Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Sistemi per il recupero delle informazioni
SISTEMI PER IL RECUPERO DELL’INFORMAZIONE

2
INTRODUZIONE Un concetto che può essere confuso con le basi di dati è quello delle banche di dati (o banca dati). Esistono fra di loro delle differenze sostanziali. Sempre più spesso i documenti nascono direttamente in forma elettronica dando vita a enormi banche dati che contengono oltre ad una sintetica descrizione dei documenti anche il testo in forma integrale. Esistono numerose raccolte di articoli apparsi in riviste specializzate e gestite da organismi internazionali (riviste scientifiche, banche di dati giuridici gestite dalla Cassazione, quelle sui brevetti, quelle della polizia ecc.). Queste raccolte sono consultabili interattivamente, anche con Internet, per fare ricerche in base al nome di un autore oppure in base al contenuto del riassunto.
. Esistono fra di loro delle differenze sostanziali. Sempre più spesso i documenti nascono direttamente in forma elettronica dando vita a enormi banche dati che contengono oltre ad una sintetica descrizione dei documenti anche il testo in forma integrale. Esistono numerose raccolte di articoli apparsi in riviste specializzate e gestite da organismi internazionali (riviste scientifiche, banche di dati giuridici gestite dalla Cassazione, quelle sui brevetti, quelle della polizia ecc.). Queste raccolte sono consultabili interattivamente, anche con Internet, per fare ricerche in base al nome di un autore oppure in base al contenuto del riassunto.")
3
PRINCIPALI DIFFERENZE
Nelle banche dati: le informazioni non sono organizzate in insiemi in relazione fra loro, ma sono rappresentate come insiemi di testi non sono modificabili in linea non sono utilizzabili per la gestione del sistema informativo di un’organizzazione possono solo raccogliere informazioni in forma testuale.

4
PRINCIPALI DIFFERENZE
BANCA DATI Inutile Utile per la gestione di una biblioteca, dove invece interessa una base di dati aggiornabile per trattare mediante transazioni l’acquisto dei libri, gli abbonamenti delle riviste, i prestiti ecc per effettuare ricerche di pubblicazioni su alcuni argomenti Per banca di dati intenderemo una raccolta di informazioni rappresentate in forma testuale e messe a disposizione di un gran pubblico di utenti per essere reperite specificando in modo parziale il loro contenuto.

5
PRELIMINARI La necessità di gestire automaticamente grandi quantità di informazioni memorizzate in forma di testo ha giustificato un vasto lavoro di ricerca motivato dalla consultazione di materiale bibliografico (libri, giornali e riviste) e di sommari di pubblicazioni scientifiche dall’automazione del lavoro d’ufficio (lettere, studi, relazioni), dove, secondo recenti stime, soltanto un terzo delle informazioni eterogenee trattate sono dati strutturati, mentre il resto è costituito da testi, immagini, voce.
 e di sommari di pubblicazioni scientifiche. dall’automazione del lavoro d’ufficio (lettere, studi, relazioni), dove, secondo recenti stime, soltanto un terzo delle informazioni eterogenee trattate sono dati strutturati, mentre il resto è costituito da testi, immagini, voce.")
6
IL DOCUMENTO Un documento è un’entità che possiede una parte strutturata, chiamata profilo, e una parte di testo. Il profilo contiene informazioni strutturate. Ad esempio: nel caso di un libro il nome dell’autore il titolo l’editore la data e il luogo di pubblicazione nel caso di un rapporto autore data nel caso di una lettera mittente e destinatario oggetto

7
RECUPERO DEI DOCUMENTI
I documenti, una volta archiviati, possono venir recuperati in base alle informazioni presenti nel profilo in base al contenuto del testo Nel primo caso si utilizzano le tradizionali tecniche sviluppate per i sistemi di gestione di basi di dati. Nel secondo caso si usano tecniche sviluppate espressamente per la gestione di testi.

8
GESTIRE I TESTI Il problema della gestione di testi per consentire il recupero di quelli che contengono alcune informazioni, è stato affrontato nel settore disciplinare noto attualmente con il nome di “recupero dell’informazione” (information retrieval) e sono stati sviluppati sistemi adatti a tale scopo. L’Information Retrieval (IR) si occupa della rappresentazione, memorizzazione e organizzazione dell’informazione, al fine di rendere agevole all’utente il soddisfacimento dei propri bisogni informativi.
 e sono stati sviluppati sistemi adatti a tale scopo. L’Information Retrieval (IR) si occupa della rappresentazione, memorizzazione e organizzazione dell’informazione, al fine di rendere agevole all’utente il soddisfacimento dei propri bisogni informativi.")
9
Information retrieval
Data una collezione di documenti e un bisogno informativo dell’utente, obiettivo dell’IR è di recuperare, all’interno di una collezione, tutti e solo i documenti rilevanti per un particolare utente con una particolare richiesta informativa sistemi specializzati nella gestione di documenti di testo e nel recupero in base al loro contenuto Rilevanza è un concetto chiave dell’IR, su cui torneremo grossa collezione di documenti Collezioni fulltext Digital libraries Pagine Web (motori di ricerca – search engines) Rispetto alla teoria classica delle basi di dati, l’enfasi non è sulla ricerca di dati ma sulla ricerca di informazioni. Un sistema per il recupero dell’informazione (Information Retrieval System - IRS) è un sistema che gestisce raccolte di documenti al fine di recuperare documenti giudicati rilevanti dal sistema stesso rispetto alle richieste effettuate dagli utenti.
 Rispetto alla teoria classica delle basi di dati, l’enfasi non è sulla ricerca di dati ma sulla ricerca di informazioni. Un sistema per il recupero dell’informazione (Information Retrieval System - IRS) è un sistema che gestisce raccolte di documenti al fine di recuperare documenti giudicati rilevanti dal sistema stesso rispetto alle richieste effettuate dagli utenti.")
10
Information retrieval
Il settore dell’Information Retrieval è stato studiato fin dagli anni `70. l’espressione “information retrieval” è coniata da C. Mooers nel 1952 Il primo computer studiato per l’irs è del 1957 Negli anni `90, l’esplosione del Web ha moltiplicato l’interesse per IR. Il Web infatti non è altro che un’enorme collezione di documenti, sui quali gli utenti vogliono fare ricerche informazionali. per quanto riguarda le risorse informative di tipo elettronico reperibili in www, uno studio compiuto dall’On Line Catalogue della Library of Congress Office of Research (OCLC) parla di risorse per il solo web pubblico (corrispondente a circa il 35% del web totale) (O’Neill 2003). Per la ricerca di informazioni disponibili su calcolatori di tutto il mondo collegati in rete Internet è disponibile il sistema Google. Altra possibilità per il futuro è la disponibilità di banche dati multimediali, ad esempio di immagini, sulle quali si possono fare ricerche per contenuto con una filosofia analoga a quella usata per i testi.
 parla di risorse per il solo web pubblico (corrispondente a circa il 35% del web totale) (O’Neill 2003). Per la ricerca di informazioni disponibili su calcolatori di tutto il mondo collegati in rete Internet è disponibile il sistema Google. Altra possibilità per il futuro è la disponibilità di banche dati multimediali, ad esempio di immagini, sulle quali si possono fare ricerche per contenuto con una filosofia analoga a quella usata per i testi.")
11
RILEVANZA DEI DOCUMENTI
Quando una persona desidera trovare i documenti di una raccolta che contengono alcune informazioni, formula una richiesta e di solito ottiene in risposta sia documenti effettivamente utili, o rilevanti, che documenti inutili. La rilevanza di un documento non può essere garantita dal sistema per il recupero dell’informazione, ma solo da chi ha formulato la richiesta. Pertanto può accadere che documenti che l’utente considererebbe rilevanti non facciano parte dei documenti recuperati dal sistema, e viceversa. Un sistema per il recupero dell’informazione cerca di limitare questi due inconvenienti che, in generale, non possono essere eliminati. Il problema centrale di IRS è trovare una serie di documenti ritenuti rilevanti da una collezione praticamente infinita e che soddisfano l’esigenza informativa del soggetto espressa attraverso una domanda. Al fine di recuperare un documento l’IRS deve comparare il contenuto semantico della domanda (query) con il contenuto semantico di una serie di documenti. IRS considera rilevante un documento per una query se la query è contenuta nel documento o se la query può essere recuperata in qualche modo nel documento. È opportuno ricordare che il soggetto che pone la domanda ha una valutazione propria di ciò che viene recuperato per cui la valutazione di IRS può essere diversa dalla valutazione fatta dal soggetto che interroga il sistema. Per avvicinare la valutazione del soggetto alla valutazione del sistema sono stati ideati vari linguaggi di interrogazione che vanno dalla logica booleana al linguaggio naturale. Data la tendenza di IRS di interpretare la query con la logica booleana, con algoritmi probabilistici o con il linguaggio naturale, oltre a verificarsi una discrepanza tra valutazione dei documenti recuperati da parte del soggetto che formula la query e IRS, può accadere anche che la formulazione della query, la sua grammatica, venga ritenuta errata per cui il soggetto deve ristrutturarla. Il documento è rilevante se il soggetto che formula la query lo ritiene tale. A partire da tale presupposto, si sono sviluppati sistemi di retrieval orientati sempre più verso la valorizzazione della semantica dell’interrogazione. DEFINIZIONE Un documento è rilevante se soddisfa il bisogno d’informazione che l’utente ha espresso con la sua richiesta.
 con il contenuto semantico di una serie di documenti. IRS considera rilevante un documento per una query se la query è contenuta nel documento o se la query può essere recuperata. in qualche modo nel documento. È opportuno ricordare che il soggetto che pone la domanda ha una valutazione propria di ciò. che viene recuperato per cui la valutazione di IRS può essere diversa dalla valutazione fatta dal soggetto che interroga il. sistema. Per avvicinare la valutazione del soggetto alla valutazione del sistema sono stati ideati vari linguaggi di. interrogazione che vanno dalla logica booleana al linguaggio naturale. Data la tendenza di IRS di interpretare la query con la logica booleana, con algoritmi probabilistici o con il linguaggio. naturale, oltre a verificarsi una discrepanza tra valutazione dei documenti recuperati da parte del soggetto che formula la. query e IRS, può accadere anche che la formulazione della query, la sua grammatica, venga ritenuta errata per cui il. soggetto deve ristrutturarla. Il documento è rilevante se il soggetto che formula la query lo ritiene tale. A partire da tale presupposto, si sono. sviluppati sistemi di retrieval orientati sempre più verso la valorizzazione della semantica dell’interrogazione. DEFINIZIONE. Un documento è rilevante se soddisfa il bisogno d’informazione che l’utente ha espresso con la sua richiesta.")
12
ESEMPIO DI RILEVANZA Si supponga di avere un insieme Impiegati di dati strutturati, con attributi Nome, Indirizzo, Codice, AnnoAssunzione, e Stipendio; per conoscere il nome e l’indirizzo degli impiegati assunti dopo il 1970 che guadagnano più di 2000€ al mese, una possibile formulazione della richiesta è la seguente: SQL> SELECT Nome, Indirizzo FROM Impiegati WHERE AnnoAssunzione >= 1970 AND Stipendio > 2000 In risposta si ottengono i dati che soddisfano esattamente la condizione specificata e quindi certamente rilevanti.

13
ESEMPIO DI RILEVANZA Si supponga invece di avere un insieme di documenti; per recuperare i documenti relativi all’uso dei calcolatori per lo sviluppo di progetti architettonici, sapendo che il termine CAD è sinonimo di progetto assistito dal calcolatore, una possibile formulazione della richiesta è la seguente: SEARCH ‘architett%’ AND (CAD OR (‘progetto’ AND ‘calcolatore’)) FROM SENTENCE In risposta si ottengono documenti in cui le parole della richiesta assumono anche un significato differente da quello ad essi attribuito. Ad esempio, fra i documenti recuperati potrebbe esserci quello contenente la seguente frase “… l’impiego del calcolatore per lo sviluppo di progetti architettonici riguarda il campo di applicazione dell’informatica conosciuto con il nome di CAD (Computer Aided Design), …” ma anche quello contenente la frase “… nell’affrontare il progetto dell’architettura di un calcolatore bisogna tener conto del settore di applicazione in cui verrà utilizzato …” D’altra parte, documenti concettualmente pertinenti potrebbero essere ignorati. Fra i documenti non recuperati potrebbe esserci quello contenente la seguente frase “… l’uso di computer nel disegno di componenti VLSI è una delle aree di sicuro interesse per la progettazione assistita dal calcolatore …”
) FROM SENTENCE. In risposta si ottengono documenti in cui le parole della richiesta assumono anche un significato differente da quello ad essi attribuito. Ad esempio, fra i documenti recuperati potrebbe esserci quello contenente la seguente frase. … l’impiego del calcolatore per lo sviluppo di progetti architettonici riguarda il campo di applicazione dell’informatica conosciuto con il nome di CAD (Computer Aided Design), … ma anche quello contenente la frase. … nell’affrontare il progetto dell’architettura di un calcolatore bisogna tener conto del settore di applicazione in cui verrà utilizzato … D’altra parte, documenti concettualmente pertinenti potrebbero essere ignorati. Fra i documenti non recuperati potrebbe esserci quello contenente la seguente frase. … l’uso di computer nel disegno di componenti VLSI è una delle aree di sicuro interesse per la progettazione assistita dal calcolatore …")
14
Information Retrieval vs Data Retrieval
Un sistema di Data Retrieval (ad esempio un DBMS) gestisce dati che hanno una struttura ed una semantica ben definita. Un sistema di Information Retrieval gestisce testi scritti in linguaggio naturale, spesso non ben strutturati e semanticamente ambigui. Un linguaggio per Data Retrieval permette di trovare tutti gli oggetti che soddisfano esattamente le condizioni definite. Tali linguaggi (algebra relazionale, SQL) garantiscono una risposta corretta e completa. Un sistema di Information Retrieval, invece, potrebbe restituire, tra gli altri, oggetti non esatti; piccoli errori sono accettabili e probabilmente non verranno notati dall’utente.
 gestisce dati che hanno una struttura ed una semantica ben definita. Un sistema di Information Retrieval gestisce testi scritti in linguaggio naturale, spesso non ben strutturati e semanticamente ambigui. Un linguaggio per Data Retrieval permette di trovare tutti gli oggetti che soddisfano esattamente le condizioni definite. Tali linguaggi (algebra relazionale, SQL) garantiscono una risposta corretta e completa. Un sistema di Information Retrieval, invece, potrebbe restituire, tra gli altri, oggetti non esatti; piccoli errori sono accettabili e probabilmente non verranno notati dall’utente.")
15
DIFFERENZE CON I SGBD Documenti con molto testo piuttosto che dati strutturati. Le richieste sono espressioni imprecise del bisogno informativo Le risposte sono riferimenti a documenti “che potrebbero contenere le risposte” piuttosto che direttamente le risposte

16
Domanda tipica a un SGBD
SELECT Nome, Ufficio FROM Impiegati WHERE AnnoAssunzione > 1970 AND Stipendio > 3000

17
Domanda tipica a un SRI FIND architett*
AND (cad OR (progetto AND calcolatore)) “… l’impiego del calcolatore per lo sviluppo di progetti architettonici riguarda il campo di applicazioni dell’informatica conosciuto con il nome di CAD, ovvero progetto assistito da calcolatore…” “… nell’affrontare il progetto dell’architettura di un calcolatore bisogna tener conto del settore di applicazione in cui verrà utilizzato …” si trovano documenti con contenuto diverso
) … l’impiego del calcolatore per lo sviluppo di progetti architettonici riguarda il campo di applicazioni dell’informatica conosciuto con il nome di CAD, ovvero progetto assistito da calcolatore… … nell’affrontare il progetto dell’architettura di un calcolatore bisogna tener conto del settore di applicazione in cui verrà utilizzato … si trovano documenti con contenuto diverso.")
18
Sintesi delle differenze

19
COSA AFFRONTEREMO… Il modo in cui si rappresenta il contenuto dei documenti il criterio adottato per stabilire quali documenti recuperare per soddisfare una richiesta.

20
Il nucleo di un SRI

21
IL PROBLEMA INFORMATIVO
Il problema informativo corrisponde ad un particolare bisogno di informazione dell’utente. Tramite un processo di rappresentazione, il problema informativo viene tradotto in una richiesta espressa nel linguaggio di interrogazione dell’IRS. Analogamente, dai documenti, tramite un altro processo di rappresentazione, spesso chiamato di classificazione o indicizzazione, si passa al surrogato dei documenti, cioè alla loro rappresentazione nell’IRS. Sia nella classificazione di un documento da parte di un esperto che nella formulazione della richiesta da parte di un utente può essere usato un vocabolario controllato organizzato in un thesaurus. Un sistema di recupero dell’informazione gestisce i documenti. Per agevolare l’accesso ai dati il sistema costruisce delle rappresentazioni sintetiche dei documenti (dati ausiliari).
.")
22
IL PROBLEMA INFORMATIVO
I metodi di rappresentazione dei documenti si possono separare in due categorie: quelli che danno una rappresentazione diretta del contenuto dei documenti e quelli che ne danno una rappresentazione indiretta. Nel primo caso il documento è rappresentato dalle parole in esso contenute mentre nel secondo il documento è rappresentato da termini di indicizzazione derivati manualmente o automaticamente e che ne descrivono in modo sintetico e completo il contenuto Rappresentazione dei documenti in forma sintetica: indicizzazione: l’idea è quella di associare a ciascun documento un insieme di termini significativi che saranno utilizzati per selezionare il documento.

23
IL PROBLEMA INFORMATIVO
Possiamo pensare ad un SRI come ad un sistema in cui da un lato entrano documenti che vengono sottoposti ad un processo di indicizzazione, per ottenerne una rappresentazione sintetica, dall’altro entrano le richieste dell’utente che devono essere codificate in modo analogo, cioè come un insieme di termini. In fase di recupero: Formalizzazione delle richieste Contronto tra richieste e rappresentazione di documenti All’interno dell’IRS l’esecuzione di una richiesta utente di una ricerca di documenti avviene confrontando la rappresentazione del contenuto dei documenti (surrogato) con la rappresentazione della richiesta utente (interrogazione). In questo processo di confronto l’IRS adotta una particolare tecnica di recupero dei documenti che serve per giudicare quali documenti sono rilevanti e in che misura rispetto all’interrogazione La presenza di documenti non rilevanti come risultato di una richiesta utente e l’assenza di alcuni documenti rilevanti è da imputare sia al processo di trasformazione dal problema informativo All’interrogazione ()cioè come il bisogno di informazione dell’utente viene espresso nel linguaggio di interrogazione) sia al processo di trasformazione dal contenuto dei documenti al loto surrogato
 con la rappresentazione della richiesta utente (interrogazione). In questo processo di confronto l’IRS adotta una particolare tecnica di recupero dei documenti che serve per giudicare quali documenti sono rilevanti e in che misura rispetto all’interrogazione. La presenza di documenti non rilevanti come risultato di una richiesta utente e l’assenza di alcuni documenti rilevanti è da imputare sia al processo di trasformazione dal problema informativo All’interrogazione ()cioè come il bisogno di informazione dell’utente viene espresso nel linguaggio di interrogazione) sia al processo di trasformazione dal contenuto dei documenti al loto surrogato.")
24
IL PROBLEMA INFORMATIVO
Si definisce tecnica di recupero (retrieval technique) di un IRS la tecnica adottata dal sistema per confrontare l’interrogazione utente con il surrogato dei documenti. La tecnica di recupero adottata da un IRS, è il meccanismo interno del sistema che lo guida nel giudicare come rilevanti o non rilevanti i documenti di una raccolta, in rapporto ad una specifica interrogazione. Le tecniche di recupero sono di due tipi: per corrispondenza esatta (exact match) per similitudine o corrispondenza parziale (partial match) Risultato Binario (si/no) – il risultato soddisfa o non soddisfa la richiesta (corrispondenza esatta) Probabilistico – il risultato soddisfa la richiesta in una qualche misura (corrispondenza parziale)
 di un IRS la tecnica adottata dal sistema per confrontare l’interrogazione utente con il surrogato dei documenti. La tecnica di recupero adottata da un IRS, è il meccanismo interno del sistema che lo guida nel giudicare come rilevanti o non rilevanti i documenti di una raccolta, in rapporto ad una specifica interrogazione. Le tecniche di recupero sono di due tipi: per corrispondenza esatta (exact match) per similitudine o corrispondenza parziale (partial match) Risultato. Binario (si/no) – il risultato soddisfa o non soddisfa la richiesta (corrispondenza esatta) Probabilistico – il risultato soddisfa la richiesta in una qualche misura (corrispondenza parziale)")
25
DBMS vs IRS Riprendendo il confronto con i DBMS riassumiamo le principali caratteristiche dei due sistemi Modello dei dati: come si rappresentano le informazioni. Nei DBMS le informazioni si rappresentano come insieme di dati strutturati e relazioni fra insiemi. Negli IRS le informazioni si rappresentano come insieme di testi. Richiesta: come si specifica ciò che si cerca. Nei DBMS l’utente descrive in modo completo e preciso ciò di cui ha bisogno; negli IRS non si specifica completamente il valore del testo di un documento ma se ne specifica il contenuto mediante una descrizione abbreviata e pertanto soggettiva e incompleta

26
DBMS vs IRS Tecnica di recupero: come il sistema, in fase di ricerca, decide se un documento soddidfa la richiesta. Nei DBMS la scelta delle registrazioni da recuperare si basa sula corrispondenza esatta fra quanto specificato nella richiesta e quanto in esse contenuto; negli IRS questa corrispondenza è in generale parziale perché basata su un criterio di similitudine che dipende da come si rappresenta il contenuto del documento Risultato: cosa fornisce il sistema come risposta ad una richiesta. Nei DBMS vengono fornite solo le registrazioni che soddisfano la condizione di ricerca; negli IRS vengono forniti documenti probabilmente rilevanti: è compito dell’utente stablire quali di essi siano davvero tali, sapendo che il sistema non garantisce che fra i documenti non recuperati non ne esistano di rilevanti

27
EFFETTO RUMORE E SILENZIO
Si tratta di due effetti negativi che caratterizzano un sistema per il recupero dell’informazione: l’effetto rumore è la presenza di documenti non rilevanti fra quelli recuperati l’effetto silenzio è il mancato recupero di documenti rilevanti Dato un insieme di documenti e una richiesta, è possibile individuare quattro sottoinsiemi: l’insieme dei documenti correttamente recuperati in quanto rilevanti per la richiesta (A), l’inseme dei documenti che pur non essendo rilevanti sono stati recuperati (B) l’insieme dei documenti giustamente omessi in quanto non rilevanti (C) l’insieme dei documenti non recuperati anche se rilevanti (D)
, l’inseme dei documenti che pur non essendo rilevanti sono stati recuperati (B) l’insieme dei documenti giustamente omessi in quanto non rilevanti (C) l’insieme dei documenti non recuperati anche se rilevanti (D)")
28
SCHEMATIZZANDO

29
EFFICACIA DEL SISTEMA Come è possibile rispondere alla domanda “quale di questi due sistemi di IR funziona meglio”? Un sistema tradizionale di Data Retrieval può essere valutato oggettivamente, sulla base delle performance (velocità di indicizzazione, ricerca ecc.). In un sistema di IR tali valutazioni delle performance sono possibili, ma, a causa della soggettività delle risposte alle query, le cose si complicano… Quello che si vorrebbe in qualche modo misurare è la soddisfazione dell’utente.
. In un sistema di IR tali valutazioni delle performance sono possibili, ma, a causa della soggettività delle risposte alle query, le cose si complicano… Quello che si vorrebbe in qualche modo misurare è la soddisfazione dell’utente.")
30
EFFICACIA DEL SISTEMA Per misurare l’efficacia di un sistema per il recupero dell’informazione si usano due parametri, chiamati richiamo (recall) e precisione (precision). Il richiamo R è il rapporto fra il numero di documenti rilevanti recuperati (A) e il totale dei documenti rilevanti archiviati (A + D). La precisione P è il rapporto fra il numero di documenti rilevanti recuperati (A) e il totale dei documenti recuperati (A + B). Il massimo valore sia per il richiamo che per la precisione è 1. Il richiamo misura la capacità del sistema di recuperare tutti i documenti rilevanti, mentre la precisione misura la capacità del sistema di recuperare solo documenti rilevanti. Un sistema con precisione P < 1 ammette nelle risposte documenti non rilevanti. Un sistema con richiamo R < 1 ammette che documenti rilevanti non siano reperiti.
 e precisione (precision). Il richiamo R è il rapporto fra il numero di documenti rilevanti recuperati (A) e il totale dei documenti rilevanti archiviati (A + D). La precisione P è il rapporto fra il numero di documenti rilevanti recuperati (A) e il totale dei documenti recuperati (A + B). Il massimo valore sia per il richiamo che per la precisione è 1. Il richiamo misura la capacità del sistema di recuperare tutti i documenti rilevanti, mentre la precisione misura la capacità del sistema di recuperare solo documenti rilevanti. Un sistema con precisione P < 1 ammette nelle risposte documenti non rilevanti. Un sistema con richiamo R < 1 ammette che documenti rilevanti non siano reperiti.")
31
Richiamo e Precisione Parametri da valutare sempre contemporaneamente
Indicizzazione esaustiva + linguaggio specifico = alto RICHIAMO e alta PRECISIONE

32
Modelli di SRI Un modello cerca di astrarre le caratteristiche salienti che stanno alla base di una classe di sistemi. Nel caso degli SRI un modello riguarda: lo stile di rappresentazione dei documenti; lo stile di rappresentazione delle richieste; la modalità del confronto tra rappresentazioni di documenti e richieste. Sistemi IR: struttura l’insieme delle possibili chiavi di accesso assegnate ai documenti; l’insieme delle domande formulabili dagli utenti; l’insieme degli indicatori di valore informativo da assegnare ai documenti; una regola di recupero.

33
Modelli di SRI Modello booleano un modello a corrispondenza esatta
Modello vettoriale un modello a corrispondenza parziale Ne esistono molti altri intermedi: il modello fuzzy, probabilistico … L’indicizzazione si occupa di come si ottiene la rappresentazione dei documenti (dopo)
")
34
Modello booleano Rappresentazione dei documenti
I documenti vengono rappresentati come insiemi di termini che ne rappresentano il contenuto (scelti durante l’indicizzazione) Interrogazioni Le query vengono specificate come espressioni booleane, cioè come un elenco di termini connessi dagli operatori booleani AND, OR e NOT. Criterio di corrispondenza La strategia di ricerca è basata su un criterio di decisione binario, senza alcuna nozione di grado di rilevanza: un documento viene considerato rilevante o non rilevante. AND: i termini sono entrambi presenti OR: almeno uno dei due termini è presente NOT: il termine non è presente chiavi di accesso: PIU’ DI UN DESCRITTORE PUO’ ESSERE ASSEGNATO A OGNI DOCUMENTO COME CHIAVE D’ACCESSO domande: OGNI DOMANDA PUO’ CONTENERE PIU’ DI UN DESCRITTORE indicatori di valore informativon : COME NEI MODELLI A, B regola di recupero: AL DOC. VIENE ATTRIBUITO VALORE INFORMATIVO SE TUTTI I DESCRITTORI CONTENUTI NELLA DOMANDA SONO UGUALI A QUELLI ASSEGNATI COME CHIAVI D’ACCESSO AL DOC.
 Interrogazioni. Le query vengono specificate come espressioni booleane, cioè come un elenco di termini connessi dagli operatori booleani AND, OR e NOT. Criterio di corrispondenza. La strategia di ricerca è basata su un criterio di decisione binario, senza alcuna nozione di grado di rilevanza: un documento viene considerato rilevante o non rilevante. AND: i termini sono entrambi presenti. OR: almeno uno dei due termini è presente. NOT: il termine non è presente. chiavi di accesso: PIU’ DI UN DESCRITTORE PUO’ ESSERE ASSEGNATO A OGNI DOCUMENTO COME CHIAVE D’ACCESSO. domande: OGNI DOMANDA PUO’ CONTENERE PIU’ DI UN DESCRITTORE. indicatori di valore informativon : COME NEI MODELLI A, B. regola di recupero: AL DOC. VIENE ATTRIBUITO VALORE INFORMATIVO SE TUTTI I DESCRITTORI CONTENUTI NELLA DOMANDA SONO UGUALI A QUELLI ASSEGNATI COME CHIAVI D’ACCESSO AL DOC.")
35
Esempio (film AND amore) documenti che contengono “film” e “amore”
(dramma OR drammatico) documenti che contengono “dramma” o “drammatico” NOT (dramma OR drammatico) … che non contengono “dramma” o “drammatico” ((film AND amore) AND NOT (dramma OR drammatico))
 documenti che contengono dramma o drammatico NOT (dramma OR drammatico) … che non contengono dramma o drammatico ((film AND amore) AND NOT (dramma OR drammatico))")
36
Modello vettoriale: documenti
Rappresentazione dei documenti una sequenza di numeri lunga quanto il numero di tutti i termini utilizzati per rappresentare i documenti nella collezione, un vettore appunto. D = (t1, t2, …, tn) n numero di termini tk=0 se il termine non è presente altrimenti tk è il peso del termine kesimo nel documento, una misura di importanza chiavi di accesso: COME NEL MODELLI BOOLEANO domande: COME NEI MODELLI D, E; E’ POSSIBILE “FILTRARE” LE DOMANDE indicatori di valore informativo: GLI INDICATORI DI VALORE INFORMATIVO SONO TUTTI I NUMERI REALI (il documento può avere maggiore o minore valore informativo in funzione di una domanda) regola di recupero:AL DOC. VIENE ATTRIBUITO UN INDICATORE DI VALORE (che ne determina la priorità di recupero) CALCOLATO SECONDO ALGORITMI diversi secondo i diversi sistemi
 n numero di termini. tk=0 se il termine non è presente altrimenti tk è il peso del termine kesimo nel documento, una misura di importanza. chiavi di accesso: COME NEL MODELLI BOOLEANO. domande: COME NEI MODELLI D, E; E’ POSSIBILE FILTRARE LE DOMANDE. indicatori di valore informativo: GLI INDICATORI DI VALORE INFORMATIVO SONO TUTTI I NUMERI REALI (il documento può avere maggiore o minore valore informativo in funzione di una domanda) regola di recupero:AL DOC. VIENE ATTRIBUITO UN INDICATORE DI VALORE (che ne determina la priorità di recupero) CALCOLATO SECONDO ALGORITMI diversi secondo i diversi sistemi.")
37
Il modello vettoriale: interrogazione
Interrogazione: un insieme di termini Rappresentazione dell’interrogazione: un vettore, simile ai documenti (con moltissimi 0 e qualche 1 in corrispondenza dei termini specificati dall’utente) Q(t1, t2, … tn)
 Q(t1, t2, … tn)")
38
Il modello vettoriale: confronto
Una misura di similitudine tra documenti e richiesta. Esempio Di(ti1, ti2, ti3, …, tin) Q(q1, q2, q3, …, qn) S(Q, Di) = q1*ti1 + q2*ti qn*tin = Σj qj * tij con 0<j <=n AL DOC. VIENE ATTRIBUITO UN INDICATORE DI VALORE (che ne determina la priorità di recupero) CALCOLATO SECONDO ALGORITMI diversi secondo i diversi sistemi
 Q(q1, q2, q3, …, qn) S(Q, Di) = q1*ti1 + q2*ti qn*tin = Σj qj * tij con 0<j <=n. AL DOC. VIENE ATTRIBUITO UN INDICATORE DI VALORE (che ne determina la priorità di recupero) CALCOLATO SECONDO ALGORITMI diversi secondo i diversi sistemi.")
39
Esempio Due documenti che trattano di Papa, Roma e Vaticano … Vettori:
Interrogazione Q=[… 1, …, 1, …, 1, …] Similitudine Sim(D1, Q)=0,1+0,1+0,2=0,4 Sim(D2,Q)=0,1+0,9+0,9=1,9
=0,1+0,1+0,2=0,4. Sim(D2,Q)=0,1+0,9+0,9=1,9.")
40
… Passiamo ora ad esaminare i principali aspetti che distinguono i sistemi per il recupero delle informazioni Il modo in cui si rappresenta il contenuto dei documenti Il criterio adottato per stabilire quali documenti recuperare per soddisfare una richiesta

41
RAPPRESENTAZIONE DEI DOCUMENTI
I metodi di rappresentazione dei documenti si possono separare in due categorie in base alla rappresentazione che danno: rappresentazione diretta, in cui il documento è rappresentato dalle parole in esso contenute rappresentazione indiretta, in cui il documento è rappresentato da termini di indicizzazione, derivati manualmente o automaticamente, che ne descrivono in modo sintetico e completo il contenuto.

42
RAPPRESENTAZIONE DEL CONTENUTO DEI DOCUMENTI:
DIRETTA E INDIRETTA Con la rappresentazione diretta, un testo è rappresentato nella sua forma originaria come una sequenza di parole. Ai fini della ricerca, vengono trascurate le parole contenute in una lista di parole da ignorare (lista di esclusione o stop list) — come articoli, preposizioni, congiunzioni, avverbi ecc. — ritenute poco rappresentative del contenuto di un documento. La sequenza di parole di un testo, però, non sempre è una rappresentazione adeguata perché essa consente solo il recupero di testi con richieste che specificano una condizione sulle parole in essi presenti. Ad esempio con la richiesta “trovare i documenti che trattano il problema dell’emigrazione”, si vorrebbe avere fra i documenti rilevanti anche quello con titolo “Gli albanesi in Italia nel 1996”, anche se ci sono poche parole in comune con quanto richiesto. Pertanto la rappresentazione diretta del contenuto di un documento non è in generale adeguata.
 — come articoli, preposizioni, congiunzioni, avverbi ecc. — ritenute poco rappresentative del contenuto di un documento. La sequenza di parole di un testo, però, non sempre è una rappresentazione adeguata perché essa consente solo il recupero di testi con richieste che specificano una condizione sulle parole in essi presenti. Ad esempio con la richiesta trovare i documenti che trattano il problema dell’emigrazione , si vorrebbe avere fra i documenti rilevanti anche quello con titolo Gli albanesi in Italia nel 1996 , anche se ci sono poche parole in comune con quanto richiesto. Pertanto la rappresentazione diretta del contenuto di un documento non è in generale adeguata.")
43
RAPPRESENTAZIONE DEL CONTENUTO DEI DOCUMENTI:
DIRETTA E INDIRETTA Con la rappresentazione indiretta, ai fini delle ricerche, ad un testo è associato un insieme di parole chiave (keywords), semplici o composte, che ne descrivono in modo sintetico il contenuto. Ad esempio, a questa sezione potrebbero essere associate le seguenti parole chiavi: recupero dell’informazione e indicizzazione. L’operazione di attribuzione delle parole chiave ad un testo, denominata classificazione o indicizzazione (indexing), è di solito fatta manualmente da esperti, ma sono state studiate anche tecniche automatiche basate su metodi statistici.
, semplici o composte, che ne descrivono in modo sintetico il contenuto. Ad esempio, a questa sezione potrebbero essere associate le seguenti parole chiavi: recupero dell’informazione e indicizzazione. L’operazione di attribuzione delle parole chiave ad un testo, denominata classificazione o indicizzazione (indexing), è di solito fatta manualmente da esperti, ma sono state studiate anche tecniche automatiche basate su metodi statistici.")
44
Sistemi per il recupero delle informazioni
INDICIZZAZIONE

45
INDICIZZAZIONE Il problema fondamentale: identificare i contenuti dei documenti Indicizzazione: processo di rappresentazione dei documenti mediante una descrizione sintetica (es: catalogazione per soggetto in ambito bibliotecario) La caratterizzazione del documento consiste nell’ assegnazione a ciascun documento un insieme di termini, detti parole chiave o parole indice Serve per costruire indici su collezioni di documenti organizzazione indicizzata degli archivi Un indice è costituito da: una lista di termini una lista di termini pesati I sistemi di IR non operano sui documenti originali, ma su una vista logica degli stessi. Tradizionalmente i documenti di una collezione vengono rappresentati tramite un insieme di keyword. La capacità di memorizzazione dei moderni elaboratori permette talvolta di rappresentare un documento tramite l’intero insieme delle parole in esso contenute; si parla allora di vista logica full text. Per collezioni molto grandi tale tecnica può essere inutilizzabile; si utilizzano allora tecniche di modifica del testo per ridurre la dimensione della vista logica, che diventa un insieme di index term. Il modulo di gestione della collezione si occupa di creare gli opportuni indici, contenenti tali termini.
 La caratterizzazione del documento consiste nell’ assegnazione a ciascun documento un insieme di termini, detti parole chiave o parole indice. Serve per costruire indici su collezioni di documenti. organizzazione indicizzata degli archivi. Un indice è costituito da: una lista di termini. una lista di termini pesati. I sistemi di IR non operano sui documenti originali, ma su una vista logica degli stessi. Tradizionalmente i documenti di una collezione vengono rappresentati tramite un insieme di keyword. La capacità di memorizzazione dei moderni elaboratori permette talvolta di rappresentare un documento tramite l’intero insieme delle parole in esso contenute; si parla allora di vista logica full text. Per collezioni molto grandi tale tecnica può essere inutilizzabile; si utilizzano allora tecniche di modifica del testo per ridurre la dimensione della vista logica, che diventa un insieme di index term. Il modulo di gestione della collezione si occupa di creare gli opportuni indici, contenenti tali termini.")
46
INDICIZZAZIONE Tipicamente l’indicizzazione genera un insieme di termini indice (possibilmente pesati) come elementi base della rappresentazione formale di un documento I termini indice sono utilizzati come surrogati per la rappresentazione del documento originale e, quindi, possono essere utilizzati al suo posto durante la fase di recupero. L’uso degli indici semplifica e accelera il recupero (esempio: indice analitico di un libro).
 come elementi base della rappresentazione formale di un documento. I termini indice sono utilizzati come surrogati per la rappresentazione del documento originale e, quindi, possono essere utilizzati al suo posto durante la fase di recupero. L’uso degli indici semplifica e accelera il recupero (esempio: indice analitico di un libro).")
47
INDICIZZAZIONE Nell’IR testuale gli indici possono essere:
parole automaticamente estratte dal documento; radici di parole (per esempio class-) automaticamente estratte dal documento. Questa opzione è la più frequente; frasi (ad esempio “classificazione di processi industriali”) automaticamente estratte dal documento. Questo tipo di indici non hanno dato risultati migliori di 1 e 2; parole (o frasi) estratte da un vocabolario controllato; (in modo addizionale) metadati (ad esempio titolo, autori, data di creazione ecc. )
 automaticamente estratte dal documento. Questa opzione è la più frequente; frasi (ad esempio classificazione di processi industriali ) automaticamente estratte dal documento. Questo tipo di indici non hanno dato risultati migliori di 1 e 2; parole (o frasi) estratte da un vocabolario controllato; (in modo addizionale) metadati (ad esempio titolo, autori, data di creazione ecc. )")
48
Linguaggio di indicizzazione
Linguaggio di indicizzazione: insieme dei termini scelti per descrivere una collezione di documenti. E’ definito su un insieme di simboli (Vocabolario) Come sono scelte le parole del linguaggio di indicizzazione? Linguaggio controllato: limitato ad un vocabolario predefinito identificazione manuale dei termini significativi introduce meno errori, ma comporta costi aggiuntivi Linguaggio libero: termini estratti liberamente dal testo del documento e non definiti a priori Come sono fatti i termini del linguaggio … Termini singoli (es. “recupero”, “informazione”, “sistema”…) Termini in contesto: composti da diverse parole (es. “sistemi di recupero dell’informazione”)
 Come sono scelte le parole del linguaggio di indicizzazione Linguaggio controllato: limitato ad un vocabolario predefinito. identificazione manuale dei termini significativi. introduce meno errori, ma comporta costi aggiuntivi. Linguaggio libero: termini estratti liberamente dal testo del documento e non definiti a priori. Come sono fatti i termini del linguaggio … Termini singoli (es. recupero , informazione , sistema …) Termini in contesto: composti da diverse parole (es. sistemi di recupero dell’informazione )")
49
Gli strumenti per l’indicizzazione
Vocabolari controllati Anelli di sinonimi Termini preferiti (Authority file) Tassonomie e schemi organizzativi (gerarchie tra termini di un vocabolario) Thesauri: Vocabolari controllati con relazioni tra termini
 Tassonomie e schemi organizzativi (gerarchie tra termini di un vocabolario) Thesauri: Vocabolari controllati con relazioni tra termini.")
50
Vocabolari controllati
Nella sua forma più semplice un vocabolario controllato è un sottoinsieme di un linguaggio che rappresenta un sapere specialistico, per esempio un elenco (indice) dei termini specifici di una disciplina (arte, medicina, economia, ecc. ) Un vocabolario controllato di questo tipo può essere: deciso da uno o più esperti costruito automaticamente scartando dai testi del settore le parole cosiddette “non-stop” (articoli, preposizioni, pronomi, ecc.)
 dei termini specifici di una disciplina (arte, medicina, economia, ecc. ) Un vocabolario controllato di questo tipo può essere: deciso da uno o più esperti. costruito automaticamente scartando dai testi del settore le parole cosiddette non-stop (articoli, preposizioni, pronomi, ecc.)")
51
Vocabolari controllati:anelli di sinonimi
Un primo arricchimento del vocabolario controllato è costituito dalla introduzione dei sinonimi, o meglio di termini considerati equivalenti secondo certi criteri, nella stessa lingua o in lingue diverse, comprendendo anche errori ortografici comuni. Poiché nessuno dei termini equivalenti è considerato preferito, si parla di anelli di sinonimi Pro e contro: maggiore quantità di risultati (richiamo o recall), minore rilevanza (precisione o precision).
, minore rilevanza (precisione o precision).")
52
Vocabolari controllati: schemi di classificazione
Un vocabolario controllato diventa uno schema di classificazione, (schema organizzativo) o tassonomia, quando i termini vengono organizzati in una gerarchia. Uno schema di classificazione svolge un triplice ruolo: per l’architetto dell’informazione, come strumento di organizzazione e etichettatura dei documenti per l’utente, come ausilio alla navigazione (se, come in Yahoo!, è resa visibile come parte integrante dell’interfaccia) home>science>computer science>artificial-intelligence per l’utente, nella ricerca, quando gli vengono mostrate le categorie in cui è stato trovato il termine dell’interrogazione shopping>animali>cani familiarizzandolo con lo schema di classificazione del sistema Una tassonomia dovrebbe essere semplice, facile da ricordare e facile da usare.
 o tassonomia, quando i termini vengono organizzati in una gerarchia. Uno schema di classificazione svolge un triplice ruolo: per l’architetto dell’informazione, come strumento di organizzazione e etichettatura dei documenti. per l’utente, come ausilio alla navigazione (se, come in Yahoo!, è resa visibile come parte integrante dell’interfaccia) home>science>computer science>artificial-intelligence. per l’utente, nella ricerca, quando gli vengono mostrate le categorie in cui è stato trovato il termine dell’interrogazione. shopping>animali>cani. familiarizzandolo con lo schema di classificazione del sistema. Una tassonomia dovrebbe essere semplice, facile da. ricordare e facile da usare.")
53
Thesaurus Un thesaurus è un insieme di termini, e di relazioni fra di essi, che costituiscono il lessico specialistico da usare per descrivere il contenuto dei documenti pubblicati in un ambito disciplinare. Il thesaurus ha quindi un ruolo analogo a quello di un vocabolario di una lingua con la differenza che per i termini, oltre alla eventuale definizione, vengono indicate le relazioni che esistono fra di essi. Le relazioni possono essere di tre tipi: preferenza gerarchia affinità semantica Un thesaurus è un insieme di termini, e di relazioni tra di essi, che costituiscono il lessico specialistico da usare per descrivere il contenuto dei documenti pubblicati in un certo ambito disciplinare Il thesaurus è necessario per i linguaggi di indicizzazione controllati È un vocabolario di un linguaggio di indicizzazione controllato in maniera formalizzata in modo che le relazioni a priori tra i concetti sono rese esplicite La caratteristica principale di un tesauro è la sua capacità di facilitare nella ricerca dei termini per mezzo di categorie generali

54
Thesaurus: tipi di relazioni
Le relazioni di preferenza si usano per rimandi da termini non accettati a termini accettati e viceversa. Esse sono USA o VEDI e USATO PER. Ad esempio: Elaboratore VEDI Calcolatore; Calcolatore USATO PER Elaboratore, Calcolatrice, Stazione di lavoro. Le relazioni di gerarchia mettono in evidenza il rapporto specificità-generalità tra due termini; esse sono: termine più generale (broader term - BT) e termine più specifico (narrower term - NT). Ad esempio: Felini NT Gatti Leoni Tigri; Gatti BT Felini. Un Thesaurus è un vocabolario controllato in cui vengono esplicitate relazioni semantiche fra termini.
 e termine più specifico (narrower term - NT). Ad esempio: Felini NT Gatti Leoni Tigri; Gatti BT Felini. Un Thesaurus è un vocabolario controllato in cui vengono esplicitate relazioni semantiche fra termini.")
55
Thesaurus: tipi di relazioni
Le relazioni di affinità semantica si usano per collegare termini con significato affine o che esprimono concetti correlati; esse sono: termine correlato (related term (RT)) e sinonimi (synonymous term (ST)). Ad esempio, In corrispondenza del termine “geometria” si potrebbe trovare: BT matematica, NT geometria piana, geometria solida, geometria analitica, RT algebra lineare Associativa è per esempio la relazione di contestualità fra termini, come “forchetta” e “coltello”, “autostrada” e “casello”, “Waterloo” e “Napoleone”.
) e sinonimi (synonymous term (ST)). Ad esempio, In corrispondenza del termine geometria si potrebbe trovare: BT matematica, NT geometria piana, geometria solida, geometria analitica, RT algebra lineare. Associativa è per esempio la relazione di contestualità fra termini, come forchetta e coltello , autostrada e casello , Waterloo e Napoleone .")
56
Esempio

57
Processo di indicizzazione
Manuale: è una persona che sceglie quali termini meglio caratterizzano il contenuto di un documento Più “semantico” e quindi migliore Soggettivo, costoso Linguaggio controllato Automatico: fatto da un programma Più sintattico, su base statistica e quindi “peggiore” Economico, scalabile Linguaggio libero

58
Qualità dell’indicizzazione
Finalità: rappresentare il contenuto semantico di un documento con due obbiettivi: Esaustività: assegnare un grande numero di termini indice Specificità: il grado di specificità del linguaggio utilizzato termini generici: non sono adatti a distinguere i documenti rilevanti da quelli irrilevanti termini specifici: permettono di reperire pochi documenti, ma la maggior parte di questi è rilevante Modalità: estrazione diretta dal documento intero (full text) o mediante l’utilizzo di fonti esterne (es: dizionari controllati) tecniche associative (tesauri, pseudo-tesauri, clustering)
 o mediante l’utilizzo di fonti esterne (es: dizionari controllati) tecniche associative (tesauri, pseudo-tesauri, clustering)")
59
INDICIZZAZIONE MANUALE
L’indicizzazione manuale può essere fatta usando parole estratte dal testo o termini controllati, o descrittori, estratti da un thesaurus preesistente. In generale viene utilizzato un linguaggio controllato; questa scelta presenta diversi vantaggi: Semplificazione del processo di indicizzazione Indipendenza, o minor dipendenza, dal soggetto che effettua l’indicizzazione Semplificazione dell’ uso da parte degli utenti ( se conoscono il linguaggio di indicizzazione)
")
60
INDICIZZAZIONE MANUALE
VANTAGGI E SVANTAGGI Vantaggio: permette una rappresentazione indiretta del contenuto dei documenti con termini che evidenziano i concetti in essi trattati, Svantaggio: può portare a rappresentazioni non accurate né consistenti se non è fatta da persone con una buona conoscenza dell’argomento trattato nel documento. Una rappresentazione è accurata quando viene fatta usando un numero adeguato di termini; contrariamente si pregiudica il richiamo del sistema. Una rappresentazione è consistente se documenti che trattano lo stesso argomento vengono rappresentati, anche da persone diverse, con gli stessi termini; contrariamente si pregiudica la precisione del sistema. In generale, comunque, con l’indicizzazione manuale è difficile garantire rappresentazioni accurate e consistenti.

61
INDICIZZAZIONE AUTOMATICA
L’indicizzazione automatica (automatic indexing) di un documento testuale è il processo che esamina automaticamente gli oggetti informativi che compongono il documento e, utilizzando degli algoritmi appositi, produce una lista di termini indici (index terms). Questa lista può essere utilizzata per una rappresentazione più compatta del contenuto informativo del documento di partenza. Tipicamente: indicizzazione full-text. L’uso del thesaurus è previsto anche per l’indicizzazione automatica per sostituire termini estratti automaticamente con termini più specifici o più generali.
 di un documento testuale è il processo che esamina automaticamente gli oggetti informativi che compongono il documento e, utilizzando degli algoritmi appositi, produce una lista di termini indici (index terms). Questa lista può essere utilizzata per una rappresentazione più compatta del contenuto informativo del documento di partenza. Tipicamente: indicizzazione full-text. L’uso del thesaurus è previsto anche per l’indicizzazione automatica per sostituire termini estratti automaticamente con termini più specifici o più generali.")
62
Schema del processo di indicizzazione automatica di documenti testuali

63
INDICIZZAZIONE AUTOMATICA
L’indicizzazione automatica si basa su tecniche statistiche, partendo dal presupposto che la frequenza di occorrenza delle parole in un testo in linguaggio naturale sia correlata con l’importanza di queste parole nel rappresentare il suo contenuto. Se invece che un singolo documento si considera una raccolta di documenti, per stabilire quali parole chiave scegliere nell’indicizzazione, si tiene conto anche di come esse siano distribuite nella raccolta: se una parola appare con una frequenza alta in tutti i documenti, allora diminuisce la sua importanza. Si pensi alla parola “calcolatore” in una raccolta di testi di informatica.

64
Considerazioni sulla frequenza dei termini
Termini funzionali avverbi, articoli, preposizioni ecc. es., "and", "or", "of", "but", … la frequenza di questi termini è alta in tutti i documenti le parole in assoluto più frequenti sono anche poco significative le 250 parole più comuni coprono in media il % di un testo Quello che conta non è la frequenza assoluta ma la frequenza relativa Termini indicatori del contenuto parole che identificano i contenuti del documento hanno frequenza variabile da un documento all’altro della collezione la loro frequenza è indicativa dell’importanza nel rappresentare il contenuto del documento

65
algoritmo per l’indicizzazione automatica di documenti
I termini che si ottengono dopo l’eliminazione delle parole comuni, la riduzione delle restanti alla radice e l’esclusione dei termini con scarso potere discriminante, sono assegnati ai documenti della raccolta.

66
Analisi lessicale e selezione delle parole
E’ il processo di trasformazione di un flusso di caratteri di input (il testo originario del documento) in un flusso di parole (o tokens ), ovvero in una sequenza di caratteri portatore di uno specifico significato. Nel testo le parole possono essere facilmente identificate grazie alla presenza di spazi, a capo, segni di interruzione, ecc…
 in un flusso di parole (o tokens ), ovvero in una sequenza di caratteri portatore di uno specifico significato. Nel testo le parole possono essere facilmente identificate grazie alla presenza di spazi, a capo, segni di interruzione, ecc…")
68
Il procedimento inizia con l’analisi delle parole che costituiscono i documenti per eliminare quelle più comuni contenute nella lista di esclusione (preposizioni, articoli, congiunzioni, avverbi ecc.) Ad esempio una lista di esclusione per testi in lingua italiana contiene parole tipo: a, abbastanza, ad, adesso, agli, al, alla, …, che, chi, ce, ci, ciò, cioè, …. Da esperimenti fatti su testi in lingua italiana risulta che circa il 50% delle parole usate sono particelle e quindi eliminandole si riduce mediamente la lunghezza di un testo alla metà.

69
Esempio Eliminazione delle parole comuni
Stralcio di una lista di esclusione per la lingua inglese: A ALMOST AMONGST ANYWHERE ABOUT ALONE AN ARE ACROSS ALONG AND AROUND AFTER ALREADY ANOTHER AS AFTERWORDS ALSO ANY AT AGAIN ALTHOUGH ANYHOW BE AGAINST ALWAYS ANYONE BECAME ALL AMONG ANYTHING BECAUSE Per la lingua inglese è stata preparata nel tempo una lista di circa 250 parole che sono considerate da tutti stop- words.

70
Si eliminano i suffissi delle parole riducendole alla radice per prescindere dalle diverse forme verbali di un verbo, dal singolare o plurale, ecc. I problemi che si presentano dipendono dalla lingua usata nei documenti. Ad esempio per la lingua italiana i suffissi “are”, “ere”, “ire” devono essere eliminati dall’infinito di un verbo, ma non dalle parole “casolare” o “giardiniere” da cui bisogna togliere rispettivamente “e” e “iere”. La scelta di rappresentare i documenti con solo le radici delle parole significative in essi contenute ha lo scopo di ridurre il numero di termini assegnati alla raccolta e di aumentare il richiamo, poiché più parole hanno la stessa radice.

71
Esempio Riduzione delle parole alla radice
Si utilizzano liste di suffissi: Es. calcol[are] calcol[atore] calcol[atrice] calcol[abilità] calcol[o]

75
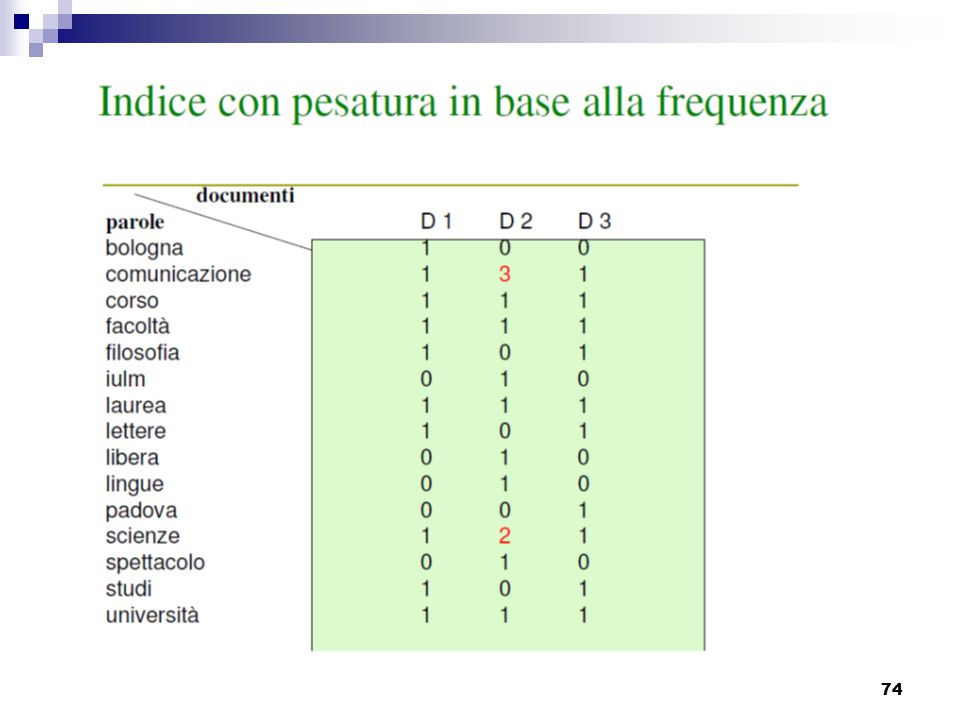
Termini pesati L’efficacia dell’indicizzazione aumenta se ai termini che caratterizzano un documento si assegna un peso che rifletta l’importanza del termine per il documento. Se n sono i termini usati per l’indicizzazione, il documento D della raccolta viene rappresentato dal vettore D = (T1, …, Tn), dove ogni Ti è il peso del termine nel documento. Una raccolta di documenti si riduce cosi ad una matrice di termini con tante righe quanto sono i documenti e tante colonne quanti sono i termini usati per l’indicizzazione. i termini con peso alto vengono assegnati al documento
, dove ogni Ti è il peso del termine nel documento. Una raccolta di documenti si riduce cosi ad una matrice di termini con tante righe quanto sono i documenti e tante colonne quanti sono i termini usati per l’indicizzazione. i termini con peso alto vengono assegnati al documento.")
76
Termini pesati Fra le funzioni proposte per il calcolo del peso di un termine la più usata tiene conto sia della sua rappresentatività considerando la frequenza di occorrenza in un documento sia della capacità del termine di discriminare un documento dagli altri Se ad es il linguaggio di indicizzazione è: {Arbusto, Architettura, botanica, coltivazione, colonna, pianta, Rinascimento, Roma, ....}, il vettore rappresenta un documento in cui ‘arbusto’ ha peso 0, ‘architettura’ ha peso 4, ‘botanica’ ha peso 0,

77
Termini pesati I pesi w possono essere binari o valori reali o interi
positivi: sono calcolati in fase di indicizzazione

78
Indicizzazione automatica: un algoritmo

79
Indicizzazione automatica: i problemi
Identificare le soglie di frequenza minima e massima eliminare i termini molto frequenti abbassa il Richiamo eliminare i termini poco frequenti abbassa la Precisione Un buon termine indice: deve rendere reperibile il documento (Richiamo) deve essere in grado di distinguere il documento all’ interno dell’ intera collezione (Precisione) non può essere un termine presente in tutti i documenti è molto frequente in alcuni documenti (ipotesi del minimo sforzo) non è molto frequente nell’ intera collezione di documenti
 deve essere in grado di distinguere il documento all’ interno dell’ intera collezione (Precisione) non può essere un termine presente in tutti i documenti. è molto frequente in alcuni documenti (ipotesi del minimo sforzo) non è molto frequente nell’ intera collezione di documenti.")
80
OSSERVAZIONI Sono stati effettuati numerosi esperimenti per valutare le prestazioni dei sistemi che adottano l’indicizzazione automatica. Esperimenti eseguiti su piccole collezioni (meno di documenti) hanno mostrato che non sempre l’indicizzazione manuale porta a risultati migliori dell’indicizzazione automatica, totale o incompleta. L’approccio manuale, anche se qualitativamente superiore, non è scalabile In certi domini (es. Web) l’indicizzazione automatica è l’unica possibile
 hanno mostrato che non sempre l’indicizzazione manuale porta a risultati migliori dell’indicizzazione automatica, totale o incompleta. L’approccio manuale, anche se qualitativamente superiore, non è scalabile. In certi domini (es. Web) l’indicizzazione automatica è l’unica possibile.")
Presentazioni simili






>")















