Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Analisi della varianza in forma matriciale Regressione con variabili dummy Significato dei parametri stimati Scomposizione della varianza Effect coding Significato dei parametri stimati Codifiche ortogonali (multipla, media) Codifiche ortogonalimultiplamedia Scomposizione della varianza Codifica ortogonale con k>3 Disegno sperimentale con due fattori indipendenti Disegno sperimentale 3x3 con interazione Disegno a misure ripetute Disegno 2x2 a misure ripetute Disegno misto Analisi covarianza Potenza del test
 Codifiche ortogonalimultiplamedia Scomposizione della varianza Codifica ortogonale con k>3 Disegno sperimentale con due fattori indipendenti Disegno sperimentale 3x3 con interazione Disegno a misure ripetute Disegno 2x2 a misure ripetute Disegno misto Analisi covarianza Potenza del test")
2
Regressione con variabili dummy (0 & 1) I dati di un esperimento con 1 fattore a k=4 livelli indipendenti
 I dati di un esperimento con 1 fattore a k=4 livelli indipendenti")
3
Regressione con variabili dummy Con k gruppi indipendenti è possibile codificare i k livelli del fattore utilizzando la Dummy coding. È allora possibile costruire una matrice X dove ad ogni colonna X k corrisponde un livello del fattore posto in contrasto con il livello di riferimento, in questo caso l’ultimo. Da notare la colonna X 0 per codificare la media di riferimento, qui quella del k-esimo gruppo.

4
Regressione con variabili dummy (0 & 1) Questo sistema di codifica implica che la generale matrice X’X assumerà come valori:
 Questo sistema di codifica implica che la generale matrice X’X assumerà come valori:")
5
Regressione con variabili dummy (0 & 1) Da cui: Analogamente la matrice X’y diventerà:
 Da cui: Analogamente la matrice X’y diventerà:")
6
Regressione con variabili dummy (0 & 1)
")
7
La codifica dummy stabilisce che il parametro b 0 corrisponde alla media della k-esima categoria presa in considerazione; gli altri parametri corrispondono alla differenza tra le medie dei gruppi e la categoria di riferimento e cioè l’ultima, quella codificata con il vettore (0,0,0). Sicché: mentre Significato parametri stimati

8
I parametri beta stimati nella codifica dummy permettono di valutare nell’ordine le seguenti ipotesi nulle: Significato parametri stimati

9
Noi sappiamo che Per ciascuna delle n k osservazioni possiamo riscontrare che X k = 1 mentre i rimanenti X -k = 0. Pertanto il valore stimato dalla regressione per ogni gruppo di indipendenti osservazioni può essere ricondotto alla media delle osservazioni. Infatti: Significato parametri stimati

10
In generale, è possibile scomporre la sommatoria totale dei quadrati (SS tot ) nella componente attribuita alla regressione (SS T ) e la componente dovuta all’errore (SS W ). Sommatorie dei quadrati

13
Risultati dell’ANOVA Dove con k si indica il numero di colonne della matrice X escludendo X 0. Come nella regressione multipla, è possibile verificare l’ipotesi nulla complessiva della uguaglianza dei beta stimati con 0, giungendo al seguente risultato:

14
Effect coding (1, 0, -1) È possibile codificare i livelli del fattore utilizzando una codifica centrata sulla media generale delle osservazioni. Tale codifica viene detta Effect coding. Da notare la colonna X 0 per codificare la media generale. L’ultimo gruppo viene ad assume come valore -1, portando a 0 la sommatoria dei valori presenti in ciascuna colonna.

15
Questo sistema di codifica implica che la generale matrice X’X assumerà come valori: Effect coding (1, 0, -1)
")
16
Da cui: Analogamente la matrice X’y diventerà: Effect coding (1, 0, -1)
")
18
La Effect coding stabilisce che il parametro b 0 corrisponde alla media generale delle osservazioni; gli altri parametri corrispondono alla differenza tra la media del gruppo e la media generale. Sicché: mentre Significato parametri stimati

19
I parametri beta stimati nella Effect coding permettono di valutare nell’ordine le seguenti ipotesi nulle: Significato parametri stimati

20
Noi sappiamo che Per ciascuna delle n k osservazioni possiamo riscontrare che X k = 1 mentre i rimanenti X -k = 0. Pertanto il valore stimato dalla regressione per ogni gruppo di indipendenti osservazioni può essere ricondotto alla media delle osservazioni. Infatti: Significato parametri stimati

21
Per il k-esimo gruppo avremo: Si mostra quindi come la differenza tra le due codifiche consiste nel valore che assume il parametro beta. Mentre nella dummy rappresenta la differenza della media rispetto al gruppo di riferimento, nella coding rappresenta la differenza rispetto alla media generale. Significato parametri stimati

22
Quando le variabili indipendenti sono tra loro mutuamente indipendenti il loro contributo all’adattamento del modello ai dati è ripartibile secondo le proporzioni: I contributi delle k variabili X saranno unici ed indipendenti e non vi saranno effetti indiretti. Tale condizione si può realizzare attraverso la codifica ortogonale dei livelli dei fattori. Codifiche ortogonali

23
La codifica è ortogonale quando: Quando le componenti degli effetti sono puramente additive, con quindi le componenti moltiplicative uguali a zero, questi vengono a costituire confronti tra medie ortogonali all’interno dell’analisi di varianza. Questo tipo di confronti vengono indicati come contrasti ortogonali. Codifiche ortogonali

24
È possibile costruire tali contrasti in differenti modi. Come regola generale, per codificare un fattore a l=3 livelli, si consiglia di utilizzare:

25
Tale codifica permette di sottoporre a valutazione le seguenti ipotesi nulle: I parametri beta stimati permettono di prendere una decisione circa tali ipotesi, infatti: Codifiche ortogonali

26
Appare chiaro come sia preferibile una codifica direttamente centrata sulle medie, in modo che i parametri beta stimati siamo più “leggibili”: Codifiche ortogonali

27
I parametri stimati corrispondono dunque a:

28
Scomposizione della varianza 1.calcolare la SS reg e la SS res per il modello contenente tutte le variabili indipendenti 2.calcolare la SS reg per il modello escludendo le variabili di cui si vuole testare la significatività (SS -i ), o in disegni bilanciati ortogonali, calcolare direttamente la sommatoria dei quadrati dovuti alle sole variabili di cui si vuole testare la significatività (SS i ). 3.effettuare un test F con al numeratore SS i pesato per la differenza i gradi di libertà; e con denominatore SS res / (n-k-1) Al fine di condurre un test statistico sui coefficienti di regressione è necessario:
 Al fine di condurre un test statistico sui coefficienti di regressione è necessario:.")
29
Scomposizione della varianza Per testare, ad esempio, il peso della sola prima variabile X 1 rispetto al modello totale, è necessario calcolare SS reg partendo da b 1 e X 1.

30
Scomposizione della varianza

32
Si può calcolare allora la statistica F per il modello completo come per le singole variabili X i.

33
Scomposizione della varianza Analogamente anche la quantità di varianza spiegata dal modello può essere ricomposta additivamente:

34
Scomposizione della varianza Esistono comunque differenti algoritmi per scomporre la varianza attribuendola ai diversi fattori, specialmente quando le variabili dipendenti (DV) e le eventuali covariate (CV) sono correlate tra loro. In accordo con la distinzione operata da SAS, sono indicate 4 modalità di scomposizione della varianza. Queste modalità prendono il nome di: Tipo-I Tipo-II Tipo-III Tipo-IV

35
Scomposizione della varianza In R / S-PLUS la funzione anova calcola SS utilizzando il Tipo-I. È stata sviluppata la libreria car che permette, attraverso la funzione Anova, di utilizzare il Tipo-II e Tipo- III. Per un approfondimento si veda: Langsrud, Ø. (2003), ANOVA for Unbalanced Data: Use Type II Instead of Type III Sums of Squares, Statistics and Computing, 13, 163-167.
, ANOVA for Unbalanced Data: Use Type II Instead of Type III Sums of Squares, Statistics and Computing, 13,")
36
Scomposizione della varianza Type-I: sequential The SS for each factor is the incremental improvement in the error SS as each factor effect is added to the regression model. In other words it is the effect as the factor were considered one at a time into the model, in the order they are entered in the model selection. The SS can also be viewed as the reduction in residual sum of squares (SSE) obtained by adding that term to a fit that already includes the terms listed before it. Pros: (1) Nice property: balanced or not, SS for all the effects add up to the total SS, a complete decomposition of the predicted sums of squares for the whole model. This is not generally true for any other type of sums of squares. (2) Preferable when some factors (such as nesting) should be taken out before other factors. For example with unequal number of male and female, factor "gender" should precede "subject" in an unbalanced design. Cons: (1) Order matters! Hypotheses depend on the order in which effects are specified. If you fit a 2-way ANOVA with two models, one with A then B, the other with B then A, not only can the type I SS for factor A be different under the two models, but there is NO certain way to predict whether the SS will go up or down when A comes second instead of first.This lack of invariance to order of entry into the model limits the usefulness of Type I sums of squares for testing hypotheses for certain designs. (2) Not appropriate for factorial designs
 obtained by adding that term to a fit that already includes the terms listed before it. Pros: (1) Nice property: balanced or not, SS for all the effects add up to the total SS, a complete decomposition of the predicted sums of squares for the whole model. This is not generally true for any other type of sums of squares. (2) Preferable when some factors (such as nesting) should be taken out before other factors. For example with unequal number of male and female, factor gender should precede subject in an unbalanced design. Cons: (1) Order matters. Hypotheses depend on the order in which effects are specified. If you fit a 2-way ANOVA with two models, one with A then B, the other with B then A, not only can the type I SS for factor A be different under the two models, but there is NO certain way to predict whether the SS will go up or down when A comes second instead of first.This lack of invariance to order of entry into the model limits the usefulness of Type I sums of squares for testing hypotheses for certain designs. (2) Not appropriate for factorial designs.")
37
Scomposizione della varianza Type II: hierarchical or partially sequential SS is the reduction in residual error due to adding the term to the model after all other terms except those that contain it, or the reduction in residual sum of squares obtained by adding that term to a model consisting of all other terms that do not contain the term in question. An interaction comes into play only when all involved factors are included in the model. For example, the SS for main effect of factor A is not adjusted for any interactions involving A: AB, AC and ABC, and sums of squares for two-way interactions control for all main effects and all other two-way interactions, and so on. Pros: (1) appropriate for model building, and natural choice for regression. (2) most powerful when there is no interaction (3) invariant to the order in which effects are entered into the model Cons: (1) For factorial designs with unequal cell samples, Type II sums of squares test hypotheses that are complex functions of the cell ns that ordinarily are not meaningful. (2) Not appropriate for factorial designs
 appropriate for model building, and natural choice for regression. (2) most powerful when there is no interaction (3) invariant to the order in which effects are entered into the model Cons: (1) For factorial designs with unequal cell samples, Type II sums of squares test hypotheses that are complex functions of the cell ns that ordinarily are not meaningful. (2) Not appropriate for factorial designs.")
38
Scomposizione della varianza Type III: marginal or orthogonal SS gives the sum of squares that would be obtained for each variable if it were entered last into the model. That is, the effect of each variable is evaluated after all other factors have been accounted for. Therefore the result for each term is equivalent to what is obtained with Type I analysis when the term enters the model as the last one in the ordering. Pros: Not sample size dependent: effect estimates are not a function of the frequency of observations in any group (i.e. for unbalanced data, where we have unequal numbers of observations in each group). When there are no missing cells in the design, these subpopulation means are least squares means, which are the best linear-unbiased estimates of the marginal means for the design. Cons: (1) testing main effects in the presence of interactions (2) Not appropriate for designs with missing cells: for ANOVA designs with missing cells, Type III sums of squares generally do not test hypotheses about least squares means, but instead test hypotheses that are complex functions of the patterns of missing cells in higher-order containing interactions and that are ordinarily not meaningful.
. When there are no missing cells in the design, these subpopulation means are least squares means, which are the best linear-unbiased estimates of the marginal means for the design. Cons: (1) testing main effects in the presence of interactions (2) Not appropriate for designs with missing cells: for ANOVA designs with missing cells, Type III sums of squares generally do not test hypotheses about least squares means, but instead test hypotheses that are complex functions of the patterns of missing cells in higher-order containing interactions and that are ordinarily not meaningful..")
39
Codifica ortogonale con K>3 Per codificare un fattore con l=4, la codifica generale diventa:

40
Codifica ortogonale con K>3 La somma dei quadrati può allora essere scomposta in modo ortogonale nel modo seguente È possibile così testare le seguenti ipotesi:

41
Disegni con più fattori indipendenti Prendiamo come riferimento il seguente esperimento con due fattori indipendenti, ciascuno a due livelli (2x2):
:")
42
Disegni con più fattori indipendenti È possibile avere una rappresentazione grafica delle medie A i B j :

43
Disegni con più fattori indipendenti Si possono codificare i due livelli di ciascun fattore assegnando a ciascun fattore una colonna della matrice X (rispettivamente X 1 e X 2 ). È inoltre necessario codificare anche l’interazione tra i fattori, aggiungendo tante colonne quante sono le possibili interazioni tra i fattori. Qui la colonna che codifica l’interazione è X 3 calcolata linearmente come prodotto X 1 X 2

44
Disegni con più fattori indipendenti La codifica ortogonale precedentemente considerata non permette una immediata comprensione dei parametri stimati. Si consiglia pertanto la seguente codifica ortogonale, dove l’elemento al denominatore corrisponde al numero dei livelli del fattore. L’interazione si calcola nel modo precedentemente indicato.

45
Disegni con più fattori indipendenti I parametri stimati indicano: Stimando i parametri beta si trova: Il parametro b 3 relativo all’interazione permette la verifica dell’ipotesi di parallelismo. Questo parametro deve essere studiato prima dei singoli fattori.

46
Disegni con più fattori indipendenti

47
È possibile a questo punto verificare le seguenti ipotesi:

48
Disegni con più fattori indipendenti È possibile stimare la percentuale di varianza spiegata dai fattori e dall’interazione, come dal modello complessivo:

49
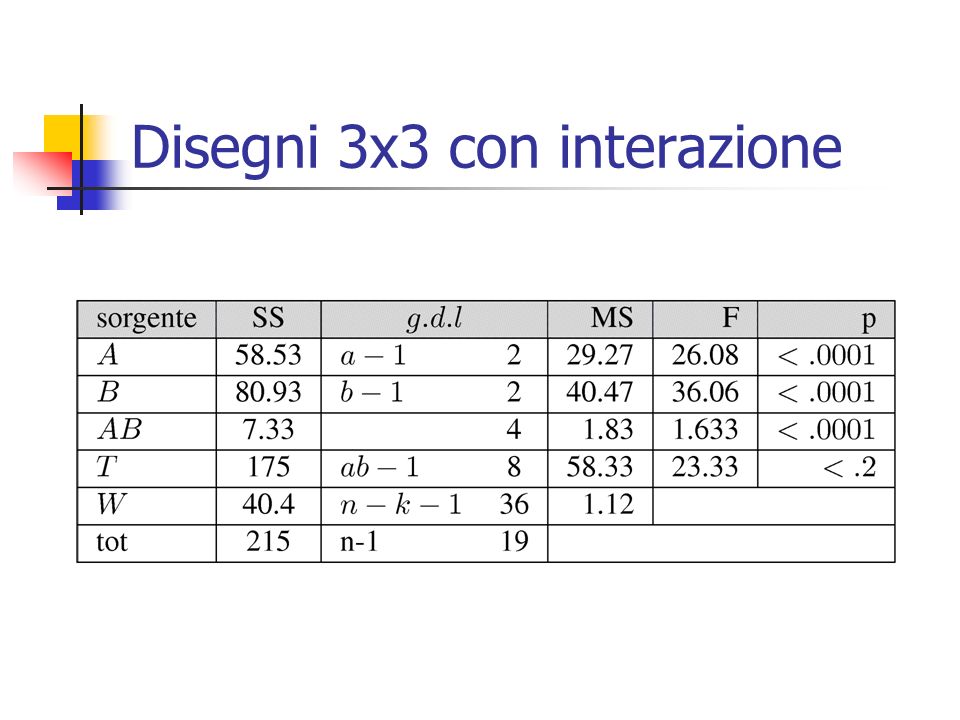
Disegni 3x3 con interazione Analizziamo ora un modello sperimentale più complesso, con due fattori ciascuno a tre livelli (3x3).
.")
50
Per codificare i livelli dei due fattori e le interazioni, è possibile costituire una matrice come la seguente, con riferimento alla codifica dummy (in cui viene riportato solo il valore osservato relativo all’ultimo soggetto). X 1 e X 2 codificano il primo fattore A, X 3 e X 4 codificano il secondo fattore B, X 5,X 6,X 7,X 8 codificano le interazioni tra i livelli. La matrice completa delle X risulterà dunque di 45 righe x 9 colonne. Disegni 3x3 con interazione

51
Ugualmente anche la seguente codifica ortogonale risulta adeguata: Disegni 3x3 con interazione

52
La seguente scrittura permette di riconoscere nei parametri beta direttamente i contrasti tra i livelli. La codifica dell’interazione può essere agevolmente fatta moltiplicando le rispettive colonne della matrice X che codificano i fattori principali

53
Stimando i parametri e le sommatorie dei quadrati si trova: Disegni 3x3 con interazione

54
Attraverso i parametri beta è immediata la scomposizione della varianza nei due fattori e nell’interazione: Disegni 3x3 con interazione

55
È possibile a questo punto verificare le seguenti ipotesi, tante quanti sono i parametri beta stimati: Disegni 3x3 con interazione

57
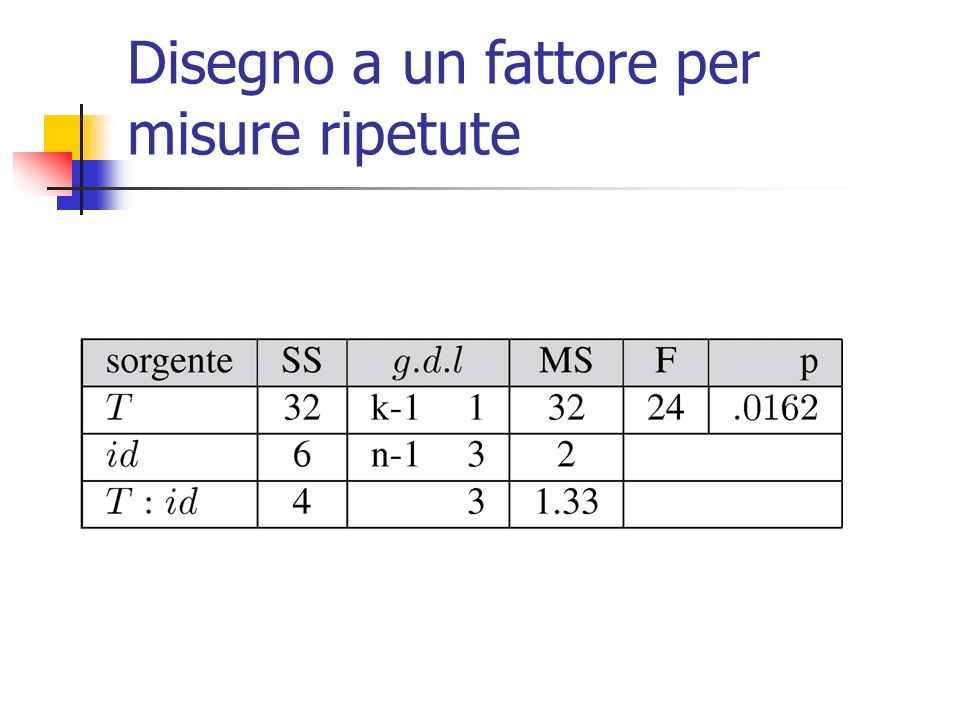
Disegno a un fattore per misure ripetute Dati osservati Es. Punteggio ottenuta in una scala a 10 punti per l’ansia prima e dopo il trattamento da 4 soggetti.

58
Disegno a un fattore per misure ripetute Soggetti Fattore Interazioni Anche un disegno semplice come quello proposto comporta la costruzione di una grande matrice in cui vengono codificati i soggetti, i fattori e le interazioni.

59
È possibile stimare i parametri b secondo la formula generale: Successivamente è possibile calcolare: Disegno a un fattore per misure ripetute

60
Diversamente dal modello fattoriale between, in questo modello within non viene calcolata la SS res. Ci troviamo qui in presenza di un modello “saturo”, in cui la quota di errore della regressione è nulla, poiché il modello spiega tutta la varianza.

61
La verifica statistica concernerà dunque la diversità da 0 della quota di varianza dovuta al fattore (SS T ) corretta per la quota di varianza dovuta all’interazione dei soggetti col trattamento (SS int ). Tale ipotesi può anche essere così formulata: Disegno a un fattore per misure ripetute

63
Disegno a misure ripetute 2x2 Prendiamo ora in considerazione un disegno sperimentale a misure ripetute con i seguenti fattori: stimolo sx/dx (qstSE) risposta sx/dx (qreSE) La variabile dipendente misurata è il tempo di reazione, misurato in msec. La misurazione delle 2x2 condizioni è avvenuta su di un campione di 20 soggetti

64
Disegno a misure ripetute 2x2 A Questo disegno comporta la costruzione di una grande matrice in cui vengono codificate le misure ripetute (nel nostro caso sono i soggetti, id), i fattori (A e B), e le interazioni. Nella tabella si considerano solo 3 soggetti. BidABAidBidABid

65
Disegno a misure ripetute 2x2 La matrice completa del disegno presenta Righe = A(2) x B(2) x id(20) = 80 Colonne = x0 + A(1) * B(1) * id(19) = 80 Per comodità l’analisi prosegue attraverso le funzioni native del linguaggio R, basate sulla regressione matriciale. Nello specifico la funziona lm(formula,…) calcola la matrice X dei contrasti partendo da variabili di tipo factor attraverso la funzione model.matrix ; successivamente stima i parametri con il metodo LS: solve(t(x)%*%x,t(x)%*%y). Si vedano in dettaglio gli script commentati, che riportano anche il codice delle funzioni rmFx e a.rm.
 calcola la matrice X dei contrasti partendo da variabili di tipo factor attraverso la funzione model.matrix ; successivamente stima i parametri con il metodo LS: solve(t(x)%*%x,t(x)%*%y). Si vedano in dettaglio gli script commentati, che riportano anche il codice delle funzioni rmFx e a.rm..")
66
Disegno a misure ripetute 2x2 Trattandosi di un modello saturo, ci si aspetta che i residui del modello siano nulli. > aov.lmgv0<-anova(lm(tr~id*qstSE*qreSE)) > aov.lmgv0 Analysis of Variance Table Response: tr Df Sum Sq Mean Sq F value Pr(>F) id 19 273275 14383 qstSE 1 1268 1268 qreSE 1 3429 3429 id:qstSE 19 6326 333 id:qreSE 19 15628 823 qstSE:qreSE 1 3774 3774 id:qstSE:qreSE 19 18030 949 Residuals 0 0
) > aov.lmgv0 Analysis of Variance Table Response: tr Df Sum Sq Mean Sq F value Pr(>F) id qstSE qreSE id:qstSE id:qreSE qstSE:qreSE id:qstSE:qreSE Residuals 0 0.")
67
Disegno a misure ripetute 2x2 È necessario individuare “a mano” l’elemento di correzione per ciascun fattore indagato. Nello specifico: qstSE viene corretto con l’interazione tra id e qstSE, qui indicata con id:qstSE. qreSE viene corretto da id:qreSE. qstSE:qreSE viene corretto da id:qstSE:qreSE.

68
Disegno a misure ripetute 2x2 La funzione rmFx permette di inserire tali contrasti e calcolare i valori di F. > aov.lmgv0<-anova(lm(tr~id*qstSE*qreSE)) > ratioF<-c(2,4, 3,5, 6,7) > aov.lmgv0<-rmFx(aov.lmgv0,ratioF) > aov.lmgv0 Analysis of Variance Table Response: tr Df Sum Sq Mean Sq F value Pr(>F) [1,] id 19 273275 14383 [2,] qstSE 1 1268 1268 3.8075 0.06593. [3,] qreSE 1 3429 3429 4.1693 0.05529. [4,] id:qstSE 19 6326 333 [5,] id:qreSE 19 15628 823 [6,] qstSE:qreSE 1 3774 3774 3.9766 0.06069. [7,] id:qstSE:qreSE 19 18030 949 [8,] Residuals 0 0
) > ratioF<-c(2,4, 3,5, 6,7) > aov.lmgv0<-rmFx(aov.lmgv0,ratioF) > aov.lmgv0 Analysis of Variance Table Response: tr Df Sum Sq Mean Sq F value Pr(>F) [1,] id [2,] qstSE [3,] qreSE [4,] id:qstSE [5,] id:qreSE [6,] qstSE:qreSE [7,] id:qstSE:qreSE [8,] Residuals 0 0.")
69
Disegno a misure ripetute 2x2 Medesimi risultati sono prodotti dalla funzione a.rm(formula,…) > a.rm(tr~qstSE*qreSE*id) Analysis of Variance Table Response: tr Df Sum Sq Mean Sq F value Pr(>F) qstSE 1 1268 1268 3.8075 0.06593. qreSE 1 3429 3429 4.1693 0.05529. id 19 273275 14383 qstSE:qreSE 1 3774 3774 3.9766 0.06069. qstSE:id 19 6326 333 qreSE:id 19 15628 823 qstSE:qreSE:id 19 18030 949 Residuals 0 0 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1

70
Disegno misto Consideriamo il seguente disegno misto, ripreso da Keppel (2001), pp. 350ss. L’esperimento “dei Sommeliers” consiste in un disegno misto 2x3: Y: variabile dipendente (“qualità del vino”), A: 1 fattore between (“tipo di vino”), B: 1 fattore within (“tempo di ossigenazione”), Id: 5 soggetti, assegnati casualmente. Lo script commentato è riportato in anova7.r
, A: 1 fattore between ( tipo di vino ), B: 1 fattore within ( tempo di ossigenazione ), Id: 5 soggetti, assegnati casualmente. Lo script commentato è riportato in anova7.r.")
71
Disegno misto

72
Ci si aspetta che i residui del modello siano nulli: Diventa necessario stabilire quali MS sono da porre al denominatore per il calcolo delle F. > anova(lm(y~A*B*id)) Analysis of Variance Table Response: y Df Sum Sq Mean Sq F value Pr(>F) A 1 53.333 53.333 B 2 34.067 17.033 id 8 34.133 4.267 A:B 2 10.867 5.433 B:id 16 19.067 1.192 Residuals 0 0.000
) Analysis of Variance Table Response: y Df Sum Sq Mean Sq F value Pr(>F) A B id A:B B:id Residuals")
73
Disegno misto Il fattore between A viene corretto con la variabilità dovuta ai soggetti, id. Il fattore within B e l’interazione A:B vengono corretti dall’interazione tra B e id, B:id. > aov.lmgv0 <- anova(lm(y~A*B*id)) > ratioF<-c(1,3, 2,5, 4,5) > aov.lmgv0<-rmFx(aov.lmgv0,ratioF) > aov.lmgv0 Analysis of Variance Table Response: y Df Sum Sq Mean Sq F value Pr(>F) A 1 53.333 53.333 12.5000 0.0076697 ** B 2 34.067 17.033 14.2937 0.0002750 *** id 8 34.133 4.267 A:B 2 10.867 5.433 4.5594 0.0270993 * B:id 16 19.067 1.192 Residuals 0 0.000
) > ratioF<-c(1,3, 2,5, 4,5) > aov.lmgv0<-rmFx(aov.lmgv0,ratioF) > aov.lmgv0 Analysis of Variance Table Response: y Df Sum Sq Mean Sq F value Pr(>F) A ** B *** id A:B * B:id Residuals")
74
Disegno misto Confronti pianificati

75
Alcune chiarificazioni ANOVA, MANOVA,ANCOVA e MANCOVA: quali differenze? ANOVA = analisi della varianza ad una o più vie ANCOVA = analisi della covarianza (o regressione) MANOVA = analisi della varianza multivariata (più variabili dipendenti) MANCOVA = analisi della covarianza multivariata (simile alla regressione multipla)
 MANOVA = analisi della varianza multivariata (più variabili dipendenti) MANCOVA = analisi della covarianza multivariata (simile alla regressione multipla).")
76
Analisi Covarianza ANCOVA è una estensione della ANOVA nella quale gli effetti principali e le interazioni delle variabili indipendenti (IV) sulla dipendente (DV) sono valutati dopo aver rimosso gli effetti di una o più covariate. Una covariata (CV) è una sorgente di variazione esterna; quando questa viene rimossa da DV, si viene a ridurre la grandezza del termine di errore.
 è una sorgente di variazione esterna; quando questa viene rimossa da DV, si viene a ridurre la grandezza del termine di errore..")
77
Analisi Covarianza Scopi principali della ANCOVA 1. Incrementare la sensibilità di un test riducendo l’errore 2. Correggere le medie della DV To adjust the means on the DV attraverso i punteggi della CV

78
Analisi Covarianza ANCOVA aumenta la potenza del test F rimuovendo varianza non sistematica nella DV. IV DV Error IV DV Covariate ANOVAANCOVA Error

79
Analisi Covarianza Prendiamo come esempio il seguente data- set, da Tabachnick, pp. 283, 287-289:

80
Analisi Covarianza Per analizzare la relazione del punteggio al post-test con il gruppo sperimentale, ponendo come covariata il punteggio al pre-test, è necessario costruire la seguente matrice:

81
Analisi Covarianza È interessante notare la differenza nella significatività dei risultati tra questo modello di analisi ed il modello che non considera il punteggio al pre- test (ANOVA). I risultati completi sono riportati nel file anova8.zip SSdfMSF Gruppo366.202183.106.13* Errore149.43529.89 *p <.05 ANCOVA SSdfMSF Gruppo432.892216.444.52 Errore287.33647.89 ANOVA

82
Per concludere, si può notare che: Regressione, ANOVA, e ANCOVA sono molto simili. La regressione include 2 o più variabili continue (1 o più IV e 1 DV) ANOVA ha almeno 1 variabile categoriale (IV) ed esattamente 1 variabile continua (DV) ANCOVA include almeno 1 variabile categoriale (IV), almeno 1 variabiale continua, la covariata (CV), e una singola variabile continua DV. MANOVA e MANCOVA sono simili, tranne che presentano multipli e correlate DV
 ANOVA ha almeno 1 variabile categoriale (IV) ed esattamente 1 variabile continua (DV) ANCOVA include almeno 1 variabile categoriale (IV), almeno 1 variabiale continua, la covariata (CV), e una singola variabile continua DV. MANOVA e MANCOVA sono simili, tranne che presentano multipli e correlate DV.")
83
Calcolo della potenza… … e dei soggetti necessari per un esperimento: http://duke.usask.ca/~campbelj/work/MorePower.html http://www.stat.uiowa.edu/~rlenth/Power/

Presentazioni simili







>")














>")
