Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Caratteristiche operative dei test diagnostici e curve ROC
Prof. Vieri Boddi Dipartimento di Sanità Pubblica, Università di Firenze

2
Un breve ripasso della “probabilità”
definiamo probabilità di successo il rapporto fra il numero di successi e numero totale di prove fatte P = s/n Probabilità del 3 lanciando un dado a 6 facce P(3) = 1/6 Definito successo il trovare un paziente guarito, calcoliamo la probabilità di trovare un guarito in un gruppo di N pazienti dal rapporto fra numero di guariti (G) e il totale dei pazienti: P(G) = (G) / N. Su 130 pazienti contiamo 77 guariti, P(G) = 77/130 = ovvero 59.2%.
 = 1/6. Definito successo il trovare un paziente guarito, calcoliamo la probabilità di trovare un guarito in un gruppo di N pazienti dal rapporto fra numero di guariti (G) e il totale dei pazienti: P(G) = (G) / N. Su 130 pazienti contiamo 77 guariti, P(G) = 77/130 = ovvero 59.2%.")
3
Ancora su probabilità La probabilità è un numero che varia fra 0 (evento impossibile) e 1 (evento certo). La probabilità che avvenga uno o un altro evento fra eventi che si escludono a vicenda è data dalla somma delle probabilità dei singoli eventi. La probabilità di un numero pari in un lancio di un dado è data dal rapporto fra (numero di risultati pari / numero i risultati possibili) P( o 2 o 4 o 6) = 3/6 = 0.50 P(2) = 1/6 P(4) = 1/6 P(6) = 1/6 P( o 2 o 4 o 6) = P(2) + P(4) + P(6)
 P( o 2 o 4 o 6) = 3/6 = P(2) = 1/6 P(4) = 1/6 P(6) = 1/6. P( o 2 o 4 o 6) = P(2) + P(4) + P(6)")
4
Ancora su probabilità La probabilità che avvengano insieme eventi indipendenti è data dal prodotto delle probabilità dei singoli eventi. La probabilità di ottenere due teste lanciando due monete è data dal rapporto fra numero di modi di ottenere due teste e il numero di possibili risultati diversi. Possibili risultati diversi: T1eT2 T1eC2 C1eT2 C1eC2; fra questi c’è un solo successo T1eT2. P(T1eT2) = 1/4 P(T1) = 1/2 P(T2) = 1/2 P(T1eT2) = P(T1)*P(T2)
 = 1/4. P(T1) = 1/2 P(T2) = 1/2. P(T1eT2) = P(T1)*P(T2)")
5
Ancora su probabilità Si abbia un mazzo di 40 carte; si vuol calcolare la probabilità che la seconda carta estratta sia un re (K) P(2°K). Tale probabilità dipende (è condizionata) dal risultato della prima estrazione e dal destino della prima carta. P(1°K) = 4/40 = 0.10 P(2°K) = 4/40 = 0.10 se la prima è stata reinserita nel mazzo dopo la prima estrazione P(2°K) = 4/39 = se la prima non era un K ed è rimasta sul tavolo => P(2°K|1° non K) Si legge “probabilità che la seconda sia K dato che (a condizione che) la prima non era K (ed è rimasta sul tavolo)” => Probabilità condizionale P(2°K) = 3/39 = se la prima era un K ed è rimasta sul tavolo => P(2°K|1° K)
 dal risultato della prima estrazione e dal destino della prima carta. P(1°K) = 4/40 = P(2°K) = 4/40 = 0.10 se la prima è stata reinserita nel mazzo dopo la prima estrazione. P(2°K) = 4/39 = se la prima non era un K ed è rimasta sul tavolo => P(2°K|1° non K) Si legge probabilità che la seconda sia K dato che (a condizione che) la prima non era K (ed è rimasta sul tavolo) => Probabilità condizionale. P(2°K) = 3/39 = se la prima era un K ed è rimasta sul tavolo => P(2°K|1° K)")
6
Teorema di Bayes Teorema di Bayes P(B|A) = P(AeB) / P(A)
P(AeB) = P(B|A) * P(A) La probabilità che avvenga l’evento B a condizione che sia avvenuto l’evento A è data dalla probabilità che avvengano sia A che B divisa per la probabilità che avvenga l’evento condizione (A).
 = P(B|A) * P(A) La probabilità che avvenga l’evento B a condizione che sia avvenuto l’evento A è data dalla probabilità che avvengano sia A che B divisa per la probabilità che avvenga l’evento condizione (A).")
7
Esempio tabella 2x2 Femmine Maschi Occhiali SI 80 70 150 Occhiali NO
20 30 50 Totale 100 200

8
Nella tabella precedente è riportata una casistica relativa
a 200 pazienti di uno studio dentistico, ciascuno classificato in base al sesso e all’uso di occhiali. In tabelle di questo tipo si possono stimare varie probabilità, immaginando di estrarre a caso una cartella. Probabilità di estrarre la cartella di una femmina P(F) = 100/200 Probabilità di estrarre la cartella di una persona che non usa gli occhiali P(ON) = 50/200=0.25 P(MeOS) = 70/200 = 0.35 Se è noto che si sta estraendo una cartella di una femmina, quale è la probabilità che questa usi gli occhiali; caso tipico di probabilità condizionale P(OS|F) = 80/100= 0.80 P(F|OS) = ? P(ON|M) = ? P(FeON) = ?
 = 100/200. Probabilità di estrarre la cartella di una persona che non usa gli. occhiali P(ON) = 50/200=0.25. P(MeOS) = 70/200 = Se è noto che si sta estraendo una cartella di una femmina, quale. è la probabilità che questa usi gli occhiali; caso tipico di. probabilità condizionale P(OS|F) = 80/100= P(F|OS) = P(ON|M) = P(FeON) =")
9
Test diagnostici 1 La diagnosi è un aspetto importante della pratica clinica; la ricerca clinica è in buona parte rivolta a migliorare i metodi diagnostici. Caso più semplice: i pazienti possono essere classificati in due gruppi, distinti e ben definiti, in base a criteri ben codificati. (D+ e D- Disease) ; si cerca un metodo (test diagnostico) che permetta di individuare nel modo migliore il “vero” stato di salute dei pazienti (T+ e T- risultato del Test).
 ; si cerca un metodo (test diagnostico) che permetta di individuare nel modo migliore il vero stato di salute dei pazienti (T+ e T- risultato del Test).")
10
Test diagnostici 2 La bontà di un test diagnostico viene valutata dal confronto dei risultati del test in esame con quelli di un test ‘definitivo’ (per esempio biopsia, autopsia) o di un ‘gold standard’ (test accettato come riferimento); deve cioè esistere un metodo, indipendente da quello in esame, per determinare con ‘certezza’ quali sono i malati (D+) e quali i non malati (D-).
 o di un ‘gold standard’ (test accettato come riferimento); deve cioè esistere un metodo, indipendente da quello in esame, per determinare con ‘certezza’ quali sono i malati (D+) e quali i non malati (D-).")
11
D+ D- Totale T+ 39 2 falsi positivi 41 T- 1 falsi negativi 25 26 40 27
Si abbia una casistica relativa a 67 pazienti, classificati in base alla malattia (D+ o D-) e al risultato di un test diagnostico (T+ o T-). D+ D- Totale T+ 39 2 falsi positivi 41 T- 1 falsi negativi 25 26 40 27 67 Si possono stimare varie probabilità che, in questo contesto hanno nomi particolari: Sensibilità = P(T+|D+) Specificità = P(T-|D-) Solo se la casistica è rappresentativa Valore predittivo positivo P(D+|T+) Valore predittivo negativo P(D-|T-) Prevalenza P(D+)
 e al risultato di un test. diagnostico (T+ o T-). D+ D- Totale. T falsi positivi. 41. T- 1 falsi negativi Si possono stimare varie probabilità che, in questo contesto. hanno nomi particolari: Sensibilità = P(T+|D+) Specificità = P(T-|D-) Solo se la casistica è rappresentativa. Valore predittivo positivo P(D+|T+) Valore predittivo negativo P(D-|T-) Prevalenza P(D+)")
12
POTERE DISCRIMINANTE DI UN TEST
Malattia Pres Ass Test Pos 39 VP 2 FP 41 Neg 1 FN 25 VN 26 40 27 67 Selvais, 1998 Sensibilità = 39/40 = % Specificità = 25/27 = VP(+) = 39/41 = VP(-) = 25/26 = 0.961 Prevalenza = 40/67 = 0.597
 = 39/41 = VP(-) = 25/26 = Prevalenza = 40/67 =")
13
Dividendo tutti i termini di questa tabella per il numero totale di
osservazioni (67), si ottiene una tabella di probabilità: D+ D- T+ 0.582 0.030 0.612 T- 0.015 0.373 0.388 Totale 0.597 0.403 1.000 P(D+eT+) = P(D-eT+) = P(D-) = 0.403 Da una tabella di questo tipo si possono calcolare i valori predittivi, utilizzando il teorema di Bayes. VP(-) = P(D-|T-) = P(D-eT-)/P(T-) = 0.373/0.388 = 0.961
, si ottiene una tabella di probabilità: D+ D- T T Totale P(D+eT+) = P(D-eT+) = P(D-) = Da una tabella di questo tipo si possono calcolare i valori predittivi, utilizzando il teorema di Bayes. VP(-) = P(D-|T-) = P(D-eT-)/P(T-) = 0.373/0.388 =")
14
Caveat Sensibilità e specificità sono relative alle colonne della tabella e sono quindi indipendenti dalla prevalenza (diffusione della malattia nella struttura nella quale viene eseguito il test). I valori predittivi sono vincolati alle righe della tabella, quindi fortemente condizionati dal valore della prevalenza nella popolazione in esame.
. I valori predittivi sono vincolati alle righe della tabella, quindi fortemente condizionati dal valore della prevalenza nella popolazione in esame.")
15
Dipendenza dei valori predittivi dalla prevalenza
tenerla ben presente per la scelta di un test diagnostico e per l’interpretazione dei risultati; nella messa a punto di un test si tenderà a usare un campione con pari numeri di ‘sicuramente D+’ e ‘sicuramente D-‘, cioè con prevalenza del 50%, per stimare sensibilità e specificità in gruppi di pari consistenza numerica. L’utente del test deve invece riferirsi alla prevalenza della malattia nella popolazione oggetto del suo studio, poiché è in funzione di questa che variano i valori predittivi, e quindi ‘l’utilità’ del test da adottare.

16
Per valutare l’utilità diagnostica di un particolare test in contesti con prevalenza diversa della malattia in studio si può ricorrere al teorema di Bayes. Nota la sensibilità e la specificità del particolare test diagnostico, si ricorre al calcolo dei valori predittivi conoscendo la prevalenza della malattia. Come esempio si ricostruisca la tabella delle probabilità a partire da una prevalenza del 10% (P(D+)=0.100), nota sensibilità = e Specificità = 0.926 D+ D- T+ T- Totale 0.100 0.900 1.000
=0.100), nota sensibilità = e. Specificità = D+ D- T+ T- Totale")
17
D+ D- T+ 0.097 0.067 0.164 T- 0.003 0.833 0.836 Totale 0.100 0.900 1.000 P(D+eT+) = P(T+|D+) * P(D+) = sensibilità * prevalenza = 0.975 * 0.10 = 0.097 P(D-eT-) = P(T-|D-) * p(D-) = specificità * (1- prevalenza) = = * = 0.833 E’ possibile ora calcolare i VP: VP(+) = P(D+|T+) = P(D+ e T+)/P(T+) = 0.097/0.164 = 0.591 Analogamente VP(-) = 0.996 Notare come, al variare della prevalenza, varino i valori predittivi.
 = P(T+|D+) * P(D+) = sensibilità * prevalenza = * 0.10 = P(D-eT-) = P(T-|D-) * p(D-) = specificità * (1- prevalenza) = = * = E’ possibile ora calcolare i VP: VP(+) = P(D+|T+) = P(D+ e T+)/P(T+) = 0.097/0.164 = Analogamente VP(-) = Notare come, al variare della prevalenza, varino i valori predittivi.")
18
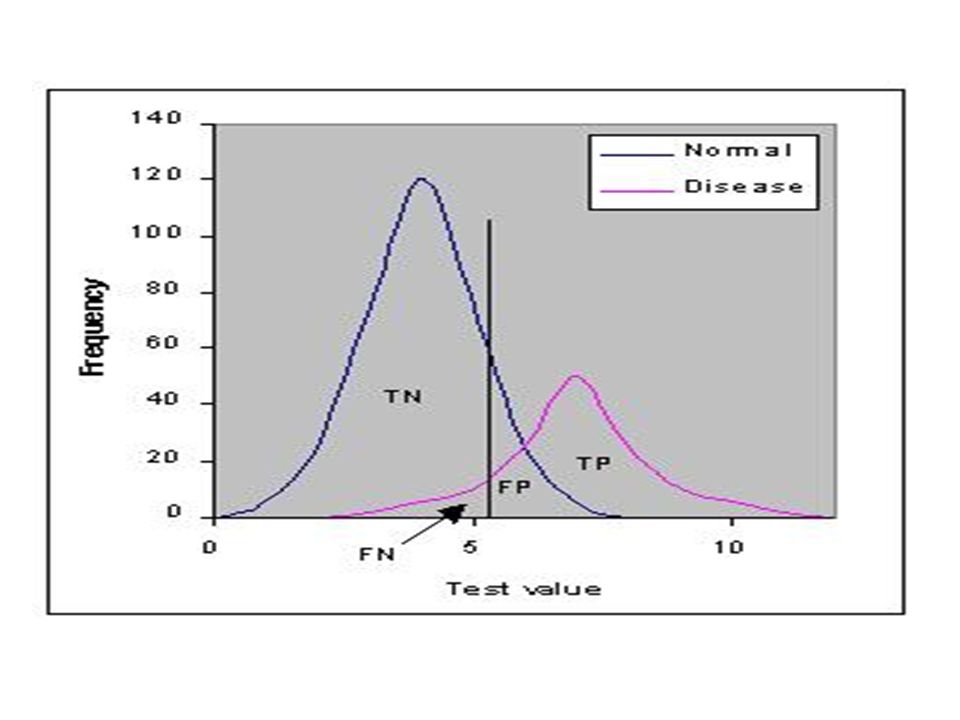
Importanza del tipo di variabile test utilizzata.
Finora abbiamo implicitamente ammesso che la risposta fosse chiara e dicotomica (T+ o T-). Ma in numerosi casi la risposta del test può essere un valore rilevato su una qualsiasi scala numerica: ordinale, intervallare, razionale. In tal caso i problemi di interpretazione di un test diagnostico diventano più complicati. Il caso più fortunato è quello in cui la distribuzione della variabile risposta nei D+ non ha nessuna sovrapposizione con la distribuzione della stessa variabile nei D-; in questo caso è facile trovare un valore soglia, posto fra le due distribuzioni, che separa in modo netto i D+ dai D-; in questo caso non esistono né Falsi Positivi, né Falsi Negativi (Sensibilità e Specificità = e 100%). Il caso più sfortunato è quello in cui le distribuzioni dei D+ e dei D- sono completamente sovrammesse; non esiste in tal caso nessun valore soglia utile per la discriminazione fra D+ e D -, dato il risultato del test.
. Ma in numerosi casi la risposta del test può essere un valore rilevato su una qualsiasi scala numerica: ordinale, intervallare, razionale. In tal caso i problemi di interpretazione di un test diagnostico diventano più complicati. Il caso più fortunato è quello in cui la distribuzione della variabile risposta nei D+ non ha nessuna sovrapposizione con la distribuzione della stessa variabile nei D-; in questo caso è facile trovare un valore soglia, posto fra le due distribuzioni, che separa in modo netto i D+ dai D-; in questo caso non esistono né Falsi Positivi, né Falsi Negativi (Sensibilità e Specificità = 1.00 e 100%). Il caso più sfortunato è quello in cui le distribuzioni dei D+ e dei D- sono completamente sovrammesse; non esiste in tal caso nessun valore soglia utile per la discriminazione fra D+ e D -, dato il risultato del test.")
19
Un test è utilizzabile quando le due distribuzioni sono solo parzialmente sovrammesse
Esiste però un problema relativo alla scelta del valore soglia (cutoff) per discriminare fra T+ e T-
 per discriminare fra T+ e T-")
20
Sensibilità e specificità al variare del valore soglia
Per studiarne l’andamento si costruiscono le curve ROC. Tale nome (ROC: Receiver Operating Characteristic) deriva dai primordi dell’esistenza del radar, quando l’operatore doveva distinguere i segnali causati dagli aerei dal rumore di fondo, causato da altre sorgenti. Le curve ROC forniscono una rappresentazione completa delle caratteristiche del test nell’intero range di valori della variabile test che sono potenziali cutoff.
 deriva dai primordi dell’esistenza del radar, quando l’operatore doveva distinguere i segnali causati dagli aerei dal rumore di fondo, causato da altre sorgenti. Le curve ROC forniscono una rappresentazione completa delle caratteristiche del test nell’intero range di valori della variabile test che sono potenziali cutoff.")
21
Segnali radar e ROC

22
Costruzione delle curve ROC
Si traccia un grafico nel quale ogni punto ha come coordinate la sensibilità (True Positive Rate, TPR) e (1 – specificità) (False Positive Rate, FPR) corrispondenti a diversi valori di soglia (cutoff); si adatta poi una curva a questo insieme di punti. N.B.: sono disponibili diversi pacchetti di software applicativo che eseguono le elaborazioni ROC partendo dai dati grezzi
 e (1 – specificità) (False Positive Rate, FPR) corrispondenti a diversi valori di soglia (cutoff); si adatta poi una curva a questo insieme di punti. N.B.: sono disponibili diversi pacchetti di software applicativo che eseguono le elaborazioni ROC partendo dai dati grezzi.")
23
Curve ROC Tutte partono dall’angolo inferiore sinistro, per il quale il cutoff è così alto che nessun test lo supera, quindi tutti i test sono negativi: la sensibilità è 0% e la specificità 100% [(1 – specificità) = 0%]. Tutte terminano all’angolo superiore destro, per il quale il cutoff è così basso che tutti i test sono positivi: la sensibilità è il 100% e la specificità 0% [(1 – specificità) = 100%]. Spostando il cutoff dal valore massimo al minimo si ottengono coppie di valori di sensibilità e specificità [(1 – specificità]), per mezzo delle quali si costruisce il grafico ROC ( vedi figura).
 = 0%]. Tutte terminano all’angolo superiore destro, per il quale il cutoff è così basso che tutti i test sono positivi: la sensibilità è il 100% e la specificità 0% [(1 – specificità) = 100%]. Spostando il cutoff dal valore massimo al minimo si ottengono coppie di valori di sensibilità e specificità [(1 – specificità]), per mezzo delle quali si costruisce il grafico ROC ( vedi figura).")
25
In definitiva la sensibilità (TPR) è la proporzione di D+ che hanno valori della variabile test maggiori del cutoff, rispetto al totale dei D+; cioè il rapporto tra la porzione di area della curva dei D+ delimitata dal cutoff e l’area di tutta la curva. [1- specificità] (FPR) è la porzione dei D- che hanno valori della variabile test maggiori del cutoff, rispetto al totale dei D-; cioè il rapporto tra la porzione di area della curva dei D- delimitata dal cutoff e l’area di tutta la curva. Poché sensibilità e specificità sono calcolate su gruppi diversi di individui, anche la curva ROC, basata su sensibilità e specificità, è indipendente dalla prevalenza della malattia nel campione.
 è la porzione dei D- che hanno valori della variabile test maggiori del cutoff, rispetto al totale dei D-; cioè il rapporto tra la porzione di area della curva dei D- delimitata dal cutoff e l’area di tutta la curva. Poché sensibilità e specificità sono calcolate su gruppi diversi di individui, anche la curva ROC, basata su sensibilità e specificità, è indipendente dalla prevalenza della malattia nel campione.")
26
Esempio cattivo (il blu)
La curva ROC di un test inutile segue una linea retta dall’angolo inferiore sinistro all’angolo superiore destro

27
Esempio buono (il giallo)
La curva ROC di un buon test mostra un rapido incremento (fino verso il 100%) nella sensibilità (TPR) già con il primo modesto incremento di (1 – specificità) (FPR)
 nella sensibilità (TPR) già con il primo modesto incremento di (1 – specificità) (FPR)")
28
Scelta del cutoff ottimale
Il cutoff (‘ottimale’) della variabile test viene individuato nella zona più vicina all’angolo superiore sinistro della curva (qui il 7)
 della variabile test viene individuato nella zona più vicina all’angolo superiore sinistro della curva (qui il 7)")
29
Validità del test La validità di un test può essere misurata dall’area sotto la curva ROC (Area Under the Curve: AUC). Qui è quasi 1, ottima

30
Sono stati messi a punto vari metodi per il fitting di una curva ROC ai punti sperimentali e per il successivo calcolo della AUC (trapezoide…). E’ possibile stimare l’errore standard di AUC. Un test che manca di contenuto informativo giace sulla diagonale ed ha una AUC = 0,50. Viceversa un test perfetto ha una curva che segue i lati sinistro e superiore ed una AUC = 1,0. E’ quindi possibile saggiare l’ipotesi zero: AUC nella popolazione = 0,50. Il rifiuto di tale ipotesi depone per un contenuto informativo significativo del test diagnostico in questione.

31
Confronto di test Le curve ROC possono servire per confrontare il comportamento di più test diagnostici. La figura mostra le curve ROC per 3 test, con validità diversa

32
Le curve ROC mostrano l’intero range di sensibilità e di specificità dei due test, offrendo quindi una rappresentazione molto più ricca del potenziale contenuto informativo dei due test. Per tutti i cutoff scelti è evidente che i test 1 e 3 hanno un comportamento migliore del test 2. Calcolando gli errori standard delle AUC è possibile determinare se differiscono ad un livelli di significatività prescelto.

33
Rapporti di verosimiglianza
Per valutare la bontà di un test diagnostico vengono usati anche i rapporti di verosimiglianza (Likelihood Ratios). LR è il rapporto delle proporzioni di pazienti con e senza la malattia, che hanno un certo risultato al test (esistono due LR, uno per il risultato: test positivo (LR(+)) l’altro per il test negativo (L(R(-)). In formule: LR(+) = P(T+|D+) / P(T+|D-) = sensibilità / (1 – specificità) LR(-) = P(T-|D+) / P(T-|D-) = (1 – specificità) / specificità
. LR è il rapporto delle proporzioni di pazienti con e senza la malattia, che hanno un certo risultato al test (esistono due LR, uno per il risultato: test positivo (LR(+)) l’altro per il test negativo (L(R(-)). In formule: LR(+) = P(T+|D+) / P(T+|D-) = sensibilità / (1 – specificità) LR(-) = P(T-|D+) / P(T-|D-) = (1 – specificità) / specificità.")
34
LR è il rapporto fra probabilità di uno dei risultati del test in persone che hanno la malattia e la probabilità dello stesso risultato del test in persone che non hanno la malattia. Un valore di LR > 1 indica che quel risultato del test è associato con la presenza di malattia. Un valore di LR < 1 indica che il risultato del test è associato con l’assenza di malattia. Quanto più LR è diverso da 1, tanto maggiore è l’evidenza della presenza o dell’assenza di malattia.

35
Si abbia la seguente tabella che mostra i risultati di uno studio sulla storia pregressa di abitudine al fumo nella diagnosi dell’ostruzione delle vie aeree superiori. Fumo Ostruzione vie aeree Likelihood Ratio (T+) pacchetti anno Si No >= 40 42 2 (42/148)/(2/144)= 20.4 20 – 40 25 24 (25/148)/(24/144)= 1.01 0 – 20 29 51 (29/148)/(51/144)= 0.55 Mai fumato 52 67 (52/148)/(67/144)= 0.76 148 144
 pacchetti. anno. Si. No. >= (42/148)/(2/144)= – (25/148)/(24/144)= – (29/148)/(51/144)= Mai fumato (52/148)/(67/144)=")
36
Scegliendo il valore: 40 pacchetti anno come cutoff, la tabella viene compattata in
Fumo Ostruzione vie aeree Likelihood Ratio (T+) pacchetti anno Si No >= 40 42 2 (42/148)/(2/144)= 20.4 0 – 40 106 142 148 144 Aver fumato più di 40 pacchetti anno è fortemente predittivo di una diagnosi di ostruzione delle vie aeree
 pacchetti. anno. Si. No. >= (42/148)/(2/144)= – Aver fumato più di 40 pacchetti anno è fortemente predittivo di una diagnosi di ostruzione delle vie aeree.")
37
A differenza di sensibilità e specificità il calcolo di LR non richiede la dicotomizzazione del risultato del test (T+ o T-), ma si possono calcolare LR diversi per livelli diversi della variabile test ottenendo una informazione clinica molto più dettagliata. Nella tabella precedente si nota chiaramente come il rischio di malattia aumenta con l’aumentare dei pacchetti anno Sono facilmente calcolabili gli intervalli di confidenza di LR, che permettono di saggiare l’ipotesi: LR = 1. Da notare: i due termini del rapporto sono calcolati per colonna e quindi non cambiano col variare della prevalenza della malattia.

38
Calcolo della probabilità post-test utilizzando i Likelihood Ratios
Alcuni termini: Probabilità pre-test della malattia = prevalenza = P(D+) Odds della malattia = probabilità di malattia/probabilità di non malattia = P(D+)/P(D-) = P(D+)/P(1 - D+) Valgono le relazioni: Post-test odds = pre-test odds * LR Post-test probability = Post-test odds/(1+ Post-test odds) Dalle ultime due relazioni si vede chiaramente come LR misuri il cambiamento della diagnosi da prima del test a dopo il test.
 Odds della malattia = probabilità di malattia/probabilità di non malattia = P(D+)/P(D-) = P(D+)/P(1 - D+) Valgono le relazioni: Post-test odds = pre-test odds * LR. Post-test probability = Post-test odds/(1+ Post-test odds) Dalle ultime due relazioni si vede chiaramente come LR misuri il cambiamento della diagnosi da prima del test a dopo il test.")
39
Probabilità pre-test = 148/292 = 0.507
Fumo Ostruzione vie aeree Likelihood Ratio (T+) pacchetti anno Si No >= 40 42 2 (42/148)/(2/144)= 20.4 0 – 40 106 142 248 148 144 292 Probabilità pre-test = 148/292 = 0.507 Pre-test odds = 0.507/0.493 = 1.028 Post-test odds = * 20.4 = 21 Probabilità post-test = 21/22 = 0.954 Partendo direttamente dalla tabella Probabilità post-test = P(D+|T+) = 42/44 = 0.954 Da una Probabilità pre-test diversa …….
 pacchetti. anno. Si. No. >= (42/148)/(2/144)= – Probabilità pre-test = 148/292 = Pre-test odds = 0.507/0.493 = Post-test odds = * 20.4 = 21. Probabilità post-test = 21/22 = Partendo direttamente dalla tabella. Probabilità post-test = P(D+|T+) = 42/44 = Da una Probabilità pre-test diversa …….")
40
Dopo un test diagnostico
Post-test odds = pre-test odds * LR Dopo una serie di test diagnostici Post-test Odds = Pre-test odds * LR1 * LR2 * LR3 *……

41
Tutorials Collegandosi a: o a si trovano le istruzioni per lavorare con le curve ROC, utilizzando dei pacchetti di software commerciale a si trovano delle dispense sul tema

42
Dimostrazione interattiva
Il collegamento a fornisce un’applet che permette di avvicinare o allontanare le distribuzioni del parametro nei sani e nei malati, e di spostare il cutoff per vedere come si modifica la curva ROC

43
Approfondimenti Seguono diversi quadri con estratti di articoli sulla valutazione dei test diagnostici Viene indicata la fonte A volte viene inserito un collegamento al testo completo dell’articolo Le indicazioni sono tratte da MedLine

44
Collegamento A non-parametric method for the comparison of partial areas under ROC curves and its application to large health care data sets. Zhang DD, Zhou XH, Freeman DH Jr, Freeman JL. Office of Biostatistics, University of Texas Medical Branch at Galveston, Galveston, TX , USA. The receiver operating characteristic (ROC) curve is a statistical tool for evaluating the accuracy of diagnostic tests. Investigators often compare the validity of two tests based on the estimated areas under the respective ROC curves. However, the traditional way of comparing entire areas under two ROC curves is not sensitive when two ROC curves cross each other. Also, there are some cutpoints on the ROC curves that are not considered in practice because their corresponding sensitivities or specificities are unacceptable. For the purpose of comparing the partial area under the curve (AUC) within a specific range of specificity for two correlated ROC curves, a non-parametric method based on Mann-Whitney U-statistics has been developed. The estimation of AUC along with its estimated variance and covariance is simplified by a method of grouping the observations according to their cutpoint values. The method is used to evaluate alternative logistic regression models that predict whether a subject has incident breast cancer based on information in Medicare claims data. Copyright 2002 John Wiley & Sons, Ltd
 curve is a statistical tool for evaluating the accuracy of diagnostic tests. Investigators often compare the validity of two tests based on the estimated areas under the respective ROC curves. However, the traditional way of comparing entire areas under two ROC curves is not sensitive when two ROC curves cross each other. Also, there are some cutpoints on the ROC curves that are not considered in practice because their corresponding sensitivities or specificities are unacceptable. For the purpose of comparing the partial area under the curve (AUC) within a specific range of specificity for two correlated ROC curves, a non-parametric method based on Mann-Whitney U-statistics has been developed. The estimation of AUC along with its estimated variance and covariance is simplified by a method of grouping the observations according to their cutpoint values. The method is used to evaluate alternative logistic regression models that predict whether a subject has incident breast cancer based on information in Medicare claims data. Copyright 2002 John Wiley & Sons, Ltd.")
45
Comment on: · Med Decis Making Oct-Dec;20(4): Determining the area under the receiver operating characteristic curve for a binary diagnostic test: best is not always ideal. Jager G. Publication Types: · Comment · Letter

46
What white blood cell count should prompt antibiotic treatment in a febrile child? Tutorial on the importance of disease likelihood to the interpretation of diagnostic tests. Kohn MA, Newman MP. Department of Epidemiology and Biostatistics, University of California, San Francisco, USA. Most diagnostic tests are not dichotomous (negative or positive) but, rather, have a range of possible results (very negative to very positive). If the pretest probability of disease is high, the test result that prompts treatment should be any value that is even mildly positive. If the pretest probability of disease is low, the test result needed to justify treatment should be very positive. Simple decision rules that fix the cutpoint separating positive from negative test results do not take into account the individual patient's pretest probability of disease. Allowing the cutpoint to change with the pretest probability of disease increases the value of the test. This is primarily an issue when the pretest probability of disease varies widely between patients and depends on characteristics that are not measured by the test. It remains an issue for decision rules based on multiple test results if these rules fail to account for important determinants of patient-specific risk. This tutorial demonstrates how the value of a diagnostic test depends on the ability to vary the cutpoint, using as an example the white blood cell count in febrile children at risk for bacteremia. Med Decis Making 2001 Nov-Dec;21(6):479-89
 but, rather, have a range of possible results (very negative to very positive). If the pretest probability of disease is high, the test result that prompts treatment should be any value that is even mildly positive. If the pretest probability of disease is low, the test result needed to justify treatment should be very positive. Simple decision rules that fix the cutpoint separating positive from negative test results do not take into account the individual patient s pretest probability of disease. Allowing the cutpoint to change with the pretest probability of disease increases the value of the test. This is primarily an issue when the pretest probability of disease varies widely between patients and depends on characteristics that are not measured by the test. It remains an issue for decision rules based on multiple test results if these rules fail to account for important determinants of patient-specific risk. This tutorial demonstrates how the value of a diagnostic test depends on the ability to vary the cutpoint, using as an example the white blood cell count in febrile children at risk for bacteremia. Med Decis Making 2001 Nov-Dec;21(6):")
47
mROC: a computer program for combining tumour markers in predicting disease states. Kramar A, Faraggi D, Fortune A, Reiser B. CRLC Val d'Aurelle, Unite de Biostatistiques, Parc Euromedecine, Montpellier cedex 5, France. Receiver operating characteristic (ROC) curves are limited when several diagnostic tests are available, mainly due to the problems of multiplicity and inter-relationships between the different tests. The program presented in this paper uses the generalised ROC criteria, as well as its confidence interval, obtained from the non-central F distribution, as a possible solution to this problem. This criterion corresponds to the best linear combination of the test for which the area under the ROC curve is maximal. Quantified marker values are assumed to follow a multivariate normal distribution but not necessarily with equal variances for two populations. Other options include Box-Cox variable transformations, QQ-plots, interactive graphics associated with changes in sensitivity and specificity as a function of the cut-off. We provide an example to illustrate the usefulness of data transformation and of how linear combination of markers can significantly improve discriminative power. This finding highlights potential difficulties with methods that reject individual markers based on univariate analyses.
 curves are limited when several diagnostic tests are available, mainly due to the problems of multiplicity and inter-relationships between the different tests. The program presented in this paper uses the generalised ROC criteria, as well as its confidence interval, obtained from the non-central F distribution, as a possible solution to this problem. This criterion corresponds to the best linear combination of the test for which the area under the ROC curve is maximal. Quantified marker values are assumed to follow a multivariate normal distribution but not necessarily with equal variances for two populations. Other options include Box-Cox variable transformations, QQ-plots, interactive graphics associated with changes in sensitivity and specificity as a function of the cut-off. We provide an example to illustrate the usefulness of data transformation and of how linear combination of markers can significantly improve discriminative power. This finding highlights potential difficulties with methods that reject individual markers based on univariate analyses..")
48
Statistics in the pathology laboratory: characteristics of diagnostic tests. Empson MB. Department of Public Health and Community Medicine, Westmead Hospital, Auckland, New Zealand. Sensitivity, specificity and receiver operating characteristic (ROC) curves all provide information about the ability of a diagnostic test to provide useful information in the assessment of disease. They are discussed in this review along with the importance of estimates of precision. 5: Pathology 2001 Feb;33(1):93-5 Related Articles, Books, LinkOut
:93-5. Related Articles, Books, LinkOut.")
49
Meta-analysis of diagnostic tests for acute sinusitis
Meta-analysis of diagnostic tests for acute sinusitis. Engels EA, Terrin N, Barza M, Lau J. Division of Clinical Care Research, Department of Medicine, New England Medical Center, Tufts University School of Medicine, 750 Washington Street, Boston, MA 02111, USA. To facilitate management of acute sinusitis, we conducted a meta-analysis of published studies comparing diagnostic tests for this disorder. Thirteen studies were identified through literature search. Based on sinus puncture/aspiration (considered most accurate), 49-83% of symptomatic patients had acute sinusitis. Compared with puncture/aspiration, radiography offered moderate ability to diagnose sinusitis (summary receiver operator curve [SROC] area, 0.83). Using sinus opacity or fluid as the criterion for sinusitis, radiography had sensitivity of 0.73 and specificity of Studies evaluating ultrasonography revealed substantial variation in test performance. The clinical evaluation, particularly risk scores formally incorporating history and physical examination findings, had moderate ability to identify patients with positive radiographs (SROC area, 0.74). Many studies were of poor quality, with inadequately described test methods and unblinded test interpretation. In conclusion, acute sinusitis is common among symptomatic patients. Radiography and clinical evaluation (especially risk scores) appear to provide useful information for diagnosis of sinusitis. J Clin Epidemiol 2000 Aug;53(8):852-62 Related Articles, Books, LinkOut
, 49-83% of symptomatic patients had acute sinusitis. Compared with puncture/aspiration, radiography offered moderate ability to diagnose sinusitis (summary receiver operator curve [SROC] area, 0.83). Using sinus opacity or fluid as the criterion for sinusitis, radiography had sensitivity of 0.73 and specificity of Studies evaluating ultrasonography revealed substantial variation in test performance. The clinical evaluation, particularly risk scores formally incorporating history and physical examination findings, had moderate ability to identify patients with positive radiographs (SROC area, 0.74). Many studies were of poor quality, with inadequately described test methods and unblinded test interpretation. In conclusion, acute sinusitis is common among symptomatic patients. Radiography and clinical evaluation (especially risk scores) appear to provide useful information for diagnosis of sinusitis. J Clin Epidemiol 2000 Aug;53(8): Related Articles, Books, LinkOut.")
50
Med Decis Making 2000 Jul-Sep;20(3):323-31
Comparing three-class diagnostic tests by three-way ROC analysis. Dreiseitl S, Ohno-Machado L, Binder M. Brigham and Women's Hospital, Division of Health Sciences and Technology, Harvard Medical School, Massachusetts Institute of Technology, Boston, USA. Three-way ROC surfaces are based on a generalization of dichotomous ROC analysis to three-class diagnostic tests. The discriminatory power of three-class diagnostic tests is measured by the volume under the ROC surface. This measure can be given a probabilistic interpretation similar to the equivalence of the c-index to the area under the ROC curve. This article presents a method to calculate nonparametric estimates of the variance of the volume under the surface using Mann-Whitney U statistics. As a simple extension of this result, it is possible to calculate covariance estimates for the volume under the surface. This allows the statistical comparison of two tests used for diagnostic tasks with three possible outcomes. The formulas derived are validated on synthetic data and applied to a three-class data set of pigmented skin lesions. It is shown that a neural network algorithm trained on clinical data and lesion features performs better than one trained on only the lesion features. Med Decis Making 2000 Jul-Sep;20(3):323-31 Related Articles, Books, LinkOut
: Related Articles, Books, LinkOut.")
51
[Evaluation of added value of diagnostic tests] [Article in Dutch] Moons KG, van der Graaf Y. Universitair Medisch Centrum, Julius Centrum voor Huisartsgeneeskunde en Patientgebonden Onderzoek, GA Utrecht. In the evaluation of diagnostic tests emphasis is placed on the evaluation of a particular diagnostic test in order to estimate it's sensitivity, specificity, or area under the 'receiver operating characteristic' curve (so called test research). This kind of test research is only useful in situations in which a diagnosis is set by one test (i.e. screening) and in the initial phases of test development for efficiency reasons. But, test research is not suitable to evaluate the clinical or added value of a test. The value of a diagnostic test can be evaluated on its value to discriminate between the presence and absence of a particular disease, to guide therapeutic decisions and to improve the prognosis of the patient. For evaluation of the added value of a diagnostic test within the diagnostic process, the study design should take into account the patient group in which the test will be applied in practice, the target disease of the test and the prior probability (prevalence) of the target disease in that population, the subsequent diagnostic stages and the reference test. In analysing the data it is calculated for each step of the diagnostic process how the test result changes the probability of presence or absence of the target disease. Ned Tijdschr Geneeskd 2000 Jun 24;144(26):
![[Evaluation of added value of diagnostic tests] [Article in Dutch] Moons KG, van der Graaf Y. Universitair Medisch Centrum, Julius Centrum voor Huisartsgeneeskunde en Patientgebonden Onderzoek, GA Utrecht. In the evaluation of diagnostic tests emphasis is placed on the evaluation of a particular diagnostic test in order to estimate it s sensitivity, specificity, or area under the receiver operating characteristic curve (so called test research). This kind of test research is only useful in situations in which a diagnosis is set by one test (i.e. screening) and in the initial phases of test development for efficiency reasons. But, test research is not suitable to evaluate the clinical or added value of a test. The value of a diagnostic test can be evaluated on its value to discriminate between the presence and absence of a particular disease, to guide therapeutic decisions and to improve the prognosis of the patient. For evaluation of the added value of a diagnostic test within the diagnostic process, the study design should take into account the patient group in which the test will be applied in practice, the target disease of the test and the prior probability (prevalence) of the target disease in that population, the subsequent diagnostic stages and the reference test. In analysing the data it is calculated for each step of the diagnostic process how the test result changes the probability of presence or absence of the target disease.](http://slideplayer.it/slide/975528/3/images/51/%5BEvaluation+of+added+value+of+diagnostic+tests%5D+%5BArticle+in+Dutch%5D+Moons+KG%2C+van+der+Graaf+Y.+Universitair+Medisch+Centrum%2C+Julius+Centrum+voor+Huisartsgeneeskunde+en+Patientgebonden+Onderzoek%2C+GA+Utrecht.+In+the+evaluation+of+diagnostic+tests+emphasis+is+placed+on+the+evaluation+of+a+particular+diagnostic+test+in+order+to+estimate+it+s+sensitivity%2C+specificity%2C+or+area+under+the+receiver+operating+characteristic+curve+%28so+called+test+research%29.+This+kind+of+test+research+is+only+useful+in+situations+in+which+a+diagnosis+is+set+by+one+test+%28i.e.+screening%29+and+in+the+initial+phases+of+test+development+for+efficiency+reasons.+But%2C+test+research+is+not+suitable+to+evaluate+the+clinical+or+added+value+of+a+test.+The+value+of+a+diagnostic+test+can+be+evaluated+on+its+value+to+discriminate+between+the+presence+and+absence+of+a+particular+disease%2C+to+guide+therapeutic+decisions+and+to+improve+the+prognosis+of+the+patient.+For+evaluation+of+the+added+value+of+a+diagnostic+test+within+the+diagnostic+process%2C+the+study+design+should+take+into+account+the+patient+group+in+which+the+test+will+be+applied+in+practice%2C+the+target+disease+of+the+test+and+the+prior+probability+%28prevalence%29+of+the+target+disease+in+that+population%2C+the+subsequent+diagnostic+stages+and+the+reference+test.+In+analysing+the+data+it+is+calculated+for+each+step+of+the+diagnostic+process+how+the+test+result+changes+the+probability+of+presence+or+absence+of+the+target+disease..jpg "Ned Tijdschr Geneeskd 2000 Jun 24;144(26):")
52
Principles and practical application of the receiver-operating characteristic analysis for diagnostic tests. Greiner M, Pfeiffer D, Smith RD. Institute for Parasitology and Tropical Veterinary Medicine, Department of Tropical Veterinary Medicine and Epidemiology, Freie Universitat Berlin, Konigsweg, Germany. We review the principles and practical application of receiver-operating characteristic (ROC) analysis for diagnostic tests. ROC analysis can be used for diagnostic tests with outcomes measured on ordinal, interval or ratio scales. The dependence of the diagnostic sensitivity and specificity on the selected cut-off value must be considered for a full test evaluation and for test comparison. All possible combinations of sensitivity and specificity that can be achieved by changing the test's cut-off value can be summarised using a single parameter; the area under the ROC curve. The ROC technique can also be used to optimise cut-off values with regard to a given prevalence in the target population and cost ratio of false-positive and false-negative results. However, plots of optimisation parameters against the selected cut-off value provide a more-direct method for cut-off selection. Candidates for such optimisation parameters are linear combinations of sensitivity and specificity (with weights selected to reflect the decision-making situation), odds ratio, chance-corrected measures of association (e. g. kappa) and likelihood ratios. We discuss some recent developments in ROC analysis, including meta-analysis of diagnostic tests, correlated ROC curves (paired-sample design) and chance- and prevalence-corrected ROC curves. Prev Vet Med 2000 May 30;45(1-2):23-41
:")
53
Diagnostic tests: distinguishing good tests from bad and even ugly ones. Farr BM, Shapiro DE. University of Virginia Health System, Charlottesville , USA. This article focuses on the selection and interpretation of diagnostic tests, emphasizing the importance of understanding how their mathematical parameters affect the information they provide in various settings. The utility and limitations of sensitivity, specificity, predictive value, and receiver operating characteristic (ROC) curves are discussed using catheter-related bloodstream infections as an example. ROC curves have been used for selecting optimal cutoff values for a positive result and for selecting among several alternative diagnostic tests. For example, 16 different tests have been proposed for diagnosis of catheter-related bloodstream infection; ROC analysis provides an effective way to determine which test offers the best overall performance. Infect Control Hosp Epidemiol 2000 Apr;21(4):278-84
:")
54
Statistical techniques for evaluating the diagnostic utility of laboratory tests. Kazmierczak SC. East Carolina University School of Medicine, Department of Pathology and Laboratory Medicine, Greenville, NC , USA. Clinical laboratory data is used to help classify patients into diagnostic disease categories so that appropriate therapy may be implemented and prognosis estimated. Unfortunately, the process of correctly classifying patients with respect to disease status is often difficult. Patients may have several concurrent disease processes and the clinical signs and symptoms of many diseases lack specificity. In addition, results of laboratory tests and other diagnostic procedures from healthy and diseased individuals often overlap. Finally, advances in computer technology and laboratory automation have resulted in an extraordinary increase in the amount of information produced by the clinical laboratory; information which must be correctly evaluated and acted upon so that appropriate treatment and additional testing, if necessary, can be implemented. Clinical informatics refers to a broad array of statistical methods used for the evaluation and management of diagnostic information necessary for appropriate patient care. Within the realm of clinical chemistry, clinical informatics may be used to indicate the acquisition, evaluation, representation and interpretation of clinical chemistry data. This review discusses some of the techniques that should be used for the evaluation of the diagnostic utility of clinical laboratory data. The major topics to be covered include probabilistic approaches to data evaluation, and information theory. The latter topic will be discussed in some detail because it introduces important concepts useful in providing for cost-effective, quality patient care. In addition, an example illustrating how the informational value of diagnostic tests can be determined is shown. Clin Chem Lab Med 1999 Nov-Dec;37(11-12):1001-9
:")
55
An improved measure for comparing diagnostic tests. Adams NM, Hand DJ
An improved measure for comparing diagnostic tests. Adams NM, Hand DJ. Department of Mathematics, Imperial College, London, UK. We present a loss based method for comparing the predictive performance of diagnostic tests. Unlike standard assessment mechanisms, like the area under the receiver-operating characteristic curve and the misclassification rate, our method takes specific advantage of any information that can be obtained about misclassification costs. We argue that not taking costs into account can lead to incorrect conclusions, and illustrate with two examples. Comput Biol Med 2000 Mar;30(2):89-96
:")
56
Comparing diagnostic tests: a simple graphic using likelihood ratios
Comparing diagnostic tests: a simple graphic using likelihood ratios. Biggerstaff BJ. Centers for Disease Control and Prevention, National Center for Infectious Diseases, Division of Vector-Borne Infectious Diseases, P. O. Box 2087, Fort Collins, Colorado , USA. The diagnostic abilities of two or more diagnostic tests are traditionally compared by their respective sensitivities and specificities, either separately or using a summary of them such as Youden's index. Several authors have argued that the likelihood ratios provide a more appropriate, if in practice a less intuitive, comparison. We present a simple graphic which incorporates all these measures and admits easily interpreted comparison of two or more diagnostic tests. We show, using likelihood ratios and this graphic, that a test can be superior to a competitor in terms of predictive values while having either sensitivity or specificity smaller. A decision theoretic basis for the interpretation of the graph is given by relating it to the tent graph of Hilden and Glasziou (Statistics in Medicine, 1996). Finally, a brief example comparing two serodiagnostic tests for Lyme disease is presented. Published in 2000 by John Wiley & Sons, Ltd. Stat Med 2000 Mar 15;19(5):649-63
. Finally, a brief example comparing two serodiagnostic tests for Lyme disease is presented. Published in 2000 by John Wiley & Sons, Ltd. Stat Med 2000 Mar 15;19(5):")
57
Collegamenti a risorse rilevanti
dispense illustrate sulle curve ROC esempi pratici, e quiz

Presentazioni simili

 Brussels, 26 settembre 2013.>")

 064825120 - fax.>")



>")



>")





 abbiamo cominciato a lavorare utilizzando i maniera didattica tecnologie di tipo hardware.>")

