Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Tipi di allineamenti

2
Misura delle similarità di sequenza:
La distanza di Hamming è definita tra due stringhe della stessa lunghezza ed è valutata calcolando il numero di posizioni con caratteri non corrispondenti agtc distanza di Hamming=2 cgta La distanza di Levenshtein è definita tra stringhe che non hanno necessariamente la stessa lunghezza ed è il numero di “operazioni di edit” richieste per cambiare una stringa in un’altra. Per operazioni di edit si intende una delezioni, un’inserzione o l’alterazione di un singolo carattere in entrambe le sequenze. ag-tcc distanza di Levenshtein=3 cgctca

3
SOLUZIONE: DECLENSION RECREATION SOLUZIONE: BIOINFORMATICS
1° Esercizio: Valutare la distanza di Hamming tra DECLENSION e RECREATION 2° Esercizio: Valutare la distanza di Levenshtein tra BIOINFORMATICS e CONFORMATION SOLUZIONE: DECLENSION RECREATION SOLUZIONE: BIOINFORMATICS -CO-NFORMATION

4
Differenza tra i termini similarità ed omologia
Il termine omologia indica che due entità condividono una stessa origine filogenetica, da cui si sono evolute differenziandosi l’una dall’altra Il termine similarità ha un significato più generale che indica una somiglianza prescindendo dalle ragioni che l’hanno determinata. Questa similarità spesso è dovuta ad omologia ma può essere generata dal caso oppure da fenomeni di convergenza adattativa sia a livello morfologico sia a livello molecolare. Ad esempio l’ala di un uccello e quella di un pipistrello si sono evolute indipendentemente l’una dall’altra e pertanto non sono omologhe. Quindi l’omologia è una caratteristica qualitativa, che indica un’origine filogenetica comune. La similarità è una caratteristica quantitativa che sulla base di qualche criterio comparativo indica un livello di somiglianza.

5
SIMILARITA’ DI SEQUENZE ED ALGORITMI DI ALLINEMANTO
L’allineamento dovrebbe portare all’appaiamento delle regioni simili condivise dalle due sequenze. Vari sono i criteri che possono essere utilizzati per misurare la similarità tra due o più sequenze. Il problema è che i concetti di similarità ed allineamento sono intimamente associati: infatti non si possono allineare sequenze senza definire dei criteri di similarità ed allo stesso tempo per valutare quanto due sequenze siano simili è necessario allinearle. Comunque per allineare varie sequenze è necessario disporre anche di un metodo (che in informatica è definito algoritmo) che sulla base dei criteri di similarità sia in grado di produrre un allineamento.
 che sulla base dei criteri di similarità sia in grado di produrre un allineamento.")
6
Quindi Per poter allineare delle sequenze abbiamo bisogno di due cose: Definizione di criteri di similarità Algoritmo

7
Se definissimo come criterio di similarità quello di valutare il numero di lettere che si appaiano esattamente, si potrebbe implementare un semplice algoritmo che faccia virtualmente scorrere una sequenza sull’altra e che valuti ad ogni spostamento tutte le lettere abbinate per stabilire il numero di appaiamenti esatti.

8
L’applicazione di questo algoritmo comporta che ad ogni avanzamento della sequenza si dovranno confrontare tutte le lettere appaiate tra le due sequenze. In questo modo potremo facilmente dimostrare che alla fine si dovranno effettuare un numero di confronti pari al prodotto delle lunghezze delle due sequenze che si vogliono allineare. Infatti ogni lettera della prima sequenza dovrà essere confrontata con ogni lettera dell’altra. Nel nostro caso specifico ci sono complessivamente 30 coppie di lettere appaiate, un numero pari al prodotto delle lunghezze delle due sequenze (5 e 6 amminoacidi). L’efficienza di un algoritmo dipenderà dal tempo impiegato per eseguire le varie operazioni. Questo tempo viene spesso indicato come proporzionale alla lunghezza O(nm) dove n e m sono le lunghezze delle due sequenze che stiamo andando a confrontare.
. L’efficienza di un algoritmo dipenderà dal tempo impiegato per eseguire le varie operazioni. Questo tempo viene spesso indicato come proporzionale alla lunghezza O(nm) dove n e m sono le lunghezze delle due sequenze che stiamo andando a confrontare.")
9
La necessità di effettuare ricerche di similarità in banche dati di sequenze ha determinato una crescente esigenza di disporre di rapidi algoritmi di allineamento. Infatti le ricerche di similarità consistono nel ripetere automaticamente la procedura di allineamento di una data sequenza (definita query) con ognuna delle sequenze della banca dati. In questo modo sarà possibile individuare la sequenza che ha il massimo punteggio di allineamento. La crescita esponenziale delle banche dati ha portato allo sviluppo di programmi (FASTA e BLAST) che sono in grado di effettuare velocemente delle ricerche di similarità, grazie a soluzioni euristiche che sono basate su assunzioni non certe ma estremamente probabili.
 con ognuna delle sequenze della banca dati. In questo modo sarà possibile individuare la sequenza che ha il massimo punteggio di allineamento. La crescita esponenziale delle banche dati ha portato allo sviluppo di programmi (FASTA e BLAST) che sono in grado di effettuare velocemente delle ricerche di similarità, grazie a soluzioni euristiche che sono basate su assunzioni non certe ma estremamente probabili.")
10
Allineamenti di sequenze con gap
La complessità del problema di allineare sequenze di acidi nucleici e di proteine deriva dal fatto che deve essere considerata la possibilità che il migliore allineamento comporti l’inserimento di gap. Questa esigenza è necessaria dal momento che nel corso dell’evoluzione si possono avere processi di inserzione o delezione che comportano una diversa lunghezza di sequenze omologhe. ATGGACCGGATGGATGATGGACCGTTAGGAT ATGGACCGAATGGCTGACGGACCGTGAGGAT ATGGAC.TGGCTGACGGACCGTGAGGAT -CGAA Sostituzioni puntiformi Delezioni ATGGAC.TGGCTGACGGAACTCCGTGAGGAT Inserzioni AGTCCA.TGGCTGACGGAACTCCGTGAGGAT Inversioni

11
Guardate questi due allineamenti:
10 25 Sono stati prodotti rispettivamente senza e con la possibilità di inserire gap. E’ evidente come inserendo un gap in ciascuna delle due sequenze si passa da 10 a 25 appaiamenti esatti.

12
RESPUBLICA RE-PUBLIC-
DOT MATRIX per individuare e localizzare similarità di sequenza anche in presenza di gap che graficamente appaiono come salti in diagonale Sequenza 1 Sequenza 2 Quindi l’allineamento che ne viene fuori sarà: RESPUBLICA RE-PUBLIC-

13
Altro esempio: LAMIAP---RIMASEQ CREATA --MIA-ALTR--ASEQDAALLIN--EARE 10 RESIDUI ALLINEATI

14
Matrici di sostituzione
Le Matrici di sostituzione sono usate quando è opportuno applicare dei criteri di dimilarità che non si limitano a verificare l’identità assoluta ma tengono conto del fatto che gli amminoacidi possano essere più o meno simili tra loro Matrici di sostituzione PAM BLOSUM

15
MATRICI DI SOSTITUZIONE
Le Matrici di sostituzione sono usate quando è opportuno applicare dei criteri di Similarità che non si limitano a verificare l’identità assoluta ma tengono conto del fatto che gli amminoacidi possano essere più o meno simili tra loro. Infatti

16
RICERCA DI SIMILARITA’ E ALLINEAMENTO DI SEQUENZE
BLAST e PSI-BLAST FASTA oppure BCM Search Launcher Pole Bio-Informatique Lyonnais –

17
Alcune caratteristiche dei tools più usati:
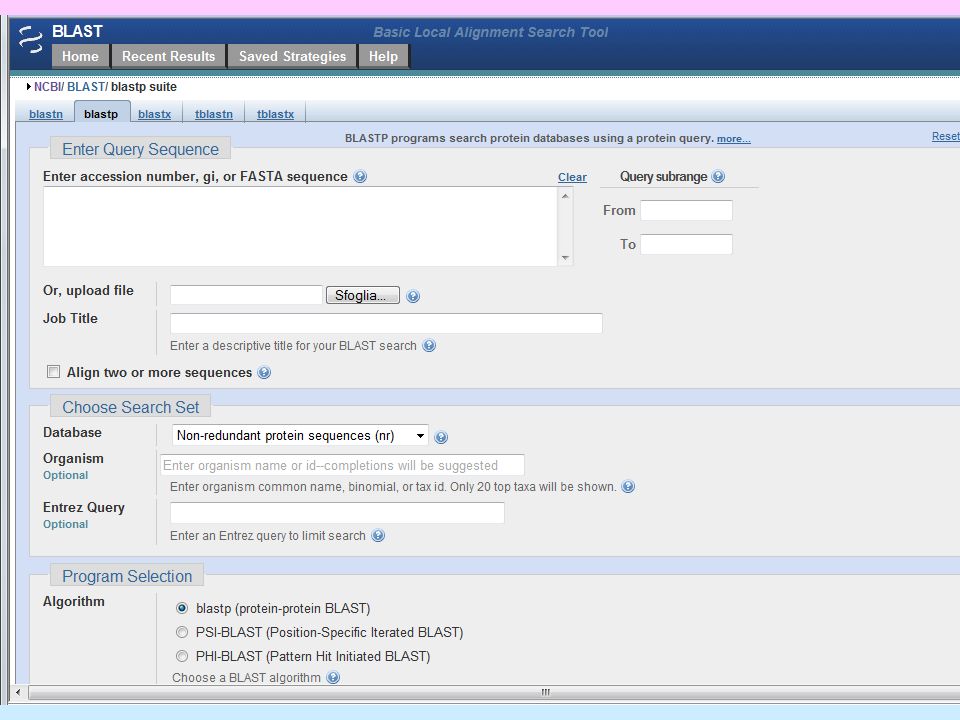
BLAST (Basic Local Alignment Search Tool), sviluppato dal National Center for Biotechnology Information, NCBI): - allineamento locale - estremamente veloce - parte cercando brevi frammenti della sequenza, che poi prova ad estendere - usa una matrice di sostituzione in entrambe le fasi del processo di allineamento (scansione del database e estensione della subsequenza): più preciso ha quattro opzioni fondamentali: BLASTP: confronta sequenze proteiche contro un database proteico BLASTN: confronta sequenze nuclotidiche contro un database nucleotidico TBLASTN: confronta una sequenza proteica contro un database nucleotidico, traducendo ciascuna sequenza del database nucleotidico nei suoi 6 frames di lettura BLASTX: confronta una sequenza nucleotidica contro un database proteico, dopo averla tradotta nei suoi 6 frames di lettura.
, sviluppato dal National Center for. Biotechnology Information, NCBI): - allineamento locale. - estremamente veloce. - parte cercando brevi frammenti della sequenza, che poi prova ad estendere. - usa una matrice di sostituzione in entrambe le fasi del processo di allineamento (scansione del database e estensione della subsequenza): più preciso ha quattro opzioni fondamentali: BLASTP: confronta sequenze proteiche contro un database proteico. BLASTN: confronta sequenze nuclotidiche contro un database nucleotidico. TBLASTN: confronta una sequenza proteica contro un database nucleotidico, traducendo ciascuna sequenza del database nucleotidico nei suoi 6 frames di lettura. BLASTX: confronta una sequenza nucleotidica contro un database proteico, dopo averla tradotta nei suoi 6 frames di lettura.")
18
PSI-BLAST (Position Specific Interated BLAST): modificazione di BLAST che combina elementi sia del metodo di allineamento a coppie che multiplo: usa una ricerca iterativa per cui le sequenze trovate ad ogni ciclo sono usate in allineamento multiplo per costruire un modello di punteggio (profilo, vedi più avanti) per il ciclo successivo. Ad ogni ciclo il profilo viene modulato sempre più finemente. Vantaggi: aumentata sensibilità trova anche omologhi remoti PHI-BLAST (Pattern Hit Initiated BLAST): combina PSI-BLAST con la capacità di identificare pattern regolari I vantaggi di FASTA (FAST-All) (Lipman & Pearson, 1985): 1. alta sensibilità per confronti veloci (prima identifica, poi ottimizza) 2. allineamento locale 3. la fase di estensione produce allineamenti “gapped” 4. usa una matrice di sostituzione solo per la fase di estensione della subsequenza
: combina PSI-BLAST con. la capacità di identificare pattern regolari. I vantaggi di FASTA (FAST-All) (Lipman & Pearson, 1985): 1. alta sensibilità per confronti veloci (prima identifica, poi ottimizza) 2. allineamento locale. 3. la fase di estensione produce allineamenti gapped 4. usa una matrice di sostituzione solo per la fase di estensione della subsequenza.")
19
I valori di default usati da BLAST sono W=3, T=13, Matrice=BLOSUM 62
Suddivide la sequenza in “parole” (3 per le proteine e 11 per gli acidi nucleici Confronta ogni parola con regioni di uguali dimensioni delle sequenze contenute nei database e calcola un valore si score Se lo score è > di un valore soglia T al sotto del quale la similarità è considerata troppo bassa, il programma estende la regione allineata cercando regioni di alta similarità. In questo modo si ottiene un segmento di allineamento locale non ulteriormente estendibile, definito HSP (High-scoring Segment Pair). Il parametro S definisce una soglia di score al di sopra della quale un HSP viene ritenuto degno di attenzione. I valori di default usati da BLAST sono W=3, T=13, Matrice=BLOSUM 62
. Il parametro S definisce una soglia di score al di sopra della quale un HSP viene ritenuto degno di attenzione. I valori di default usati da BLAST sono W=3, T=13, Matrice=BLOSUM 62.")
23
Numero atteso di HSP valutato su base statistica
Dimensione delle parole Scelta della matrice di sostituzione Penalità assegnata ai gap

24
FASTA Suddivide le sequenze in parole (2 per proteine, 6 per acidi nucleici) Trova le parole nelle sequenze del database e calcola un indice in base alla posizione in cui ciascuna parola è trovata all’interno della sequenza query. Calcola la similarità delle dieci regioni con maggiori parole identiche per ciascuna sequenza del database (init1) Calcola la similarità delle dieci regioni con maggiori parole identiche includendo le penalizzazione per inserzioni o delezioni (initN) Allinea le N sequenze con il migliore punteggio initN
 Calcola la similarità delle dieci regioni con maggiori parole identiche includendo le penalizzazione per inserzioni o delezioni (initN) Allinea le N sequenze con il migliore punteggio initN.")
25
FASTA: http://www.ebi.ac.uk/fasta33/
Ktup: lunghezza delle parole Align: numero di allineamenti finali Open e residue: Penalità per i gap Vari database Sequenza in formato FASTA

26
Differenze tra BLAST e FASTA:
Lunghezze delle “parole usate” FASTA si limita ad un’indicizzazione diretta della parola invece BLAST seleziona da ogni parola diverse parole simili (indicate come W-mers). BLAST utilizza una matrice di sostituzione sin dalle prime fasi dell’analisi BLAST è ottimizzato per trovare segmenti di similarità locale privi di gap
. BLAST utilizza una matrice di sostituzione sin dalle prime fasi dell’analisi. BLAST è ottimizzato per trovare segmenti di similarità locale privi di gap.")
27
FASTA: http://fasta. bioch. virginia. edu/fasta_www2/fasta_www. cgi

28
Cliccando su Protein-Protein FASTA
In Program ci sono tutte le possibili opzioni

29
SSEARCH

30
Quante sequenze troviamo? Quante strutture PDB?
Esempio pratico Ricercare la sequenza di myoblobin bovine usando SRS Ricercare in BLAST tutte le sequenze simili alla mioglobina bovina Ricercare in BLAST tutte le strutture PDB simili alla mioglobina bovina Quante sequenze troviamo? Quante strutture PDB? 4. Ripetere la stessa ricerca con FASTA 5. Provare a modificare le matrici di sostituzioni e valutare le differenze.

31
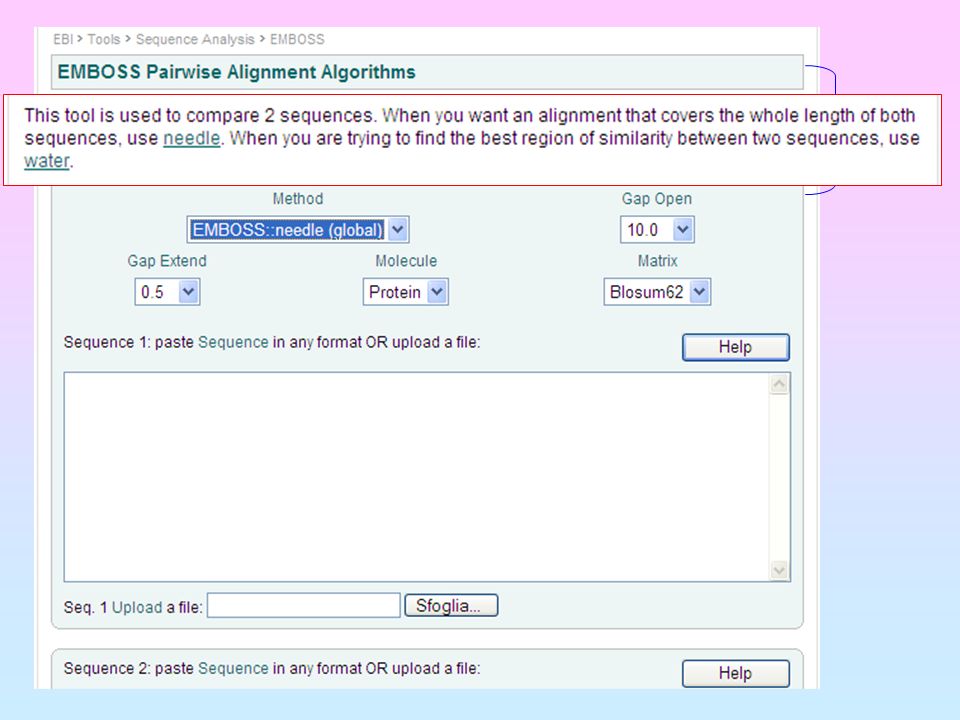
Allineamento di due sequenze:
BLAST: bl2seq LALIGN: EMBOSS:

32
LALIGN:

34
Dal sito Exspasy:

35
ALLINEAMENTO MULTIPLO DI SEQUENZE
Informazione biologica maggiore rispetto a quella riportata l’allineamento di due sole sequenze: i residui più importanti dal punto di vista strutturale o funzionale saranno estremamente conservati tra tutte le sequenze dell’allineamento. “Una sequenza amminoacidica fa la timida; un paio di sequenze omologhe sussurrano; molte sequenze allineate gridano”. Per essere informativo un allineamento multiplo dovrebbe contenere una distribuzione di sequenze sia strettamente sia lontanamente correlate: Svantaggi: •tutte strettamente correlate => ridondanza •tutte lontanamente correlate => allineamento inaccurato => inutilità

36
ALLINEAMENTO MULTIPLO DI SEQUENZE

37
Parametri importanti per la ricerca di omologhi di proteine note:
Sensibilità = riconoscere tutte le correlazioni anche molto lontane Selettività = minimizzare il numero di sequenze trovate che non siano dei veri omologhi Da un allineamento riusciamo a dedurre informazioni sui profili: Un profilo esprime tutta l’informazione contenuta in un multiallineamento: in generale, osservando gli amminoacidi rappresentati, si attribuisce un punteggio a ciascun amminoacido per ogni colonna dell’allineamento (con le matrici di sostituzione) osservandone la conservazione. Analogamente, osservando la frequenze dei gap, si attribuisce una penalità per il loro inserimento.
 osservandone la conservazione. Analogamente, osservando la frequenze dei gap, si attribuisce una penalità per il loro inserimento.")
38
ALLINEAMENTO MULTIPLO DI SEQUENZE
1. 2. CLUSTAL W: il tool più comune utilizzato per l’allineamento multiplo di sequenza: potenziato per allineamenti di sequenze proteiche divergenti favorisce l’apertura di gaps in regioni in cui è potenzialmente presente un loop piuttosto che una struttura secondaria ordinata (in base a una penalità residuo-specifica e a una penalità ridotta in regioni idrofiliche) favorisce l’apertura di gaps nelle stesse posizioni. HMMer: crea profili utilizzando gli HMM e li usa per la ricerca contro una banca dati proteica
 favorisce l’apertura di gaps nelle stesse posizioni. HMMer: crea profili utilizzando gli HMM e li usa per la ricerca contro. una banca dati proteica.")
Presentazioni simili

















>")

>")