Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
TIER 2 DI CMS RISPOSTE ALLE DOMANDE AGGIUNTIVE 1 Tommaso Boccali - INFN Pisa Roma, 27 Gennaio 2014

2
outline Bari E spiegazioni metodologiche per le domande comuni LNL Pisa Roma1-CMS Nota: alcune risposte le avrete gia’ sentite (ALICE) e altrre le sentirete domani (ATLAS). Per quanto possibile abbiamo controllato siano compatibili… 2

3
Bari 1. Fornire HS06 il valore numerico degli pledged e medi utilizzati (non cores). (domanda presente per tutti) Nel documento abbiamo scelto di Prendere I valori di HS06 di pledge dei siti Stimato il core medio: 10 HS06/core Confrontato con monitoring HLRMON Locale quando disponibile Perche’ abbiamo fatto cosi’? 3
 Nel documento abbiamo scelto di Prendere I valori di HS06 di pledge dei siti Stimato il core medio: 10 HS06/core Confrontato con monitoring HLRMON Locale quando disponibile Perche’ abbiamo fatto cosi’. 3.")
4
1. 10 HS06/core e’ un numero sensato 1. Vedi CNAF (che dice addirittura 12) 2. Vedi LNL che ha fatto il calcolo preciso: viene effettivamente 10 HS06 2. HLRMON non da’ stime in HS06 1. O ore vere, o ore.kSi2k 2. Poi da Si2k si puo’ volendo passare a HS06, utilizzando il fattore Michelotto = 250 (ma era una stima su singolo core di anni fa, chissa’ ora dove siamo) 3. HLRMON dipende dai numeri pubblicati nel BDII di sito 1. Non sempre aggiornati 4. Per la review non vogliamo testare la catena di conversione fra si2k/HS06/cores, meglio usare un valore affidabile 5. I monitoring locali (sui quali ci si appoggia per un x-check, visto anche I problemi noti di DGAS) “parlano” solo in jobs 4 Normalized a si2k
 3. HLRMON dipende dai numeri pubblicati nel BDII di sito 1. Non sempre aggiornati 4. Per la review non vogliamo testare la catena di conversione fra si2k/HS06/cores, meglio usare un valore affidabile 5. I monitoring locali (sui quali ci si appoggia per un x-check, visto anche I problemi noti di DGAS) parlano solo in jobs 4 Normalized a si2k.")
5
In pratica, I valori reali in HS06 del sito sono quelli del documento, utilizzando di nuovo #HS06 = #cores * 10 Per cui dai documenti BA = 10.1 kHS06 LNL = 11.4 kHS06 PI = 15.5 kHS06 RM1 = 700 kHS06 5

6
Periodo 04/2012 - oggi Pledges da rebus (non divise per sito) = 45 kHS06 invariata, per cui faccio periodo unico (sono 660 giorni) = 4500 cores In cores: BA = 1050 cores LNL = 1220 cores PI = 1430 cores RM1 = 550 cores TOT = 4250 (RM1 non include i 200 per calibrazione, vedi dopo) (PISA non include i ~ 100 jobs in piu’ che vediamo dal monitoring locale) 6
 = 45 kHS06 invariata, per cui faccio periodo unico (sono 660 giorni) = 4500 cores In cores: BA = 1050 cores LNL = 1220 cores PI = 1430 cores RM1 = 550 cores TOT = 4250 (RM1 non include i 200 per calibrazione, vedi dopo) (PISA non include i ~ 100 jobs in piu’ che vediamo dal monitoring locale) 6")
7
Quindi … SiteCores used HS06 usedHS06 pledge FractionNota Bari1050105001280082% LNL12201220011300113% Pisa1430+1001530012600121% Rm1550 + 20075001000075%(10% nodi off, diventa 85%) TOT45504550045000100% 7
 TOT % 7")
8
3. Fornire il ranking del Tier2 usando la metrica di qualita’ usata da ciascun esperimento. Risposta per tutti: preso il 2011- ora LNL = 99% RM1 = 96% Pisa = 89% Bari = 91% MEDIA = 94% NB: CMS identifica T2 soddisfacenti quelli che hanno > 80% E T1 soddisfacenti quelli che hanno > 90% Per cui i ns T2 sono “ok” anche per la metrica T1 Problemi specifici di Bari che hanno recentemente abbassato l’availability 2 major problems alla cabina elettrica del Campus di Bari2 LNL RM1 Bari Pisa Soglia 80% 8 Soglia 90%

9
4. Fornire la misura o la stima dei consumi del Tier-2, l’efficienza energetica in termini di rapporto fra consumi e potenza di CPU media utilizzata e se misurabile il PUE. Nel paragrafo 2.3.2 Limitazioni e costi del documento è riportata la lettura della potenza fornita dall’UPS: 99.4 kW. Nelle stesse condizioni il consumo complessivo della farm è risultato pari a 152 kVA. L’UPS alimenta sia la farm vera e propria che i Servizi della Sezione (server WEB, Mail server, DNS, etc.). La potenza complessiva viene spesa oltre che per raffreddare la sala calcolo vera e propria, anche per raffreddare altri due ambienti: quello con i servizi di Sezione e quello con gli UPS). Un calcolo preciso del PUE è complicato da fare senza misurazioni aggiuntive oltre quelle fornite dai display presenti sull’alimentazione elettrica, ma una buona indicazione può essere ottenuta valutando il coefficiente di prestazione ottenuto divedendo la potenza complessivamente assorbita (in kVA) per la potenza erogata dagli UPS (in kW) assumendo che quest’ultima coincida con la potenza informatica: PUE = 152/99,4= 1,53. Questo rapporto non è esattamente il PUE: per ottenere il PUE il numeratore va diminuito a causa del cosphi e per le perdite nell’UPS, il denominatore va diminuito per tener conto del assorbimento delle residue unità di ventilazione alimentate attraverso UPS. Si osservi infine che il coefficiente di prestazione così calcolato può avere una dipendenza dal periodo nell’anno in cui viene calcolato. Il valore di 1,53 è stato misurato a novembre 2013. kVA/kHS06= 152/40kHS06 => 3.85 W/HS06 (e’ di sito, non di cms!!!!) 9
. La potenza complessiva viene spesa oltre che per raffreddare la sala calcolo vera e propria, anche per raffreddare altri due ambienti: quello con i servizi di Sezione e quello con gli UPS). Un calcolo preciso del PUE è complicato da fare senza misurazioni aggiuntive oltre quelle fornite dai display presenti sull’alimentazione elettrica, ma una buona indicazione può essere ottenuta valutando il coefficiente di prestazione ottenuto divedendo la potenza complessivamente assorbita (in kVA) per la potenza erogata dagli UPS (in kW) assumendo che quest’ultima coincida con la potenza informatica: PUE = 152/99,4= 1,53. Questo rapporto non è esattamente il PUE: per ottenere il PUE il numeratore va diminuito a causa del cosphi e per le perdite nell’UPS, il denominatore va diminuito per tener conto del assorbimento delle residue unità di ventilazione alimentate attraverso UPS. Si osservi infine che il coefficiente di prestazione così calcolato può avere una dipendenza dal periodo nell’anno in cui viene calcolato. Il valore di 1,53 è stato misurato a novembre kVA/kHS06= 152/40kHS06 => 3.85 W/HS06 (e’ di sito, non di cms!!!!) 9.")
10
5. Riassumere i contributi forniti da CSN, CCR e GE negli ultimi 5 anni per lo sviluppo dell’infrastruttura e il funzionamento del sito. 10

11
6. Definire l’impegno da parte della struttura ospitante per la manutenzione ordinaria e straordinaria dei componenti dell’infrastruttura. L’Università di Bari contribuisce attraverso: La fornitura e la manutenzione dei locali La manutenzione dell’alimentazione elettrica. Si sono da poco conclusi i lavori di riqualificazione della cabina MT/BT del Dipartimento la fornitura dell’energia elettrica In generale: La Sezione INFN si occupa della Manutenzione Ordinaria Per la M. Straordinaria, la Sezione prova a coprire, richiedendo contributo CCR altrimenti 11

12
7. Completare la descrizione del personale aggiungendo le persone coinvolte in ruoli manageriali e di esperimento con i relativi FTE. Oltre alla tabella nel documento, ecco altro personale CMS che svolge attività per il TIER2: 12

13
8. Indicare se le risorse del Tier-2 sono disponibili per uso opportunistico per altri gruppi di ricerca. La farm di Bari è da sempre organizzata come farm multidisciplinare. Le risorse aggiuntive rese disponibili mantenendo attive, compatibilmente con i consumi elettrici, alcune delle risorse della farm dopo il periodo di ammortamento, sono state messe a disposizione degli utenti che in modo opportunistico, usando il middleware di grid o con account locale sul cluster, hanno potuto usare la farm di calcolo. La farm di Bari oltre che agli utenti locali è aperta ad alcune VO internazionali, come biomed e compchem, a cui viene garantito un uso opportunistico delle risorse computazionali. Informazioni interattive si possono trovare a questo link: http://cloud-mysql.ba.infn.it/ 13

14
2013 14
15
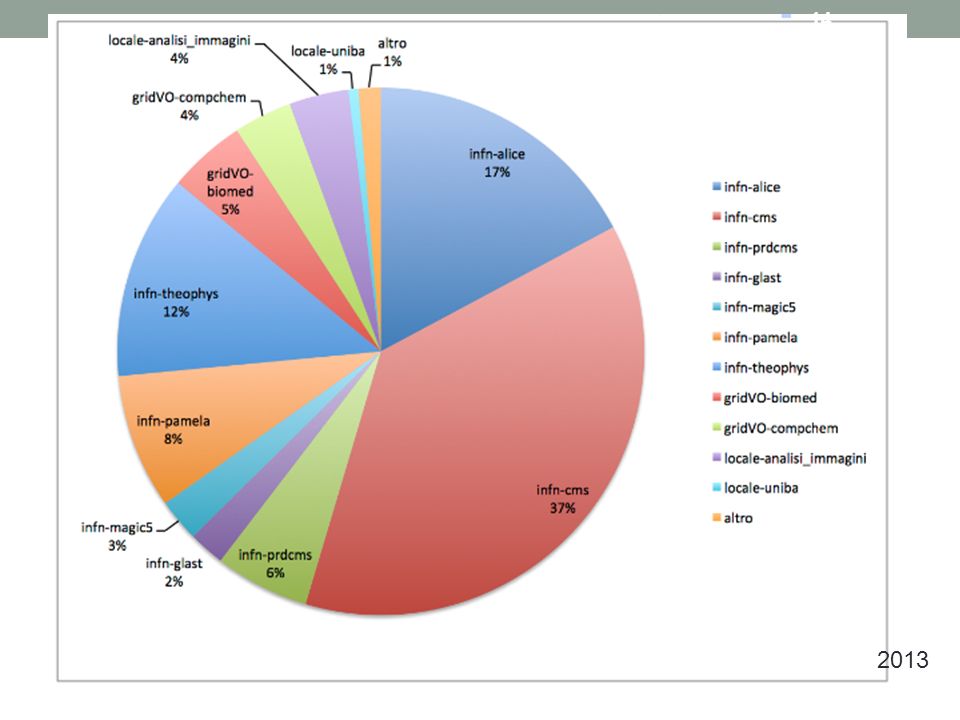
9. Il modello di calcolo di LHC potrebbe evolvere verso un numero minore di centri di maggiori dimensioni. Per questioni di economia di scala questi centri potrebbero essere multidisciplinari. Dire quali sono in termini di infrastruttura e/o personale i possibili margini di espansione del vostro sito. Le risorse computazionali presenti nella farm di Bari comprendono, sia le risorse dei TIER2 di ALICE e CMS, ma anche risorse acquistate da altri esperimenti INFN come per esempio PAMELA, FERMI-GLAST, T2K, Totem, Magic5, gruppo teorico, e perfino risorse acquistate da gruppi non INFN. La gestione della Farm è stata sempre improntata ad assicurare ai contributori delle risorse un uso corrispondente al loro contributo. E’ opportuno precisare che in molti casi l’uso da parte di altri gruppi di utenti (diversi da CMS e Alice) non è stato puramente opportunistico ma è stato fornito un vero e proprio supporto agli utenti. Questo approccio ha permesso acquisire utenti anche da altri gruppi di ricerca della Sezione e del Dipartimento di Fisica e più in generale dell’Università di Bari, ma soprattutto ha dato la possibilità di contribuire a progetti multidisciplinari come per esempio quelli svolti in collaborazione con la comunità di bioinformatica (quali LIBI, Bioinfogrid, BioVeL). Questa tipo di attività, ha dimostrato già una sua autosostenibilità evidente dalla continuità temporale dei progetti citati (dal 2005 al 2014). 15
 non è stato puramente opportunistico ma è stato fornito un vero e proprio supporto agli utenti. Questo approccio ha permesso acquisire utenti anche da altri gruppi di ricerca della Sezione e del Dipartimento di Fisica e più in generale dell’Università di Bari, ma soprattutto ha dato la possibilità di contribuire a progetti multidisciplinari come per esempio quelli svolti in collaborazione con la comunità di bioinformatica (quali LIBI, Bioinfogrid, BioVeL). Questa tipo di attività, ha dimostrato già una sua autosostenibilità evidente dalla continuità temporale dei progetti citati (dal 2005 al 2014). 15.")
16
Considerazioni sui margini di espansione Infrastruttura: Il progetto ReCaS rappresenta per Bari un momento di forte espansione sia per quanto riguarda la parte infrastrutturale (fino a 1 MW di potenza informatica, 80 racks) sia per quanto riguarda le risorse computazionali: più di un fattore due rispetto alle risorse attualmente disponibili. E’ però necessario aggiungere che sfruttando il progetto ReCaS, si sta procedendo ad una valutazione sistematica di diversi tool di gestione della farm: ci aspettiamo che, pur con un raddoppio delle dimensioni della farm, non sia necessario un incremento di personale. Per raggiungere la scala finale di ReCaS ovviamente la quantità di personale necessario **non** sarà lineare. 16

17
ReCaS Il centro parte con circa 600kW di potenza IT e 60 Rack utilizzabili. Nella configurazione finale (1MW e 80 Rack) è possibile ospitare fino a 35-40 mila cores (~ 400 kHS06) e 50 PetaByte di storage. Considerando le CPU e i dischi attualmente in produzione. Questo con la tecnologia di oggi, poi -> legge di Moore 17
 è possibile ospitare fino a mila cores (~ 400 kHS06) e 50 PetaByte di storage. Considerando le CPU e i dischi attualmente in produzione. Questo con la tecnologia di oggi, poi -> legge di Moore 17.")
18
Personale: E’ stato di recente approvato dal Direttivo un bando di tecnologo T.I. per il Servizio Calcolo della Sezione di Bari. Inoltre, come descritto nel documento, negli anni scorsi la gestione del TIER2 è stata realizzata attraverso una serie di contratti su fondi esterni, in generale dell’INFN ma anche in qualche caso dell’Università di Bari, sfruttando al massimo tutte le sinergie tra gli obiettivi dei progetti e le attività di gestione della farm. L’esperienza fin qui maturata sui progetti su fondi esterni ci fa ben sperare che anche per il futuro questa strada sia ancora percorribile. Infine, all’interno del progetto ReCaS stiamo mettendo particolare attenzione, soprattutto in riferimento alle risorse acquisite nel progetto dell’Università, affinchè il centro di calcolo diventi autosostenibile. Questo ci fa sperare che ulteriori unità di personale possano essere pagate in futuro anche dall’Università. 18

19
Nota generale sull’espandibilita’ Il manpower necessario NON scala con HS06 e/o TB, ma con il numero di oggetti singoli e distinti da gestire. Per esempio, 100 macchine dual core danno lo stesso carico di lavoro di 100 macchine a 32 cores Un sistema SAN da 100 dischi da 1 TB da’ lo stesso lavoro di un sistema da 4 TB Un sistema SAN da 100 dischi da ~ lo stesso lavoro di un sistema SAN da 500 dischi (“contano le teste dello storage, non I dischi”) Lo stesso per elettricita’/raffreddamento/m^3 In prima approx, scalano con il numero di CPU, non di core In prima approx, scalano con il numero di WN 19
 Lo stesso per elettricita’/raffreddamento/m^3 In prima approx, scalano con il numero di CPU, non di core In prima approx, scalano con il numero di WN 19.")
20
Quindi l’espandibilita’ realizzata con aggiornamento tecnologico e’ praticamente gratis dal punto di vista infrastrutturale/ di manpower; dove possibile abbiamo fatto questo esercizio Altra cosa e’ l’espansione del centro come # di macchine installate Richiede investimenti e aumento delle spese di gestione (elettricita’) Richiede nuovi spazi Richiede aumento di manpower, che certamente pero’ NON e’ lineare con le risorse installate Amministrare 100 WN e’ marginalmente piu’ complesso che amministrarne 200, soprattutto se in presenza di sistemi automatizzati di gestione installazione che oggi tutti abbiamo Nel 2006 i nostri siti avevano ~ 20 WN, e c’era tipicamente PIU’ personale di adesso 20
 Richiede nuovi spazi Richiede aumento di manpower, che certamente pero’ NON e’ lineare con le risorse installate Amministrare 100 WN e’ marginalmente piu’ complesso che amministrarne 200, soprattutto se in presenza di sistemi automatizzati di gestione installazione che oggi tutti abbiamo Nel 2006 i nostri siti avevano ~ 20 WN, e c’era tipicamente PIU’ personale di adesso 20")
21
LEGNARO 1. Fornire il valore numerico degli HS06 pledged e medi utilizzati (non cores). Vedere parte di Bari … 2. Fornire il ranking del Tier2 usando la metrica di qualita’ usata da ciascun esperimento. Vedere parte di Bari … 21

22
3. Fornire la misura o la stima dei consumi del Tier-2, l’efficienza energetica in termini di rapporto fra consumi e potenza di CPU media utilizzata e se misurabile il PUE. LEGNARO: PUE = (75+50)/75 = 1.7 (LNL) “Il consumo medio attuale è di circa 75 kW per le macchine in sala e circa 50 kW per il raffreddamento, quindi ampiamente entro i limiti dell’infrastruttura “ PADOVA: PUE = 121 / 86 = 1.4 consumo macchine: 43% di 200kW = 86kW raffreddamento: 35 kW (x LNL e’ di sito, non di cms!) W/HS06 sui due siti ~6 22
/75 = 1.7 (LNL) Il consumo medio attuale è di circa 75 kW per le macchine in sala e circa 50 kW per il raffreddamento, quindi ampiamente entro i limiti dell’infrastruttura PADOVA: PUE = 121 / 86 = 1.4 consumo macchine: 43% di 200kW = 86kW raffreddamento: 35 kW (x LNL e’ di sito, non di cms!) W/HS06 sui due siti ~6 22.")
23
4. Riassumere i contributi forniti da CSN, CCR e GE negli ultimi 5 anni per lo sviluppo dell’infrastruttura e il funzionamento del sito. Ci sono i seguenti finanziamenti CCR, tutti relativi a networking (centro stella T2 e link LNL-PD) 2008 - modulo 4 porte 10Gb per HP5400 piu’ transceiver per collegamento con PD 11k di finanziamento parziale 2010 switch centro stella T2: 16k manutenzione fibra LNL-PD: 9.5k 2011 reintegro centro stella T2: 18k manutenzione fibra LNL-PD: 9.5k 2012 ottiche 10Gb ER per link LNL-PD: 12k manutenzione fibra LNL-PD: 9.5k Vedi anche commenti alla domanda 8. 23
 modulo 4 porte 10Gb per HP5400 piu’ transceiver per collegamento con PD 11k di finanziamento parziale 2010 switch centro stella T2: 16k manutenzione fibra LNL-PD: 9.5k 2011 reintegro centro stella T2: 18k manutenzione fibra LNL-PD: 9.5k 2012 ottiche 10Gb ER per link LNL-PD: 12k manutenzione fibra LNL-PD: 9.5k Vedi anche commenti alla domanda")
24
5. Definire l’impegno da parte della struttura ospitante per la manutenzione ordinaria e straordinaria dei componenti dell’infrastruttura. Legnaro: Energia eletterica: a carico dei Laboratori. Raffreddamento: manutenzione dei chiller a carico dei Laboratori. UPS: manutenzione e sostituzione batterie a carico dei Laboratori. Rete: l’infrastruttura di rete interna (esclusi quindi i collegamenti verso l’esterno) per la parte Tier-2 è a carico di ALICE e CMS tramite il finanziamento al T2 di CSN1 e CSN3. La parte rimanente a carico dei Laboratori (principalmente Servizio Calcolo, con eventuali contributi degli esperimenti locali che usufruiscono di macchine in sala); gli apparati e le ottiche per l'accesso verso l'esterno, sia a GARR-X che al link Legnaro-Padova, sono stati finanziati dalla CCR. I contratti di manutenzione delle fibre sono a carico del GARR e quindi rientrano nei contributi INFN→GARR. STRAORDINARIA: La Sezione copre se possibile, altrimenti viene chiesto contributo CCR 24
 per la parte Tier-2 è a carico di ALICE e CMS tramite il finanziamento al T2 di CSN1 e CSN3. La parte rimanente a carico dei Laboratori (principalmente Servizio Calcolo, con eventuali contributi degli esperimenti locali che usufruiscono di macchine in sala); gli apparati e le ottiche per l accesso verso l esterno, sia a GARR-X che al link Legnaro-Padova, sono stati finanziati dalla CCR. I contratti di manutenzione delle fibre sono a carico del GARR e quindi rientrano nei contributi INFN→GARR. STRAORDINARIA: La Sezione copre se possibile, altrimenti viene chiesto contributo CCR 24.")
25
Padova: Energia elettrica: a carico dell’Universita di Padova, senza limiti di kW (convenzione in scadenza il 15.12.2013 ed in fase di rinnovo) nella bozza in via di approvazione si confermano le condizioni attuali Raffreddamento: manutenzione dell’impianto a carico della Sezione. UPS: manutenzione e sostituzione batterie a carico della Sezione. Rete: la rete interna alla sala è tipicamente a carico della Sezione. Acquisti specifici dedicati al Tier-2 (ad es. schede e ottiche 10Gb/s) sono a carico di CMS e ALICE tramite il finanziamento al Tier-2 di CSN1 e CSN3; gli apparati e le ottiche per l'accesso verso l'esterno, sia a GARR-X che al link Legnaro-Padova, sono stati finanziati dalla CCR. I contratti di manutenzione delle fibre sono a carico del GARR e quindi rientrano nei contributi INFN→GARR. STRAORDINARIA: La Sezione copre se possibile, altrimenti viene chiesto contributo CCR 25
 sono a carico di CMS e ALICE tramite il finanziamento al Tier-2 di CSN1 e CSN3; gli apparati e le ottiche per l accesso verso l esterno, sia a GARR-X che al link Legnaro-Padova, sono stati finanziati dalla CCR. I contratti di manutenzione delle fibre sono a carico del GARR e quindi rientrano nei contributi INFN→GARR. STRAORDINARIA: La Sezione copre se possibile, altrimenti viene chiesto contributo CCR 25.")
26
6. Indicare la data di scadenza della convenzione per la fornitura di energia elettrica della Sezione con l’Universita’ e se questa prevede limitazioni di utilizzo del Tier-2. Solo applicabile a Padova: la convenzione precedente e’ scaduta il 15-12-2013 ed attualmente e’ in fase di rinnovo Nella bozza attuale non sono previsti contributi espliciti per la corrente elettrica da parte dell’INFN. (nessuna variazione rispetto alla situazione attuale) 26
 26.")
27
7. Indicare una stima della percentuale dei consumi del Tier-2 rispetto a quello globale del laboratorio. Il consumo totale annuo dei Laboratori nel 2013 e’ stato di 18.479.570 kWh. Il consumo annuo del T2 assumendo il valore medio indicato nel documento di 125kW risulta di 125*24*365=1095000 kWh Frazione stimata = 6% 27

28
8. Commentare su eventuali costi aggiuntivi dovuti alla divisione del Tier-2 su due siti. I costi aggiuntivi diretti sono quelli riguardanti il link in fibra ottica tra le due sedi: fino al 2012 il contratto di manutenzione della fibra era a carico dei Laboratori (9.5k annui finanziati da CCR), dal 2013 e’ a carico del GARR, quindi il link LNL-PD rientra nel servizio che GARR fornisce all’INFN. A questo bisogna aggiungere il costo delle ottiche 10Gb di tipo ER (Extended Range) negli apparati su cui si attestano le fibre (dipende dall’apparato, ma circa ~5k ciascuna). Da notare che comunque la fibra non e’ ad uso esclusivo del Tier-2 ma e’ una risorsa disponibile per altri servizi e attivita’ in sinergia tra LNL e PD (vedi ad es. il progetto di cloud di calcolo scientifico in comune LNL-PD citato nel par. 7 del documento). Non ci sono stati altri costi tipo aumento infrastruttura ecc. in quanto entrambe le sedi erano gia’ dotate di computing room attrezzata. 28
, dal 2013 e’ a carico del GARR, quindi il link LNL-PD rientra nel servizio che GARR fornisce all’INFN. A questo bisogna aggiungere il costo delle ottiche 10Gb di tipo ER (Extended Range) negli apparati su cui si attestano le fibre (dipende dall’apparato, ma circa ~5k ciascuna). Da notare che comunque la fibra non e’ ad uso esclusivo del Tier-2 ma e’ una risorsa disponibile per altri servizi e attivita’ in sinergia tra LNL e PD (vedi ad es. il progetto di cloud di calcolo scientifico in comune LNL-PD citato nel par. 7 del documento). Non ci sono stati altri costi tipo aumento infrastruttura ecc. in quanto entrambe le sedi erano gia’ dotate di computing room attrezzata. 28.")
29
9. Completare la descrizione del personale aggiungendo le persone coinvolte in ruoli manageriali e di esperimento con i relativi FTE. Per quanto riguarda il personale di esperimento, sia per CMS che per ALICE c’e’ una persona che fa da “interfaccia” tra il Tier-2 e l’esperimento: Stefano Lacaprara per CMS e Andrea Dainese per ALICE (Come ruoli manageriali c’era Gaetano Maron fino ad ottobre 2013 ma ora non piu’ e la sua attivita’ verra’ coperta dal restante personale.) Aggiungiamo inoltre i due responsabili del Calcolo delle due sedi (contributi per procedure di acquisto, infrastruttura sale, ecc.): Michele Gulmini per Legnaro e Michele Michelotto per Padova Tutto il personale citato partecipa per complessivi stimabili FTE ~ 20% 29
 Aggiungiamo inoltre i due responsabili del Calcolo delle due sedi (contributi per procedure di acquisto, infrastruttura sale, ecc.): Michele Gulmini per Legnaro e Michele Michelotto per Padova Tutto il personale citato partecipa per complessivi stimabili FTE ~ 20% 29.")
30
10.Indicare se le risorse del Tier-2 sono disponibili per uso opportunistico per altri gruppi di ricerca. Da sempre il Tier-2 ospita anche altre VO con delle code dedicate ma senza priorita’, quindi accesso alle risorse solo se sono lasciate libere da CMS e ALICE. La VO che piu’ di tutte ha sfruttato questo uso opportunistico e’ sempre stata LHCB, ma oltre a questa ci sono anche “enmr”, “superb”, “euindia” e “cdf”. 30

31
11.Il modello di calcolo di LHC potrebbe evolvere verso un numero minore di centri di maggiori dimensioni. Per questioni di economia di scala questi centri potrebbero essere multidisciplinari. Dire quali sono in termini di infrastruttura e/o personale i possibili margini di espansione del vostro sito. Per quanto riguarda l’aspetto del supporto di VO diverse (centro multidisciplinare), va notato che gia’ adesso Legnaro-Padova e’ Tier-2 ufficiale per 2 VO pienamente supportate. La VO lhcb e’ da sempre abilitata all’uso opportunistico: se pur non vi siano contatti diretti con l’ esperimento, viene naturalmente dato supporto tramite gli eventuali ticket GGUS dell’ infrastruttura EGI. Oltre a queste, anche per altre VO minori in passato si e’ offerto un supporto ben maggiore di quello per un uso puramente “opportunistico”. Tra gli esempi ricordiamo: SuperB: setup di un SE dedicato e supporto produzioni MC, in collegamento col gruppo SuperB di Padova; Agata: VO di un esperimento di gr.3 ospitato presso LNL nel periodo 2007-2010, ha usato il T2 per lo storage locale, il data management ed il data transfer verso altri siti (setup di SE dedicato e door gridftp); Enmr: supporto all’integrazione in Grid e poi alle produzioni mediante persona nel progetto europeo EU-NMR nel team del T2 fino al 2010 (S. Badoer); EuIndia: EuIndia: supporto all’integrazione in grid e poi alle produzioni mediante persona nel progetto europeo EU-IndiaGrid nel team del T2 fino a fine progetto (S. Fantinel) 31
, va notato che gia’ adesso Legnaro-Padova e’ Tier-2 ufficiale per 2 VO pienamente supportate. La VO lhcb e’ da sempre abilitata all’uso opportunistico: se pur non vi siano contatti diretti con l’ esperimento, viene naturalmente dato supporto tramite gli eventuali ticket GGUS dell’ infrastruttura EGI. Oltre a queste, anche per altre VO minori in passato si e’ offerto un supporto ben maggiore di quello per un uso puramente opportunistico . Tra gli esempi ricordiamo: SuperB: setup di un SE dedicato e supporto produzioni MC, in collegamento col gruppo SuperB di Padova; Agata: VO di un esperimento di gr.3 ospitato presso LNL nel periodo , ha usato il T2 per lo storage locale, il data management ed il data transfer verso altri siti (setup di SE dedicato e door gridftp); Enmr: supporto all’integrazione in Grid e poi alle produzioni mediante persona nel progetto europeo EU-NMR nel team del T2 fino al 2010 (S. Badoer); EuIndia: EuIndia: supporto all’integrazione in grid e poi alle produzioni mediante persona nel progetto europeo EU-IndiaGrid nel team del T2 fino a fine progetto (S. Fantinel) 31.")
32
Espandibilita’ del sito - LNL :Calcoliamo la quantita’ massima di HS06 e TB che possono essere installati nella sala attuale ad infrastruttura esistente, senza quindi ipotizzare espansioni di spazio, potenza elettrica o raffreddamento. I rack in sala sono 22, di cui assumiamo 18 disponibili per il T2 e gli altri 4 per utilizzi diversi e servizi. Partiamo calcolando la densita’ per unita’ di rack di HS06 e TB con server e storage attuali (analoghi agli ultimi acquisti effettuati): server: dual twin con 4 server 32 core su 2U => 64 core per U => 640 HS06 / U storage: enclosure da 60HD da 4TB in 4U => 15 HD per U => 60 TB / U I rack nella sala LNL non possono essere riempiti completamente (42 U) per vincoli di peso (max 700Kg di carico utile per rack) e di corrente elettrica (max 3*32A per rack). Con questi vincoli l’occupazione massima risulta: rack di server: 12 enclosure 2U dual-twin pesano ~500Kg e assorbono ~3*28A, quindi con questi raggiungiamo il limite di potenza (~17 KW/rack). max 24 U per rack di server rack di storage: qui c’e’ solo il limite di peso, 5 enclosure 4U da 60HD pesano ~600Kg max 20 U per rack di storage Ipotizzando di dedicare 9 rack ai server e 9 allo storage otteniamo: Max server: 9 rack * 24 U = 216 U => 138240 HS06 Max storage: 9 rack * 20 U = 180 U => 10800 TB Con un rapporto HS06/TB di ~13, non distante da quello reale in uso attualmente (~10 per CMS). Naturalmente si puo’ variare il rapporto HS06/TB a seconda delle esigenze. 32
: server: dual twin con 4 server 32 core su 2U => 64 core per U => 640 HS06 / U storage: enclosure da 60HD da 4TB in 4U => 15 HD per U => 60 TB / U I rack nella sala LNL non possono essere riempiti completamente (42 U) per vincoli di peso (max 700Kg di carico utile per rack) e di corrente elettrica (max 3*32A per rack). Con questi vincoli l’occupazione massima risulta: rack di server: 12 enclosure 2U dual-twin pesano ~500Kg e assorbono ~3*28A, quindi con questi raggiungiamo il limite di potenza (~17 KW/rack). max 24 U per rack di server rack di storage: qui c’e’ solo il limite di peso, 5 enclosure 4U da 60HD pesano ~600Kg max 20 U per rack di storage Ipotizzando di dedicare 9 rack ai server e 9 allo storage otteniamo: Max server: 9 rack * 24 U = 216 U => HS06 Max storage: 9 rack * 20 U = 180 U => TB Con un rapporto HS06/TB di ~13, non distante da quello reale in uso attualmente (~10 per CMS). Naturalmente si puo’ variare il rapporto HS06/TB a seconda delle esigenze. 32.")
33
LNL Naturalmente Legnaro non avrebbe problemi ad espandersi in maniera anche piu significativa potendo contare su un campus con numerose aree libere e sulla disponibilità di una infrastruttura elettrica progettata per fornire potenze ragguardevoli e tipiche del mondo degli acceleratori. Servirebbero in questo caso investimenti mirati allo scopo e che in questo momento non sono però nella road map del laboratorio. 33

34
Espandibilita’ del sito - PD Facendo un calcolo analogo per Padova, dove i rack che possono essere dedicati al T2 sono 20, teniamo gli stessi valori delle densita’: 640 HS06 / U 60 TB / U In questo caso non ci sono vincoli di peso ma quelli di corrente elettrica per rack sono come per LNL (3 linee da 32A per rack), quindi i limiti sono: rack di server: come per LNL max 24 U per rack di server rack di storage: arriviamo fino a 9 enclosure 4U da 60HD max 36 U per rack di storage Ipotizzando 12 rack di server e 8 rack di storage otteniamo: Max server: 12 rack * 24 U = 288 U => 184320 HS06 Max storage: 8 rack * 36 U = 288 U => 17280 TB Sommando le capacita’ max delle due sale si ottiene Max server: 322560 HS06 Max storage: 28080 TB 34
, quindi i limiti sono: rack di server: come per LNL max 24 U per rack di server rack di storage: arriviamo fino a 9 enclosure 4U da 60HD max 36 U per rack di storage Ipotizzando 12 rack di server e 8 rack di storage otteniamo: Max server: 12 rack * 24 U = 288 U => HS06 Max storage: 8 rack * 36 U = 288 U => TB Sommando le capacita’ max delle due sale si ottiene Max server: HS06 Max storage: TB 34")
35
PISA 1. Fornire il valore numerico degli HS06 pledged e medi utilizzati (non cores). Vedere parte di Bari … 3. Fornire il ranking del Tier2 usando la metrica di qualita’ usata da ciascun esperimento. Vedere parte di Bari … 35

36
(inoltre…) Pisa dispone di un monitoring locale, che si basa sui logs LSF, e che e’ considerato piu’ affidabile perche’ non dipende da demoni / comunicazioni, etc Tramite tale monitoring, stimiamo ~ 100 core aggiuntivi attivi in media (vedere documento) 36
 Pisa dispone di un monitoring locale, che si basa sui logs LSF, e che e’ considerato piu’ affidabile perche’ non dipende da demoni / comunicazioni, etc Tramite tale monitoring, stimiamo ~ 100 core aggiuntivi attivi in media (vedere documento) 36")
37
2. Fornire l’availability del sito (OPS) Usiamo i report WLCG mensili http://sam-reports.web.cern.ch/sam- reports/2013/201312/wlcg/WLCG_Tier2_OPS_Dec2013.pdf Purtroppo, dopo 12 mesi sono cancellati, per cui abbiamo solo l’ultimo anno 93.1% 37
 Usiamo i report WLCG mensili reports/2013/201312/wlcg/WLCG_Tier2_OPS_Dec2013.pdf Purtroppo, dopo 12 mesi sono cancellati, per cui abbiamo solo l’ultimo anno 93.1% 37.")
38
Motivi di calo di availability Apr-13 A=84 R=85 Problemi hardware DDN e upgrade a EMI2 dei CE Jul-13 A=93 R= 93 Problemi elettrici in sala che hanno fermato lo storage Sep-13 A=95 R=95 Problemi elettrici in sala che hanno fermato lo storage In entrambi i casi, il DDN ha avuto dei problemi che NON doveva avere. L’assistenza ha proceduto in seguito a un upgrade di firmware Oct-13 A=82 R=95 Messo in produzione il 12k quindi fermo dello storage Nov-13 A=81 R=90 Distacco corrente alla marzotto e upgrade EMI3 di StoRM con il problema al FE Bug storm che ha necessitato di 3 gg di debug da parte degli sviluppatori 38

39
4. Fornire la misura o la stima dei consumi del Tier-2, l’efficienza energetica in termini di rapporto fra consumi e potenza di CPU media utilizzata e se misurabile il PUE. Da documento: Potenza “informatica” = 200 kW Potenza per servizi: 150kW PUE = 1.75 Stime piu’ recenti e accurate Potenza “informatica” = 225kW Potenza per servizi: 135kW PUE = 1.6 W/HS06: da ultimi numeri: 360 kW/66 kHS06 = 5.5 W/HS06 39

40
5. Riassumere i contributi forniti da CSN, CCR e GE negli ultimi 5 anni per lo sviluppo dell’infrastruttura e il funzionamento del sito. CSN1 = nulla; GE = nulla CSN4 = contributi specifici per il cluster dei teorici CCR = manutenzioni di apparati di rete, contributi all’infrastruttura Storage di Sezione Collaborazioni esterne = ingegneria etc … 40

41
41

42
6. Definire l’impegno da parte della struttura ospitante per la manutenzione ordinaria e straordinaria dei componenti dell’infrastruttura. 42 STRAORDINARIA: La Sezione copre se possibile, altrimenti viene chiesto contributo CCR

43
7. Esplicitare il numero di FTE coinvolti per personale tecnico e di esperimento. 43 100% calcolo scientifico NomeFunzioneFTE T.BoccaliResp. Nazionale, esperto SW di CMS 10% G.BagliesiData Manager<10 % Pers CMS 50% calcolo scientifico 100% calcolo scientifico 50% calcolo scientifico 100% calcolo scientifico 50% calcolo scientifico

44
8. Commentare sulla criticita’ delle 4 persone a tempo determinato Delle 4 persono a t.d. Una e’ interamente su SUMA e calcolo teorico Una segue anche altri progetti INFN (AAI) Una segue anche progetti di DP Una non segue calcolo GRID, ma applicativi locali (che CMS non usa) Lo statement del documento, qui riaffermato, e’ “Per la parte del personale, i membri staff riescono a garantire la gestione ordinaria del sito “ Detto questo, il numero di Progetti e Collaborazioni rende plausibile la presenza di personale a t.d. 44
 Una segue anche progetti di DP Una non segue calcolo GRID, ma applicativi locali (che CMS non usa) Lo statement del documento, qui riaffermato, e’ Per la parte del personale, i membri staff riescono a garantire la gestione ordinaria del sito Detto questo, il numero di Progetti e Collaborazioni rende plausibile la presenza di personale a t.d. 44.")
45
9. Indicare se le risorse del Tier-2 sono disponibili per uso opportunistico per altri gruppi di ricerca Il sito come politica e’ sempre stato aperto a TUTTE le VO supportate da INFNGRID, nell’ottica di mantenere le macchine piene In quanto tale, il sito ha sempre risposto (in seconda priorita’) ai ticket di TUTTE le VO (Uso opportunistico o no?) 45
 ai ticket di TUTTE le VO (Uso opportunistico o no ) 45.")
46
VO/gruppi che hanno girato a Pisa ( http://farmsmon.pi.infn.it/lsfmon )http://farmsmon.pi.infn.it/lsfmon 46
 46")
47
10.Il modello di calcolo di LHC potrebbe evolvere verso un numero minore di centri di maggiori dimensioni. Per questioni di economia di scala questi centri potrebbero essere multidisciplinari. Dire quali sono in termini di infrastruttura e/o personale i possibili margini di espansione del vostro sito. VO / Gruppi supportati ufficialmente a Pisa (extra CMS, naturalmente) SuperB: sito ufficiale di “produzione” Belle II: sito ufficiale di “produzione” Glast: abbiamo supportato (e istruito!) il VO manager, tutte le attivita’ Grid/Glast iniziate su Pisa e poi passate altrove Teorici: centro nazionale di CSN4 Nato dal fatto che i primi teorici italiani a usare Grid sono stati i pisani, avvicinati alla Grid mediante i corsi organizzati in Sede (il primo 09/2007). CVI: “…the Committee praises the upgrade of the CSN4 cluster “zefiro” which serves the computing needs of some 16 research groups” (LHCB??) 47
 SuperB: sito ufficiale di produzione Belle II: sito ufficiale di produzione Glast: abbiamo supportato (e istruito!) il VO manager, tutte le attivita’ Grid/Glast iniziate su Pisa e poi passate altrove Teorici: centro nazionale di CSN4 Nato dal fatto che i primi teorici italiani a usare Grid sono stati i pisani, avvicinati alla Grid mediante i corsi organizzati in Sede (il primo 09/2007). CVI: …the Committee praises the upgrade of the CSN4 cluster zefiro which serves the computing needs of some 16 research groups (LHCB ) 47.")
48
VO theophys 2008-2010 (prima della creazione del centro nazionale) VO theophys 2013 48
 VO theophys")
49
49 Tripiccione, 10/2013, CSN4 Tramontana, Theocluster, Zefiro

50
LHCB …. V.Vagnoni, 05/2012 50 LHCB …

51
Altre collaborazioni Ingegneria (fluidodinamica): come tramite per collaborazioni industriali 51
: come tramite per collaborazioni industriali 51")
52
52

53
Espandibilita’ del sito NON abbiamo possibilità di espansione fisica (rack) la sala è piena (34 racks) attualmente abbiamo circa 7000/700 macchine core e sostituendo tutto il vecchio con processori di ultima generazione (AMD 16 core o Intel 12) potremmo arrivare a circa 25000 core ~250 kHS06 storage: mantenendo gli attuali sistemi (2xddn9900 + 1xddn12000) per un totale di 1800 dischi Con dischi da 3 TB, ~6PB; con dischi da 4, ~7PB Tutto questo senza modifiche infrastrutturali (elettricità, rack, condizionamento e rete) Se “permettiamo” ai WN di aumentare in numero, c’e’ circa un altro fattore ~2 dovuto all’occupanza media dei rack (il tutto _OGGI_, poi legge di Moore) 53
 la sala è piena (34 racks) attualmente abbiamo circa 7000/700 macchine core e sostituendo tutto il vecchio con processori di ultima generazione (AMD 16 core o Intel 12) potremmo arrivare a circa core ~250 kHS06 storage: mantenendo gli attuali sistemi (2xddn xddn12000) per un totale di 1800 dischi Con dischi da 3 TB, ~6PB; con dischi da 4, ~7PB Tutto questo senza modifiche infrastrutturali (elettricità, rack, condizionamento e rete) Se permettiamo ai WN di aumentare in numero, c’e’ circa un altro fattore ~2 dovuto all’occupanza media dei rack (il tutto _OGGI_, poi legge di Moore) 53")
54
ROMA 1. Fornire il valore numerico degli HS06 pledged e medi utilizzati (non cores). Vedere parte di Bari … (e notare aggiunta a mano di 200 cores … vedi prossimo punto) 4. Fornire il ranking del Tier2 usando la metrica di qualita’ usata da ciascun esperimento. Vedere parte di Bari … 54
 4. Fornire il ranking del Tier2 usando la metrica di qualita’ usata da ciascun esperimento. Vedere parte di Bari … 54.")
55
2. Giustificare l’uso delle risorse pledged per le calibrazioni. Dire se questo e’ accounted dall’esperimento sia a livello nazionale che internazionale. L’uso delle risorse per le calibrazioni ECAL non e’ al momento pledged ne’ accounted. La ragione e’ che per motivi tecnici i job sono eseguiti in locale, cioe’ su code locali del T2, e quindi non passano per CRAB: infatti i job accedono i raw data, creano un formato intermedio su cui ricalcolano iterativamente per diversi passaggi. Tuttavia e’ possibile modificare HLRMON locale per accreditare questi job a CMS e quindi farne poi un pledge ufficiale. Tale modifica verrà quindi implementata ASAP. 55

56
3. Commentare sul fatto che nel 2012 e 2013 si sono resi indisponibili circa il 10% dei cores all’anno, cosa che non si riscontra negli altri siti. Come spiegato nel rapporto, nel 2012 non ci sono state nuove acquisizioni di CPU e non erano state chieste dismissioni (questo a posteriori è stato un errore di valutazione da parte del responsabile del T2). A inizio 2012 erano disponibili circa 1000 core distribuiti su circa 80 server di vario tipo (dual 2-core, dual 4-core,dual 6-core, twin e non); con il termine indisponibili si intende sia i server che nel 2012 e nel 2013 sono stati dismessi perchè guasti (in generale server vecchi con cpu dual-core o quad-core per un totale di -92 core), sia worker node in servizio ma problematici: in particolare, tra 2012 e prima metà del 2013, 5 lame di server twin acquistate da E4 (su gara nazionale) hanno dato problemi ripetuti, prolungati e non risolti da E4. Ogni lama ha 12 core (2 CPU da 6 core). Ogni intervento su una lama del genere comporta lo spegnimento dell’intera twin, quindi anche della lama gemella funzionante. L’effetto medio (-92 core dismessi -60 core ripetutamente guasti - 60 core gemelli forzosamente fermi durante interventi su quelli guasti) e’ quantificabile in circa -10% in questione. 56
. A inizio 2012 erano disponibili circa 1000 core distribuiti su circa 80 server di vario tipo (dual 2-core, dual 4-core,dual 6-core, twin e non); con il termine indisponibili si intende sia i server che nel 2012 e nel 2013 sono stati dismessi perchè guasti (in generale server vecchi con cpu dual-core o quad-core per un totale di -92 core), sia worker node in servizio ma problematici: in particolare, tra 2012 e prima metà del 2013, 5 lame di server twin acquistate da E4 (su gara nazionale) hanno dato problemi ripetuti, prolungati e non risolti da E4. Ogni lama ha 12 core (2 CPU da 6 core). Ogni intervento su una lama del genere comporta lo spegnimento dell’intera twin, quindi anche della lama gemella funzionante. L’effetto medio (-92 core dismessi -60 core ripetutamente guasti - 60 core gemelli forzosamente fermi durante interventi su quelli guasti) e’ quantificabile in circa -10% in questione. 56.")
57
5. Indicare come si e’ misurato il PUE. Abbiamo (== CMS+ATLAS!) una misura continua della potenza assorbita da tutti i dispositivi sotto UPS che sono esclusivamente quelli relativi al calcolo e reti (la parte di rack e’ gia’ sottratta) Tutta la potenza impiegata per il raffreddamento NON è sotto UPS, perciò calcoliamo il PUE come potenza erogata dal quadro elettrico principale diviso potenza erogata dall'UPS. La potenza erogata dal quadro elettrico principale non è sotto monitor continuo, ma è stata misurata a campione e risulta abbastanza stabile (come del resto la potenza erogata dall'UPS). I numeri sono: P_tot =~ 120 kW e P_UPS(info) =~ 80 kW PUE = P_tot/P_UPS(info) = 1.5 (W/HS06 = 5.8) 57
 una misura continua della potenza assorbita da tutti i dispositivi sotto UPS che sono esclusivamente quelli relativi al calcolo e reti (la parte di rack e’ gia’ sottratta) Tutta la potenza impiegata per il raffreddamento NON è sotto UPS, perciò calcoliamo il PUE come potenza erogata dal quadro elettrico principale diviso potenza erogata dall UPS. La potenza erogata dal quadro elettrico principale non è sotto monitor continuo, ma è stata misurata a campione e risulta abbastanza stabile (come del resto la potenza erogata dall UPS). I numeri sono: P_tot =~ 120 kW e P_UPS(info) =~ 80 kW PUE = P_tot/P_UPS(info) = 1.5 (W/HS06 = 5.8) 57.")
58
6. Riassumere i contributi forniti da CSN, CCR e GE negli ultimi 5 anni per lo sviluppo dell’infrastruttura e il funzionamento del sito. Negli ultimi 5 anni CSN e GE non hanno contribuito nè allo sviluppo dell’infrastruttura nè al funzionamento del sito. La CCR ha contribuito 2010: 42 k€ + 25 k€ per Router 10 Gbps, switch servizi, ottiche 2013: 9.5 k€ batterie UPS, finanz straordinario consumo 2013: 20 k€ Router di frontiera T2 I contributi citati sono condivisi tra ATLAS e CMS 58

59
7. Definire l’impegno da parte della struttura ospitante per la manutenzione ordinaria e straordinaria dei componenti dell’infrastruttura. Il Dipartimento di Fisica si limita a fornire i locali nell’ambito della convenzione con l’INFN (e la corrente!) La Sezione di Roma dell’INFN ha a suo carico la manutenzione ordinaria dell’infrastruttura di cooling, la manutenzione elettrica a valle dei quadri di distribuzione (finora è costata quasi zero, sono stati sostituiti due sezionatori del costo di circa 300 euro l’uno in 6 anni) e la manutenzione della rete dati. Le spese di manutenzione straordinaria, escluse quelle citate al punto 6 a carico della CCR, sono state finora trascurabili e a carico della Sezione. 59
 La Sezione di Roma dell’INFN ha a suo carico la manutenzione ordinaria dell’infrastruttura di cooling, la manutenzione elettrica a valle dei quadri di distribuzione (finora è costata quasi zero, sono stati sostituiti due sezionatori del costo di circa 300 euro l’uno in 6 anni) e la manutenzione della rete dati. Le spese di manutenzione straordinaria, escluse quelle citate al punto 6 a carico della CCR, sono state finora trascurabili e a carico della Sezione. 59.")
60
8. Indicare la data di scadenza della convenzione per la fornitura di energia elettrica con l’Universita’ e se questa prevede limitazioni di utilizzo del Tier-2. Come già spiegato nel rapporto non c’è una convenzione specifica per la fornitura di energia elettrica: c’è una convenzione generale tra Università e INFN firmata nel 2013 e di durata quinquennale, quindi con scadenza nel 2018. 60

61
9. Indicare se le risorse del Tier-2 sono disponibili per uso opportunistico per altri gruppi di ricerca. Le risorse del Tier-2 in linea di principio sono disponibili per uso opportunistico, purchè questo non implichi un carico di lavoro addizionale per le persone responsabili del sito, in particolare per il responsabile tecnico Dr.Ivano Talamo che è già impegnato al 100% per la gestione CMS. quindi = si possono aprire all’uso opportunistico, ma tale deve essere No support! 61

62
10.Indicare se ci sono gruppi di ricerca oltre a CMS supportati direttamente dal Tier-2. NO 62

63
11.Valutare i pro e contro di una eventuale unione col Tier-2 di ATLAS. I Tier-2 di ATLAS-Roma e CMS-Roma sono gia’ uniti nell’infrastruttura non solo di base (cooling, rete etc.) ma anche dei servizi software (LFS, monitor, installazione etc). Quello che NON e’ unito e’ attualmente 1. Lo storage 2. I WN/le code (ognuno gira sulle sue macchine) 3. I Computing Element (cioe’ sono due “siti” WLCG distinti) Analizziamo uno per uno questi punti, con costi/benefici dell’unione 63
 ma anche dei servizi software (LFS, monitor, installazione etc). Quello che NON e’ unito e’ attualmente 1. Lo storage 2. I WN/le code (ognuno gira sulle sue macchine) 3. I Computing Element (cioe’ sono due siti WLCG distinti) Analizziamo uno per uno questi punti, con costi/benefici dell’unione 63.")
64
1 – lo storage RM1-CMS usa dCache, RM1-ATLAS DPM D’altra parte DPM e’ da sempre la tecnologia + problematica per CMS. Ha sempre richiesto patch per la messa in produzione (incompatibilita’ a livello di librerie SSL con CMSSW), e il suo utilizzo a livello mondiale e’ in calo verticale. Attualmente, per siti nuovi, CMS consiglia di NON adottarlo. La sua sostenibilita’ in CMS e’ dubbia, e lo e’ anche a livello WLCG (ATLAS ha dovuto accollarsene in parte lo sviluppo / manutenzione) dCache e’ invece la tecnologia d’eccellenza x CMS, e la sua sostenibilita’ non e’ in dubbio fino a che FNAL lo utilizza (e NON esistono piani attualmente per un cambiamento a FNAL) RM1-CMS ha un’ampia esperienza in dCache, e’ il sito italiano che lo prova per primo, e Ivano Talamo e’ ben inserito nella comunita’ degli sviluppatori dCache Indipendentemente da tutto, un cambio di tecnologia con 1 PB installato e pieno non e’ facile (a meno di non avere un altro PB vuoto….) 64
, e il suo utilizzo a livello mondiale e’ in calo verticale. Attualmente, per siti nuovi, CMS consiglia di NON adottarlo. La sua sostenibilita’ in CMS e’ dubbia, e lo e’ anche a livello WLCG (ATLAS ha dovuto accollarsene in parte lo sviluppo / manutenzione) dCache e’ invece la tecnologia d’eccellenza x CMS, e la sua sostenibilita’ non e’ in dubbio fino a che FNAL lo utilizza (e NON esistono piani attualmente per un cambiamento a FNAL) RM1-CMS ha un’ampia esperienza in dCache, e’ il sito italiano che lo prova per primo, e Ivano Talamo e’ ben inserito nella comunita’ degli sviluppatori dCache Indipendentemente da tutto, un cambio di tecnologia con 1 PB installato e pieno non e’ facile (a meno di non avere un altro PB vuoto….) 64.")
65
2 – WN/le code I WN sono configurati in modo molto simile e CMS/ATLAS stanno gia’ lavorando per ottenere una configurazione comune gestita via “Puppet”. Al momento i WN targati ATLAS e quelli targati CMS si trovano in code batch diverse, accessibili rispettivamente dai job Grid delle rispettive VO. Nulla osta a abilitare l’accesso incrociato ai WN, sebbene in periodo di presa dati questa scelta potrebbe essere riconsiderata 65

66
3 – I CE (e in generale i siti WLCG) CE: al momento 4 per ATLAS e 3 per CMS Siti WLCG: INFN-ROMA1 (Atlas), INFN-ROMA1-CMS (CMS): Richiede riconfigurazione dei CE (poco male…) Richiede interventi manuali a tutti i sistemi di monitoring / accounting esistenti (WLCG, CMS, MONALISA, HLRMON, REBUS, SiteDB di CMS, database Phedex ….) nella pratica NON esiste un modo certificato per farlo se non … farlo e poi mettere una pezza ai problemi, che possono necessi Molto probabimente si perderebbe tutto lo storico antecedente Prova della sua complessita’: alcuni siti si sono trovati con nomi non ottimali, e non hanno mai pensato di cambiarli LNL si chiama tuttora INFN-LNL-2 Karlsruhe ha cambiato nome in KIT prima dell’inizio della presa dati. Un bagno di sangue durato 2 mesi Il guadagno e’ minimo: probabilmente per 2 T2 servirebbero comunque 7 CE, che sono comunque configurati uguali a meno di quella stringa … La (high) availability data da 3 CE non e’ troppo diversa da quella con 4,5,6 … 66
 availability data da 3 CE non e’ troppo diversa da quella con 4,5,6 … 66.")
67
12.Il modello di calcolo di LHC potrebbe evolvere verso un numero minore di centri di maggiori dimensioni. Per questioni di economia di scala questi centri potrebbero essere multidisciplinari. Dire quali sono in termini di infrastruttura e/o personale i possibili margini di espansione del vostro sito. l’attuale Tier-2 (ATLAS+CMS) occupa 10 rack e si puo’ espandere fino a 14 rack senza modifiche dell’infrastruttura elettrica e di cooling, senza costi aggiuntivi (a parte ovviamente l’acquisto dei rack) e negli spazi di nostra competenza I 10 rack attuali sono completamente pieni, ma non contengono tutti hardware di ultima generazione. Utilizzando CPU da 16 core Dischi da 4 Si potrebbe raddoppiare il centro a parita’ di tutto il resto OGGI (+legge di Moore per il futuro). Un aumento del numero di rack oltre 14 richiede un notevole aggiornamento dell’infrastruttura di base, sia elettrica che di cooling, oltre che una trattativa sugli spazi, che, pur essendo disponibili, non sono di nostra competenza. 67
 occupa 10 rack e si puo’ espandere fino a 14 rack senza modifiche dell’infrastruttura elettrica e di cooling, senza costi aggiuntivi (a parte ovviamente l’acquisto dei rack) e negli spazi di nostra competenza I 10 rack attuali sono completamente pieni, ma non contengono tutti hardware di ultima generazione. Utilizzando CPU da 16 core Dischi da 4 Si potrebbe raddoppiare il centro a parita’ di tutto il resto OGGI (+legge di Moore per il futuro). Un aumento del numero di rack oltre 14 richiede un notevole aggiornamento dell’infrastruttura di base, sia elettrica che di cooling, oltre che una trattativa sugli spazi, che, pur essendo disponibili, non sono di nostra competenza. 67.")
Presentazioni simili
 timeline dell'esperimento –Presa dati conclusa nel 2000. Alcune analisi tuttora in corso.>")











>")
 nella realta’ italiana u I Computing models degli esperimenti LHC gia’ presentati a Gennaio.>")

 Lamberto Luminari CSN1 – Roma, 3 Aprile 2006.>")

>")

