Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Il pretrattamento La fase di pretrattamento nel DM è pesante e delicata Oltre ai problemi connessi con i valori mancanti e alla mancanza di alcune informazioni rilevanti ce ne possono essere altre ridondanti o inutili. Inoltre, nei dati ci sono spesso rumore ed errori In questa fase occorre correggere le inaccuratezze, eliminare le anomalie ed eliminare i record duplicati Occorre riempire i buchi e controllare la coerenza Si tratta di tutte le operazioni necessarie affinché i dati originali siano organizzati in modo da essere sottoposti alle opportune procedure di DM

2
Feature selection E’ molto importante la scelta delle caratteristiche da analizzare, ma il problema è più delicato di quello normalmente richiesto nella specificazione di un modello di regressione classico I 2 problemi principali di fronte ad una base di dati enorme sono: 1.masking variables l’inclusione di variabili irrilevanti può rendere difficile e fuorviare la ricerca di strutture 2.il numero e la rilevanza delle variabili rischio della “maledizione della multidimensionalità (“gli spazi multidimensionali sono tutti vuoti”), ma naturalmente occorre includere tutte le variabili interessanti. Informzio a priori (se disponibile) dovrebbe essere utilizzata per effettuare la corretta selezione. Procedure data driven, quali le tecniche statistiche di riduzione della dimensionalità (ACP) possono risultare utili
 dovrebbe essere utilizzata per effettuare la corretta selezione. Procedure data driven, quali le tecniche statistiche di riduzione della dimensionalità (ACP) possono risultare utili.")
3
Tipiche applicazioni di DM Individuazioni di transazioni fraudolente Approvazione di mutui Analisi di investimenti Costituzione di portafogli finanziari Analisi di mercato Analisi di processi produttivi Analisi di dati scientifici Analisi dei percorsi su Web

4
Strategie di Mining: SEMMA Un possibile approccio al Mining, proposto dal Sas Enterpise Miner, è la cosiddetta strategia SEMMA: Sample Explore Modify Model Assess

5
S Sample: Campionare sufficientemente grande sufficientemente piccolarapidamente Si tratta di una fase facoltativa: si estrae un campione di record dalla base di dati, sufficientemente grande da consevare l’informazione rilevante, ma sufficientemente piccola da essere trattata rapidamente, elemento rilevante nelle decisioni aziendali casuale La strategia di campionamento proposta da SAS Enterprise Miner è una procedura casuale Il rischio è quello di perdere informazioni delicate, che non riescono ad emergere in una indagine su campione. alternativepartizioni campione di apprendimentocampione di convalida campione di verifica Vengono proposte alternative basate sul ricorso a partizioni della base di dati, così da disporre di un campione di apprendimento, per identificare il modello, di un campione di convalida, per assestarlo ed evitare i rischi di overfitting e di un campione di verifica, per ottenere una valutazione onesta della capacità di generalizzazione del modello

6
E E xplore - Esplorare Esplorare significa cercare nei dati andamenti inattesi, anomalie così da iniziare a comprendere ed qcquisire nuove idee. Esplorare aiuta a rifinire il processo di scoperta. Le rappresentzioni grafiche possono rivelare andamenti e regolarità. Se non bastano le teciche statistiche descrittive elemntari possono essere necessarie trasformazioni e tecniche di riduzione di dimensionalità, quali i metodi fattoriali, l’analisi delle corrispondenze, quelle di clustering Queste ultime tecniche possono essere particolarmente interessanti nelle ricerche di mercato, poiché consentono di identificare segmanti di mercato, con diversi sistemi di preferenze, cui rivolgere, ad esempio, specifiche campagne promozionali

7
M M odify - Modificare Modificare vuol dire creare, selezionare e trasformare le variabili, con l’obiettivo di aiutare il processo di formulazione di un modello Le trasformazioni sono indotte dai risultati della fase di esplorazione: può essere importante includere relazioni di gruppo, oppure introdurre nuove variabili, non considerate nelle prime fasi Può risultare necessario tener conto della presenza di valori anomali, ad esempio introducendo trasformazioni In questa fase appare paticolarmente rilevante la componente dinamica, interattiva e iterativa del processo di DM Questo vuole dire che le fasi non sono necessariamente sequenziali. Modificare può essere necessario anche dopo la fase di modellazione, ad esempio

8
M M odel - Modellare Si tratta di procedure automatiche di ricerca per identificare combinazioni di dati che riescano a predire in maniera affidabile il risultato desiderato Le tecniche di modellazione all’interno del DM include reti neurali, modelli ad albero, modelli logistici e altri tipi di modelli – quali analisi delle serie storiche, analisi in componenti principali, … Ogni tipo di modello ha punti di forza e possono essere appropriati alle diverse situazioni di DM e ai diversi obiettivi Ad esempio le reti neurali sono particolarmente adatte in situazioni in cui esistono relazione non lineari molto complesse

9
A A ssess - Valutare Valutare l’utilità e l’affidabilità dei risultati del processo di DM e stimare quanto bene funziona è un momento importante Uno strumento classico per valutare un modello è quello di applicarlo ad una parte dei dati su cui non è stato stimato Se il modello è valido e funziona bene sul campione di apprendimento, dovrà funzionare anche su quello di convalida Allo stesso modo il modello può essere verificato su risultati noti. Ad esempio, se si sa che i clienti presenti in un archivio di dati hanno degli alti tassi di fidelizzazione e il modello identificato predice fedeltà, allora si può provare sui clienti di cui si conosce il comportamento, se il modello la predice correttamente Ancora, applicazioni pratiche del modello, come ad esempio invii parziali in una campagna di contatti postali diretti, aiuta a provare la validità del modello

10
I compiti del DM1 I compiti del DM son generalmente divisi in 2 grandi categorie: 1.DM descrittivo 1.DM descrittivo che produce sintesi dei dati ed identificano proprietà interessanti 2.DM predittivo 2.DM predittivo che costruisce uno o un insieme di modelli, fa inferenza sull’insieme di dati disponibili e cerca di predire il comportamento di nuovi insiemi di dati

11
Descrizione di classi Descrizione di classi: produce sintesi dell’insieme di dati, calcolando statistiche di base Può servire, ad esempio, per confrontare le caratteristiche delle vendite di un’azienda sul mercato interno e su quello estero Associazioni Associazioni: si tratta dell’identificazione di relazioni di associazione e correlazione all’interno dei dati. Sono spesso espresse in termini di regole che mostrano condizioni attributo-valore che si osservano frequentemente insieme in un dato insieme di dati. Si tratta di tecniche largamente utilizzate nell’analisi di transazioni nel direct marketing, nella costruzione di cataloghi o in altre situazioni aziendali, come strumento di supporto alle decisioni I compiti del DM2

12
Ancora sulle associazioni Una regola di associazione ha la tipica forma X Y e va letta: “tuple del database che soddisfano X probabilmente soddisfano Y” tupla dove per tupla si intende una riga di una matrice bidimensionale delle relazioni di un database relazionale. Rappresenta l'entità base che deve essere memorizzata nel database. Più tabelle di un database possono, ad esempio, essere messe in relazione definendo i campi che, se contengono valori uguali nelle due tabelle, generano un corrispondente blocco di tuple, formato dall'unione dei dati delle due tabelle In questo ambito si sono avuti molti degli sviluppi metodologici più interessanti nell’ambito del DM

13
I compiti del DM3 Classificazione Classificazione: si analizza un campione di addestramento (inteso come un insieme di oggetti di cui si conosce l’etichettatura) e si costruisce un modello per ciascuna classe, sulla base delle caratteristiche dei dati analizzati. Un albero decisionale, o un insieme di regole di classificazione, è generato da questo processo di classificazione e può essere utilizzato per comprendere al meglio le diverse classi presenti nella base di dati e per classificare dati futuri. Ad es. classificare una malattia sulla base dei sintomi manifestati dai pazienti I metodi di classificazione sono stati sviluppati in ambiti differenti: nel machine learning, in statistica, gestione di data base, reti neurali, … Nel DM sono usati per la segmentazione dei mercati, nel business modeling, nell’analisi del credito

14
Predizione Predizione: si tratta di prevedere i valori possibili per dati mancanti, oppure la distribuzione di alcune variabili per dati insiemi di dati. Si tratta di applicare metodi statistici, di solito, per individuare le variabili rilevanti e predire i valori, o le distribuzione, sulla base del comportamento di individui simili Ad es., il salario potenziale di un impiegato può essere predetto sulla base della distribuzione dei salari di impiegati simili, all’interno dell’azienda Fino ad ora, modelli di regressione, modelli lineari generalizzati, analisi della correlazione e alberi di decisione sono stati frequentemente utilizzati, insieme agli algoritmi genetici e le reti neurali I compiti del DM3

15
Analisi dei gruppi: cluster cluster Analisi dei gruppi: si identificano gruppi (cluster) all’interno della massa di dati, intendendo come cluster un sottoinsieme di dati che sono simili fra loro. La similarità può essere calcolata attraverso misure specificate dagli utenti o da esperti. Un buon metodo di clustering produce gruppi di buona qualità, tali da assicurare che la similarità interna a un gruppo sia più bassa e quella fra gruppi più alta Per esempio, si possono raggrupare case in un’area a seconda alla loro categoria, alla dimensione, e alla localizzazione. I metodi fino ad oggi utilizzati nel DM si sono concentrati su metodi specificamente progettati per lavorare con grandi basi di dati e data warehouse multidimensionali I compiti del DM4

16
CLUSTERING (detto anche unsupervised machine learning) classificazione non supervisionata Si tratta della classificazione non supervisionata di osservazioni, in gruppi. Il problema del clustering è presente in innumerevoli contesti e quindi è stato affrontato da ricercatori di diversi discipline. Il suo interesse prevalente è esplorativo Le fasi principali sono: Costruzione della struttura dei dati, eventualmente con selezione o estrazione delle variabili Definizione della misura appropriata al dominio dei dati Raggruppamento Validazione, se necessario Le tecniche del DM1a

17
E’ una fase che risulta spesso utile in un momento esplorativo, ma può portare anche a risultati autonomi Dato un insieme di oggetti, ognuno descritto da un insieme di attributi, il clustering ha l’obiettivo di individuare uno schema di classificazione per raggruppare gli oggetti in un numero di classi tali che gli elementi all’interno di una classe siano simili, rispetto alle caratteristiche considerate, e diversi da quelli delle altre classi. Questo si traduce nella determinazione del nuero delle classi e nella loro descrizione e rappresentazione. Cruciale è la scelta della misura di (dis-)similarità. Questo rappresenta uno dei punti di maggiore interesse per uno statistico I diversi metodi possono essere classificati a seconda dell’informazione a priori necessaria, circa il numero delle classi Le reti neurali non supervisionate (incluse le SOM di Kohonen) hanno rappresentato un notevole sviluppo di queste tecniche Le tecniche del DM1b
similarità. Questo rappresenta uno dei punti di maggiore interesse per uno statistico I diversi metodi possono essere classificati a seconda dell’informazione a priori necessaria, circa il numero delle classi Le reti neurali non supervisionate (incluse le SOM di Kohonen) hanno rappresentato un notevole sviluppo di queste tecniche Le tecniche del DM1b.")
18
Classificazione (detto anche supervised machine learning) Se il numero delle classi e l’appartenenza degli oggetti alle classi è nota per un gran numero di oggetti, allora l’obiettivo della classificazione diventa l’assegnazione di nuovi oggetti alle classi note. Una delle tecniche maggiormente utilizzate è basata sulle reti neurali feed- forward Le tecniche del DM 2

19
Le tecniche del DM 2.1a Rete neurale Neuroni e sinapsi formano la rete neuronale biologica alla base dell’intelligenza umana. Il termine si è però affermato anche per indicare modelli matematici composti di "neuroni" artificiali e, in tal senso, vengono dette “reti neurali artificiali” (neural network, NN) Le reti neurali artificiali sono, quindi, modelli matematici che rappresentano l'interconnessione tra costrutti matematici che in qualche misura imitano le proprietà dei neuroni viventi, cercando di emulare il comportamento del cervello umano Ogni neurone riceve gli ingressi da altri neuroni, ne fa una somma pesata, applica un operatore matematico (lineare o meno) a tale somma e con tale operazione produce la sua uscita, Nel caso delle reti feed-forward i valori di uscita dipendono solamente dagli ingressi attuali e non dalla storia precedente, al contrario delle reti neurali ricorrenti in cui i valori di uscita dipendono anche dalla evoluzione della rete precedente
 Le reti neurali artificiali sono, quindi, modelli matematici che rappresentano l interconnessione tra costrutti matematici che in qualche misura imitano le proprietà dei neuroni viventi, cercando di emulare il comportamento del cervello umano Ogni neurone riceve gli ingressi da altri neuroni, ne fa una somma pesata, applica un operatore matematico (lineare o meno) a tale somma e con tale operazione produce la sua uscita, Nel caso delle reti feed-forward i valori di uscita dipendono solamente dagli ingressi attuali e non dalla storia precedente, al contrario delle reti neurali ricorrenti in cui i valori di uscita dipendono anche dalla evoluzione della rete precedente.")
20
I neuroni delle N sono di solito organizzati a livelli: un primo livello di neuroni (input layer) che riceve le afferenze sensoriali (o vettori di ingresso), uno o più strati nascosti (hidden layer) e uno strato di uscita (output layer). Nella maggior parte dei casi ogni neurone di uno strato riceve gli ingressi da tutti i neuroni dello strato precedente, anche perché ancora non esiste una teoria completa sulle reti non totalmente connesse Le tecniche del DM2.1b X h1h1 h2h2 h3h3 g1g1 g2g2 f input hidden layer output

21
Alberi di decisione

22
Classificazione “naive Bayes” Gli algoritmi di classificazione Naive Bayes (NB), basano le proprie previsioni su probabilità calcolate mediante il teorema di Bayes L’obiettivo è sia predittivo che descrittivo Si analizza la relazione di ciascuna variabile indipendente e della variabile dipendente in termini di probabilità condizionate. Quando si analizza un nuovo caso, si predice combinando gli effetti delle variabili indipendenti sulla variabile dipendente E’ evidente che in teoria dovrebbe funzionare solo quando l’ipotesi si indipendenza dei predittori è soddisfatta (cosa difficilmente assumibile nel DM) Ma in pratica sembra che funzioni bene anche in presenza di violazioni dell’ipotesi di indiendenza
 Ma in pratica sembra che funzioni bene anche in presenza di violazioni dell’ipotesi di indiendenza.")
23
L’algortimo Nella fase di apprendimento, la probabilità di ogni modalità della variabile dipendente è calcolata sulla base delle frequenze nel training set Questa è considerata la probabilità a priori. Accanto alle probabilità a priori si calcola la frequenza, per ogni varaibile indipendente, con cui le sue modalità si associano a ciascuna modalità della variabile dipendente Queste frequenze sono utilizzate per costruire le frequenze condizionate, combinandole con le probabilità a priori (Teorema di Bayes)
.")
24
Esempio di applicazione del teorema di Bayes Conoscenza pregressa un dottore sa che la meningite causa rigidità del collo per il 50% dei casi: P(rigidità del collo|meningite) = ½ La probabilità a priori che un paziente possa avere la meningite è: P(meningite) = 1/50000 = 0,00002 La probabilità incondizionata che un paziente possa avere rigidità del collo è: P(rigidità del collo) = 1/20 = 0,05 Se un paziente ha rigidità del collo, qual è la probabilità che egli abbia la meningite?
 = ½ La probabilità a priori che un paziente possa avere la meningite è: P(meningite) = 1/50000 = 0,00002 La probabilità incondizionata che un paziente possa avere rigidità del collo è: P(rigidità del collo) = 1/20 = 0,05 Se un paziente ha rigidità del collo, qual è la probabilità che egli abbia la meningite")
25
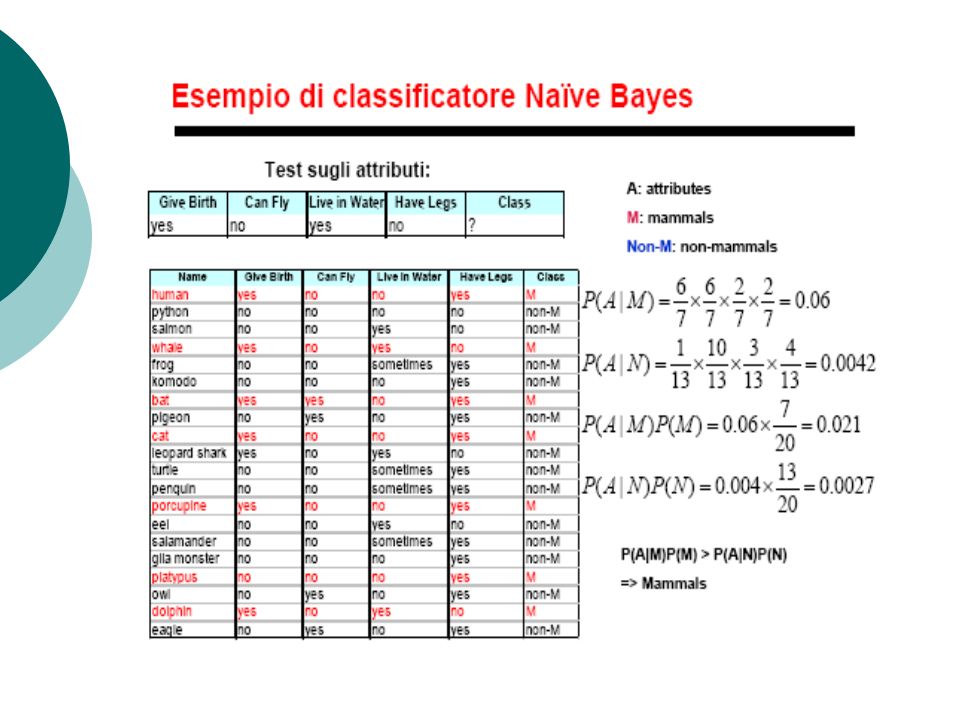
Classificatori Bayesiani Si ragiona in termini di variabili casuali Dato un individuo I m su cui sono state osservate le variabili X 1, X 2, …, X p Lo scopo è predire la classe C di I, trovando il valore che massimizza: P(C | X 1, X 2, …, X p ) Sulla base del teorema di Bayes, si può equivalentemente scegliere il valore di C che massimizza P(X 1, X 2, …, X p | C) P(C)
 Sulla base del teorema di Bayes, si può equivalentemente scegliere il valore di C che massimizza P(X 1, X 2, …, X p | C) P(C)")
26
Assunzione Naïve Assumiamo l’indipendenza tra le variabili X 1, X 2, …, X j, …, X p,(j = 1, …, p), data una certo valore di C, c k P(X 1, X 2, …, X p | c k ) = P(X 1 | c k ) P(X 2 | c k ) … P(X p | c k ) P(X j | c k ) per tutte le coppie X j e c k nel training set, oltre ai vari P(c k ) Un nuovo individuo I l è classificato come c k se risulta massima la produttoria: P(c k ) P(X j | c k ) = P(c k ) P(X 1, X 2, …, X j, …, X p |c k )
, data una certo valore di C, c k P(X 1, X 2, …, X p | c k ) = P(X 1 | c k ) P(X 2 | c k ) … P(X p | c k ) P(X j | c k ) per tutte le coppie X j e c k nel training set, oltre ai vari P(c k ) Un nuovo individuo I l è classificato come c k se risulta massima la produttoria: P(c k ) P(X j | c k ) = P(c k ) P(X 1, X 2, …, X j, …, X p |c k )")
27
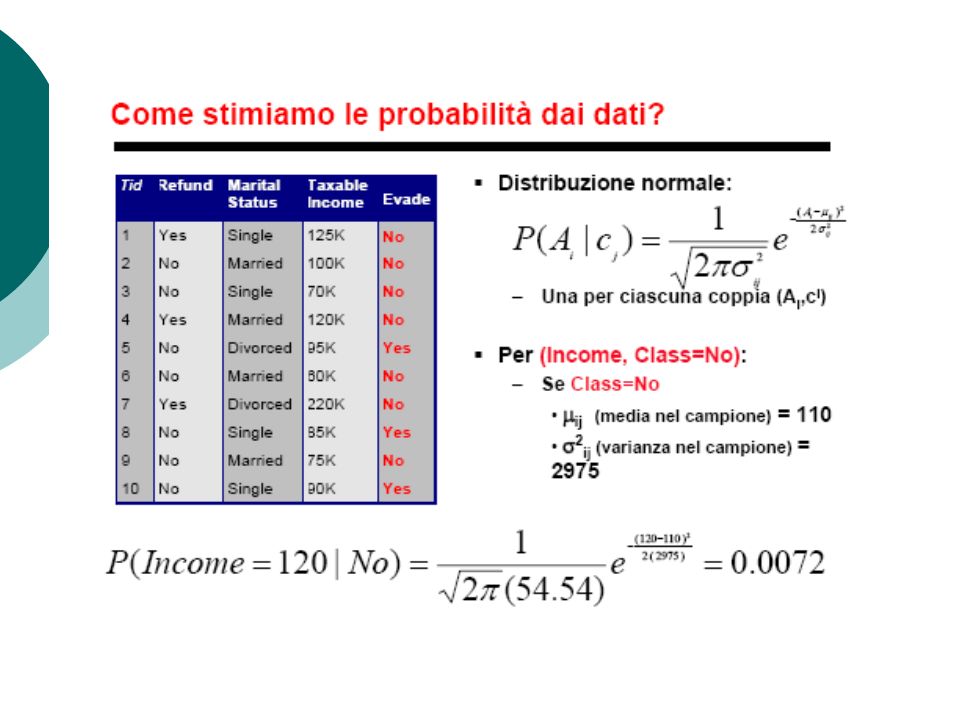
Esempio di classificazione NB Calcolo della frequenza osservata nelle singole classi come stima della probabilità P(c k ) = N k /N dove N k è il numero di individui che appartengono alla classe c k nel training set composto da N individui Es., P(No) = 7/10, P(Yes) = 3/10 Analogamente la probabilità condizionata: P(X 1, X 2, …, X p | C) P(Married | No) = 4/7 P(Refund=Yes | Yes)=0
 = N k /N dove N k è il numero di individui che appartengono alla classe c k nel training set composto da N individui Es., P(No) = 7/10, P(Yes) = 3/10 Analogamente la probabilità condizionata: P(X 1, X 2, …, X p | C) P(Married | No) = 4/7 P(Refund=Yes | Yes)=0")
28
PRO/CONTRO della classificazione Naive-Bayes PRO: L’algoritmo richiede un solo passaggio sul training set per generare il modello di classificazione. Questo lo rende l’algoritmo più efficiente di tutto il DM Robusto rispetto al rumore CONTRO: non tratta variabili continue, che devono essere discretizzate, con i problemi dell’arbitrarietà della costruzione delle classi

Presentazioni simili




 IL CAMPIONE CASUALE SEMPLICE CON RIPETIZIONE>")












>")



