Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Campionamento e Inferenza statistica

2
Popolazione e campione
Una popolazione statistica viene definita dalla variabile oggetto di indagine e viene definito un criterio oggettivo per assegnare o non assegnare un elemento alla popolazione che interessa (es. criterio di inclusione studi clinici) In campo statistico per popolazione si intende una serie di informazioni o dati raccolti per obiettivi conoscitivi (es. reparti ospedali di ASL, tempi di sopravvivenza,...) Molti studi vengono programmati con l’obiettivo di raggiungere conclusioni generali valide per tutta la popolazione, utilizzando i risultati ottenuti da un numero ridotto di osservazioni
 In campo statistico per popolazione si intende una serie di informazioni o dati raccolti per obiettivi conoscitivi (es. reparti ospedali di ASL, tempi di sopravvivenza,...) Molti studi vengono programmati con l’obiettivo di raggiungere conclusioni generali valide per tutta la popolazione, utilizzando i risultati ottenuti da un numero ridotto di osservazioni.")
3
Inferenza Attraverso il metodo statistico probabilistico dell’ Inferenza si formulano ipotesi su una popolazione in base ai dati di un suo sottoinsieme (campione) Le caratteristiche della popolazione (μ,σ) costituiscono i parametri ignoti Gli indici calcolati sul campione rappresentano stime dei parametri della popolazione A B C
 Le caratteristiche della popolazione (μ,σ) costituiscono i parametri ignoti. Gli indici calcolati sul campione rappresentano stime dei parametri della popolazione. A. B. C.")
4
Schema logico operativo di un’indagine statistica campionaria
tecniche campionarie Popolazione campione rilevamento ed elaborazione dati Parametri stime della popolazione campionarie Inferenza statistica

5
Requisiti del campione
Rappresentatività La capacità del campione di riprodurre le caratteristiche essenziali dell’universo al quale appartiene Numerosità L’entità numerica delle unità statistiche che entrano a far parte del campione

6
Rappresentatività del campione
Il campione deve essere affidabile per i risultati ottenuti ovvero deve essere rappresentativo Vengono considerati rappresentativi i campioni selezionati secondo rigorosi criteri casuali Un campione si considera rappresentativo quando probabilisticamente rappresenta l’universo campionario La Statistica consente di definire la numerosità campionaria per garantire la rappresentatività e l’applicabilità delle tecniche inferenziali

7
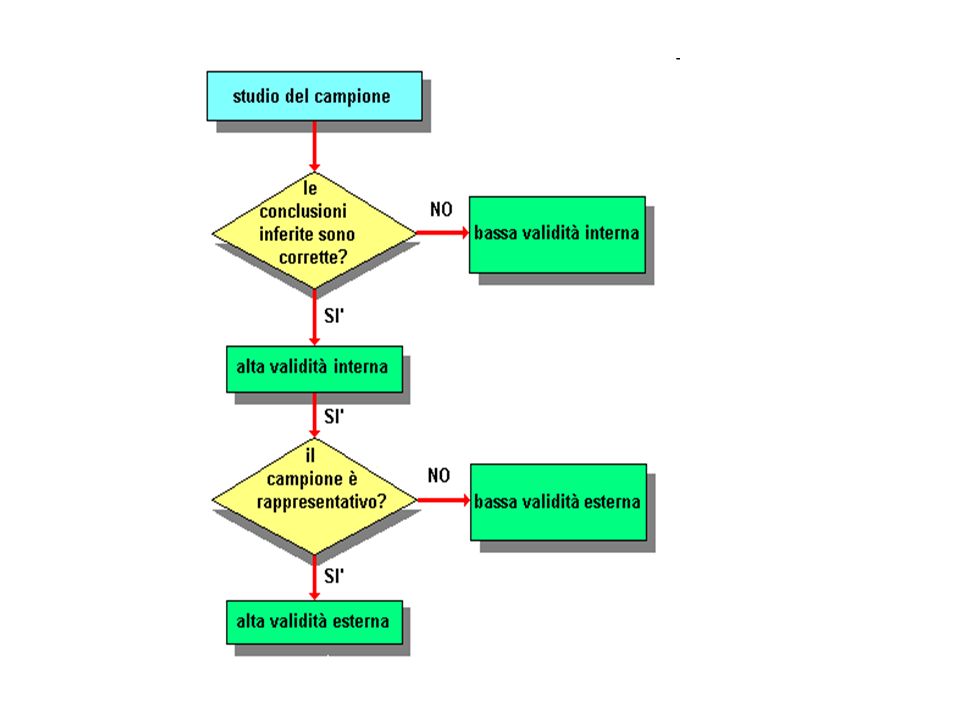
Caratteristiche del campione
Esaminiamo i dati rilevati con il campione ? Le conclusioni sono corrette per le unità campionate Il campione è rappresentativo della popolazione da cui è stato estratto Validità interna Validità esterna

8
Validità interna Misura quanto i risultati di uno studio sono corretti per il campione studiato Negli studi clinici è legata alla correttezza dell’impostazione dello studio stesso, della scelta delle tecniche diagnostiche, da un loro corretto utilizzo, da una buona analisi dei dati …… La validità interna viene compromessa dalla variazione casuale e dai bias La validità interna è una condizione necessaria ma non sufficiente che lo studio sia utile

9
Validità esterna Rappresenta il grado di generalizzabilità delle conclusioni di uno studio. se i risultati di uno studio epidemiologico sono affidabili sono applicabili anche ad altri pazienti con la stessa caratteristica? La validità esterna misura il grado di verità dell’assunto secondo cui gli individui studiati con il campione sono “assimilabili” ad altri pazienti con la stessa condizione patologica

11
Esempio Si vuole conoscere l'età media di un gruppo di 600 persone che frequentano un centro di riabilitazione. Poiché non abbiamo la possibilità di accedere ai documenti di tutti gli ospiti, estraiamo un campione di 6 soggetti gli poniamo la domanda e calcoliamo la loro media. É evidente che, con questo metodo, avremo un valore che si potrà scostare anche di parecchi anni dalla media della popolazione da cui essi provengono (cioè il gruppo di 600). Se intervistiamo altre persone e le aggiungiamo alle prime, la nuova media ottenuta sarà più vicina a quella vera; cioè, l'accuratezza della nostra stima aumenterà con il numero di persone intervistate, però non otterremo una misura perfetta finché non avremo intervistato tutti gli ospiti.
. Se intervistiamo altre persone e le aggiungiamo alle prime, la nuova media ottenuta sarà più vicina a quella vera; cioè, l accuratezza della nostra stima aumenterà con il numero di persone intervistate, però non otterremo una misura perfetta finché non avremo intervistato tutti gli ospiti.")
12
Errore di campionamento
L'errore di campionamento è rappresentato dalla differenza tra i risultati ottenuti dal campione e la vera caratteristica della popolazione che vogliamo stimare. L'errore di campionamento non può mai essere determinato con esattezza, in quanto la "vera" caratteristica della popolazione è (per definizione) ignota. Esso tuttavia può essere contenuto entro limiti più o meno ristretti adottando appropriati metodi di campionamento; inoltre, esso può essere stimato: ciò significa che, con adatti metodi statistici, si possono determinare i limiti probabili della sua entità.
 ignota. Esso tuttavia può essere contenuto entro limiti più o meno ristretti adottando appropriati metodi di campionamento; inoltre, esso può essere stimato: ciò significa che, con adatti metodi statistici, si possono determinare i limiti probabili della sua entità.")
13
Modalità di selezione del campione
non probabilistico scelta di comodo (campionamento per quote o convenience sampling) scelta ragionata (campionamento ragionato o judgmental sampling) probabilistico probabilistic sampling randomizzazione semplice randomizzazione sistematica randomizzazione stratificata
 scelta ragionata (campionamento ragionato o judgmental sampling) probabilistico probabilistic sampling. randomizzazione semplice. randomizzazione sistematica. randomizzazione stratificata.")
14
Campionamento non probabilistico
Non garantisce la equiprobabilità Essendo soggetto da un forte bias può fornire dati poco affidabili e può essere facilmente viziato da errori sistematici In un sondaggio di opinioni all'interno di una piccola azienda con 200 impiegati si vuole studiare la valutazione attribuita alla qualità della mensa. A questo scopo si decide di esaminare un campione composto da 20 persone. Per motivi di convenienza, si intervistano le prime 20 persone che si presentano in sala mensa. Questo criterio é molto pratico, in quanto non bisogna attendere l'arrivo di tutti i dipendenti; tuttavia, si esamineranno impiegati di livello più basso: i dipendenti più impegnati o comunque meno "affamati" non entreranno a far parte del campione. Questo campione, è dunque viziato da un errore sistematico. D'altra parte, l'errore si sarebbe evitato scegliendo una persona ogni fra quelle che varcano la porta d'uscita.

15
Campionamento casuale semplice randomizzazione
Il processo di randomizzazione consiste nell’assegnare ad ogni unità della popolazione una uguale probabilità di essere inclusa nel campione (principio base del campionamento casuale) La selezione si può effettuare per sorteggio, mediante lancio di dadi o monete, utilizzando tabelle di numeri casuali La buona rappresentatività del campionamento casuale fa riferimento alla probabilità elevata di selezionare individui che presentano valori concentrati in corrispondenza della tendenza centrale (distribuzione gaussiana). Minore probabilità è associata all’estrazione di individui con scostamento più elevato dalla media
 La selezione si può effettuare per sorteggio, mediante lancio di dadi o monete, utilizzando tabelle di numeri casuali. La buona rappresentatività del campionamento casuale fa riferimento alla probabilità elevata di selezionare individui che presentano valori concentrati in corrispondenza della tendenza centrale (distribuzione gaussiana). Minore probabilità è associata all’estrazione di individui con scostamento più elevato dalla media.")
16
Procedura di campionamento casuale
Assegnare un numero d’ordine a tutte le unità della popolazione (base di campionamento) Individuazione delle unità campionarie mediante l’uso di tavole di numeri aleatori Da una popolazione N=780 si estrae un campione n=10 Si considerano nella Tavola tante cifre quante quelle di N Si individua il gruppo di altrettante colonne o righe della tavola(verso sinistra, destra, in basso, in alto....) Tutti i numeri di 3 cifre che si incontrano, ≤ a N=780 rispondono al problema: i primi 10 sono il campione richiesto
 Individuazione delle unità. campionarie mediante l’uso di. tavole di numeri aleatori. Da una popolazione N=780. si estrae un campione n=10. Si considerano nella Tavola tante cifre quante quelle di N. Si individua il gruppo di altrettante colonne o righe della tavola(verso sinistra, destra, in basso, in alto....) Tutti i numeri di 3 cifre che si incontrano, ≤ a N=780 rispondono al problema: i primi 10 sono il campione richiesto.")
17
Esempio tavola di numeri casuali
0249 0541 2227 9443 9364 1196 7364 6960 6278 3701 4825 6834 6549 6992 4079 2724 6730 8021 4812 3536 3253 2772 6572 4307 0722

18
Campionamento per randomizzazione sistematica
Nel campionamento per randomizzazione sistematica le n unità che costituiranno il campione sono scelte dalla popolazione ad intervalli regolari ( in un reparto ospedaliero si potrà scegliere un soggetto ogni 4 degenti). Questo metodo è più pratico rispetto alla randomizzazione semplice, ed assicura anche che le singole unità del campione siano distribuite uniformemente all'interno della popolazione. Occorre tuttavia porre attenzione che l'intervallo di campionamento prescelto non sia influenzato da qualche variabile esterna che agisce con la stessa ciclicità del campionamento.
. Questo metodo è più pratico rispetto alla randomizzazione semplice, ed assicura anche che le singole unità del campione siano distribuite uniformemente all interno della popolazione. Occorre tuttavia porre attenzione che l intervallo di campionamento prescelto non sia influenzato da qualche variabile esterna che agisce con la stessa ciclicità del campionamento.")
19
Esempio Si vuole stimare il livello di contaminazione batterica di un reparto di inflaconamento, ed in particolare osservare se esso subisce variazioni nel tempo. Procediamo quindi al prelievo di materiali diversi (tamponi da filtri dell'aria, dai pavimenti, dalle macchine, ecc.) attraverso randomizzazione sistematica effettuata per due settimane in base al giorno della settimana: i prelievi vengono fatti i giorni dispari: lunedì, mercoledì e venerdì. Nel reparto ogni sabato viene effettuata un'operazione di pulizia e disinfezione particolarmente energica. Pertanto, il campione costituito dai «tamponi del lunedì» non è rappresentativo.
 attraverso randomizzazione sistematica effettuata per due settimane in base al giorno della settimana: i prelievi vengono fatti i giorni dispari: lunedì, mercoledì e venerdì. Nel reparto ogni sabato viene effettuata un operazione di pulizia e disinfezione particolarmente energica. Pertanto, il campione costituito dai «tamponi del lunedì» non è rappresentativo.")
20
Errori di campionamento
I fattori responsabili di un errore di campionamento sono -variazione casuale -selezione viziata Casualità Es. due farmaci A e B egualmente efficaci per una certa sintomatologia(guariscono il 50% dei pazienti trattati). Non sono presenti bias(errore sistematico). Se si analizzano i risultati per un numero limitato di pazienti può accadere di osservare che il farmaco A guarisce con maggiore frequenza rispetto al farmaco B(o viceversa) Variazione casuale L’errore di campionamento è condizionato dalla variabilità degli individui della popolazione di riferimento ( tutti uguali = errore campionamento nullo)
. Non sono presenti bias(errore sistematico). Se si analizzano i risultati per un numero limitato di pazienti può accadere di osservare che il farmaco A guarisce con maggiore frequenza rispetto al farmaco B(o viceversa) Variazione casuale. L’errore di campionamento è condizionato dalla variabilità degli individui della. popolazione di riferimento ( tutti uguali = errore campionamento nullo)")
21
Errori di campionamento
Selezione viziata La scelta delle unità campionarie non segue regole rigorosamente casuali Solo quando la scelta delle unità campionarie avviene in modo casuale è possibile prevedere e calcolare l’entità della differenza tra campione e popolazione. In caso contrario il campione è distorto. Un campione distorto tende a fornire risultati che si discostano sistematicamente dai valori veri La selezione viziata è quella che determina un campione non rappresentativo

22
Distorsione da confondimento
La distorsione da confondimento è presente quando una variabile J, in grado di modificare la risposta, ha influito anche nel processo di formazione dei gruppi. La differenza tra i gruppi potrebbe non essere reale ma dovuta alla variabile J che prende il nome di fattore confondente ES:l’età è in grado di modificare la risposta e può intervenire a creare differenza tra i gruppi. -la selezione di 10 cavie tra 50 inserendo una mano nella gabbia sono quelle meno reattive -interviste telefoniche con selezione da elenco categorie non posseggono telefono o non appaiono sull’elenco

23
Campione randomizzato e sperimentazioni cliniche
Occorre prestare attenzione al fatto che anche un campione casuale, particolarmente nella sperimentazioni clinica, non può essere considerato esente da errori: le persone non sono oggetti e la loro variabilità biologica rende il campione intrinsecamente affetto da bias

24
Problemi nella randomizzazione esempio -persi al follow up
Al termine di una ricerca clinica si tende a valutare i soggetti presenti nello studio escludendo i persi al follow up Distorsione da selezione: la perdita di pazienti non si può ritenere indipendente dalle condizioni generali del paziente (effetti collaterali, non efficacia della terapia.....) Il problema è più rilevante nel caso di diversa entità di persi al follow nei due gruppi: -peggior trattamento- molti persi al fw- rimangono pazienti in migliori condizioni -miglior trattamento-pochi persi al fw-rimangono pazienti anche in condizioni peggiori con risposta peggiore autoselezione
 Il problema è più rilevante nel caso di diversa entità di persi al follow nei due gruppi: -peggior trattamento- molti persi al fw- rimangono pazienti in migliori condizioni. -miglior trattamento-pochi persi al fw-rimangono pazienti anche in. condizioni peggiori con risposta peggiore. autoselezione.")
25
Problemi nella validità esterna
I pazienti hanno il diritto di ritirarsi dallo studio I pazienti rimasti sono simili a quelli che si sono ritirati o sono un sottogruppo dell’intera popolazione oggetto di studio? Diverse strategie nell’analisi dei dati Intenzione di trattare il paziente ha abbandonato lo studio per problemi che definiscono un risultato negativo da assegnare al trattamento originario Analizzare i dati come se il paziente non avesse mai preso parte allo studio ( campione troppo piccolo, distorto..) Formare un terzo gruppo e analizzare i dati separatamente (i gruppi originari sono cambiati, cosa rappresenta il terzo gruppo...)
 Formare un terzo gruppo e analizzare i dati separatamente (i gruppi originari sono cambiati, cosa rappresenta il terzo gruppo...)")
26
Il disegno dello studio e la randomizzazione
È finalizzato a rimuovere le distorsioni sistematiche che potrebbero influire sulla risposta Se i gruppi sono simili non può avere agito un meccanismo di distorsione di selezione Non può esistere una variabile in grado di influenzare la risposta rispetto alla quale i gruppi potrebbero essere sbilanciati La randomizzazione è l’allocazione delle unità ai trattamenti in modo rigorosamente casuale

27
Effetti della randomizzazione
Evita la distorsione da selezione -un medico potrebbe decidere di assegnare un paziente non in buone condizioni al trattamento che ritiene più tollerabile Produce un buon equilibrio dei gruppi sperimentali rispetto ai fattori prognostici - la randomizzazione non garantisce che i gruppi abbiano la stesa distribuzione rispetto ai fattori prognostici, ma garantisce con elevata probabilità che non si verifichi uno squilibrio tale da poter addebitare ad esso la diversa efficacia dei trattamenti Fornisce una base logica al test statistico adottato per il confronto finale -se la randomizzazione ha avuto successo, il test statistico sarà conclusivo nel valutare l’efficacia dei due trattamenti. Altrimenti oltre al test del protocollo si dovrebbero utilizzare tecniche statistiche per aggiustare i risultati rispetto a tali fattori di squilibrio

28
Metodi complessi di campionamento
Si utilizzano quando Non è possibile predisporre (per costo o motivi logistici) un listato della popolazione La popolazione è diffusa in un’area molto vasta La popolazione consiste di distinti sottogruppi Condizione essenziale Ogni unità statistica deve avere uguale probabilità di essere estratta
 un listato della popolazione. La popolazione è diffusa in un’area molto vasta. La popolazione consiste di distinti sottogruppi. Condizione essenziale. Ogni unità statistica deve avere uguale probabilità di essere. estratta.")
29
Campionamento stratificato
Un campione stratificato viene utilizzato in determinati casi per aumentare l’efficacia dello schema di campionamento Viene costituito, in base ai requisiti scelti, rispettando i rapporti numerici presenti nella realtà La casualità viene rispettata perché per ogni strato viene seguito il criterio di randomizzazione Per poter fornire stime di ordine inferenziale ogni strato dovrebbe contenere almeno 30 unità

30
Finalità della stratificazione
Per il campionamento e la statistica inferenziale: selezionare un campione che riproduca la struttura della popolazione Avere sottogruppi omogenei di popolazione che consentano stime migliori dei parametri della popolazione Per l’indagine: Individuare insiemi di unità con caratteristiche specifiche: - reparti omogenei di ospedali - pazienti affetti da una data patologia - ricoverati in un reparto in un dato anno - aziende omogenee per numero di addetti

31
Campione stratificato
Si utilizza quando la popolazione è articolata in sottogruppi, o strati, che differiscono rispetto all’oggetto di rilevazione e sono essi stessi di interesse: stratificazione per età, sesso, residenza,ecc. in indagini epidemiologiche Da ogni strato si estrae un sottocampione casuale semplice La numerosità dei sottocampioni (frazione di campionamento) può essere calcolata con 2 diversi principi: - viene estratta la stessa proporzione di individui per ciascun strato; - viene estratta una proporzione di individui in funzione diretta della variabilità dello strato nella popolazione
 può essere calcolata con 2 diversi principi: - viene estratta la stessa proporzione di individui per ciascun. strato; - viene estratta una proporzione di individui in funzione diretta. della variabilità dello strato nella popolazione.")
32
Campionamento stratificato
Se si vuole estrarre un campione stratificato secondo il sesso e l’età - si divide l’intero universo in tanti gruppo di sesso ed età uguali - si estrae (con metodo casuale) all’interno di ciascun gruppo omogeneo la parte di campione che occorre per costituire l’intero campione N1;N2;... Ni, con N1 + N2 + Ni = N Da ogni strato vengono estratte rispettivamente n1;n2;....;ni (n1+ n2 +...ni= n) In caso di campionamento proporzionale la numerosità campionaria è proporzionale alla dimensione dello strato ni = Estrarre un campione di n = 1000 da una popolazione di N = unità divisa in due strati N1= e N2 = n1 = = / x 1000 = 600 (I° strato) e 400(II°strato)
 all’interno di ciascun gruppo. omogeneo la parte di campione che occorre per costituire l’intero. campione. N1;N2;... Ni, con N1 + N2 + Ni = N. Da ogni strato vengono estratte rispettivamente. n1;n2;....;ni (n1+ n2 +...ni= n) In caso di campionamento proporzionale la numerosità campionaria è. proporzionale alla dimensione dello strato. ni = Estrarre un campione di n = 1000 da una popolazione di N = unità divisa in due strati N1= e N2 = n1 = = / x 1000 = 600 (I° strato) e 400(II°strato)")
33
Campione stratificato
È più flessibile di quello eseguito con randomizzazione semplice Nei diversi strati può essere scelta una percentuale differente (es. 10% in uno strato, 5% in un altro, ecc.) Lo svantaggio del campionamento stratificato è rappresentato dalla necessità che prima dei scegliere il campione sia noto lo stato di tutte le unità di campionamento rispetto ai fattori su cui è basata la stratificazione
 Lo svantaggio del campionamento stratificato è rappresentato dalla necessità che. prima dei scegliere il campione sia noto lo stato. di tutte le unità di campionamento rispetto. ai fattori su cui è basata la stratificazione.")
34
Campione stratificato proporzionale
Per ottenere un campione stratificato proporzionale occorre conoscere la parte di popolazione che afferisce ad ogni strato È possibile effettuare la stratificazione solo per quelle variabili di cui si hanno informazioni al momento del campionamento Es. Per accertare l’influenza dell’età sull’incidenza di una patologia si tende ad evitare che il campione sia rappresentato o da soggetti giovani o anziani (campionamento casuale semplice) e si stratifica la popolazione per età e si calcola una frazione costante per ogni strato Problema Per una campagna di prevenzione delle malattie cardiovascolari si vuole conoscere il livello di colesterolemia in una popolazione. Si concorda di eseguire l’indagine solo sui soggetti di sesso maschile di età compresa tra i 45 e i 65 anni (popolazione a rischio più elevato)
 e si stratifica la popolazione per età e si calcola una frazione costante per ogni strato. Problema. Per una campagna di prevenzione delle malattie cardiovascolari si vuole conoscere il livello di colesterolemia in una popolazione. Si concorda di eseguire l’indagine solo sui soggetti di sesso maschile di età compresa tra i 45 e i 65 anni (popolazione a rischio più elevato)")
35
Campione stratificato proporzionale
Si definisce la composizione dei comuni del territorio scelto per lo studio con relativo numero di residenti maschi nati tra il 1935 al 1955 Comune % residenti A B Si decide di campionare 4482 unità corrispondenti all’1% della popolazione composta da soggetti Dal comune A vengono campionati 314 soggetti (7% di 4482); dal Comune B 269 soggetti (6% di 4482) ecc
; dal Comune B 269 soggetti (6% di 4482) ecc")
36
Campionamento a grappolo (cluster)
Volendo estrarre un campione di pazienti fra quelli ricoverati in un anno in diverse strutture sanitarie di una regione si può estrarre un campione casuale delle strutture e poi studiare tutti i pazienti ricoverati in ognuna di quelle estratte I singoli pazienti ricoverati in una particolare struttura vengono campionati o non campionati tutti insieme, a grappolo

37
Campionamento a più stadi
In alcune indagini è preferibile ricorrere a uno schema di campionamento a due stadi Estrarre un campione di nuclei familiari dall’universo delle famiglie italiane Considerare l’universo dei comuni italiani (unità primarie) ed estrarre da esso un campione rappresentativo (primo stadio) Considerare solo le famiglie (unità secondarie) dei comuni sorteggiati ed estrarre un campione da ciascun comune, con o senza stratificazione (secondo stadio) Vantaggio le liste dell’unità di popolazione e la loro numerazione sono richieste solo per gli elementi che appartengono alle unità scelte nel campione Svantaggio minore precisione della stima rispetto a un campionamento casuale semplice della popolazione
 ed estrarre da esso un campione rappresentativo (primo stadio) Considerare solo le famiglie (unità secondarie) dei comuni sorteggiati ed estrarre un campione da ciascun comune, con o senza stratificazione (secondo stadio) Vantaggio le liste dell’unità di popolazione e la loro numerazione sono richieste solo per gli elementi che appartengono alle unità scelte nel campione. Svantaggio minore precisione della stima rispetto a un campionamento casuale semplice della popolazione.")
38
Campionamento a due o più stadi
Estrazione casuale di un certo numero di strutture sanitarie (primo stadio) Estrazione di un campione casuale di pazienti ricoverati in ciascuna di esse (secondo stadio) Es. indagini sulla prevalenza di malattia in una popolazione. Si seleziona un campione casuale di soggetti che si sottopongono a una valutazione preliminare di screening (questionario psichiatrico, rx torace...). Il campione può essere suddiviso in due sottogruppi: positivi e negativi al test Si può decidere di selezionare un campione casuale da entrambi i gruppi per procedere ad un esame più approfondito (campionamento doppio)
 Estrazione di un campione casuale di pazienti ricoverati in ciascuna di esse (secondo stadio) Es. indagini sulla prevalenza di malattia in una popolazione. Si seleziona un campione casuale di soggetti che si sottopongono a una valutazione preliminare di screening (questionario psichiatrico, rx torace...). Il campione può essere suddiviso in due sottogruppi: positivi e negativi al test. Si può decidere di selezionare un campione casuale da entrambi i gruppi per procedere ad un esame più approfondito (campionamento doppio)")
39
Inferenza statistica

40
Inferenza statistica Si chiama inferenza statistica l’insieme delle tecniche che hanno come obiettivo la ricerca del grado di validità di ciò che è stato osservato su uno o più campioni estratti da una popolazione più ampia. Le tecniche permettono di pervenire a certe conclusioni la cui validità per un collettivo più ampio è espressa in termini probabilistici

41
Inferenza statistica La statistica inferenziale offre criteri e metodi che permettono di stabilire con quale probabilità un risultato da indagini campionarie possa essere riferito alla popolazione Nel caso più semplice vengono valutati i parametri della popolazione(μ,σ) attraverso stime campionarie In casi più complessi viene valutata la probabilità che un fenomeno si verifichi casualmente o possa essere imputato a fattori sperimentali (verifica delle ipotesi statistiche)
 attraverso stime campionarie. In casi più complessi viene valutata la probabilità che un fenomeno si verifichi casualmente o possa essere imputato a fattori sperimentali (verifica delle ipotesi statistiche)")
42
Come li risolve l’inferenza?
Teoria campionaria Partendo dalla ipotesi che si conoscano i parametri dell’universo si cercano le regole da soddisfare tali che da un campione di unità estratte dall’universo si possono ottenere parametri campionari simili a quelli ipotizzati per l’universo (problema diretto) Dalle assunzioni dei parametri rilevati in un campione di cui si conosce il procedimento di estrazione, si risale alle corrispondenti stime dei parametri dell’universo da cui il campione è stato estratto (problema inverso) Come li risolve l’inferenza? Stima statistica dei parametri ignoti dell’universo da cui il campione è stato estratto Prova o verifica delle ipotesi statistiche
 Dalle assunzioni dei parametri rilevati in un campione di cui si conosce il procedimento di estrazione, si risale alle corrispondenti stime dei parametri dell’universo da cui il campione è stato estratto (problema inverso) Come li risolve l’inferenza Stima statistica dei parametri ignoti dell’universo da cui il campione è stato estratto. Prova o verifica delle ipotesi statistiche.")
43
Popolazione e campione
originaria (N,μ,σ2) Criterio di estrazione 2°campione (n,m,s) Campione (n,m,s) 1°campione (n,m,s) Al variare del risultato dell’operazione di scelta, varia il campione nell’universo dei campioni
 Criterio di. estrazione. 2°campione. (n,m,s) Campione. (n,m,s) 1°campione. (n,m,s) Al variare del risultato dell’operazione di scelta, varia il campione. nell’universo dei campioni.")
44
Parametri e stime I parametri sono dei valori caratteristici della popolazione la media aritmetica, un indice di variabilità, la probabilità del verificarsi di un evento.... Le stime sono delle funzioni delle osservazioni campionarie e dipendono dagli elementi del campione Media aritmetica del campione, frequenza di un dato evento nel campione,..... L’insieme di tutti i campioni estraibili casualmente da una popolazione è detto spazio campionario. Se la popolazione è finita si parla di universo dei campioni Al variare del campione nell’universo campionario la stima assume valori diversi per cui è possibile costruire la sua distribuzione (distribuzione campionaria)
")
45
Stime e stimatori Per stimare un parametro (media) della popolazione originaria si estrae un solo campione Tutti i possibili campioni sono estraibili e sono quindi possibili ω stime del parametro Si possono costruire distribuzioni di frequenza delle medie campionarie che, in termini probabilistici, costituiscono una variabile casuale descrivibile da un modello discreto o continuo (stimatore) Lo stimatore è una variabile casuale definita nell’universo dei campioni, ovvero, assume valori in ciascun campione di tale insieme La conoscenza delle distribuzioni delle medie campionarie consente di rispondere in termini di probabilità a problemi sull’inferenza delle medie
 Lo stimatore è una variabile casuale definita nell’universo dei campioni, ovvero, assume valori in ciascun campione di tale insieme. La conoscenza delle distribuzioni delle medie campionarie consente di rispondere in termini di probabilità a problemi sull’inferenza delle medie.")
46
Parametro stima e stimatore
Parametro è ogni indice statistico calcolato nella popolazione λ A partire dai dati osservati sul campione è possibile calcolare una stima c di λ c = f(x1,x2,.... x n) Se c è una stima di λ al variare del campione nell’universo dei campioni, la prima , la seconda,....l’ultima osservazione variano e descrivono variabili casuali X1,X2,.... X n simili e indipendenti La stessa funzione f usata per definire la stima, applicata a tali variabili casuali, da luogo a una variabile casuale definita stimatore C = f(X1,X2,.... X n) Lo stimatore è una variabile casuale definita nell’universo dei campioni , quindi assume valori in ciascun campione di tale insieme
 Se c è una stima di λ al variare del campione nell’universo dei campioni, la prima , la seconda,....l’ultima osservazione variano e descrivono variabili casuali X1,X2,.... X n simili e indipendenti. La stessa funzione f usata per definire la stima, applicata a tali variabili casuali, da luogo a una variabile casuale definita stimatore. C = f(X1,X2,.... X n) Lo stimatore è una variabile casuale definita nell’universo dei campioni , quindi assume valori in ciascun campione di tale insieme.")
47
Proprietà dello stimatore
Correttezza. Uno stimatore si dice corretto se la sua media è uguale al valore del parametro. La mancata coincidenza con il valore del parametro è imputabile unicamente al caso (campionamento) e non a un errore sistematico Efficienza. Nella classe degli stimatori corretti dello stesso parametro si definisce efficiente quello che ha la varianza minima Consistenza. Uno stimatore corretto è consistente se n (numerosità campionaria) tende all’infinito e fornisce una stima che coincide con il parametro. Quando si lavora su un campione molto grande la stima (corretta) è con elevata probabilità vicina al valore del parametro
 e non a un errore sistematico. Efficienza. Nella classe degli stimatori corretti dello stesso parametro si definisce efficiente quello che ha la varianza minima. Consistenza. Uno stimatore corretto è consistente se n (numerosità campionaria) tende all’infinito e fornisce una stima che coincide con il parametro. Quando si lavora su un campione molto grande la stima (corretta) è con elevata probabilità vicina al valore del parametro.")
48
Attendibilità delle stime campionarie
Distribuzioni di campionamento (delle medie) n osservazioni estratte casualmente da una popolazione e si reintroducono nella popolazione Si ripeta all’infinito l’estrazione calcolando per ciascun campione n la media Si ottiene un insieme di medie di campioni di grandezza n che poste in una seriazione di frequenza determinano la distribuzione di campionamento delle medie di campioni di dimensione n
 n osservazioni estratte casualmente da una popolazione e si reintroducono nella popolazione. Si ripeta all’infinito l’estrazione calcolando per ciascun campione n la media. Si ottiene un insieme di medie di campioni di grandezza n che poste in una seriazione di frequenza determinano la distribuzione di campionamento delle medie di campioni di dimensione n.")
49
Lo stimatore della media
La media aritmetica calcolata sul campione rappresenta la migliore stima puntuale della media sconosciuta della popolazione Al variare del campione nell’universo dei campioni, la media (calcolata sul campione) varia e descrive una variabile casuale normale con media μ e varianza σ2/n
 varia e descrive una variabile casuale normale con media μ e varianza σ2/n.")
50
Proprietà della distribuzione delle medie di campionamento
La media della distribuzione di campionamento delle medie è uguale alla media della popolazione μ La deviazione standard della distribuzione di campionamento delle medie è σ2/n La forma della distribuzione di campionamento delle medie è approssimativamente normale, indipendentemente dalla forma della distribuzione della popolazione e presupposto che n sia sufficientemente grande

51
Teorema del limite centrale
Se un campionamento viene ripetuto infinite volte (diverse stime della media) per il teorema del limite centrale le medie campionarie si distribuiscono in modo gaussiano, anche quando non lo è la distribuzione delle singole misure Il valore medio dell’insieme di tutte le possibili medie campionarie sarà uguale alla media della popolazione d’origine La deviazione standard dell’insieme di tutte le possibili medie campionarie di campioni di numerosità n, definita errore standard della media, è funzione sia della deviazione standard della popolazione, sia della numerosità del campione
 per il teorema del limite centrale le medie campionarie si distribuiscono in modo gaussiano, anche quando non lo è la distribuzione delle singole misure. Il valore medio dell’insieme di tutte le possibili medie campionarie sarà uguale alla media della popolazione d’origine. La deviazione standard dell’insieme di tutte le possibili medie campionarie di campioni di numerosità n, definita errore standard della media, è funzione sia della deviazione standard della popolazione, sia della numerosità del campione.")
52
Errore standard E’ un indice di dispersione che traduce la variabilità in errore di misura riferito non ai singoli dati ma alla loro media L’errore standard rappresenta l‘incertezza nell’attribuzione alla popolazione del valore medio rilevato nel campione ( la deviazione standard descrive la variabilità della popolazione) n rappresenta la numerosità campionaria che crescendo riduce l’errore nella media
 n rappresenta la numerosità campionaria che crescendo riduce l’errore nella media.")
53
Significato dell’errore standard
La deviazione standard indica quanto ogni unità si discosta dalla media della distribuzione (variabilità della distribuzione) L’errore standard esprime quanto varia ciascuna stima, in media dal valore del parametro (variabilità dei campioni) Valuta empiricamente l’errore accidentale da cui è affetta, in media, ciascuna misura Fornisce una misura teorica dell’errore accidentale medio da cui è affetta ciascuna stima
 L’errore standard esprime quanto varia ciascuna stima, in media dal valore del parametro (variabilità dei campioni) Valuta empiricamente l’errore accidentale da cui è affetta, in media, ciascuna misura. Fornisce una misura teorica dell’errore accidentale medio da cui è affetta ciascuna stima.")
54
La distribuzione di una popolazione di una ASL si distribuisce normalmente secondo la glicemia con μ σ2 =196. Da tale popolazione è stato estratto con ripetizione un campione di 100 individui in cui la stima della glicemia media è risultata pari a 85mg/100ml L’errore standard è 14√100=14. Ogni stima è diversa dal vero valore della glicemia media, in media, 1,4 mg/100ml Ci si può attendere che anche la stima ottenuta nel campione si discosti dal valore del parametro all’incirca di 1,4. Con i 2/3 di probabilità(l’area sottesa alla curva normale standardizzata compresa tra -1 e +1 è pari a ~0,68) il valore della glicemia dell’intera popolazione è compreso nell’intervallo ,4. ci si attende che sia compreso tra 83,6 e 86,4mg/100ml Se il campione fosse stato composto solo da 25 unità il corrispondente ES sarebbe stato 2,8 raddoppiando l’incertezza della stima. Con 400 unità l’incertezza della stima si sarebbe dimezzata
 il valore della glicemia dell’intera popolazione è compreso nell’intervallo 85 1,4. ci si attende che sia compreso tra 83,6 e 86,4mg/100ml. Se il campione fosse stato composto solo da 25 unità il corrispondente ES sarebbe stato 2,8 raddoppiando l’incertezza della stima. Con 400 unità l’incertezza della stima si sarebbe dimezzata.")
55
Stima puntuale e stima per intervallo
Lo stimatore della media è una variabile casuale normale e continua È improbabile che la media calcolata sul campione coincida con la media della popolazione Si costruisce una stima basata su un intervallo che con elevata probabilità comprenda il valore del parametro

56
Intervalli di confidenza
L’intervallo di confidenza (IC) definisce la fiducia probabilistica prescelta nello stabilire entro quali valori sia localizzata la media vera in base alle stime campionarie
 definisce la fiducia probabilistica prescelta nello stabilire entro quali valori sia localizzata la media vera in base alle stime campionarie.")
57
Valori notevoli della distribuzione z
z area compresa area esterna all’intervallo nell’intervallo (- z + z) (code della distribuzione) (-z + z) (≈ 68%) (≈ 32%) (≈ 95%) (≈ 5%) (≈ 99%) (≈ 1%)
 (code della distribuzione) (-z + z) (≈ 68%) (≈ 32%) (≈ 95%) 0.05 (≈ 5%) (≈ 99%) 0.01 (≈ 1%)")
58
Intervallo di confidenza
Metodo per definire l’intervallo di confidenza Stabilire il rischio che si vuole correre nel dichiarare che il parametro cade entro il limite scelto , quando in realtà non è vero Ipotesi: si decide di correre il rischio di sbagliare il 5% delle volte, ovvero, si utilizza un intervallo di fiducia del 95% L’intervallo si ottiene calcolando nelle due direzioni dalla stima puntuale (es. media del campione) un certo numero di volte l’errore standard Per stimare la media dell’universo μ possiamo ottenere un intervallo (usando il livello 95%)
 un certo numero di volte l’errore standard. Per stimare la media dell’universo μ possiamo ottenere un intervallo (usando il livello 95%)")
59
Stima intervallare di una media
La distribuzione delle medie è una gaussiana anche quando non lo è la distribuzione delle misure Si può sfruttare la proprietà della gaussiana standardizzata (z) quindi la media μ di una popolazione sarà compresa : con il 95% di probabilità nell’intervallo con il 99% di probabilità nell’intervallo
 quindi la media μ di una popolazione sarà compresa : con il 95% di probabilità nell’intervallo. con il 99% di probabilità nell’intervallo.")
60
Stima intervallare di una media
Per definire l’intervallo (intervallo di fiducia o di confidenza) si dovrà decidere il rischio che si vuole correre nel dichiarare che il parametro ricade all’interno entro il limite scelto, anche se non è vero. Definire il rischio di sbagliare al 5% viene indicato un intervallo di fiducia del 95% L’intervallo si ottiene calcolando nelle due direzioni della stima puntuale (es. media) un certo numero di volte l’ammontare dell’errore standard in base al livello di fiducia scelto
 si dovrà decidere il rischio che si vuole correre nel dichiarare che il parametro ricade all’interno entro il limite scelto, anche se non è vero. Definire il rischio di sbagliare al 5% viene indicato un intervallo di fiducia del 95% L’intervallo si ottiene calcolando nelle due direzioni della stima puntuale (es. media) un certo numero di volte l’ammontare dell’errore standard in base al livello di fiducia scelto.")
61
Stima intervallare di una media
es. stima della media dell’universo μ ottenendo un intervallo (usando il livello del 95%) Se x =15, σ = 5 e N=100 l’intervallo di fiducia sarà L’intervallo andrà da 14,02 a 15,98 Solo cinque volte su cento mediante questo procedimento otterremo intervalli tali da non includere il parametro Le altre 95 volte le medie del campione saranno abbastanza vicine al parametro da permettere che l’intervallo di fiducia includa il parametro stesso
 Se x =15, σ = 5 e N=100 l’intervallo di fiducia sarà. L’intervallo andrà da 14,02 a 15,98. Solo cinque volte su cento mediante questo procedimento otterremo. intervalli tali da non includere il parametro. Le altre 95 volte le medie del campione saranno abbastanza vicine al. parametro da permettere che l’intervallo di fiducia includa il parametro. stesso.")
62
Calcolo dell’intervallo di confidenza della media di una popolazione
Problema: qual è l’intervallo di confidenza al 95% della media del peso di una popolazione, se in un campione di 100 soggetti la media (x) è pari a 75 kg e la deviazione standard (s) è pari a 12 Kg Dati: x = 75 kg s = 12 kg n = 100 Formula da utilizzare: poiché n è maggiore di 30, si può usare la distribuzione di probabilità z ; IC= 95%, z=1.96 Quindi: IC 95% = x s /
 è pari a 75 kg e la deviazione standard (s) è pari a 12 Kg. Dati: x = 75 kg. s = 12 kg. n = 100. Formula da utilizzare: poiché n è maggiore di 30, si può usare la. distribuzione di probabilità z ; IC= 95%, z=1.96. Quindi: IC 95% = x 1.96 s /")
63
Calcolo dell’intervallo di confidenza della media di una popolazione
I fase: calcolare l’errore standard (deviazione standard della media campionaria) E.S. = s/ = 12/ = 12 /10 = 1,2kg. II fase: calcolo dell’intervallo di confidenza = 77.35 IC95%= x E. S. = = 75 – = 72.65 L’intervallo che va da 72,65 kg.(limite inferiore) a kg. (limite superiore) ha 95 probabilità su 100 di contenere la media vera della popolazione
 E.S. = s/ = 12/ = 12 /10 = 1,2kg. II fase: calcolo dell’intervallo di confidenza = IC95%= x 1.96 E. S. = = 75 – = L’intervallo che va da 72,65 kg.(limite inferiore) a kg. (limite. superiore) ha 95 probabilità su 100 di contenere la media vera della. popolazione.")
64
Calcolo dell’intervallo di confidenza di una proporzione
Per ogni proporzione, p, stimata su un campione di dimensione n, l’ES è dato da Stima della proporzione di bambini che soffrono di asma. Avendo proceduto a un campionamento casuale semplice di 100 bambini si riscontrano 9 casi di asma. La stima richiesta sarà del 9% L’ES stimato è è e l’intervallo di confidenza al 95% (0.03, 0.15) In conclusione diremo che la prevalenza di asma nella popolazione campionata è fra 3% e 15%
 In conclusione diremo che la prevalenza di asma nella popolazione campionata è fra 3% e 15%")
65
Differenze tra medie Anche la differenza tra le medie di due campioni ha un proprio ES La media della popolazione solitamente è sconosciuta: la media di uno dei campioni rappresenta una stima di essa È probabile(95%) che si collochi all’interno dell’intervallo definito da 1,96 volte il suo ES Se il secondo campione proviene dalla stessa popolazione anche la sua media avrà il 95% di probabilità di collocarsi nell’intervallo definito da 1,96 ES dalla media della popolazione Se vogliamo sapere se è verosimile che essi provengano dalla stessa popolazione dobbiamo chiederci se si collocano all’interno di un certo intervallo individuato dai loro ES
 che si collochi all’interno dell’intervallo definito da. 1,96 volte il suo ES. Se il secondo campione proviene dalla stessa popolazione anche la sua media avrà il 95% di probabilità di collocarsi nell’intervallo definito da 1,96 ES dalla media della popolazione. Se vogliamo sapere se è verosimile che essi provengano dalla stessa popolazione dobbiamo chiederci se si collocano all’interno di un certo intervallo individuato dai loro ES.")
66
Intervalli di confidenza per la differenza tra le medie di due campioni
Se σ1 è la ds del campione 1 σ2 è la ds del campione 2 n1 è la numerosità del campione 1 e n2 la numerosità del campione 2 L’ES della differenza tra due medie sarà

67
Pressione arteriosa diastolica media dei tipografi e degli agricoltori
Intervalli di confidenza per la differenza tra le medie di due campioni Si vogliono confrontare la media della press. arteriosa dei tipografi con quella degli agricoltori Pressione arteriosa diastolica media dei tipografi e degli agricoltori numero press. media(mmHg) ds Tipografi ,5 Agricoltori ,2 La differenza tra le medie è mmHg= 9 mmHg Possiamo calcolare l’IC al 95% delle medie 9 – 1,96 x 0,81 mmHg a 9 + 1,96 x 0,81 mmHg da 7,41 mmHg a 10,59 mmHg
 ds. Tipografi ,5. Agricoltori ,2. La differenza tra le medie è mmHg= 9 mmHg. Possiamo calcolare l’IC al 95% delle medie. 9 – 1,96 x 0,81 mmHg a 9 + 1,96 x 0,81 mmHg. da 7,41 mmHg a 10,59 mmHg.")
68
Deviazione standard - Errore standard
La DS mostra la variabilità delle osservazioni individuali, l’ES mostra la variabilità delle medie Mentre la media 1,96 DS stima il range in cui ci si potrebbe aspettare che cadano il 95% delle osservazioni individuali, la media 1,96 ES stima il range in cui ci sarebbe da aspettare che cada il 95% delle medie dei campioni ripetuti(intervallo di riferimento e intervallo di confidenza) Poiché la popolazione è unica ha una sola DS con grandezza che dipende dalla variabilità delle osservazioni. L’ES è una misura della precisione della stima di un parametro della popolazione (media, mediana, DS)
 Poiché la popolazione è unica ha una sola DS con grandezza che dipende dalla variabilità delle osservazioni. L’ES è una misura della precisione della stima di un parametro della popolazione (media, mediana, DS)")
69
Intervallo di confidenza
L’intervallo di confidenza è uno strumento di controllo dell’errore accidentale Interpretazione frequentista Un intervallo di confidenza al 95% significa che, in media, per ogni 100 intervalli che si costruiscono con tale coefficiente, 95 contengono il valore del parametro, mentre 5 non lo contengono

70
Percorso della stima di un parametro

71
Dimensione campionaria nella stima della media
Per stimare la media di una popolazione(μ) attraverso un campione casuale semplice, si assume la media del campione stesso(x) come stima corretta di quella popolazione (la media delle medie di tutti i possibili campioni è uguale alla media della popolazione). Per determinare la dimensione campionaria nel caso di grandi campioni si usa la distribuzione gaussiana (Z) Dove E è l’errore ammesso e σ la DS della variabile esaminata X Nella maggior parte dei casi σ è incognito: si stima attraverso studi precedenti o indagini pilota
 attraverso un campione casuale semplice, si assume la media del campione stesso(x) come stima corretta di quella popolazione (la media delle medie di tutti i possibili campioni è uguale alla media della popolazione). Per determinare la dimensione campionaria nel caso di grandi campioni si usa la distribuzione gaussiana (Z) Dove E è l’errore ammesso e σ la DS della variabile esaminata X. Nella maggior parte dei casi σ è incognito: si stima attraverso studi precedenti o indagini pilota.")
72
Dimensione campionaria nella stima della media
Si vuole determinare la numerosità campionaria minima per condurre un’indagine sui livelli medi di HDL-colesterolo in soggetti di sesso maschile Se si richiede il valore di n affinché il 5% dei campioni superi la μ (media della popolazione) di 5 mg/dl, si assume il valore α=0. 05 (valore di z zα=1,65 che lascia il 5% dell’area alla sua destra). Il valore di σ è di 15 mg/dl, la dimensione di n sarà n =[(1.65 x 15)/5]2=24.5 si può richiedere che il livello di HDL medio della popolazione non si discosti, in più o in meno, di 5 mg/dl da quello ottenuto tramite il campione Questa domanda prevede scostamenti in ambedue le direzioni di μ, per cui un’attendibilità del 95% (z2/α=1.96) il valore di n sarà n= [(1.96 x 15)/5]2= 34,6
 di 5 mg/dl, si assume il valore. α=0. 05 (valore di z zα=1,65 che lascia il 5% dell’area alla sua destra). Il valore di σ è di 15 mg/dl, la dimensione di n sarà. n =[(1.65 x 15)/5]2=24.5. si può richiedere che il livello di HDL medio della popolazione non si discosti, in più o in meno, di 5 mg/dl da quello ottenuto tramite il campione. Questa domanda prevede scostamenti in ambedue le direzioni di μ, per cui un’attendibilità del 95% (z2/α=1.96) il valore di n sarà. n= [(1.96 x 15)/5]2= 34,6.")
73
Dimensione campionaria nella stima di frequenze relative
1.Livello di confidenza desiderato (1-α); 2.l’errore di campionamento permesso (ES = f - p) ovvero la differenza tra il valore di f che risulterà dal campione del campione e il parametro p che si vuole stimare 3.Quando non abbiamo a disposizione una stima precedente della frequenza relativa reale p, dovremmo usare p=0. 5
; 2.l’errore di campionamento permesso (ES = f - p) ovvero la differenza tra il valore di f che risulterà dal campione del campione e il parametro p che si vuole stimare. 3.Quando non abbiamo a disposizione una stima precedente della frequenza relativa reale p, dovremmo usare p=0. 5.")
74
Dimensione campionaria nella stima di frequenze relative
Il responsabile del Servizio farmaceutico di una A.S.L. vuole determinare la numerosità campionaria necessaria per la stima della frequenza relativa di donne utilizzatrici abituali di tranquillanti. Vuole una “confidenza” del 90% entro un intervallo intorno alla proporzione reale Non si hanno informazioni sul valore di p, quindi p=0.5 -per il 90% di confidenza si ha z=zα/2 =1.645; -E=0.04; -p=0.5

75
Dimensione campionaria nella stima di frequenze relative
Si ipotizzi che la Direzione sanitaria di un grande ospedale voglia stimare la frequenza di infezioni ospedaliere tra i pazienti ricoverati Lo studio prevede un grado di accuratezza del 5% (l’errore tollerato):se dalla rilevazione campionaria risultasse una prevalenza del 20% di infezioni, ciò significherà che la percentuale dell’intera popolazione di degenti sarà compresa tra 15 e 25% Il ricercatore fissa a 0.01 la sua probabilità di errore α(si riserva una probabilità su cento di incontrare un campione rappresentativo) Da precedenti studi effettuati in altri ospedali risulta che la prevalenza del fenomeno in studi e di circa il 15% Numerosità campionaria
:se dalla rilevazione campionaria risultasse una prevalenza del 20% di infezioni, ciò significherà che la percentuale dell’intera popolazione di degenti sarà compresa tra 15 e 25% Il ricercatore fissa a 0.01 la sua probabilità di errore α(si riserva una probabilità su cento di incontrare un campione rappresentativo) Da precedenti studi effettuati in altri ospedali risulta che la prevalenza del fenomeno in studi e di circa il 15% Numerosità campionaria.")
Presentazioni simili
 GLI INTERVALLI DI CONFIDENZA>")












>")

>")



