Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Web Information Retrieval

2
Il World Wide Web Sviluppato da Tim Berners-Lee nel 1990 al CERN per organizzare documenti di ricerca disponibili su Internet. Combina lidea di scaricare documenti via FTP con lidea di ipertesti per collegare fra loro i documenti Ha sviluppato il protocollo HTTP, il concetto di URLs, ed il primo web server.

3
Problemi per WEB IR Dati distribuiti: I documenti sono sparsi su milioni di server differenti Dati Volatili: Molti documenti appaiono e spariscono (così detti dead links). Enormi volumi di dati: Miliardi di documenti diversi Dati non strutturati e ridondanti: Non esiste una struttura uniforme, ci sono errori html, circa 30% di documenti duplicati. Qualità dei dati: Non ci sono controlli editoriali, le informazioni possono essere false, possono esserci errori, testi mal scritti.. Dati eterogenei: multimediali (immagini, video, suoni..) diversi linguaggi, diversi formati (pdf, ps..)
 diversi linguaggi, diversi formati (pdf, ps..).")
4
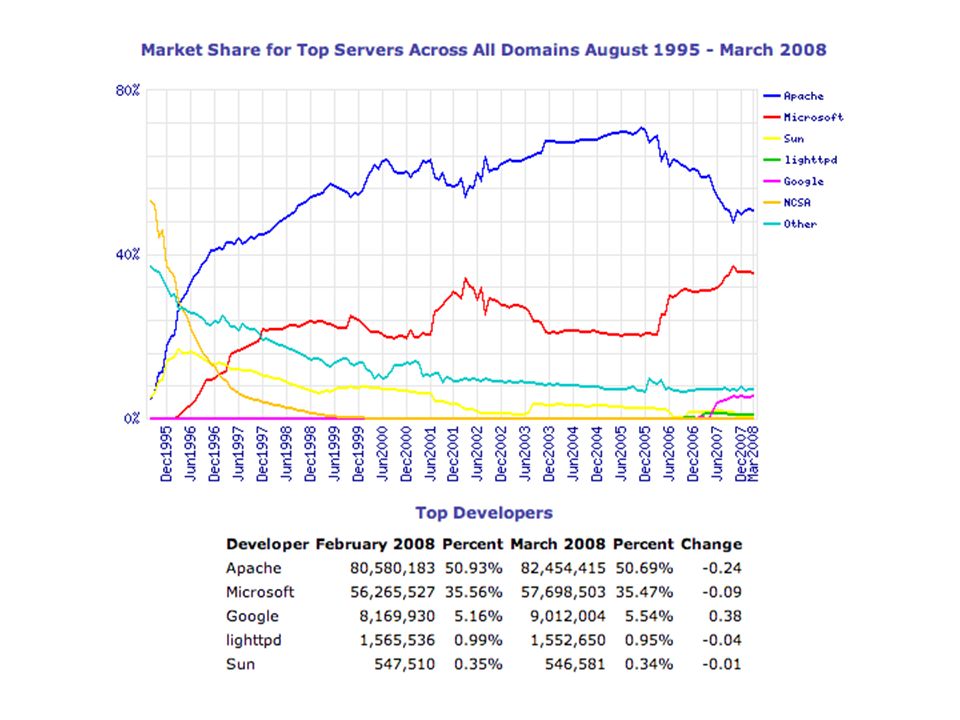
Numero di Web Servers

6
Struttura a grafo del Web http://www9.org/w9cdrom/160/160.html Pagine con link in uscita Pagine con link in ingresso Pagine con link di ingresso e uscita

7
Ricerca sul Web Il Web Ind. commerciali Spider Indicizzatore Indici Search Utente

8
WWW Spiders /Crawlers Page Respository Modulo IR Modulo Indiciz- zazione Testo Struttura Link Controllo Spidering Utenti Query Ranked results

9
FASI Spidering/Crawling: esplorazione di una porzione del web Indicizzazione: generazione di indici che associno i documenti a dei puntatori, su tre basi: –struttura del documento, –contenuto, –posizione del documento nel grafo del web. Ranking: sulla base della query e degli indici, presentare gli indirizzi delle pagine ordinate per rilevanza

10
Web Search 1. Spidering (o Crawling)
")
11
Spiders (Robots/Bots/Crawlers) Sono programmi che attraversano la rete spedendo pagine nuove o aggiornate ad un server principale,e dove queste vengono indicizzate Uno Spider gira su macchine locali e spedisce richieste a server remoti Gli indici sono usati in maniera centralizzata per rispondere alle query degli utenti
 Sono programmi che attraversano la rete spedendo pagine nuove o aggiornate ad un server principale,e dove queste vengono indicizzate Uno Spider gira su macchine locali e spedisce richieste a server remoti Gli indici sono usati in maniera centralizzata per rispondere alle query degli utenti")
12
Spiders (Robots/Bots/Crawlers) Si parte da un insieme pre-identificato di URL radice. Si seguono tutti i link a partire dalle radici alla ricerca di pagine addizionali. Alcuni sistemi consentono allutente di sottomettere pagine per lindicizzazione (o stabilire i nodi radice).
..")
13
Spidering Web URLs esplorate e analizzate Frontiera URLs Il Web nascosto pagine iniziali (seeds)
")
14
Questo semplice schema presenta complicazioni Non si può effetuare il crawling con una sola macchina, quindi tutte le fasi sono distribuite su threads Problemi: –Latenza e ampiezza di banda varia sui server remoti –Quanto in profondità esplorare la gerachia di URL in un sito? –Pagine duplicate e siti mirror Pagine maliziose –Pagine spam –Spider traps

15
Uno schema meno semplice URLs crawled E analizzate Web nascosto Pagin e Seed frontiera Crawling thread

16
Fasi di crawling Seleziona una URL dalla frontiera Preleva il documento a quell URL Analizza il documento –Estrai i link ad altri documenti (URLs) Verifica se esistono pagine già analizzate –Se no, aggiungi gli indici Per ogni URL estratta –Controlla che superi opportuni URL test di filtraggio –Elimina duplicati Es., accetta gli.edu, obbedisci ai robots.txt, etc. Quale?

17
Architettura WWW Fetch DNS Parse Già visto? Doc FPs Dup URL elim URL set URL Frontier URL filter robots filters Domain name server Analizza la front page Filtri e robot exlcusion Elimina duplicati

18
Spider Control Decide quali link i crawler debbano esplorare e quali ignorare Può usare dei feedback provenienti da usage patterns (analisi di comportamenti di utente) per guidare il processo di esplorazione
 per guidare il processo di esplorazione")
19
Strategie di ricerca Breadth-first Search

20
Strategie di Ricerca (2) Depth-first Search
 Depth-first Search")
21
Trade-Offs Breadth-first esplora uniformemente a partire dalla pagina(e) root, ma richiede la memorizzazione di tutti i nodi del livello precedente (è esponenziale nel fattore di profondità p). E il metodo standard. Depth-first richiede di memorizzare p volte il fattore di branching (lineare in p), ma si perde seguendo ununica traccia.
, ma si perde seguendo ununica traccia..")
22
Algoritmo di Spidering Inizializza la coda Q con un set iniziale di URL note. Until Q vuota o si esauriscono i limiti di tempo o pagine memorizzabili: Estrai URL, L, dalla testa di Q. Se L non è una pagina HTML (.gif,.jpeg,.ps,.pdf,.ppt…) continua il ciclo. Se L già visitata, continua il ciclo. Scarica la pagina, P, di L. Se non è possibile scaricare P (e.g. 404 error, robot exclusion) continua ciclo. Indicizza P (cioè aggiungi rapp(P) allinverted inedex,oppure memorizza una copia cache). Analizza P per ottenere una nuova lista di links N. Appendi N in coda a Q.
 continua il ciclo. Se L già visitata, continua il ciclo. Scarica la pagina, P, di L. Se non è possibile scaricare P (e.g. 404 error, robot exclusion) continua ciclo. Indicizza P (cioè aggiungi rapp(P) allinverted inedex,oppure memorizza una copia cache). Analizza P per ottenere una nuova lista di links N. Appendi N in coda a Q..")
23
Append:Strategie di queueing I nuovi link aggiunti come modificano la strategia di ricerca? FIFO (appendi alla coda di Q) determina una strategia di ricerca breadth-first. LIFO (aggiungi in testa a Q) determina una strategia di ricerca depth-first. Alcuni sistemi usano delle euristiche per collocare i nuovi link secondo priorità focused crawler tese a direzionare la ricerca verso pagine interessanti.
 determina una strategia di ricerca breadth-first. LIFO (aggiungi in testa a Q) determina una strategia di ricerca depth-first. Alcuni sistemi usano delle euristiche per collocare i nuovi link secondo priorità focused crawler tese a direzionare la ricerca verso pagine interessanti..")
24
Strategie per Spider specializzati Ristretti a siti specifici. –Rimuove alcuni links da Q. Ristretti a directories specifici. –Rimuove i links non contenuti nel directory. Obbedisce a restrizioni imposte dai proprietari dei siti (robot exclusion).
..")
25
Dettagli sulle tecniche di Spidering : 1. Estrazione dei Link (puntatori) Si devono identificare tutti i links contenuti in una pagina ed estrarre le relative URLs, per proseguire nellesplorazione. – Se esistono URL specificate con riferimento alla URL della pagina corrente, devono costruire un URL completo : – diventa http://www.cs.utexas.edu/users/mooney/ir-course/proj3 – diventa http://www.cs.utexas.edu/users/mooney/cs343/syllabus.html I frames dividono una pagina in sezioni
 Si devono identificare tutti i links contenuti in una pagina ed estrarre le relative URLs, per proseguire nellesplorazione. – Se esistono URL specificate con riferimento alla URL della pagina corrente, devono costruire un URL completo : – diventa – diventa I frames dividono una pagina in sezioni.")
26
2. Esprimere i Link in formato canonico Variazioni equivalenti vengono normalizzate rimuovendo la slash finale http://www.cs.utexas.edu/users/mooney/ –http://www.cs.utexas.edu/users/mooney Si rimuovono i riferimenti a pagine interne (refs) : –http://www.cs.utexas.edu/users/mooney/welcome.html#courses –http://www.cs.utexas.edu/users/mooney/welcome.html
 : – –")
27
3. Refresh: aggioramento delle pagine Il Web è dinamico: ci sono molte pagine nuove, pagine aggiornate, cancellate, riposizionate.. Periodicamente lo Spider deve verificare tutte le pagine indicizzate per aggiornamenti e cancellazioni : –Basta guardare le info di intestazione (es. META tags sullultimo aggiornamento) per verificare se la pagina è stata aggiornata, e ricaricarla se necessario. Tiene traccia delle pagine più dinamiche nel tempo, e controlla quelle in prevalenza. Aggiorna e verifica con preferenza le pagine più popolari.
 per verificare se la pagina è stata aggiornata, e ricaricarla se necessario. Tiene traccia delle pagine più dinamiche nel tempo, e controlla quelle in prevalenza. Aggiorna e verifica con preferenza le pagine più popolari..")
28
4. Robot Exclusion Alcuni siti Web o pagine possono richiedere che gli spiders/robot non accedano né indicizzino certe aree. Due componenti: –Robots Exclusion Protocol: E un protocollo che vieta laccesso da direttori specificati allintero sito. Robots META Tag: Etichetta documenti specifici per evitarne lindicizzazione o lesplorazione.

29
Robots Exclusion Protocol Gli amministratori dei siti mettono un file robots.txt alla radice del web directory dellhost. –http://www.ebay.com/robots.txthttp://www.ebay.com/robots.txt –http://www.cnn.com/robots.txthttp://www.cnn.com/robots.txt Il file contiene una lista di directories proibite per un dato robot, o agente di utente. –Exclude all robots from the entire site: User-agent: * Disallow: /

30
Robot Exclusion Protocol Examples Escludere directories: User-agent: * Disallow: /tmp/ Disallow: /cgi-bin/ Disallow: /users/paranoid/ Escludere uno specifico robot: User-agent: GoogleBot Disallow: / Consentire luso solo ad uno specifico robot: User-agent: GoogleBot Disallow: User-agent: * Disallow: /

31
5. Multi-Threaded Spidering Il collo di bottiglia consiste nel ritardo di rete per scaricare singole pagine. E preferibile seguire molti fili della rete in parallelo ognuno dei quali richiede una pagina da diversi host. Il precedente spider di Google aveva molti crawlers coordinati, ognuno con 300 thread, complessivamente capaci di scaricare più di 100 pagine al secondo.

32
6. Selezione delle pagine Quali pagine scaricare?? (non tutto il web!!) Metriche di importanza: –Interest-driven (spiders specializzati) –Popularity driven –Location driven
 Metriche di importanza: –Interest-driven (spiders specializzati) –Popularity driven –Location driven.")
33
Sommario (Spiders) Strategia di ricerca Strategia di aggiornamento (refresh) Minimizzazione del carico su altre organizzazioni (robot exclusion) Selezione delle pagine
 Strategia di ricerca Strategia di aggiornamento (refresh) Minimizzazione del carico su altre organizzazioni (robot exclusion) Selezione delle pagine")
34
2. Indicizzazione 1. Spidering (o Crawling)
")
35
Modalità per indicizzare le pagine sul Web Per ogni pagina identificata dallo Spider va creato un indice. Tre metodi (non esclusivi) –Si usano dei directories, che classificano le pagine Web per argomento –Si indicizza ogni documento esplorato dallo Spider come full text (flat o strutturato) –Si tiene conto della struttura ipertestuale del Web, cioè degli hyperlinks
 –Si usano dei directories, che classificano le pagine Web per argomento –Si indicizza ogni documento esplorato dallo Spider come full text (flat o strutturato) –Si tiene conto della struttura ipertestuale del Web, cioè degli hyperlinks.")
36
Indicizzazione mediante Directories: a) Classificazione manuale Yahoo usa editors umani per generare un directory gerachico di pagine web. –http://www.yahoo.com/http://www.yahoo.com/ Open Directory Project è un progetto simile, basato sul lavoro distribuito di editors volontari (net-citizens provide the collective brain). E utilizzato da molti motori di ricerca. Il progetto è stato avviato da Netscape. –http://www.dmoz.org/http://www.dmoz.org/
. E utilizzato da molti motori di ricerca. Il progetto è stato avviato da Netscape. –")
41
Indicizzazione mediante Directories: b) Classificazione automatica La classificazione manuale dei documenti sul web ad opera dei gestori di portali o motori di ricerca richiede molto tempo e molta forza-lavoro, è soggettiva, e soggetta a errori. I metodi automatici di classificazione dei testi possono essere usati per alleviare questo lavoro. Questi metodi si basano su tecniche di machine learning.

42
Gerarchizzazione automatica di documenti Lo sviluppo di tassonomie è un processo complesso, richiede tempo, è soggettivo, produce errori. Esistono metodi automatici (Hierarchical Agglomerative Clustering (HAC) ) per ottenere automaticamente una strutturazione gerarchica.
 ) per ottenere automaticamente una strutturazione gerarchica..")
43
Metodi di classificazione automatica Sport C n Politica C 1 Economia C 2........... Wonderfu l Totti Yesterday match Berlusconi acquires Inzaghi before elections Bush declare s war

44
Classificazione Automatica (2) Dato: –Un insieme di categorie: –Un insieme T di documenti d, definisci f : T 2 C VSM (Vector Space Model) –I documenti sono rappresentati come vettori (modello vettoriale). –Sia i documenti che le categorie sono vettori. –d è assegnato a se

45
Esempio Berlusconi Bush Totti Bush declares war. Berlusconi gives support Wonderful Totti in the yesterday match against Berlusconis Milan Berlusconi acquires Inzaghi before elections d 1 : Politica d1d1 d2d2 d3d3 C1C1 C 1 : Politica d 2 : Sportd 3 :Economia C2C2 C 2 : Sport

46
Si parte da un insieme di documenti-campione T, preassegnati manualmente alle varie classi, il peso di wi in dj –Ad esempio (ma esistono altri schemi di pesatura) TF * IDF, il peso di wi in C k :, i documenti di addestramento per Un documento d è assegnato alla classe C k se: Il Classificatore di Rocchio
 TF * IDF, il peso di wi in C k :, i documenti di addestramento per Un documento d è assegnato alla classe C k se: Il Classificatore di Rocchio")
47
Il classificatore di Rocchio Il peso della parola wi nel vettore che rappresenta Ck è il massimo fra: –0 –La differenza fra la somma dei pesi di wi nei documenti campione usati per apprendere il vettore Ck e la somma dei pesi di wi in tutti i documenti del set di apprendimento che NON sono appartenenti a Ck

48
Iperpiano di seperazione Altri metodi di classificazione: SVM Support Vectors Tk

49
1.Indicizzazione mediante classificazione 2. Creazione degli indici 2.1 Full text 2.2 Usando informazioni aggiuntive sul testo

50
Creazione automatica di Indici nel Web IR Molti sistemi usano varianti dell inverted file Ad ogni parola o keyword viene associato l insieme dei puntatori alle pagine che contengono la parola Eliminazione di stopwords, punteggiatura.. Usualmente si associa anche una breve descrizione del contenuto della pagina (per mostrarlo all utente)
.")
51
Creazione automatica di Indici (2) –Poiché occorrono circa 500 bytes per memorizzare linformazione relativa ad ogni pagina, occorrono circa 50 Gb per mantenere le informazioni relative a 100 milioni di pagine !! –Tecniche di compressione possono consentire di ridurre la taglia di un inverted file di circa il 30% (dunque bastano 15 Gb per 100 milioni di pagine)
.")
52
Creazione automatica di Indici (3) Alcuni inverted files puntano all occorrenza di una parola nel testo (non nel documento), ma la tecnica è troppo costosa in termini di memoria. Se si possiede un puntatore di posizione dentro la pagina, è possibile fare proximity search cio è cercare frasi (parole fra loro contigue). Qualche motore di ricerca consente proximity search, ma le tecniche non sono note interamente.
. Qualche motore di ricerca consente proximity search, ma le tecniche non sono note interamente..")
53
Creazione automatica di Indici (4) Una soluzione intermedia consiste nel puntare a blocchi anzich é a singole occorrenze nel documento. Questo riduce la taglia dei puntatori e velocizza la ricerca.

54
Metodi avanzati: Indicizzazione usando il testo nelle ancore Lo Spider analizza il testo nelle ancore (between and ) di ogni link seguito. Il testo nelle ancore di solito è molto informativo sul contenuto del documento cui punta. Si aggiunge il testo contenuto nellancora alla rappresentazione del contenuto della pagina destinazione (keywords). Questo metodo è usato da Google: – Evil Empire – IBM
. Questo metodo è usato da Google: – Evil Empire – IBM.")
55
Indicizzazione usando il testo nelle ancore (cont) E particolarmente utile quando il contenuto descrittivo nelle pagine destinazione è nascosto nei logo delle immagini piuttosto che in testi accessibili. Spesso non è affatto utile: –click here Migliora la descrizione del contenuto di pagine popolari con molti link entranti, ed aumenta la recall di queste pagine. Si può anche assegnare un peso maggiore al testo contenuto nelle ancore.

56
1. Classificazione 2. Creazione degli indici 2.1 Full text 2.2 Usando informazioni aggiuntive sul testo 3. Ranking 3.1 Ranking sulla base del contenuto 3.2 Ranking sulla base della struttura ipertestuale

57
Ranking I metodi di ranking usati dai motori di ricerca sono top- secret I metodi più usati sono il modello vettoriale e booleano La maggioranza dei motori utilizzano per il ranking anche gli hyperlinks. Le pagine risposta p i vengono valutate (ed il loro numero viene esteso) sulla base del numero di connessioni da e verso p i.
 sulla base del numero di connessioni da e verso p i..")
58
Link Analysis

59
Primi metodi di link analysis Gli Hyperlinks contengono informazioni che sussumono un giudizio sulla pagina Più links entrano in un sito, più importante è il giudizio Assunzioni La visibilità (hubness) di un sito si misura mediante il numero di siti che puntano ad esso La luminosità (authority) di un sito è il numero di altri siti che esso punta Limite: non cattura limportanza relativa dei siti parenti (cioè ad esso collegati )
 di un sito si misura mediante il numero di siti che puntano ad esso La luminosità (authority) di un sito è il numero di altri siti che esso punta Limite: non cattura limportanza relativa dei siti parenti (cioè ad esso collegati )")
60
HITS - Kleinbergs Algorithm HITS – Hypertext Induced Topic Selection Per ogni vertice v V in un sottografo di interesse: Un sito è autorevole se riceve molte citazioni. Le citazioni da parte di siti importanti pesano di più di quelle da parte di siti meno importanti. Un buon hub è un sito che è collegato con molti siti autorevoli a(v) - l authority di v h(v) - la hubness di v
 - l authority di v h(v) - la hubness di v.")
61
Authority e Hubness 2 3 4 1 1 5 6 7 a(1) = h(2) + h(3) + h(4) h(1) = a(5) + a(6) + a(7)
 = h(2) + h(3) + h(4) h(1) = a(5) + a(6) + a(7)")
62
Il grafo dei collegamenti I documenti sono visti come i nodi di un grafo Gli hyperlinks sono visti come archi diretti Gli archi possono avere pesi Si costruisce in tal modo il grafo dellintero web G web = (V(G web ), E(G web )) –E(G web ) V(G web ) V(G web ) 1 3 4 2 5 6 7 0010000 1000000 0001101 0000000 0000000 0001000 0001000 L: Matrice delle adiacenze
, E(G web )) –E(G web ) V(G web ) V(G web ) L: Matrice delle adiacenze")
63
Due metodi di ranking sono i più diffusi: HITS e Page Rank Basati sulla link analysis: –HITS (Hypertext Induced Topic Selection) (Kleinberg, 1997) Obiettivo: ottenere il ranking di una pagina per ogni specifica query (dinamico) –PageRank (Brin and Page, 1998) Obiettivo : ottenere un ranking di tutte le pagine del web indipendentemente dalle query (statico)
 (Kleinberg, 1997) Obiettivo: ottenere il ranking di una pagina per ogni specifica query (dinamico) –PageRank (Brin and Page, 1998) Obiettivo : ottenere un ranking di tutte le pagine del web indipendentemente dalle query (statico)")
64
HITS Hubs and Authorities (1) Si estrae il set P di pagine che includono le keywords di Q Si include il set delle back pages B = { b : (b, p) E(G web ) } Si include anche il set delle forward pages F = { f : (p, f) E(G web ) } Si definisce: –V Q = P B F –E Q = E web (B P P F) –G Q = (V Q, E Q ) search results p1p1 p |P| p2p2...... b1b1 b |B| b2b2...... back set f1f1 f |F| f2f2...... forward set Obiettivo : ottenere un ranking delle pagine per una particolare query Q = {w 1, …, w n }

65
Hubs and Authorities (2) Per una specifica query si vuole trovare: –Le authorities su quellargomento o topic (dove cioè le informazioni richieste effettivamente sono contenute) –I siti hub, che puntano alle migliori pagine su quel topic le authorities più importanti avranno molti siti che puntano ad esse Gli hubs più importanti avranno molti puntatori Assunzione: le migliori authorities sono puntate dai migliori hubs e viceversa
 Per una specifica query si vuole trovare: –Le authorities su quellargomento o topic (dove cioè le informazioni richieste effettivamente sono contenute) –I siti hub, che puntano alle migliori pagine su quel topic le authorities più importanti avranno molti siti che puntano ad esse Gli hubs più importanti avranno molti puntatori Assunzione: le migliori authorities sono puntate dai migliori hubs e viceversa")
66
Hubs and Authorities (3) Partendo dal grafo G Q, e dalla matrice di adiacenza L, si definiscono due vettori a = (a 1, a 2, …, a n ) T e h = (h 1, h 2, …, h n ) T, |V Q | = n, tali che: –a i è il grado di autorità di v i V(G Q ) –h i è il grado di di hubness di v i V(G Q )
 Partendo dal grafo G Q, e dalla matrice di adiacenza L, si definiscono due vettori a = (a 1, a 2, …, a n ) T e h = (h 1, h 2, …, h n ) T, |V Q | = n, tali che: –a i è il grado di autorità di v i V(G Q ) –h i è il grado di di hubness di v i V(G Q )")
67
The HITS algorithm (Kleinberg, 1998) h (0) := (1, 1, …, 1) T k := 1 Fino alla convergenza, esegui: –a (k) := L T h (k-1) (aggiorna a) –h (k) := L a (k) (aggiorna h) –a (k) := a (k) /||a (k) || and h (k) := h (k) /||h (k) || (normalizzazione) Si possono riscrivere le due assegnazioni nei termini degli stessi vettori dell iterazione precedente : –a (k) := L T h (k-1) = L T L a (k-1) –h (k) := L a (k) = L L T h (k-1) InizializzazoneIterazioni
 h (0) := (1, 1, …, 1) T k := 1 Fino alla convergenza, esegui: –a (k) := L T h (k-1) (aggiorna a) –h (k) := L a (k) (aggiorna h) –a (k) := a (k) /||a (k) || and h (k) := h (k) /||h (k) || (normalizzazione) Si possono riscrivere le due assegnazioni nei termini degli stessi vettori dell iterazione precedente : –a (k) := L T h (k-1) = L T L a (k-1) –h (k) := L a (k) = L L T h (k-1) InizializzazoneIterazioni")
68
Significato delle matrici L L T e L T L L è la adjacency matrix di G Q L T L è detta authority matrix: ij k A ij è il numero co-citazioni, cioè Il numero di nodi che puntano sia a i che j..vi ricorda qualcosa di già visto???????

69
Significato delle matrici L L T e L T L L è la adjacency matrix di G Q L T L è detta authority matrix L L T è detta hubness matrix: ij k H ij è il numero di co-referenze, cioè Il numero di nodi puntati sia da i che j j i

70
Significato delle matrici L L T e L T L L è la adjacency matrix di G Q L T L è detta authority matrix L L T è detta hubness matrix Le matrici sono: –Simmetriche (a ij = a ji i,j = 1, …, n) –Positive semidefinite ( i, i 0, i = 1, …, n)
 –Positive semidefinite ( i, i 0, i = 1, …, n)")
71
Il Power Method (1) Ricordate il passo iterativo : –a (k) := L T L a (k-1) –h (k) := L L T h (k-1) Lalgoritmo iterativo per calcolare i vettori HITS a e h è il power method per calcolare l eigenvector dominante (cioè l autovettore che corrisponde all autovalore di valore massimo) di L T L e LL T, rispettivamente (riguardatevi la lezione su LSI!!)
 Ricordate il passo iterativo : –a (k) := L T L a (k-1) –h (k) := L L T h (k-1) Lalgoritmo iterativo per calcolare i vettori HITS a e h è il power method per calcolare l eigenvector dominante (cioè l autovettore che corrisponde all autovalore di valore massimo) di L T L e LL T, rispettivamente (riguardatevi la lezione su LSI!!)")
72
Il Power Method Converge al Dominant Eigenvector 1, 2, …, k sono gli n eigenvalues di una matrice A (=LL T ) e | 1 | > | 2 | … | k | x 1, …, x k sono gli eigenvectors associati e linearmente indipendenti (indipendenza lineare : 1 x 1 + 2 x 2 +…+ k x k =0 iff 1 =…= k =0) Un generico vettore v 0 (h (0) o a (0) ) può essere scritto come: –v 0 = 1 x 1 + 2 x 2 +…+ k x k Quindi: –v 1 =Av 0 = 1 Ax 1 + 2 Ax 2 +…+ k Ax k = 1 1 x 1 + 2 2 x 2 +…+ k k x k = – 1 [ 1 x 1 + 2 ( 2 / 1 )x 2 +…+ k ( k / 1 )x k ] E in generale: –v m =Av m-1 =A m v 0 = 1 A m x 1 + 2 A m x 2 +…+ k A m x k = 1 1 m x 1 + 2 2 m x 2 +…+ k k m x k = 1 m [ 1 x 1 + 2 ( 2 / 1 ) m x 2 +…+ k ( k / 1 ) m x k ] Poichè | i / 1 | < 1, i = 2, 3, …, n, abbiamo: a (k) := L T L a (k-1) =A a (k-1)
![Il Power Method Converge al Dominant Eigenvector 1, 2, …, k sono gli n eigenvalues di una matrice A (=LL T ) e | 1 | > | 2 | … | k | x 1, …, x k sono gli eigenvectors associati e linearmente indipendenti (indipendenza lineare : 1 x x 2 +…+ k x k =0 iff 1 =…= k =0) Un generico vettore v 0 (h (0) o a (0) ) può essere scritto come: –v 0 = 1 x x 2 +…+ k x k Quindi: –v 1 =Av 0 = 1 Ax Ax 2 +…+ k Ax k = 1 1 x x 2 +…+ k k x k = – 1 [ 1 x ( 2 / 1 )x 2 +…+ k ( k / 1 )x k ] E in generale: –v m =Av m-1 =A m v 0 = 1 A m x A m x 2 +…+ k A m x k = 1 1 m x m x 2 +…+ k k m x k = 1 m [ 1 x ( 2 / 1 ) m x 2 +…+ k ( k / 1 ) m x k ] Poichè | i / 1 | < 1, i = 2, 3, …, n, abbiamo: a (k) := L T L a (k-1) =A a (k-1)](http://images.slideplayer.it/1/570461/slides/slide_72.jpg "Il Power Method Converge al Dominant Eigenvector 1, 2, …, k sono gli n eigenvalues di una matrice A (=LL T ) e | 1 | > | 2 | … | k | x 1, …, x k sono gli eigenvectors associati e linearmente indipendenti (indipendenza lineare : 1 x x 2 +…+ k x k =0 iff 1 =…= k =0) Un generico vettore v 0 (h (0) o a (0) ) può essere scritto come: –v 0 = 1 x x 2 +…+ k x k Quindi: –v 1 =Av 0 = 1 Ax Ax 2 +…+ k Ax k = 1 1 x x 2 +…+ k k x k = – 1 [ 1 x ( 2 / 1 )x 2 +…+ k ( k / 1 )x k ] E in generale: –v m =Av m-1 =A m v 0 = 1 A m x A m x 2 +…+ k A m x k = 1 1 m x m x 2 +…+ k k m x k = 1 m [ 1 x ( 2 / 1 ) m x 2 +…+ k ( k / 1 ) m x k ] Poichè | i / 1 | < 1, i = 2, 3, …, n, abbiamo: a (k) := L T L a (k-1) =A a (k-1)")
73
Convergenza del Power Method (2) Perciò, con m grande: Osservazione: la velocità di convergenza dipende dal rapporto | 1 / 2 |
 Perciò, con m grande: Osservazione: la velocità di convergenza dipende dal rapporto | 1 / 2 |")
74
HITS: Esempio (1) 3 6 1 4 2 5
")
75
HITS: Esempio (2) a1a1 h1h1 3 6 1 4 2 5 hubs –a (1) := L T h (0) –h (1) := L a (1) 3 6 1 2 5 authorities 4 h0h0 a1a1 = (la normalizzazione non è evidenziata)
 a1a1 h1h hubs –a (1) := L T h (0) –h (1) := L a (1) authorities 4 h0h0 a1a1 = (la normalizzazione non è evidenziata)")
76
HITS: Esempio (3) 3 6 1 4 2 5 hubs 3 6 1 4 2 5 authorities h1h1 a2a2 a2a2 h2h2 –a (2) := L T h (1) –h (2) := L a (2)
 hubs authorities h1h1 a2a2 a2a2 h2h2 –a (2) := L T h (1) –h (2) := L a (2)")
77
HITS: Esempio (4) 3 6 1 4 2 5 h2h2 a3a3 a3a3 h3h3 3 6 1 4 2 5 authorities hubs –a (3) := L T h (2) –h (3) := L a (3)
 h2h2 a3a3 a3a3 h3h authorities hubs –a (3) := L T h (2) –h (3) := L a (3)")
78
HITS: Esempio (5) 3 6 1 4 2 5 h3h3 a4a4 a4a4 h4h4 3 6 1 4 2 5 authorities hubs –a (4) := L T h (3) –h (4) := L a (4)
 h3h3 a4a4 a4a4 h4h authorities hubs –a (4) := L T h (3) –h (4) := L a (4)")
79
Strategia di Ranking L authority vector è il ranking delle pagine in G Q Cè un rischio di topic drift (slittamento del topic) –Le pagine Back e Forward possono essere più generali –Cè il rischio di recuperare pagine troppo generiche rispetto alla query Q Inoltre, è possibile influenzare i punteggi di hubness –Aggiungere degli archi in una pagina ne aumenta il valore di hubness, il quale a sua volta aumenta lautorithy delle pagine puntate, portando ad un effetto di SPAM!!
 –Le pagine Back e Forward possono essere più generali –Cè il rischio di recuperare pagine troppo generiche rispetto alla query Q Inoltre, è possibile influenzare i punteggi di hubness –Aggiungere degli archi in una pagina ne aumenta il valore di hubness, il quale a sua volta aumenta lautorithy delle pagine puntate, portando ad un effetto di SPAM!!")
80
PageRank Introdotto da Brin & Page (1998) –Il peso dipende dal rank dei nodi parenti P(a) è la probabilità che un navigatore casuale (random walker) raggiunga la pagina a C(a i ) numero complessivo di (out) links della pagina a i d è il damping factor e modella la probabilità che ilrandom walker smetta di navigare Differenza rispetto a HITS –HITS prende i pesi di Hubness & Authority –Page Rank è proporzionale al rank dei suoi nodi parenti ma inversamente proporzionale al outdegree dei suoi parenti
 –Il peso dipende dal rank dei nodi parenti P(a) è la probabilità che un navigatore casuale (random walker) raggiunga la pagina a C(a i ) numero complessivo di (out) links della pagina a i d è il damping factor e modella la probabilità che ilrandom walker smetta di navigare Differenza rispetto a HITS –HITS prende i pesi di Hubness & Authority –Page Rank è proporzionale al rank dei suoi nodi parenti ma inversamente proporzionale al outdegree dei suoi parenti")
81
PageRank è usato da Google The Anatomy of a Large-Scale Hypertextual Web Search Engine. Brin, S. & Page, L (1998). http://dbpubs.stanford.edu:8090/pub/1998-8
.")
82
T1 PR=0.5 T2 PR=0.3 T3 PR=0.1 A PR(A)=(1-d) + d*(PR(T1)/C(T1) + PR(T2)/C(T2) + PR(T3)/C(T3)) =0.15+0.85*(0.5/3 + 0.3/4+ 0.1/5) 3 4 5 2
=(1-d) + d*(PR(T1)/C(T1) + PR(T2)/C(T2) + PR(T3)/C(T3)) = *(0.5/ /4+ 0.1/5)")
83
Interpretazione probabilistica di PageRank PageRank dispone di una chiara ed intuitiva spiegazione probabilistica del suo funzionamento Pensiamo ad un navigatore che visita senza un particolare ordine i nodi del web seguendo i vari links che trova nelle pagine partendo da una pagina scelta a priori a caso (es. www.yahoo.com) www.yahoo.com Il PageRank non è altro che un indice di quanto tempo, mediamente, tale navigatore impiegherà ad arrivare su una certa pagina. Questo modello prende il nome di random walk o passeggiata casuale.

84
Notazione matriciale Matrice delle transizioni P = A meno del dumping factor, posso riscrivere la formula del PageRank di Brill&Page usando la notazione matriciale: dove è il vettore delle probabilità di raggiungere ogni pagina a i. P ij =0 se da i non cè hyperlink verso j; 1/C(a i ) altrimenti
 altrimenti.")
85
Come calcolare il vettore delle probabilità? Il modello delle Random Walk può essere modellato mediante le Markov Chains

86
Catene di Markov Una catena di Markov consiste in n stati (sia S tale insieme), e una matrice di probabilità di transizione n n P. Ad ogni passo, ci troviamo esattamente in uno stato. Per 1 i,j n, P(s i s j ) =P ij è la probabilità di transitare in s j, se ci troviamo attualmente in s i. Inoltre, se X k è la variabile aleatoria che indica lo stato raggiunto in t k (X assume valori in S), P(X k /X 1,X 2,… X k-1 )=P(X k /X k-1 ) Il valore di X al tempo k dipende solo dal valore della variabile aleatoria nellistante precedente
 =P ij è la probabilità di transitare in s j, se ci troviamo attualmente in s i. Inoltre, se X k è la variabile aleatoria che indica lo stato raggiunto in t k (X assume valori in S), P(X k /X 1,X 2,… X k-1 )=P(X k /X k-1 ) Il valore di X al tempo k dipende solo dal valore della variabile aleatoria nellistante precedente.")
87
Markov chains Ovviamente Le catene di Markov rappresentano un modello delle passeggiate casuali (random walks).
.")
88
Vettori di probabilità Indichiamo con x = (x 1, … x n ) un vettore che indichi lo stato raggiunto in un certo istante. Es: (000…1…000) indica che si è nello stato s i. in1 Poiché si tratta di un processo probabilistico, dovremo invece considerare il vettore x =(P(s 1 ), … P(s n ))= (x 1, … x n ), che indica che la passeggiata ha condotto in s i con probabilità x i, e
 indica che si è nello stato s i. in1 Poiché si tratta di un processo probabilistico, dovremo invece considerare il vettore x =(P(s 1 ), … P(s n ))= (x 1, … x n ), che indica che la passeggiata ha condotto in s i con probabilità x i, e.")
89
Catene di Markov ergodiche Una catena di Markov è ergodica se: –Esiste un percorso fra ogni coppia di stati –Da ogni stato, dopo un periodo di transizione T 0, la probabilità di raggiungere un qualsiasi altro stato in un tempo fisso T>T 0 è sempre diversa da zero.

90
Catene ergodiche Se una catena di Markov è ergodica, ogni stato ha una probabilità stazionaria di essere visitato, indipendentemente dal punto di partenza. –Il vettore delle probabilità x converge ad un valore stazionario a

91
Variazioni del vettore di probabilità Se il vettore è x (i) = (x 1, … x n ) al passo i, come cambierà al successivo passo? La riga i-esima della matrice P ci dice dove si transiterà dallo stato i (contiene le probabiltà di transizione da i verso gli stati ad essa collegati). Da x (i), la prob. dello stato successivo è distribuito come x (i) P (x (i+1) = x (i) P ) Se il processo è ergodico, x convergerà ad un vettore a tale che a=aP Poiché P è una matrice e a un vettore, che vettore è a per P??
. Da x (i), la prob. dello stato successivo è distribuito come x (i) P (x (i+1) = x (i) P ) Se il processo è ergodico, x convergerà ad un vettore a tale che a=aP Poiché P è una matrice e a un vettore, che vettore è a per P .")
92
Power method x (k+1) =Px (k) La sequenza di vettori x k converge al valore stazionario a Per il calcolo del valore stazionario a si utilizza il power method (già visto per HITS) x (k+1) =xP k =x (k) P Lassunzione che esista un autovalore dominante è essenziale per la convergenza del metodo Notate che, poiché in condizioni stazionarie deve essere a=aP, a è lautovettore dominante con autovalore dominante 1.
 =Px (k) La sequenza di vettori x k converge al valore stazionario a Per il calcolo del valore stazionario a si utilizza il power method (già visto per HITS) x (k+1) =xP k =x (k) P Lassunzione che esista un autovalore dominante è essenziale per la convergenza del metodo Notate che, poiché in condizioni stazionarie deve essere a=aP, a è lautovettore dominante con autovalore dominante 1.")
93
Come si calcola pageRank? Si parte da pesi casuali e si itera il procedimento Es: AB d = 0.85 PR(A) = (1 – d) + d(PR(B)/1) PR(B) = (1 – d) + d(PR(A)/1) Partiamo con P=1 PR(A)= 0.15 + 0.85 * 1= 1 PR(B)= 0.15+0,85*1=1 già converge!! Partiamo con P=0 PR(A)= 0.15 + 0.85 * 0= 0.15 PR(B)= 0.15+0,85*0.15=0.2775 PR(A)= 0.15 + 0.85 * 0.2775=0.385875 PR(B)=0.47799.. PR(A)=0.5562.. PR(B)=0.6228.. Tende a 1!!
 = (1 – d) + d(PR(B)/1) PR(B) = (1 – d) + d(PR(A)/1) Partiamo con P=1 PR(A)= * 1= 1 PR(B)= ,85*1=1 già converge!. Partiamo con P=0 PR(A)= * 0= 0.15 PR(B)= ,85*0.15= PR(A)= * = PR(B)= PR(A)= PR(B)= Tende a 1!!.")
94
Esempio 2

95
Matrice adiacenze normalizzata 1/C(a i ) P
 P")
96
Iterazioni x 0 x 1 x 2 x 3 x 4 x 60 x 611 x (k+1) =Px (k)
 =Px (k)")
98
Nota: c in figura è il damping factor (d)
")
99
Problemi Problema del Rank Sink –In generale, molte pagine web non hanno inlinks/outlinks E.g. nessun parente rank 0 nessun figlio P converge ad un vettore di zeri (pozzi o rank sink)
.")
100
Nessun figlio --> converge a zero

101
Convergenza di Page Rank PageRank è un algoritmo che è garantito convergere se e solo se la matrice P derivata da quella di adiacenza è irriducibile (cioè se il grafo è fortemente connesso) e aperiodica (il che corrisponde alla condizione di ergodicità vista prima) Per laperiodicità non ci sono problemi nella pratica (le pagine contenute in anelli sono molto poche in confronto alle pagine del web); per lirriducibilità serve utilizzare una formula leggermente diversa, che introduce gli archi tra tutte le pagine (anche dai pozzi), rendendo il grafo fortemente connesso Il vettore E è una distribuzione di probabilità di pagine a cui il navigatore può attingere per uscire da un rank-sink, allorché ne raggiunga uno, o da una pagina senza out-edges (E(a)=1/C(a))
 e aperiodica (il che corrisponde alla condizione di ergodicità vista prima) Per laperiodicità non ci sono problemi nella pratica (le pagine contenute in anelli sono molto poche in confronto alle pagine del web); per lirriducibilità serve utilizzare una formula leggermente diversa, che introduce gli archi tra tutte le pagine (anche dai pozzi), rendendo il grafo fortemente connesso Il vettore E è una distribuzione di probabilità di pagine a cui il navigatore può attingere per uscire da un rank-sink, allorché ne raggiunga uno, o da una pagina senza out-edges (E(a)=1/C(a))")
102
Rank sink Nella pratica dunque, i pozzi vengono trattati in uno di questi modi: –Per ogni pozzo i, si aggiungono archi fittizi dalla pagina i ad ogni altro pozzo, in modo da far sì che i pozzi cedano uniformemente la loro importanza al resto del grafo –Ad ogni passo di PageRank si aggiunge alle componenti del vettore a una stessa quantità (E) in modo che la norma di a rimanga pari a 1 –Alternativamente, si eliminano tutti i pozzi e si applica PageRank al grafo così ottenuto; i pozzi verranno poi reinseriti alla fine
 in modo che la norma di a rimanga pari a 1 –Alternativamente, si eliminano tutti i pozzi e si applica PageRank al grafo così ottenuto; i pozzi verranno poi reinseriti alla fine")
103
Altri Problemi di PageRank Guardate la figura e intuite il problema..

104
Problemi 302 Google Jacking: ogni pagina con rank basso che viene ridirezionata, mediante un 302 server header or a "Refresh" meta tag, ad una pagina con P elevato, aumenta artificialmente il proprio P. Alcune web companies vendono links con valori alti di P ai webmasters. Google combatte queste politiche. Attributo nofollow per combattere spamindexing (non seguire questo link..)
.")
Presentazioni simili





>")




>")
>")


>")
>")

>")
 Un collegamento end-to-end è formato da tre tratte, la prima AB con la velocità di 5 Mb/s, la seconda BC di 20 Mb/s e la terza CD di.>")



 Ogni doc. j è un vettore di valori tf idf Si può normalizzare a lunghezza.>")