Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
L'analisi di varianza Concetti principali: l'analisi di varianza di basa sul calcolo della statistica F. Si mette a confronto la varianza tra i gruppi con la varianza entro i gruppi. dove: k: numero di trattamenti n: numero di soggetti nel gruppo SQtot = SQtra + SQentro.

2
Uno sperimentatore eseguo uno studio per verificare gli effetti della droga sulle abilità psicomotorie. La abilità psicomotorie sono misurate tramite il numero di errori commessi in un test psicomotorio. Maggiore è il punteggio, peggiore è la prestazione psicomotoria. Variabile indipendente: droga vs no droga (2 condizioni sperimentali) Variabile dipendente: abilità psicomotoria scala di misura: numero di errori commessi (scala ad intervallo) disegno: soggetti diversi nelle due condizioni sperimentali Matrice dei dati:
 Variabile dipendente: abilità psicomotoria. scala di misura: numero di errori commessi (scala ad intervallo) disegno: soggetti diversi nelle due condizioni sperimentali. Matrice dei dati:")
3
Somma dei quadrati (SQ):
Formula computazionale della somma dei quadrati Esempio: X = {6, 4, 3, 3, 4}

4
Logica dell'analisi di varianza
Equazione del modello: Scarto delle medie dei trattamenti da m: SQtra :5[(4 – 2,5)2 + (1 – 2,5)2] = 5(4.5) = 2= 22,5 medie: Media totale Scarto dei punteggi dei soggetti dalle medie dei rispettivi gruppi: SQentro :[(6 – 4) (4 – 4)2] + [(0 – 1) (1 – 1)2] = = 10 Varianza totale: SQtot = SQtra + SQentro = 22, = 32,5 SQtot :(6 – 2,5) (4 – 2,5)2 + (0 –2,5) (1 – 2,5)2 = 32,5
2 + (1 – 2,5)2] = 5(4.5) = 2= 22,5. medie: Media totale. Scarto dei punteggi dei soggetti dalle medie dei rispettivi gruppi: SQentro :[(6 – 4) (4 – 4)2] + [(0 – 1) (1 – 1)2] = = 10. Varianza totale: SQtot = SQtra + SQentro = 22, = 32,5. SQtot :(6 – 2,5) (4 – 2,5)2 + (0 –2,5) (1 – 2,5)2 = 32,5.")
5
Componenti della varianza totale: SQtot
Media pop. Punteggi osservati scartitra scartientro = + + Componenti della varianza totale: SQtot SQtra SQentro

6
Calcolo delle medie dei quadrati (MQ)
MQtra = SQtra / (k – 1) MQentro = SQentro / k(n – 1) gdl: N – 1 k – 1 k(n – 1) N: numero totale di soggetti MQtra = 22,5 / (2 – 1) = 22,5 / 1 = 22,5 MQentro = 10 / 2(5 – 1) = 10 / 2(4) = 10 / 8 = 1,25 L'effetto della droga è significativo
 MQentro = SQentro / k(n – 1) gdl: N – 1. k – 1. k(n – 1) N: numero totale di soggetti. MQtra = 22,5 / (2 – 1) = 22,5 / 1 = 22,5. MQentro = 10 / 2(5 – 1) = 10 / 2(4) = 10 / 8 = 1,25. L effetto della droga è significativo.")
7
F1,8 = 18 Fcrit = 5,32

8
Disegni con più di due gruppi e dati su scala a intervallo o a rapporto
Se lo psicologo deve utilizzare più di 2 gruppi di soggetti per la raccolta dati, allora è costretto a usare un test statistico diverso dal t-test. Se, supponiamo, lo psicologo usa tre gruppi di soggetti, indicati con A, B e C, allora qualcuno potrebbe sostenere che si potrebbe fare una serie di t-test per confrontare ciascun gruppo con tutti gli altri. In questo modo si avrebbero 3 t-test per ciascun confronto (A con B, A con C e B con C). La formula generale per calcolare tutti i possibili confronti a coppie è Esempi: 3 gruppi: 14 gruppi:
. La formula generale per calcolare tutti i possibili confronti a coppie è. Esempi: 3 gruppi: 14 gruppi:")
9
Quindi aumentando il numero di gruppi aumenta notevolmente anche il numero di confronti a coppie.
La figura seguente mostra l'incremento del numero di confronti a coppie in relazione al numero di gruppi. Come si vede l'incremento ha andamento esponenziale.

10
In linea di principio è ammissibile effettuare tutti i possibili confronti a coppie, ma esiste il problema dell'errore di gruppo. Per errore di gruppo si intende il fatto che se con un t-test si ha una probabilità pari a 0,05 di commettere un errore del I° tipo (rifiutare l'ipotesi nulla mentre in realtà è vera), se si esegue un unico confronto. Se, invece, si eseguono tanti t-test questa probabilità aumenta. La formula per calcolare l'errore di gruppo è: Cp è il numero di confronti e a è l'errore di I° tipo. Posto a = 0,05, riprendendo gli esempi precedenti, per 3 gruppi Cp = 3, quindi EG = 0,14. In questo caso abbiamo una probabilità pari al 14% di commettere un errore rifiutando l'ipotesi nulla quando questa è vera. Per 14 gruppi, Cp = 91, quindi EG = 0,99. In questo caso abbiamo una probabilità del 99% di commettere un errore. Pertanto aumentando il numero di confronti, aumentiamo la probabilità di commettere un errore del I° tipo.

11
Un modo per risolvere tale problema è quello di ricorrere al test di Bonferroni (detto anche test di Dunn). Il test di Bonferroni si basa sull’ineguaglianza di Bonferroni che stabilisce che l’evenienza di uno o più eventi non può superare la somma delle probabilità individuali. Facendo riferimento all’errore di I° tipo, se α = 0,05, e se facciamo tre confronti ( Cp = 3), allora la probabilità di fare almeno un errore di I° tipo è 3(0,05)= 0,15. Se vogliamo quindi mantenere basso l’errore di gruppo, indicando con α’ l’errore di riferimento, allora α’ = α/ Cp. Una volta calcolato α’ e in base ai gradi di libertà è possibile trovare il valore critico di t consultando delle apposite tavole sviluppate da Dunn. Ad esempio, per α' = 0,0167 e gdl =5, allora tcrit = 3,53. Se i t calcolati con le formule per il t-test sono inferiori a tale valore, allora l'ipotesi nulla non può essere rifiutata. Occorre far notare che per α = 0,05 e gdl = 5, allora tcrit = 2,57 (ipotesi a due code), per cui, ovviamente, aumentando il numero di confronti a coppie aumenta il valore critico di t, rendendo sempre più difficile la determinazione di una differenza significativa (si riduce la potenza del test). Un altro modo per risolvere il problema dei confronti multipli è quello di ricorrere all'analisi della varianza.

12
Analisi della varianza
I disegni fattoriali: 1) è un disegno in cui una data variabile indipendente assume diversi livelli di valori (esempio: a 5 gruppi di topi vengono somministrate diverse dosi di un farmaco) oppure in cui si hanno 2 o più variabili indipendenti articolate in due o più livelli (esempio: si possono suddividere i topi in maschi e femmine e si creano per ciascun sesso 5 gruppi a cui vengono somministrate diverse dosi di un farmaco). 2) a differenza dei disegni sperimentali semplici (con due gruppi) i disegni fattoriali consentono l'analisi degli effetti di più variabili contemporaneamente con un minor numero di soggetti, risparmiando tempo ed energia. 3) I disegni fattoriali consentono di fare un'analisi aggiuntiva: oltre agli effetti delle singole variabili (analisi degli effetti principali) consentono l'analisi dell'interazione, ossia di analizzare quanto le variazioni di una variabile sono modulate dagli effetti delle altre variabili.
 è un disegno in cui una data variabile indipendente assume diversi livelli di valori (esempio: a 5 gruppi di topi vengono somministrate diverse dosi di un farmaco) oppure in cui si hanno 2 o più variabili indipendenti articolate in due o più livelli (esempio: si possono suddividere i topi in maschi e femmine e si creano per ciascun sesso 5 gruppi a cui vengono somministrate diverse dosi di un farmaco). 2) a differenza dei disegni sperimentali semplici (con due gruppi) i disegni fattoriali consentono l analisi degli effetti di più variabili contemporaneamente con un minor numero di soggetti, risparmiando tempo ed energia. 3) I disegni fattoriali consentono di fare un analisi aggiuntiva: oltre agli effetti delle singole variabili (analisi degli effetti principali) consentono l analisi dell interazione, ossia di analizzare quanto le variazioni di una variabile sono modulate dagli effetti delle altre variabili.")
13
Disegni fattoriali: 1. Disegno fattoriale con una sola variabile indipendente a più livelli a misure indipendenti o non ripetute (disegno con 1 fattore between) 2. Disegno fattoriale con una sola variabile indipendente a più livelli a misure dipendenti o ripetute (disegno con 1 fattore within) 3. Disegno fattoriale con due variabili indipendenti a misure indipendenti o non ripetute (disegno con 2 fattori between) 4. Disegno fattoriale con due variabili indipendenti, una a misure ripetute e una a misure non ripetute (disegno misto: 1 fattore between e 1 within)
 2. Disegno fattoriale con una sola variabile indipendente a più livelli a misure dipendenti o ripetute (disegno con 1 fattore within) 3. Disegno fattoriale con due variabili indipendenti a misure indipendenti o non ripetute (disegno con 2 fattori between) 4. Disegno fattoriale con due variabili indipendenti, una a misure ripetute e una a misure non ripetute (disegno misto: 1 fattore between e 1 within)")
14
1. Rappresentazione del disegno con 1 fattore between
livelli della var. indipendente A A1 A2 A3 A4 a d g l b e h m c f i n ogni lettera indica un diverso soggetto si hanno soggetti diversi per ogni livello di A 2. Rappresentazione del disegno con 1 fattore within livelli della var. indipendente A A1 A2 A3 A4 si ripetono gli stessi soggetti per ogni livello di A

15
3. Rappresentazione del disegno con 2 fattori between
livelli della var. indipendente A A1 A2 B1 B2 B1 B2 ogni lettera indica un diverso soggetto livelli della var. indipendente B si hanno soggetti diversi per ogni combinazione di livelli di A e di B 4. Rappresentazione del disegno misto con 1 fattore between e 1 fattore within livelli della var. indipendente A (fattore between) A1 A2 B1 B2 B1 B2 ogni lettera indica un diverso soggetto livelli della var. indipendente B (fattore within) si hanno soggetti diversi per ciascun livello di A e si ripetono gli stessi soggetti per ciascun livello di B
 A1. A2. B1. B2. B1. B2. ogni lettera indica un diverso soggetto. livelli della var. indipendente B (fattore within) si hanno soggetti diversi per ciascun livello di A e si ripetono gli stessi soggetti per ciascun livello di B.")
16
Disegno con una sola variabile indipendente a più livelli:
Struttura: 4 gruppi di bambini (ogni gruppo composto da 5 soggetti ciascuno). Tre gruppi di bambini sono sottoposti a tre diversi metodi per la comprensione del testo (indicati con A, B e C), mentre il quarto gruppo (indicato con D) non è sottoposto ad alcun metodo. I quattro gruppi vengono sottoposti ad un compito di comprensione del testo, in cui vengono dati dei voti da 0 a 10. Gruppo A Gruppo B Gruppo C Gruppo D
. Tre gruppi di bambini sono sottoposti a tre diversi metodi per la comprensione del testo (indicati con A, B e C), mentre il quarto gruppo (indicato con D) non è sottoposto ad alcun metodo. I quattro gruppi vengono sottoposti ad un compito di comprensione del testo, in cui vengono dati dei voti da 0 a 10. Gruppo A. Gruppo B. Gruppo C. Gruppo D.")
17
k = livello della variabile indipendente (K = 4, 1 ≤ k ≤ 4 )
Modello algebrico del disegno con una sola variabile indipendente a misure non ripetute (1 fattore between): var. dip. media popolazione var. indip. errore k = livello della variabile indipendente (K = 4, 1 ≤ k ≤ 4 ) i = numero del soggetto (I = 5, 1 ≤ i ≤ 5 ) Struttura della varianza dei punteggi per il disegno con un solo fattore between: varianza totale partizione dei g.d.l.: IK − 1 varianza tra i gruppi (trattamento) varianza entro i gruppi (errore) K − 1 K(I − 1)
: var. dip. media. popolazione. var. indip. errore. k = livello della variabile indipendente (K = 4, 1 ≤ k ≤ 4 ) i = numero del soggetto (I = 5, 1 ≤ i ≤ 5 ) Struttura della varianza dei punteggi per il disegno con un solo fattore between: varianza totale. partizione dei g.d.l.: IK − 1. varianza. tra i gruppi (trattamento) varianza. entro i gruppi (errore) K − 1. K(I − 1)")
18
Calcolo manuale della varianza
1. calcolo delle medie per trattamento e della media globale 2. calcolo delle SQ (somme dei quadrati) del trattamento e della SQ di tutti i soggetti entro i gruppi (varianza d'errore) 3. calcolo dei g.d.l. dei livelli di trattamento e dei g.d.l. di tutti i soggetti 4. calcolo delle MQ (medie dei quadrati) del trattamento e della MQ di tutti i soggetti entro i gruppi 5. calcolo della F e verifica della significatività del trattamento varianza dovuta al trattamento varianza dovuta all'errore
 del trattamento e della SQ di tutti i soggetti entro i gruppi (varianza d errore) 3. calcolo dei g.d.l. dei livelli di trattamento e dei g.d.l. di tutti i soggetti. 4. calcolo delle MQ (medie dei quadrati) del trattamento e della MQ di tutti i soggetti entro i gruppi. 5. calcolo della F e verifica della significatività del trattamento. varianza dovuta al trattamento. varianza dovuta all errore.")
19
Struttura del disegno: A B C D
medie: media globale * scarto media trattamento-media globale scarto punteggio soggetto-media trattamento (*) In realtà si dovrebbe scrivere: per facilità di lettura i sigma sono omessi dalla formula del modello simbolo di varianza
 In realtà si dovrebbe scrivere: per facilità di lettura i sigma sono omessi dalla formula del modello. simbolo di varianza.")
20
La varianza totale è indicata dalla SQTOT. Inoltre
Per il calcolo manuale dell'analisi della varianza si ricorre al calcolo delle somme dei quadrati (SQ). La varianza totale è indicata dalla SQTOT. Inoltre SQTOT = SQtratt + SQerr varianza totale varianza dell'errore varianza del trattamento 1. SQ della varianza totale: (8 − 5)2 A B C D SQTOT =
. La varianza totale è indicata dalla SQTOT. Inoltre. SQTOT = SQtratt + SQerr. varianza totale. varianza dell errore. varianza del. trattamento. 1. SQ della varianza totale: (8 − 5)2. A. B. C. D. SQTOT =")
21
formula computazionale:
numero soggetti× livelli di trattamento = 20

22
2. SQ della varianza dovuta al trattamento:
numero soggetti per gruppo (I = 5) formula computazionale: numero livelli di trattamento = 4
 formula computazionale: numero livelli di trattamento = 4.")
23
3. SQ della varianza dovuta all'errore:
formula computazionale:

24
SQTOT = SQtratt + SQerr 82 = 33,2 + 48,8 4. calcolo dei g.d.l.: g.d.l. del trattamento: gdltratt = K – 1 = 3 g.d.l. dell'errore: gdlerr = K(I – 1) = 16 g.d.l. della varianza totale: gdlTOT =(I × K) – 1 = 19 5. calcolo delle MQ MQtratt = SQtratt / gdltratt = 33,2 / 3 = 11,07 MQerr = SQerr / gdlerr = 48,8 / 16 = 3,05
 = 16. g.d.l. della varianza totale: gdlTOT =(I × K) – 1 = calcolo delle MQ. MQtratt = SQtratt / gdltratt = 33,2 / 3 = 11,07. MQerr = SQerr / gdlerr = 48,8 / 16 = 3,05.")
25
6. Calcolo dell'F: F = MQtratt / MQerr = 11,07 / 3,05 = 3,63 F è significativo? Per saperlo si possono seguire due modi: Trovare nelle tavole dei libri di statistica l'Fcrit corrispondente e verificare se F > Fcrit. Per trovare l'Fcrit corrispondente occorre sapere quali sono i g.d.l del numeratore e i g.d.l. del denominatore del rapporto di F (in questo caso i g.d.l. del numeratore sono 3 e quelli del denominatore sono 16). Inoltre occorre stabilire le proporzione di errore del I° tipo (0.01, 0.05, e così via). Stabilito a = 0.05, allora per 3 e 16 g.d.l., Fcrit = 3,24 < 3,63 (l'F calcolato). Se si usa un programma statistico, il programma fornisce automaticamente il valore di p associato all'F calcolato ( p = 0.036) L'F calcolato risulta, dunque, significativo.
. Inoltre occorre stabilire le proporzione di errore del I° tipo (0.01, 0.05, e così via). Stabilito a = 0.05, allora per 3 e 16 g.d.l., Fcrit = 3,24 < 3,63 (l F calcolato). Se si usa un programma statistico, il programma fornisce automaticamente il valore di p associato all F calcolato ( p = 0.036) L F calcolato risulta, dunque, significativo.")
26
Per sapere quale gruppo ha fornito la prestazione migliore, ossia ha il
livello più alto di comprensione del testo, conviene fare un grafico delle medie della var. dipendente in relazione ai vari livelli del trattamento sperimentale. La figura seguente riposta i dati del nostro esempio. I puntini del grafico indicano le medie. Le barre sopra e sotto i puntini riportano l'errore standard. Maggiore è l'ampiezza delle barre, maggiore è la varianza del campione. Dal grafico emerge che il gruppo A ha la migliore prestazione, mentre il gruppo D è il peggiore.

27
Tavola dei valori critici di F per a = 0,05 valore critico di F
per 3 g.d.l. al numeratore e 16 g.d.l. al denominatore

28
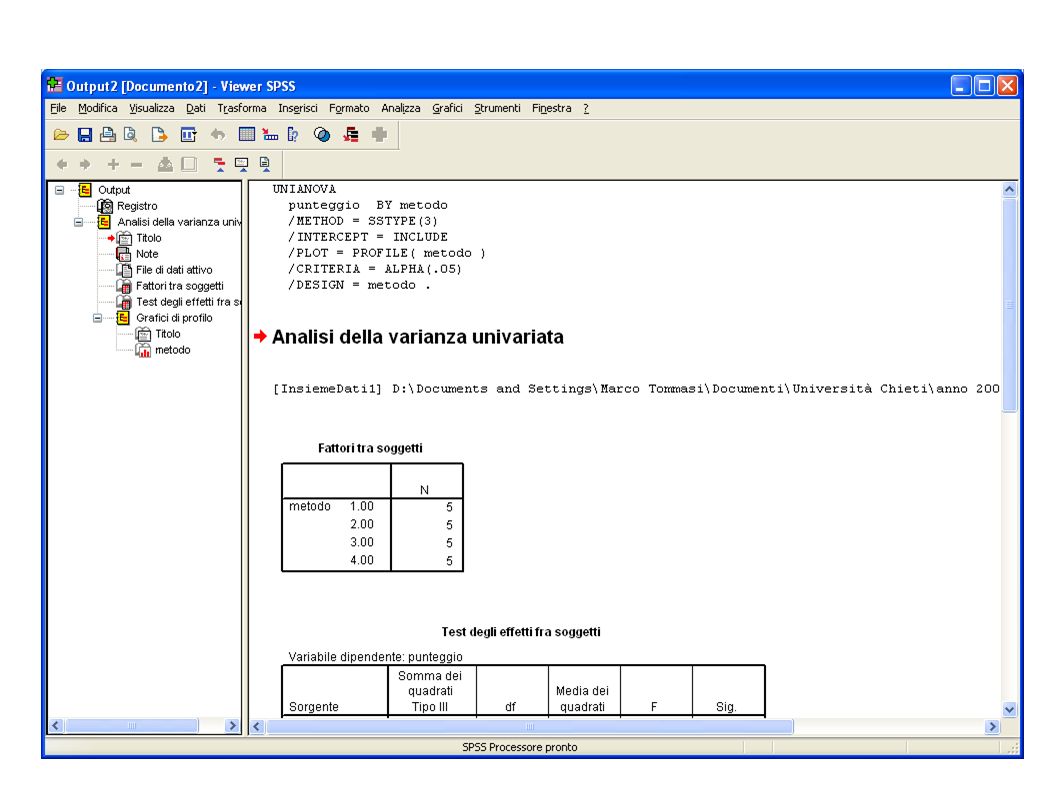
Inserimento dati per l’SPSS:
è necessario creare due colonne: la prima colonna “metodo” definisce i gruppi. Per distinguere i gruppi si possono usare numeri o lettere o codici alfa-numerici, ecc… La seconda colonna “punteggio” riposte ai valori o misure della variabile dipendente, un questo caso il livello di comprensione del testo. Per fare un’ANOVA univariata, occorre una colonna che definisce i gruppi o le categorie di soggetti e una colonna che riporta le misure o i dati su cui si effettua il test

29
Scelta dei comandi: Menù: Analizza Modello lineare generalizzato Univariata…

32
Tavola degli F: Grafico delle medie per gruppi:

33
L’ANOVA consente di stabilire se esiste almeno una differenza tra due gruppi. È altresì possibile che esista più di una differenza. Ad esempio se si hanno 5 gruppi, e possibile che oppure Se per il ricercatore è importante sapere anche quali sono le differenze può seguire due strategie. O stabilire prima di eseguire l’analisi statistica quali contrasti analizzare, oppure analizzare i contrasti dopo aver eseguito il test generale. In altri termini si può decidere a priori di fare l’analisi dei confronti o a posteriori. L’analisi a priori è possibile se il ricercatore ha già ipotizzato quali sono i confronti importanti. Quella a posteriori viene eseguita quando, invece, il ricercatore non ha formulato alcuna ipotesi specifica e desidera raccogliere ulteriori informazioni. TexPoint fonts used in EMF. Read the TexPoint manual before you delete this box.: AAAAAAAAA

34
ANOVA per campioni indipendenti
Confronti a priori: 1. t-test multipli 2. contrasti lineari 3. contrasti ortogonali 4. test di Bonferroni (o Dunn o Sidak)
")
35
t-test multipli Consistono nell’esecuzione di diversi t-test. C’è il rischio dell’incremento dell’errore di gruppo. La formula per i t-test multipli è: dove e sono le medie dei due gruppi e MSerror la varianza entro i gruppi ed n il numero di soggetti per gruppo. Se i gruppi hanno varianze omogenee, si può usare la MSerror come termine di errore per il t test. Il t test è a due code, quindi posto α = 0.05, occorre cercare i t critici per

36
Contrasti lineari I contrati lineari sono una combinazione lineare di somme di medie indicata con L: La regole impone che ∑aj = 0, in altri termini i valori dei paramentri a devono essere tali da annullarsi. Nel caso di 5 gruppi ecco possibili combinazioni valide di parametri: = = =0 I valori dei parametri a sono arbitrari. Si consiglia di scegliere valori che facilitino i calcoli. Un esempio di una combinazione lineare L è:

37
Per calcolare la significatività di un contrasto lineare occorre calcolare la somma dei quadrati dei contrasti o SScontrasto che è n è il numero di soggetti. Se calcoliamo diversi contrasti ad esempio 2, allora SStratt = SScontrasto1 + SScontrasto2 . I gradi di libertà dei contrasti lineari sono sempre uguali a uno (si tratta sempre del confronto tra due medie), ossia dfcontrasto = 1. Quindi MScontrasto = SScontrasto / dfcontrasto = SScontrasto / 1 = SScontrasto .
, ossia dfcontrasto = 1. Quindi MScontrasto = SScontrasto / dfcontrasto = SScontrasto / 1 = SScontrasto .")
38
La significatività del contrasto è
dove MSerror è la varianza d’errore dell’ANOVA generale. L’F critico ha 1 e dferror gradi di libertà. Esempio: esperimento sull’efficacia dei metodi di lettura sulla comprensione del testo. Supponiamo di voler confrontare il gruppo A con il gruppo D. Facciamo un contrasto lineare. n = 5 MSerror = 3,05 la cui probabilità è: p = 0,007. Quindi la differenza è significativa.

39
Contrasti ortogonali Talvolta i contrasti sono tra loro indipendenti, talvolta no. Per indipendenza si intende la possibilità dei preveder una differenza. Ad es., se 1 è più grande della medie di 2 e 3, questo non ci dice nulla se 4 è più grande di 5, ma abbiamo una probabilità maggiore di 50% che 1 risulti più grande di 2. Le regole principali dei contrasti ortogonali sono 2: ∑aj = 0 (ossia la somma dei parametri deve esse uguale a zero) e ∑ajbj = 0 (ossia la somma del prodotto dei parametri tra contrasti deve essere zero). Es: dati 5 gruppi, abbiamo la seguente partizione dei contrasti
 e ∑ajbj = 0 (ossia la somma del prodotto dei parametri tra contrasti deve essere zero). Es: dati 5 gruppi, abbiamo la seguente partizione dei contrasti.")
40
La tabella dei coefficienti risulta:

41
test di Bonferroni Il test di Bonferroni, talvolta chiamato test di Dunn o Sidak, si basa sull’ineguaglianza di Bonferroni che stabilisce che l’evenienza di uno o più eventi non può superare la somma delle probabilità individuali. Facendo riferimento all’errore di I° tipo, se α = .05, e se facciamo tre confronti, allora la probabilità di fare almeno un errore di I° tipo è 3(.05)= Se vogliamo quindi mantenere basso l’errore di gruppo, indicando con α’ l’errore di riferimento, allora α’ = α/c, dove c è il numero di confronti. In altri termini occorre abbassare α per abbassare l’errore di gruppo. Sulla base di queste considerazioni Dunn ha sviluppato un test che consente di calcolare la significatività dei contrasti tramite t test e facendo riferimento all’errore α’. Nel caso di tre confronti, se α’ è posto uguale a 0.05, allora α = .05/3= Il t critico corrispondente a tale livello di errore è consultabile nelle tavole di Dunn (il t per α = e dferror=5 è 3.53).
= Se vogliamo quindi mantenere basso l’errore di gruppo, indicando con α’ l’errore di riferimento, allora α’ = α/c, dove c è il numero di confronti. In altri termini occorre abbassare α per abbassare l’errore di gruppo. Sulla base di queste considerazioni Dunn ha sviluppato un test che consente di calcolare la significatività dei contrasti tramite t test e facendo riferimento all’errore α’. Nel caso di tre confronti, se α’ è posto uguale a 0.05, allora α = .05/3= Il t critico corrispondente a tale livello di errore è consultabile nelle tavole di Dunn (il t per α = e dferror=5 è 3.53).")
42
La formula per il calcolo del t è la stessa usata per i t multipli, ossia
In questo caso t’ indica che sono necessarie le tavole di Dunn per trovare il valore critico di t.

43
Confronti a posteriori
Si dividono in due gruppi: test che non fissano il valore di FW (familywise error o errore di gruppo) e test che fissano FW. I primi sono detti non conservativi e i secondi conservativi in quanto più restrittivi, nel senso che pongono condizioni che più difficilmente consentono l’individuazione di differenze significative. Test che non fissano FW: 1. metodo delle minima differenza significativa (least significant difference o LSD) 2. Newman-Keuls test Test che fissano FW: 1.Test di Tukey 2. Test di Ryan 3. Test di Scheffé 4. Test di Dunnett
 e test che fissano FW. I primi sono detti non conservativi e i secondi conservativi in quanto più restrittivi, nel senso che pongono condizioni che più difficilmente consentono l’individuazione di differenze significative. Test che non fissano FW: 1. metodo delle minima differenza significativa (least significant difference o LSD) 2. Newman-Keuls test. Test che fissano FW: 1.Test di Tukey. 2. Test di Ryan. 3. Test di Scheffé. 4. Test di Dunnett.")
44
Differenza minima significativa (Least Significant Difference o LSD).
Anche questa procedura si basa sull’uso di t test multipli, L’unica differenza è che la procedura LSD richiede un F significativo per l’analisi globale. Il problema è sempre il valore di FW che aumenta all’aumentare dei confronti. Per questo è una procedura generalmente non consigliata.

45
Differenza minima significativa (Least Significant Difference o LSD).
μB μC μD = ≠

46
Test di Newman-Keuls Si basa sul calcolo di una particolare statistica, detta statistica del rango studentizzata (q). La formula per il calcolo del q è dove l e s sono rispettivamente le media più grande (largest o l) e più piccola (smallest o s) della serie di medie. La formula è simile a quelle dei t test multipli, tranne per il fatto che al denominatore non compare √2. Quindi per ottenere q da t, q = t√2.
. La formula per il calcolo del q è. dove l e s sono rispettivamente le media più grande (largest o l) e più piccola (smallest o s) della serie di medie. La formula è simile a quelle dei t test multipli, tranne per il fatto che al denominatore non compare √2. Quindi per ottenere q da t, q = t√2.")
47
Per stabilire se la differenza tra la media più piccola e più grande è significativa si ricorre alla seguente formula dove q0.05 è il valore critico di q per α = .05 ed r indica il numero di medie della serie di trattamenti tra la media più grande e la media più piccola (se abbiamo 5 trattamenti, allora r=5). r è la distanza in rango tra le medie. dferror sono i gradi di libertà della varianza d’errore. La formula calcola la differenza minima significativa tra medie che deve poi essere confrontata con quella reale. Se la differenza reale risulta maggiore allora è significativa. I q critici per r e dferror gradi di libertà sono ricavati da apposite tavole.
. r è la distanza in rango tra le medie. dferror sono i gradi di libertà della varianza d’errore. La formula calcola la differenza minima significativa tra medie che deve poi essere confrontata con quella reale. Se la differenza reale risulta maggiore allora è significativa. I q critici per r e dferror gradi di libertà sono ricavati da apposite tavole.")
48
Il test Newman-Keuls si basa sul calcolo di diversi q per le diverse distanze tra le medie. Ossia, date 5 medie, abbiamo r = 2, 3, 4, 5 distanze e per ciascuna si calcola la differenza minima significativa tra medie. Poi si calcolano le differenze reali e si confrontano con quelle minime. Se le reali sono maggiori della minima, allora la differenza è significativa. Test di Tukey Il test di Tukey si basa come il Newman Keuls sul calcolo di q per tutte le possibili distanze, solo che considera tutte le differenze come se fossero distanti 5 intervalli. Ossia due medie con distanza r = 2 vengono considerate con distanza r =5.

49
Newman-Keuls test insieme 1: μA = μB = μC; insieme 2: μB = μC = μD μB μA μD μC Test di Tukey insieme 1: μA = μB = μC; insieme 2: μB = μC = μD μB μA μD μC

50
Test di Scheffè Il test di Scheffè invece della distribuzione di q usa la distribuzione F. La formula per il calcolo di F coincide con quella dei contrasti lineari, ossia ma l’F critico è calcolato nel seguente modo: Fcrit = (k-1)Fa (k-1, dferror),dove k è il numero di medie, α l’errore di I° tipo (sempre constante) e dferror i gradi di libertà della varianza d’errore. Fa è il valore critico di F per k -1 e dferror. Tra tutti i test è quello più conservativo ossia quello con la minor capacità di rivelare differenze significative.
Fa (k-1, dferror),dove k è il numero di medie, α l’errore di I° tipo (sempre constante) e dferror i gradi di libertà della varianza d’errore. Fa è il valore critico di F per k -1 e dferror. Tra tutti i test è quello più conservativo ossia quello con la minor capacità di rivelare differenze significative.")
51
Test di Scheffé Il test di Scheffé è troppo conservativo: nessuna coppia di medie ha una differenza significativa, nonostante l’F sia significativo! μB μA μC μD

52
Il test di Dunnett Se l’ANOVA prevede un gruppo di controllo e diversi gruppi sperimentali, allora si applica il test di Dunnett. Il test di Dunnett fa riferimento ad apposite tavole di t, elaborate proprio da Dunnett. Indicando con td il t critico delle tavole di Dunnett, individuabile se si hanno k = 5 medie e se si conosce il valore di dferror allora si può calcolare la differenza minima significativa tra gruppo di controllo e gruppo sperimentale , dove c è la media del gruppo di controllo e j è la media di un gruppo sperimentale. Pertanto Si procede al calcolo di tutte le differenze tra gruppi sperimentali e il gruppo di controllo e quelle che risultano inferiori alla differenza calcolata con la formula precedente non sono significative.

53
confronto 1: μA ≠ μD; confronto 2: μB = μD; confronto 3: μC = μD.

54
Trend analysis Se diversi gruppi sono assegnati a ciascun livello di una data variabile, ma tale variabile consente di ordinare i gruppi lungo un continuum, allora si può eseguire un’analisi volta a stabilire la forma globale dell’effetto della variabile. Questo tipo di analisi è detta Trend Analysis. L’analisi del trend consiste essenzialmente nell’identificare quale curva lineare (lineare o polinomiale) è quella più adatta a descrivere l’effetto della variabile. A differenza dei confronti tra media a priori o posteriori, in cui si calcola la differenza tra due medie o gruppi di medie, essa consente di stabilire quale tipo di relazione descrive meglio l’andamento dei valori della variabile. Es.: se a diversi gruppi di soggetti vengono fornite dosi crescenti di un farmaco ( mg), la cui funzione è prevenire l’infarto, possiamo con la trend analysis verificare se la relazione tra dosi di farmaco e rischio di infarto è di tipo lineare (ossia il rischio è inversamente proporzionale all’aumento della dose), o quadratico (ossia l’aumento del farmaco è efficace fino ad in punto e poi diminuisce).
 è quella più adatta a descrivere l’effetto della variabile. A differenza dei confronti tra media a priori o posteriori, in cui si calcola la differenza tra due medie o gruppi di medie, essa consente di stabilire quale tipo di relazione descrive meglio l’andamento dei valori della variabile. Es.: se a diversi gruppi di soggetti vengono fornite dosi crescenti di un farmaco ( mg), la cui funzione è prevenire l’infarto, possiamo con la trend analysis verificare se la relazione tra dosi di farmaco e rischio di infarto è di tipo lineare (ossia il rischio è inversamente proporzionale all’aumento della dose), o quadratico (ossia l’aumento del farmaco è efficace fino ad in punto e poi diminuisce).")
55
La formula per il calcolo del tipo di curva è uguale a quella dei contrasti lineari. Indicando con L la componente di curva dove aj sono i parametri della curva. Ogni curva ha un insieme specifico di parametri: curva lineare: curva quadratica: Nota bene: la serie di coefficienti sopra presentata è valida se: a) la variabile è discreta b) gli intervalli tra i livelli della variabile sono costanti. I coefficienti delle curve hanno le stesse proprietà dei contrasti ortogonali, ossia ∑aj = 0 e ∑ajbj = 0.
 la variabile è discreta. b) gli intervalli tra i livelli della variabile sono costanti. I coefficienti delle curve hanno le stesse proprietà dei contrasti ortogonali, ossia ∑aj = 0 e ∑ajbj = 0.")
56
Per stabilire se è significativa la componente lineare o quadratica, occorre calcolare le SSlineare e le SSquadratiche. dato che dflineare = 1 e dfquadratica = 1, allora MSlineare = SSlineare e MSquadratica = SSquadratica. Flineare = MSlineare/ MSerror e Fquadratica = MSquadratica/ MSerror, dove la MSerror è la varianza d’errore dell’ANOVA globale. Si confrontano gli F ottenuti con l’Fcrit(1,dferror) e se superano l’Fcrit allora la componente di curva è significativa.
 e se superano l’Fcrit allora la componente di curva è significativa.")
57
A, B e C tre metodi di lettura D: nessun metodo
Trend analysis: l’effetto della variabile indipendente è lineare o quadratico? A, B e C tre metodi di lettura D: nessun metodo Coefficienti trend lineare: = 0 Coefficienti trend quadratico: = 0 trend lineare: trend quadratico: MQerr = 3,05 MQ trend lineare: MQ trend quadr.: Solo la componente lineare è significativa. L’effetto della var. indip. è, dunque, lineare.

58
Nell’ANOVA l’effect size viene calcolato in due modi principali
Nell’ANOVA l’effect size viene calcolato in due modi principali. Uno fa riferimento al valore d di Cohen, l’altro invece al coefficiente di correlazione al quadrato r2. Gli indici calcolati nel secondo modo vengono definiti “grandezza dell’effetto”. Esistono sei indici della grandezza dell’effetto sperimentale, ma i due più usati e qui considerati sono l’eta al quadrato (h2) e l’omega al quadrato (w2). l’eta al quadrato (2). L’eta al quadrato, talvolta indicato come rapporto di correlazione, è la più antica forma di misura dell’effetto sperimentale. L’eta (h) viene definito in alcuni manuali come coefficiente di regressione o correlazione curvilineare, in quanto consente di trovare la migliore regressione quando la relazione tra due variabili non è lineare. La formula per il calcolo del coefficiente di correlazione per la retta di regressione è:
 e l’omega al quadrato (w2). l’eta al quadrato (2). L’eta al quadrato, talvolta indicato come rapporto di correlazione, è la più antica forma di misura dell’effetto sperimentale. L’eta (h) viene definito in alcuni manuali come coefficiente di regressione o correlazione curvilineare, in quanto consente di trovare la migliore regressione quando la relazione tra due variabili non è lineare. La formula per il calcolo del coefficiente di correlazione per la retta di regressione è:")
59
La figura successiva evidenzia la distribuzione dei punteggi per 5 gruppi con diversi numeri di soggetti impegnati nel ricordo di liste di parole usando 5 tipi di tecniche di memorizzazione

60
I quadrati bianchi uniti dalle linee indicano le medie dei gruppi
I quadrati bianchi uniti dalle linee indicano le medie dei gruppi. La formula per il calcolo dell’eta al quadrato è simile a quella per il calcolo di r2 se al posto di inseriamo . Effettuata la sostituzione, si ottiene: dato che SStotal – SSresidual = SStreatment, allora la formula si riduce semplicemente a

61
Utilizzando i dati riprodotti nella figura si ottiene che h2 = 0
Utilizzando i dati riprodotti nella figura si ottiene che h2 = 0.447, il che significa che il 44,7 % della varianza nei punteggi di ricordo è attribuibile all’effetto del trattamento. Quindi l’eta al quadrato indica la percentuale di varianza spiegata dal trattamento. Occorre far notare che l’indice dell’eta al quadrato assume che la vera linea di regressione passi attraverso le medie del trattamento. Se i dati sono tratti dalla popolazione, questo è vero. Se i dati sono tratti da dei campioni, allora è possibile che ci sia un bias tra la media del campione e quella della popolazione. L’eta al quadrato, perciò risulta suscettibile alle distorsioni. Esempio: 1 - b η2

62
L’omega al quadrato. È una statistica discussa da Hays e sviluppata da Fliess. L’omega viene derivato dal modello strutturale dell’anova. La formula è: Usando sempre i dati del ricordo, allora w2 = Il valore dell’omega a quello dell’eta per gli stessi dati risulta inferiore. Ciò indica la distorsione presente nell’eta. Occorre far notare che esistono due formule per il calcolo dell’omega, una (quella qui presentata) per l’anova che usa un modello a effetti fissi, l’altra per l’anova che usa il modello a effetti random. Una versione del coefficiente di correlazione intraclasse coincide con l’omega al quadrato calcolato secondo la formula per il modello a effetti random.
 per l’anova che usa un modello a effetti fissi, l’altra per l’anova che usa il modello a effetti random. Una versione del coefficiente di correlazione intraclasse coincide con l’omega al quadrato calcolato secondo la formula per il modello a effetti random.")
Presentazioni simili


 e nel verificare se con i dati a disposizione è possibile rifiutarla o no.>")

















