Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Test di porting su architetture SoC F. Pantaleo for T. Boccali

2
Outline Soprattutto tests sulla Nvidia Jetson TK1 Soprattutto tests sulla Nvidia Jetson TK1 – Qualcosa su Odroid XU Nessun real update sul SW degli esperimenti LHC Nessun real update sul SW degli esperimenti LHC – Mostro qualcosa di CHEP – Vero scoglio e’ la (non) acquistabilita’ di ARMv8 a 64 bit Ce ne e’ uno a Princeton, di recente uno al CERN Ce ne e’ uno a Princeton, di recente uno al CERN ROOT5 con ARMv7 non ha mai funzionato fino in fondo, e il ROOT team ha preferito non spendere energie per farlo funzionare ROOT5 con ARMv7 non ha mai funzionato fino in fondo, e il ROOT team ha preferito non spendere energie per farlo funzionare La cosa cambia completamente con ROOT6/ARMv8 … ma ancora non ne ho avuto uno fra le mani La cosa cambia completamente con ROOT6/ARMv8 … ma ancora non ne ho avuto uno fra le mani CMS (not official): funziona tutto al volo CMS (not official): funziona tutto al volo Tanti piccoli test di SW hand-made, reale Tanti piccoli test di SW hand-made, reale – Soprattutto codice teorico e/o generatori MC
 acquistabilita’ di ARMv8 a 64 bit Ce ne e’ uno a Princeton, di recente uno al CERN Ce ne e’ uno a Princeton, di recente uno al CERN ROOT5 con ARMv7 non ha mai funzionato fino in fondo, e il ROOT team ha preferito non spendere energie per farlo funzionare ROOT5 con ARMv7 non ha mai funzionato fino in fondo, e il ROOT team ha preferito non spendere energie per farlo funzionare La cosa cambia completamente con ROOT6/ARMv8 … ma ancora non ne ho avuto uno fra le mani La cosa cambia completamente con ROOT6/ARMv8 … ma ancora non ne ho avuto uno fra le mani CMS (not official): funziona tutto al volo CMS (not official): funziona tutto al volo Tanti piccoli test di SW hand-made, reale Tanti piccoli test di SW hand-made, reale – Soprattutto codice teorico e/o generatori MC")
3
CHEP: CMS: CMS: – http://indico.cern.ch/event/304944/session/8/c ontribution/493/material/slides/0.pdf ARMv8

4
Atom/ARMv8 alla pari come evt/s/thread e scalabilita’

5
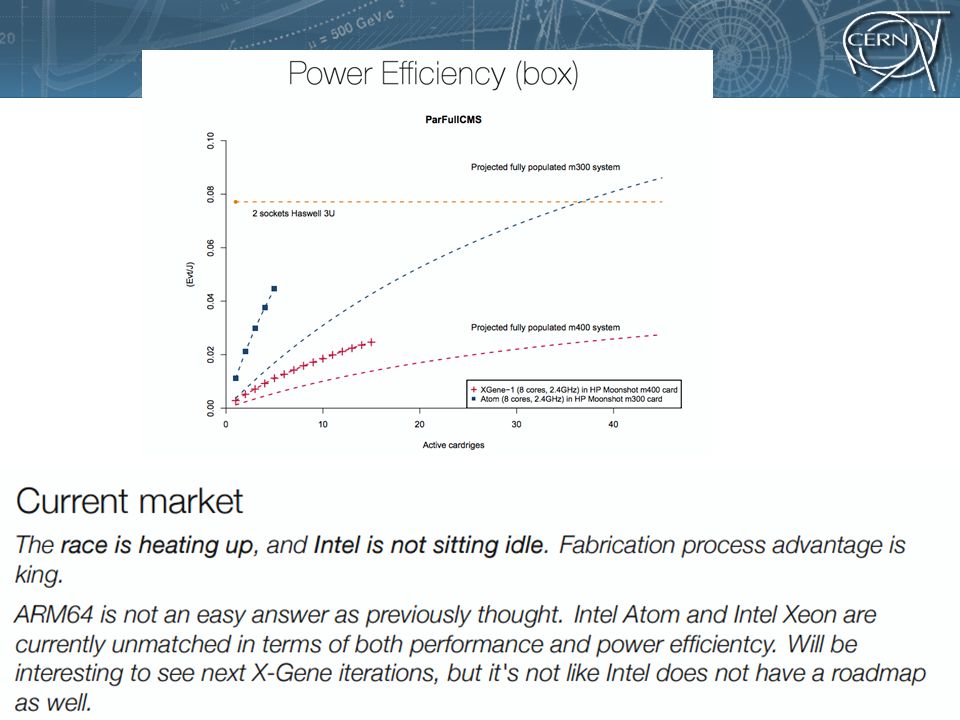
Evt/(s*W) = Evt/(J) = direttamente traducibile in Ev/$ dato il prezzo della corrente Sembrerebbe da questi numeri che Intel abbia piu’ che colmato il gap? Notare pero’ che questo X-gene1 e’ lontano dall’essere ottimizzato

7
NVIDIA Jetson TK1 Noi 2 GB <200 Euro Arriva equipaggiata con Ubuntu 14.04 CUDA kit completo 10-15W max

8
Odroid XU Ubuntu 13.10 2 GB RAM 4-core Cortex A9 5 W

9
Tests eseguiti Codice scalare HEP Codice scalare HEP – Generatori MC, ROOT, Analisi CMS/Higgs Codice Multi threaded teorico Codice Multi threaded teorico – Parallelizzazione codice Passarino Codice CUDA teorico Codice CUDA teorico – Claudio Bonati Intel XEON vs Intel Atom vs Nvidia K1 vs Odroid Intel XEON vs Intel Atom vs Nvidia K1 vs Odroid – Non sempre tutte le combinazioni possibili…

10
PYTHIA Standard test MC05 (500 eventi, pp 14 TeV, Jets e loro caratteristiche) Standard test MC05 (500 eventi, pp 14 TeV, Jets e loro caratteristiche) Suite completa di test (> 20) Suite completa di test (> 20) MacchinaReal Time 05Tutti i testsRatio 05 (X/Intel) Odroid u2 30m22.565s45m0.935s 9 Nvidia K113m41.977s 26m10.149s 2.8 IntelCore i7-2600 CPU @ 3.40GHz 4m32.135s 9m23.435s 1 Marvell ARMADA XP (Dell Copper) 51m1.198s 79m52.159s 8.8
 Standard test MC05 (500 eventi, pp 14 TeV, Jets e loro caratteristiche) Suite completa di test (> 20) Suite completa di test (> 20) MacchinaReal Time 05Tutti i testsRatio 05 (X/Intel) Odroid u2 30m22.565s45m0.935s 9 Nvidia K113m41.977s 26m10.149s 2.8 IntelCore i GHz 4m32.135s 9m23.435s 1 Marvell ARMADA XP (Dell Copper) 51m1.198s 79m52.159s 8.8")
11
ROOT Calcolo dei ROOTMarks Calcolo dei ROOTMarks MacchinaROOTMark s Ratio ROOTMarks (X/Intel) Odroid u2 309 0.14 Nvidia K15830.26 IntelCore i7- 2600 CPU @ 3.40GHz 22141 Marvell ARMADA XP (Dell Copper) 1570.07
 Odroid u Nvidia K IntelCore i GHz Marvell ARMADA XP (Dell Copper)")
12
CMS Analysis test Macro per calcolare fit alla massa dell’Higgs Macro per calcolare fit alla massa dell’Higgs – dati veri dell’analisi H to bb – Macro root compilata – Comprende I/O sequenziale (~ 1 GB di root files) MacchinaZinvHRatio ZinvH(X/Intel) Odroid u2 238 sec 10.8 Nvidia K1110 sec5.0 IntelCore i7- 2600 CPU @ 3.40GHz 22 sec1 Marvell ARMADA XP (Dell Copper) 443 sec20
 MacchinaZinvHRatio ZinvH(X/Intel) Odroid u2 238 sec 10.8 Nvidia K1110 sec5.0 IntelCore i GHz 22 sec1 Marvell ARMADA XP (Dell Copper) 443 sec20")
13
Test di codice teorico Case Study: Higgs Dalitz Decay Case Study: Higgs Dalitz Decay Tesi di laurea di P. Viviani (UniTo): parallelizzazione codice NLO di Passarino Tesi di laurea di P. Viviani (UniTo): parallelizzazione codice NLO di Passarino Integrazione su spazio delle fasi, tempo scalare per integrazione: Integrazione su spazio delle fasi, tempo scalare per integrazione: – O(10 6 ) punti da integrare: mesi su CPU scalare single thread – Codice fortran, non immediatamente riscrivibile in C++
: parallelizzazione codice NLO di Passarino Tesi di laurea di P. Viviani (UniTo): parallelizzazione codice NLO di Passarino Integrazione su spazio delle fasi, tempo scalare per integrazione: Integrazione su spazio delle fasi, tempo scalare per integrazione: – O(10 6 ) punti da integrare: mesi su CPU scalare single thread – Codice fortran, non immediatamente riscrivibile in C++.")
16
Performance Utilizzati: Utilizzati: – 2x Intel Xeon E5-2660 2.2 GHz (16 cores total) – 4x Intel Xeon E7-4820 2 GHz (32 cores total) – Intel Atom SoC C2750 2.4 GHz (8 cores, cluster di 4 nodi = 32 cores) – Una prima nota: il codice scala in modo quasi perfetto, non ci sono lock e/o inter thread communication a parte il reduce finale
 – 4x Intel Xeon E GHz (32 cores total) – Intel Atom SoC C GHz (8 cores, cluster di 4 nodi = 32 cores) – Una prima nota: il codice scala in modo quasi perfetto, non ci sono lock e/o inter thread communication a parte il reduce finale")
17
XEON i5 XEON i7 Scaling ottimale in tutti i casi (HT attivo)
")
18
Nvidia K1 (OpenMP + FastFlow) CPUSeq timeBest parallel time Multi thread scaling Single core wrt i5 I5 2.2 GHz670 sec35.3 sec191 I7 2.0 Ghz1060 sec30.5 sec351.6 Atom 2.4 GHz 1960 sec285 sec6.92.9 Nvidia K11680 sec530 sec3.22.5 Un po’ sorprendente …
 CPUSeq timeBest parallel time Multi thread scaling Single core wrt i5 I5 2.2 GHz670 sec35.3 sec191 I7 2.0 Ghz1060 sec30.5 sec351.6 Atom 2.4 GHz 1960 sec285 sec Nvidia K11680 sec530 sec Un po’ sorprendente …")
21
Come andare oltre? Serve test serio su SW di produzione HEP Serve test serio su SW di produzione HEP – Temo pero’ che serva davvero ARMv8 prima … avete stime? Servirebbe qualcosa di fisica applicata (come da progetto), per esempio Servirebbe qualcosa di fisica applicata (come da progetto), per esempio – Simulazioni di fisica medica ?
, per esempio Servirebbe qualcosa di fisica applicata (come da progetto), per esempio – Simulazioni di fisica medica .")
22
Questions?Questions?

23
BackupBackup

24
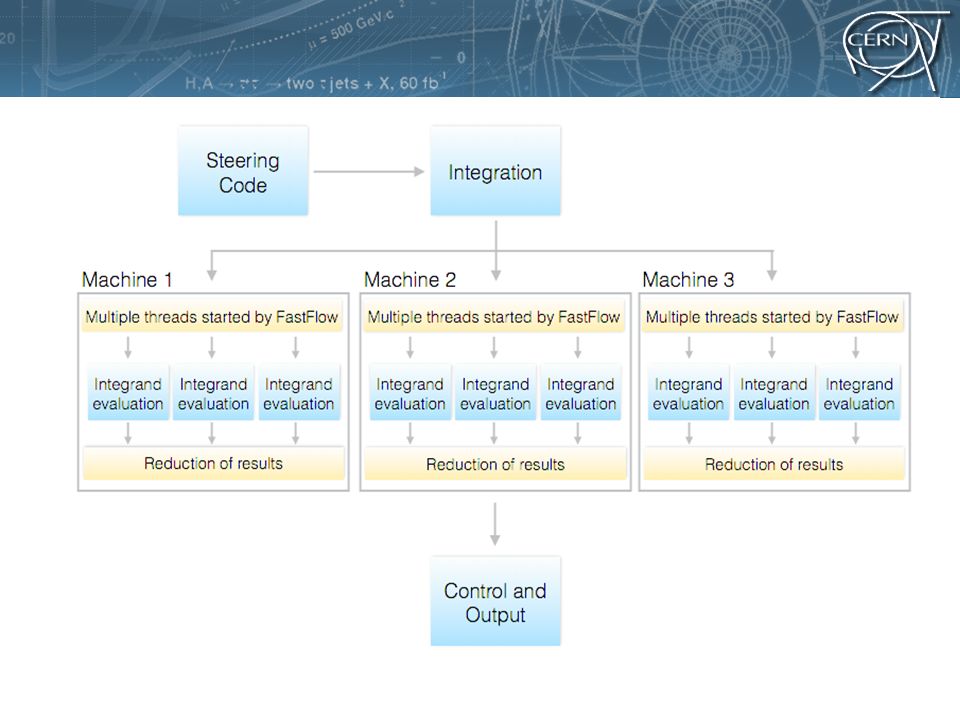
FastFlow UniPi, UniTo (vedere anche: Concurrency Forum Meeting)Concurrency Forum Meeting
Concurrency Forum Meeting")
Presentazioni simili






>")











 e i linguaggi evoluti (alto livello) esiste uno strato di software.>")



 che ci ho capito io Tommaso Boccali – SNS Pisa.>")