti negli annunci (AS_PATH) e a politiche di routing implementate (route-map, access-list) sul router. Il path-vector di un annuncio indica quali AS bisogna attraversare per raggiungere una certa destinazione. L’exterior router può scegliere, tra diversi annunci, di mantenere in memoria ed usare quello relativo a degli AS con cui il proprio AS ha degli accordi per il trasporto di traffico. Anche gli annunci da propagare vengono scelti in base a politiche di routing; in genere BGP annuncia ai suoi neighbor solo il best-path.
 e a politiche di routing implementate (route-map, access-list) sul router. Il path-vector di un annuncio indica quali AS bisogna attraversare per raggiungere una certa destinazione. L’exterior router può scegliere, tra diversi annunci, di mantenere in memoria ed usare quello relativo a degli AS con cui il proprio AS ha degli accordi per il trasporto di traffico. Anche gli annunci da propagare vengono scelti in base a politiche di routing; in genere BGP annuncia ai suoi neighbor solo il best-path.")
70
Il Class Less interDomain Routing (CIDR) è una modalità di propagazione dell’informazione di raggiungibilità, quindi di annuncio delle reti IP, con trasporto di indirizzo IP e di maschera. Il CIDR è specificato in RFC 1517, RFC 1581, RFC 1519 e RFC CIDR supporta due importanti caratteristiche che hanno portato grossi benefici al sistema di routing di Internet: elimina il concetto tradizionale di indirizzi di rete di classe A, classe B e classe C, consentendo un’allocazione efficiente dello spazio degli indirizzi IP; supporta l’aggregazione degli indirizzi, consentendo di rappresentare lo spazio di indirizzi di migliaia di reti classfull tradizionali in una singola entry nella tabella di routing. CIDR permette quindi di trasmettere indirizzi contigui come se fossero un indirizzo solo, usando maschere più corte di quelle naturali, e riduce la quantità di informazioni che devono essere propagate. È supportato da OSPF e dalla versione più recente di BGP, il BGP4.

72
L’interconnessione di reti eterogenee
Macrolezione 6: L’interconnessione di reti eterogenee

Presentazioni simili
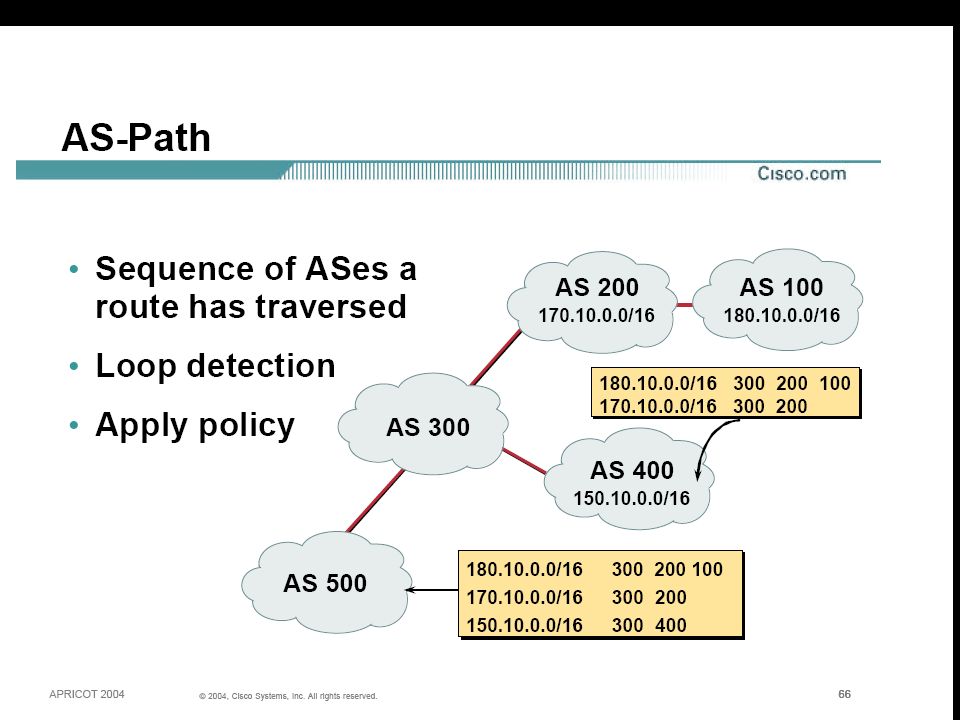
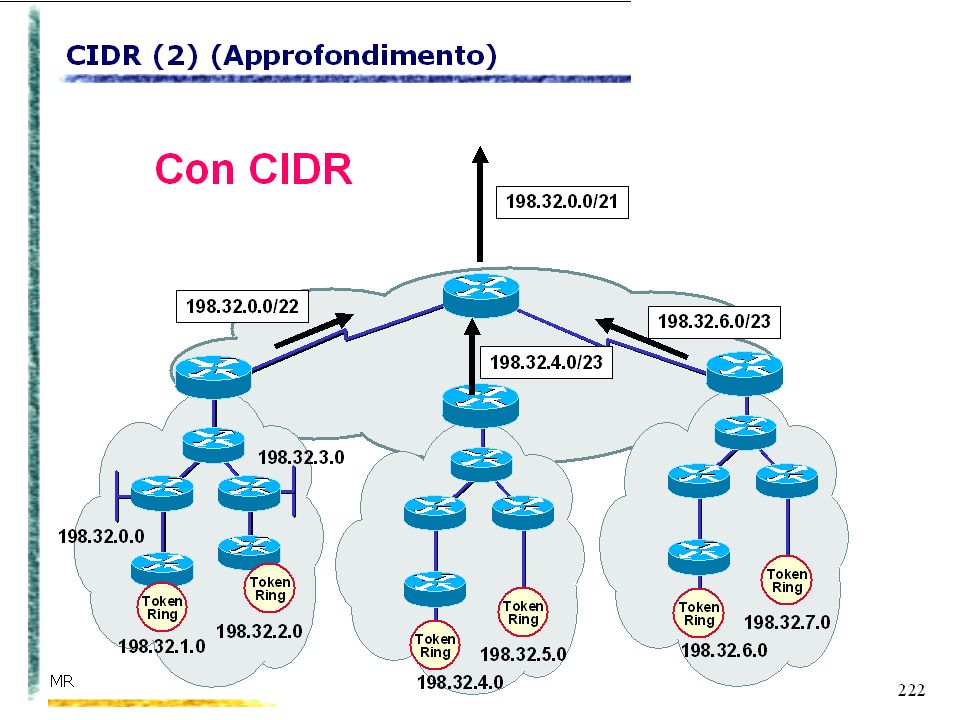











>")
>")

: applicazioni e host>")


 Un collegamento end-to-end è formato da tre tratte, la prima AB con la velocità di 5 Mb/s, la seconda BC di 20 Mb/s e la terza CD di.>")

