Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Negli ultimi anni l’utilizzo delle tecniche quantitative è diventato molto più facile grazie alla reperibilità di nuovi software (anche gratuiti) facili da usare e che pertanto sono alla portata di coloro essere che non conoscono le formule matematiche su cui sono basati i vari stimatori. A questo si aggiunga la grande reperibilità di informazioni e dati oggi disponibile e il continuo aumento della velocità e capacità di elaborazione dei computer il cui prezzo va invece continuamente riducendosi

2
Esempio di software facili da usare -Eviews (a pagamento: disponibile in biblioteca su alcuni computer) -GRETL (gratis scaricabile da internet nelle principali lingue)
 -GRETL (gratis scaricabile da internet nelle principali lingue)")
3
I principali metodi quantitativi utilizzabili appartengono a quattro filoni: (a)analisi di regressione tradizionale; (b)analisi sulla volatilità; (c)case-studies; (d)simulazioni con calibrazioni o con numeri casuali (metodo Montecarlo)
analisi di regressione tradizionale; (b)analisi sulla volatilità; (c)case-studies; (d)simulazioni con calibrazioni o con numeri casuali (metodo Montecarlo)")
4
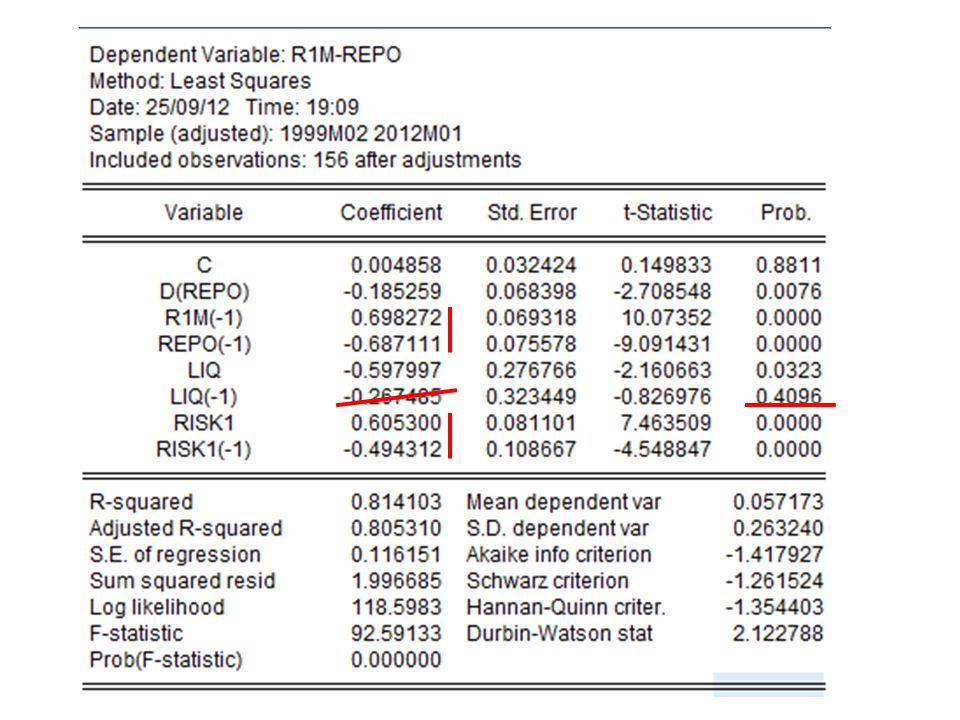
(a) Analisi di regressione tradizionale Esempio: stima dello spread tra l’Euribor a 1 mese R1M e il REPO (primo giorno dopo la riunione della BCE) Ipotesi: il differenziale dipende dalla liquidità del sistema bancario (LIQ) e dal rischio del mercato interbancario (RISK1). Ci possono essere degli effetti ritardati ESEMPIO: PROGRAMMA EVIEWS ISTRUZIONE: (R1M-REPO) C D(REPO) R1M(-1) REPO(-1) LIQ LIQ(-1) RISK RISK(-1) (D = variazione; (-1)=valore assunto dalla variabile nel periodo precedente; c è la costante)
 C D(REPO) R1M(-1) REPO(-1) LIQ LIQ(-1) RISK RISK(-1) (D = variazione; (-1)=valore assunto dalla variabile nel periodo precedente; c è la costante).")
6
(a) Analisi di regressione tradizionale Le stime evidenziano: 1.Il coefficiente di LIQ(-1) non significativamente diverso da zero 2.I coefficienti di R1M(-1) REPO(-1) sono simili ma hanno segno opposto 3.Lo stesso succede per RISK RISK(-1)
 Analisi di regressione tradizionale Le stime evidenziano: 1.Il coefficiente di LIQ(-1) non significativamente diverso da zero 2.I coefficienti di R1M(-1) REPO(-1) sono simili ma hanno segno opposto 3.Lo stesso succede per RISK RISK(-1)")
7
Estimation Command: ========================= LS (R1M-REPO) C D(REPO) R1M(-1) REPO(-1) LIQ LIQ(-1) RISK RISK(-1) Estimation Equation: ========================= R1M-REPO = C(1) + C(2)*D(REPO) + C(3)*R1M(-1) + C(4)*REPO(-1) + C(5)*LIQ + C(6)*LIQ(-1) + C(7)*RISK + C(8)*RISK(-1) Substituted Coefficients: ========================= R1M-REPO = 0.005 - 0.185*D(REPO) + 0.698*R1M(-1) - 0.687*REPO(-1) - 0.597*LIQ - 0.267*LIQ(-1) + 0.605*RISK - 0.494*RISK(-1) La relazione stimata
 C D(REPO) R1M(-1) REPO(-1) LIQ LIQ(-1) RISK RISK(-1) Estimation Equation: ========================= R1M-REPO = C(1) + C(2)*D(REPO) + C(3)*R1M(-1) + C(4)*REPO(-1) + C(5)*LIQ + C(6)*LIQ(-1) + C(7)*RISK + C(8)*RISK(-1) Substituted Coefficients: ========================= R1M-REPO = *D(REPO) *R1M(-1) *REPO(-1) *LIQ *LIQ(-1) *RISK *RISK(-1) La relazione stimata")
8
Eseguo il test di Wald per verificare che i coefficienti siano effettivamente uguali ma con segno opposto Accetto l’ipotesi nulla che i coefficienti siano uguali

9
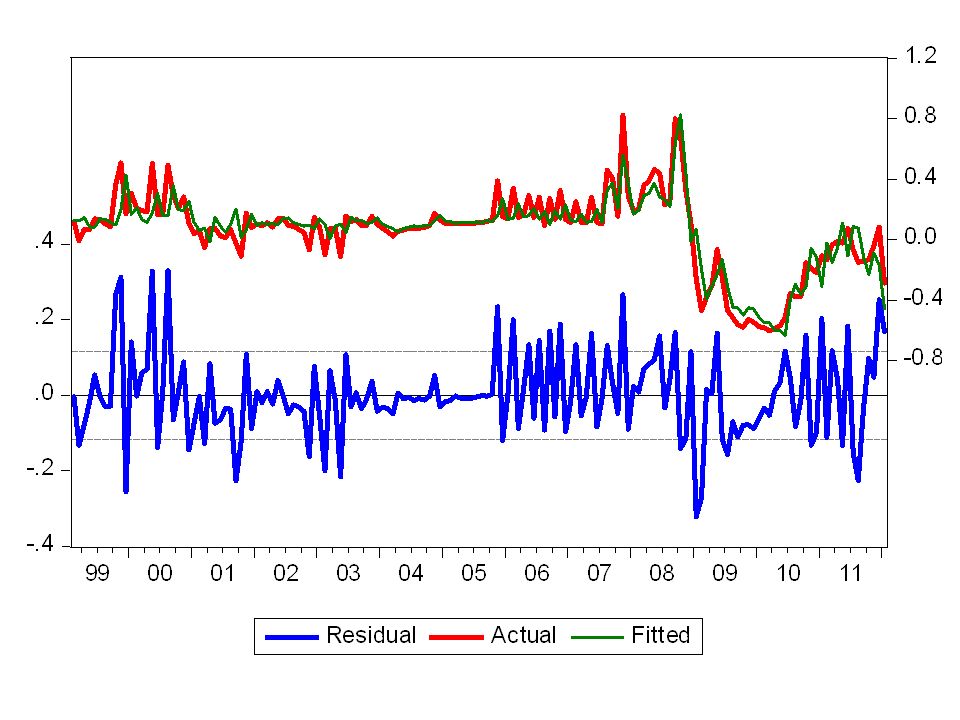
Elimino la variabile non significativa Controllo la bontà della stima: Adjusted R2

11
Aggiunta di altre importanti variabili

12
Dopo l’aggiunta della altre variabili

13
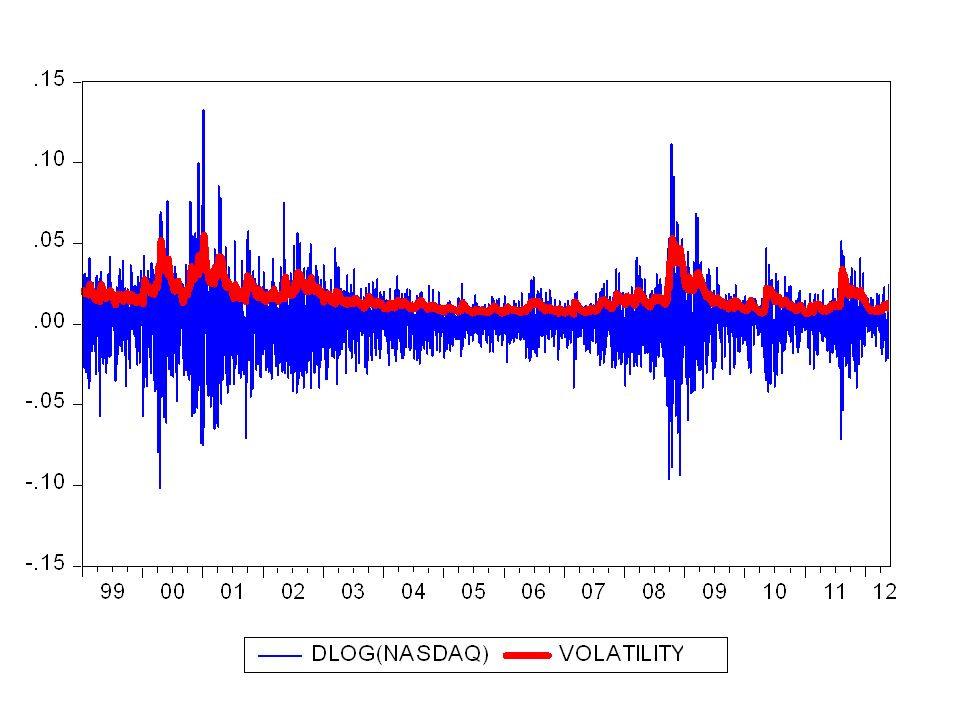
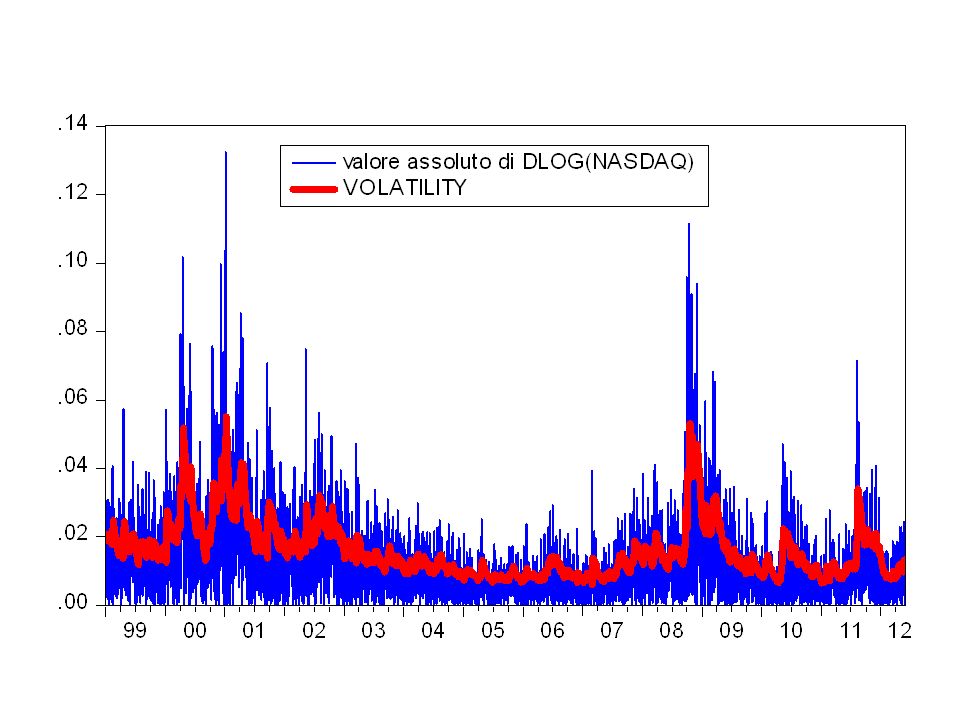
(b) Analisi della volatilità L’analisi della volatilità risponde alla esigenza di una valutazione dell’incertezza di rendimenti futuri. Al concetto di volatilità vengono associate misure statistiche di variabilità (varianza). Problema: la volatilità non è direttamente osservabile, ma gode di alcune caratteristiche comunemente osservate nelle serie dei rendimenti.
. Problema: la volatilità non è direttamente osservabile, ma gode di alcune caratteristiche comunemente osservate nelle serie dei rendimenti..")
14
(b) Analisi della volatilità La variabilità dei rendimenti non è costante nel tempo; Esistono fenomeni di volatility clustering (la volatilità può essere alta in alcuni periodi e bassa in altri); C’è persistenza nella volatilità, ovvero alta volatilità tende ad essere seguita da alta volatilità; bassa volatilità tende ad essere seguita da bassa volatilità; Raramente si osservano scatti di volatilità (si sviluppa lungo il tempo in maniera continua)
 Analisi della volatilità La variabilità dei rendimenti non è costante nel tempo; Esistono fenomeni di volatility clustering (la volatilità può essere alta in alcuni periodi e bassa in altri); C’è persistenza nella volatilità, ovvero alta volatilità tende ad essere seguita da alta volatilità; bassa volatilità tende ad essere seguita da bassa volatilità; Raramente si osservano scatti di volatilità (si sviluppa lungo il tempo in maniera continua)")
15
(b) Analisi della volatilità La volatilità non diverge all’infinito ma varia in un range fisso. Statisticamente parlando, questo significa che spesso la volatilità è stazionaria;

16
(b) Analisi della volatilità
 Analisi della volatilità")
17
La volatilità non è costante nel tempo !!!

20
(b) Analisi della volatilità La stima della volatilità si risolve nella ricerca di modelli (per i rendimenti) che descrivano l’evoluzione temporale della varianza condizionata (dei rendimenti). L’andamento della varianza del processo generatore dei dati è di tipo condizionatamente autoregressivo. Modelli ARCH (AutoRegressive Conditional Heteroskedasticity).
..")
21
Quando si riunisce la BCE la volatilità dei tassi è maggiore del solito?

22
c) case-studies Analisi dei soli episodi ritenuti rilevanti o confronto tra particolari situazioni e le condizioni “normali”
 case-studies Analisi dei soli episodi ritenuti rilevanti o confronto tra particolari situazioni e le condizioni normali")
23
(m = scadenza dell’euribor); solo giorni delle riunioni
; solo giorni delle riunioni")
24
Esempio di Case Analysi Report; Solo giorni delle riunioni

25
Confronto tra i giorni delle riunioni e gli altri giorni

26
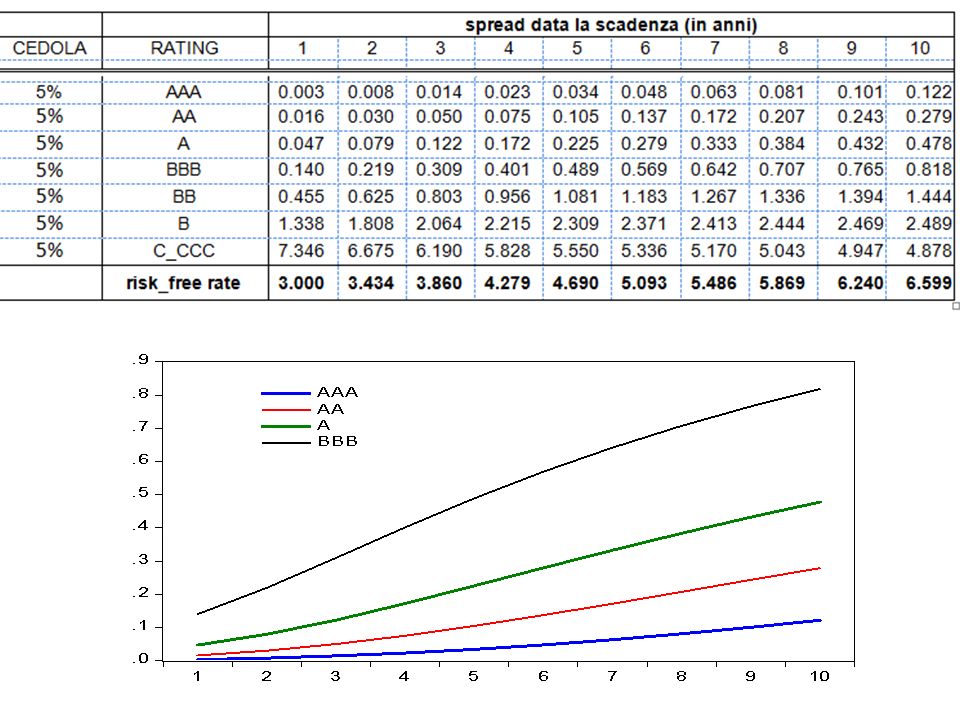
d) simulazioni con calibrazioni o con numeri casuali (metodo Montecarlo) Esempio di calibrazione. Supponendo che l’unico rischio delle obbligazioni di default fosse quello di insolvenza quale sarebbe lo spread delle obbligazioni corporate europee al crescere della scadenza dato il rating? Si analizza il valore attuale delle entrate probabili in relazione alle caratteristiche di rischiosità legate al rating, alla cedola, alla vita residua… al risk free … (spesso usando l’analisi di regressione) Poi si calcola il rendimento di un titolo che con quelle caratteristiche tecniche (vita residua, cedola…. ) corrisponde a quel valor attuale
 Poi si calcola il rendimento di un titolo che con quelle caratteristiche tecniche (vita residua, cedola…. ) corrisponde a quel valor attuale.")
28
Esempio di simulazione con numeri casuali (metodo Montecarlo) Stima delle entrate del comune di xxxx relative al servizio della scuola materna Dati a disposizione: -Le famiglie potenzialmente fruitrici del servizio sono 1802. Di queste famiglie si hanno ISEE, numero componenti, figli a carico, numero genitori che lavorano, presenza di disabili….. Queste caratteristiche sono quelle che entrano nel calcolo della tariffa. -Si sa però che le famiglie che effettivamente usufruiranno del servizio saranno circa 500.

29
Procedimento 1)Estrarre a sorte un numero minore-uguale a 1802. 2)Calcolare la tariffa che pagherebbe quella famiglia in base alle sue caratteristiche familiari 3)Rifare i punti (1) e (2) per 500 volte (il numero presunto delle famiglie che manderanno i figli alla scuola materna) 4)Sommare quello che pagherebbero le 500 famiglie estratte per avere il totale delle entrate del comune. 5)Ripetere il procedimento da (1) a (4) per es. 10.000 volte. La media ci darà la stima delle entrate e la distribuzione ci permetterà di conoscere la precisione della stima Entrate per il comune frequenze (%)
Calcolare la tariffa che pagherebbe quella famiglia in base alle sue caratteristiche familiari 3)Rifare i punti (1) e (2) per 500 volte (il numero presunto delle famiglie che manderanno i figli alla scuola materna) 4)Sommare quello che pagherebbero le 500 famiglie estratte per avere il totale delle entrate del comune. 5)Ripetere il procedimento da (1) a (4) per es volte. La media ci darà la stima delle entrate e la distribuzione ci permetterà di conoscere la precisione della stima Entrate per il comune frequenze (%).")
30
A che cosa servono queste analisi? L’impiego delle analisi econometriche può essere diviso in tre gruppi principali: (a)verifica di ipotesi (visione del passato) (b)simulazioni di scenari economici alternativi (futuri e passati potenziali alternativi) (c)previsioni di alcune variabili (visione del futuro)
verifica di ipotesi (visione del passato) (b)simulazioni di scenari economici alternativi (futuri e passati potenziali alternativi) (c)previsioni di alcune variabili (visione del futuro).")
31
Problema con le previsioni -Variabili esplicative che non sono note al momento delle previsioni -Possibile evoluzione nel mondo nel periodo cui si riferiscono le aspettative -E’ molto importante provare scenari alternativi

32
La metodologia utilizzata non può prescindere da una buona conoscenza della realtà da parte dell’utilizzatore. La conoscenza del fenomeno economico in esame suggerisce infatti le variabili da utilizzate e le relazioni da considerare. Da questo dipende qual è la metodologia più appropriata e la possibilità di introduzione eventuali vincolo che rendano più efficienti le stime. Un risultato “strano” rispetto alle conoscenze che l’utilizzatore ha della realtà corrisponde, nel 99% dei casi, a un risultato sbagliato

33
Spiegazione del Repo in base ale variabili economiche

34
Andamento previsto dal 2007 in avanti tenendo conto del tasso minimo

35
Andamento previsto dal 2007 in avanti non tenendo conto del tasso minimo

36
Ora cominciamo……

37
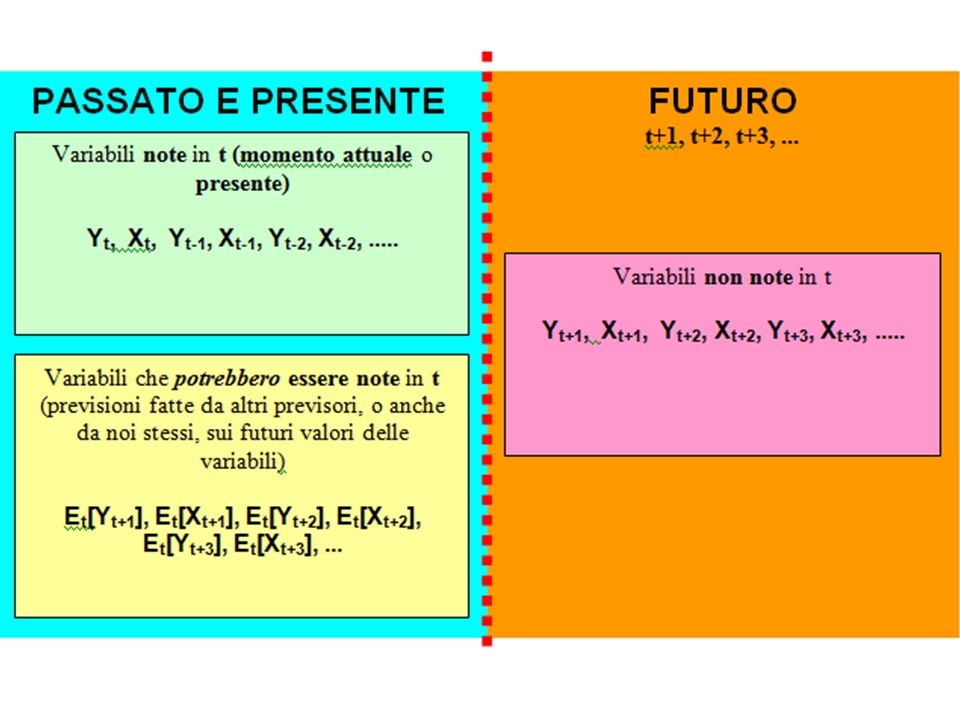
Y t = F( X t, Y t-1, X t-1 ) + t E t [Y t+j ] = ….. Si supponga inoltre che nell’istante t i valori di X t, Y t e tutti i loro valori passati siano noti
![Y t = F( X t, Y t-1, X t-1 ) + t E t [Y t+j ] = …..](http://images.slideplayer.it/38/10761965/slides/slide_37.jpg "Si supponga inoltre che nell’istante t i valori di X t, Y t e tutti i loro valori passati siano noti.")
39
E t [Y t+1 ] = E t [F( X t+1, Y t, X t )] E t [Y t+1 ] = F( E t [X t+1 ], Y t, X t ) Y t = 0 + 10 X t + 21 Y t-1 + 11 X t-1 + t Y t+1 = 0 + 10 X t+1 + 21 Y t + 11 X t + t+1 X t+1 = E t [X t+1 ] + t+1 Y t+1 = 0 + 10 (E t [X t+1 ] + t+1 ) + 21 Y t + 11 X t + t+1 = 0 + 10 E t [X t+1 ] + 21 Y t + 11 X t + ( t+1 + 10 t+1 ) E t [Y t+2 ] = F( E t [X t+2 ], E t [Y t+1 ], E t [X t+1 ] ) Utilizzando stime la posto dei valori reali dei regressori si ottengono stime più imprecise
![E t [Y t+1 ] = E t [F( X t+1, Y t, X t )] E t [Y t+1 ] = F( E t [X t+1 ], Y t, X t ) Y t = 0 + 10 X t + 21 Y t-1 + 11 X t-1 + t Y t+1 = 0 + 10 X t+1 + 21 Y t + 11 X t + t+1 X t+1 = E t [X t+1 ] + t+1 Y t+1 = 0 + 10 (E t [X t+1 ] + t+1 ) + 21 Y t + 11 X t + t+1 = 0 + 10 E t [X t+1 ] + 21 Y t + 11 X t + ( t+1 + 10 t+1 ) E t [Y t+2 ] = F( E t [X t+2 ], E t [Y t+1 ], E t [X t+1 ] ) Utilizzando stime la posto dei valori reali dei regressori si ottengono stime più imprecise](http://images.slideplayer.it/38/10761965/slides/slide_39.jpg "E t [Y t+1 ] = E t [F( X t+1, Y t, X t )] E t [Y t+1 ] = F( E t [X t+1 ], Y t, X t ) Y t = 0 + 10 X t + 21 Y t-1 + 11 X t-1 + t Y t+1 = 0 + 10 X t+1 + 21 Y t + 11 X t + t+1 X t+1 = E t [X t+1 ] + t+1 Y t+1 = 0 + 10 (E t [X t+1 ] + t+1 ) + 21 Y t + 11 X t + t+1 = 0 + 10 E t [X t+1 ] + 21 Y t + 11 X t + ( t+1 + 10 t+1 ) E t [Y t+2 ] = F( E t [X t+2 ], E t [Y t+1 ], E t [X t+1 ] ) Utilizzando stime la posto dei valori reali dei regressori si ottengono stime più imprecise")
40
GRADO DI INTEGRAZIONE DELLE VARIABILI Per ottenere stime sensate è opportuno verificare che la relazione che descrive il meccanismo generatore dei dati sia attendibile. A tal fine occorre analizzare il grado di integrazione delle variabili La variabile u t =k+ ε t, si dice che è integrata di ordine 0 (o stazionaria) e la si indica con I(0) se il suo valore continua ad oscillare attorno a un valore deterministico (nell’esempio la costante k)
 e la si indica con I(0) se il suo valore continua ad oscillare attorno a un valore deterministico (nell’esempio la costante k).")
41
Anche la variabile u t =k+ u t-1 + ε t con <1 è detta stazionaria, ma in questo caso presenta una certa persistenza (integrata di ordine 0 I(0) con persistenza) dal momento che il valore in t di u risente del suo valore precedente, anche se nel tempo continua ad oscillare attorno a k.
 con persistenza) dal momento che il valore in t di u risente del suo valore precedente, anche se nel tempo continua ad oscillare attorno a k.")
42
Si consideri il caso precedente ma con = 1. In questo caso le caratteristiche di u t =k+ u t -1 + ε t cambierebbero drasticamente. La nuova u t diventerebbe infatti u t =k+ u t -1 + ε t ovvero u t - u t-1 = k+ ε t u t = k+ ε t Il valore atteso di u t sarebbe così E t [u t ]=k+ u t -1

43
E non esisterebbe alcun valore di equilibrio a cui tende la variabile u t. Infatti, per t+1 sarebbe: u t+1 = k+ u t + ε t+1 = k + (k+ u t-1 + ε t ) + ε t+1 = 2k + u t-1 + ε t + ε t+1 che in t+2 diventerebbe u t+2 = 3k + u t-1 + ε t + ε t+1 + ε t+2 In generale, per t+i si ha: u t+i = (1+i)k + u t 1 + (ε t + ε t+1 + ε t+2 + …. + ε t+i ) La presenza di un k 0 introdurrebbe un trend lineare (1+i)k, cui si aggiungono il valore “storico” u t-1 della variabile u e la componente stocastica (ε t + ε t+1 + ε t+2 + …. + ε t+i ).
 + ε t+1 = 2k + u t-1 + ε t + ε t+1 che in t+2 diventerebbe u t+2 = 3k + u t-1 + ε t + ε t+1 + ε t+2 In generale, per t+i si ha: u t+i = (1+i)k + u t 1 + (ε t + ε t+1 + ε t+2 + …. + ε t+i ) La presenza di un k 0 introdurrebbe un trend lineare (1+i)k, cui si aggiungono il valore storico u t-1 della variabile u e la componente stocastica (ε t + ε t+1 + ε t+2 + …. + ε t+i )..")
44
La posizione storica di partenza u t-1 non viene mai “dimenticata”: continua a influenzare tutti i successivi u t+i Supponiamo ore che k=0, cioè nel caso il trend lineare non esistesse. La relazione si ridurrebbe a: u t+i = u t-1 + (ε t + ε t+1 + ε t+2 + …. + ε t+i ) e qualunque sia i (con i 0) il valore atteso di u t+i, dato che E[ε t+i ]=0, sarebbe E[u t+i ] = u t-1 Non esisterebbe pertanto alcun valore deterministico attorno cui la successione {u t } tende ad oscillare. Semplicemente ogni volta la variabile oscilla attorno al suo valore precedente. Una variabile di questo genere si dice integrata di prim’ordine I(1).
 e qualunque sia i (con i 0) il valore atteso di u t+i, dato che E[ε t+i ]=0, sarebbe E[u t+i ] = u t-1 Non esisterebbe pertanto alcun valore deterministico attorno cui la successione {u t } tende ad oscillare. Semplicemente ogni volta la variabile oscilla attorno al suo valore precedente. Una variabile di questo genere si dice integrata di prim’ordine I(1)..")
45
La sua varianza per i diventa Var(lim u t+i ) = Var(lim (ε t + ε t+1 + ε t+2 + …. + ε t+i )) = (σ 2 + σ 2 + σ 2 + …. σ 2 ) = i σ 2 = La successione {u t } non ha quindi varianza finita. Qualunque varianza campionaria (che è necessariamente finita) non può essere una buona approssimazione della varianza della popolazione (che è infinita). Si arriva quindi alla situazione paradossale che il valore atteso dei futuri valori della variabile corrisponderebbe all’ultima osservazione disponibile, ma il futuro valore effettivo tende ad allontanarsi sempre più da questo valore (varianza infinita) anche se non è possibile prevederne la direzione.
) = (σ 2 + σ 2 + σ 2 + …. σ 2 ) = i σ 2 = La successione {u t } non ha quindi varianza finita. Qualunque varianza campionaria (che è necessariamente finita) non può essere una buona approssimazione della varianza della popolazione (che è infinita). Si arriva quindi alla situazione paradossale che il valore atteso dei futuri valori della variabile corrisponderebbe all’ultima osservazione disponibile, ma il futuro valore effettivo tende ad allontanarsi sempre più da questo valore (varianza infinita) anche se non è possibile prevederne la direzione..")
46
Se k fosse diverso da zero, all’andamento della u di aggiungerebbe un trend (1+i)k, ma anche in questo caso non esisterebbe pertanto alcun valore deterministico attorno cui la successione {u t } tende ad oscillare. Ogni volta la variabile oscillerebbe attorno al suo valore precedente + k. La presenza di un k 0 aggiungerebbe infatti un trend alla relazione, ma non muterebbe la sostanza del problema: non esiste alcun valore deterministico cui tende la successione{u t }. Una variabile costituita dalla somma di un I(1) con un trend è detta anche integrata di ordine 1 con un trend I(1,T).
 con un trend è detta anche integrata di ordine 1 con un trend I(1,T)..")
47
Le variabili integrate di ordine 1 (o superiori ad 1) sono dette anche variabili non stazionarie o trend stocastici. La caratteristica di queste variabili è quella di muoversi lentamente nel tempo, senza alcuna tendenza verso un valore di equilibrio. E’ evidente che se u t è di ordine I(1), la sua variazione u t è I(0) (stazionaria), infatti: u t = u t - u t-1 =(k+ u t -1 + ε t ) - u t-1 = (k + ε t ) Si dice che una variabile è I(n) ( = integrata di ordine n) se occorre effettuare n variazioni per ottenere una variabile stazionaria.
, la sua variazione u t è I(0) (stazionaria), infatti: u t = u t - u t-1 =(k+ u t -1 + ε t ) - u t-1 = (k + ε t ) Si dice che una variabile è I(n) ( = integrata di ordine n) se occorre effettuare n variazioni per ottenere una variabile stazionaria..")
48
Tra le variabili non stazionarie, in economia sono importanti solo e I(1) e, qualche volta, le I(2). In particolare, i prezzi e le quantità nominali sono generalmente I(1) o I(2); le grandezze reali sono generalmente I(1) o I(0) con trend; i rendimenti sono generalmente I(1) o I(0), come anche le crescite. Una serie I(2) (integrata di ordine 2) ha un andamento di tipo particolarmente smussato in quanto per definizione anche la sua variazione non ha alcuna tendenza a riportarsi vero un valore deterministico.
 o I(2); le grandezze reali sono generalmente I(1) o I(0) con trend; i rendimenti sono generalmente I(1) o I(0), come anche le crescite. Una serie I(2) (integrata di ordine 2) ha un andamento di tipo particolarmente smussato in quanto per definizione anche la sua variazione non ha alcuna tendenza a riportarsi vero un valore deterministico..")
50
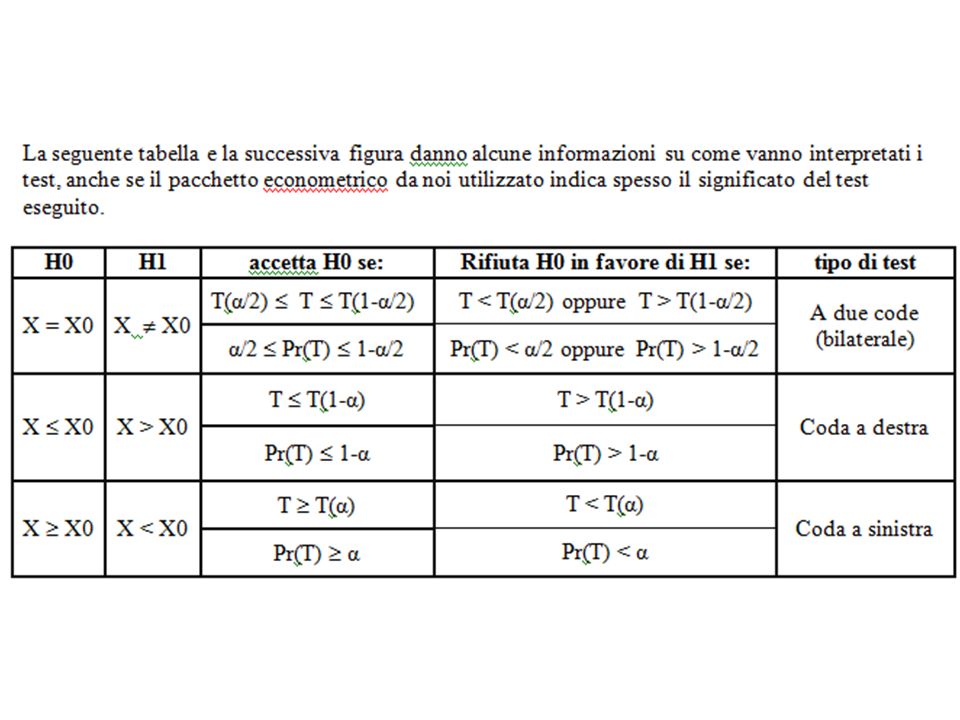
L’impiego dei test La valutazione dei test dipende dalla cosiddetta “ipotesi nulla” H 0. In altri termini, i test sono stati costruiti nell’ipotesi che la variabile soggetta a test segua un certo comportamento: se la differenza tra il valore effettivo del test e quello teorico è così elevata che è quasi impossibile che questa differenza sia dovuta al caso, l’ipotesi nulla H 0 viene respinta e si accetta il suo opposto, cioè la cosiddetta ipotesi alternativa H 1. Per esempio, se H 0 è che un certo valore sia nullo e il vero valore è così lontano dallo zero che la probabilità che questo fenomeno sia dovuto a un puro caso è molto bassa, si rifiuta l’ipotesi H 0 (il valore è nullo) a favore dell’ipotesi H 1 (il valore non è nullo).
 a favore dell’ipotesi H 1 (il valore non è nullo)..")
51
I test, però, possono essere sia diretti che indiretti in relazione all’ipotesi nulla di partenza. Con i test diretti siamo interessati all’ipotesi H 0 che accettiamo quando la probabilità che l’ipotesi H 0 sia vera è sufficientemente “alta” (cioè maggiore di un certo valore α, es. il 5%). Con i test indiretti noi siamo invece interessati all’ipotesi alternativa H 1 che accettiamo quando viene respinta H 0, cioè quando la probabilità che H 0 sia vera è “bassa” (per esempio inferiore al 5%). Tutto questo, in alcuni casi, può generare perplessità sul risultato. A questo si aggiunga che i test talvolta sono a due code (bilaterali), talvolta a una sola coda (centrali).
. Con i test indiretti noi siamo invece interessati all’ipotesi alternativa H 1 che accettiamo quando viene respinta H 0, cioè quando la probabilità che H 0 sia vera è bassa (per esempio inferiore al 5%). Tutto questo, in alcuni casi, può generare perplessità sul risultato. A questo si aggiunga che i test talvolta sono a due code (bilaterali), talvolta a una sola coda (centrali)..")
54
H0: I(1); H1: I(0) (stazionaria) H0: I(0) (stazionaria); H1: I(1)
; H1: I(0) (stazionaria) H0: I(0) (stazionaria); H1: I(1)")
56
La non stazionarietà delle variabili crea dei problemi per le regressioni. Nel caso di variabili I(0) senza trend, l’errore u della regressione u = Y-(a-bX+cZ) è sicuramente stazionario perché tutte le variabili Y, X e Z oscillano attorno a un valore deterministico e quindi anche ogni loro combinazione lineare deve oscillare attorno a qualche valore deterministico.
 senza trend, l’errore u della regressione u = Y-(a-bX+cZ) è sicuramente stazionario perché tutte le variabili Y, X e Z oscillano attorno a un valore deterministico e quindi anche ogni loro combinazione lineare deve oscillare attorno a qualche valore deterministico..")
57
Se però le variabili fossero I(1), nessuna di loro oscillerebbe attorno a un valore deterministico e pertanto nulla ci garantisce che l’errore u debba oscillare attorno a qualche valore deterministico (ad es. 0) Se però il residuo u fosse un I(1) la regressione non sarebbe valida (si parla in questo caso di regressione “spuria”) perché il procedimento dei minimi quadrati minimizzerebbe una varianza campionaria dei residui che, essendo finita, non può essere una buona stima di quella della popolazione che è infinita. Qualunque fossero le stime si a, b e c, non esisterebbe nessun motivo per cui Y debba tendere ad avvicinarsi alla sua stima a+bX+cZ !!
 Se però il residuo u fosse un I(1) la regressione non sarebbe valida (si parla in questo caso di regressione spuria ) perché il procedimento dei minimi quadrati minimizzerebbe una varianza campionaria dei residui che, essendo finita, non può essere una buona stima di quella della popolazione che è infinita. Qualunque fossero le stime si a, b e c, non esisterebbe nessun motivo per cui Y debba tendere ad avvicinarsi alla sua stima a+bX+cZ !!.")
58
Può però capitare che le componenti I(1) delle variabili si compensino fra loro e che quindi il residuo u sia I(0). In questo caso tutte le variabili Y, X e Z tendono ad allontanarsi sempre più dal loro valore di partenza, ma il movimento della Y oscilla attorno al valore della relazione (a + bX + cZ) che ne rappresenta quindi la relazione di equilibrio (si pensi alla terra che è vincolata ad oscillare attorno al solo il quale a sua volta si muove nell’universo).
 che ne rappresenta quindi la relazione di equilibrio (si pensi alla terra che è vincolata ad oscillare attorno al solo il quale a sua volta si muove nell’universo)..")
59
Nel caso le variabili Y, X e Z siano I(1), ma esista qualche loro relazione u = Y –a –bX –cZ che sia I(0) si direbbe che le variabili Y, X e Z sono cointegrate e il vettore dei loro coefficienti [1, -a, -b, -c] si chiamerebbe vettore di cointegrazione. In questo caso particolare (ma solo in questo caso) è possibile procedere a una stima della relazione tra Y e le sue variabili esplicative Si noti, comunque, che se il vettore = [1, -a, -b, -c] è un vettore di cointegrazione lo sarà anche il vettore h = [h, -ah, - bh, -ch] (con h 0); quindi, per esempio, se b 0, anche /(-b) = [-1/b, a/b, 1, c/b] è equivalente a .
![Nel caso le variabili Y, X e Z siano I(1), ma esista qualche loro relazione u = Y –a –bX –cZ che sia I(0) si direbbe che le variabili Y, X e Z sono cointegrate e il vettore dei loro coefficienti [1, -a, -b, -c] si chiamerebbe vettore di cointegrazione.](http://images.slideplayer.it/38/10761965/slides/slide_59.jpg "In questo caso particolare (ma solo in questo caso) è possibile procedere a una stima della relazione tra Y e le sue variabili esplicative Si noti, comunque, che se il vettore = [1, -a, -b, -c] è un vettore di cointegrazione lo sarà anche il vettore h = [h, -ah, - bh, -ch] (con h 0); quindi, per esempio, se b 0, anche /(-b) = [-1/b, a/b, 1, c/b] è equivalente a ..")
60
Date tre variabili Y, X e Z, è però possibile che i vettori di cointegrazione siano addirittura due, uno per ogni coppia di variabili. Potrebbero per esempio essere singolarmente cointegrate le coppie (X,Y) e (Y,Z). In questo caso vi sarebbero due relazioni di equilibrio, con la X che oscilla attorno a una trasformazione lineare della Y che, a sua volta, oscillerebbe attorno a una trasformazione lineare della Z. E’ evidente che non è possibile che una variabile I(1) possa essere cointegrata con una variabile I(0): è infatti impossibile che una variabile che si muove liberamente nello spazio sia vincolata ad oscillare attorno ad una variabile che oscilla attorno a un punto ben definito.
 e (Y,Z). In questo caso vi sarebbero due relazioni di equilibrio, con la X che oscilla attorno a una trasformazione lineare della Y che, a sua volta, oscillerebbe attorno a una trasformazione lineare della Z. E’ evidente che non è possibile che una variabile I(1) possa essere cointegrata con una variabile I(0): è infatti impossibile che una variabile che si muove liberamente nello spazio sia vincolata ad oscillare attorno ad una variabile che oscilla attorno a un punto ben definito..")
61
Uno dei metodi più usati per determinare se delle variabili I(1) sono cointegrate, cioè per stabilire se tra loro esiste una (o più) relazioni di equilibrio (vettori di cointegrazione) radici unitarie), è il metodo di Johansen, col quale si calcolano anche i valori dei coefficienti di equilibrio. Il metodo verrà spiegato direttamente all’interno degli esempio concreti (in particolare vedi i casi della relazione tra Euribor e Repo e la stima del tasso a lunga). Si ricordi che tra le alternative che questo procedimento usa per individuare il numero di vettori di cointegrazione quello considerato migliore è quello della traccia ed è quindi a questo test che è meglio fare riferimento.
. Si ricordi che tra le alternative che questo procedimento usa per individuare il numero di vettori di cointegrazione quello considerato migliore è quello della traccia ed è quindi a questo test che è meglio fare riferimento..")
62
Detto questo, per eseguire delle regressioni in forma appropriata al tipo di variabili che si stanno utilizzando (I(1) o I(0) ), ci si può attenere a questi principi: Quando c’è già un modello teorico ben definito (come per es. nel caso fra tasso implicito e tasso futuro) non c’è da preoccuparsi: basta eseguire una normale regressione. E’ ovvio, però, che una varabile I(1) non potrà mai essere spiegata da sole variabili I(0) Quando siamo di fronte a un caso non ben conosciuto è utile determinare innanzitutto il grado d’integrazione delle variabili per stabilire se sono I(0) o I(1) [le variabili economiche sono spesso I(1), le loro differenza (spread) sono invece spesso I(0) ] mediante l’ispezione visione del grafico e il test d’integrazione. Si seguono poi queste regole:
 non c’è da preoccuparsi: basta eseguire una normale regressione. E’ ovvio, però, che una varabile I(1) non potrà mai essere spiegata da sole variabili I(0) Quando siamo di fronte a un caso non ben conosciuto è utile determinare innanzitutto il grado d’integrazione delle variabili per stabilire se sono I(0) o I(1) [le variabili economiche sono spesso I(1), le loro differenza (spread) sono invece spesso I(0) ] mediante l’ispezione visione del grafico e il test d’integrazione. Si seguono poi queste regole:.")
63
a) Se le variabili sono I(0) (stazionarie) i loro valori vanno messi nelle regressioni in livelli. Y t = a 0 + a 10 X t + a 20 Z t + a 01 Y t-1 + a 11 X t-1 + a 21 Z t-1 + a 02 Y t-2 + a 12 X t-2 + a 22 Z t-2 +.... b) Nel caso di variabili I(1) X, Y, Z (dove Y è la dipendente) la stima va invece eseguita nella forma ∆Y t = a 0 + a 10 ∆X t + a 20 ∆Z t + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t-2 +.... le variabili sono espresse in variazioni e i livelli delle variabili entrano come variabili indipendenti solo in t-1. NOTA: se nell’equazione (b) vi fossero delle variabili esplicative I(0), queste andrebbero messe nei loro livelli (come nella (a) )
 Nel caso di variabili I(1) X, Y, Z (dove Y è la dipendente) la stima va invece eseguita nella forma ∆Y t = a 0 + a 10 ∆X t + a 20 ∆Z t + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t le variabili sono espresse in variazioni e i livelli delle variabili entrano come variabili indipendenti solo in t-1. NOTA: se nell’equazione (b) vi fossero delle variabili esplicative I(0), queste andrebbero messe nei loro livelli (come nella (a) ).")
64
Nel casi esista una relazione di equilibrio (cointegrazione) tra i livelli delle variabili Y, X e Z, e la variazione della dipendente è sensibile all’equilibrio preesistente, questo valore può essere ricavato tenendo presente che, in equilibrio, le variazioni delle variabili sono nulle (a parte dei trend interni) e i valori al tempo t dei livelli sono uguali a quelli al tempo t-1. Ne deriva che, in equilibrio, la nostra equazione si riduce a: 0 = 0 + b 0 Y+b 1 X+ b 2 Z + 0, da cui Y = -(b 1 /b 0 )X - (b 2 /b 0 )Z ovvero Y = 1 X t + 2 Z dove 1 = -(b 1 /b 0 ) e 2 = -(b 2 /b 0 ) In altri termini, i coefficienti di equilibrio si ottengono dividendo i coefficienti dei livelli delle variabili indipendenti ritardate per il coefficiente del livello della dipendente ritardata cambiato di segno.
X - (b 2 /b 0 )Z ovvero Y = 1 X t + 2 Z dove 1 = -(b 1 /b 0 ) e 2 = -(b 2 /b 0 ) In altri termini, i coefficienti di equilibrio si ottengono dividendo i coefficienti dei livelli delle variabili indipendenti ritardate per il coefficiente del livello della dipendente ritardata cambiato di segno..")
65
Analogamente, l’espressione + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 contenuta nella regressione può anche essere scritta, mettendo in evidenza b 0 come + b 0 (Y t-1 + b 1 /b 0 X t-1 + b 2 /b 0 Z t-1 ) = b 0 (Y t-1 - 1 X t-1 - 2 Z t-1 ) =b 0 [Y t-1 - ( 1 X t-1 + 2 Z t-1 )] ma l’espressione (Y t-1 - 1 X t-1 - 2 Z t-1 ) non è altro che la differenza in t-1 tra il valore effettivo di Y e il suo valore di equilibrio ( 1 X t-1 + 2 Z t-1 ): essa, cioè, non è altro che il disequilibrio in t di Y rispetto al suo valore di equilibrio.
![Analogamente, l’espressione + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 contenuta nella regressione può anche essere scritta, mettendo in evidenza b 0 come + b 0 (Y t-1 + b 1 /b 0 X t-1 + b 2 /b 0 Z t-1 ) = b 0 (Y t-1 - 1 X t-1 - 2 Z t-1 ) =b 0 [Y t-1 - ( 1 X t-1 + 2 Z t-1 )] ma l’espressione (Y t-1 - 1 X t-1 - 2 Z t-1 ) non è altro che la differenza in t-1 tra il valore effettivo di Y e il suo valore di equilibrio ( 1 X t-1 + 2 Z t-1 ): essa, cioè, non è altro che il disequilibrio in t di Y rispetto al suo valore di equilibrio.](http://images.slideplayer.it/38/10761965/slides/slide_65.jpg "Analogamente, l’espressione + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 contenuta nella regressione può anche essere scritta, mettendo in evidenza b 0 come + b 0 (Y t-1 + b 1 /b 0 X t-1 + b 2 /b 0 Z t-1 ) = b 0 (Y t-1 - 1 X t-1 - 2 Z t-1 ) =b 0 [Y t-1 - ( 1 X t-1 + 2 Z t-1 )] ma l’espressione (Y t-1 - 1 X t-1 - 2 Z t-1 ) non è altro che la differenza in t-1 tra il valore effettivo di Y e il suo valore di equilibrio ( 1 X t-1 + 2 Z t-1 ): essa, cioè, non è altro che il disequilibrio in t di Y rispetto al suo valore di equilibrio.")
66
Una maniera alternativa di esprimere la relazione (5) è quindi mediante l’equazione (6) ∆Y t = a 0 + a 10 ∆X t +a 20 ∆Z t + b 0 (Y t-1 - 1 X t-1 - 2 Z t-1 ) + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t-2 +.... in cui oltre alle variazioni delle variabili figura il disequilibrio in t-1. Da quest’ultima relazione risulta chiaro che b 0, il coefficiente di Y t-1 della (5), può essere anche interpretato come la velocità con cui la variabile Y in t reagisce al suo disequilibrio in t-1. Il valore dev’essere quindi negativo perché in questo caso a un valore eccessivo di Y in t-1 rispetto al suo valore di equilibrio segue una riduzione di Y in t (∆Y t 0).
, può essere anche interpretato come la velocità con cui la variabile Y in t reagisce al suo disequilibrio in t-1. Il valore dev’essere quindi negativo perché in questo caso a un valore eccessivo di Y in t-1 rispetto al suo valore di equilibrio segue una riduzione di Y in t (∆Y t 0)..")
67
E’ ovvio che quanto detto è vero solo se l’equilibrio esiste e Y reagisce al disequilibrio. Se l’equilibrio non dovesse esistere e/o b 0 =0, il valore di b 0 (Y t-1 - 1 X t-1 - 1 Z t-1 ) si ridurrebbe identicamente a 0 e l’equazione (6) potrebbe essere espressa solo nelle variazioni: (6’) ∆Y t = a 0 + a 10 ∆X t + a 20 ∆Z t + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t-2 +.... Lo stesso succederebbe anche alla (5), dal momento che questa e la (6) sono equivalenti: se mancano dei regressori nella seconda equazione devono mancare anche nella prima!
 si ridurrebbe identicamente a 0 e l’equazione (6) potrebbe essere espressa solo nelle variazioni: (6’) ∆Y t = a 0 + a 10 ∆X t + a 20 ∆Z t + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t Lo stesso succederebbe anche alla (5), dal momento che questa e la (6) sono equivalenti: se mancano dei regressori nella seconda equazione devono mancare anche nella prima!.")
68
Per stimare il modello (5)/(6) si possono seguire due procedimenti, diretto e indiretto:
/(6) si possono seguire due procedimenti, diretto e indiretto:")
69
Metodo diretto: si stima direttamente l’equazione Nel caso di variabili I(1) X, Y, Z (dove Y è la dipendente) la stima va eseguita nella forma ∆Y t = a 0 + a 10 ∆X t + a 20 ∆Z t + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t-2 +....
 X, Y, Z (dove Y è la dipendente) la stima va eseguita nella forma ∆Y t = a 0 + a 10 ∆X t + a 20 ∆Z t + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t")
70
Attenzione: col metodo diretto si può utilizzare la forma alternativa, con la dipendente espressa in livello Y t invece che in variazioni ∆Y t, mediante l’identità ∆Y t Y t - Y t-1 : ∆Y t = a 0 + a 10 ∆X t + a 20 ∆Z t + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t-2 +.... Y t - Y t-1 = a 0 + a 10 ∆X t + a 20 ∆Z t + b 0 Y t-1 +b 1 X t-1 + b 2 Z t-1 + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t-2 +.... Y t = a 0 + a 10 ∆X t + a 20 ∆Z t + (1+b 0 )Y t-1 +b 1 X t-1 + b 2 Z t-1 + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t-2 +....
Y t-1 +b 1 X t-1 + b 2 Z t-1 + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t")
71
In questo caso, però, il coefficiente della ritardata corrisponde a (1 + b 0 ), dove b 0 è il coefficiente con la dipendente espressa in variazioni e di questo si deve tener conto nel valutare i risultati e nell’effettuare i test sui coefficienti. Per esempio, i coefficienti di equilibrio corrispondono ai coefficienti dei livelli delle variabili X e Z ritardate diviso 1 meno il coefficiente della dipendente Y ritardata. Siccome b 0 dovrebbe essere negativo e non superiore ad 1, il coefficiente dalla ritardata Y t-1 dell’equazione con Y t come dipendente dovrebbe essere un numero positivo compreso tra zero e 1.

72
Metodo indiretto: Si verifica prima se l’equilibrio esiste e lo si stima con le tecniche di cointegrazione (es. Johansen). - a) Se l’equilibrio c’è (il che significa che il disequilibrio è una variabile I(0), cioè stazionaria) ed è uno solo (esiste un solo vettore di cointegrazione) si mette il disequilibrio in t-1 come un regressore al posto dei livelli presi separatamente. Per esempio, si supponga di aver trovato che l’equilibrio esiste, è unico e è dato da Y=1.212 X – 0.571 Z, ovvero il disequilibrio è dato da (Y - 1.212 X + 0.571 Z); la stima delle variazione ∆Y t viene allora effettuata stimando la seguente regressione (detta anche “dinamica” o “finale” o “di breve periodo):
. - a) Se l’equilibrio c’è (il che significa che il disequilibrio è una variabile I(0), cioè stazionaria) ed è uno solo (esiste un solo vettore di cointegrazione) si mette il disequilibrio in t-1 come un regressore al posto dei livelli presi separatamente. Per esempio, si supponga di aver trovato che l’equilibrio esiste, è unico e è dato da Y=1.212 X – Z, ovvero il disequilibrio è dato da (Y X Z); la stima delle variazione ∆Y t viene allora effettuata stimando la seguente regressione (detta anche dinamica o finale o di breve periodo):.")
73
∆Y t = a 0 + a 10 ∆X t +a 20 ∆Z t + b 0 (Y t-1 -1.212 X t-1 +0.571 Z t-1 ) + a 01 ∆Y t-1 + a 11 ∆X t-1 + a 21 ∆Z t-1 + a 02 ∆Y t-2 + a 12 ∆X t-2 + a 22 ∆Z t-2 +.... - b) Se l’equilibrio non c’è (non esiste nessun vettore di cointegrazione) nell’equazione si mettono solo le variazioni delle variabili. - c) Se vi è più di equilibrio (c’è più di un vettore di cointegrazione) vi conviene usare il metodo diretto con i livelli ritardati delle variabili (eq. 5). Questo problema è infatti troppo difficile da trattare per chi è alle prime armi e in questo caso, comunque, il metodo diretto funziona normalmente bene.
 Se l’equilibrio non c’è (non esiste nessun vettore di cointegrazione) nell’equazione si mettono solo le variazioni delle variabili. - c) Se vi è più di equilibrio (c’è più di un vettore di cointegrazione) vi conviene usare il metodo diretto con i livelli ritardati delle variabili (eq. 5). Questo problema è infatti troppo difficile da trattare per chi è alle prime armi e in questo caso, comunque, il metodo diretto funziona normalmente bene..")
74
Fine Grazie !!!!!!!

Presentazioni simili






>")



>")
>")
 Per effettuare test di qualsiasi natura è necessaria.>")
>")

>")






