Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
CLUSTERING WITH WEKA Branca Stefano Dosi Clio Gnudi Edward William

2
Outline Introduzione Algoritmi partizionanti
Clustering con weka Algoritmi partizionanti K-Means Algoritmi basati sulla densità DBScan OPTICS Algoritmi per DB transazionali CLOPE

3
Clusterizzazione del Dataset “Iris”
Tecniche di clusterizzazione con WEKA Clusterizzazione del Dataset “Iris” Funzioni per la misura della similarità locale vs. globale 3

4
Tecniche di clusterizzazione con WEKA
Possibilità di scelta tra vari algoritmi Funzioni per la misura della similarità locale vs. globale 4

5
Tecniche di clusterizzazione con WEKA
Possibilità di scelta tra vari algoritmi Funzioni per la misura della similarità locale vs. globale 5

6
Tecniche di clusterizzazione con WEKA
Scelta dei parametri Funzioni per la misura della similarità locale vs. globale 6

7
Tecniche di clusterizzazione con WEKA
Scelta dei parametri Funzioni per la misura della similarità locale vs. globale 7

8
Tecniche di clusterizzazione con WEKA
Cluster Mode Il “Cluster mode” è utilizzato per scegliere cosa clusterizzare e le modalità con cui valutare i risultati Funzioni per la misura della similarità locale vs. globale 8

9
Tecniche di clusterizzazione con WEKA
Ignore attribute Funzioni per la misura della similarità locale vs. globale Il pulsante “Ignore attribute” apre una finestra che permette di selezionare eventuali attributi da non considerare nella formazione dei cluster 9

10
Premendo il tasto “Start” si fa partire l'algoritmo.
Tecniche di clusterizzazione con WEKA Premendo il tasto “Start” si fa partire l'algoritmo. Le informazioni riguardanti il processamento dei dati vengono mostrate nel riquadro a destra Funzioni per la misura della similarità locale vs. globale 10

11
Tecniche di clusterizzazione con WEKA
Funzioni per la misura della similarità locale vs. globale 11

12
Identificazione degli attributi più significativi
Tecniche di clusterizzazione con WEKA Identificazione degli attributi più significativi Funzioni per la misura della similarità locale vs. globale 12

13
Tecniche di clusterizzazione con WEKA
Funzioni per la misura della similarità locale vs. globale 13

14
Tecniche di clusterizzazione con WEKA
Funzioni per la misura della similarità locale vs. globale K = 2 K = 5 14

15
Algoritmi partizionanti K-Means
Applicazione al Dataset “Wine” Funzioni per la misura della similarità locale vs. globale 15

16
Algoritmi partizionanti K-Means
Applicazione al Dataset “Wine” Funzioni per la misura della similarità locale vs. globale 16

17
Algoritmi basati sulla densità
DBScan

18
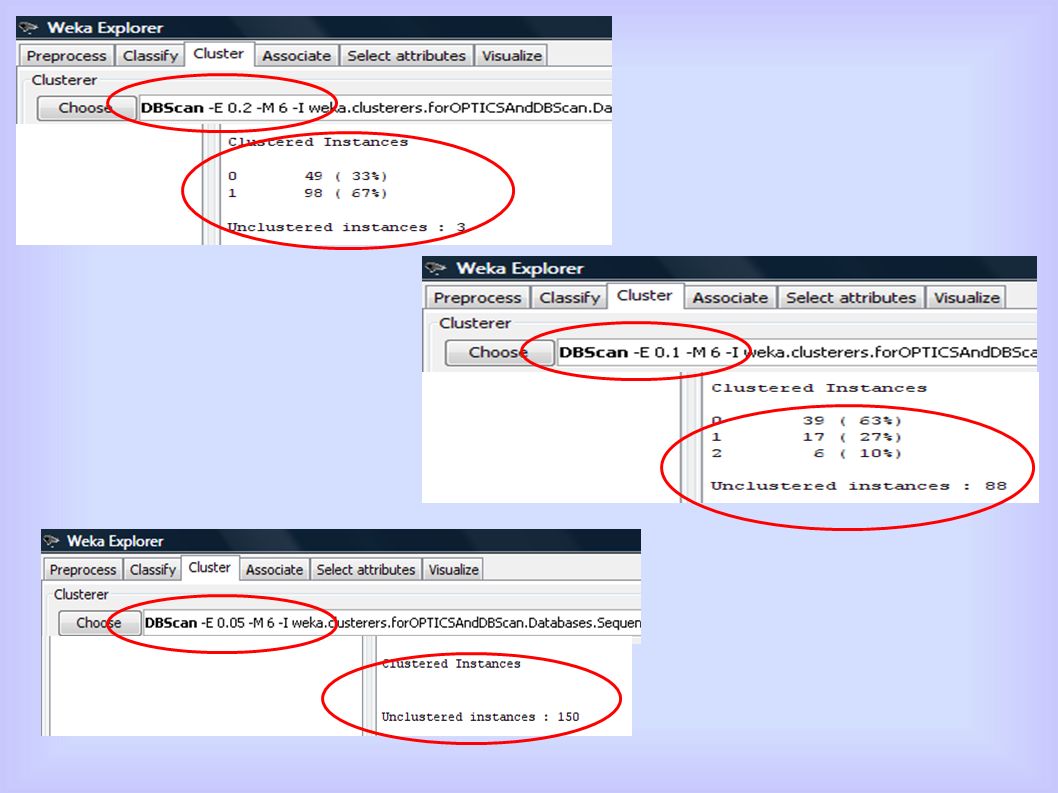
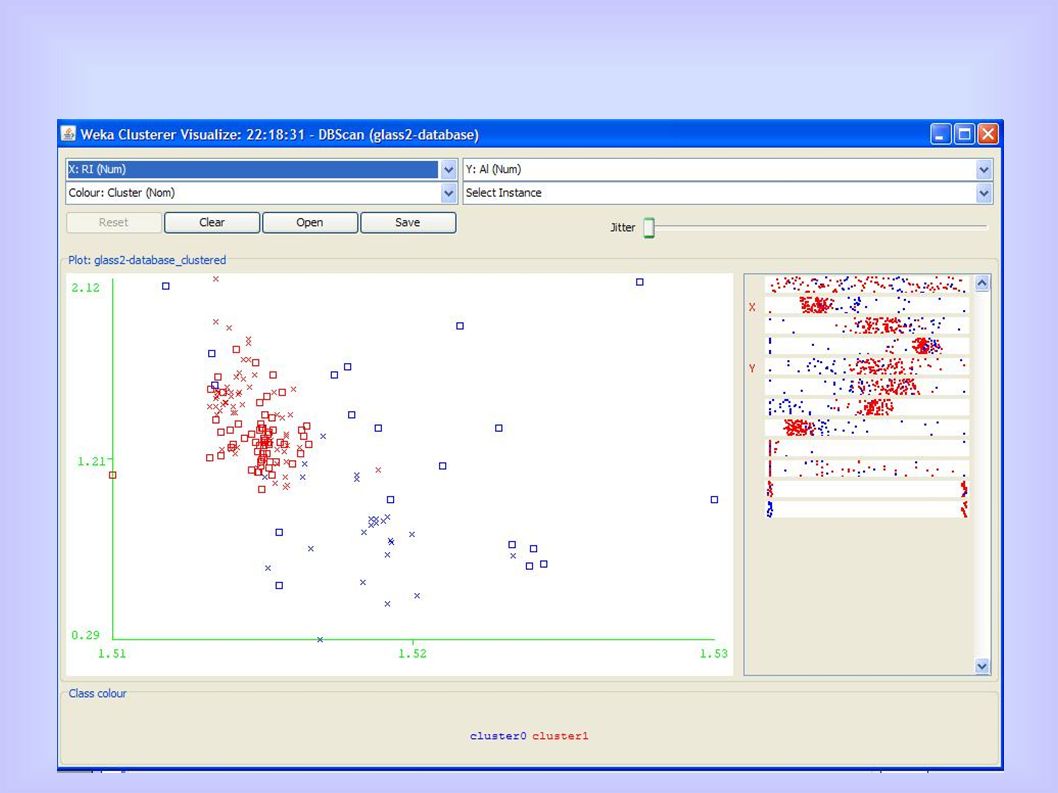
Algoritmi basati sulla densità - DBScan
Variando ε (IRIS)
")
20
Algoritmi basati sulla densità - DBScan
Variando MinPoints (IRIS)
")
21
Algoritmi basati sulla densità - DBScan
Limiti Quali dimensioni dare a ε? Non si possono individuare tutti i cluster e sottocluster in presenza di densità diverse

22
( Ordering Points To Identify the Clustering Structure )
Algoritmi basati sulla densità OPTICS ( Ordering Points To Identify the Clustering Structure ) “it does not produce a clustering of a data set explicitly; but instead creates an augmented ordering of the database representing its density-based clustering structure”
 it does not produce a clustering of a data set explicitly; but instead creates an augmented ordering of the database representing its density-based clustering structure")
23
Al-Ri, optics ε=0.3

25
Algoritmi basati sulla densità - OPTICS
Algoritmo = è un core object

26
Algoritmi basati sulla densità - OPTICS
Confronto con DBScan ε = 0.9 ; MinPoints= 6 Clustered Instances (100%) ε = 0.5 ; MinPoints= 6 (si perdono i cluster a bassa densità) ( 58%) ( 42%) Unclustered instances : 14
 ε = 0.5 ; MinPoints= 6 (si perdono i cluster a bassa densità) 0 86 ( 58%) 1 63 ( 42%) Unclustered instances : 14.")
27
Algoritmi basati sulla densità - OPTICS
Confronto con DBScan ε = 0.3 ; MinPoints= 6 Clustered Instances ( 16%) ( 43%) ( 40%) Unclustered instances : 22 cluster cluster Cluster Undefined 23 Perché?
 1 61 ( 43%) 2 57 ( 40%) Unclustered instances : 22. cluster cluster Cluster Undefined 23. Perché")
28
Algoritmi basati sulla densità - OPTICS
Confronto con DBScan ?? BORDER rispetto ad un core non ancora processato??

29
Algoritmi per DB transazionali
Caratteristiche dei dataset transazionali: Alta dimensione Sparsità Grandi volumi di tuple In questi casi, algoritmi basati sulle distanze (es. k-means) sono inefficienti. Gli algoritmi gerarchici (es. ROCK) sono, invece, abbastanza efficienti ma poco scalabili Funzioni per la misura della similarità locale vs. globale
 sono inefficienti. Gli algoritmi gerarchici (es. ROCK) sono, invece, abbastanza efficienti ma poco scalabili. Funzioni per la misura della similarità locale vs. globale.")
30
( Clustering with sLOPE )
Algoritmi per DB transazionali CLOPE ( Clustering with sLOPE ) Idea di base Misurare la qualità di un cluster attraverso una funzione di similarità globale basata sul rapporto altezza/larghezza dell’istogramma del cluster. Esempio: cluster formato dalle transazioni {ab, abc, acd} H=2 a b c d W=4 Più alto è il rapporto H/W, migliore è il cluster perché viene migliorato l’overlapping intra-cluster.
 Idea di base. Misurare la qualità di un cluster attraverso una funzione di similarità globale basata sul rapporto altezza/larghezza dell’istogramma del cluster. Esempio: cluster formato dalle transazioni {ab, abc, acd} H=2. a. b. c. d. W=4. Più alto è il rapporto H/W, migliore è il cluster perché viene migliorato l’overlapping intra-cluster.")
31
Algoritmi per DB transazionali - CLOPE
Sia C un cluster, si definiscono: D(C) insieme degli item distinti presenti nel cluster; Occ(i,C) occorrenze dell’item i nel cluster; S(C) dimensione dell’istogramma del cluster. Per un clustering C={C1,…,Ck} la funzione profitto è: Si introduce il parametro r detto repulsione usato per controllare il livello di similarità intra-cluster
 insieme degli item distinti presenti nel cluster; Occ(i,C) occorrenze dell’item i nel cluster; S(C) dimensione dell’istogramma del cluster. Per un clustering C={C1,…,Ck} la funzione profitto è: Si introduce il parametro r detto repulsione usato per controllare il livello di similarità intra-cluster.")
32
Algoritmi per DB transazionali - CLOPE
Algoritmo /* Fase 1 - Initialization */ 1: while not end of the database file 2: read the next transaction 〈t,unknown〉; 3: put t in an existing cluster or a new cluster Ci that maximize profit; 4: write 〈t, i〉 back to database; /* Fase 2 - Iteration */ 5: repeat 6: rewind the database file; 7: moved = false; 8: while not end of the database file 9: read 〈t, i〉; 10: move t to an existing cluster or new cluster Cj that maximize profit; 11: if Ci ≠ Cj then 12: write 〈t, j〉; 13: moved = true; 14: until not moved; Occupazione di memoria: nella RAM vengono memorizzati solo la transazione corrente e alcune informazioni (cluster feature) per ogni cluster come numero di transazioni (N), numero di item distinti (W), le occorrenze per ciascun item (occ) e la dimensione del cluster (S). Calcolo del profitto: è possibile individuare il miglior cluster in cui inserire una transazione attraverso la funzione DeltaAdd che calcola, utilizzando le clustering feature, l‘aumento relativo della funzione Profit 1: int DeltaAdd(C, t, r) { 2: S_new = C.S + t.ItemCount; 3: W_new = C.W; 4: for (i = 0; i < t.ItemCount; i++) 5: if (C.occ[t.items[i]] == 0) ++W_new; 6: return S_new*(C.N+1)/(W_new)r-C.S*C.N /(C.W)r; 7: } L‘algoritmo è composto da 2 fasi: la prima fase esegue un primo scan del database e costruisce il clustering, la seconda fase rifinisce il clustering eseguendo altri scan (in genere pochi). L‘algoritmo termina quando l‘ultimo scan non ha modificato il clustering. Complessità di DeltaAdd = O(t.itemCount)
 per ogni cluster come numero di transazioni (N), numero di item distinti (W), le occorrenze per ciascun item (occ) e la dimensione del cluster (S). Calcolo del profitto: è possibile individuare il miglior cluster in cui inserire una transazione attraverso la funzione DeltaAdd che calcola, utilizzando le clustering feature, l‘aumento relativo della funzione Profit. 1: int DeltaAdd(C, t, r) { 2: S_new = C.S + t.ItemCount; 3: W_new = C.W; 4: for (i = 0; i < t.ItemCount; i++) 5: if (C.occ[t.items[i]] == 0) ++W_new; 6: return S_new*(C.N+1)/(W_new)r-C.S*C.N /(C.W)r; 7: } L‘algoritmo è composto da 2 fasi: la prima fase esegue un primo scan del database e costruisce il clustering, la seconda fase rifinisce il clustering eseguendo altri scan (in genere pochi). L‘algoritmo termina quando l‘ultimo scan non ha modificato il clustering. Complessità di DeltaAdd = O(t.itemCount)")
33
Algoritmi per DB transazionali - CLOPE
Vantaggi Rapidità Complessità: O(N x K x A) Bassa occupazione di memoria Database con item e cluster possono essere memorizzati in 40 MB Efficienza Qualità del clustering molto vicina a quella di algoritmi come ROCK e scarsa sensibilità all’ordine delle transazioni N:transazioni K: num max di cluster A: dimensione media delle transazioni
 Bassa occupazione di memoria. Database con item e cluster possono essere memorizzati in 40 MB. Efficienza. Qualità del clustering molto vicina a quella di algoritmi come ROCK e scarsa sensibilità all’ordine delle transazioni. N:transazioni. K: num max di cluster. A: dimensione media delle transazioni.")
34
Algoritmi per DB transazionali - CLOPE
Applicazione con WEKA L’algoritmo è attivo solo se il dataset caricato è composto di attributi categorici. L’unico parametro da introdurre è la repulsione. Per provare l’algoritmo con il dataset di prova (Iris), è stato applicato un filtro per discretizzare gli attributi (10 bin equi-frequenza) e renderli binari.
, è stato applicato un filtro per discretizzare gli attributi (10 bin equi-frequenza) e renderli binari.")
35
Algoritmi per DB transazionali - CLOPE
Risultati Tutti gli attributi selezionati e repulsione a 2.8 Selezionati solo gli attributi sul petalo e repulsione a 2.5 CLOPE clustering results =============================================== Clustered instances: 150 Clustered Instances ( 33%) ( 36%) 46 ( 31%) ( 1%) Class attribute: class Classes to Clusters: <-- assigned to cluster | Iris-setosa | Iris-versicolor | Iris-virginica Cluster 0 <-- Iris-setosa Cluster 1 <-- Iris-versicolor Cluster 2 <-- Iris-virginica Cluster 4 <-- No class Incorrectly clustered instances : % CLOPE clustering results =============================================== Clustered instances: 150 Clustered Instances ( 31%) ( 38%) ( 28%) 5 ( 3%) Class attribute: class Classes to Clusters: <-- assigned to cluster | Iris-setosa | Iris-versicolor | Iris-virginica Cluster 0 <-- Iris-setosa Cluster 1 <-- Iris-versicolor Cluster 2 <-- Iris-virginica Cluster 3 <-- No class Incorrectly clustered instances : %
 1 54 ( 36%) 46 ( 31%) 4 1 ( 1%) Class attribute: class. Classes to Clusters: <-- assigned to cluster | Iris-setosa | Iris-versicolor | Iris-virginica. Cluster 0 <-- Iris-setosa. Cluster 1 <-- Iris-versicolor. Cluster 2 <-- Iris-virginica. Cluster 4 <-- No class. Incorrectly clustered instances : % CLOPE clustering results. =============================================== Clustered instances: 150. Clustered Instances ( 31%) 1 57 ( 38%) 2 42 ( 28%) 5 ( 3%) Class attribute: class. Classes to Clusters: <-- assigned to cluster | Iris-setosa | Iris-versicolor | Iris-virginica. Cluster 0 <-- Iris-setosa. Cluster 1 <-- Iris-versicolor. Cluster 2 <-- Iris-virginica. Cluster 3 <-- No class. Incorrectly clustered instances : %")
36
Applicazione al Dataset “Voting”
Algoritmi per DB transazionali - CLOPE Applicazione al Dataset “Voting”

37
GRAZIE PER L’ATTENZIONE

Presentazioni simili









>")









