Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Welcome in Genomics

2
Welcome in “omics”

3
“omics” observation of large data sets which can be made with high throughput procedures

4
“omics” genomics proteomics transcriptomics …………… diagnosticomics

5
Illustration provided by the National Human Genome Research Institute
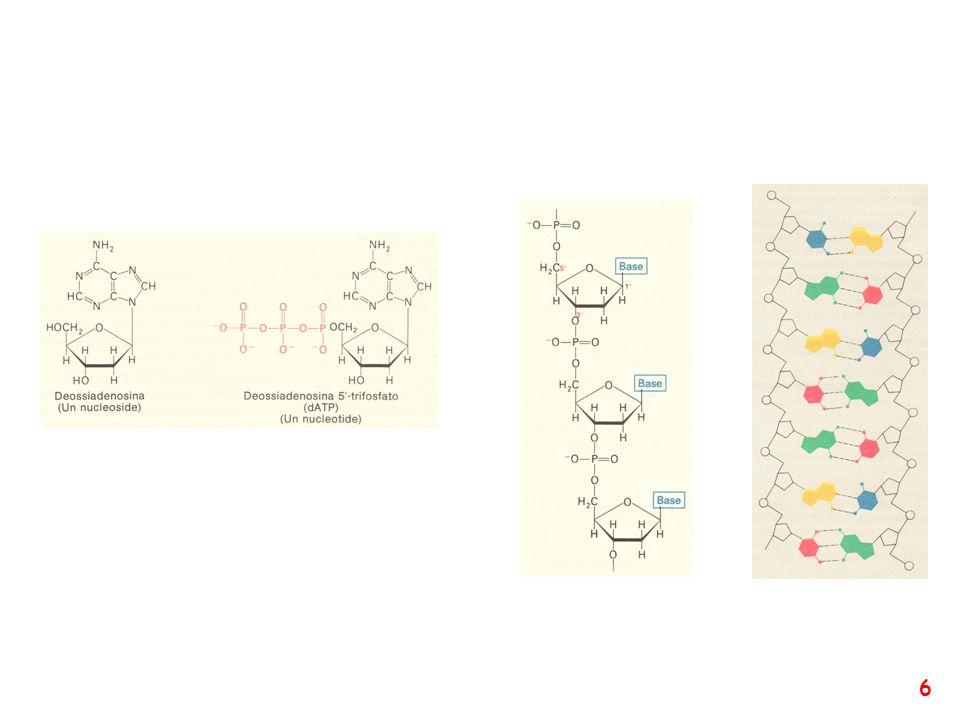
Central Dogma of Molecular Biology DNA > RNA > PROTEIN Illustration provided by the National Human Genome Research Institute The central dogma of molecular biology is based on the principle that the flow of genetic information travels from DNA to RNA and finally to the translation of PROTEINS. DNA can self replicate in the nucleus of a cell by using one strand of the double helix as a template (this is true for eukaryotes, some organisms such as bacteria have no nucleus and as a result their DNA replicates in the cytoplasm of the single-celled organism). The DNA also codes for mRNA (messenger RNA) in a process called transcription. The structure of RNA is similar to that of DNA except that RNA exists as a single stranded unit with Uracil replacing the DNA counterpart Thymine. The mRNA is then transported out of the nucleus and into the cytoplasm of eukaryotes were proteins are formed through a process called translation. A series of 3 nucleotides, or codon, is responsible for coding one amino acid. The amino acids are carried to the site of translation by transfer RNA (tRNA) Long chains of these 20 different amino acids form proteins.
. The DNA also codes for mRNA (messenger RNA) in a process called transcription. The structure of RNA is similar to that of DNA except that RNA exists as a single stranded unit with Uracil replacing the DNA counterpart Thymine. The mRNA is then transported out of the nucleus and into the cytoplasm of eukaryotes were proteins are formed through a process called translation. A series of 3 nucleotides, or codon, is responsible for coding one amino acid. The amino acids are carried to the site of translation by transfer RNA (tRNA) Long chains of these 20 different amino acids form proteins.")
8
nel DNA B

9
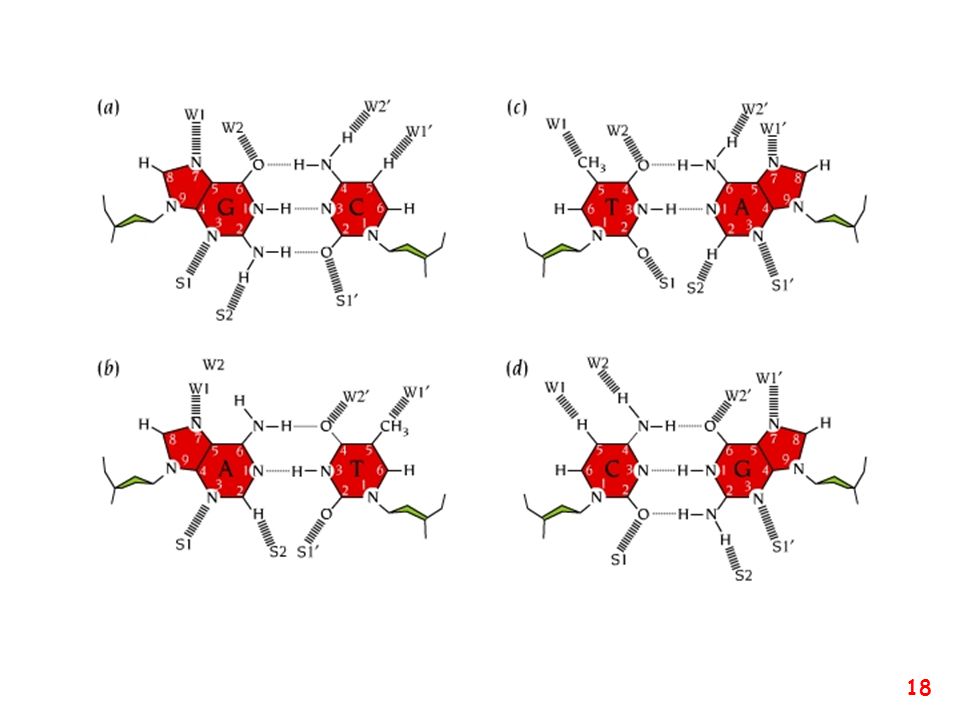
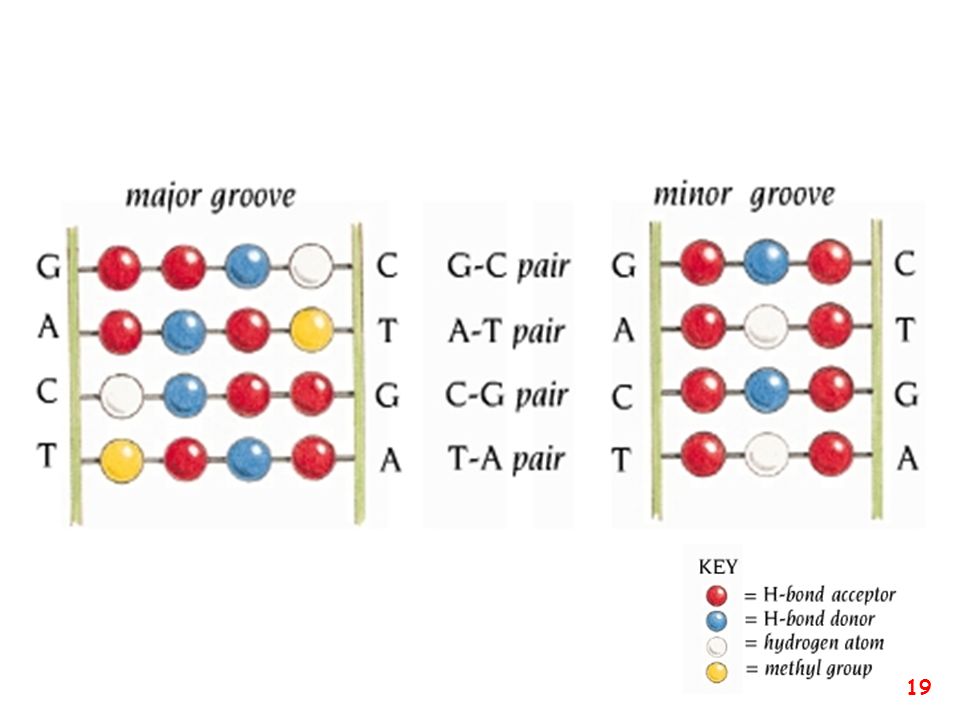
pirimidina purina purina pirimidina

10
T A pirimidina purina C G purina pirimidina

11
3.4 Å

12
3.4 Å x 2.9 Gb = m

14
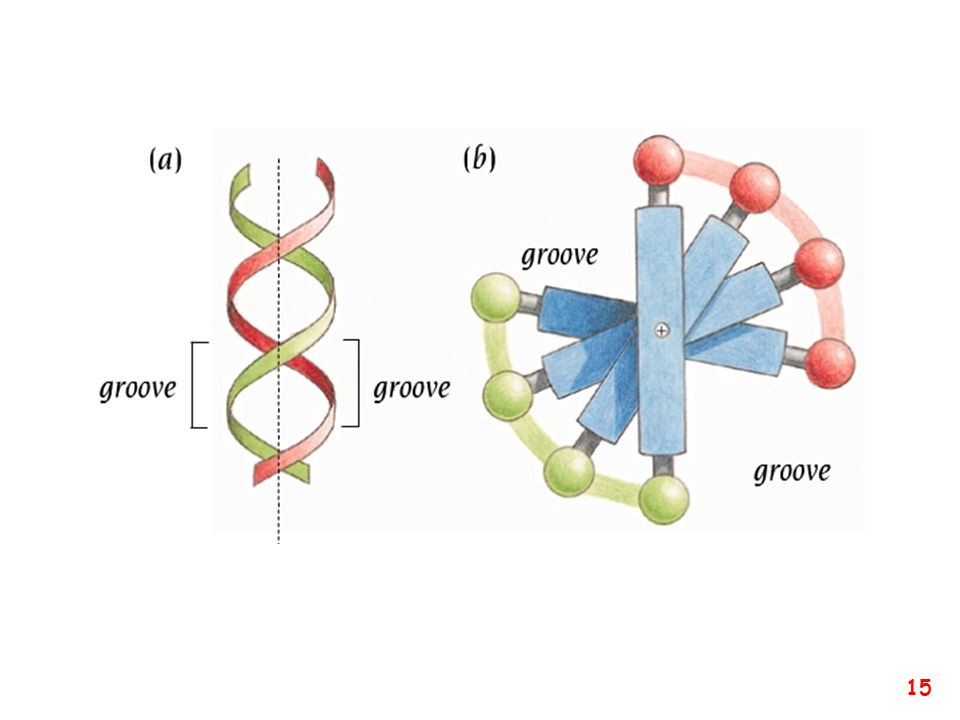
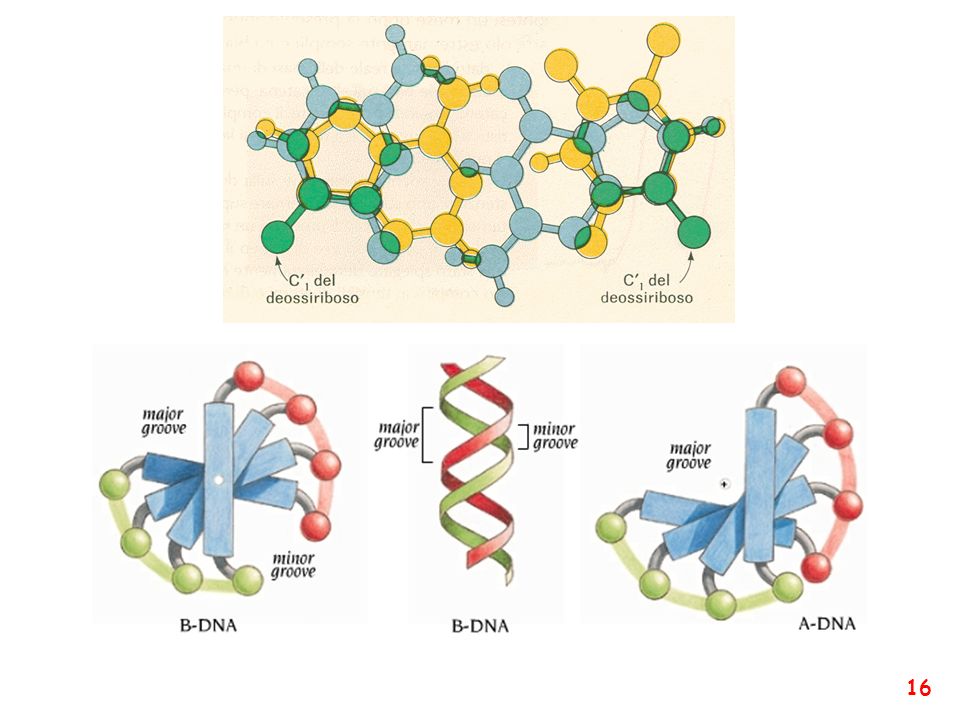
A B Z Caratteristiche delle principali forme di DNA A-DNA B-DNA Z-DNA Senso dell'elica destrorso sinistrorso Unità ripetuta 1 bp 1 bp 2 bp Rotazione/bp 33.6° 35.9° 60°/2bp bp medie/giro 10.7 10.0 12 Inclinazione delle bp rispetto all'asse +19° -1.2° -9° Passo/bp lungo l'asse 2.3 Å 3.32 Å 3.8 Å Passo/giro d'elica 24.6 Å 33.2 Å 45.6 Å Propeller twist medio +18° +16° 0° Diametro 25.5 Å 23.7 Å 18.4 Å ll DNA esiste in diversi tipi di conformazioni. Esse sono denominate A-DNA, B-DNA, C-DNA, D-DNA, E-DNA, H-DNA, L-DNA, P-DNA e Z-DNA. In ogni caso, solo le conformazioni A-DNA, B-DNA e Z-DNA sono state osservate nei sistemi biologici naturali. La conformazione del DNA può dipendere dalla sequenza, dal superavvolgimento, dalla presenza di modificazioni chimiche delle basi o dalle condizioni del solvente, come la concentrazione di ioni metallici. Di tali conformazioni, la conformazione B è la più frequente nelle condizioni standard delle cellule. Le due conformazioni alternative sono differenti dal punto di vista della geometria e delle dimensioni. La forma A è un'ampia spirale destrorsa (il solco minore è largo ma poco profondo, quello maggiore è più stretto e profondo), con un passo di 2,9 nm (circa 11bp) ed un diametro di 2,5 nm. Tale conformazione è presente in condizioni non fisiologiche, quando il DNA viene disidratato. In condizioni fisiologiche, questa conformazione caratterizza gli eteroduplex di DNA e RNA e i complessi formati dalle associazioni DNA-proteina.[51][52] La conformazione Z è tipica invece delle sequenze che presentano modificazioni chimiche come la metilazione, e dei tratti di DNA ricchi di basi C e G. Essa assume un andamento sinistrorso, opposto rispetto alla conformazione B.[53] Ha un passo di 4,6 nm ed un diametro di 1,8 nm, il solco maggiore più superficiale e quello minore più stretto; deve il suo nome all'andamento a zig-zag che la caratterizza. Queste strutture inusuali possono essere riconosciute da specifiche Z-DNA-binding proteins, con conseguenze notevoli nella regolazione della trascrizione.
, con un passo di 2,9 nm (circa 11bp) ed un diametro di 2,5 nm. Tale conformazione è presente in condizioni non fisiologiche, quando il DNA viene disidratato. In condizioni fisiologiche, questa conformazione caratterizza gli eteroduplex di DNA e RNA e i complessi formati dalle associazioni DNA-proteina.[51][52] La conformazione Z è tipica invece delle sequenze che presentano modificazioni chimiche come la metilazione, e dei tratti di DNA ricchi di basi C e G. Essa assume un andamento sinistrorso, opposto rispetto alla conformazione B.[53] Ha un passo di 4,6 nm ed un diametro di 1,8 nm, il solco maggiore più superficiale e quello minore più stretto; deve il suo nome all andamento a zig-zag che la caratterizza. Queste strutture inusuali possono essere riconosciute da specifiche Z-DNA-binding proteins, con conseguenze notevoli nella regolazione della trascrizione.")
21
Interazione tra acidi nucleici e proteine

22
Interazione tra acidi nucleici e proteine

23
Interazione tra acidi nucleici e proteine
Dito a zinco

24
Fermatura lampo a leucina

25
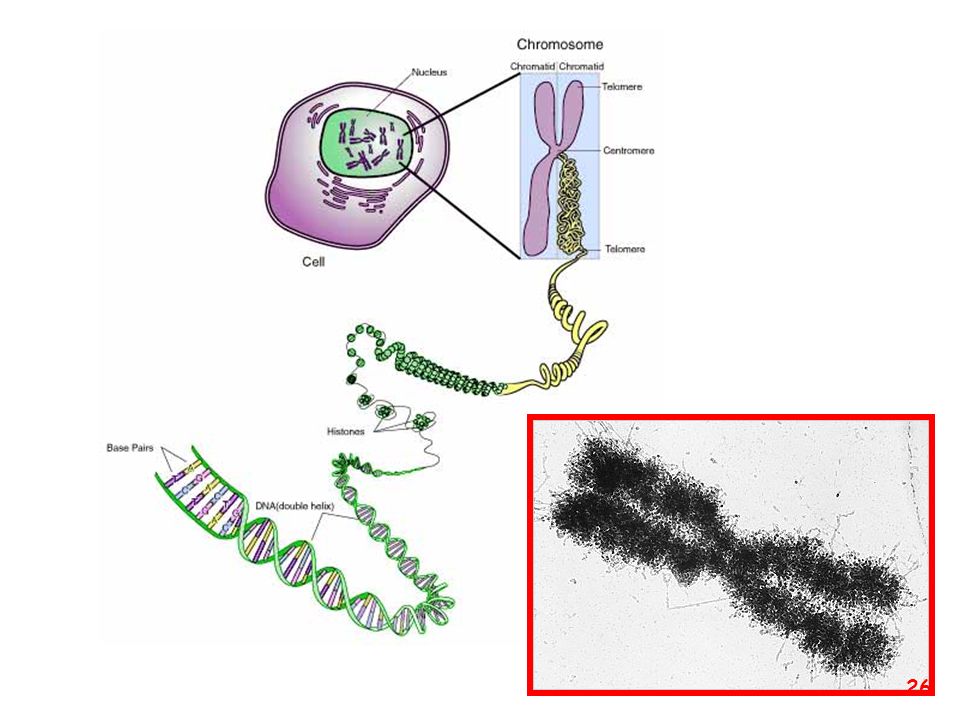
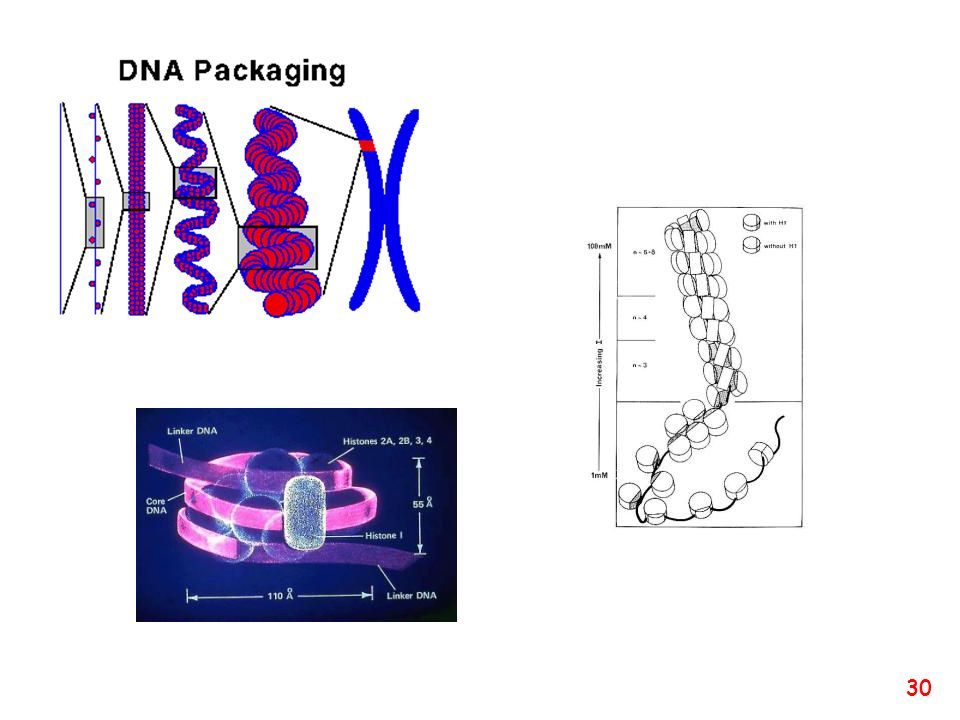
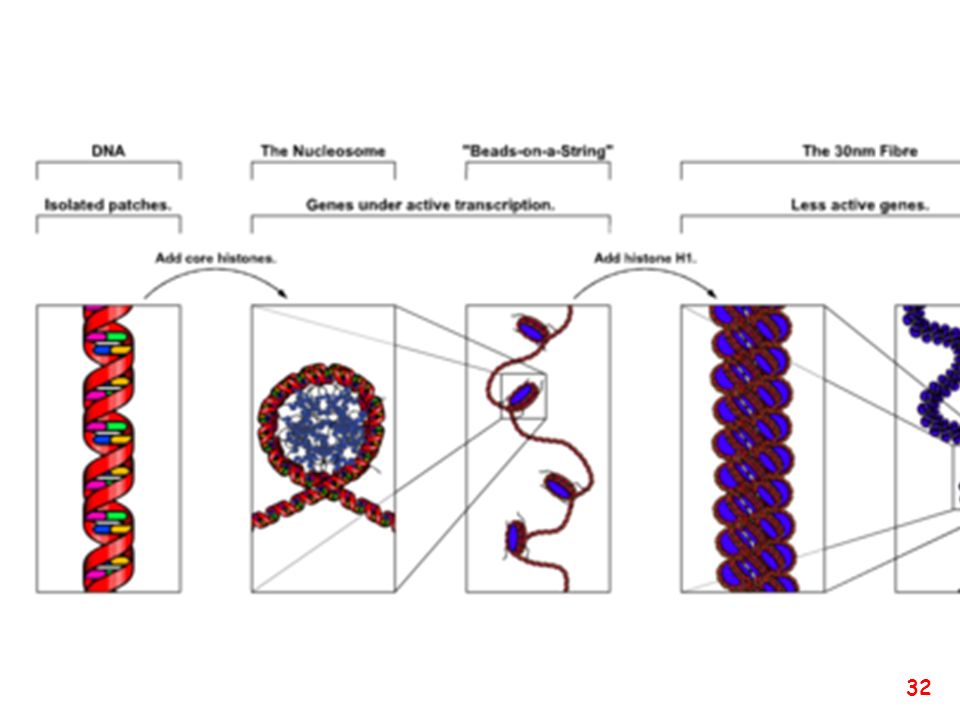
Organizzazione del DNA all’interno della cellula

28
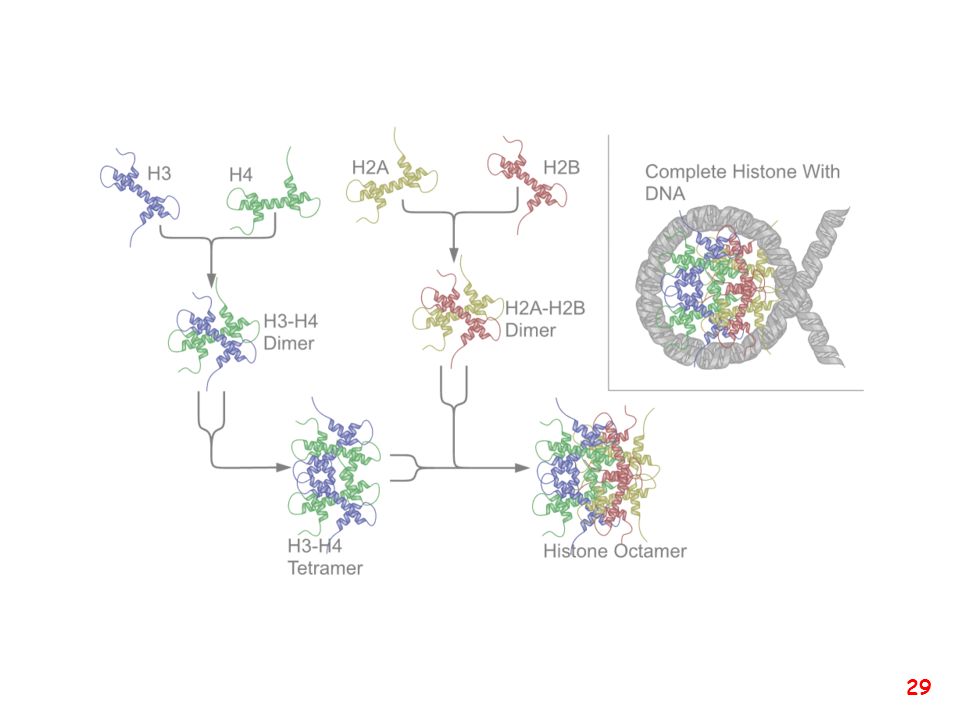
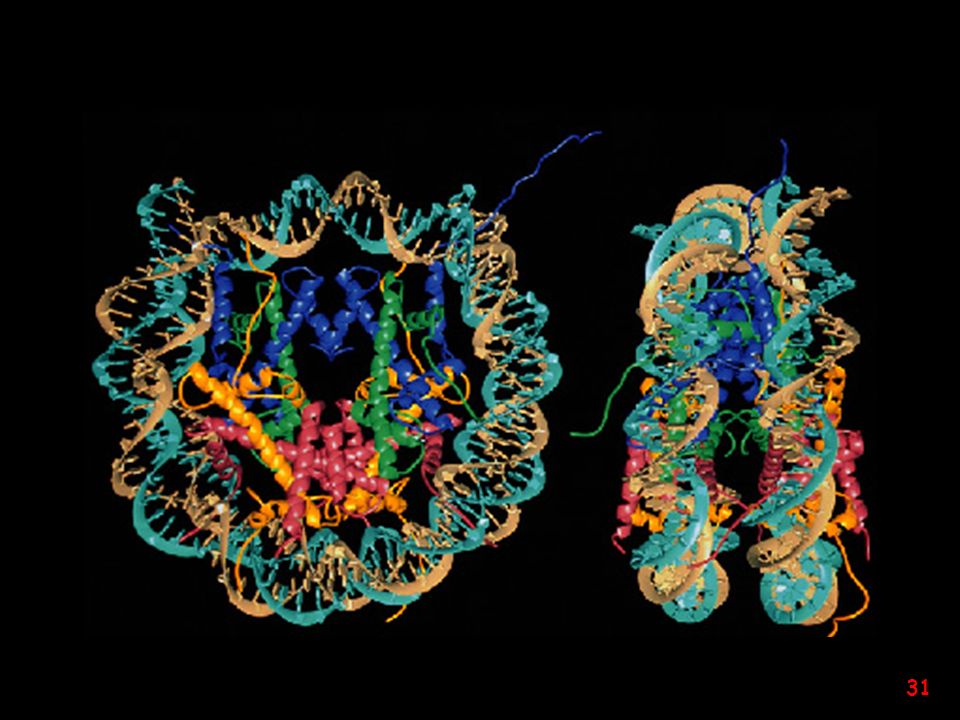
Chromatin is the DNA-protein complex that constitutes chromosomes
Chromatin is the DNA-protein complex that constitutes chromosomes. The major protein component of chromatin is the nucleosome octamer.

34
Acetilazione degli istoni = scompattamento
Deacetilazione degli istoni = compattamento

35
Avvolgimenti e super-avvolgimenti del DNA delle cellule procariotiche

36
In terms of the "3 kingdoms of Life", it looks as though the DNA in Eubacteria is negatively supercoiled, the DNA in Archaebacteria is positively supercoiled, and the DNA in eukaryotes is, on average, wrapped around proteins and not very supercoiled at all, except for small regions around actively transcribed gene

37
Cromosoma di Escherichia coli

38
Human Chromosomes This shows the 23 paired chromosomes of a human male
Human Chromosomes This shows the 23 paired chromosomes of a human male. These little bundles of data carry all the genetic information needed to make a complete guy. This is how chromosomes look when they're not replicating -- so the DNA is tightly coiled.

39
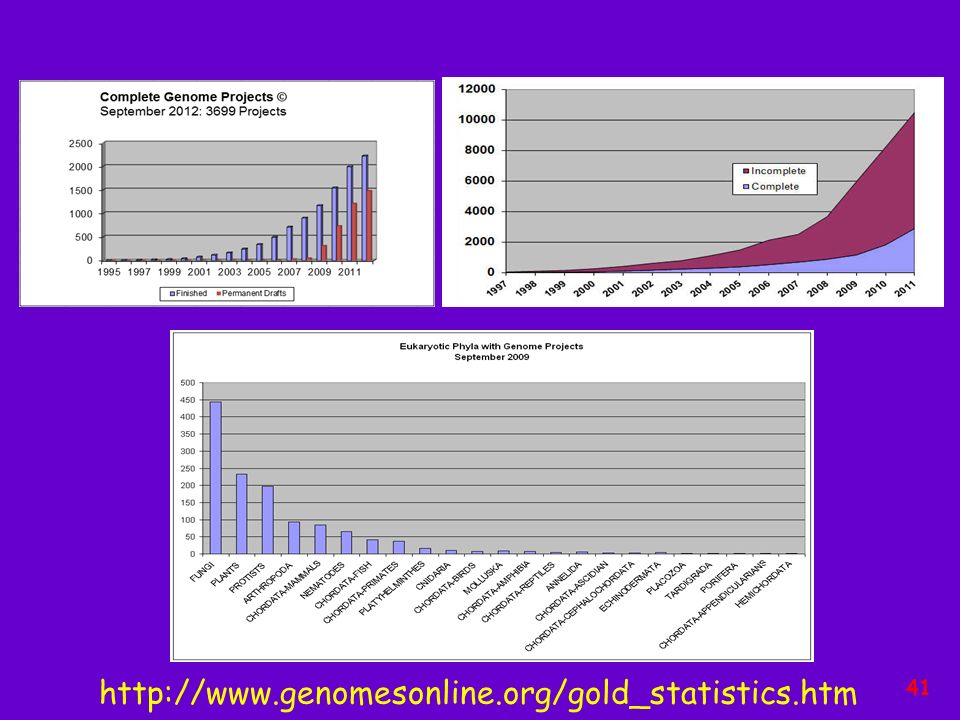
Analisi genomiche

43
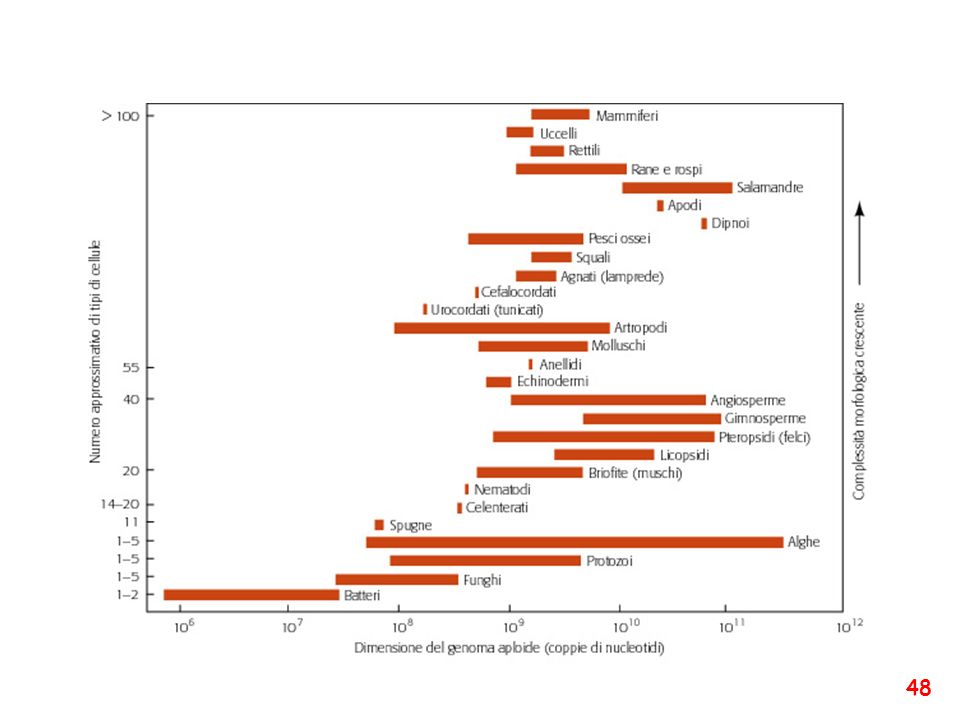
Ad oggi conosciamo il genoma completo di quasi 2000 specie del regno animale e vegetale

44
Il codice a barre della natura
nucleotidi Che c’è? Non hai mai visto un codice a barre? Il DNA barcoding è una metodica molecolare sviluppata per l'identificazione di identità biologiche, che si basa sull'analisi della variabilità di un marcatore molecolare. Nel mondo animale, i cosiddetti metazoi, il marcatore principalmente utilizzato è un frammento del gene mitocondriale, codificante la subunità I della citocromo ossidasi, coxI.

46
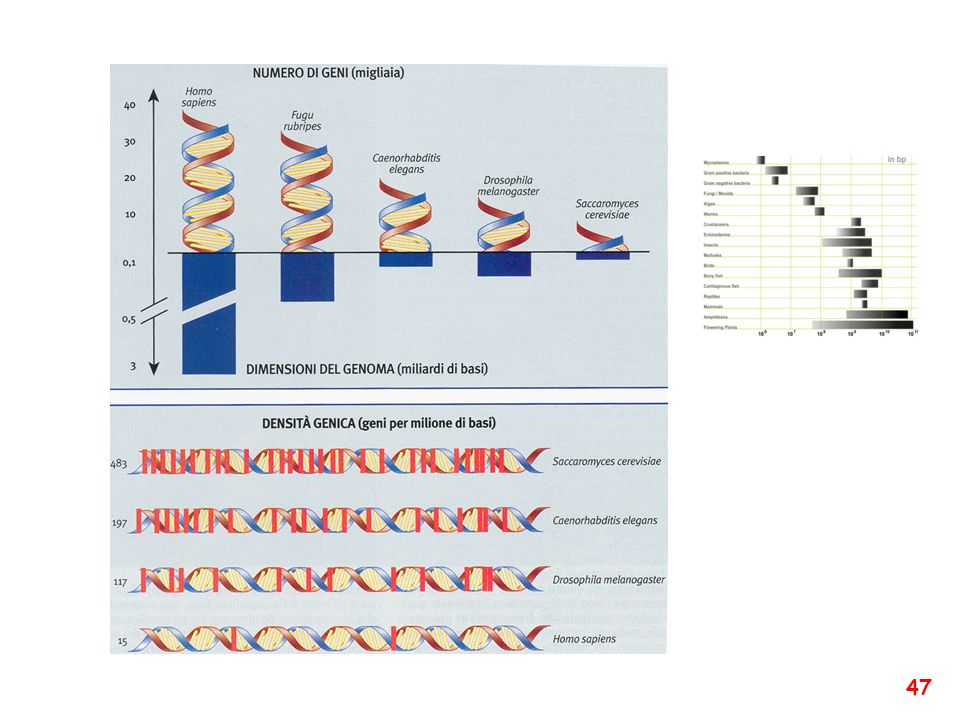
The UK MRC funds the Fugu Genomics Group at the HGMP-RC, as part of its commitment to comparative mapping and sequencing of vertebrate genomes. The group, headed by Greg Elgar, is involved in a number of projects geared towards understanding sequence data generated by the human genome project. Fugu rubripes (the Japanese puffer fish) is particularly suited to this kind of analysis because whilst its 400Mb genome is eight times smaller than human's, it has a similar repertoire of genes. These genome characteristics along with the large evolutionary distance between bony fish and mammals make Fugu a useful tool for studying gene evolution. See Elgar et al., 1999 for further details. Please use the links in the navigation bars at the bottom of this webpage to access areas of the website.
 is particularly suited to this kind of analysis because whilst its 400Mb genome is eight times smaller than human s, it has a similar repertoire of genes. These genome characteristics along with the large evolutionary distance between bony fish and mammals make Fugu a useful tool for studying gene evolution. See Elgar et al., 1999 for further details. Please use the links in the navigation bars at the bottom of this webpage to access areas of the website..")
49
Genoma umano: 3 miliardi di coppie di basi in 46 cromosomi
le 4 basi componenti la doppia elica del DNA frammento di DNA --ATGCGTACTGGTACTAAATGCGTACTGG-- --TAGCCATGACCATGATTTAGCCATGACC-- Adenina (A) Timina (T) Guanina (G) Citosina (C) Genoma umano: 3 miliardi di coppie di basi in 46 cromosomi Genoma umano: 2 metri di DNA suddiviso in 46 cromosomi contenuti in ciascuno dei nostri miliardi di cellule The only cells which lack DNA are the mature red blood cells (erythrocytes). This is because they lack a nucleus, which is where the DNA is found in other cells. Red blood cells also lack mitochondria which themselves have DNA. Therefore they not only lack nuclear DNA, but mitochondrial DNA as well. Genoma suino: 2,7 miliardi di coppie di basi in 38 cromosomi
 Timina (T) Guanina (G) Citosina (C) Genoma umano: 3 miliardi di coppie di basi in 46 cromosomi. Genoma umano: 2 metri di DNA suddiviso in 46 cromosomi contenuti in ciascuno dei nostri miliardi di cellule. The only cells which lack DNA are the mature red blood cells (erythrocytes). This is because they lack a nucleus, which is where the DNA is found in other cells. Red blood cells also lack mitochondria which themselves have DNA. Therefore they not only lack nuclear DNA, but mitochondrial DNA as well. Genoma suino: 2,7 miliardi di coppie di basi in 38 cromosomi.")
50
Genoma umano: 3 miliardi di coppie di basi in 46 cromosomi
Mappatura del genoma umano (6 aprile 2000) = decodifica della sequenza dei 3 miliardi di coppie di basi ed individuazione dei geni gene = istruzione per costruire le molecole della vita (le proteine) --ATGCGTACTGGTACTAAATGCGTACTGG-- --TAGCCATGACCATGATTTAGCCATGACC-- 1,2 miliardi di coppie di basi Genoma umano: 3 miliardi di coppie di basi in 46 cromosomi fritillaria 130 miliardi di paia di basi in 36 cromosomi Impossibile fare gerarchie da lunghezze di DNA o numero di cromosomi Genoma suino: 2,7 miliardi di coppie di basi in 38 cromosomi
 = decodifica della sequenza dei 3 miliardi di coppie di basi ed individuazione dei geni. gene = istruzione per costruire le molecole della vita (le proteine) --ATGCGTACTGGTACTAAATGCGTACTGG-- --TAGCCATGACCATGATTTAGCCATGACC-- 1,2 miliardi di coppie di basi. Genoma umano: 3 miliardi di coppie di basi in 46 cromosomi. fritillaria. 130 miliardi di paia di basi in 36 cromosomi. Impossibile fare gerarchie da lunghezze di DNA o numero di cromosomi. Genoma suino: 2,7 miliardi di coppie di basi in 38 cromosomi.")
51
Impossibile fare gerarchie da lunghezze di DNA o numero di cromosomi
--ATGCGTACTGGTACTAAATGCGTACTGG-- --TAGCCATGACCATGATTTAGCCATGACC-- Impossibile fare gerarchie da lunghezze di DNA o numero di cromosomi

52
mappatura dei microsatelliti
--ATGCGTACTGGTACTAAATGCGTACTGG-- --TAGCCATGACCATGATTTAGCCATGACC-- microsatelliti: sequenze ripetute da 10 a 100 volte di DNA (privo di geni) costituite da unità di ripetizione molto corte (1-5 bp) CA GT 2 bp ripetute 8 volte I microsatelliti sono utilizzabili come marcatori molecolari
 costituite da unità di ripetizione molto corte (1-5 bp) CA. GT. 2 bp ripetute 8 volte. I microsatelliti sono utilizzabili come marcatori molecolari.")
53
mappatura dei microsatelliti
--ATGCGTACTGGTACTAAATGCGTACTGG-- --TAGCCATGACCATGATTTAGCCATGACC--

54
mappatura dei microsatelliti --ATGCGTACTGGTACTAAATGCGTACTGG--
--TAGCCATGACCATGATTTAGCCATGACC--

55
Biotecnologie - Ingegneria molecolare a DNA

Presentazioni simili