Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Classificazione (aka Cluster Analysis)
")
2
Classificazione non gerarchica Classificazione gerarchica divisiva
es. k-means Classificazione gerarchica divisiva Classificazione gerarchica agglomerativa Legame: singolo, completo, medio, … Coefficiente di correlazione cofenetica Classificazione con vincoli Metodi innovativi (machine learning) es. Self-organizing maps
 es. Self-organizing maps.")
3
Classificazione (= Cluster Analysis) Obiettivo:
? (= Cluster Analysis) Obiettivo: massimizzare l’omogeneità dei gruppi (o classi o clusters) (cioè: gli oggetti simili devono essere nello stesso cluster) Problema generale: cercare le discontinuità nello spazio dei dati da classificare
 Obiettivo: massimizzare l’omogeneità dei gruppi (o classi o clusters) (cioè: gli oggetti simili devono essere nello stesso cluster) Problema generale: cercare le discontinuità nello spazio dei dati da classificare.")
4
Discontinuità Reali o “naturali”: es. tassonomia Arbitrarie:
es. ecologia delle comunità

5
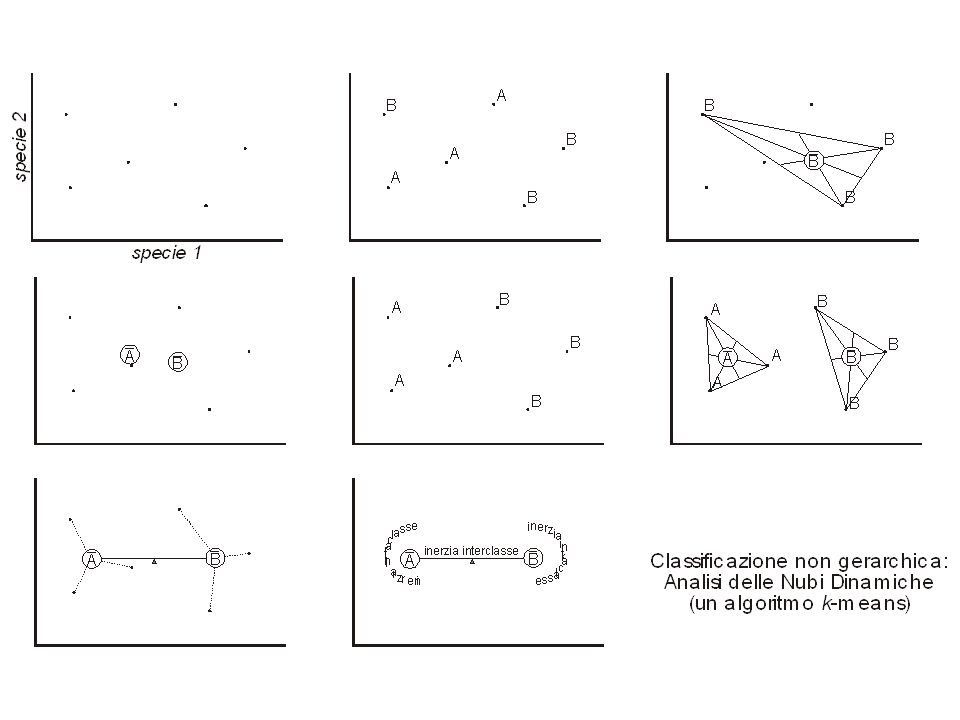
Clustering non-gerarchico: k-means
Si utilizza direttamente la matrice dei dati calcolando distanze euclidee Si massimizza la varianza inter-classe per un numero dato a priori di classi In pratica, equivale a cercare le classi che massimizzano il rapporto F di una MANOVA a una via

6
k-means Procedura iterativa: 1. Scegli un numero di classi
2. Assegna gli oggetti alle classi (a caso o in base ad un’altra classificazione) 3. Sposta gli oggetti nelle classi il cui centroide è più vicino (la varianza intra-classe diminuisce) 4. Ripeti lo step 3 finchè non c’è più nessun cambiamento nella composizione delle classi
 3. Sposta gli oggetti nelle classi il cui centroide è più vicino (la varianza intra-classe diminuisce) 4. Ripeti lo step 3 finchè non c’è più nessun cambiamento nella composizione delle classi.")
8
k-means con 3 classi Variabile InterSQ gdl IntraSQ gdl rapporto F
X Y ** TOTALE **

9
k-means con 3 classi Classe 1 di 3 (contiene 4 casi)
Membri Statistiche Caso Distanza | Variabile Min Media Max Dev.St. Caso | X Caso | Y Caso | Caso | Classe 2 di 3 (contiene 4 casi) Caso Distanza | Variabile Min Media Max Dev.St. Caso | X Caso | Y Caso | Caso | Classe 3 di 3 (contiene 2 casi) Caso | X Caso | Y
 Caso Distanza | Variabile Min Media Max Dev.St. Caso | X Caso | Y Caso | Caso | Classe 3 di 3 (contiene 2 casi) Caso | X Caso | Y")
10
Svantaggi della classificazione k-means
Ottimizza le classi, ma non in modo globale (iterando si può ottenere una partizione più efficace) Bisogna scegliere il numero di classi a priori Ma quante classi devono essere scelte?
 Bisogna scegliere il numero di classi a priori. Ma quante classi devono essere scelte")
12
Classificazione gerarchica
Solitamente si rappresenta con un dendrogramma

13
Classificazione gerarchica
Divisiva Si cercano partizioni successive di un insieme di oggetti in due sotto-insiemi in modo da soddisfare un criterio predefinito Agglomerativa Si aggregano gli oggetti in gruppi ed i gruppi fra loro secondo un criterio predefinito

14
Classificazione gerarchica divisiva
Si inizia con tutti gli oggetti in una sola classe, poi: si dividono mediante classificazioni k-means o altre tecniche divisive con partizioni in due classi; si divide ogni volta la classe più eterogenea… Oppure si dividono simultaneamente tutte le classi esistenti. Si tratta di tecniche efficienti, ma poco usate!

15
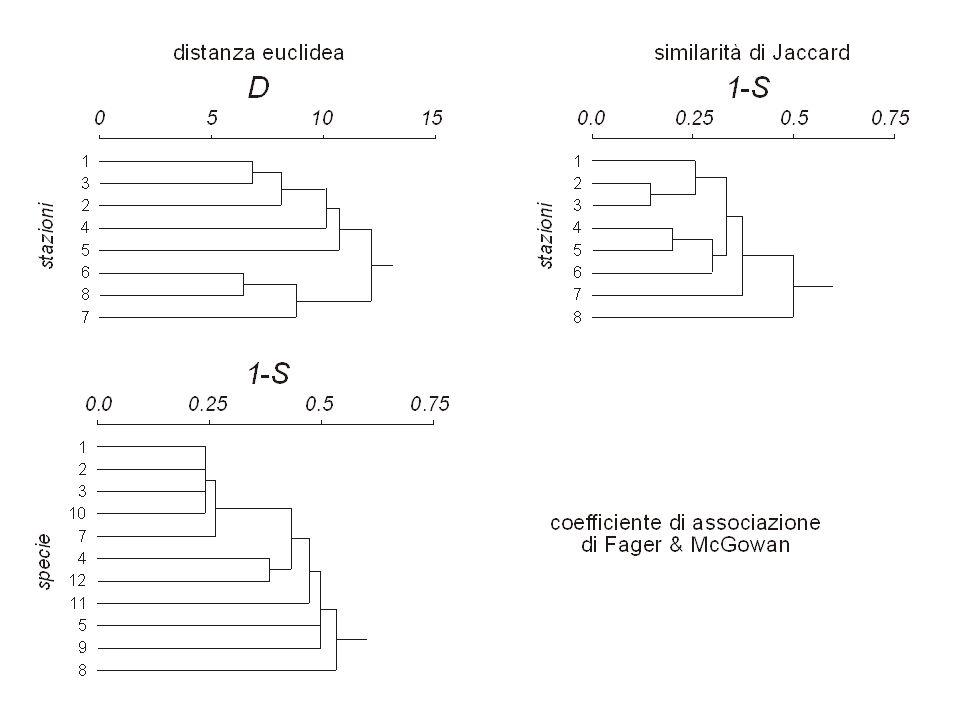
Classificazione gerarchica agglomerativa
Si inizia con un oggetto per classe Le classi vengono fuse finchè ne rimane una soltanto E’ la classe di metodi di gran lunga più ampiamente diffusa

16
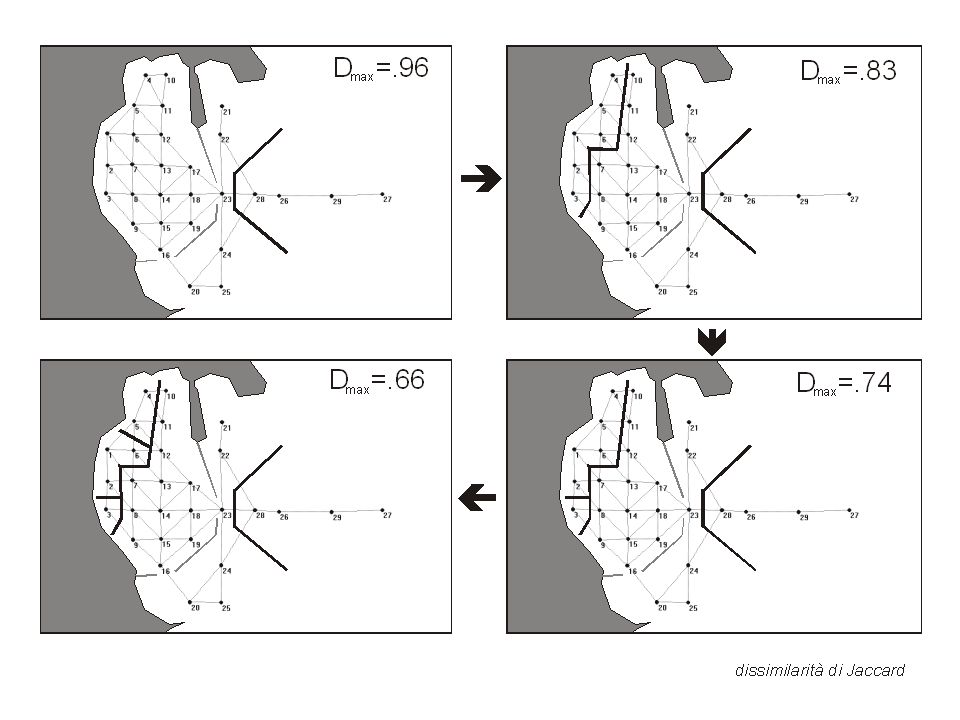
Classificazione gerarchica agglomerativa
Si lavora su una matrice di dissimilarità o distanza Procedura generale: 1. Si calcola una matrice simmetrica di dissimilarità/distanza fra le classi Le classi fra cui la dissimilarità/distanza è minima vengono fuse fra loro Si calcola la dissimilarità/distanza fra la nuova classe ottenuta e tutte le altre N.B. I diversi algoritmi differiscono nel punto 3

17
Classificazione gerarchica agglomerativa
A B C D E A B C D E AD B C E AD B ? 0 . . C ? E ? Prima fusione: A e D Come calcolare le nuove distanze?

18
Classificazione gerarchica agglomerativa Legame semplice
A B C D E A B C D E AD B C E AD B C ? E ? d(AD,B)=Min{d(A,B), d(D,B)}
=Min{d(A,B), d(D,B)}")
19
Classificazione gerarchica agglomerativa Legame completo
A B C D E A B C D E AD B C E AD B C ? E ? d(AD,B)=Max{d(A,B), d(D,B)}
=Max{d(A,B), d(D,B)}")
20
Classificazione gerarchica agglomerativa Legame intermedio
A B C D E A B C D E AD B C E AD B C ? E ? d(AD,B)=Mean{d(A,B), d(D,B)}
=Mean{d(A,B), d(D,B)}")
21
Classificazione gerarchica agglomerativa Metodo di Ward
Minimizza la varianza intra-classe Affine ad algortimi basati sul calcolo delle distanze dai centroidi di classe (come nel caso dell’algoritmo k-means)
")
22
Legame intermedio
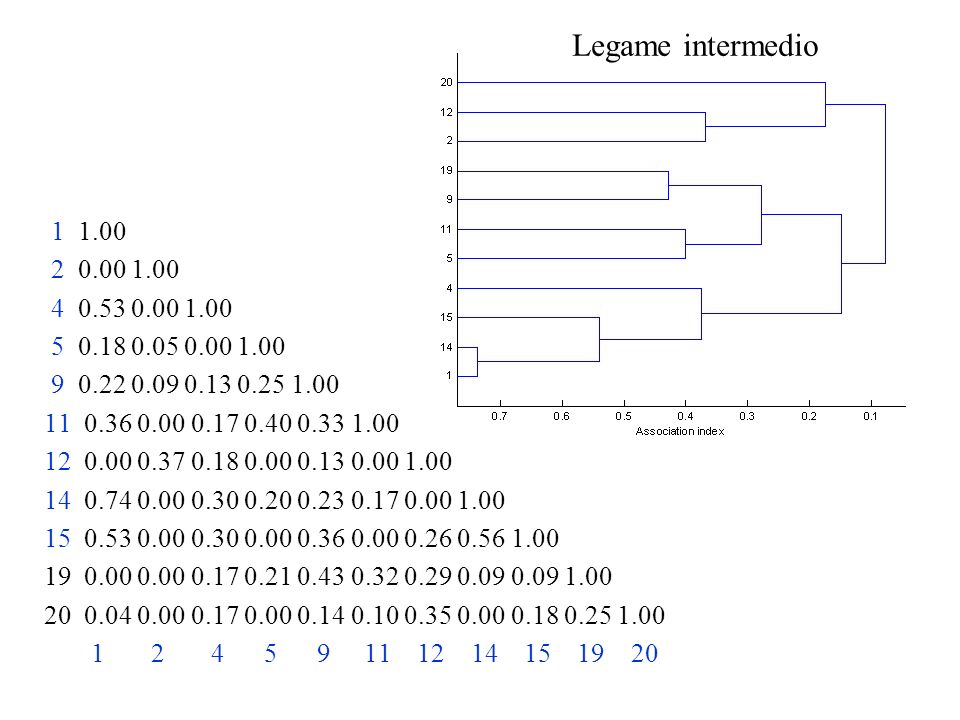
23
Legame singolo Legame intermedio Legame completo Algoritmo di Ward

24
Metodi di classificazione gerarchica agglomerativa
Legame semplice Produce “catene” di oggetti, “contrae” lo spazio intorno alle classi Non appropriato se l’errore di campionamento è grande Usato in tassonomia Invariante rispetto alle trasformazioni dei dati Legame completo Produce classi compatte e “dilata” lo spazio intorno a esse Legame intermedio, centroide, di Ward Maggiore probabilità di riconoscere partizioni “naturali” Non invarianti rispetto alle trasformazioni dei dati

26
Coefficiente di correlazione cofenetica (CCC)
Correlazione fra la matrice di dissimilarità originale e quella inferita in base alla classificazione CCC >~ 0.8 indica un buon accordo CCC <~ 0.8 indica che il dendrogramma non è una buona rappresentazione delle relazioni fra oggetti Si può usare il CCC per scegliere l’algoritmo ottimale

27
Legame singolo Legame intermedio Legame completo Algoritmo di Ward
CCC=0.77 CCC=0.83 Legame completo Algoritmo di Ward CCC=0.80 CCC=0.75

28
Classificazione vincolata
Si definisce un vincolo di natura spaziale (es. contiguità fra oggetti) o di natura temporale (es. successione) Si definisce un metodo per verificare che il vincolo sia rispettato (es. rete di Gabriel per rappresentare la contiguità) Si applica il vincolo ad un qualsiasi algoritmo di classificazione Le classi ottenute possono essere più vicine alla nostra percezione della realtà Il fuoco si sposta dalla composizone delle classi alle discontinuità fra di esse
 o di natura temporale (es. successione) Si definisce un metodo per verificare che il vincolo sia rispettato (es. rete di Gabriel per rappresentare la contiguità) Si applica il vincolo ad un qualsiasi algoritmo di classificazione. Le classi ottenute possono essere più vicine alla nostra percezione della realtà. Il fuoco si sposta dalla composizone delle classi alle discontinuità fra di esse.")
29
k=5 k=5

31
Problemi aperti Esistono realmente classi biologicamente o ecologicamente rilevanti? Il dendrogramma rappresenta la realtà biologica (web-of-life vs. tree-of-life)? Quante classi usare? le regole per la selezione sono arbitrarie! Quale metodo usare? la tecnica ottimale dipende dai dati! I dendrogrammi non sono efficienti nel visualizzare classificazioni complesse…
 Quante classi usare le regole per la selezione sono arbitrarie! Quale metodo usare la tecnica ottimale dipende dai dati! I dendrogrammi non sono efficienti nel visualizzare classificazioni complesse…")
33
C’è qualcosa di meglio per casi complessi?
Esistono metodi di nuova generazione, che non sono ancora molto diffusi in Ecologia La loro diffusione sta crescendo, ma bisogna che siano accettati dagli ecologi In molti casi, sfruttano le capacità di calcolo attualmente disponibili per tutti Si tratta soprattutto di tecniche mutuate dal campo del Machine Learning, dell’Intelligenza Artificiale e del Data Mining

34
Ordinamento e classificazione:
Self-Organizing Maps (SOMs) o Mappe di Kohonen
 o Mappe di Kohonen.")
35
. . . Campioni Oi Op O1 O2 O3 Specie sp1 sp2 spn Inizializzazione
Specie sp1 sp2 spn . . . . . Inizializzazione Addestramento delle unità virtuali (iterativo) - scelta casuale di un’osservazione - identificazione della “best matching unit” (BMU) O - addestramento della BMU e delle unità adiacenti O Proiezione delle osservazioni sulla mappa O We consider a classical data set in the form of a matrix with n rows and p columns, the rows representing the species and the columns the sample units. Measurements of abundance may be density, presence, frequency biomass and so on. With the Self Organizing Map , the dataset will be projected in a non-linear way onto a rectangular grid laid out on a hexagonal lattice: the Kohonen map. For this purpose, in each hexagon, a reference vector will be considered. The reference vectors are in fact virtual sites with species abundance to be computed. The modifications of the Virtual Units are made through an Artificial Neural Network and computed during a training phase by iterative adjustments. In fact, the Kohonen neural network consists of two layers: the first one (input layer) is connected to each vector of the dataset, the second one (output layer) forms a two-dimensional array of nodes. In the output layer, the units of the grid (virtual sites) give a representation of the distribution of the sample units in an ordered way. For learning, only input units are used, no expected-output data is given to the system: we are referring to unsupervised learning. Some words about the training of this network : •The first step is initialization : the virtual sites are chosen randomly among the the sample units. Second step : a sample unit is randomly chosen as an input unit, then this input is connected to each unit in the map. We are finding the map unit closest to the input unit. When this unit has been found, we'll talk about the Best Matching Unit. We have to modify this Best Matching Unit in order to reduce the distance between the sample unit and the reference vector. •But to obtain a smooth representation on the map, the neighbours of the Best Matching Unit are also updated. •Then, with an iterative process, the reference vectors are changed and learn the distribution of the samples. And now each sample can be projected on the map by seeking its Best Matching Unit. O Vettori di riferimento (unità virtuali)
 - scelta casuale di un’osservazione. - identificazione della best matching unit (BMU) O. - addestramento della BMU. e delle unità adiacenti. O. Proiezione delle osservazioni sulla mappa. O. We consider a classical data set in the form of a matrix with n rows and p columns, the rows representing the species and the columns the sample units. Measurements of abundance may be density, presence, frequency biomass and so on. With the Self Organizing Map , the dataset will be projected in a non-linear way onto a rectangular grid laid out on a hexagonal lattice: the Kohonen map. For this purpose, in each hexagon, a reference vector will be considered. The reference vectors are in fact virtual sites with species abundance to be computed. The modifications of the Virtual Units are made through an Artificial Neural Network and computed during a training phase by iterative adjustments. In fact, the Kohonen neural network consists of two layers: the first one (input layer) is connected to each vector of the dataset, the second one (output layer) forms a two-dimensional array of nodes. In the output layer, the units of the grid (virtual sites) give a representation of the distribution of the sample units in an ordered way. For learning, only input units are used, no expected-output data is given to the system: we are referring to unsupervised learning. Some words about the training of this network : •The first step is initialization : the virtual sites are chosen randomly among the the sample units. Second step : a sample unit is randomly chosen as an input unit, then this input is connected to each unit in the map. We are finding the map unit closest to the input unit. When this unit has been found, we ll talk about the Best Matching Unit. We have to modify this Best Matching Unit in order to reduce the distance between the sample unit and the reference vector. •But to obtain a smooth representation on the map, the neighbours of the Best Matching Unit are also updated. •Then, with an iterative process, the reference vectors are changed and learn the distribution of the samples. And now each sample can be projected on the map by seeking its Best Matching Unit. O. Vettori di riferimento. (unità virtuali)")
36
Al termine della procedura di addestramento…
Oj On At the end of the learning process, we have two data sets : the initial data set. The data set with the virtual units : the species components are known for each virtual unit.

37
Visualizzazione delle osservazioni
Oj On Visualizzazione delle Unità Virtuali O1 Oj On UV1 UV2 UVk UVS ... So at the end of the learning, some information can be displayed on the map. Firstly, the sample units : similar sites (for species composition) are displayed in the same hexagon or in neighbouring hexagons when disimilar sites are displayed in distant hexagons. But we can also display the species composition of each virtual unit using a gray shade level. The two previous representations can be mixed on the same map.
 are displayed in the same hexagon or in neighbouring hexagons when disimilar sites are displayed in distant hexagons. But we can also display the species composition of each virtual unit using a gray shade level. The two previous representations can be mixed on the same map.")
38
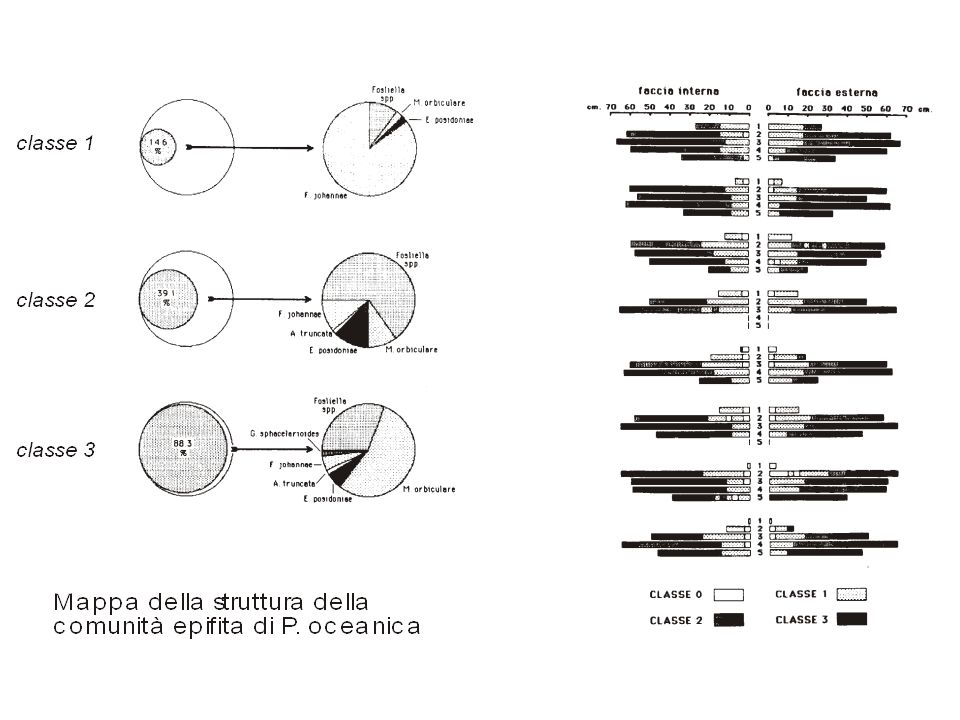
Ogni specie ha una diversa distribuzione…
If we have a look to species distributions in the virtual units using a gray shade level (dark hexagons for large abundance, light hexagons for poor abundance and white hexagons for absence), several patterns can be observed. For instance : a large regular gradient from one side of the map to an other one A small gradient for species located only in an area of the map Separated dark areas. Each pattern corresponds to the main ecological traits of each species and by a visual way, the best species for the structuration of the map can be selected. But for large data sets, the observation of each map is a very hard work, so we have looked for an index able to give the structuring power of each species : the structuring index (SI). Specie 2 Specie i
, several patterns can be observed. For instance : a large regular gradient from one side of the map to an other one. A small gradient for species located only in an area of the map. Separated dark areas. Each pattern corresponds to the main ecological traits of each species and by a visual way, the best species for the structuration of the map can be selected. But for large data sets, the observation of each map is a very hard work, so we have looked for an index able to give the structuring power of each species : the structuring index (SI). Specie 2. Specie i.")
39
ASI ILT MOL SPI PAL FIG SMA LAV MAD SPT SER LAP PAS CAV SAN SPA SOF
Una SOM 8 x 5 basata sui dati di presenza/assenza delle farfalle diurne in un sottoinsieme delle piccole isole circumsarde Specie Accordo PMA ok PBR ok PRA ok PDA ok CCR ok GCL ok LSI ok LCE ok CJA ok VAT ok VCA ok HNE ok HAR ok MJU ok PCE ok CCO ok PAE ok LTI ok LPH ok LBO ok LPI ok CAR ok LCO ok AAG ok ACR ok PIC ok CAL ok GPU ok TAV UV ASI ILT MOL SPI PAL FIG CAM SMA LAV MAD SPT MAL SER BAR LIN LAP PAS CAV LEB SAN SPA SOF BUD CAP MLT OGL RAZ SST TAV MOR

40
La matrice U consente di visualizzare le distanze fra gli elementi di una SOM.
CAP SAN TAV MOL MAD ASI SER SPI LAP SMA PAS LAV PAL CAV SPT RAZ BUD SOF FIG ILT MLT CAM LEB BAR MOR SST OGL LIN MAL D D D SPA SPA D D D

41
Un’applicazione delle Self-Organizing Maps (SOMs)
Dati estratti da: Marina Cobolli, Marco Lucarelli e Valerio Sbordoni (1996). Le farfalle diurne delle piccole isole circumsarde. Biogeographia, 18:
. Le farfalle diurne delle piccole isole circumsarde. Biogeographia, 18:")
42
28 specie identificate in 30 isole

43
ASI ILT MOL SPI PAL FIG SMA LAV MAD SPT SER LAP PAS CAV SAN SPA SOF
Una SOM 8 x 5 basata sui dati di presenza/assenza delle farfalle diurne in un sottoinsieme delle piccole isole circumsarde Specie Accordo PMA ok PBR ok PRA ok PDA ok CCR ok GCL ok LSI ok LCE ok CJA ok VAT ok VCA ok HNE ok HAR ok MJU ok PCE ok CCO ok PAE ok LTI ok LPH ok LBO ok LPI ok CAR ok LCO ok AAG ok ACR ok PIC ok CAL ok GPU ok TAV UV ASI ILT MOL SPI PAL FIG CAM SMA LAV MAD SPT MAL SER BAR LIN LAP PAS CAV LEB SAN SPA SOF BUD CAP MLT OGL RAZ SST TAV MOR

44
La matrice U consente di visualizzare le distanze fra gli elementi di una SOM.
CAP SAN TAV MOL MAD ASI SER SPI LAP SMA PAS LAV PAL CAV SPT RAZ BUD SOF FIG ILT MLT CAM LEB BAR MOR SST OGL LIN MAL D D D SPA SPA D D D

45
Self-Organizing Map vs. Analisi delle Coordinate Principali
B P Z U D - 1 . 5 2 3 MAD ASI SER SPI LAP SMA PAS LAV PAL CAV SPT CAP SAN SPA RAZ BUD SOF FIG ILT MLT CAM LEB BAR TAV MOL MOR SST OGL LIN MAL

46
Gonepteryx cleopatra (L., 1767)
Foto:

47
Gonepteryx cleopatra Altitudine Foto:

48
Classification Trees

49
Il metodo: un esempio classico...
1 Nodo 1 Iris setosa larg_petalo<10 FALSO Nodo 2 2 larg_petalo>=10 VERO Nodo 3 3 larg_petalo<18 VERO Iris versicolor (91%) Nodo 5 lung_petalo<57 Iris verginica (9%) VERO Nodo 6 Iris verginica lung_petalo>=57 FALSO Nodo 4 Iris verginica (98%) larg_petalo>=18 Iris versicolor (2%) FALSO
 Nodo 5. lung_petalo<57. Iris verginica (9%) VERO. Nodo 6. Iris verginica. lung_petalo>=57. FALSO. Nodo 4. Iris verginica (98%) larg_petalo>=18. Iris versicolor (2%) FALSO.")
50
1 2 3 80 70 60 50 40 30 20 10 10 20 30 lung_petalo Iris setosa
Iris verginica Iris versicolor 30 20 10 10 20 30 larg_petalo

51
Modelli strutturali: classification tree
Variabili predittive: Profondità Varianza della profondità (raggio=500 m) Distanza dal punto noto senza Posidonia più vicino (distanza dal margine della prateria stimata per eccesso) Variabile da predire: Classe di densità della prateria (secondo Giraud)
 Distanza dal punto noto senza Posidonia più vicino (distanza dal margine della prateria stimata per eccesso) Variabile da predire: Classe di densità della prateria (secondo Giraud)")
52
Un modello per Rosignano:

53
92% ok 84% ok

54
In sintesi…

55
Alcuni metodi di classificazione
Tipo Tecnica Uso Non gerarchico k-means Partizionare insiemi di dati Gerarchico divisivo k-means ripetuto Buona tecnica su piccoli insiemi di dati Gerarchico agglomerativo Legame semplice Tassonomia Legame completo Classi omogenee Legame intermedio, centroide, di Ward Scelta più frequente Machine learning SOM Visualizzazione di insiemi di dati complessi Classification trees Previsione e pattern recognition

Presentazioni simili






 di un composto a partire dalla percentuali in peso degli elementi che lo compongono Si ricava 1) il peso di.>")












