Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Banche dati biologiche
Bionformatica Banche dati biologiche NBRF (1970) EMBL (1980), GenBank e DDBJ (1986) PROSITE, EPD (1985) PDB (Protein Data Bank) Sistemi di interrogazione: SRS Entrez Metodologie bio-computazionali Programmi per la ricerca di similarità delle sequenze (BLAST e FASTA Studi di evoluzione molecolare Predizioni di strutture di RNA Predizioni di strutture secondarie proteiche Predizioni di strutture tridimensionali proteiche
 EMBL (1980), GenBank e DDBJ (1986) PROSITE, EPD (1985) PDB (Protein Data Bank) Sistemi di interrogazione: SRS. Entrez. Metodologie bio-computazionali. Programmi per la ricerca di similarità delle sequenze (BLAST e FASTA. Studi di evoluzione molecolare. Predizioni di strutture di RNA. Predizioni di strutture secondarie proteiche. Predizioni di strutture tridimensionali proteiche.")
2
La bioinformatica Nasce negli anni 70 quando vennero pubblicate le prime sequenze nucleotidiche e cominciò a nascere l’esigenza di avere a disposizione sistemi informatici per l’archiviazione e l’analisi di dati di sequenza che sono state prodotte nel futuro in grande quantità. Compiti della bioinformatica: Mettere a punto dei sistemi idonei per collezionare ed interrogare l’enorme mole di dati biologici. Progettazione, implementazione ed applicazione di metodi matematico-statistici rivolti - alla caratterizzazione funzionale delle sequenza biologiche, - a studi di evoluzione molecolare - a studi strutturali degli acidi nucleici e delle proteine.

3
Genetic Computer Group
Tre pacchetti per analizzare i dati: Genetic Computer Group (commerciale) Phylip Analisi di evoluzione molecolare EMBOSS Infrastrutture bioinformatiche: EBI (UK) EMBL NCBI GenBank Expasy Sanger SIB EMBnet
 Phylip. Analisi di evoluzione molecolare. EMBOSS. Infrastrutture bioinformatiche: EBI (UK) EMBL NCBI GenBank Expasy Sanger SIB EMBnet")
4
Programma del corso Le lezioni in laboratorio riguarderanno i seguenti argomenti: - Elementi di base di Informatica e Programma Access - Interrogazione di banche dati biologiche usando Entrez, SRS etc. - Ricerca in banche dati di sequenze nucleotidiche. - Ricerca in banche dati di sequenze e strutture proteiche. - Studio ed utilizzo di banche dati di geni e trascrittomi. - Allineamento di sequenze di acidi nucleici e di proteine mediante i programmi BLAST e FASTA. - Utilizzo di algoritmi per allineamenti multipli globali e locali e per la costruzione di alberi filogenetici (ad es. i programmi CLUSTAL e PHYLIPS). - Predizione della struttura secondaria di RNA. - Ricerca di motivi e pattern funzionali in proteine. - Programmi per la predizione della struttura secondaria (metodi statistici e neural network). - Programmi per la visualizzazione grafica di strutture proteiche. - Programmi per la predizione di struttura tridimensionale delle proteine. - Banche dati di interazioni proteiche e programmi di docking.
. - Predizione della struttura secondaria di RNA. - Ricerca di motivi e pattern funzionali in proteine. - Programmi per la predizione della struttura secondaria (metodi statistici e neural network). - Programmi per la visualizzazione grafica di strutture proteiche. - Programmi per la predizione di struttura tridimensionale delle proteine. - Banche dati di interazioni proteiche e programmi di docking.")
5
Esercitazioni: Ricerca in banche dati di sequenze nucleotidiche (EMBL, GenBank) e proteiche (SWISSPROT, Uni-Prot) Ricerca in banche dati di strutture proteiche (PDB, CATH e SCOP) Utilizzo del programma Access Interrogazione in banche dati mediante SRS Localizzazione di un gene sul genoma umano mediante Ensembl. - Predizione di geni codificanti proteine in sequenze genomiche. - Determinazione della struttura di un gene mediane il confronto tra la sequenza genomica e l’mRNA maturo. - Analisi di sequenze proteiche (peso molecolare, punto isoelettrico) utilizzando i tools sul sito Expasy. - Predizione della struttura secondaria di una proteina di cui è nota la sequenza mediante i programmi JPred e PsiPred. - Modellamento per omologia della struttura tridimensionale di una proteina a partire dalla sola sequenza usando SwissModel.
 Utilizzo del programma Access. Interrogazione in banche dati mediante SRS. Localizzazione di un gene sul genoma umano mediante Ensembl. - Predizione di geni codificanti proteine in sequenze genomiche. - Determinazione della struttura di un gene mediane il confronto tra la sequenza genomica e l’mRNA maturo. - Analisi di sequenze proteiche (peso molecolare, punto isoelettrico) utilizzando i tools sul sito Expasy. - Predizione della struttura secondaria di una proteina di cui è nota la sequenza mediante i programmi JPred e PsiPred. - Modellamento per omologia della struttura tridimensionale di una proteina a partire dalla sola sequenza usando SwissModel.")
6
Scopo di realizzare una banca dati
Consentire la consultazione e l’analisi delle informazioni in essa contenute e di ogni altra informazione a esse correlate e memorizzate in altre banche dati Tipi di banche dati: Primarie o derivate Nelle banche dati primarie sono presenti solo le informazioni minime necessarie da associare ai dati per identificarli al meglio. Le banche dati derivate contengono invece insiemi di dati omogenei che possono derivare da banche dati primarie, ma rivisti e annotati con varie informazioni che danno un valore aggiunto alla banca dati stessa. Non Curate o curate Le banche dati non curate contengono i dati grezzi così come sono forniti da chi li ha ottenuti, o con annotazioni da sistemi automatici. Le banche dati curate presentano informazioni che sono verificate, confrontate con quelle di altre banche dati, opportunamente corrette (o per lo meno con segnalazione di possibili errori e conflitti con altri dati) Relazionali Nelle banche dati relazionali i dati sono gestiti come tabelle, tutte correlate tra loro (ACCESS è un esempio di programma per creare database).
 Relazionali. Nelle banche dati relazionali i dati sono gestiti come tabelle, tutte correlate tra loro (ACCESS è un esempio di programma per creare database).")
7
Banche dati biologiche
Una banca dati biologica raccoglie informazioni e dati derivanti dalla letteratura e da analisi effettuate sia in laboratorio sia attraverso analisi bioinformatiche. Ogni banca dati biologica è caratterizzata da un elemento biologico centrale che costituisce l’oggetto principale intorno al quale viene costruita la entry della banca dati. Esempi di elemento centrale: 1) la sequenza nucleotidica di DNA nelle banche dati di acidi nucleici 2) promotore nelle banche dati di promotori eucariotici. Ciascuna entry raccoglie tutte le informazioni che caratterizzano l’elemento centrale.
 la sequenza nucleotidica di DNA nelle banche dati di acidi nucleici. 2) promotore nelle banche dati di promotori eucariotici. Ciascuna entry raccoglie tutte le informazioni che caratterizzano l’elemento centrale.")
8
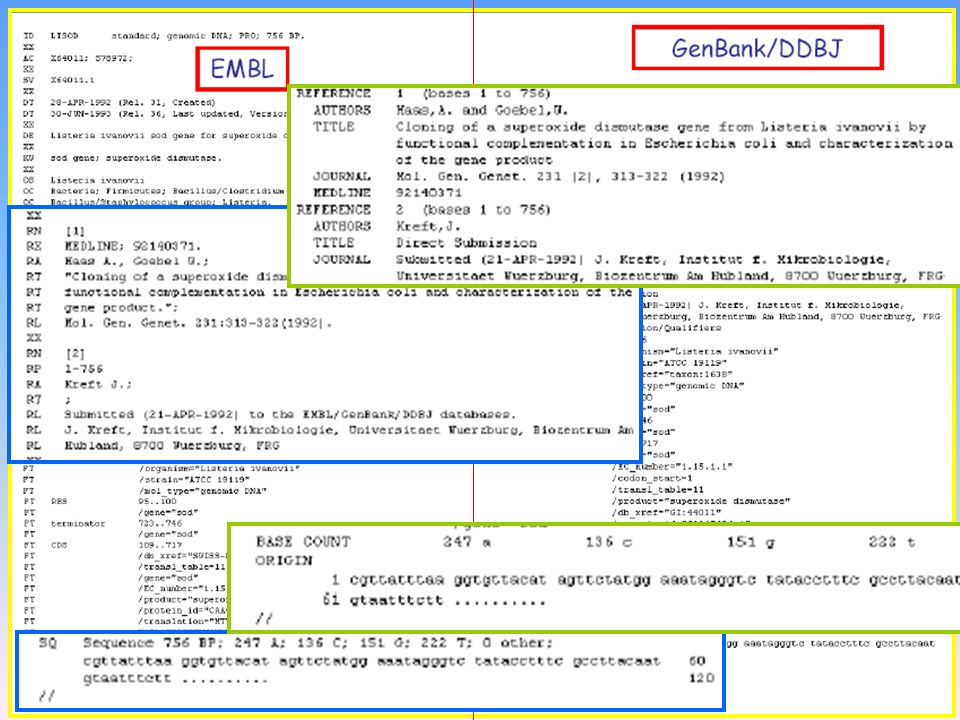
Esempio entry in EMBL File flat-file File sequenziale nel quale ogni classe di informazione è riportata su una o più linee consecutive identificate da un codice a sinistra caratterizzante gli attributi annotati nella linea stessa. Vantaggi: 1. Molto semplice da creare 2. Facilmente analizzabile da diversi programmi Svantaggi: Dati eterogenei difficilmente maneggiabili

9
Codici in un File flat-file
Ogni sequenza inviata al database viene contrassegnata da un accession number (AC) permanente per l’entry. Viene anche assegnata una entry name (ID). Altre informazioni annotate: DT: date di creazione e aggiornamento KW: parole chiave per la descrizione OS: nome della specie OC: classificazione tassonomica RN, RA, RT, RL: informazioni sulla bibliografia FT: regioni funzionalmente caratterizzate SQ: sequenza nucleotidica
 permanente per l’entry. Viene anche assegnata una entry name (ID). Altre informazioni annotate: DT: date di creazione e aggiornamento. KW: parole chiave per la descrizione. OS: nome della specie. OC: classificazione tassonomica. RN, RA, RT, RL: informazioni sulla bibliografia. FT: regioni funzionalmente caratterizzate. SQ: sequenza nucleotidica.")
10
Tipi di banche dati: Riferimenti scientifici Sequenze nucleotidiche Sequenze proteiche Strutture Proteiche Interazioni tra molecole dati di espressione genica malattie genetiche pathway biochimici Sequenze nucleotidiche: GenBank EMBL LocusLink GeneCards RefSeq UniGene Ensembl Proteine SwissProt UniProt PROSITE PDB ENZYME CATH SCOP PDBsum Altre banche dati : PubMed OMIM UTR 2DPAGE IARC P53

11
Tipi di banche dati: Banche dati di letteratura scientifica (PubMed) Banche dati di sequenze nucleotidiche (EMBL, GenBank, DDBJ) Banche dati di geni (LocusLink, GeneCards, RefSeq, UniGene) Banche dati di genomi (Ensembl) Banche dati di prodotti di trascrizione (dbEST, UniGene) Banche dati di profili di espressione (GEO, ArrayExpress) Banche dati di polimorfismi e mutazioni (dbSNPs, HGMD) Banche dati di sequenze proteiche (SwissProt, UniProt, PIR) Banche dati di motivi e domini proteici (PROSITE, Pfam) Banche dati di strutture proteiche (PDB, CATH e SCOP) Banche dati di profili di proteomica (OPD) Banche dati di pathways metabolici (ENZYME, PATHWAYS) Banche dati mitocondriali (MITOMAP) Banche dati di malattie genetiche (OMIM)
 Banche dati di genomi (Ensembl) Banche dati di prodotti di trascrizione (dbEST, UniGene) Banche dati di profili di espressione (GEO, ArrayExpress) Banche dati di polimorfismi e mutazioni (dbSNPs, HGMD) Banche dati di sequenze proteiche (SwissProt, UniProt, PIR) Banche dati di motivi e domini proteici (PROSITE, Pfam) Banche dati di strutture proteiche (PDB, CATH e SCOP) Banche dati di profili di proteomica (OPD) Banche dati di pathways metabolici (ENZYME, PATHWAYS) Banche dati mitocondriali (MITOMAP) Banche dati di malattie genetiche (OMIM)")
12
PUBMED (http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?DB=pubmed)
E’ considerata la banca dati per eccellenza della letteratura medica e biologica. E’ consultabile in modo gratuito e permette il link diretto ai siti delle riviste per visionare o scaricare l’articolo (gratuitamente o a pagamento a seconda della policy della rivista). Le ricerche in PubMed possono essere effettuate tramite diverse opzioni: 1. Autore 2. Rivista 3. Parole chiave usando anche le possibilità offerte dal database Esercizio: Ricerchiamo gli articoli che negli ultimi 3 anni riguardano gli “amminacidi” usando l’opzione Limits
. Le ricerche in PubMed possono essere effettuate tramite diverse opzioni: 1. Autore. 2. Rivista. 3. Parole chiave. usando anche le possibilità offerte dal database. Esercizio: Ricerchiamo gli articoli che negli ultimi 3 anni riguardano gli amminacidi usando l’opzione Limits.")
13
Esempio PUBMED

14
Esempio Risultato (febbraio 2007)
")
15
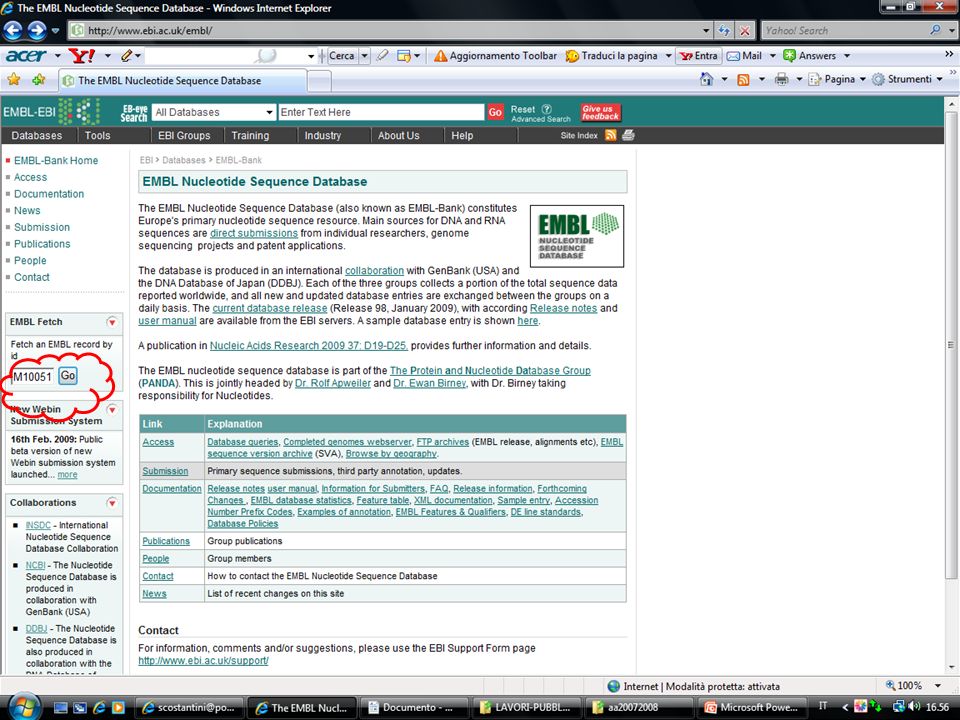
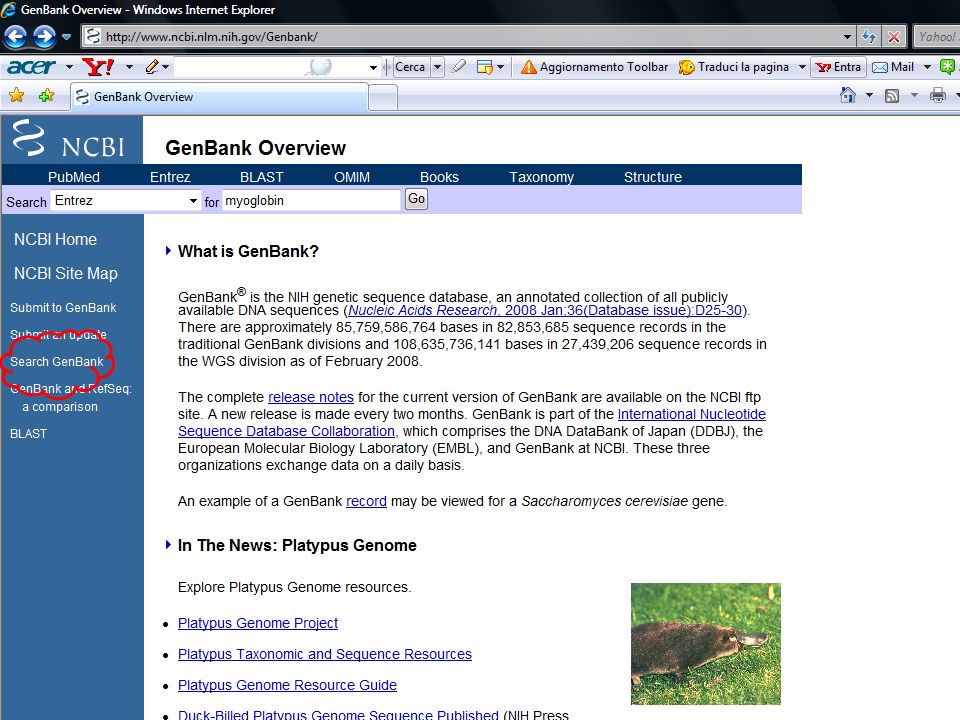
Banche dati di sequenze nucleotidiche
EMBL (Inghilterra) GenBank (America) DDBJ (Giappone) Per ogni sequenza le informazioni riportate sono identiche anche se la struttura dei file è abbastanza diversa
 GenBank (America) DDBJ (Giappone) Per ogni sequenza le informazioni riportate sono identiche anche se la struttura dei file è abbastanza diversa.")
17
Banche dati di sequenze nucleotidiche
Esercizi: Ricercare la sequenza nucleotidica che corrisponde all’Accession number M10051 in EMBL. 2. Ricercare in GenBank tutte le entry che corrispondono al termine “myoglobin” 3. Confrontare le entry nelle due banche dati se ricerchiamo in entrambe all’Accession number M10051

21
UNIPROT (http://www.pir.uniprot.org)
E’ la banca dati di riferimento per le sequenze proteiche. Deriva da un consorzio tra: 1. SWISSPROT ( banca dati originale, sviluppata in Svizzera. E’ una banca dati altamente curata, con alto livello di annotazione (descrizione della proteina, delle funzioni, della sua struttura, di modificazioni post-traslazionali e post-trasduzionali, di varianti, di polimorfismi etc), alto livello di integrazione con altri database, basso livello di ridondanza. Questa banca dati ci fornisce entry di formato flat-file che si differenzia da quello di EMBL soprattutto per qunto riguarda le features che descrivono nelle proteine la presenza di aa modificati, regioni peptidiche corrispondenti ad isoforme, domini strutturali e siti di polimorfismi 2. TREMBL ( banca dati di sequenze proteiche ottenute tramite traduzione delle sequenze nucleotidiche contenute in EMBL, annotate automaticamente. Di queste sequenze annotate una parte che costituisce SPTREMBL è inserita in SWISSPROT mentre la parte relativa alle proteine immunologiche è raccolta in REMTREMBL. In SRS con il termine SWALL è indicato l’insieme di SWISSPROT+ SPTREMBL. 3. PIR ( altra banca dati di sequenze proteiche sviluppata negli USA. E’ molto curata e ben annotata, ma è poco integrata con altri database e quindi offre minori vantaggi nel suo uso.
, alto livello di integrazione con altri database, basso livello di ridondanza. Questa banca dati ci fornisce entry di formato flat-file che si differenzia da quello di EMBL soprattutto per qunto riguarda le features che descrivono nelle proteine la presenza di aa modificati, regioni peptidiche corrispondenti ad isoforme, domini strutturali e siti di polimorfismi. 2. TREMBL ( banca dati di sequenze proteiche ottenute tramite traduzione delle sequenze nucleotidiche contenute in EMBL, annotate automaticamente. Di queste sequenze annotate una parte che costituisce SPTREMBL è inserita in SWISSPROT mentre la parte relativa alle proteine immunologiche è raccolta in REMTREMBL. In SRS con il termine SWALL è indicato l’insieme di SWISSPROT+ SPTREMBL. 3. PIR ( altra banca dati di sequenze proteiche sviluppata negli USA. E’ molto curata e ben annotata, ma è poco integrata con altri database e quindi offre minori vantaggi nel suo uso.")
22
Dal sito UniProt UniProt has three components, each optimized for different uses. The UniProt Knowledgebase (UniProtKB) is the central access point for extensive curated protein information, including function, classification, and cross-reference. The UniProt Reference Clusters (UniRef) databases combine closely related sequences into a single record to speed searches. The UniProt Archive (UniParc) is a comprehensive repository, reflecting the history of all protein sequences.
 is the central access point for extensive curated protein information, including function, classification, and cross-reference. The UniProt Reference Clusters (UniRef) databases combine closely related sequences into a single record to speed searches. The UniProt Archive (UniParc) is a comprehensive repository, reflecting the history of all protein sequences.")
23
Esempio UniProt home page

24
Esempio di output

25
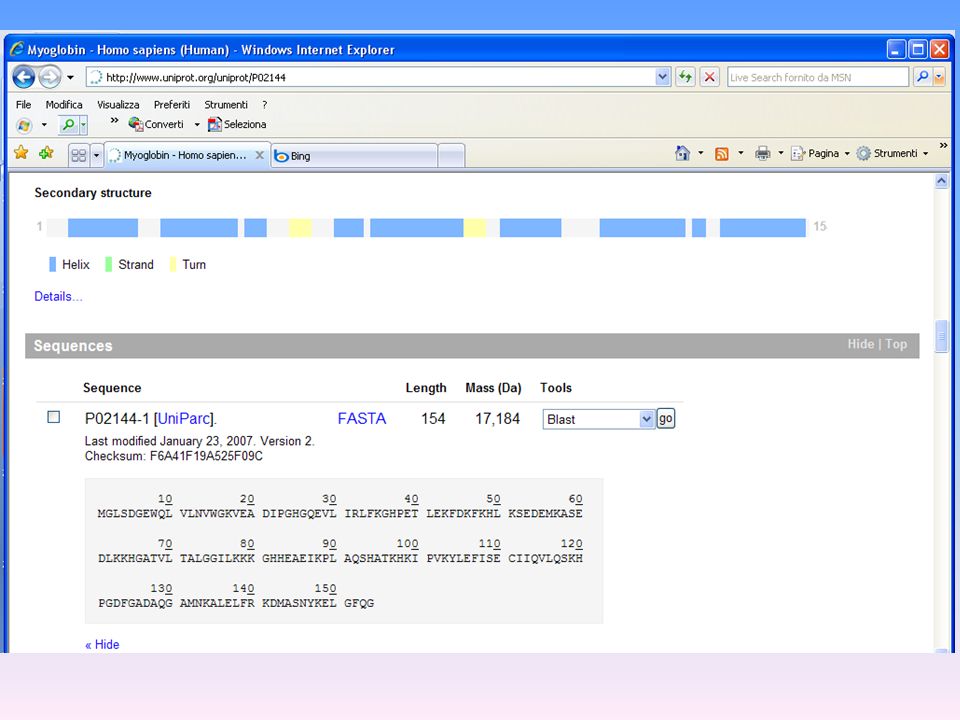
Se clicco su MYG_HUMAN

28
Database di STRUTTURE PDB ( Banca dati di riferimento per i dati strutturali 3D di proteine, comprendente le coordinate atomiche determinate attraverso analisi cristallografiche ai raggi X, analisi NMR o altre tecniche (microscopia elettronica etc.). Comprende anche una sezione dedicata alle strutture delle proteine determinate tramite metodi computazionali. Anche in questo caso è stato recentemente creato un consorzio tra le tre organizzazioni responsabili del mantenimento dei server: RCSB (USA), MSD-EBI (EU) e PDBj (Giappone) MMDB [Entrez's Molecular Modeling Database] NDB ( : banca dati di strutture di acidi nucleici, soli o assieme a proteine CSD ( : banca dati di strutture di piccole molecole organiche ed organometalliche
. Comprende anche una sezione dedicata alle strutture delle proteine determinate tramite metodi computazionali. Anche in questo caso è stato recentemente creato un consorzio tra le tre organizzazioni responsabili del mantenimento dei server: RCSB (USA), MSD-EBI (EU) e PDBj (Giappone) MMDB [Entrez s Molecular Modeling Database] db=Structure. NDB ( : banca dati di strutture di acidi nucleici, soli o assieme a proteine. CSD ( : banca dati di strutture di piccole molecole organiche ed organometalliche.")
29
Esempio HomePage PDB 2MM1

30
Esempio di file PDB

32
Altre banche dati che riguardano la struttura delle proteine:
DSSP (Dictionary of Protein Secondary Structure) raccolta delle strutture secondarie. Programma: Database HSSP (Homology derived Secondary Structure of Proteins) contiene informazioni utili per costruire modelli di proteine. Database FSSP (Fold classification based on Secondary Structure alignment of Proteins) include l’allineamento con le proteine di struttura simile e riporta i residui che sono equivalenti nelle strutture. PDBsum ( riassume per ogni proteina tutte le informazioni derivanti dalle varie banche dati correlati. SCOP [Structural Classification of Proteins] ( organizza le strutture proteiche gerarchicamente seguendo criteri evolutivi e di similarità strutturale. CATH ( presenta una classificazione strutturale simile a quellla offerta da SCOP, basata su confronti di strutture.
 raccolta delle strutture secondarie. Programma: Database HSSP (Homology derived Secondary Structure of Proteins) contiene informazioni utili per costruire modelli di proteine. Database FSSP (Fold classification based on Secondary Structure alignment of Proteins) include l’allineamento con le proteine di struttura simile e riporta i residui che sono equivalenti nelle strutture. PDBsum ( riassume per ogni proteina tutte le informazioni derivanti dalle varie banche dati correlati. SCOP [Structural Classification of Proteins] ( organizza le strutture proteiche gerarchicamente seguendo criteri evolutivi e di similarità strutturale. CATH ( presenta una classificazione strutturale simile a quellla offerta da SCOP, basata su confronti di strutture.")
33
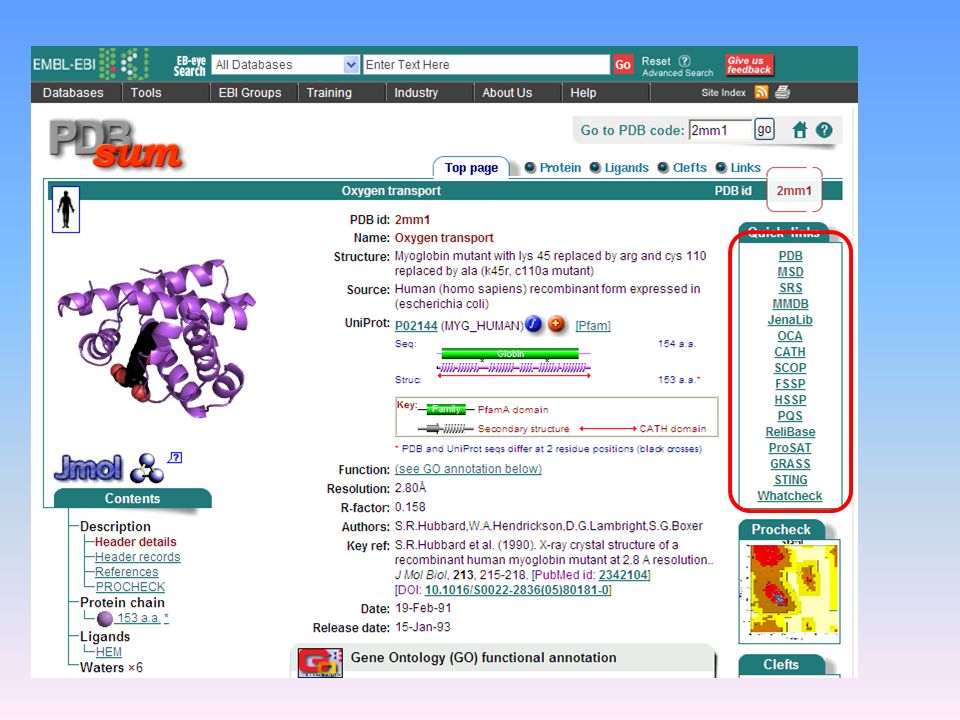
Esempio pagina web PDBsum e risultato di una ricerca

35
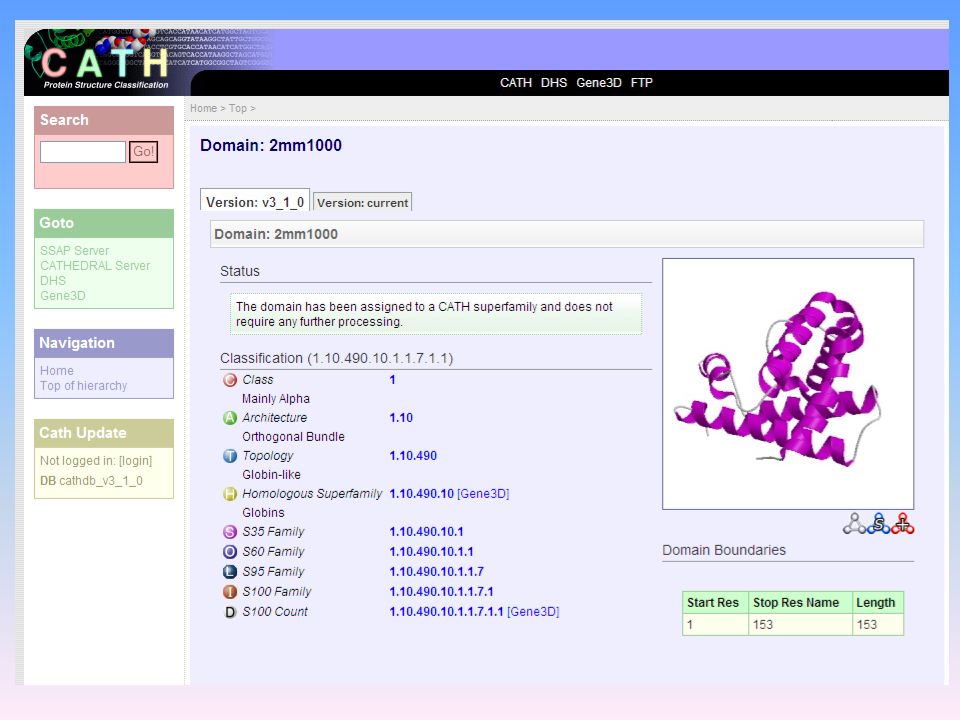
Esempio pagina web CATH

37
Esempio pagina web SCOP

38
Esercizi: Ricercare in CATH e SCOP le entries relative alla keyword “myoglobin” Ricercare in PDBsum l’entry “2MM1” Usare DSSP per assegnare la struttura secondaria della proteina che corrisponde al codice 2MM1

39
HGMD (Human Gene Mutation Database)
Questa banca dati raccoglie i dati presenti in letteratura sulle mutazioni derivanti da alterazioni e disfunzioni geniche. Si annotano solo mutazioni sperimentalmente determinate sul DNA e non sulla proteina, ma le mutazioni silenti sono annotate solo se determinano influenze sullo splicing. Ogni mutazione è associata al fenotipo clinico OMIM (Online Mendelian Inheritance in Man) La banca dati OMIM nasce da un catalogo (MIM) per la raccolta delle informazioni correlate alle malattie genetiche di natura mendeliana. Il database attualmente contiene informazioni non solo su malattie genetiche di tipo autosomico, ma anche su malattie associate ad alterazioni dei cromosomi sessuali e dei mitocondri. Presenta cross-links a diverse altre banche dati. Sistema ENSEMBL ( raccoglie dati relativi alle annotazioni del genoma umano, murino, pesce zebra (Danio rerio) e la zanzara (Anopheles gambiae). Annotare un genoma significa caratterizzare le sue funzioni attraverso la ricerca di dati già determinati o attraverso l’applicazione di metodologie bioinformatiche che consentono di caratterizzare nuove funzioni
 La banca dati OMIM nasce da un catalogo (MIM) per la raccolta delle informazioni correlate alle malattie genetiche di natura mendeliana. Il database attualmente contiene informazioni non solo su malattie genetiche di tipo autosomico, ma anche su malattie associate ad alterazioni dei cromosomi sessuali e dei mitocondri. Presenta cross-links a diverse altre banche dati. Sistema ENSEMBL ( raccoglie dati relativi alle annotazioni del genoma umano, murino, pesce zebra (Danio rerio) e la zanzara (Anopheles gambiae). Annotare un genoma significa caratterizzare le sue funzioni attraverso la ricerca di dati già determinati o attraverso l’applicazione di metodologie bioinformatiche che consentono di caratterizzare nuove funzioni.")
40
Banche dati di motivi e domini proteici
InterPro ( è una risorsa bioinformatica che raccoglie varie informaioni strutturali e funzionali relative ad una proteina o ad una famiglia di proteine. All’interno di InterPro sono comprese varie banche dati: PROSITE ( annota patterns amminoacidici individuati in un set di sequenze proteiche attraverso analisi in silico e studi sperimentali. PRODOM è un database che raccoglie dati relativi a famiglie di proteine generate dall’applicazione di PSI-BLAST, che partendo dal confronto di una sequenza proteica contro un database diproteine, raccoglie in un multiallineamento tutte le sequuenze proteiche per le quali Blast ha determinato uno score più aòtro di un score indicato come threshold. PFAM è una banca dati di famiglie di proteine accomunate da elementi strutturali e funzionali.

41
PRINTS è un database che raccoglie sequenze proteiche in clusters definiti da un comune Fingerprint dove per Fingerprint si intende l’insieme di più motivi conservatie dedotti dall’osservazione di un multiallineamento ottenuto applicando algoritmi per la ricerca di similarità locali. SMART è una risorsa che raccoglie dati relativi a domini proteici e consente la ricerca di domini in nuove sequenze proteiche Esercizio: Ricerca in PRODOM inserendo la parola “myoglobin” in Keyword Search

42
Esempio Prosite

43
Esempio Prosite

44
Sistemi di interrogazione:
Modalità di ricerca dei dati È possibile utilizzare la logica booleana che consente di effettuare intersezioni (AND), somme (OR) ed esclusioni (BUT NOT) di insiemi di dati. Sistemi di interrogazione: SRS Entrez EMBL Genbank PDB MMDB …… ……. Per SRS: Per Entrez:
, somme (OR) ed esclusioni (BUT NOT) di insiemi di dati. Sistemi di interrogazione: SRS Entrez. EMBL Genbank. PDB MMDB. …… ……. Per SRS: -page+srsq2+-noSession. Per Entrez:")
45
ENTREZ (http://www.ncbi.nlm.nih.gov/Database/index.html)
Comprende Medline banca dati bibliografica OMIM malattie mendeliane GenBank sequenze genomiche Taxonomy classificazione degli organismi La ricerca viene fatta sempre usando la combinazione di AND, OR and BUT NOT. Come SRS permette la navigazione tra le varie banche dati disponibili utilizzando il meccanismo dei neighbors Il comando History visualizza tutte le query selezionate nell’ambito però di una singola categoria (nucleotidi, proteine etc). History è l’equivalente di Resuls in SRS I dati associati a ciascuna query possono essere salvati e visualizzati mediante il comando Text
. History è l’equivalente di Resuls in SRS. I dati associati a ciascuna query possono essere salvati e visualizzati mediante il comando Text.")
46
Esercizio con Entrez (http://www.ncbi.nlm.nih.gov/gquery/gquery.fcgi):
Cosa succede se io ricerco inserendo la keyword: myoglobin? Cosa succede se io ricerco inserendo la keyword: myoglobin human?

47
SRS: - consente di interrogare più banche dati contemporaneamente più banche dati biologiche - sfrutta i meccanismi di codifica di cross-referencing e consente la navigazione tra le banche dati Nella top page sono riportati i nomi di tutte le banche dati indicizzate su server e raggruppate in categorie. A sinistra di ciascuna categoria è riportata una box con – quando è visibile l’intero elenco delle banche dati + quando c’è solo un testo succinto che descrive le caratteristiche della banca dati e dei suoi contenuti. Ci sono due possibili Query: Standard Query Form Extended Query Form

48
Le Query usano 3 criteri possibili:
AND: & in SRS OR: | in SRS BUT NOT: ! in SRS Possibili funzioni: Formati di visualizzazione menu View Salvare i dati comando Save Link consente di ottenere informazioni su dati presenti nella banca dati e correlati ai dati associati alla query prescielta. Launch consente di applicare programmi di analisi ai dati di sequenza associati alla query selezionata Tool: Blast, Fasta e Clustal

49
In pratica SRS ci permette di:
1. scegliere i database da utilizzare per la ricerca 2. immettere una o più query concatenate 3. visualizzare i risultati in modo personalizzabile 4. Applicare i programmi di analisi ai risultati ottenuti 5. salvare nel server EBI i risultati di una ricerca e di richiamarli successivamente Esempi pratici ……….

50
Differenze tra Entrez ed SRS:
E’ un sistema disponibile sul sito dell’NCBI ( per interrogare ed estrarre dati dalle più varie banche dati esistenti. Non è commercialmente disponibile e quindi non può essere scaricato ed installato localmente, né è possibile modificare le banche dati implementate sul sistema. SRS – Sequence Retrieval System Il nome può suggerire un uso limitato a “sequenze”. In realtà è un sistema utilizzabile su qualunque tipo di database. Molti centri di ricerca hanno installato SRS sul proprio web server utilizzandolo per offrire un servizio di consultazione di banche dati. Uno dei sistemi SRS più curati è quello presente sul sito dell’EBI (

51
Esercizio usando SRS: Ricercare in UniProt/SWISSProt tutte le sequenze di mioglobine Lanciare un Blast su una sequenza a vostra scelta Selezionare tutte le sequenze e ricercare le strutture corrispondenti nella banca dati PDB Scelta una struttura ricercare le corrispondenti strutture riportate in DSSP Modificare il modo di visualizzare i risultati Salvare i risultati Data una sequenza predire la sua struttura secondaria mediante Garnier

Presentazioni simili



>")

>")












 Web of Science Beilstein e Gmelin Crossfire.>")



